All Prometheus metrics are based on time series - streams of timestamped values belonging to the same metric. Each time series is uniquely identified by its metric name and optional key-value pairs called labels. The metric name specifies some characteristics of the measured system, such as http_requests_total - the total number of received HTTP requests. In practice, you often will be interested in some subset of the values of a metric, for example, in the number of requests received by a particular endpoint; and here is where the labels come in handy. We can partition a metric by adding endpoint label and see the statics for a particular endpoint: http_requests_total{endpoint="api/status"}. Every metric has two automatically created labels: job_name and instance. We see their roles in the next section.
Prometheus provides a functional query language called PromQL. The result of the query might be evaluated to one of four types:
Scalar (aka float)
String (currently unused)
Instant Vector - a set of time series that have exactly one value per timestamp.
Range Vector - a set of time series that have a range of values between two timestamps.
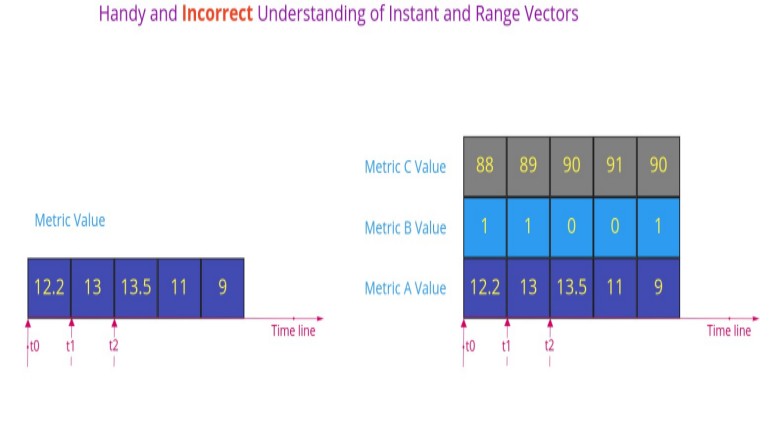
At first glance, Instant Vector might look like an array, and Range Vector as a matrix.
If that would be the case, then a Range Vector for a single time series "downgrades" to an Instant Vector. However, that's not the case: