Я думаю, многие уже успели заглянуть и прочитать эту статью на английском в моем блоге, но для тех кому все таки комфортней читать на родном языке, нежели иностранном (как сказали бы на dirty.ru – на анти-монгольском), я перевожу очередную свою статью.
Вы уже наверняка знаете, что NUMA это неравномерный доступ к памяти. В настоящий момент эта технология представлена в процессорах Intel Nehalem и AMD Opteron. Честно говоря, я, как практикующий по большей части сетевик, всегда был уверен, что все процессоры равномерно борются за доступ к памяти между собой, однако в случае с NUMA процессорами мое представление сильно устарело.
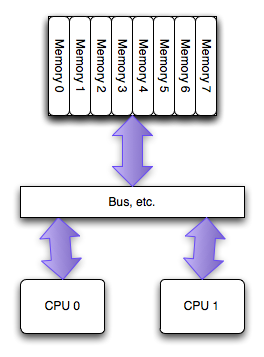
Приблизительно так это выглядело до появления нового поколения процессеров.
В новой же архитектуре каждый процессорный сокет имеет прямой доступ только к определенным слотам памяти и образует NUMA узел. То есть при 4 процессорах и 64 Гбайт памяти у вас будет 4 NUMA узла, каждый с 16 Гбайт памяти.
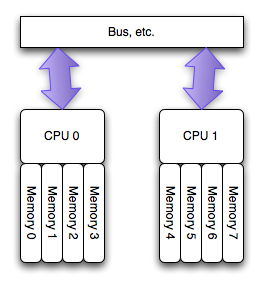
Насколько я понял, новый подход к распределению доступа к памяти был изобретен в силу того, что современные сервера настолько напичканы процессорами и памятью, что становится технологически и экономически невыгодно обеспечивать доступ к памяти через единственную общую шину. Что в свою очередь может вести к соперничеству за полосу пропускания между процессорами, ну и к более низкой масштабируемости производительности самих серверов. Новый подход привносит 2 новых понятия – Локальная память и Удаленная память. В то время как к локальной памяти процессор обращается напрямую, то к Удаленной памяти ему приходится обращаться старым дедовским методом, через общую шину, что означает более высокую задержку. Это также означает, что для эффективного использования новой архитектуры наша ОС понимать, что она работает на NUMA узле и правильно управлять своими проложениями/процессами, иначе ОС просто рискует оказаться в ситуации, когда приложение исполняется на процессоре одного узла, в то время как его (приложения) адресное пространство памяти располагается на другом узле. Быстрый поиск показал, что NUMA архитектура поддерживается Майкрософт начиная с Windows 2003 и Vmware – как минимум с ESX Server 2.
Не уверен, что в GUI как то можно увидеть данные NUMA узла, но определенно это можно посмотреть в esxtop.
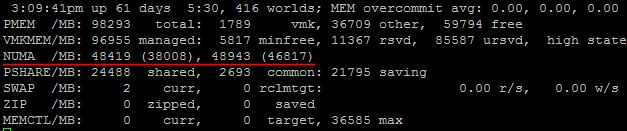
Итак, тут мы можем наблюдать, что в нашем сервере 2 NUMA узла, и что в каждом их них 48 Гбайт памяти. Вот этот документ говорит, что первое значение означает количество локальной памяти в NUMA узле, а второе, в скобочках – количество свободной памяти. Однако, пару раз на своих продакшн серверах я наблюдал второе значение выше, чем первое, и никакого объяснения этому найти не смог.
Итак, как только ESX сервер обнаруживает, что он работает на сервере с NUMA архитектурой, он незамедлительно включает NUMA планировщик, который в свою очередь заботится о виртуальных машинах и о том, чтобы все vCPU каждой машины находились в пределах одного NUMA узла. В предыдущих версиях ESX (до 4.1) для эффективной работы на NUMA системах максимальное количество vCPU виртуальной машины всегда ограничивалось количеством ядер на одном процессоре. Иначе NUMA планировщик просто игнорировал эту ВМ и vCPU равномерно распределялись поверх всех доступных ядер. Однако в ESX 4.1 была представлена новая технология, называемая Wide VM. Она позволяет нам назначать в ВМ большее количество vCPU, чем ядер на процессоре. Согласно Vmware документу планировщик разбивает нашу «широкую виртуальную машину» на несколько NUMA клиентов и затем уже каждый NUMA клиент обрабатывается по стандартной схеме, в пределах одного NUMA узла. Однако, память все таки будет разрозненной между выбранными NUMA узлами этой Wide VM, на которых работают vCPU виртуальной машины. Это происходит потому, что предсказать к какому участку памяти обратится тот или иной vCPU NUMA клиент практически невозможно. Несмотря на это, Wide VM все равно предоставляют существенно улучшенный механизм доступа к памяти по сравнению со стандартным «размазыванием» виртуальной машины поверх всех NUMA узлов.
Еще одна замечательная особенность NUMA планировщика это то, что он не только решает где расположить виртуальную машину при ее запуске, но и постоянно следит за ее соотношением локальной и удаленной памяти. И если это значение уходит ниже порога (по неподтвержденной инфо – 80%), то планировщик начинает мигрировать ВМ в другой NUMA узел. Более того ESX будет контролировать скорость миграции чтобы избежать излишней загруженности общей шины, через которую общаются все NUMA узлы.
Стоит также отметить, что при установке в памяти сервер вы должны уставновить память в правильные слоты, т.к. за распределение памяти между NUMA узлами отвечает не NUMA планировщик, а именно физическая архитектура сервера.
Ну и напоследок, немного полезной информации, которую вы можете подчерпнуть из esxtop.

Краткое описание значений:
NHN Номер NUMA узла
NMIG Количество миграций виртуальной машины между NUMA узлами
NMREM Количество удаленной памяти, используемой ВМ
NLMEM Количество локальной памяти, используемой ВМ
N&L Процентное соотношение между локальной и удаленной памятью
GST_ND(X) Количество выделенной памяти для ВМ на узле X
OVD_ND(X) Количество памяти потраченной на накладные расходы на узле X
Хотелось бы отметить, что как обычно вся эта статья всего лишь компиляция того, что мне показалось интересным из прочитанного за последнее время в блогах таких товарищей как Frank Denneman и Duncan Epping, а также официальных документов Vmware.
Вы уже наверняка знаете, что NUMA это неравномерный доступ к памяти. В настоящий момент эта технология представлена в процессорах Intel Nehalem и AMD Opteron. Честно говоря, я, как практикующий по большей части сетевик, всегда был уверен, что все процессоры равномерно борются за доступ к памяти между собой, однако в случае с NUMA процессорами мое представление сильно устарело.

Приблизительно так это выглядело до появления нового поколения процессеров.
В новой же архитектуре каждый процессорный сокет имеет прямой доступ только к определенным слотам памяти и образует NUMA узел. То есть при 4 процессорах и 64 Гбайт памяти у вас будет 4 NUMA узла, каждый с 16 Гбайт памяти.

Насколько я понял, новый подход к распределению доступа к памяти был изобретен в силу того, что современные сервера настолько напичканы процессорами и памятью, что становится технологически и экономически невыгодно обеспечивать доступ к памяти через единственную общую шину. Что в свою очередь может вести к соперничеству за полосу пропускания между процессорами, ну и к более низкой масштабируемости производительности самих серверов. Новый подход привносит 2 новых понятия – Локальная память и Удаленная память. В то время как к локальной памяти процессор обращается напрямую, то к Удаленной памяти ему приходится обращаться старым дедовским методом, через общую шину, что означает более высокую задержку. Это также означает, что для эффективного использования новой архитектуры наша ОС понимать, что она работает на NUMA узле и правильно управлять своими проложениями/процессами, иначе ОС просто рискует оказаться в ситуации, когда приложение исполняется на процессоре одного узла, в то время как его (приложения) адресное пространство памяти располагается на другом узле. Быстрый поиск показал, что NUMA архитектура поддерживается Майкрософт начиная с Windows 2003 и Vmware – как минимум с ESX Server 2.
Не уверен, что в GUI как то можно увидеть данные NUMA узла, но определенно это можно посмотреть в esxtop.

Итак, тут мы можем наблюдать, что в нашем сервере 2 NUMA узла, и что в каждом их них 48 Гбайт памяти. Вот этот документ говорит, что первое значение означает количество локальной памяти в NUMA узле, а второе, в скобочках – количество свободной памяти. Однако, пару раз на своих продакшн серверах я наблюдал второе значение выше, чем первое, и никакого объяснения этому найти не смог.
Итак, как только ESX сервер обнаруживает, что он работает на сервере с NUMA архитектурой, он незамедлительно включает NUMA планировщик, который в свою очередь заботится о виртуальных машинах и о том, чтобы все vCPU каждой машины находились в пределах одного NUMA узла. В предыдущих версиях ESX (до 4.1) для эффективной работы на NUMA системах максимальное количество vCPU виртуальной машины всегда ограничивалось количеством ядер на одном процессоре. Иначе NUMA планировщик просто игнорировал эту ВМ и vCPU равномерно распределялись поверх всех доступных ядер. Однако в ESX 4.1 была представлена новая технология, называемая Wide VM. Она позволяет нам назначать в ВМ большее количество vCPU, чем ядер на процессоре. Согласно Vmware документу планировщик разбивает нашу «широкую виртуальную машину» на несколько NUMA клиентов и затем уже каждый NUMA клиент обрабатывается по стандартной схеме, в пределах одного NUMA узла. Однако, память все таки будет разрозненной между выбранными NUMA узлами этой Wide VM, на которых работают vCPU виртуальной машины. Это происходит потому, что предсказать к какому участку памяти обратится тот или иной vCPU NUMA клиент практически невозможно. Несмотря на это, Wide VM все равно предоставляют существенно улучшенный механизм доступа к памяти по сравнению со стандартным «размазыванием» виртуальной машины поверх всех NUMA узлов.
Еще одна замечательная особенность NUMA планировщика это то, что он не только решает где расположить виртуальную машину при ее запуске, но и постоянно следит за ее соотношением локальной и удаленной памяти. И если это значение уходит ниже порога (по неподтвержденной инфо – 80%), то планировщик начинает мигрировать ВМ в другой NUMA узел. Более того ESX будет контролировать скорость миграции чтобы избежать излишней загруженности общей шины, через которую общаются все NUMA узлы.
Стоит также отметить, что при установке в памяти сервер вы должны уставновить память в правильные слоты, т.к. за распределение памяти между NUMA узлами отвечает не NUMA планировщик, а именно физическая архитектура сервера.
Ну и напоследок, немного полезной информации, которую вы можете подчерпнуть из esxtop.

Краткое описание значений:
NHN Номер NUMA узла
NMIG Количество миграций виртуальной машины между NUMA узлами
NMREM Количество удаленной памяти, используемой ВМ
NLMEM Количество локальной памяти, используемой ВМ
N&L Процентное соотношение между локальной и удаленной памятью
GST_ND(X) Количество выделенной памяти для ВМ на узле X
OVD_ND(X) Количество памяти потраченной на накладные расходы на узле X
Хотелось бы отметить, что как обычно вся эта статья всего лишь компиляция того, что мне показалось интересным из прочитанного за последнее время в блогах таких товарищей как Frank Denneman и Duncan Epping, а также официальных документов Vmware.
