 В апреле-мае 2011 года компания Яндекс проводила очередной тур конкурса Яндекс интернет математика. Тема тура: «Определение визуальной схожести изображений».
В апреле-мае 2011 года компания Яндекс проводила очередной тур конкурса Яндекс интернет математика. Тема тура: «Определение визуальной схожести изображений».Я публиковал новость про объявление победителей и обещал в скором времени описать решение поставленной задачи нашей командой — LookLikeIt, которая заняла 12-е место в финальном рейтинге.
И вот, не совсем скорое время наступило!
Введение
«Яндекс интернет математика» — это серия конкурсов, организованная компанией Яндекс, которая в 2011 году проводился в пятый раз. Основное содержание конкурса – соревнования по решению реальных задач на основе реальных данных. В качестве задания для конкурса в 2011 году был выбран анализ визуальной схожести изображений для определения лишних кадров в сериях панорам. В данной статье будет описана постановка задачи, методика и подходы к её решению, которые были применены нами в рамках конкурса, а так же анализ полученных результатов.
Данные для конкурса представляли собой изображения, полученные из панорамных снимков сервиса Яндекс.Карты. Конкурс был разбит на два этапа – тренировочный этап, который содержал 6000 серий по 5 изображений в каждой (размерность каждого изображения составляло 300х300 пикселей), и финальный этап, который содержал другой набор из 6000 серий по 5 изображений в каждой. Основа каждой серии – последовательные фрагменты панорамы с частичным перекрытием (возможно, в неправильном порядке). В некоторых сериях есть один или два лишних снимка из других панорамных серий. Задачей участников было с помощью автоматических методов определить лишние кадры в серии. Среди 6000 серий тренировочного набора 1000 представляли собой обучающую выборку, для которой было указано какие картинки лишние.
Примеры серий:


Методика проведения конкурса была следующей. Команды составляли ответ на вопрос: какие фотографии лишние в каждой серии из 5-ти фотографий для 5000 серий на тренировочном этапе (с 1001 по 6000, так как первая 1000 серий являлась обучающей и ответы для неё были известны). Этот ответ формировался в виде текстового файла, в котором указывались лишние картинки для каждой серии. На основе этого файла сервером Яндекса рассчитывалась публичная оценка результатов анализа. На финальном этапе был предложен набор из 6000 заранее не известных серий. Предварительный этап длился 2 месяца, финальный этап длился ровно сутки (с 16 по 17е мая 2011 года).
Основной метрикой оценки результатов является доля правильно классифицированных фотографий (рассматривается два класса: фотографии составляющие панораму и лишние). Оценка проводилась по формуле:
(Tp+Tn)/(P+N), где P – число изображений, относящихся к панораме, N – число лишних изображений, Tp – число изображений, которые система правильно отнесла к панораме, Tn – число изображений, которые система правильно отнесла к классу лишних. Таким образом, если система абсолютно правильно разделила все фотографии по классам панорамы и лишних, то оценка будет равна 1.
Проанализировав метрику становится понятно, что ошибка в серии может по-разному влиять на общую оценку результата. Рассмотрим серию, представленную на рисунке 1. Если система скажет, что 2,3,4,5 картинки находятся в одной панораме, а 1я лишняя, то оценка будет (3+1)/(3+2)=4/5. Если же система даст результат, что 2, 3 и 4я картинки в одной панораме, а 1 и 5 – лишние, то оценка будет составлять (1+0)/(3+2)=1/5. Как видно из этого, некоторые типы ошибок могут значительно больше ухудшать общую оценку, чем другие, что необходимо учитывать при проектировке системы.
Основными задачами при разработке системы для решения поставленной проблемы было определения метрик, на основании которых можно определить являются ли два изображения частями одной панорамы и создание подсистемы принятия решений, которая на основании этих метрик будет строить результирующий ответ для каждой серии.
Метрики
Для того чтобы определить принадлежат ли два изображения одной панораме нами были разработаны несколько типов метрик, которые используются в разных ситуациях. Изображения в одной серии сравниваются попарно. Рассмотрим эти метрики детальнее.
1. Метрика наложения
В постановке задачи было указано условие того, что изображения из одной панорамы должны иметь частичное перекрытие. Это не всегда так, но в большинстве случаев, действительно, перекрытие имело место.
Для определения изображений с частичными перекрытиями нами был разработан метод, суть которого заключалась в следующем. Два изображения накладываются друг на друга с шириной окна наложения в 50 пикселей.
В полученном окне для каждого пикселя высчитывается разница по модулю компонент RGB, после чего рассчитывается относительное количество пикселей, у которых разница значений R,G и B получилась менее 20 для каждой компоненты – такие пиксели будем называть «черными». Это количество показывает насколько близкими по цветам были пиксели, которые были наложены друг на друга и определяет таким образом степень близости наложенного участка первого и второго изображения.
После этого окно смещается на 6 пикселей и процедура повторяется, пока ширина окна наложения не увеличится до 150 пикселей (половина изображения). Эта же процедура повторяется для тех же изображений с наложением противоположными сторонами (сначала правая грань первого изображения на левую грань второго, а потом – наоборот, правая грань второго изображения на левую грань первого).
Для примера рассмотрим изображения:
Покажем итеративный процесс наложения этих изображений и расчет разницы пикселей в окне наложения:

График изменения относительного количества темных пикселей в зависимости от итерации наложения:

Как видно, на 13 итерации мы получили значительный пик, а это означает, что мы максимально точно попали на перекрытие, что так же подтверждается иллюстрацией.
После этой процедуры для каждой пары изображений в серии мы имеем по два вектора со значениями относительного количества «черных» пикселей и ищем максимальное из них. Это и является метрикой близости двух изображений по их частичному перекрытию. Другими словами, мы определяем, насколько сильно совпадают два изображения при их наложении друг на друга.
Очевидными проблемами данной метрики являются изначально темные изображения (ночные панорамы и т.д.), так как при наложении темной области на темную область разница значений R,G,B будет маленькой, не смотря на то, что реального перекрытия у изображений может не быть. Для решения этой проблемы перед запуском процедуры проверяется общее количество темных пикселей у каждого изображения, и если оно достаточно велико (более 70% изображения), то такая серия не анализируется с помощью данной метрики. Пример такой серии:

Второй проблемой при применении такой метрики являются изображения, перекрытие которых не являются точными, а имеют определенные искажения:
-перспективные:

-появление объекта (машины) на месте перекрытия:

-наличие высокодетализированных объектов на месте перекрытия (деревьев, сложных текстур на зданиях, бликов), которые не могут идеально «наложиться» друг на друга и дать высокое относительное количество «черных» пикселей при применении описанной выше процедуры:

Кроме того, не смотря на то, что частичное перекрытие упоминалось в постановке задачи как обязательное условие для фотографий из одной панорамы, попадалось довольно большое количество серий, где перекрытия в фотографиях не было:

В таком случае применялись уточняющие метрики, которые будут описаны далее.
Третей проблемой, связанной с метрикой наложения было определение порога метрики (максимального количества «черных» пикселей при проходе наложения с двух сторон), когда можно сказать, что два изображения имеют частичное перекрытие или нет.
Первоначальным решением этой задачи был выбор статического порога, значение которого выбиралось эмпирическим подбором в некотором диапазоне значений с определенным шагом по обучающей выборке. Таким образом, мы получили некоторое значение статического порога, при котором результат публичной оценки на обучающей выборке был максимальным. Однако очевидно, что такой подход не является достаточно эффективным, поскольку один и тот же порог плохо подходит под разные серии фотографий (например, в серии А у двух фотографий наложение ярко выражено и метрика дает результат в 95%, а в серии Б на перекрытии двух фотографий имеется высоко детализированный объект и метрика дала результат в 70%, что достаточно мало в сравнении с 95% из серии А, но может быть намного больше в сравнении с другими фотографиями в рамках серии Б). Кроме того, обучающая выборка, на которой мы подбирали порог была довольно маленькой и не достаточно репрезентативной.
В связи с этими проблемами было принято решение, что порог определения близости по метрике наложения необходимо рассчитывать для каждой серии отдельно. Сначала рассчитывается значение метрики для всех фотографий в серии попарно, после чего определяется средне-квадратическое этих оценок. Средне-квадратическое было выбрано из соображений того, что слишком высокие или слишком низкие значения являются выразительными и показывают яркую принадлежность двух фотографий к одной панораме или наоборот, их слишком большую разницу, поэтому эти пики должны сильнее влиять на среднюю оценку по серии с помощью вознесения в квадрат при расчете средней оценки. После этого каждая оценка сравнивается с полученной средней оценкой и если она больше неё (с некоторым запасом), то фотографии считаются принадлежащими к одной панораме. Если же такого запаса нету, то это означает, что все картинки в серии имеют примерно одинаковые значения, что может означать либо то, что в этой серии лишних картинок нет, либо то, что метрика не сработала и необходимо уточнять результат дальше.
Использование подхода динамического определения порога для каждой серии позволило улучшить результат публичной оценки более чем на две десятых.
2. Метрика корреляции спектров
Данная метрика использовалась для серий, в которых перекрытие на изображениях из одной панорамы было не явным и плохо определялось с помощью метрики наложения. В достаточно большом количестве серий изображения из панорамы и лишние изображения были сфотографированы при совсем разных условиях (времена года, время суток, структура вида (здания и лес, например) и т.д.), что дает значительную разницу между ними в распределении цветов и яркостей на изображениях.

Потому для оценки схожести/разности по распределению цветов каждую картинку из серии мы раскладывали на спектр (гистограмму) из 10-ти значений: цвета радуги (красный, оранжевый, желтый, зеленый, голубой, синий, фиолетовый) и нейтральные цвета: белый, серый и черный. Для цветов радуги было использовано цветовое пространство HSV по компоненте hue (тон), которая лежит в диапазоне значений 0-360 и отражает тон пикселя. Однако при таком подходе, не рассматривая компоненту яркости в каждом под диапазоне цветов, мы будем включать белые, серые и черные цвета, как показано на рисунке:

Поэтому для исключения белого, серого и черного цвета сначала проводится проверка компонент каждого пикселя в пространстве RGB на принадлежность к диапазонам этих цветов (для белого все компоненты должны быть в диапазоне: 225-255, для серого: 125-225, для черного: 0-30).
Каждая компонента спектра означает относительное количество цветов того или иного под диапазона в изображении, другими словами показывает распределение цветов по изображению. Выглядит он примерно так:

Поскольку каждый спектр является вектором из 10-ти значений, то для определения существования зависимости между спектрами пары изображений в серии был использован коэффициент корреляции Пирсона:
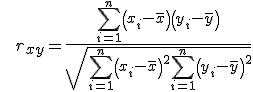
Этот подход очень хорошо себя зарекомендовал, и значение корреляции стремительно росло для изображений, распределение цветов у которых было схожим.
Важной проблемой данной метрики являются, как и у метрики наложения – определение порога, который должно пересечь значение коэффициента корреляции для двух изображений, чтобы сказать, что они принадлежат одной панораме. Для решения этой проблемы был так же использован метод с динамическим определением порога для каждой серии по средне-квадратическому значению корреляции в серии.
Второй проблемой является то, что встречаются серии, в которых фотография из панорамы и лишняя имеют очень близкое распределение цветов (например, цвет неба и зелени), что дает ложные срабатывания.

Третей проблемой являются изображения из одной панорамы, на одном из которых появляется крупный объект (например проезжающая машина), который иногда достигал половины изображения. В таком случае для такого изображения спектральное распределение сильно меняется (появлялось много синего цвета, например, которого не было на других изображениях в панораме) и корреляция не может показать зависимости его спектра со спектрами других изображений панорамы.

3. Метрика на основе дескрипторов SURF
Метод SURF (Speeded Up Robust Features) – один из самых эффективных и быстрых современных алгоритмов по распознаванию изображений и определению их схожести.
Основной смысл метода заключается в выделении на изображении неких ключевых точек и небольших участков вокруг них. Ключевой точкой считается такая точка, которая имеет некие признаки, существенно отличающие её от основной массы точек. Например, это могут быть края линий, небольшие круги, резкие перепады освещенности, углы и т.д. Малые участки вокруг точек выбираются потому, что маленький участок изображения мало подвержен перспективным и масштабным искажениям, однако слишком малые участки так же не подходят, так как несут в себе слишком мало информации.
Метод SURF ищет особые точки с помощью матрицы Гессе, детерминант которой достигает экстремума в точках максимального изменения градиента яркости и хорошо детектирует пятна, углы и края линий. Примеры ключевых точек:

Этот метод инвариантен к масштабу, поворотам в плоскости изображения, зашумленности, перекрыванию другими предметами, изменению яркости и контраста. То есть, идеально подходит для тех серий, которые были проблемными для первых двух метрик.
Значением метрики при сравнении двух изображений было количество общих ключевых точек. Нами было замечено, что при количестве точек более десяти — два изображения в абсолютном большинстве случаев имеют общие объекты, потому для этой метрики использовался статический порог, который практически не давал ложных срабатываний.
Данная метрика позволила определять те фотографии, которые был изменен масштаб, в панорамах типа 360 градусов, где углы зрения слишком сильно меняются и возникают большие перспективные и геометрические искажения, но при этом объекты остаются и остаются ключевые точки. Например, в таких сериях:


Основным минусом этого метода является высокая вычислительная нагрузка, а, следовательно, длительное время работы. Однако нами он был использован в качестве уточняющего и рассчитывался в самых проблемных и спорных ситуациях, поэтому получилось снизить количество расчетов к минимуму.
В качестве реализации метода была использована библиотека OpenSURF 2.0.
Более детально о методе SURF можете почитать в замечательной статье Обнаружение устойчивых признаков изображения: метод SURF, откуда мы нагло позаимствовали иллюстрацию и описание метода:)
Логика принятия решений
Разработав метрики для по парного сравнения изображений внутри определенной серии и проанализировав их достоинства и недостатки, а так же проведя серию тестов на обучающей выборке мы создали подсистему принятия решений, которая на основе этих метрик должна формировать ответ: какие фотографии лишние в данной серии.
Сначала рассмотрим возможные варианты серий:
1) В серии 3 фотографии в панораме и 2 фотографии лишние;
а) лишние фотографии в одной панораме;
б) лишние фотографии из разных панорам;
2) В серии 4 фотографии в панораме и 1 фотография лишняя;
3) Лишних нет;
Рассматривая серию фотографий система создает два множества с картинками: мн.1 и мн.2. Изначально алгоритм распределяет по этим множествам картинки, которые между собой превышают динамический порог по метрике наложения. После этого возможны следующие логические варианты распределения изображений по этим множествам. Опишем действия для этих вариантов:
1) (0) (0) – такой вариант не возможен, так как при использовании динамического порога всегда найдутся изображения, у которых метрика наложения больше среднего квадратического внутри этой серии (если в метрике наложения не будет преодолен «запас», то серия разобьется по множествам с помощью метрики корреляции спектров, в которой «запас» не предусмотрен)
2) (2) (2) – этот вариант означает, что алгоритм определил, что две картинки находятся в одной панораме, две – в другой, а про пятую ничего сказать не смог. В таком случае возможны следующие варианты:
А) пятая войдет в мн.1, а мн.2 станет лишним;
Б) пятая войдет в мн.2, а мн.1 станет лишним;
В) пятая войдет в оба множества, тогда лишних не будет;
Д) ни одна метрика не может определить к какому множеству относится пятая картинка, потому анализируется наибольшее значение коэффициента корреляции этой картинки с картинками первого множества, второго множества, а так же коэффициенты корреляции картинок из множества 1 и множества 2. Объединение происходит по наибольшему значению коэффициента корреляции спектров:
— мн.1 и мн.2 объединятся и 5я картинка будет лишней;
— мн.1 и 5я картинка объединятся и мн.2 будет лишним;
— мн.2 и 5я картинка объединятся и мн.1 будет лишним.
Все уточнения происходят по метрике коэффициента корреляции спектра и метода SURF
3) (3) (2) – эмпирически было замечено, что на тренировочной выборке в абсолютном большинстве случаев этот вариант сразу является правильным и уточнение не требуется (мн.2 – лишнее). В случае, когда это не так, ошибка будет не слишком грубой и не сильно повлияет на общую оценку результата;
4) (2) (3) – аналогично предыдущему пункту (мн.1 – лишнее);
5) (3) (0) – в данном случае возможны следующие варианты:
А) Обе картинки лишние (вариант (3) (2));
Б) одна из двух картинок входит в панораму, а пятая – лишняя (вариант (4) (1));
В) обе картинки входят в панораму, лишних нет (вариант (5) (0));
Все уточнения происходят по метрике коэффициента корреляции спектра и метода SURF
6) (4) (0) – в этом случае возможны варианты:
А) 5я картинка не входит в панораму, то есть 5я – лишняя;
Б) 5я картинка входят в панораму, лишних нет;
Все уточнения происходят по метрике коэффициента корреляции спектра и метода SURF
7) (5) (0) – без вариантов. Ответ – лишних нет.
Оценка результатов
Решение поставленной задачи происходило итеративно, применяя все более сложные подходы, постепенно увеличивая при этом значения публичной оценки.
Наибольший результат был получен по описанному выше решению и составил 0.945 на предварительной публичной оценке. Финальный результат возрос до 0.967. Результат победителя на финальной выборке составил 0.994.
Время анализа одной серии в среднем составило около 20 секунд.
Основная причина такого резкого поднятия результата на финальной выборке, на наш взгляд, состоит в том, что финальный набор серий был более тщательно проверен и в нем практически отсутствовали ошибки составителей, которые достаточно часто встречались в сериях предварительного этапа.
Так как данная метрика не очень наглядна и по её значению не очень понятно реальные результаты распознавания приведем статистику, которую мы получили на тренировочной выборке (такую статистику можно получить только на ней, так как для неё были известны ответы):
Абсолютно правильных ответов: 85,3%; неправильных ответов с разного рода ошибками: 14,7%.
Этот результат является достаточно высоким. Анализируя серии, которые попали в ошибки, мы часто сталкивались с тем, что сами не могли определить правильный ответ (либо правильный, на наш взгляд, ответ не совпадал с таковым от Яндекса).
Например, в серии:

лишними являются 1 и 4 (хотя между изображениями 2, 3 и 5 общего очень мало).
А в этой серии:

лишней считается только первая картинка. На наш взгляд, четвертая фотография может как входит в одну панораму с 2,3 и 5, так и не входить туда и определить это нереально.
Проанализировав результаты, основными недостатками описанного решения мы считаем недостаточное количество метрик и жесткую логическую структуру принятия решений. По сути, тренировочная выборка была использована только для получения быстрой оценки того или иного метода и сбора статистики, никакого машинного обучения в системе предусмотрено не было. Однако, несколько лидирующих команд, которые на предварительном этапе занимали места в первой 5-ке, на финальной выборке значительно снизили результат (с 0.975 до 0.941), в связи с тем, что их система была слишком сильно переобучена на предварительном наборе данных.
Надеюсь, вам было интересно и вы добрались до конца этой статьи:). Описание других решений (в том числе и решение победителей) можно прочитать тут: Клуб Яндекса.
