Фундаментальный поворот к параллелизму в программировании
Автор: Герб Саттер
Перевод: Александр Качанов
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
(By Herb Sutter)
Ссылка на оригинал статьи: www.gotw.ca/publications/concurrency-ddj.htm
Примечание переводчика: В данной статье дается обзор современных тенденций развития процессоров, а также, что именно эти тенденции значат для нас — программистов. Автор считает, что тенденции эти имеют фундаментальное значение, и что каждому современному программисту придется кое в чем переучиваться, чтобы не отстать от жизни.
Данная статья достаточно старая. Ей уже 7 лет, если считать с момента ее первой публикации в начале 2005 года. Помните об этом, когда будете читать перевод, так как многие вещи, которые для вас уже стали привычными, для автора статьи в 2005 году были в новинку и только-только появлялись.
В ваши двери стучится крупнейшая революция в области разработки программного обеспечения со времен революции ООП, и зовут ее Параллелизм.
Данная статья впервые была опубликована в журнале «Dr. Dobb's Journal» в марте 2005 года. Более короткая версия этой статьи была опубликована в журнале «C/C++ Users Journal» в феврале 2005 года под названием «Революция параллелизма».
Обновление: график тенденций роста процессоров был обновлен в августе 2009 года. К нему были добавлены новые данные, которые показывают, что все предсказания данной статьи сбываются. Остальной текст данной статьи остался без изменений в том виде, как он был опубликован в декабре 2004 года.
Бесплатного супа скоро больше не будет. Что вы будете делать по этому поводу? Что вы сейчас делаете по этому поводу?
У ведущих производителей процессоров и архитектур, начиная от Intel и AMD и кончая Sparc и PowerPC, большей частью исчерпаны традиционные возможности увеличения производительности. Вместо того, чтобы и дальше увеличивать частоту процессоров и их линейную пропускную способность, они массово обращаются к гиперпоточным и многоядерным архитектурам. Обе эти архитектуры уже присутствуют в сегодняшних процессорах. В частности современные процессоры PowerPC и Sparc IV являются многоядерными, а в 2005 году к течению присоединятся Intel и AMD. Кстати, крупной темой форума In-Stat/MDR Fall Processor Forum, прошедшего осенью 2004 года была как раз тема многоядерных устройств, так как именно там множество компаний представило свои как новые так и обновленные многоядерные процессоры. Не будет преувеличением сказать, что 2004 год стал годом многоядерности.
Значит мы подходим к фундаментальной поворотной точке в разработке ПО, по крайней мере на несколько лет вперед и для приложений, предназначенных для настольных компьютеров общего назначения и и для нижнего сегмента серверов (которые, кстати, в долларовом выражении составляют громадную долю всех программ, продаваемых ныне на рынке). В данной статье я опишу, как меняется аппаратное обеспечение, почему эти изменения вдруг стали для нас важны, как именно революция параллелизации коснется вас, и того, как вы скорей всего будете писать программы в будущем.
Пожалуй, бесплатный суп закончился уже как год или два назад. Мы только сейчас стали это замечать.
Вы наверное слышали такую интересную поговорку: «Сколько бы Энди не выдал, Билл заберет все» («Andy giveth and Bill taketh away»)? (прим.переводчика — Имеется в виду Энди Гроув — руководитель компании Intel, и Билл Гейтс — руководитель компании Microsoft). Сколько бы процессоры не увеличивали скорость своей работы, программы всегда придумают, на что потратить эту скорость. Сделайте процессор в десять раз быстрее, и программа найдет в десять раз больше работы для него (либо, в некоторых случаях, позволит себе выполнять ту же самую работу в десять раз менее эффективно). Большинство приложений на протяжение нескольких десятилетий работали все быстрее и быстрее, не делая для этого абсолютно ничего, даже без выпуска новых версий или коренных изменений в коде. Просто изготовители процессоров (в первую очередь) и производители памяти и жестких дисков (во вторую очередь) всякий раз создавали все новые и новые, все более быстрые компьютерные системы. Тактовая частота работы процессора не единственный критерий оценки его производительности, и даже не самый правильный, но тем не менее он говорит о многом: мы видели, как на смену 500 МГц-овым процессорам пришли процессоры с тактовой частотой 1ГГц, а за ними – 2ГГц-овые процессоры и так далее. Так что сейчас мы переживаем этап, когда вполне рядовым является процессор с тактовой частотой 3 ГГц.
Теперь зададимся вопросом: Когда же закончится эта гонка? Вроде бы Закон Мура (Moore’s Law) предсказывает экспоненциальный рост. Ясно, что такой рост не может продолжаться вечно, он неизбежно упрется в физические пределы: ведь с годами скорость света быстрее не становится. Значит рост рано или поздно замедлится и даже остановится. (Маленькое уточнение: Да, Закон Мура говорит главным образом о плотности транзисторов, но можно сказать, что экспоненциальный рост наблюдался и в такой области, как тактовая частота. А в других областях рост был даже еще большим, например, рост емкостей накопителей, но это тема отдельной статьи.)
Если вы – разработчик программного обеспечения, скорей всего вы уже давно расслабленно едете на волне увеличения производительности настольных компьютеров. Ваша программа медленно работает при выполнении какой-то операции? «Чего волноваться?», скажете вы, — «завтра выйдут еще более быстрые процессоры, а вообще программы работают медленно не только из-за медленного процессора и медленной памяти (например, еще из-за медленных устройств ввода-вывода, из-за обращений к базам данных)». Верный ход мыслей?
Вполне верный. Для вчерашнего дня. Но абсолютно неверный для обозримого будущего.
Хорошая новость – процессоры будут становиться все мощнее и мощнее. Плохая новость — по крайне мере в ближайшем будущем рост мощности процессоров будет идти в таком направлении, которое никак не приведет к автоматическом ускорению работы большинства ныне существующих программ.
На протяжение последних 30 лет разработчики процессоров смогли увеличить производительность в трех главных областях. Первые две из них связаны с исполнением кода программ:
Увеличение тактовой частоты означает увеличение скорости. Если увеличить скорость работы процессора, это более менее приведёт к тому, что он будет выполнять тот же самый код быстрее.
Оптимизация исполнения кода программы означает выполнение большего объема работы за один такт. Сегодняшние процессоры оснащены очень мощными инструкциями, а еще они выполняют разные оптимизации, от тривиальных до экзотических, включая конвейерное исполнение кода, предугадывание ветвлений (branch predictions), исполнение нескольких инструкций за один и тот же такт и даже выполнение команд программы в ином порядке (instructions reordering). Все эти технологии были придуманы для того, чтобы код исполнялся как можно лучше и/или как можно быстрее, чтобы выжать как можно больше из каждого такта, сводя задержки к минимуму и выполняя больше операций за каждый такт.
Небольшое отступление по поводу выполнения инструкций в ином порядке (instruction reordering) и моделях памяти (memory models): хочу отметить, что под словом «оптимизациями» я имел в виду нечто на самом деле большее. Эти «оптимизации» могут менять смысл программы и приводить к результатам, которые будут противоречить ожиданиям программиста. Это имеет огромное значение. Разработчики процессоров не безумцы, и в жизни они мухи не обидят, им и в голову не придет портить ваш код… в обычной ситуации. Но в течение последних лет они решились на агрессивные оптимизации с единственной целью: выжать еще больше из каждого такта процессора. При этом они прекрасно понимают, что эти агрессивные оптимизации ставят под угрозу семантику вашего кода. Что ж, это они из вредности так делают? Вовсе нет. Их стремление – это реакция на давление рынка, который требует все более и более быстрых процессоров. Это давление настолько велико, что такое увеличение скорости работы вашей программы ставит под угрозу её корректность и даже её способность вообще работать.
Приведу два наиболее ярких примера: изменение порядка операций записи данных (write reordering) и порядка их чтения (read reordering). Изменение порядка операций записи данных приводит к таким удивительным последствиям и сбивает с толку стольких программистов, что эту функцию приходится обычно отключать, так как при ее включении становится слишком трудно правильно судить о том, как будет вести себя написанная программа. Перестановка операций чтения данных тоже может привести к удивительным результатам, но эту функцию обычно оставляют включенной, так как здесь особенных трудностей у программистов не возникает, а требования к производительности операционных систем и программных продуктов заставляют программистов идти хоть на какой-то компромис и скрепя сердце выбирать меньше из «зол» оптимизации.
Наконец, увеличение размера встроенного кэша означает стремление как можно реже обращаться к оперативной памяти. ОЗУ компьютера работает намного медленнее, чем процессор, поэтому лучше всего размещать данные как можно ближе к процессору, чтобы не бегать за ними в ОЗУ. Самое близкое – это хранить их на том же кусочке кремния, где находится сам процессор. Рост размеров кэш-памяти за последние годы был просто ошеломительным. Сегодня уже никого нельзя удивить процессорами со встроенной кэш-памятью 2-го уровня (L2) в 2Мб и более. (Из трех исторических подходов по увеличению производительности процессоров, рост кэш-памяти будет единственным перспективным подходом на ближайшее будущее. Еще немного о важности кэш-памяти я поговорю несколько ниже.)
Хорошо. К чему я это все?
Главное значение этого списка в том, что все перечисленные направления никак не связаны с параллелизмом. Прорывы во всем перечисленным направлениям приведут как к ускорению последовательных (непараллельных, одно-процессных) приложений, так и тех приложений, которые используют параллелизм. Сей вывод важен потому, что большинство сегодняшних приложений является одно-поточными, о причинах этого я скажу ниже.
Разумеется и компиляторам прошлось поспевать за процессорами; вам время от времени приходилось перекомпилировать ваше приложение, выбирая определенную модель процессора как минимально приемлимую, чтобы извлечь пользу из новых инструкций (например, MMX, SSE), новых функций и новых характеристик. Но в целом даже старые программы всегда работали значительно быстрее на новых процессорах, чем на старых, даже без всякой перекомпилляции и использования новейших инструкций новейших процессоров.
Как прекрасен был этот мир. К сожалению, этого мира больше не существует.
Привычный для нас рост производительности процессоров два года назад натолкнулся на стену. Большинство из нас уже стали замечать это.
Похожий график можно создать и для других процессоров, но в данной статье я собираюсь воспользоваться данными по процессорам Intel. На рис.1 представлен график, отображающий, когда какой процессор Intel был представлен на рынке, его тактовая частота и количество транзисторов. Как видите, количество тразисторов продолжает расти. А вот с тактовой частотой у нас проблемы.
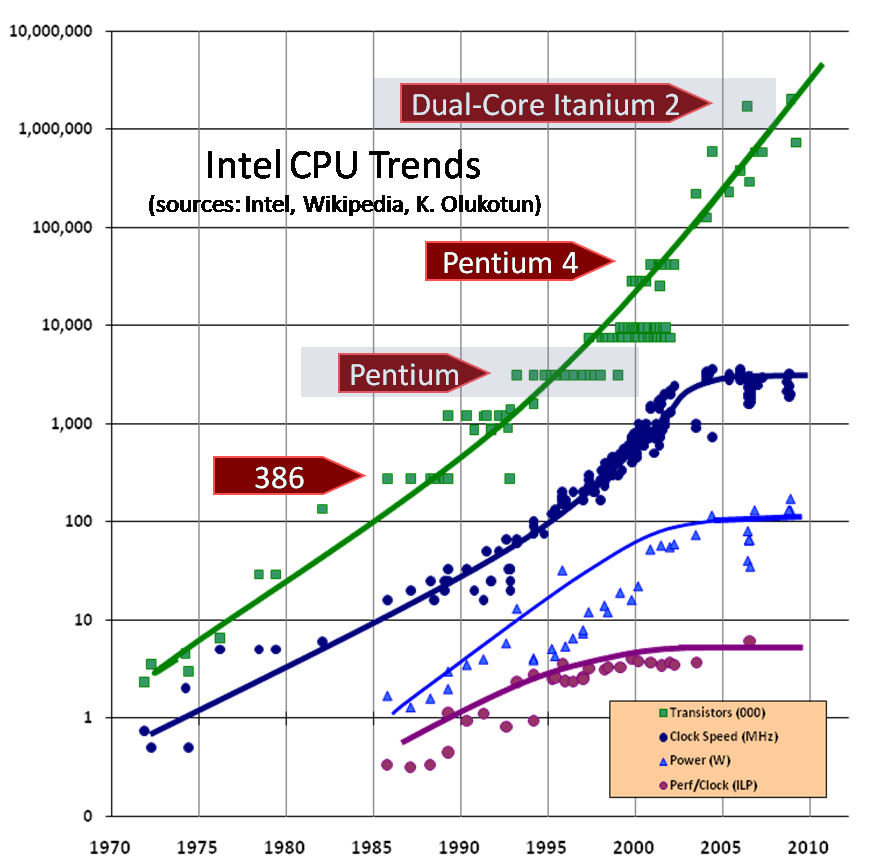
Обратите внимание, что в районе 2003 года график тактовой частоты резко и странно отклоняется от привычной тенденции непрерывного роста. Между точками я провел линии, чтобы была более понятна тенденция; вместо того, чтобы продолжать расти, график неожиданно становится горизонтальным. Рост тактовой частоты дается все большей и большей ценой, и физических препятствий на пути роста не одно, а множество, например нагрев процессоров (слишком много выделяется тепла и его слишком трудно рассеивать), потребление энергии (слишком высоко) и паразитная утечка тока.
Краткое отступление: посмотрите, какова тактовая частота процессора на вашем компьютере? Может быть 10ГГц? Процессоры Intel достигли уровня 2ГГц давным давно (в августе 2001 года), а если бы тенденция роста тактовой частоты, существовавшая до 2003 года, продолжалась, то сейчас — в начале 2005 года — должны были бы появиться первые процессоры Pentium с частотой 10ГГц. Осмотритесь, видите ли вы их? Более того, процессоров с такой тактовой частотой ни у кого даже в планах нет, и мы даже не знаем, когда такие планы появятся.
Ну, а что насчет 4ГГц-вого процессора? Уже сейчас есть процессоры с частотой 3.4ГГц, значит 4ГГц не за горами? Увы, мы не можем дотянуться даже до 4ГГц. В середние 2004 года вы наверное помните, как компания Intel перенесла выпуск 4ГГц-ового процессора на 2005 год, а потом осенью 2004 года официально объявила о полном отказе от этих планов. На момент написания данной статьи Intel планирует продвинуться чуть вперед, выпустив в начале 2005 года процессор с частотой 3.73ГГц (на рис.1 на графике роста частоты это самая верхняя точка), но можно сказать, что гонка за герцами закончена, по крайней мере на сегодняшний момент. В будущем компания Intel и большинство производителей процессоров будут добиваться роста другими способами: все они активно стали обращаться к многоядерным (multicore) решениям.
Возможно когда-то мы все же увидим 4ГГц-овые процессоры в наших настольных компьютерах, но это будет не в 2005 году. Конечно в лабораториях Intel есть опытные образцы, которые работают и на более высоких скоростях, но достигаются эти скорости прямо-таки героическими усилиями, например с помощью громоздкого охлаждающего оборудования. Не ждите, что такое охлаждающее оборудование появится когда-либо в вашем офисе, и уж точно не в самолете, где вам бы хотелось поработать на ноутбуке.
«Бесплатного супа не бывает (БСНБ)» — Р.А.Хайнлайн, «Луна — строгая хозяйка»
Значит ли это, что Закон Мура больше не действителен? Самое интересное, что ответ будет «нет». Разумеется, как и всякая экспоненциальная прогрессия Закон Мура когда-то перестанет работать, но по всей видимости на ближайшие несколько лет Закону ничего не угрожает. Несмотря на то, что конструкторы процессоров больше не могут увеличивать тактовую частоту, число транзисторов в их процессорах продолжает расти взрывным темпом, и в ближайшие годы рост по Закону Мура будет продолжаться.
Главное отличие от прежних тенденций, ради чего и была написана данная статья, заключается в том, что прирост производительности нескольких грядущих поколений процессоров будет достигаться фундаментально другими способами. И большинство нынешних приложений на этих новых более мощных процессорах уже не будут автоматически работать быстрее, если только в их дизайн не будут внесены значительные изменения.
В ближайшем будущем, точнее в ближайшие несколько лет, прирост производительности в новых процессорах будет достигаться тремя главными способами, лишь один из которых остался из прежнего списка. А именно:
Гиперпоточность (Hyperthreading) это технология исполнения двух и более потоков (threads) параллельно в одном и том же процессоре. Гиперпоточные процессоры уже сейчас имеются на рынке, и они действительно позволяют выполнять несколько инструкций параллельно. Однако, несмотря на то, что у гиперпоточного процессора для выполненяи этой задачи имеется в наличии дополнительные аппаратные срества, например, дополнительные регистры, у него по прежнему всего один кэш, один вычислительные блок для целочисленной математики, один блок для операций с плавающей запятой и вообще по одному всего, что есть в наличии в любом простом процессоре. Считается, что гиперпоточность позволяет увеличивать производительность сносно написанных много-поточных программ на 5-15 процентов, а производительность отлично написанных многопоточных программ при идеальных условиях увеличивается аж на 40%. Неплохо, но это далеко не удвоение производительности, а однопоточные программы здесь ничего выиграть не могут.
Многоядерность (Multicore) это технология размещения на одном и том же кристалле двух или нескольких процессоров. Некоторые процессоры, например SPARC и PowerPC, уже выпускаются в многоядерных вариантах. Первые попытки компаний Intel и AMD, которые должны реализоваться в 2005 году, отличаются друг от друга по степени интеграции процессоров, но функционально они очень схожи. Процессор от AMD будет иметь несколько ядер на одном кристалле, что приведет к большему выигрышу в производительности, в то время как первый многоядерный процессор Intel представляет собой всего лишь два сопряженных процессора Xeon на одной большой подложке. Выигрыш от такого решения будет таким же как от наличия двух-процессорной системы (только дешевле, так как на материнской плате не понадобится два сокета для установки двух чипов и дополнительных микросхемы для их согласования). В идеальных условиях скорость исполнения программ почти удвоится, но только у достаточно хорошо написанных многопоточных приложений. Однопоточные приложения не получат никакого прироста.
Наконец, ожидается рост объемов встроенного кэша (on-die cache), по крайней мере в ближайшем будущем. Из всех трех тенденций, только эта приведет к росту прозводительности большинства существующих приложений. Рост размера встроенного кэша для всех приложений важен просто потому, что размер значит скорость. Доступ к ОЗУ обходится слишком дорого, и по большому счету хочется обращаться к ОЗУ как можно реже. В случае промаха кэша (cache miss), на извлечение данных из ОЗУ уйдет в 10-50 раз больше времени, чем на их извлечение из кэша. До сих пор людей это удивляет, поскольку было принято считать, что ОЗУ работает очень быстро. Да, быстро по сравнению с дисками и сетью, но кэш-память работает еще быстрее. Если весь объем данных, с которым предстоит работать приложению, помещается в кэше, мы — в шоколаде, а если нет, то в чем-то другом. Вот поэтому растущие размеры кэш-памяти спасут некоторые сегодняшние программы и вдохнут в них еще немного жизни на несколько лет вперед без каких-либо значительных переделок с их стороны. Как говорили во времена Великой Депрессии: «Кэша мало не бывает». («Cache is king»)
(Краткое отступление: вот вам история, случившаяся с нашим компилятором, в качестве демонстрации утверждения «размер значит скорость». 32-битная и 64-битная версии нашего компилятора создаются из одного и того же исходного кода, просто при компиляции мы указываем, какой процесс надо создать: 32-битный или 64-битный. Ожидалось, что 64-битный компилятор должен работать быстрее на 64-битном процессоре, хотя бы потому, что у 64-битного процессора было намного больше регистров, а также имелись оптимизирующие функции по более быстрому выполнению кода. Все просто прекрасно. А что насчет данных? Переход на 64 разряда не поменял размеры большинства структур данных в памяти, за исключением, конечно, указателей, размер которых стал в два раза больше. Оказалось, что наш компилятор использует указатели намного чаще, чем какое-либо другое приложение. Так как размер указателей теперь стал 8 байт, вместо 4 байт, общий размер данных, с которым надо было работать компилятору, увеличился. Увеличение объема данных ухудшило производительность ровно настолько, насколько она улучшилась из-за более быстрого процессора и наличия дополнительных регистров. На момент написания этой статьи наш 64-битный компилятор работает с такой же скоростью, что и его 32-битный собрат несмотря на то, что собраны оба компилятора из одного исходного кода, а 64-битный процессор — более мощный, чем 32-битный. Размер значит скорость!)
Воистину, кэш будет править балом. Так как ни гиперпоточность, ни многоядерность не увеличат скорость работы большинства сегодняшних программ.
Так что же эти изменения в аппартном обеспечении значат для нас – программистов? Вы уже наверное поняли, каков будет ответ, так что давайте обсудим его и сделаем выводы.
Если двух-ядерный процессор состоит из двух 3ГГц-овых ядер, значит мы получает производительность 6ГГц-ового процессора. Верно?
Нет! Если два потока исполняются на двух физически раздельных процессорах, это вовсе не значит, что общая производительность программы увеличивается в два раза. Точно так же многопоточная программа не будет работать в два раза быстрее на двух-ядерных процессорах. Да, она будет работать быстрее, чем на одноядерном процессоре, но скорость не будет расти линейно.
Почему же нет? Во-первых, мы имеем издержки на согласование содержимого кэшей (cache coherency) двух процессоров (непротиворечивое состояние кэшей и разделяемой памяти), а также издержки на прочие взаимодействия. Сегодня двух- или четырех-процессорные машины не обгоняют по скорости в два или четыре раза своих однопроцессорных собратьев даже при выполнении многопоточных приложений. Проблемы остаются по сути теми же и в тех вариантах, когда вместо нескольких раздельных процессоров мы имеем несколько ядер на одном кристалле.
Во-вторых, несколько ядер используются полноценно лишь только в том случае, когда они исполняют два разных процесса, или два разных потока одного процесса, которые написаны так, что способны работать независимо друг от друга и никогда не ждут друг друга.
(Вступая в противоречие со своим предыдущим утверждением, я могу представить себе реальную ситуацию, когда однопоточное приложение у рядового пользователя будет работать быстрее на двух-ядерном процессоре. Это произойдет вовсе не потому, что второе ядро будет занято чем-то полезным. Напротив, на нем будет выполнятся какой-нибудь троян или вирус, который до этого отъедал вычислительные ресурсы у однопроцессорной машины. Предоставляю вам решать, стоит ли приобретать еще один процессор в дополнение к первому, чтобы крутить на нем вирусы и трояны.)
Если ваше приложение — однопоточное, вы используете только одно ядро процессора. Конечно некоторое ускорение будет, так как операционная система или фоновое приложение будут исполняться на других ядрах, но как правило операционные системы не нагружают процессоры на 100%, так что соседнее ядро большей частью будет простаивать. (Или опять-таки, на нем будет крутиться троян или вирус)
В конце 90-ых мы научились работать с объектами. В программировании произошел переход от структурного программирования к объектно-ориентированному, который стал самой значительной революцией в программировании за последние 20, а может даже и 30 лет. Были и другие революции, включая недавнее появление веб-сервисов, но за всю нашу карьеру мы не видели переворота более фундаментального и значительного по последствиям, чем объектная революция.
До сегодняшнего дня.
Начная с сегодняшнего дня за «суп» придется платить. Конечно кое-какой прирост производительности вы сможете получить и бесплатно, в основном за счет увеличения размера кэша. Но если вы хотите, чтобы ваша программа извлекла пользу из экспоненциального роста мощности новых процессоров, ей придется стать правильно написанным параллелизированным (как правило многопоточными) приложением. Легко сказать, да трудно сделать, потому что не все задачи можно запросто распараллелить, а также потому, что писать параллельные программы очень трудно.
Слышу крики возмущения: «Параллелизм? Какая ж это новость!? Люди уже давно пишут параллельные программы». Верно. Но это лишь ничтожная доля программистов.
Вспомните, что и объектно-ориентированным программированием люди занимались аж с конца 60-ых годов, когда вышел язык Simula. В то время ООП не вызвало никакой революции и не доминировало среди программистов. До наступления 90-ых годов. Почему именно тогда? Революция произошла в основном потому, что возникла нужда в еще более сложных программах, которые решали еще более сложные задачи и использовали все больше и больше ресурсов процессора и памяти. Для экономичной, надежной и предсказуемой разработки крупных программ сильные стороны ООП – абстракции и модульность – оказались очень кстати.
Точно также и с параллелизмом. Мы знаем о нем с незапамятных времен, когда писали сопрограммы и мониторы и прочие подобные хитрые утилиты. И за последние десять лет все больше и больше программистов стало создавать параллельные (многопроцессные или многопоточные) системы. Но о революции, о поворотной точке тогда еще рано было говорить. Поэтому сегодня большинство программ являются однопоточными.
Кстати, насчет шумихи: сколько раз нам объявляли, что мы стоим «на пороге очередной революции в области разработки ПО». Как правило те, кто это говорил, просто рекламировали свой новый продукт. Не верьте им. Новые технологии всегда интересны и даже порой оказываются полезными, но самые крупные революции в программировании производят те технологии, которые уже несколько лет присутствуют на рынке, тихонько набирают силу, пока в один прекрасный момент не происходит взрывной рост. Это неизбежно: революция может основываться только на достаточно зрелой технологии (у которой уже есть поддержка со стороны многих компаний и инструментариев). Обычно проходит лет семь, прежде чем новая технология программирования становится достаточно надежной, чтобы ее можно было бы широко применять, не наступая на грабли и глюки. В результате, настоящие революции в программировании, такие как ООП, производят те технологии, которые оттачивались годами, если не десятилетиями. Даже в Голливуде всякий актер, ставший в одну ночь суперзведой, до этого оказывается уже несколько лет играл в кино.
Параллелизм (Concurrency) — это следующая великая революция в программировании. Существуют разные мнения экспертов о том, сравнится ли она с революцией ООП, но оставим эти споры ученым мужам. Для нас, инженеров, важно то, что параллелизм сравним с ООП по масштабности (что ожидалось), а также по сложности и по трудности освоения этой новой технологии.
Есть две причины, по которым параллелизм и особенно многопоточность уже используются в основной массе программ. Во-первых, для того, что разделить выполнение независимых друг от друга операций; например, в моем сервере репликации баз данных естестенным было поместить каждую сессий репликации в свой поток, так как работали они совершенно независимо друг от друга (если только они не работали над одной о той же записью одной и той же базы данных). Во-вторых, для того, чтобы программы работали быстрее, либо благодаря ее исполнению на нескольких физических процессорах, либо за счет чередования исполнения одной процедуры в то время, когда другая – простаивает в ожидании. В моей программе репликации баз данных этот принцип тоже использовался, так что программа хорошо масштабировалась на многопроцессорных машинах.
Однако за параллелизм приходится платить. Некоторые очевидные трудности на самом деле таковыми не являются. Например, да, блокировка замедляет работу программы, но если ею пользоваться разумно и правильно, вы получаете больше от ускорения работы многопоточной программы, чем теряете на использование блокировки. Для этого вам надо распараллелить операции в вашей программе и свести к минимуму обмен данными между ними или вообще отказаться от него.
Пожалуй, второй главной трудностью на пути к параллелизации приложений является тот факт, что не все программы можно распараллелить. Об этом я скажу несколько ниже.
И все же самая главная трудность параллелизма заключается в нем самом. Модель параллельного программирования, т.е. та модель образов, которая складывается в голове программиста, и с помощью которой он судит о поведении своей программы, намного сложнее, чем модель последовательного исполнения кода.
Всякий, кто берется за изучение параллелизма, в какой-то момент считает, что разобрался в нем полностью. Потом, столкнувшись с необъяснимым состояниями гонки (race conditions), вдруг осознает, что рано еще говорить о полном понимании. Далее, по мере того, как программист обучается навыкам работы с параллельным кодом, он обнаруживет, что необычных состояний гонки можно избежать, если код тщательно оттестировать, и переходит на второй уровень мнимого знания и понимания. Но во время тестирования, обычно ускользают те ошибки параллельного программирования, которые проявляются только на реальных многопроцессорных системах, где потоки исполняются не просто переключением контекста на одном процессоре, а там, где они выполняются действительно одновременно, вызывая новый класс ошибок. Так программист, который считал что теперь-то уж он точно знает, как пишутся параллельные программы, получает новый удар. Мне встречалось множество команд, чьи приложения отлично работали во время долгого усиленного тестирования и превосходно работали у клиентов, пока в один прекрасный день один из клиентов не устанавливал программу на многопроцессорную машину, и тут же то там то здесь стали вылазить необъяснимые состояния гонки и повреждения данных.
Так вот, в контексте современных процессоров, переделка приложения в многопоточное для работы на многоядерной машине сродни попытке научиться плавать, прыгая с бортика в глубокую часть бассейна: вы попадаете в ничего непрощающую действительно параллельную среду, которая немедленно вам покажет все ваши ошибки в программировании. Но, даже если ваша команда действительно умеет писать правильный параллельный код, есть и другие подвохи: например, ваш код может оказаться абсолютно верным с точки зрения параллельного программирования, но он не будет работать быстрее, чем однопоточная версия. Обычно это происходит потому, что потоки в новой версии недостаточно независимы други от друга, или обращаются к какому-то общему ресурсу, в результате чего исполнение программы становится последовательным, а не параллельным. Тонкостей становится все больше и больше.
При переходе от структурного программирования к объектно-ориентированному у программистов были точно такие же трудности (что такое объект? что такое виртуальная функция? для чего нужно наследование? И помимо всех этих «что» и «почему», самое главное – почему правильные программные конструкции являются действительно правильными?), что и сейчас – при переходе от последовательного программирования к параллельному (что такое «гонка»? что такое «взаимная блокировка» (deadlock)? от чего она происходит и как мне ее избежать? какие программные конструкции делают мою параллельную программу последовательной? почему надо подружиться с очередью сообщений (message queue)? И помимо всех этих «что» и «почему», самое главное – почему правильные программные конструкции являются действительно правильными?)
Большинство сегодняшних программистов не разбирается в параллелизме. Точно так же 15 лет назад большинство программистов не понимало ООП. Но модели параллельного программированяи можно обучиться, особенно если мы хорошо освоим понятия передачи сообщений и блокировки (message- and lock-based programming). После этого параллельное программирование будет не труднее, чем ООП, и, надеюсь, станет вполне привычным. Просто подготовьтесь, что вам и вашей команде придется потратить некоторое время на переобучение.
(Я намеренно свел параллельное программирование к понятиям передачи сообщений и блокировки. Существует способ писать параллельные программы без блокировок (concurrent lock-free programming), и этот способ поддерживается на уровне яыка лучше всего в Java 5 и по крайней мере в одном из известных мне компиляторов С++. Но параллельное программирование без блокировок намного труднее в освоении, чем программирование с блокировками. Большей частью оно понадобится только разработчикам системного и библиотечного ПО, хотя каждому программисту придется понять, как работают такие системы и библиотеки, чтобы извлечь из них пользу для своих приложений. Честно говоря, и программировать с блокировками тоже не так уж легко и просто.)
ОК. Вернемся к тому, что все это значит для нас – программистов.
1. Первое главное последствие, которое мы уже осветили, это то, что приложения должны стать параллельными, если вы хотите на все 100% использовать растущую пропускную способность процессоров, которые уже начали появляться на рынке и будут править бал на нем в последующие несколько лет. Например, компания Intel заявляет, что в недалеком будушем она создаст процессор из 100 ядер; однопоточное приложение сможет использовать только 1/100 мощи данного процессора.
Да, не все приложения (или, если говорить точнее, важные операции, выполняемые приложением) можно распараллелить. Да, для некоторых задач, например компиляция, параллелизм походит почти идеально. Но для других – нет. Обычно в качестве контр-примера вспоминают ходячую фразу о том, что если у одной женщины уходит 9 месяцев, чтобы родить ребенка, это вовсе не значит, что 9 женщин смогут родить ребенка за 1 месяц. Вы наверное часто встречались с этой аналогией. Но заметили ли вы обманчивость этой аналогии? Когда вам в очередной раз упомянут о ней, задайте в ответ простой вопрос: «можно ли из этой аналогии заключить, что Задача Рождения Ребенка не поддается параллелизации по определению?» Обычно в ответ люди задумываются, а потом быстро приходят к заключению, что «да, эту задачу невозможно распараллелить», но это не совсем так. Разумеется, ее невозможно распараллелить, если наша цель — родить одного единственного ребенка. Но она великолепно поддается параллелизации, если мы ставим себе цель родить как можно больше детей (по одному ребенку в месяц)! Вот так, знание реальной цели может перевернуть все с ног на голову. Помните об этом принципе цели, когда решаете, стоит ли менять свою программу и каким образом это надо делать.
2. Пожалуй, менее очевидным последствием является то, что скорей всего приложения все больше и больше будут тормозить из-за процессоров (CPU-bound). Разумеется, это произойдет не со всеми приложениям, а те, с которыми это может произойти, не станут тормозить буквально завтра. Тем не менее мы, пожалуй, достигли границы, когда приложения тормозили из-за систем ввода-вывода, или из-за обращения к сети или базам данных. В этих областях скорости становятся все выше и выше (слышали про гигабитный Wi-Fi?). А все традиционные способы ускорения процессоров себя исчерапали. Только подумайте: мы сейчас прочно застряли на скорости 3ГГц. Следовательно, однопоточные программы не станут работать быстрее, ну разве только за счет увеличения размеров кеша процессоров (уж хоть какая-то хорошая новость). Другие продвижения в этом направлении будут уже не такими большими, как мы привыкли раньше. Например, вряд ли инженеры-схемотехники отыщут новый способ, как заполнять работой конвейер процессора и не допускать его простаивания. Здесь все очевидные решения уже давно были найдены и реализованы. Рынок безпристанно будет требовать от программ большей функциональности; кроме того новым приложениям придется обрабатывать все больше и больше данных. Чем больше функционала мы станем вводить в программы, тем скорее мы станем замечать, что программам не хватает мощности процессора, потому что они не параллельны.
И здесь у вас будет два варианта. Первый, переделать свое приложение в параллельное, как уже было сказано выше. Либо, для самых ленивых, переписать код так, чтобы он стал более эффективным и менее расточительным. Что приводит нас к третьему выводу:
3. Важность эффективного и оптимизированного кода будет только расти, а не уменьшаться. Языки, которые позволяют добиваться высокого уровня оптимизации кода, получат вторую жизнь, а тем языкам, которые не позволяют этого делать, придется придумывать, как выжить в новых условиях конкуренции и стать более эффектиными и более оптимизируемыми. Считаю, что на долгое время установится высокий спрос на высокопроизводительные языки и системы.
4. И наконец, языки программирования и программные системы вынуждены будут хорошо поддерживать параллелизм. Язык Java, например, поддерживает параллелизм с самого своего рождения, хотя в этой поддержке и были сделаны ошибки, которые пришлось потом исправлять на протяжение нескольких релизов, чтобы многопоточные программы на Java работали правильно и эффективно. Язык С++ с давних пор использовался для написания мощных многопоточных приложений. Однако параллелизм в этом языке не приведен к стандартам (во всех ISO-стандартах языка С++ даже не упоминаются потоки, и сделано это намеренно), так что для его реализации приходится прибегать к различным платформенно-зависимым библиотекам. (Кроме того и поддержка параллелизма далеко не полна, например, статические переменные должны быть инициализированы только раз, для чего от компилятора требуется обозначить инициализацию блокировками, а многие компиляторы С++ этого не делают). Наконец, существует несколько стандартов параллелизма в С++, включая pthreads и OpenMP, и некоторые из них поддерживают даже два вида параллелизации: скрытую (implicit) и явную (explicit). Прекрасно, если такой компилятор, работая с вашим однопоточным кодом, сумеет превратить его в параллельный, отыскав в нем куски, которые могут быть распараллелены. Однако такой автоматизированный подход имеет свои пределы и не всегда дает хороший результат по сравнению с кодом, где параллелизм присутствует явно, заданный сами программистом. Главный секрет мастерства заключается в программировании с использованием блокировок, что освоить довольно трудно. Нам срочно требуется более продвинутая модель параллельного программирования чем та, что предлагают современные языки. Об этом подробнее я скажу в другой статье.
Если вы еще этого не сделали, сделайте это сейчас: внимательно посмотрите на дизайн вашего приложения, определите, какие операции требуют или потребуют позже больших вычислительных мощностей от процессора, и решите, как эти операции можно распараллелить. Кроме того, именно сейчас вам и вашей команде надо освоить параллельное программирование, все его секреты, стили и идиомы.
Лишь небольшую часть приложений можно распараллелить без каких-либо усилий, большинство – увы, нет. Даже если вы знаете точно, в каком месте ваша программа выжимает из процессора последние соки, может оказаться, что данную операцию будет очень трудно превратить в параллельную; тем больше причин начать думать об этом уже сейчас. Компиляторы с неявной параллелизацией лишь отчасти смогут вам помочь, не ожидайте от них чуда; они не смогут превратить однопоточное приложение в паралаллельное лучше, чем это сделаете вы сами.
Благодаря росту размеров кеша и еще немногим улучшениям в оптимизации исполнения кода бесплатный суп будет доступен еще некоторое время, но начиная с сегодняшего дня в его составе будет только одна вермишель и морковка. Все наваристые кусочки мяса будут в супе лишь за дополнительную плату – дополнительные усилия программиста, дополнительная сложность кода, дополнительное тестирование. Успокаивает то, что для большинства приложений эти усилия будут не напрасными, потому что они позволят на все 100% использовать экспоненциальный рост мощности современных процессоров.
Автор: Герб Саттер
Перевод: Александр Качанов
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
(By Herb Sutter)
Ссылка на оригинал статьи: www.gotw.ca/publications/concurrency-ddj.htm
Примечание переводчика: В данной статье дается обзор современных тенденций развития процессоров, а также, что именно эти тенденции значат для нас — программистов. Автор считает, что тенденции эти имеют фундаментальное значение, и что каждому современному программисту придется кое в чем переучиваться, чтобы не отстать от жизни.
Данная статья достаточно старая. Ей уже 7 лет, если считать с момента ее первой публикации в начале 2005 года. Помните об этом, когда будете читать перевод, так как многие вещи, которые для вас уже стали привычными, для автора статьи в 2005 году были в новинку и только-только появлялись.
В ваши двери стучится крупнейшая революция в области разработки программного обеспечения со времен революции ООП, и зовут ее Параллелизм.
Данная статья впервые была опубликована в журнале «Dr. Dobb's Journal» в марте 2005 года. Более короткая версия этой статьи была опубликована в журнале «C/C++ Users Journal» в феврале 2005 года под названием «Революция параллелизма».
Обновление: график тенденций роста процессоров был обновлен в августе 2009 года. К нему были добавлены новые данные, которые показывают, что все предсказания данной статьи сбываются. Остальной текст данной статьи остался без изменений в том виде, как он был опубликован в декабре 2004 года.
Бесплатного супа скоро больше не будет. Что вы будете делать по этому поводу? Что вы сейчас делаете по этому поводу?
У ведущих производителей процессоров и архитектур, начиная от Intel и AMD и кончая Sparc и PowerPC, большей частью исчерпаны традиционные возможности увеличения производительности. Вместо того, чтобы и дальше увеличивать частоту процессоров и их линейную пропускную способность, они массово обращаются к гиперпоточным и многоядерным архитектурам. Обе эти архитектуры уже присутствуют в сегодняшних процессорах. В частности современные процессоры PowerPC и Sparc IV являются многоядерными, а в 2005 году к течению присоединятся Intel и AMD. Кстати, крупной темой форума In-Stat/MDR Fall Processor Forum, прошедшего осенью 2004 года была как раз тема многоядерных устройств, так как именно там множество компаний представило свои как новые так и обновленные многоядерные процессоры. Не будет преувеличением сказать, что 2004 год стал годом многоядерности.
Значит мы подходим к фундаментальной поворотной точке в разработке ПО, по крайней мере на несколько лет вперед и для приложений, предназначенных для настольных компьютеров общего назначения и и для нижнего сегмента серверов (которые, кстати, в долларовом выражении составляют громадную долю всех программ, продаваемых ныне на рынке). В данной статье я опишу, как меняется аппаратное обеспечение, почему эти изменения вдруг стали для нас важны, как именно революция параллелизации коснется вас, и того, как вы скорей всего будете писать программы в будущем.
Пожалуй, бесплатный суп закончился уже как год или два назад. Мы только сейчас стали это замечать.
Бесплатный суп производительности
Вы наверное слышали такую интересную поговорку: «Сколько бы Энди не выдал, Билл заберет все» («Andy giveth and Bill taketh away»)? (прим.переводчика — Имеется в виду Энди Гроув — руководитель компании Intel, и Билл Гейтс — руководитель компании Microsoft). Сколько бы процессоры не увеличивали скорость своей работы, программы всегда придумают, на что потратить эту скорость. Сделайте процессор в десять раз быстрее, и программа найдет в десять раз больше работы для него (либо, в некоторых случаях, позволит себе выполнять ту же самую работу в десять раз менее эффективно). Большинство приложений на протяжение нескольких десятилетий работали все быстрее и быстрее, не делая для этого абсолютно ничего, даже без выпуска новых версий или коренных изменений в коде. Просто изготовители процессоров (в первую очередь) и производители памяти и жестких дисков (во вторую очередь) всякий раз создавали все новые и новые, все более быстрые компьютерные системы. Тактовая частота работы процессора не единственный критерий оценки его производительности, и даже не самый правильный, но тем не менее он говорит о многом: мы видели, как на смену 500 МГц-овым процессорам пришли процессоры с тактовой частотой 1ГГц, а за ними – 2ГГц-овые процессоры и так далее. Так что сейчас мы переживаем этап, когда вполне рядовым является процессор с тактовой частотой 3 ГГц.
Теперь зададимся вопросом: Когда же закончится эта гонка? Вроде бы Закон Мура (Moore’s Law) предсказывает экспоненциальный рост. Ясно, что такой рост не может продолжаться вечно, он неизбежно упрется в физические пределы: ведь с годами скорость света быстрее не становится. Значит рост рано или поздно замедлится и даже остановится. (Маленькое уточнение: Да, Закон Мура говорит главным образом о плотности транзисторов, но можно сказать, что экспоненциальный рост наблюдался и в такой области, как тактовая частота. А в других областях рост был даже еще большим, например, рост емкостей накопителей, но это тема отдельной статьи.)
Если вы – разработчик программного обеспечения, скорей всего вы уже давно расслабленно едете на волне увеличения производительности настольных компьютеров. Ваша программа медленно работает при выполнении какой-то операции? «Чего волноваться?», скажете вы, — «завтра выйдут еще более быстрые процессоры, а вообще программы работают медленно не только из-за медленного процессора и медленной памяти (например, еще из-за медленных устройств ввода-вывода, из-за обращений к базам данных)». Верный ход мыслей?
Вполне верный. Для вчерашнего дня. Но абсолютно неверный для обозримого будущего.
Хорошая новость – процессоры будут становиться все мощнее и мощнее. Плохая новость — по крайне мере в ближайшем будущем рост мощности процессоров будет идти в таком направлении, которое никак не приведет к автоматическом ускорению работы большинства ныне существующих программ.
На протяжение последних 30 лет разработчики процессоров смогли увеличить производительность в трех главных областях. Первые две из них связаны с исполнением кода программ:
- тактовая частота процессора
- оптимизация исполнения кода
- кэш
Увеличение тактовой частоты означает увеличение скорости. Если увеличить скорость работы процессора, это более менее приведёт к тому, что он будет выполнять тот же самый код быстрее.
Оптимизация исполнения кода программы означает выполнение большего объема работы за один такт. Сегодняшние процессоры оснащены очень мощными инструкциями, а еще они выполняют разные оптимизации, от тривиальных до экзотических, включая конвейерное исполнение кода, предугадывание ветвлений (branch predictions), исполнение нескольких инструкций за один и тот же такт и даже выполнение команд программы в ином порядке (instructions reordering). Все эти технологии были придуманы для того, чтобы код исполнялся как можно лучше и/или как можно быстрее, чтобы выжать как можно больше из каждого такта, сводя задержки к минимуму и выполняя больше операций за каждый такт.
Небольшое отступление по поводу выполнения инструкций в ином порядке (instruction reordering) и моделях памяти (memory models): хочу отметить, что под словом «оптимизациями» я имел в виду нечто на самом деле большее. Эти «оптимизации» могут менять смысл программы и приводить к результатам, которые будут противоречить ожиданиям программиста. Это имеет огромное значение. Разработчики процессоров не безумцы, и в жизни они мухи не обидят, им и в голову не придет портить ваш код… в обычной ситуации. Но в течение последних лет они решились на агрессивные оптимизации с единственной целью: выжать еще больше из каждого такта процессора. При этом они прекрасно понимают, что эти агрессивные оптимизации ставят под угрозу семантику вашего кода. Что ж, это они из вредности так делают? Вовсе нет. Их стремление – это реакция на давление рынка, который требует все более и более быстрых процессоров. Это давление настолько велико, что такое увеличение скорости работы вашей программы ставит под угрозу её корректность и даже её способность вообще работать.
Приведу два наиболее ярких примера: изменение порядка операций записи данных (write reordering) и порядка их чтения (read reordering). Изменение порядка операций записи данных приводит к таким удивительным последствиям и сбивает с толку стольких программистов, что эту функцию приходится обычно отключать, так как при ее включении становится слишком трудно правильно судить о том, как будет вести себя написанная программа. Перестановка операций чтения данных тоже может привести к удивительным результатам, но эту функцию обычно оставляют включенной, так как здесь особенных трудностей у программистов не возникает, а требования к производительности операционных систем и программных продуктов заставляют программистов идти хоть на какой-то компромис и скрепя сердце выбирать меньше из «зол» оптимизации.
Наконец, увеличение размера встроенного кэша означает стремление как можно реже обращаться к оперативной памяти. ОЗУ компьютера работает намного медленнее, чем процессор, поэтому лучше всего размещать данные как можно ближе к процессору, чтобы не бегать за ними в ОЗУ. Самое близкое – это хранить их на том же кусочке кремния, где находится сам процессор. Рост размеров кэш-памяти за последние годы был просто ошеломительным. Сегодня уже никого нельзя удивить процессорами со встроенной кэш-памятью 2-го уровня (L2) в 2Мб и более. (Из трех исторических подходов по увеличению производительности процессоров, рост кэш-памяти будет единственным перспективным подходом на ближайшее будущее. Еще немного о важности кэш-памяти я поговорю несколько ниже.)
Хорошо. К чему я это все?
Главное значение этого списка в том, что все перечисленные направления никак не связаны с параллелизмом. Прорывы во всем перечисленным направлениям приведут как к ускорению последовательных (непараллельных, одно-процессных) приложений, так и тех приложений, которые используют параллелизм. Сей вывод важен потому, что большинство сегодняшних приложений является одно-поточными, о причинах этого я скажу ниже.
Разумеется и компиляторам прошлось поспевать за процессорами; вам время от времени приходилось перекомпилировать ваше приложение, выбирая определенную модель процессора как минимально приемлимую, чтобы извлечь пользу из новых инструкций (например, MMX, SSE), новых функций и новых характеристик. Но в целом даже старые программы всегда работали значительно быстрее на новых процессорах, чем на старых, даже без всякой перекомпилляции и использования новейших инструкций новейших процессоров.
Как прекрасен был этот мир. К сожалению, этого мира больше не существует.
Препятствия, или почему мы не видим 10ГГц-вых процессоров
Привычный для нас рост производительности процессоров два года назад натолкнулся на стену. Большинство из нас уже стали замечать это.
Похожий график можно создать и для других процессоров, но в данной статье я собираюсь воспользоваться данными по процессорам Intel. На рис.1 представлен график, отображающий, когда какой процессор Intel был представлен на рынке, его тактовая частота и количество транзисторов. Как видите, количество тразисторов продолжает расти. А вот с тактовой частотой у нас проблемы.
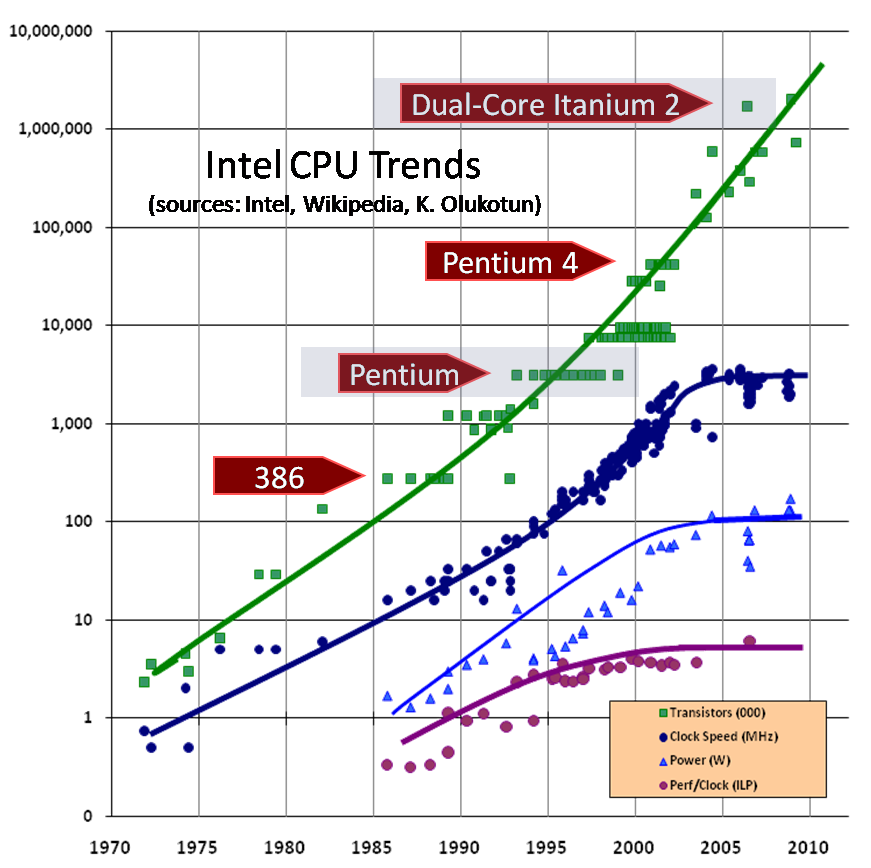
Обратите внимание, что в районе 2003 года график тактовой частоты резко и странно отклоняется от привычной тенденции непрерывного роста. Между точками я провел линии, чтобы была более понятна тенденция; вместо того, чтобы продолжать расти, график неожиданно становится горизонтальным. Рост тактовой частоты дается все большей и большей ценой, и физических препятствий на пути роста не одно, а множество, например нагрев процессоров (слишком много выделяется тепла и его слишком трудно рассеивать), потребление энергии (слишком высоко) и паразитная утечка тока.
Краткое отступление: посмотрите, какова тактовая частота процессора на вашем компьютере? Может быть 10ГГц? Процессоры Intel достигли уровня 2ГГц давным давно (в августе 2001 года), а если бы тенденция роста тактовой частоты, существовавшая до 2003 года, продолжалась, то сейчас — в начале 2005 года — должны были бы появиться первые процессоры Pentium с частотой 10ГГц. Осмотритесь, видите ли вы их? Более того, процессоров с такой тактовой частотой ни у кого даже в планах нет, и мы даже не знаем, когда такие планы появятся.
Ну, а что насчет 4ГГц-вого процессора? Уже сейчас есть процессоры с частотой 3.4ГГц, значит 4ГГц не за горами? Увы, мы не можем дотянуться даже до 4ГГц. В середние 2004 года вы наверное помните, как компания Intel перенесла выпуск 4ГГц-ового процессора на 2005 год, а потом осенью 2004 года официально объявила о полном отказе от этих планов. На момент написания данной статьи Intel планирует продвинуться чуть вперед, выпустив в начале 2005 года процессор с частотой 3.73ГГц (на рис.1 на графике роста частоты это самая верхняя точка), но можно сказать, что гонка за герцами закончена, по крайней мере на сегодняшний момент. В будущем компания Intel и большинство производителей процессоров будут добиваться роста другими способами: все они активно стали обращаться к многоядерным (multicore) решениям.
Возможно когда-то мы все же увидим 4ГГц-овые процессоры в наших настольных компьютерах, но это будет не в 2005 году. Конечно в лабораториях Intel есть опытные образцы, которые работают и на более высоких скоростях, но достигаются эти скорости прямо-таки героическими усилиями, например с помощью громоздкого охлаждающего оборудования. Не ждите, что такое охлаждающее оборудование появится когда-либо в вашем офисе, и уж точно не в самолете, где вам бы хотелось поработать на ноутбуке.
БСНБ: Закон Мура и следующие поколения процессоров
«Бесплатного супа не бывает (БСНБ)» — Р.А.Хайнлайн, «Луна — строгая хозяйка»
Значит ли это, что Закон Мура больше не действителен? Самое интересное, что ответ будет «нет». Разумеется, как и всякая экспоненциальная прогрессия Закон Мура когда-то перестанет работать, но по всей видимости на ближайшие несколько лет Закону ничего не угрожает. Несмотря на то, что конструкторы процессоров больше не могут увеличивать тактовую частоту, число транзисторов в их процессорах продолжает расти взрывным темпом, и в ближайшие годы рост по Закону Мура будет продолжаться.
Главное отличие от прежних тенденций, ради чего и была написана данная статья, заключается в том, что прирост производительности нескольких грядущих поколений процессоров будет достигаться фундаментально другими способами. И большинство нынешних приложений на этих новых более мощных процессорах уже не будут автоматически работать быстрее, если только в их дизайн не будут внесены значительные изменения.
В ближайшем будущем, точнее в ближайшие несколько лет, прирост производительности в новых процессорах будет достигаться тремя главными способами, лишь один из которых остался из прежнего списка. А именно:
- гиперпоточность (hyperthreading)
- многоядерность (multicore)
- кэш (cache)
Гиперпоточность (Hyperthreading) это технология исполнения двух и более потоков (threads) параллельно в одном и том же процессоре. Гиперпоточные процессоры уже сейчас имеются на рынке, и они действительно позволяют выполнять несколько инструкций параллельно. Однако, несмотря на то, что у гиперпоточного процессора для выполненяи этой задачи имеется в наличии дополнительные аппаратные срества, например, дополнительные регистры, у него по прежнему всего один кэш, один вычислительные блок для целочисленной математики, один блок для операций с плавающей запятой и вообще по одному всего, что есть в наличии в любом простом процессоре. Считается, что гиперпоточность позволяет увеличивать производительность сносно написанных много-поточных программ на 5-15 процентов, а производительность отлично написанных многопоточных программ при идеальных условиях увеличивается аж на 40%. Неплохо, но это далеко не удвоение производительности, а однопоточные программы здесь ничего выиграть не могут.
Многоядерность (Multicore) это технология размещения на одном и том же кристалле двух или нескольких процессоров. Некоторые процессоры, например SPARC и PowerPC, уже выпускаются в многоядерных вариантах. Первые попытки компаний Intel и AMD, которые должны реализоваться в 2005 году, отличаются друг от друга по степени интеграции процессоров, но функционально они очень схожи. Процессор от AMD будет иметь несколько ядер на одном кристалле, что приведет к большему выигрышу в производительности, в то время как первый многоядерный процессор Intel представляет собой всего лишь два сопряженных процессора Xeon на одной большой подложке. Выигрыш от такого решения будет таким же как от наличия двух-процессорной системы (только дешевле, так как на материнской плате не понадобится два сокета для установки двух чипов и дополнительных микросхемы для их согласования). В идеальных условиях скорость исполнения программ почти удвоится, но только у достаточно хорошо написанных многопоточных приложений. Однопоточные приложения не получат никакого прироста.
Наконец, ожидается рост объемов встроенного кэша (on-die cache), по крайней мере в ближайшем будущем. Из всех трех тенденций, только эта приведет к росту прозводительности большинства существующих приложений. Рост размера встроенного кэша для всех приложений важен просто потому, что размер значит скорость. Доступ к ОЗУ обходится слишком дорого, и по большому счету хочется обращаться к ОЗУ как можно реже. В случае промаха кэша (cache miss), на извлечение данных из ОЗУ уйдет в 10-50 раз больше времени, чем на их извлечение из кэша. До сих пор людей это удивляет, поскольку было принято считать, что ОЗУ работает очень быстро. Да, быстро по сравнению с дисками и сетью, но кэш-память работает еще быстрее. Если весь объем данных, с которым предстоит работать приложению, помещается в кэше, мы — в шоколаде, а если нет, то в чем-то другом. Вот поэтому растущие размеры кэш-памяти спасут некоторые сегодняшние программы и вдохнут в них еще немного жизни на несколько лет вперед без каких-либо значительных переделок с их стороны. Как говорили во времена Великой Депрессии: «Кэша мало не бывает». («Cache is king»)
(Краткое отступление: вот вам история, случившаяся с нашим компилятором, в качестве демонстрации утверждения «размер значит скорость». 32-битная и 64-битная версии нашего компилятора создаются из одного и того же исходного кода, просто при компиляции мы указываем, какой процесс надо создать: 32-битный или 64-битный. Ожидалось, что 64-битный компилятор должен работать быстрее на 64-битном процессоре, хотя бы потому, что у 64-битного процессора было намного больше регистров, а также имелись оптимизирующие функции по более быстрому выполнению кода. Все просто прекрасно. А что насчет данных? Переход на 64 разряда не поменял размеры большинства структур данных в памяти, за исключением, конечно, указателей, размер которых стал в два раза больше. Оказалось, что наш компилятор использует указатели намного чаще, чем какое-либо другое приложение. Так как размер указателей теперь стал 8 байт, вместо 4 байт, общий размер данных, с которым надо было работать компилятору, увеличился. Увеличение объема данных ухудшило производительность ровно настолько, насколько она улучшилась из-за более быстрого процессора и наличия дополнительных регистров. На момент написания этой статьи наш 64-битный компилятор работает с такой же скоростью, что и его 32-битный собрат несмотря на то, что собраны оба компилятора из одного исходного кода, а 64-битный процессор — более мощный, чем 32-битный. Размер значит скорость!)
Воистину, кэш будет править балом. Так как ни гиперпоточность, ни многоядерность не увеличат скорость работы большинства сегодняшних программ.
Так что же эти изменения в аппартном обеспечении значат для нас – программистов? Вы уже наверное поняли, каков будет ответ, так что давайте обсудим его и сделаем выводы.
Мифы и реалии: 2 x 3ГГц < 6ГГц
Если двух-ядерный процессор состоит из двух 3ГГц-овых ядер, значит мы получает производительность 6ГГц-ового процессора. Верно?
Нет! Если два потока исполняются на двух физически раздельных процессорах, это вовсе не значит, что общая производительность программы увеличивается в два раза. Точно так же многопоточная программа не будет работать в два раза быстрее на двух-ядерных процессорах. Да, она будет работать быстрее, чем на одноядерном процессоре, но скорость не будет расти линейно.
Почему же нет? Во-первых, мы имеем издержки на согласование содержимого кэшей (cache coherency) двух процессоров (непротиворечивое состояние кэшей и разделяемой памяти), а также издержки на прочие взаимодействия. Сегодня двух- или четырех-процессорные машины не обгоняют по скорости в два или четыре раза своих однопроцессорных собратьев даже при выполнении многопоточных приложений. Проблемы остаются по сути теми же и в тех вариантах, когда вместо нескольких раздельных процессоров мы имеем несколько ядер на одном кристалле.
Во-вторых, несколько ядер используются полноценно лишь только в том случае, когда они исполняют два разных процесса, или два разных потока одного процесса, которые написаны так, что способны работать независимо друг от друга и никогда не ждут друг друга.
(Вступая в противоречие со своим предыдущим утверждением, я могу представить себе реальную ситуацию, когда однопоточное приложение у рядового пользователя будет работать быстрее на двух-ядерном процессоре. Это произойдет вовсе не потому, что второе ядро будет занято чем-то полезным. Напротив, на нем будет выполнятся какой-нибудь троян или вирус, который до этого отъедал вычислительные ресурсы у однопроцессорной машины. Предоставляю вам решать, стоит ли приобретать еще один процессор в дополнение к первому, чтобы крутить на нем вирусы и трояны.)
Если ваше приложение — однопоточное, вы используете только одно ядро процессора. Конечно некоторое ускорение будет, так как операционная система или фоновое приложение будут исполняться на других ядрах, но как правило операционные системы не нагружают процессоры на 100%, так что соседнее ядро большей частью будет простаивать. (Или опять-таки, на нем будет крутиться троян или вирус)
Значение для ПО: Очередная революция
В конце 90-ых мы научились работать с объектами. В программировании произошел переход от структурного программирования к объектно-ориентированному, который стал самой значительной революцией в программировании за последние 20, а может даже и 30 лет. Были и другие революции, включая недавнее появление веб-сервисов, но за всю нашу карьеру мы не видели переворота более фундаментального и значительного по последствиям, чем объектная революция.
До сегодняшнего дня.
Начная с сегодняшнего дня за «суп» придется платить. Конечно кое-какой прирост производительности вы сможете получить и бесплатно, в основном за счет увеличения размера кэша. Но если вы хотите, чтобы ваша программа извлекла пользу из экспоненциального роста мощности новых процессоров, ей придется стать правильно написанным параллелизированным (как правило многопоточными) приложением. Легко сказать, да трудно сделать, потому что не все задачи можно запросто распараллелить, а также потому, что писать параллельные программы очень трудно.
Слышу крики возмущения: «Параллелизм? Какая ж это новость!? Люди уже давно пишут параллельные программы». Верно. Но это лишь ничтожная доля программистов.
Вспомните, что и объектно-ориентированным программированием люди занимались аж с конца 60-ых годов, когда вышел язык Simula. В то время ООП не вызвало никакой революции и не доминировало среди программистов. До наступления 90-ых годов. Почему именно тогда? Революция произошла в основном потому, что возникла нужда в еще более сложных программах, которые решали еще более сложные задачи и использовали все больше и больше ресурсов процессора и памяти. Для экономичной, надежной и предсказуемой разработки крупных программ сильные стороны ООП – абстракции и модульность – оказались очень кстати.
Точно также и с параллелизмом. Мы знаем о нем с незапамятных времен, когда писали сопрограммы и мониторы и прочие подобные хитрые утилиты. И за последние десять лет все больше и больше программистов стало создавать параллельные (многопроцессные или многопоточные) системы. Но о революции, о поворотной точке тогда еще рано было говорить. Поэтому сегодня большинство программ являются однопоточными.
Кстати, насчет шумихи: сколько раз нам объявляли, что мы стоим «на пороге очередной революции в области разработки ПО». Как правило те, кто это говорил, просто рекламировали свой новый продукт. Не верьте им. Новые технологии всегда интересны и даже порой оказываются полезными, но самые крупные революции в программировании производят те технологии, которые уже несколько лет присутствуют на рынке, тихонько набирают силу, пока в один прекрасный момент не происходит взрывной рост. Это неизбежно: революция может основываться только на достаточно зрелой технологии (у которой уже есть поддержка со стороны многих компаний и инструментариев). Обычно проходит лет семь, прежде чем новая технология программирования становится достаточно надежной, чтобы ее можно было бы широко применять, не наступая на грабли и глюки. В результате, настоящие революции в программировании, такие как ООП, производят те технологии, которые оттачивались годами, если не десятилетиями. Даже в Голливуде всякий актер, ставший в одну ночь суперзведой, до этого оказывается уже несколько лет играл в кино.
Параллелизм (Concurrency) — это следующая великая революция в программировании. Существуют разные мнения экспертов о том, сравнится ли она с революцией ООП, но оставим эти споры ученым мужам. Для нас, инженеров, важно то, что параллелизм сравним с ООП по масштабности (что ожидалось), а также по сложности и по трудности освоения этой новой технологии.
Выгоды параллелизма и во сколько они нам обойдутся
Есть две причины, по которым параллелизм и особенно многопоточность уже используются в основной массе программ. Во-первых, для того, что разделить выполнение независимых друг от друга операций; например, в моем сервере репликации баз данных естестенным было поместить каждую сессий репликации в свой поток, так как работали они совершенно независимо друг от друга (если только они не работали над одной о той же записью одной и той же базы данных). Во-вторых, для того, чтобы программы работали быстрее, либо благодаря ее исполнению на нескольких физических процессорах, либо за счет чередования исполнения одной процедуры в то время, когда другая – простаивает в ожидании. В моей программе репликации баз данных этот принцип тоже использовался, так что программа хорошо масштабировалась на многопроцессорных машинах.
Однако за параллелизм приходится платить. Некоторые очевидные трудности на самом деле таковыми не являются. Например, да, блокировка замедляет работу программы, но если ею пользоваться разумно и правильно, вы получаете больше от ускорения работы многопоточной программы, чем теряете на использование блокировки. Для этого вам надо распараллелить операции в вашей программе и свести к минимуму обмен данными между ними или вообще отказаться от него.
Пожалуй, второй главной трудностью на пути к параллелизации приложений является тот факт, что не все программы можно распараллелить. Об этом я скажу несколько ниже.
И все же самая главная трудность параллелизма заключается в нем самом. Модель параллельного программирования, т.е. та модель образов, которая складывается в голове программиста, и с помощью которой он судит о поведении своей программы, намного сложнее, чем модель последовательного исполнения кода.
Всякий, кто берется за изучение параллелизма, в какой-то момент считает, что разобрался в нем полностью. Потом, столкнувшись с необъяснимым состояниями гонки (race conditions), вдруг осознает, что рано еще говорить о полном понимании. Далее, по мере того, как программист обучается навыкам работы с параллельным кодом, он обнаруживет, что необычных состояний гонки можно избежать, если код тщательно оттестировать, и переходит на второй уровень мнимого знания и понимания. Но во время тестирования, обычно ускользают те ошибки параллельного программирования, которые проявляются только на реальных многопроцессорных системах, где потоки исполняются не просто переключением контекста на одном процессоре, а там, где они выполняются действительно одновременно, вызывая новый класс ошибок. Так программист, который считал что теперь-то уж он точно знает, как пишутся параллельные программы, получает новый удар. Мне встречалось множество команд, чьи приложения отлично работали во время долгого усиленного тестирования и превосходно работали у клиентов, пока в один прекрасный день один из клиентов не устанавливал программу на многопроцессорную машину, и тут же то там то здесь стали вылазить необъяснимые состояния гонки и повреждения данных.
Так вот, в контексте современных процессоров, переделка приложения в многопоточное для работы на многоядерной машине сродни попытке научиться плавать, прыгая с бортика в глубокую часть бассейна: вы попадаете в ничего непрощающую действительно параллельную среду, которая немедленно вам покажет все ваши ошибки в программировании. Но, даже если ваша команда действительно умеет писать правильный параллельный код, есть и другие подвохи: например, ваш код может оказаться абсолютно верным с точки зрения параллельного программирования, но он не будет работать быстрее, чем однопоточная версия. Обычно это происходит потому, что потоки в новой версии недостаточно независимы други от друга, или обращаются к какому-то общему ресурсу, в результате чего исполнение программы становится последовательным, а не параллельным. Тонкостей становится все больше и больше.
При переходе от структурного программирования к объектно-ориентированному у программистов были точно такие же трудности (что такое объект? что такое виртуальная функция? для чего нужно наследование? И помимо всех этих «что» и «почему», самое главное – почему правильные программные конструкции являются действительно правильными?), что и сейчас – при переходе от последовательного программирования к параллельному (что такое «гонка»? что такое «взаимная блокировка» (deadlock)? от чего она происходит и как мне ее избежать? какие программные конструкции делают мою параллельную программу последовательной? почему надо подружиться с очередью сообщений (message queue)? И помимо всех этих «что» и «почему», самое главное – почему правильные программные конструкции являются действительно правильными?)
Большинство сегодняшних программистов не разбирается в параллелизме. Точно так же 15 лет назад большинство программистов не понимало ООП. Но модели параллельного программированяи можно обучиться, особенно если мы хорошо освоим понятия передачи сообщений и блокировки (message- and lock-based programming). После этого параллельное программирование будет не труднее, чем ООП, и, надеюсь, станет вполне привычным. Просто подготовьтесь, что вам и вашей команде придется потратить некоторое время на переобучение.
(Я намеренно свел параллельное программирование к понятиям передачи сообщений и блокировки. Существует способ писать параллельные программы без блокировок (concurrent lock-free programming), и этот способ поддерживается на уровне яыка лучше всего в Java 5 и по крайней мере в одном из известных мне компиляторов С++. Но параллельное программирование без блокировок намного труднее в освоении, чем программирование с блокировками. Большей частью оно понадобится только разработчикам системного и библиотечного ПО, хотя каждому программисту придется понять, как работают такие системы и библиотеки, чтобы извлечь из них пользу для своих приложений. Честно говоря, и программировать с блокировками тоже не так уж легко и просто.)
Что все это значит для нас?
ОК. Вернемся к тому, что все это значит для нас – программистов.
1. Первое главное последствие, которое мы уже осветили, это то, что приложения должны стать параллельными, если вы хотите на все 100% использовать растущую пропускную способность процессоров, которые уже начали появляться на рынке и будут править бал на нем в последующие несколько лет. Например, компания Intel заявляет, что в недалеком будушем она создаст процессор из 100 ядер; однопоточное приложение сможет использовать только 1/100 мощи данного процессора.
Да, не все приложения (или, если говорить точнее, важные операции, выполняемые приложением) можно распараллелить. Да, для некоторых задач, например компиляция, параллелизм походит почти идеально. Но для других – нет. Обычно в качестве контр-примера вспоминают ходячую фразу о том, что если у одной женщины уходит 9 месяцев, чтобы родить ребенка, это вовсе не значит, что 9 женщин смогут родить ребенка за 1 месяц. Вы наверное часто встречались с этой аналогией. Но заметили ли вы обманчивость этой аналогии? Когда вам в очередной раз упомянут о ней, задайте в ответ простой вопрос: «можно ли из этой аналогии заключить, что Задача Рождения Ребенка не поддается параллелизации по определению?» Обычно в ответ люди задумываются, а потом быстро приходят к заключению, что «да, эту задачу невозможно распараллелить», но это не совсем так. Разумеется, ее невозможно распараллелить, если наша цель — родить одного единственного ребенка. Но она великолепно поддается параллелизации, если мы ставим себе цель родить как можно больше детей (по одному ребенку в месяц)! Вот так, знание реальной цели может перевернуть все с ног на голову. Помните об этом принципе цели, когда решаете, стоит ли менять свою программу и каким образом это надо делать.
2. Пожалуй, менее очевидным последствием является то, что скорей всего приложения все больше и больше будут тормозить из-за процессоров (CPU-bound). Разумеется, это произойдет не со всеми приложениям, а те, с которыми это может произойти, не станут тормозить буквально завтра. Тем не менее мы, пожалуй, достигли границы, когда приложения тормозили из-за систем ввода-вывода, или из-за обращения к сети или базам данных. В этих областях скорости становятся все выше и выше (слышали про гигабитный Wi-Fi?). А все традиционные способы ускорения процессоров себя исчерапали. Только подумайте: мы сейчас прочно застряли на скорости 3ГГц. Следовательно, однопоточные программы не станут работать быстрее, ну разве только за счет увеличения размеров кеша процессоров (уж хоть какая-то хорошая новость). Другие продвижения в этом направлении будут уже не такими большими, как мы привыкли раньше. Например, вряд ли инженеры-схемотехники отыщут новый способ, как заполнять работой конвейер процессора и не допускать его простаивания. Здесь все очевидные решения уже давно были найдены и реализованы. Рынок безпристанно будет требовать от программ большей функциональности; кроме того новым приложениям придется обрабатывать все больше и больше данных. Чем больше функционала мы станем вводить в программы, тем скорее мы станем замечать, что программам не хватает мощности процессора, потому что они не параллельны.
И здесь у вас будет два варианта. Первый, переделать свое приложение в параллельное, как уже было сказано выше. Либо, для самых ленивых, переписать код так, чтобы он стал более эффективным и менее расточительным. Что приводит нас к третьему выводу:
3. Важность эффективного и оптимизированного кода будет только расти, а не уменьшаться. Языки, которые позволяют добиваться высокого уровня оптимизации кода, получат вторую жизнь, а тем языкам, которые не позволяют этого делать, придется придумывать, как выжить в новых условиях конкуренции и стать более эффектиными и более оптимизируемыми. Считаю, что на долгое время установится высокий спрос на высокопроизводительные языки и системы.
4. И наконец, языки программирования и программные системы вынуждены будут хорошо поддерживать параллелизм. Язык Java, например, поддерживает параллелизм с самого своего рождения, хотя в этой поддержке и были сделаны ошибки, которые пришлось потом исправлять на протяжение нескольких релизов, чтобы многопоточные программы на Java работали правильно и эффективно. Язык С++ с давних пор использовался для написания мощных многопоточных приложений. Однако параллелизм в этом языке не приведен к стандартам (во всех ISO-стандартах языка С++ даже не упоминаются потоки, и сделано это намеренно), так что для его реализации приходится прибегать к различным платформенно-зависимым библиотекам. (Кроме того и поддержка параллелизма далеко не полна, например, статические переменные должны быть инициализированы только раз, для чего от компилятора требуется обозначить инициализацию блокировками, а многие компиляторы С++ этого не делают). Наконец, существует несколько стандартов параллелизма в С++, включая pthreads и OpenMP, и некоторые из них поддерживают даже два вида параллелизации: скрытую (implicit) и явную (explicit). Прекрасно, если такой компилятор, работая с вашим однопоточным кодом, сумеет превратить его в параллельный, отыскав в нем куски, которые могут быть распараллелены. Однако такой автоматизированный подход имеет свои пределы и не всегда дает хороший результат по сравнению с кодом, где параллелизм присутствует явно, заданный сами программистом. Главный секрет мастерства заключается в программировании с использованием блокировок, что освоить довольно трудно. Нам срочно требуется более продвинутая модель параллельного программирования чем та, что предлагают современные языки. Об этом подробнее я скажу в другой статье.
В заключение
Если вы еще этого не сделали, сделайте это сейчас: внимательно посмотрите на дизайн вашего приложения, определите, какие операции требуют или потребуют позже больших вычислительных мощностей от процессора, и решите, как эти операции можно распараллелить. Кроме того, именно сейчас вам и вашей команде надо освоить параллельное программирование, все его секреты, стили и идиомы.
Лишь небольшую часть приложений можно распараллелить без каких-либо усилий, большинство – увы, нет. Даже если вы знаете точно, в каком месте ваша программа выжимает из процессора последние соки, может оказаться, что данную операцию будет очень трудно превратить в параллельную; тем больше причин начать думать об этом уже сейчас. Компиляторы с неявной параллелизацией лишь отчасти смогут вам помочь, не ожидайте от них чуда; они не смогут превратить однопоточное приложение в паралаллельное лучше, чем это сделаете вы сами.
Благодаря росту размеров кеша и еще немногим улучшениям в оптимизации исполнения кода бесплатный суп будет доступен еще некоторое время, но начиная с сегодняшего дня в его составе будет только одна вермишель и морковка. Все наваристые кусочки мяса будут в супе лишь за дополнительную плату – дополнительные усилия программиста, дополнительная сложность кода, дополнительное тестирование. Успокаивает то, что для большинства приложений эти усилия будут не напрасными, потому что они позволят на все 100% использовать экспоненциальный рост мощности современных процессоров.
