Недостаточно писать код хорошо читаемым: он также должен быстро выполняться.
Существует три базовых правила для написания такого T-SQL кода, который будет работать хорошо. Они кумулятивные – выполнение всех этих правил окажет положительное влияние на код. Пропуск или изменение любого из них – скорее всего приведет к отрицательному влиянию на производительность вашего кода.
Существует несколько типичных ошибок, которые люди допускают в своем коде на T-SQL – не совершайте их.
В теории избежать этой ошибки очень просто, но вот на практике она довольно часто встречается. Например, вы используете какой-либо тип данных в своей базе данных. Используйте его же в своих параметрах и переменных! Да, я знаю, что SQL Server может неявно приводить один тип данных к другому. Но, когда происходит неявное преобразование типа, или же вы сами приводите тип данных столбца к другому типу, вы выполняете преобразование для всего столбца. Когда вы выполняете это преобразование для столбца в выражении WHERE или же в условии соединения – вы всегда будете видеть сканирование таблицы (table scan). По этому столбцу может быть построен превосходный индекс, но поскольку вы делаете CAST для значений, хранящихся в этом столбце, чтобы сравнить, например дату, хранящуюся в этом столбце, с типом char, который вы использовали в условии, индекс не будет использоваться.
Не верите? Давайте посмотрим на этот запрос:
Хорошо написан и очень прост. Он должен покрываться индексом, созданным на этой таблице. Но вот план выполнения:

Этот запрос выполняется достаточно быстро и таблица невелика, так что только четыре операции чтения потребуются, чтобы просканировать индекс. Обратите внимание на небольшой восклицательный знак на операторе SELECT. Если обратиться к его свойствам, мы увидим:

Правильно. Это предупреждение (новое в SQL Server 2012) о том, что выполняется преобразование типов, влияющее на план выполнения. Вкратце – это потому, что в запросе используется неверный тип данных:
И мы получаем вот такой план выполнения запроса:

И здесь используются только две операции чтения, вместо четырех. И да, я понимаю, что сделал и так быстро выполняющийся запрос чуть-чуть более быстрым. Но что было бы, если бы в таблице хранились миллионы строк? Ага, тогда-то я стал бы героем.
Используйте правильные типы данных.
Говоря о функциях – большинство из функций, использующихся в условиях соединения или выражениях WHERE, которым вы, в качестве аргумента, передаете столбец, мешают правильному использованию индексов. Вы увидите насколько медленнее выполняются запросы, в которых используются функции, получающие в качестве аргументов, столбцы. Вот например:
Эта функция, LEFT, получает в качестве аргумента столбец, что выливается в этот план выполнения:

В результате, осуществляется 316 операций чтения, чтобы найти нужные данные, и это занимает 9 миллисекунд (у меня очень быстрые диски). Все потому что ‘4444’ должно сравниться с каждой строкой, возвращенной этой функцией. SQL Server не может даже просто просканировать таблицу, ему необходимо выполнить LEFT для каждой строки. Однако, вы можете сделать нечто вроде этого:
И вот мы видим совершенно другой план выполнения:

Для выполнения запроса требуется 3 операции чтения и 0 миллисекунд. Ну или пусть будет 1 миллисекунда, для объективности. Это огромный прирост производительности. А все потому что я использовал такую функцию, которая может быть использована для поиска по индексу(ранее это называлось sargeable – непереводимое, в общем-то, слово: SARG – Search Arguments –able, если функция SARGeable – в нее можно передавать столбец в качестве аргумента и все равно будет использоваться Index Seek, если не SARGeable – увы, всегда будет использоваться Index Scan — прим. переводчика). В любом случае, не используйте функции в выражениях WHERE или условиях поиска, либо используйте только те, которые могут быть использованы в условиях поиска по индексу.
Multi-statement UDF в русской редакции msdn переводится примерно как «Функции, определяемые пользователем, состоящие из нескольких инструкций, но звучит это, на мой взгляд, как-то странно, поэтому в заголовке и дальше по тексту я старался избегать перевода этого термина — прим. переводчика
По сути, они загоняют вас в ловушку. На первый взгляд, этот чудесный механизм позволяет нам использовать T-SQL как настоящий язык программирования. Вы можете создавать эти функции и вызывать их одну из другой и код можно будет использовать повторно, не то что эти старые хранимые процедуры. Это восхитительно. До тех пор пока вы не попробуете запустить этот код на большом объеме данных.
Проблема с этими функциями заключается в том, что они строятся на табличных переменных. Табличные переменные – это очень крутая штука, если вы используете их по назначению. У них есть одно явное отличие от временных таблиц – по ним не строится статистика. Это отличие может быть очень полезным, а может … убить вас. Если у вас нет статистики, оптимизатор предполагает, что любой запрос, выполняющийся к табличной переменной или UDF, возвратит всего одну строку. Одну (1) строку. Это хорошо, если они действительно возвращают несколько строк. Но, однажды они возвратят сотни или тысячи строк и вы решите соединить одну UDF с другой… Производительность упадет очень-очень быстро и очень-очень сильно.
Пример достаточно велик. Вот несколько UDF:
Отличная структура. Она позволяет составлять очень простые запросы. Ну, например, вот:
Один, очень простой запрос. Вот его план выполнения, так же очень простой:

Вот только выполняется он 2,17 секунды, возвращает 148 строк и использует 1456 операций чтения. Обратите внимание, что наша функция имеет нулевую стоимость и только сканирование таблицы, табличной переменной, влияет на стоимость запроса. Хм, правда что ли? Попробуем посмотреть что скрывается за оператором выполнения UDF с нулевой стоимостью. Этот запрос достанет план выполнения функции из кэша:
И вот что там происходит на самом деле:

Ого, похоже здесь скрывается еще несколько этих маленьких функций и сканов таблиц, которые почти, но все-таки не совсем, ничего не стоят. Плюс оператор соединения Hash Match, который пишет в tempdb и имеет немалую стоимость при выполнении. Давайте посмотрим план выполнения еще одной из UDF:

Вот! А теперь мы видим Clustered Index Scan, при котором сканируется большое число строк. Это уже не здорово. Вообще, во всей этой ситуации, UDF кажутся все менее и менее привлекательными. Что если мы, ну, я прямо не знаю, просто попробуем напрямую обратиться к таблицам. Вот так, например:
Теперь, выполнив этот запрос, мы получим абсолютно те же самые данные, но всего за 310 миллисекунд, а не за 2170. Плюс, SQL Server выполнит всего 911 операций чтения, а не 1456. Честно говоря, очень просто получить проблемы с производительностью, используя UDF
Возвращаясь в прошлое, к старым компьютерам с 286-ми процессорами на борту, можно вспомнить, что по ряду причин, на передней панели у них располагалась кнопка «Turbo». Если вы случайно «отжимали» ее, то компьютер сразу же начинал безумно тормозить. Таким образом, вы поняли, что некоторые вещи всегда должны быть включены, чтобы обеспечить максимальную пропускную способность. Точно так же, многие люди смотрят на уровень изоляции READ_UNCOMMITTED и хинт NO_LOCK, как на турбо-кнопку для SQL Server. При их использовании, будьте уверены – практически любой запрос и вся система в целом станут быстрее. Это связано с тем, что при чтении не будут накладываться и проверяться никакие блокировки. Меньше блокировок – быстрее результат. Но…
Когда вы используете READ_UNCOMMITTED или NO_LOCK в своих запросах, вы сталкиваетесь с грязными чтениями. Все понимают, что это означает, что вы можете прочитать «собака» а не «кошка», если в этот момент выполняется, но еще не завершилась операция обновления. Но, кроме этого, вы можете получить большее или меньшее количество строк, чем есть на самом деле, а так же дубликаты строк, поскольку страницы данных могут перемещаться во время выполнения вашего запроса, а вы не накладываете никаких блокировок, чтобы избежать этого. Не знаю как у вас, но в большинстве компаний в которых я работал, ожидали, что большая часть запросов на большинстве систем будут возвращать целостные данные. Один и тот же запрос с одними и теми же параметрами, выполняемый к одному и тому же множеству данных, должен давать один и тот же результат. Только не в том случае, если вы используете NO_LOCK. Для того, чтобы убедиться в этом я советую вам прочесть этот пост.
Люди слишком поспешно принимают решение об использовании хинтов. Наиболее часто встречающаяся ситуация – это когда хинт помогает решить одну, очень редко встречающуюся проблему, на одном из запросов. Но, когда люди видят значительный прирост производительности на этом запросе … они немедленно начинают совать его вообще везде.
Например, множество людей считает, что LOOP JOIN – это лучший способ соединения таблиц. Они приходят к такому выводу, поскольку он наиболее часто встречается в небольших и быстрых запросах. Поэтому они решают принудительно заставить SQL Server использовать именно LOOP JOIN. Это совсем не сложно:
Этот запрос выполняется 101 миллисекунду и совершает 4115 операций чтений. В общем-то неплохо, но если мы уберем этот хинт, тот же самый запрос выполнится за 90 миллисекунд и произведет всего 2370 чтений. Чем более загружена будет система, тем более очевидной будет эффективность запроса без использования хинта.
А вот еще один пример. Люди часто создают индекс на таблице, ожидая, что он решит проблему. Итак, у нас есть запрос:
Проблема опять-таки в том, что когда вы выполняете преобразование столбца, ни один индекс не будет адекватно использоваться. Производительность падает, поскольку выполняется сканирование кластерного индекса. И вот, когда люди видят, что их индекс не используется, они делают вот что:
И теперь они получают сканирование выбранного ими, а не кластерного, индекса, так что индекс «используется», правда ведь? Но вот производительность запроса изменяется – теперь вместо 11 операций чтения выполняется 44 (время выполнения у обоих около 0 миллисекунд, поскольку у меня реально быстрые диски). «Использоваться»-то он используется, но совсем не так как предполагалось. Решение этой проблемы заключается в том, чтобы переписать запрос таким образом:
Теперь количество операций чтения упало до двух, поскольку используется поиск по индексу – индекс используется правильно.
Хинты в запросах всегда должны применяться в последнюю очередь, после того как все остальные возможные варианты были опробованы и не дали положительного результата.
Построчная обработка производится при использовании курсоров или операций в WHILE-цикле, вместо операций над множествами. При их использовании производительность очень и очень низкая. Курсоры обычно используются по двум причинам. Первая из них – это разработчики, привыкшие использовать построчную обработку в своем коде, а вторая – разработчики пришедшие с Oracle, считающие, что курсоры – хорошая штука. Какая бы не была причина, курсоры – убивают производительность на корню.
Вот типичный пример неудачного использования курсора. Нам надо обновить цвет продуктов, выбранных по определенному критерию. Он не выдуман – он базируется на коде, который мне однажды пришлось оптимизировать.
В каждой итерации мы совершаем две операции чтения, а количество продукции, отвечающей нашим критериям, исчисляется сотнями. На моей машине, без нагрузки, время выполнения составляет больше секунды. Это совершенно неприемлемо, тем более что переписать этот запрос очень просто:
Теперь выполняется всего 15 операций чтения и время выполнения составляет всего 1 миллисекунду. Не смейтесь. Люди часто пишут такой код и даже хуже. Курсоры – это такая штука, которую следует избегать и использовать только там, где без них нельзя обойтись – например в задачах обслуживания, где вам надо «пробегать» по разным таблицам или базам данных.
Представления, ссылающиеся на представления, соединяющиеся с представлениями, ссылающимися на другие представления, соединяющиеся с представлениями… Представление – это всего лишь запрос. Но, поскольку с ними можно обращаться как с таблицами, люди могут начать думать о них как о таблицах. А зря. Что происходит, когда вы соединяете одно представление с другим, ссылающееся на третье представление и так далее? Вы всего лишь создаете чертовски сложный план выполнения запроса. Оптимизатор попробует упростить его. Он будет пробовать планы, в которых используются не все таблицы, но, время на работу по выбору плана ограничено и чем более сложный план он получит, тем меньше вероятность того, что в итоге у него получится достаточно простой план выполнения. И проблемы с производительностью будут практически неизбежны.
Вот, например, последовательность простых запросов, определяющих представления:
А вот здесь автор текста забыл указать запрос, но он приводит его в комментариях (прим. переводчика):
В итоге наш запрос выполняется 155 миллисекунд и использует 965 операций чтения. Вот его план выполнения:
Выглядит неплохо, тем более, что мы получаем 7000 строк, так что вроде бы все в порядке. Но что, если мы попробуем выполнить вот такой запрос:
А теперь запрос выполняется за 3 миллисекунды и использует 685 операций чтения – довольно-таки сильно отличается. И вот его план выполнения:

Как вы можете убедиться, оптимизатор не в силах выкинуть все лишние таблицы в рамках процесса упрощения запроса. Поэтому, в первом плане выполнения есть две лишние операции – Index Scan и Hash Match, собирающий данные воедино. Вы могли бы избавить SQL Server от лишней работы, написав этот запрос без использования представлений. И помните – этот пример очень прост, большинство запросов в реальной жизни намного сложнее и приводят к гораздо большим проблемам производительности.
В комментариях к этой статье есть небольшой спор, суть которого в том, что Грант (автор статьи), похоже выполнял свои запросы не на стандартной базе AdventureWorks, а на похожей БД, но с несколько иной структурой, из-за чего план выполнения „неоптимального“ запроса, приведенного в последнем разделе, отличается от того, что можно увидеть, проводя эксперимент самостоятельно. Прим. переводчика.
Если где-то я был излишне косноязычен (а я это могу) и текст труден для понимания, или вы можете мне предложить лучшую формулировку чего бы то ни было — с радостью выслушаю все замечения.
Существует три базовых правила для написания такого T-SQL кода, который будет работать хорошо. Они кумулятивные – выполнение всех этих правил окажет положительное влияние на код. Пропуск или изменение любого из них – скорее всего приведет к отрицательному влиянию на производительность вашего кода.
- Пишите, исходя из структуры хранения данных: если вы храните данные типа datetime, используйте именно datetime, а не varchar или что-нибудь еще.
- Пишите, исходя из наличия индексов: если на таблице построены индексы, и они должны там быть, пишите код так, чтобы он мог использовать все преимущества, предоставляемые этими индексами. Убедитесь, что кластерный индекс, а для каждой таблицы он может быть только один, используется наиболее эффективным образом.
- Пишите так, чтобы помочь оптимизатору запросов: оптимизатор запросов – восхитительная часть СУБД. К сожалению, вы можете сильно затруднить ему работу, написав запрос, который ему «тяжело» будет разбирать, например, содержащий вложенные представления – когда одно представление получает данные из другого, а то из третьего – и так далее. Потратьте свое время для того, чтобы понять как работает оптимизатор и писать запросы таким образом, чтобы он мог вам помочь, а не навредить.
Существует несколько типичных ошибок, которые люди допускают в своем коде на T-SQL – не совершайте их.
Использование неправильных типов данных
В теории избежать этой ошибки очень просто, но вот на практике она довольно часто встречается. Например, вы используете какой-либо тип данных в своей базе данных. Используйте его же в своих параметрах и переменных! Да, я знаю, что SQL Server может неявно приводить один тип данных к другому. Но, когда происходит неявное преобразование типа, или же вы сами приводите тип данных столбца к другому типу, вы выполняете преобразование для всего столбца. Когда вы выполняете это преобразование для столбца в выражении WHERE или же в условии соединения – вы всегда будете видеть сканирование таблицы (table scan). По этому столбцу может быть построен превосходный индекс, но поскольку вы делаете CAST для значений, хранящихся в этом столбце, чтобы сравнить, например дату, хранящуюся в этом столбце, с типом char, который вы использовали в условии, индекс не будет использоваться.
Не верите? Давайте посмотрим на этот запрос:
SELECT e.BusinessEntityID,
e.NationalIDNumber
FROM HumanResources.Employee AS e
WHERE e.NationalIDNumber = 112457891;
Хорошо написан и очень прост. Он должен покрываться индексом, созданным на этой таблице. Но вот план выполнения:

Этот запрос выполняется достаточно быстро и таблица невелика, так что только четыре операции чтения потребуются, чтобы просканировать индекс. Обратите внимание на небольшой восклицательный знак на операторе SELECT. Если обратиться к его свойствам, мы увидим:

Правильно. Это предупреждение (новое в SQL Server 2012) о том, что выполняется преобразование типов, влияющее на план выполнения. Вкратце – это потому, что в запросе используется неверный тип данных:
SELECT e.BusinessEntityID,
e.NationalIDNumber
FROM HumanResources.Employee AS e
WHERE e.NationalIDNumber = '112457891';
И мы получаем вот такой план выполнения запроса:

И здесь используются только две операции чтения, вместо четырех. И да, я понимаю, что сделал и так быстро выполняющийся запрос чуть-чуть более быстрым. Но что было бы, если бы в таблице хранились миллионы строк? Ага, тогда-то я стал бы героем.
Используйте правильные типы данных.
Использование функций при составлении условий соединения и в выражениях WHERE
Говоря о функциях – большинство из функций, использующихся в условиях соединения или выражениях WHERE, которым вы, в качестве аргумента, передаете столбец, мешают правильному использованию индексов. Вы увидите насколько медленнее выполняются запросы, в которых используются функции, получающие в качестве аргументов, столбцы. Вот например:
SELECT a.AddressLine1,
a.AddressLine2,
a.City,
a.StateProvinceID
FROM Person.Address AS a
WHERE '4444' = LEFT(a.AddressLine1, 4) ;
Эта функция, LEFT, получает в качестве аргумента столбец, что выливается в этот план выполнения:

В результате, осуществляется 316 операций чтения, чтобы найти нужные данные, и это занимает 9 миллисекунд (у меня очень быстрые диски). Все потому что ‘4444’ должно сравниться с каждой строкой, возвращенной этой функцией. SQL Server не может даже просто просканировать таблицу, ему необходимо выполнить LEFT для каждой строки. Однако, вы можете сделать нечто вроде этого:
SELECT a.AddressLine1,
a.AddressLine2,
a.City,
a.StateProvinceID
FROM Person.Address AS a
WHERE a.AddressLine1 LIKE '4444%' ;
И вот мы видим совершенно другой план выполнения:

Для выполнения запроса требуется 3 операции чтения и 0 миллисекунд. Ну или пусть будет 1 миллисекунда, для объективности. Это огромный прирост производительности. А все потому что я использовал такую функцию, которая может быть использована для поиска по индексу(ранее это называлось sargeable – непереводимое, в общем-то, слово: SARG – Search Arguments –able, если функция SARGeable – в нее можно передавать столбец в качестве аргумента и все равно будет использоваться Index Seek, если не SARGeable – увы, всегда будет использоваться Index Scan — прим. переводчика). В любом случае, не используйте функции в выражениях WHERE или условиях поиска, либо используйте только те, которые могут быть использованы в условиях поиска по индексу.
Использование Multi-statement UDF
Multi-statement UDF в русской редакции msdn переводится примерно как «Функции, определяемые пользователем, состоящие из нескольких инструкций, но звучит это, на мой взгляд, как-то странно, поэтому в заголовке и дальше по тексту я старался избегать перевода этого термина — прим. переводчика
По сути, они загоняют вас в ловушку. На первый взгляд, этот чудесный механизм позволяет нам использовать T-SQL как настоящий язык программирования. Вы можете создавать эти функции и вызывать их одну из другой и код можно будет использовать повторно, не то что эти старые хранимые процедуры. Это восхитительно. До тех пор пока вы не попробуете запустить этот код на большом объеме данных.
Проблема с этими функциями заключается в том, что они строятся на табличных переменных. Табличные переменные – это очень крутая штука, если вы используете их по назначению. У них есть одно явное отличие от временных таблиц – по ним не строится статистика. Это отличие может быть очень полезным, а может … убить вас. Если у вас нет статистики, оптимизатор предполагает, что любой запрос, выполняющийся к табличной переменной или UDF, возвратит всего одну строку. Одну (1) строку. Это хорошо, если они действительно возвращают несколько строк. Но, однажды они возвратят сотни или тысячи строк и вы решите соединить одну UDF с другой… Производительность упадет очень-очень быстро и очень-очень сильно.
Пример достаточно велик. Вот несколько UDF:
CREATE FUNCTION dbo.SalesInfo ()
RETURNS @return_variable TABLE
(
SalesOrderID INT,
OrderDate DATETIME,
SalesPersonID INT,
PurchaseOrderNumber dbo.OrderNumber,
AccountNumber dbo.AccountNumber,
ShippingCity NVARCHAR(30)
)
AS
BEGIN;
INSERT INTO @return_variable
(SalesOrderID,
OrderDate,
SalesPersonID,
PurchaseOrderNumber,
AccountNumber,
ShippingCity
)
SELECT soh.SalesOrderID,
soh.OrderDate,
soh.SalesPersonID,
soh.PurchaseOrderNumber,
soh.AccountNumber,
a.City
FROM Sales.SalesOrderHeader AS soh
JOIN Person.Address AS a
ON soh.ShipToAddressID = a.AddressID ;
RETURN ;
END ;
GO
CREATE FUNCTION dbo.SalesDetails ()
RETURNS @return_variable TABLE
(
SalesOrderID INT,
SalesOrderDetailID INT,
OrderQty SMALLINT,
UnitPrice MONEY
)
AS
BEGIN;
INSERT INTO @return_variable
(SalesOrderID,
SalesOrderDetailId,
OrderQty,
UnitPrice
)
SELECT sod.SalesOrderID,
sod.SalesOrderDetailID,
sod.OrderQty,
sod.UnitPrice
FROM Sales.SalesOrderDetail AS sod ;
RETURN ;
END ;
GO
CREATE FUNCTION dbo.CombinedSalesInfo ()
RETURNS @return_variable TABLE
(
SalesPersonID INT,
ShippingCity NVARCHAR(30),
OrderDate DATETIME,
PurchaseOrderNumber dbo.OrderNumber,
AccountNumber dbo.AccountNumber,
OrderQty SMALLINT,
UnitPrice MONEY
)
AS
BEGIN;
INSERT INTO @return_variable
(SalesPersonId,
ShippingCity,
OrderDate,
PurchaseOrderNumber,
AccountNumber,
OrderQty,
UnitPrice
)
SELECT si.SalesPersonID,
si.ShippingCity,
si.OrderDate,
si.PurchaseOrderNumber,
si.AccountNumber,
sd.OrderQty,
sd.UnitPrice
FROM dbo.SalesInfo() AS si
JOIN dbo.SalesDetails() AS sd
ON si.SalesOrderID = sd.SalesOrderID ;
RETURN ;
END ;
GO
Отличная структура. Она позволяет составлять очень простые запросы. Ну, например, вот:
SELECT csi.OrderDate,
csi.PurchaseOrderNumber,
csi.AccountNumber,
csi.OrderQty,
csi.UnitPrice
FROM dbo.CombinedSalesInfo() AS csi
WHERE csi.SalesPersonID = 277
AND csi.ShippingCity = 'Odessa' ;
Один, очень простой запрос. Вот его план выполнения, так же очень простой:
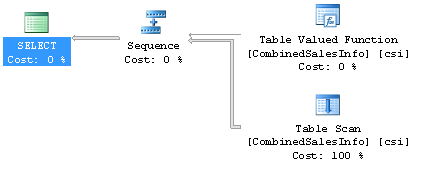
Вот только выполняется он 2,17 секунды, возвращает 148 строк и использует 1456 операций чтения. Обратите внимание, что наша функция имеет нулевую стоимость и только сканирование таблицы, табличной переменной, влияет на стоимость запроса. Хм, правда что ли? Попробуем посмотреть что скрывается за оператором выполнения UDF с нулевой стоимостью. Этот запрос достанет план выполнения функции из кэша:
SELECT deqp.query_plan,
dest.text,
SUBSTRING(dest.text, (deqs.statement_start_offset / 2) + 1,
(deqs.statement_end_offset - deqs.statement_start_offset)
/ 2 + 1) AS actualstatement
FROM sys.dm_exec_query_stats AS deqs
CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp
CROSS APPLY sys.dm_exec_sql_text(deqs.sql_handle) AS dest
WHERE deqp.objectid = OBJECT_ID('dbo.CombinedSalesInfo');
И вот что там происходит на самом деле:

Ого, похоже здесь скрывается еще несколько этих маленьких функций и сканов таблиц, которые почти, но все-таки не совсем, ничего не стоят. Плюс оператор соединения Hash Match, который пишет в tempdb и имеет немалую стоимость при выполнении. Давайте посмотрим план выполнения еще одной из UDF:

Вот! А теперь мы видим Clustered Index Scan, при котором сканируется большое число строк. Это уже не здорово. Вообще, во всей этой ситуации, UDF кажутся все менее и менее привлекательными. Что если мы, ну, я прямо не знаю, просто попробуем напрямую обратиться к таблицам. Вот так, например:
SELECT soh.OrderDate,
soh.PurchaseOrderNumber,
soh.AccountNumber,
sod.OrderQty,
sod.UnitPrice
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
JOIN Person.Address AS ba
ON soh.BillToAddressID = ba.AddressID
JOIN Person.Address AS sa
ON soh.ShipToAddressID = sa.AddressID
WHERE soh.SalesPersonID = 277
AND sa.City = 'Odessa' ;
Теперь, выполнив этот запрос, мы получим абсолютно те же самые данные, но всего за 310 миллисекунд, а не за 2170. Плюс, SQL Server выполнит всего 911 операций чтения, а не 1456. Честно говоря, очень просто получить проблемы с производительностью, используя UDF
Включение настройки «Работай быстрее!»: использование «Грязных чтений»
Возвращаясь в прошлое, к старым компьютерам с 286-ми процессорами на борту, можно вспомнить, что по ряду причин, на передней панели у них располагалась кнопка «Turbo». Если вы случайно «отжимали» ее, то компьютер сразу же начинал безумно тормозить. Таким образом, вы поняли, что некоторые вещи всегда должны быть включены, чтобы обеспечить максимальную пропускную способность. Точно так же, многие люди смотрят на уровень изоляции READ_UNCOMMITTED и хинт NO_LOCK, как на турбо-кнопку для SQL Server. При их использовании, будьте уверены – практически любой запрос и вся система в целом станут быстрее. Это связано с тем, что при чтении не будут накладываться и проверяться никакие блокировки. Меньше блокировок – быстрее результат. Но…
Когда вы используете READ_UNCOMMITTED или NO_LOCK в своих запросах, вы сталкиваетесь с грязными чтениями. Все понимают, что это означает, что вы можете прочитать «собака» а не «кошка», если в этот момент выполняется, но еще не завершилась операция обновления. Но, кроме этого, вы можете получить большее или меньшее количество строк, чем есть на самом деле, а так же дубликаты строк, поскольку страницы данных могут перемещаться во время выполнения вашего запроса, а вы не накладываете никаких блокировок, чтобы избежать этого. Не знаю как у вас, но в большинстве компаний в которых я работал, ожидали, что большая часть запросов на большинстве систем будут возвращать целостные данные. Один и тот же запрос с одними и теми же параметрами, выполняемый к одному и тому же множеству данных, должен давать один и тот же результат. Только не в том случае, если вы используете NO_LOCK. Для того, чтобы убедиться в этом я советую вам прочесть этот пост.
Необоснованное использование хинтов в запросах
Люди слишком поспешно принимают решение об использовании хинтов. Наиболее часто встречающаяся ситуация – это когда хинт помогает решить одну, очень редко встречающуюся проблему, на одном из запросов. Но, когда люди видят значительный прирост производительности на этом запросе … они немедленно начинают совать его вообще везде.
Например, множество людей считает, что LOOP JOIN – это лучший способ соединения таблиц. Они приходят к такому выводу, поскольку он наиболее часто встречается в небольших и быстрых запросах. Поэтому они решают принудительно заставить SQL Server использовать именно LOOP JOIN. Это совсем не сложно:
SELECT s.[Name] AS StoreName,
p.LastName + ', ' + p.FirstName
FROM Sales.Store AS s
JOIN sales.SalesPerson AS sp
ON s.SalesPersonID = sp.BusinessEntityID
JOIN HumanResources.Employee AS e
ON sp.BusinessEntityID = e.BusinessEntityID
JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID
OPTION (LOOP JOIN);
Этот запрос выполняется 101 миллисекунду и совершает 4115 операций чтений. В общем-то неплохо, но если мы уберем этот хинт, тот же самый запрос выполнится за 90 миллисекунд и произведет всего 2370 чтений. Чем более загружена будет система, тем более очевидной будет эффективность запроса без использования хинта.
А вот еще один пример. Люди часто создают индекс на таблице, ожидая, что он решит проблему. Итак, у нас есть запрос:
SELECT *
FROM Purchasing.PurchaseOrderHeader AS poh
WHERE poh.PurchaseOrderID * 2 = 3400;
Проблема опять-таки в том, что когда вы выполняете преобразование столбца, ни один индекс не будет адекватно использоваться. Производительность падает, поскольку выполняется сканирование кластерного индекса. И вот, когда люди видят, что их индекс не используется, они делают вот что:
SELECT *
FROM Purchasing.PurchaseOrderHeader AS poh WITH (INDEX (PK_PurchaseOrderHeader_PurchaseOrderID))
WHERE poh.PurchaseOrderID * 2 = 3400;
И теперь они получают сканирование выбранного ими, а не кластерного, индекса, так что индекс «используется», правда ведь? Но вот производительность запроса изменяется – теперь вместо 11 операций чтения выполняется 44 (время выполнения у обоих около 0 миллисекунд, поскольку у меня реально быстрые диски). «Использоваться»-то он используется, но совсем не так как предполагалось. Решение этой проблемы заключается в том, чтобы переписать запрос таким образом:
SELECT *
FROM Purchasing.PurchaseOrderHeader poh
WHERE PurchaseOrderID = 3400 / 2;
Теперь количество операций чтения упало до двух, поскольку используется поиск по индексу – индекс используется правильно.
Хинты в запросах всегда должны применяться в последнюю очередь, после того как все остальные возможные варианты были опробованы и не дали положительного результата.
Использование построчной обработки результата выполнения запроса (‘Row by Agonizing Row’ processing)
Построчная обработка производится при использовании курсоров или операций в WHILE-цикле, вместо операций над множествами. При их использовании производительность очень и очень низкая. Курсоры обычно используются по двум причинам. Первая из них – это разработчики, привыкшие использовать построчную обработку в своем коде, а вторая – разработчики пришедшие с Oracle, считающие, что курсоры – хорошая штука. Какая бы не была причина, курсоры – убивают производительность на корню.
Вот типичный пример неудачного использования курсора. Нам надо обновить цвет продуктов, выбранных по определенному критерию. Он не выдуман – он базируется на коде, который мне однажды пришлось оптимизировать.
BEGIN TRANSACTION
DECLARE @Name NVARCHAR(50) ,
@Color NVARCHAR(15) ,
@Weight DECIMAL(8, 2)
DECLARE BigUpdate CURSOR
FOR SELECT p.[Name]
,p.Color
,p.[Weight]
FROM Production.Product AS p ;
OPEN BigUpdate ;
FETCH NEXT FROM BigUpdate INTO @Name, @Color, @Weight ;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @Weight < 3
BEGIN
UPDATE Production.Product
SET Color = 'Blue'
WHERE CURRENT OF BigUpdate
END
FETCH NEXT FROM BigUpdate INTO @Name, @Color, @Weight ;
END
CLOSE BigUpdate ;
DEALLOCATE BigUpdate ;
SELECT *
FROM Production.Product AS p
WHERE Color = 'Blue' ;
ROLLBACK TRANSACTION
В каждой итерации мы совершаем две операции чтения, а количество продукции, отвечающей нашим критериям, исчисляется сотнями. На моей машине, без нагрузки, время выполнения составляет больше секунды. Это совершенно неприемлемо, тем более что переписать этот запрос очень просто:
BEGIN TRANSACTION
UPDATE Production.Product
SET Color = 'BLUE'
WHERE [Weight] < 3 ;
ROLLBACK TRANSACTION
Теперь выполняется всего 15 операций чтения и время выполнения составляет всего 1 миллисекунду. Не смейтесь. Люди часто пишут такой код и даже хуже. Курсоры – это такая штука, которую следует избегать и использовать только там, где без них нельзя обойтись – например в задачах обслуживания, где вам надо «пробегать» по разным таблицам или базам данных.
Необоснованное использование вложенных представлений
Представления, ссылающиеся на представления, соединяющиеся с представлениями, ссылающимися на другие представления, соединяющиеся с представлениями… Представление – это всего лишь запрос. Но, поскольку с ними можно обращаться как с таблицами, люди могут начать думать о них как о таблицах. А зря. Что происходит, когда вы соединяете одно представление с другим, ссылающееся на третье представление и так далее? Вы всего лишь создаете чертовски сложный план выполнения запроса. Оптимизатор попробует упростить его. Он будет пробовать планы, в которых используются не все таблицы, но, время на работу по выбору плана ограничено и чем более сложный план он получит, тем меньше вероятность того, что в итоге у него получится достаточно простой план выполнения. И проблемы с производительностью будут практически неизбежны.
Вот, например, последовательность простых запросов, определяющих представления:
CREATE VIEW dbo.SalesInfoView
AS
SELECT soh.SalesOrderID,
soh.OrderDate,
soh.SalesPersonID,
soh.PurchaseOrderNumber,
soh.AccountNumber,
a.City AS ShippingCity
FROM Sales.SalesOrderHeader AS soh
JOIN Person.Address AS a
ON soh.ShipToAddressID = a.AddressID ;
CREATE VIEW dbo.SalesDetailsView
AS
SELECT sod.SalesOrderID,
sod.SalesOrderDetailID,
sod.OrderQty,
sod.UnitPrice
FROM Sales.SalesOrderDetail AS sod ;
CREATE VIEW dbo.CombinedSalesInfoView
AS
SELECT si.SalesPersonID,
si.ShippingCity,
si.OrderDate,
si.PurchaseOrderNumber,
si.AccountNumber,
sd.OrderQty,
sd.UnitPrice
FROM dbo.SalesInfoView AS si
JOIN dbo.SalesDetailsView AS sd
ON si.SalesOrderID = sd.SalesOrderID ;
А вот здесь автор текста забыл указать запрос, но он приводит его в комментариях (прим. переводчика):
SELECT csi.OrderDate
FROM dbo. CominedSalesInfoView csi
WHERE csi.SalesPersonID = 277
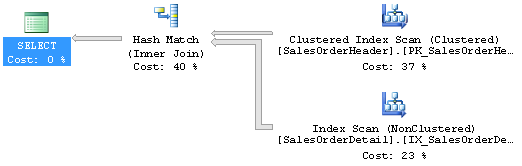
В итоге наш запрос выполняется 155 миллисекунд и использует 965 операций чтения. Вот его план выполнения:

Выглядит неплохо, тем более, что мы получаем 7000 строк, так что вроде бы все в порядке. Но что, если мы попробуем выполнить вот такой запрос:
SELECT soh.OrderDate
FROM Sales.SalesOrderHeader AS soh
WHERE soh.SalesPersonID = 277 ;
А теперь запрос выполняется за 3 миллисекунды и использует 685 операций чтения – довольно-таки сильно отличается. И вот его план выполнения:

Как вы можете убедиться, оптимизатор не в силах выкинуть все лишние таблицы в рамках процесса упрощения запроса. Поэтому, в первом плане выполнения есть две лишние операции – Index Scan и Hash Match, собирающий данные воедино. Вы могли бы избавить SQL Server от лишней работы, написав этот запрос без использования представлений. И помните – этот пример очень прост, большинство запросов в реальной жизни намного сложнее и приводят к гораздо большим проблемам производительности.
В комментариях к этой статье есть небольшой спор, суть которого в том, что Грант (автор статьи), похоже выполнял свои запросы не на стандартной базе AdventureWorks, а на похожей БД, но с несколько иной структурой, из-за чего план выполнения „неоптимального“ запроса, приведенного в последнем разделе, отличается от того, что можно увидеть, проводя эксперимент самостоятельно. Прим. переводчика.
Если где-то я был излишне косноязычен (а я это могу) и текст труден для понимания, или вы можете мне предложить лучшую формулировку чего бы то ни было — с радостью выслушаю все замечения.
