Если вы давно разрабатываете многопоточные приложения, наверняка вы сталкивались с распараллеливанием уже существующего последовательного кода. Или наоборот, вы новичок в параллельном программировании, а перед вами встали задачи оптимизации проекта и улучшения масштабируемости, которые тоже могут быть решены путём распараллеливания отдельных участков программы.
Новый инструмент Intel Advisor XE поможет вам распараллелить приложение, потратив на это минимум сил и времени.
Advisor XE вышел в свет в сентябре этого года в составе пакета для разработчиков Intel Parallel Studio XE 2013. Дословный перевод названия – «советчик» — довольно ёмко описывает его предназначение. Инструмент помогает программисту проанализировать возможности распараллеливания кода: найти наиболее подходящие для этого участки и оценить предполагаемый полезный эффект – а стоит ли вообще за это браться? Кроме того, Advisor XE подскажет, где могут возникнуть ошибки, такие как гонки данных. И всё этого без реальной модификации программы! Но обо всём по порядку.
Advisor XE выпускается для Windows* и Linux* и работает с языками C++, C# и Fortran. В этом посте я буду пользоваться версией под Windows* — в ней есть удобная интеграция в Microsoft Visual Studio* (для желающих есть и собственный интерфейс без интеграции). В качестве примера я взял программу Tachyon, входящую в набор примеров Advisor XE. Она осуществляет 2D рендеринг и трассировку лучей, выдавая такую картинку:

В Visual Studio Advisor XE добавляет свою панель инструментов, предоставляющую быстрый доступ к его функциям. Итак, открываем свой проект, строим его в режиме «Release» и открываем “Advisor XE Workflow”:

Advisor XE Workflow проводит разработчика через пять этапов оценки приложения, после которых он сможет принять осмысленное решение, стоит ли распараллеливать этот код и в каком месте это лучше сделать.
Этап 1. Профилировка (Survey Target)
Первое, что делает Advisor XE – запускает ваше приложение и профилирует его, т.е. оценивает производительность и ищет «горячие точки» — функции, циклы и отдельные инструкции, потребляющие большую часть ресурсов процессора. Это нужно для того, чтобы сконцентрировать усилия на самых критичных для производительности участках, поскольку их распараллеливание принесёт наибольший эффект. Для начала профилировки нажимаем кнопку «Collect Survey Data» в окне Advisor XE Workflow:

Advisor XE запускает приложение, дожидается окончания работы и «финализирует» собранные данные. После этого пользователю предоставляется список функций и мест в коде в иерархическом виде, для каждого из которых отображается время CPU в секундах и процентах. Отдельно показано собственное время функции и время, включающее вложенные функции:

Те места, где «горячей точкой» является цикл, помечены специальным значком. Это удобно, т.к. циклы часто становятся объектом распараллеливания, если они, например, обрабатывают большие объёмы независимых данных.
Данные профилировки дают программисту первую оценку распределения нагрузки внутри приложения. Это позволяет сделать осмысленное, основанное на цифрах предположение о том, какие участки кода будет полезно распараллелить.
В нашем примере мы остановим выбор на самой верхней по стеку вызовов функции, содержащей цикл – parallel_thread. На неё (включая вложенные функции) приходится 80,9% затраченного процессорного времени. Кстати, двойной клик на «горячую» функцию переведёт вас к просмотру исходников, где тоже будет информация об использовании CPU, но уже для конкретных строк кода.
Этап 2. Аннотации (Annotate Sources)
Когда первое предположение о будущем внедрении многопоточности сделано, нужно сообщить об этом «советчику». Для этого используются так называемые аннотации – специальные макросы (или вызовы функций, в зависимости от языка), понятные Advisor-у, но не влияющие на функционирование вашей программы.
В Visual Studio аннотации добавляются с помощью контекстного меню – просто выделяете понравившийся блок кода и запускаете Annotation Wizard:

Аннотации Advisor XE бывают нескольких типов. Для моделирования распараллеливания цикла нам пригодятся два основных – “Annotate Site” и “Annotate Task”.
“Annotate Site” используется для отметки границ параллельного региона в коде. Для С++ она представлена макросами ANNOTATE_SITE_BEGIN и ANNOTATE_SITE_END. В нашем примере мы будем распараллеливать цикл for, разбивая пространство итераций на более мелкие порции, с тем, чтобы каждая такая порция могла исполняться параллельно с другими.
“Annotate Task” используется для разметки границ одной задачи, с помощью макросов ANNOTATE_TASK_BEGIN и ANNOTATE_TASK_END. Задачей считается блок кода, который может быть исполнен многократно разными потоками. Задачи исполняются параллельно с другими задачами и остальным кодом в параллельном регионе.
Итак, приступаем к разметке. Весь цикл for заключим в параллельный регион. А тело цикла обозначим как задачу, т.к. оно будет исполняться параллельно (в модели) над разными итерациями:
#include <advisor-annotate.h>
...
static void parallel_thread (void)
{
ANNOTATE_SITE_BEGIN(allRows);
for (int y = starty; y < stopy; y++)
{
ANNOTATE_TASK_BEGIN(eachRow);
m_storage.serial = 1;
m_storage.mboxsize = sizeof(unsigned int)*(max_objectid() + 20);
m_storage.local_mbox = (unsigned int *) malloc(m_storage.mboxsize);
memset(m_storage.local_mbox,0,m_storage.mboxsize);
drawing_area drawing(startx, totaly-y, stopx-startx, 1);
for (int x = startx; x < stopx; x++) {
color_t c = render_one_pixel (x, y, m_storage.local_mbox, m_storage.serial, startx, stopx, starty, stopy);
drawing.put_pixel(c);
}
if(!video->next_frame())
{
free(m_storage.local_mbox);
return;
}
free(m_storage.local_mbox);
ANNOTATE_TASK_END(eachRow);
}
ANNOTATE_SITE_END(allRows);
}
Чтобы С++ программа скомпилировалась с аннотациями, нужно подключить заголовочный файл advisor-annotate.h.
Этап 3. Проверка эффективности (Check Suitability)
На третьем шаге Advisor XE делает повторную профилировку. Отличие от первой профилировки состоит в том, что теперь собирается не информация о «горячих функциях», а моделируется параллельное исполнение приложения и оценивается его потенциальная скорость работы.
Исполняется программа точно так же, как и без аннотаций – в однопоточном режиме. Скорость работы и корректность результатов не страдают. Однако аннотации дают возможность инструменту смоделировать многопоточное исполнение аннотированного кода и выдать оценку эффективности в цифрах на суд программиста:

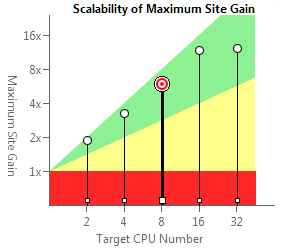
Результат оценки эффективности (или suitability анализа) даёт нам много интересной информации:
- Ускорение работы всей программы по сравнению с последовательным исполнением (в нашем примере 1,48х)
- Ускорение отдельного параллельного региона (в примере 7,88 на 8 ядрах)
- Оценка масштабируемости для 2-32 ядер процессора
- Детали о параллельных регионах и задачах (время исполнения, количество задач и т.д.)
Эту информацию можно получить для разного количества ядер, переключая соответствующий флажок. Т.е. даже работая на двухъядерном ноутбуке, вы можете оценить, как программа будет масштабироваться на многоядерном сервере.
Справедливости ради нужно сказать, что результаты далеко не всегда будут такими радужными. Может оказаться, что прогнозируемый положительный эффект от распараллеливания совсем не так высок, или вовсе нулевой. Но этот результат тоже будет полезным, т.к. вы убедитесь в неэффективности выбранного подхода, и будете искать другие пути. В этом и состоит предназначение Advisor XE – дать возможность попробовать множество подходов к распараллеливанию, потратив минимум сил и времени, и выбрать лучший.
Может случиться и так, что все испробованные подходы не дают приемлемого результата. Это может натолкнуть вас на мысль об изменении структуры кода таким образом, чтобы он легче распараллеливался. Пространных консультаций на этот счёт Advisor XE конечно не даст, но стоит обратить внимание на список подсказок – возможно, какая-то информация натолкнёт вас на правильные мысли.
Этап 4. Проверка корректности (Check Correctness)
Превращение однопоточной программы в многопоточную может привести к новым багам – таким как гонки данных. Чтобы облегчить верификацию и отладку в «живой» программе, Advisor XE позволяет провести оценку корректности смоделированного программистом решения. Для этого нужно перекомпилировать программу в режиме “Debug” и запустить проверку корректности Advisor XE – “Check Correctness”.
Проверка корректности замедлит выполнение программы, поскольку исполняемый файл подвергается бинарной инструментации, которая помогает Advisor XE отслеживать работу программы на предмет ошибок. Поэтому имеет смысл снизить нагрузку на приложение, если возможно – уменьшить размер входных данных, снизить частоту обновления фреймов и т.п.

В результате проверки появляется Correctness Report – отчёт об ошибках. Он включает в себя список ошибок, их тип, параллельный регион, в котором они проявляются. Кликнув два раза на ошибку можно перейти к просмотру исходников, где появляется дополнительная информация, например, стеки вызовов:

В нашем примере обнаружилась гонка данных – в функции video::next_frame() инкрементируется глобальная переменная g_updates. Пока на исполнение программы она не влияет, ведь в реальности код всё ещё однопоточный. Однако очевидно, что проблему надо будет устранять, и это скажется на производительности – могут появиться объекты синхронизации, сдерживающие масштабируемость, или наоборот, локализация переменных принесёт положительный эффект.
Чтобы это проверить, в Advisor XE есть ещё один тип аннотаций – “Lock Annotations”. Они используются для моделирования критических секций. В нашем примере g_updates модифицируется в функции video::next_frame(), вызов которого происходит в нашем распараллеливаемом цикле. Поэтому мы можем здесь же защитить её аннотациями синхронизации:
static void parallel_thread (void)
{
ANNOTATE_SITE_BEGIN(allRows);
for (int y = starty; y < stopy; y++)
{
ANNOTATE_TASK_BEGIN(eachRow);
m_storage.serial = 1;
m_storage.mboxsize = sizeof(unsigned int)*(max_objectid() + 20);
m_storage.local_mbox = (unsigned int *) malloc(m_storage.mboxsize);
memset(m_storage.local_mbox,0,m_storage.mboxsize);
drawing_area drawing(startx, totaly-y, stopx-startx, 1);
for (int x = startx; x < stopx; x++) {
color_t c = render_one_pixel (x, y, m_storage.local_mbox, m_storage.serial, startx, stopx, starty, stopy);
drawing.put_pixel(c);
}
ANNOTATE_LOCK_ACQUIRE(0);
if(!video->next_frame())
{
ANNOTATE_LOCK_RELEASE(0);
free(m_storage.local_mbox);
return;
}
ANNOTATE_LOCK_RELEASE(0);
free(m_storage.local_mbox);
ANNOTATE_TASK_END(eachRow);
}
ANNOTATE_SITE_END(allRows);
}
После проделанных изменений пересобираем программу и проверяем снова. Проверять можно и на предмет корректности – решена ли проблема, и на предмет производительности – каков будет эффект от распараллеливания с учётом наличия критической секции. В нашем примере введение критической секции на производительности почти не сказалось.
Этап 5. Реализация распараллеливания (Add Parallel Framework)
Последний этап распараллеливания кода – собственно распараллеливание, т.е. выбор потокового API, непосредственное кодирование и отладку. Этот шаг лишь условно включён в “workflow” Advisor XE, чтоб не забыть, так сказать. «Советчик» предназначен лишь для моделирования и предоставления разработчику аналитический информации, на основе которой тот будет чётче представлять себе, куда двигаться дальше – что и как стоит модифицировать, какого эффекта ждать и какие проблемы могут возникнуть. Дальше действовать придётся самому.
Но не надо унывать – в пакете Intel Parallel Studio XE есть ещё много инструментов, которые помогут на других этапах. Реализовать параллельный цикл по модели в приведённом примере можно с помощью множества высокоуровневых «параллельных фреймворков», которые позволяют абстрагироваться от самостоятельного создания потоков и распределения нагрузки между ними. Например, преобразовать последовательный цикл в параллельный можно с помощью Intel Cilk Plus. При этом потребуется использовать компилятор Intel. А в качестве примитива синхронизации можно взять tbb::spin_mutex из библиотеки Intel TBB. Код цикла (уже параллельного) при этом будет выглядеть так:
static void parallel_thread (void)
{
volatile bool continue_work = true;
cilk_for (int y = starty; y < stopy; y++)
{
if (continue_work) {
storage m_storage;
m_storage.serial = 1;
m_storage.mboxsize = sizeof(unsigned int)*(max_objectid() + 20);
m_storage.local_mbox = (unsigned int *) malloc(m_storage.mboxsize);
memset(m_storage.local_mbox,0,m_storage.mboxsize);
drawing_area drawing(startx, totaly-y, stopx-startx, 1);
for (int x = startx; x < stopx; x++) {
color_t c = render_one_pixel (x, y, m_storage.local_mbox, m_storage.serial, startx, stopx, starty, stopy);
drawing.put_pixel(c);
}
{
tbb::spin_mutex::scoped_lock lockUntilScopeExit(MyMutex);
if(!video->next_frame())
{
continue_work = false;
}
}
free (m_storage.local_mbox);
}
}
}
Выводы
Advisor XE будет полезен там, где уже есть работающий код, который нужно частично распараллелить. Например, есть старое научное приложение на Фортране, которое нужно оптимизировать для нового сервера или кластера. Основной плюс инструмента – возможность быстро смоделировать многопоточное исполнение. Проведя несколько экспериментов, можно определить участки кода, на которых стоит сконцентрировать усилия, и понять, чего от этого ждать – насколько распараллеливание может быть полезно, какой масштабируемости можно добиться. Проделать то же самое «по-настоящему», создавая потоки и перекраивая код, отнимет куда больше усилий.
Скачать пробную версию Intel Advisor XE можно с сайта продукта:
http://software.intel.com/en-us/intel-advisor-xe.
Intel Parallel Studio XE 2013:
http://software.intel.com/en-us/intel-parallel-studio-xe/
Intel Cilk Plus
http://software.intel.com/en-us/intel-cilk-plus-archive
Intel Threading Building Blocks
http://software.intel.com/en-us/intel-tbb
http://threadingbuildingblocks.org/
