В ходе разработки одного проекта на базе облачных услуг Amazon пришлось столкнуться с одной проблемой, описания которой в открытом доступе найти не удалось — значительные задержки при обращении к сервису Amazon RDS. Однако помочь разобраться с ней мне помогли знания в технологиях передачи данных, которые я получил в ходе работы в одном отраслевом НИИ.

Итак, сначала диагноз больного. Разрабатывается ИТ-система с клиентским приложением. Система представляет собой сервер, который размещается в облаке Amazon в виде сервиса EC2. Этот сервер взаимодействует с базой MySQL, которая стоит в том же регионе (US-west) на сервисе RDS (Relational Database Service). С сервером взаимодействует мобильное приложение, которое через сервер регистрируется, и загружает некоторые данные. В ходе работы этого приложения часто наблюдаются ошибки связи, на которые приложение выводит popup со словами Connection Error. При этом пользователи жалуются на медленную работу приложения. Такая ситуация возникает у пользователей и в США и в России.
Перенос всей системы на независимый хостинг (самый обычный, дешевый) привел к заметно более шустрой работе приложения, и отсутствию задержек Amazon RDS. Поиск по разным форумам ответа о причинах такого поведения не дал.
Для сбора временных характеристик процесса взаимодействия приложения с сервером и базой данных был написан скрипт, который делал запрос в базу данных MySQL 10 раз подряд. Чтобы исключить ситуацию кеширования запроса, в запрос была добавлена инструкция SQL_NO_CACHE. При этом база данных не кеширует такой запрос SELECT. Запрос и измерение его продолжительности осуществляется следующей функцией, которая меряет продолжительность транзакции с учетом сетевой задержки.
Этот скрипт был загружен на российский хостинг, и запущен. Результат получился такой (скрипт — Россия, СУБД — Amazon RDS, Калифорния).
Для сравнения — тоже самое, но с другой хостинговой площадки — во Франции (скрипт — Франция, СУБД — Amazon RDS, Калифорния).
Такая ситуация чрезвычайно удивила, и заставила покопаться в справочной информации о кешировании SQL-запросов. Но все изыскания говорили одно — скрипт написан корректно. Ситуация сложилась интересная. Вроде все понятно, но непонятна самая малость: а) что происходит, и б) как хотя бы сформулировать запрос в саппорт?
Хорошо. Следующий эксперимент — запуск этого скрипта локально, на сервере в том же Amazon дата-центре в Калифорнии. Наверняка серверы физически стоят рядом, и все должно происходить очень быстро. Пробуем (скрипт и СУБД — Amazon AWS, Калифорния).
Задержки сильно снизились, но в целом картина прежняя — первый запрос выполняется в разы дольше последующих. И думаю, что именно это причина всех проблем с конечным приложением. Ведь приложение обменивается с сервером информацией «в один запрос», который как раз приходиться на эту самую долгую операцию. Соответственно, именно эта операция и определяет все «тормознутость» приложения.
Чтобы проверить, что же все-таки мешает, база данных была мигрирована с Amazon RDS на отдельный хостинг (самый дешевый). И здесь ждал небольшой сюрприз — равную скорость выполнения первой и последующей транзакций (скрипт — Россия, СУБД — недорогой хостинг в США).
Немного отвлекусь — самая лучшая ситуация сложилась, когда на этот слабый, в общем-то хостинг, поставили еще и сам сервер (скрипт и СУБД — один и тот же недорогой хостинг на территории США).
Здесь можно заметить похожую ситуацию, но на единицах миллисекунд в действие уже вступают задержки ОС, а не сети. Поэтому не следует обращать на это внимание.
Но вернемся к нашей ситуации. Для чистоты эксперимента сделали еще один тест — запустили скрипт с этого дешевого хостинга на Amazon RDS. Результат — опять долгая первая транзакция (скрипт — хостинг США, СУБД — Amazon RDS, Калифорния).
Каких-то аналогов таким странностям ни мне, ни разработчикам в Интернете найти не удалось. Однако тем временем, глядя на эти цифры, у меня стало закладываться смутное подозрение, что ситуация вызвана не настройками ИТ-систем, а особенностью передачи данных в транспортной сети IP, которая связывает дата-центры Amazon.
Изложенные ниже соображения являются только моими предположениями, в которые показанные выше тайминги достаточно логично ложатся. Однако полной уверенности в этом у меня нет, и может быть, причины большой задержки иные, и лежат они на самом плаву. Было бы интересно послушать альтернативные мнения.
Итак, в телекоммуникационном мире в основе всех сетей связи лежит транспортный уровень, образованный протоколом IP. Для передачи пакетов IP через множество промежуточных маршрутизаторов используются, в общем случае, два метода, маршрутизация и коммутация.
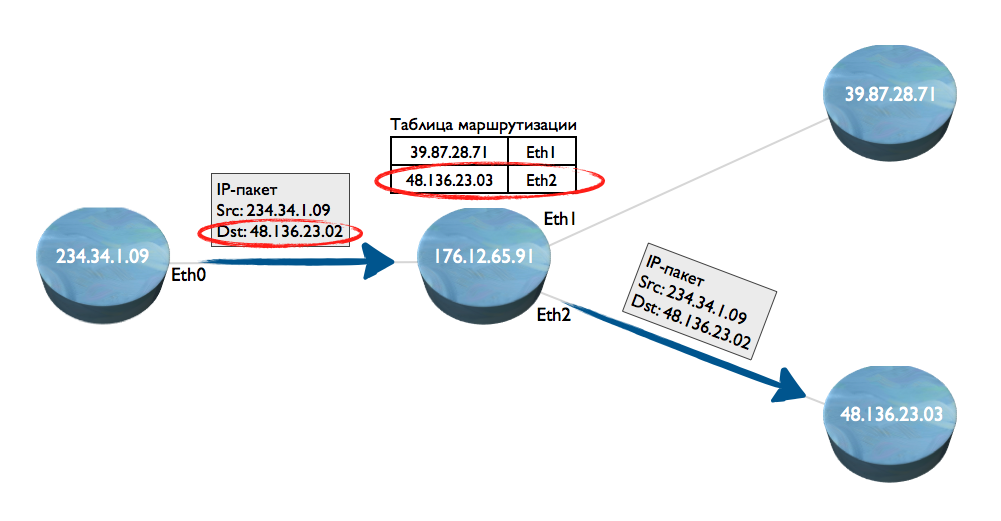
Что такое маршрутизауия? Допустим, есть четыре сетеых узла. С первого на второй передан пакет IP. Как определить, куда его направить — на узел 3 или 4? Узел 2 смотрит у себя внутри таблицу маршрутизации, ищет адрес назначения (порт Ethernet), и передает пакет — на рисунке, на узел 4 (с адресом 48.136.23.03).

Минусы этого способа — низкая скорость маршрутизации пакетов по следующим причинам: а) нужно разбирать миллионы пакетов IP и извлекать из них адрес, б) нужно каждый пакет прогонять по базе данных (таблице маршрутизации), где стоит соответствие IP-адреса номеру сетевого интерфейса Ethernet.
В больших сетях, класса операторов Tier 1 это требует просто неимоверных ресурсов процессора и все равно каждый маршрутизатор вносит задержку.
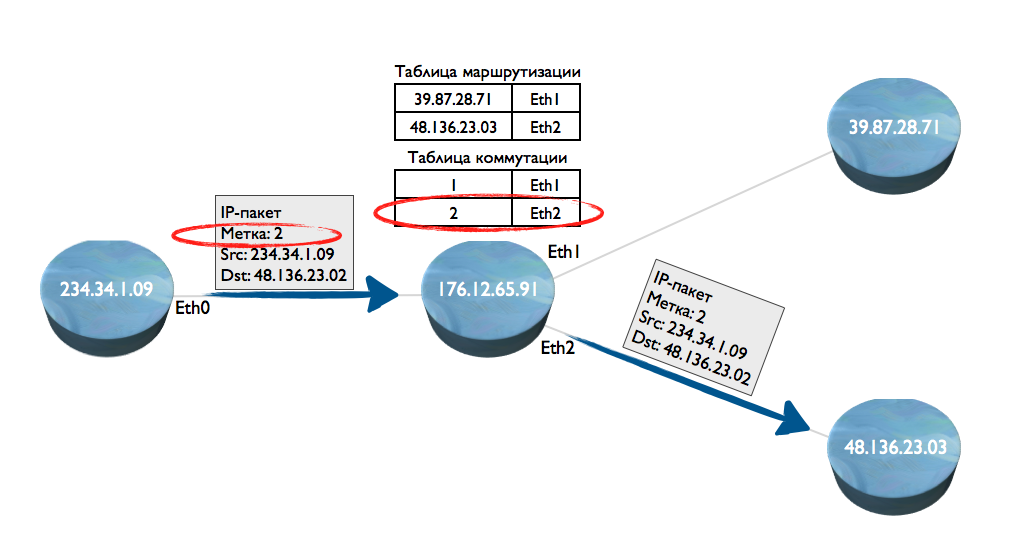
Чтобы это избежать, была придумана технология MPLS (Multiprotocol Label Switching). В простонаречии — коммуатия пакетов. Как она работает? Допустим, началась передача первого пакета. На узле 1, поверх IP-адреса, к пакету добавили метку (label). Метка — это 4-х байтное целое число, которое легко и быстро обрабатывается процессорами. Такой пакет попал на узел 2. Узел 2 по таблице маршрутизации определяет описанным выше способом, что его надо отправить на узел 3. Одновременно на узле 2 создается таблица, в которой прописывается соответствие метки интерфейсу Eternet, смотрящему в сторону узла 4.
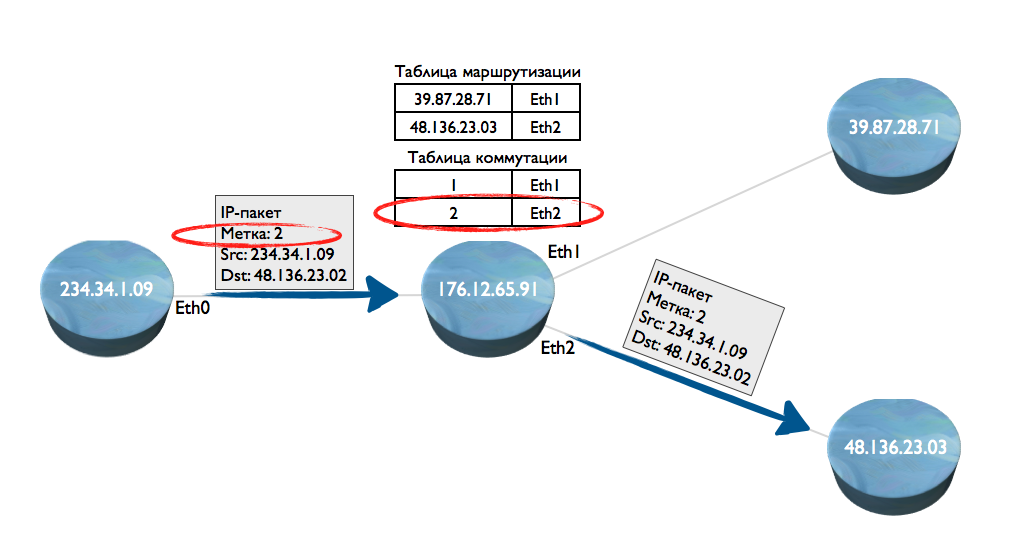
Далее, узел 1 отправляет второй пакет IP, и добавляет к нему ту же метку, что была установлена для первого пакета IP. Когда такой пакет поступит на узел 2, то узел уже не будет обрабатывать IP-адрес и искать его в таблице маршрутизации. Он сразу извлечет метку, и проверит — есть ли для нее выходной интерфейс.
Фактически, за счет построения таких таблиц коммутации на каждом промежуточном узле выстраивается «туннель» по которому осуществляется дальнейшая передача данных, без использования таблиц маршрутизации.
Плюсы этого метода — существенное сокращение сетевой задержки.
А теперь главное…
Минус — первые пакеты передаются методом маршрутизации, выстраивая за собой «туннель» из меток, и только следующие пакеты уже передаются быстро. Именно эту картину мы и наблюдаем выше. Вряд ли у дешевого хостера стоит оборудование MPLS. Как результат — мы видим одинаковую продолжительность выполнения первого и последующего запросов. А вот в Amazon, похоже, как раз и проявляется работа протокола MPLS — посылка первого запроса занимает в 3-5 раз больше времени, чем последующих.
Думаю, именно в этом лежит причина неустойчивого и долгого взаимодействия приложения с базой данных. Хотя, если бы обмен с базой данных был более интенсивный, то скорее всего, через 3-4 запроса, Amazon обогнал бы дешевый хостинг. Парадоксально, что технология, призванная значительно ускорить передачу данных, в моем конкретном случае приводит к неустойчивой работе системы в целом.
Если принять эту версию за рабочую, возникает вопрос — а как же другие? Ведь работают же на Amazon крупные клиенты, социальные сети, и таких проблем не испытывают. Справедливый вопрос, точного ответа на который у меня нет. Однако есть некоторые сображения.
В любом случае, другого объяснения сложившейся ситуации у меня нет.
А решение — есть. Три недели назад система была мигрирована на канадские выделенные серверы хостинг-провайдера OVH. На этом проблема решилась: все заработало заметно быстрее и Connection Error больше никто не видел.
Итак, сначала диагноз больного. Разрабатывается ИТ-система с клиентским приложением. Система представляет собой сервер, который размещается в облаке Amazon в виде сервиса EC2. Этот сервер взаимодействует с базой MySQL, которая стоит в том же регионе (US-west) на сервисе RDS (Relational Database Service). С сервером взаимодействует мобильное приложение, которое через сервер регистрируется, и загружает некоторые данные. В ходе работы этого приложения часто наблюдаются ошибки связи, на которые приложение выводит popup со словами Connection Error. При этом пользователи жалуются на медленную работу приложения. Такая ситуация возникает у пользователей и в США и в России.
Перенос всей системы на независимый хостинг (самый обычный, дешевый) привел к заметно более шустрой работе приложения, и отсутствию задержек Amazon RDS. Поиск по разным форумам ответа о причинах такого поведения не дал.
Для сбора временных характеристик процесса взаимодействия приложения с сервером и базой данных был написан скрипт, который делал запрос в базу данных MySQL 10 раз подряд. Чтобы исключить ситуацию кеширования запроса, в запрос была добавлена инструкция SQL_NO_CACHE. При этом база данных не кеширует такой запрос SELECT. Запрос и измерение его продолжительности осуществляется следующей функцией, которая меряет продолжительность транзакции с учетом сетевой задержки.
function query_execute ($link)
{
$time = microtime (true);
$res = mysqli_query ($link, «SELECT SQL_NO_CACHE ui.* FROM `user_item_id` ui INNER JOIN `users` u ON u.`user_id`=ui.`user_id` WHERE u.`username`='any@user.com';»);
return array («rows» => mysqli_num_rows ($res), «time» => sprintf («%4f», microtime (true) — $time));
}
Этот скрипт был загружен на российский хостинг, и запущен. Результат получился такой (скрипт — Россия, СУБД — Amazon RDS, Калифорния).
Start time to aws measure
rows: 10, duration: 2.659313
rows: 10, duration: 0.594934
rows: 10, duration: 0.595982
rows: 10, duration: 0.594558
rows: 10, duration: 0.397052
rows: 10, duration: 0.399988
rows: 10, duration: 0.399615
rows: 10, duration: 0.396856
rows: 10, duration: 0.399138
rows: 10, duration: 0.396113
— Average duration: 0.6833549
Для сравнения — тоже самое, но с другой хостинговой площадки — во Франции (скрипт — Франция, СУБД — Amazon RDS, Калифорния).
Start time to aws measure
rows: 14, duration: 1.980444
rows: 14, duration: 0.472865
rows: 14, duration: 0.318233
rows: 14, duration: 0.417172
rows: 14, duration: 0.342588
rows: 14, duration: 0.303614
rows: 14, duration: 0.908241
rows: 14, duration: 1.809397
rows: 14, duration: 0.497458
rows: 14, duration: 0.316923
— Average duration: 0.7366935
Такая ситуация чрезвычайно удивила, и заставила покопаться в справочной информации о кешировании SQL-запросов. Но все изыскания говорили одно — скрипт написан корректно. Ситуация сложилась интересная. Вроде все понятно, но непонятна самая малость: а) что происходит, и б) как хотя бы сформулировать запрос в саппорт?
Хорошо. Следующий эксперимент — запуск этого скрипта локально, на сервере в том же Amazon дата-центре в Калифорнии. Наверняка серверы физически стоят рядом, и все должно происходить очень быстро. Пробуем (скрипт и СУБД — Amazon AWS, Калифорния).
Start time to aws measure
rows: 10, duration: 0.024818
rows: 10, duration: 0.009796
rows: 10, duration: 0.006747
rows: 10, duration: 0.005163
rows: 10, duration: 0.007998
rows: 10, duration: 0.006088
rows: 10, duration: 0.009614
rows: 10, duration: 0.007938
rows: 10, duration: 0.008052
rows: 10, duration: 0.007804
— Average duration: 0.0094018
Задержки сильно снизились, но в целом картина прежняя — первый запрос выполняется в разы дольше последующих. И думаю, что именно это причина всех проблем с конечным приложением. Ведь приложение обменивается с сервером информацией «в один запрос», который как раз приходиться на эту самую долгую операцию. Соответственно, именно эта операция и определяет все «тормознутость» приложения.
Чтобы проверить, что же все-таки мешает, база данных была мигрирована с Amazon RDS на отдельный хостинг (самый дешевый). И здесь ждал небольшой сюрприз — равную скорость выполнения первой и последующей транзакций (скрипт — Россия, СУБД — недорогой хостинг в США).
Start time to linode measure
rows: 10, duration: 0.018506
rows: 10, duration: 0.017285
rows: 10, duration: 0.011917
rows: 10, duration: 0.011928
rows: 10, duration: 0.027923
rows: 10, duration: 0.011141
rows: 10, duration: 0.072708
rows: 10, duration: 0.011934
rows: 10, duration: 0.007816
rows: 10, duration: 0.008045
— Average duration: 0.0199203
Немного отвлекусь — самая лучшая ситуация сложилась, когда на этот слабый, в общем-то хостинг, поставили еще и сам сервер (скрипт и СУБД — один и тот же недорогой хостинг на территории США).
Start time to linode measure
rows: 10, duration: 0.008159
rows: 10, duration: 0.000344
rows: 10, duration: 0.000317
rows: 10, duration: 0.000309
rows: 10, duration: 0.000269
rows: 10, duration: 0.000282
rows: 10, duration: 0.000260
rows: 10, duration: 0.000263
rows: 10, duration: 0.000303
rows: 10, duration: 0.000297
— Average duration: 0.0010803
Здесь можно заметить похожую ситуацию, но на единицах миллисекунд в действие уже вступают задержки ОС, а не сети. Поэтому не следует обращать на это внимание.
Но вернемся к нашей ситуации. Для чистоты эксперимента сделали еще один тест — запустили скрипт с этого дешевого хостинга на Amazon RDS. Результат — опять долгая первая транзакция (скрипт — хостинг США, СУБД — Amazon RDS, Калифорния).
Start time to aws measure
rows: 10, duration: 0.098134
rows: 10, duration: 0.016168
rows: 10, duration: 0.011697
rows: 10, duration: 0.007868
rows: 10, duration: 0.008148
rows: 10, duration: 0.010468
rows: 10, duration: 0.033403
rows: 10, duration: 0.011947
rows: 10, duration: 0.012217
rows: 10, duration: 0.008185
— Average duration: 0.0218235
Каких-то аналогов таким странностям ни мне, ни разработчикам в Интернете найти не удалось. Однако тем временем, глядя на эти цифры, у меня стало закладываться смутное подозрение, что ситуация вызвана не настройками ИТ-систем, а особенностью передачи данных в транспортной сети IP, которая связывает дата-центры Amazon.
Изложенные ниже соображения являются только моими предположениями, в которые показанные выше тайминги достаточно логично ложатся. Однако полной уверенности в этом у меня нет, и может быть, причины большой задержки иные, и лежат они на самом плаву. Было бы интересно послушать альтернативные мнения.
Итак, в телекоммуникационном мире в основе всех сетей связи лежит транспортный уровень, образованный протоколом IP. Для передачи пакетов IP через множество промежуточных маршрутизаторов используются, в общем случае, два метода, маршрутизация и коммутация.
Что такое маршрутизауия? Допустим, есть четыре сетеых узла. С первого на второй передан пакет IP. Как определить, куда его направить — на узел 3 или 4? Узел 2 смотрит у себя внутри таблицу маршрутизации, ищет адрес назначения (порт Ethernet), и передает пакет — на рисунке, на узел 4 (с адресом 48.136.23.03).
Минусы этого способа — низкая скорость маршрутизации пакетов по следующим причинам: а) нужно разбирать миллионы пакетов IP и извлекать из них адрес, б) нужно каждый пакет прогонять по базе данных (таблице маршрутизации), где стоит соответствие IP-адреса номеру сетевого интерфейса Ethernet.
В больших сетях, класса операторов Tier 1 это требует просто неимоверных ресурсов процессора и все равно каждый маршрутизатор вносит задержку.
Чтобы это избежать, была придумана технология MPLS (Multiprotocol Label Switching). В простонаречии — коммуатия пакетов. Как она работает? Допустим, началась передача первого пакета. На узле 1, поверх IP-адреса, к пакету добавили метку (label). Метка — это 4-х байтное целое число, которое легко и быстро обрабатывается процессорами. Такой пакет попал на узел 2. Узел 2 по таблице маршрутизации определяет описанным выше способом, что его надо отправить на узел 3. Одновременно на узле 2 создается таблица, в которой прописывается соответствие метки интерфейсу Eternet, смотрящему в сторону узла 4.
Далее, узел 1 отправляет второй пакет IP, и добавляет к нему ту же метку, что была установлена для первого пакета IP. Когда такой пакет поступит на узел 2, то узел уже не будет обрабатывать IP-адрес и искать его в таблице маршрутизации. Он сразу извлечет метку, и проверит — есть ли для нее выходной интерфейс.
Фактически, за счет построения таких таблиц коммутации на каждом промежуточном узле выстраивается «туннель» по которому осуществляется дальнейшая передача данных, без использования таблиц маршрутизации.
Плюсы этого метода — существенное сокращение сетевой задержки.
А теперь главное…
Минус — первые пакеты передаются методом маршрутизации, выстраивая за собой «туннель» из меток, и только следующие пакеты уже передаются быстро. Именно эту картину мы и наблюдаем выше. Вряд ли у дешевого хостера стоит оборудование MPLS. Как результат — мы видим одинаковую продолжительность выполнения первого и последующего запросов. А вот в Amazon, похоже, как раз и проявляется работа протокола MPLS — посылка первого запроса занимает в 3-5 раз больше времени, чем последующих.
Думаю, именно в этом лежит причина неустойчивого и долгого взаимодействия приложения с базой данных. Хотя, если бы обмен с базой данных был более интенсивный, то скорее всего, через 3-4 запроса, Amazon обогнал бы дешевый хостинг. Парадоксально, что технология, призванная значительно ускорить передачу данных, в моем конкретном случае приводит к неустойчивой работе системы в целом.
Если принять эту версию за рабочую, возникает вопрос — а как же другие? Ведь работают же на Amazon крупные клиенты, социальные сети, и таких проблем не испытывают. Справедливый вопрос, точного ответа на который у меня нет. Однако есть некоторые сображения.
- Приложение, о котором я пишу, сейчас является версией 1.0. Скорее всего, а даже наверняка, у нас сейчас имеется неоптимальная структура запросов к базе данных. В будущем она будет оптимизирована, и за счет этого получим выигрыш в скорости. Но сейчас, похоже, одно наложилось на другое.
- Предполагать, что крупные соцсети базируются на Amazon, все-таки странно. Скорее всего, архитектура таких систем географически распределенная, и информация может асинхронно только стекаться в дата-центры Amazon. По крайней мере, трассировка из Москвы Facebook показывает конечной точкой ирландский сервер, Твиттер — какую-то свою площадку, Pinterest — на сети Telia и так далее.
- Между крупными узлами социальных сетей, скорее всего, предустановлены статические маршруты.
В любом случае, другого объяснения сложившейся ситуации у меня нет.
А решение — есть. Три недели назад система была мигрирована на канадские выделенные серверы хостинг-провайдера OVH. На этом проблема решилась: все заработало заметно быстрее и Connection Error больше никто не видел.
