Пять из четырех разработчиков признают, что многопоточное программирование понять непросто.
 Большую часть времени, что я провел в Ruby-сообществе, печально известная GIL оставалась для меня темной лошадкой. В этой статье я расскажу о том, как наконец познакомился с GIL поближе.
Большую часть времени, что я провел в Ruby-сообществе, печально известная GIL оставалась для меня темной лошадкой. В этой статье я расскажу о том, как наконец познакомился с GIL поближе.
Первое, что я услышал о GIL, никак не было связано с тем, как она работает или для чего нужна. Все, что я услышал — что GIL — это плохо, поскольку ограничивает параллелизм, или то, что это хорошо, потому что делает код потокобезопасным. Пришло время, я приноровился к многопоточному программированию и понял, что на самом деле все сложнее.
Я хотел знать, как работает GIL с технической точки зрения. На GIL нет ни спецификации, ни документации. По сути, это особенность MRI (Matz's Ruby Implementation). Команда разработчиков MRI ничего не говорит по поводу того, как GIL работает и что гарантирует.
Впрочем, я забегаю вперед.
Из статьи «Parallelism is a Myth in Ruby» 2008 года за авторством Ильи Григорика я получил общее понимание о GIL. Вот только общее понимание не поможет разобраться с техническими вопросами. В частности, я хочу знать, гарантирует ли GIL потокобезопасность определенных операций в Ruby. Приведу пример.
В Ruby вообще мало что потокобезопасно. Возьмем, например, добавление элемента к массиву
В этом примере каждый из пяти потоков тысячу раз добавляет
=(
Даже в таком простом примере мы сталкиваемся с непотокобезопасными операции. Разберемся в происходящем.
Обратим внимание на то, что запуск кода с использованием MRI дает верный (возможно, в данном контексте вам больше понравится слово «ожидаемый» — прим. пер.) результат, а JRuby и Rubinius — нет. Если запустить код еще раз, ситуация повторится, причем JRuby и Rubinius дадут другие (по-прежнему некорректные) результаты.
Разница в результатах обусловлена существованием GIL. Так как в MRI есть GIL, то, несмотря на то, что пять потоков работают параллельно, только один из них активен в любой момент времени. Другими словами, настоящего параллелизма здесь не наблюдается. В JRuby и Rubinius нет GIL, поэтому, когда пять потоков работают параллельно, они действительно распараллеливаются между доступными ядрами и, выполняя непотокобезопасный код, могут нарушить целостность данных.
Как такое может быть? Думали, Ruby такого не допустит? Посмотрим, как это технически возможно.
Будь то MRI, JRuby или Rubinius, Ruby реализован на другом языке: MRI написан на C, JRuby на Java, а Rubinius — на Ruby и C++. Поэтому при выполнении одной операции в Ruby, например,
Заметим, что здесь есть как минимум четыре разных операции:
Каждая из них обращается к другим функциям. Я обращаю внимание на эти детали для того, чтобы показать, как параллельные потоки могут нарушить целостность данных. Мы привыкли к линейному пошаговому выполнению кода — в однопоточном окружении можно взглянуть на короткую функцию на C и легко отследить порядок выполнения кода.
Но если мы имеем дело с несколькими потоками, так сделать нельзя. Если у нас есть два потока, они могут выполнять разные участки кода функции и приходится следить за двумя цепочками выполнения кода.
Кроме того, так как потоки используют общую память, они могут одновременно изменять данные. Один из потоков может прервать другой, изменить общие данные, после чего другой поток продолжит выполнение, будучи не в курсе о том, что данные изменились. Это и есть причина, по которой некоторые реализации Ruby выдают неожиданные результаты при простом добавлении
Изначально система находится в следующем состоянии:

У нас есть два потока, каждый из которых вот-вот приступит к выполнению функции. Пусть шаги 1-4 будут псевдокодом реализации

Чтобы разобраться в происходящем, просто следуйте по стрелкам. Я добавил надписи, отражающие положение вещей с точки зрения каждого потока.
Это всего лишь один из возможных вариантов развития событий:
Поток A начинает выполнять код функции, но когда очередь доходит до шага 3, происходит переключение контекста. Поток A приостанавливается и настает очередь потока B, который выполняет весь код функции, добавляя элемент и увеличивая длину массива.
После этого возобновляется поток A ровно с той точки, в которой был остановлен, а это случилось прямо перед тем, как увеличить длину массива. Поток A присваивает длине массива значение
Еще раз: поток B присваивает длине массива значение
Вариант развития событий, описанный выше, может привести к некорректным результатам, в чем мы убедились в случае с JRuby и Rubinius. Но с JRuby и Rubinius все еще сложнее, так как в этих реализация потоки могут на самом деле работать параллельно. На рисунке один поток приостанавливается, когда другой работает, в то время как в случае настоящего параллелизма, оба потока могут работать одновременно.
Если запустить пример выше несколько раз, используя JRuby или Rubinius, вы увидите, что результат всегда разный. Переключение контекста непредсказуемо. Оно может случиться раньше или позже или вообще не произойти. Я коснусь этой темы в следующей секции.
Почему Ruby не защищает нас от этого безумия? По той же причине, по которой базовые структуры данных в других языках не потокобезопасны: это слишком накладно. Реализации Ruby могли бы иметь потокобезопасные структуры данных, но это потребует оверхед, который сделает код еще медленее. Поэтому бремя обеспечения потокобезопасности перенесено на программиста.
Я до сих пор не коснулся технических деталей реализации GIL, и главный вопрос все еще остается неотвеченным: почему запуск кода на MRI все равно дает верный результат?
Этот вопрос послужил причиной, по которой я написал эту статью. Общее понимание GIL не дает ответа на него: ясно, что только один поток может выполнять Ruby-код в некоторый момент времени. Но ведь переключение контекста все равно может произойти посередине функции?
Но сначала...
Переключение контекста входит в задачи планировщика ОС. Во всех упомянутых реализациях одному Ruby-потоку соответствует один нативный поток. ОС должна гарантировать, что ни один поток не захватит все доступные ресурсы (процессорное время, например), поэтому она реализует планировние так, чтобы каждый поток получал доступ к ресурсам.
Для потока это означает, что он будет приостанавливаться и возобновляться. Каждый поток получает процессорное время, после чего приостанавливается, а доступ к ресурсам получает следующий поток. Когда приходит время, поток возобновляется, и так далее.
Это эффективно с точки зрения ОС, но вносит некоторую случайность и мотивирует пересмотреть взгляд на корректность программы. Например, при выполнении
Если вы хотите быть уверенным, что поток не будет прерван в неподходящем месте, используйте атомарные операции, которым обеспечено отсутствие прерываний до завершения. Благодаря этому в нашем примере поток не будет прерван на шаге 3 и в конечном итоге не нарушит целостность данных на шаге 4.
Простейший способ использовать атомарную операцию — прибегнуть к блокировке. Следующий код даст одинаковый предсказуемый результат с MRI, JRuby и Rubinius благодаря мьютексу.
Если какой-нибудь поток начинает выполнение блока
Мы увидели, как можно использовать блокировку для создания атомарной операции и обеспечения потокобезопасности. GIL — тоже блокировка, но делает ли она код потокобезопасным? Превращает ли GIL
Скоро сказка сказывается, да не скоро дело делается.Статья слишком велика для того, чтобы прочитать ее за один раз, поэтому я разбил ее на две части. Во второй части мы заглянем в реализацию GIL в MRI, чтобы ответить на поставленные вопросы.
Переводчик будет рад услышать замечания и конструктивную критику.
 Большую часть времени, что я провел в Ruby-сообществе, печально известная GIL оставалась для меня темной лошадкой. В этой статье я расскажу о том, как наконец познакомился с GIL поближе.
Большую часть времени, что я провел в Ruby-сообществе, печально известная GIL оставалась для меня темной лошадкой. В этой статье я расскажу о том, как наконец познакомился с GIL поближе.Первое, что я услышал о GIL, никак не было связано с тем, как она работает или для чего нужна. Все, что я услышал — что GIL — это плохо, поскольку ограничивает параллелизм, или то, что это хорошо, потому что делает код потокобезопасным. Пришло время, я приноровился к многопоточному программированию и понял, что на самом деле все сложнее.
Я хотел знать, как работает GIL с технической точки зрения. На GIL нет ни спецификации, ни документации. По сути, это особенность MRI (Matz's Ruby Implementation). Команда разработчиков MRI ничего не говорит по поводу того, как GIL работает и что гарантирует.
Впрочем, я забегаю вперед.
Если вы совсем ничего не знаете о GIL, вот описание в двух словах:
В MRI есть нечто, называемое GIL (global interpreter lock, глобальная блокировка интерпретатора). Благодаря ей в многопоточном окружении в некоторый момент времени может выполняться Ruby-код только в одном потоке.
Например, если у вас есть восемь потоков, работающих на восьмиядерном процессоре, только один поток может работать в некоторый момент времени. GIL призвана предотвратить появление гонки условий, которая может нарушить целостность данных. Есть некоторые тонкости, но суть такова.
Из статьи «Parallelism is a Myth in Ruby» 2008 года за авторством Ильи Григорика я получил общее понимание о GIL. Вот только общее понимание не поможет разобраться с техническими вопросами. В частности, я хочу знать, гарантирует ли GIL потокобезопасность определенных операций в Ruby. Приведу пример.
Добавление элемента к массиву не потокобезопасно
В Ruby вообще мало что потокобезопасно. Возьмем, например, добавление элемента к массиву
array = []
5.times.map do
Thread.new do
1000.times do
array << nil
end
end
end.each(&:join)
puts array.size
В этом примере каждый из пяти потоков тысячу раз добавляет
nil в один и тот же массив. В результате в массиве должно быть пять тысяч элементов, верно?$ ruby pushing_nil.rb
5000
$ jruby pushing_nil.rb
4446
$ rbx pushing_nil.rb
3088
=(
Даже в таком простом примере мы сталкиваемся с непотокобезопасными операции. Разберемся в происходящем.
Обратим внимание на то, что запуск кода с использованием MRI дает верный (возможно, в данном контексте вам больше понравится слово «ожидаемый» — прим. пер.) результат, а JRuby и Rubinius — нет. Если запустить код еще раз, ситуация повторится, причем JRuby и Rubinius дадут другие (по-прежнему некорректные) результаты.
Разница в результатах обусловлена существованием GIL. Так как в MRI есть GIL, то, несмотря на то, что пять потоков работают параллельно, только один из них активен в любой момент времени. Другими словами, настоящего параллелизма здесь не наблюдается. В JRuby и Rubinius нет GIL, поэтому, когда пять потоков работают параллельно, они действительно распараллеливаются между доступными ядрами и, выполняя непотокобезопасный код, могут нарушить целостность данных.
Почему параллельные потоки могут нарушить целостность данных
Как такое может быть? Думали, Ruby такого не допустит? Посмотрим, как это технически возможно.
Будь то MRI, JRuby или Rubinius, Ruby реализован на другом языке: MRI написан на C, JRuby на Java, а Rubinius — на Ruby и C++. Поэтому при выполнении одной операции в Ruby, например,
array << nil, может оказаться, что ее реализация состоит из десятков, а то и сотен строк кода. Вот реализация Array#<< в MRI:VALUE
rb_ary_push(VALUE ary, VALUE item)
{
long idx = RARRAY_LEN(ary);
ary_ensure_room_for_push(ary, 1);
RARRAY_ASET(ary, idx, item);
ARY_SET_LEN(ary, idx + 1);
return ary;
}
Заметим, что здесь есть как минимум четыре разных операции:
- Получение текущей длины массива
- Проверка на наличие памяти для еще одного элемента
- Добавление элемента к массиву
- Присваивание длине массива старого значения + 1
Каждая из них обращается к другим функциям. Я обращаю внимание на эти детали для того, чтобы показать, как параллельные потоки могут нарушить целостность данных. Мы привыкли к линейному пошаговому выполнению кода — в однопоточном окружении можно взглянуть на короткую функцию на C и легко отследить порядок выполнения кода.
Но если мы имеем дело с несколькими потоками, так сделать нельзя. Если у нас есть два потока, они могут выполнять разные участки кода функции и приходится следить за двумя цепочками выполнения кода.
Кроме того, так как потоки используют общую память, они могут одновременно изменять данные. Один из потоков может прервать другой, изменить общие данные, после чего другой поток продолжит выполнение, будучи не в курсе о том, что данные изменились. Это и есть причина, по которой некоторые реализации Ruby выдают неожиданные результаты при простом добавлении
nil к массиву. Происходящая ситуация подобна описанной ниже.Изначально система находится в следующем состоянии:

У нас есть два потока, каждый из которых вот-вот приступит к выполнению функции. Пусть шаги 1-4 будут псевдокодом реализации
Array#<< в MRI, приведенной выше. Ниже приведено возможное развитие событий (в начальный момент времени активен поток A):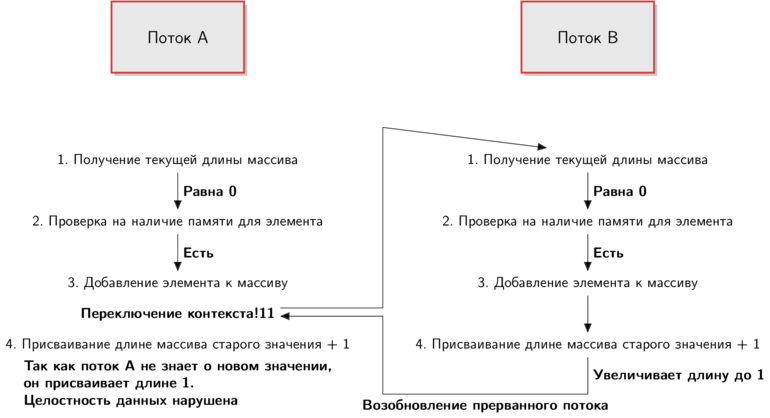
Чтобы разобраться в происходящем, просто следуйте по стрелкам. Я добавил надписи, отражающие положение вещей с точки зрения каждого потока.
Это всего лишь один из возможных вариантов развития событий:
Поток A начинает выполнять код функции, но когда очередь доходит до шага 3, происходит переключение контекста. Поток A приостанавливается и настает очередь потока B, который выполняет весь код функции, добавляя элемент и увеличивая длину массива.
После этого возобновляется поток A ровно с той точки, в которой был остановлен, а это случилось прямо перед тем, как увеличить длину массива. Поток A присваивает длине массива значение
1. Вот только поток B уже успел изменить данные.Еще раз: поток B присваивает длине массива значение
1, после чего поток A тоже присваивает ей 1, несмотря на то, что оба потока добавили к массиву элементы. Целостность данных нарушена.А я полагался на Ruby
Вариант развития событий, описанный выше, может привести к некорректным результатам, в чем мы убедились в случае с JRuby и Rubinius. Но с JRuby и Rubinius все еще сложнее, так как в этих реализация потоки могут на самом деле работать параллельно. На рисунке один поток приостанавливается, когда другой работает, в то время как в случае настоящего параллелизма, оба потока могут работать одновременно.
Если запустить пример выше несколько раз, используя JRuby или Rubinius, вы увидите, что результат всегда разный. Переключение контекста непредсказуемо. Оно может случиться раньше или позже или вообще не произойти. Я коснусь этой темы в следующей секции.
Почему Ruby не защищает нас от этого безумия? По той же причине, по которой базовые структуры данных в других языках не потокобезопасны: это слишком накладно. Реализации Ruby могли бы иметь потокобезопасные структуры данных, но это потребует оверхед, который сделает код еще медленее. Поэтому бремя обеспечения потокобезопасности перенесено на программиста.
Я до сих пор не коснулся технических деталей реализации GIL, и главный вопрос все еще остается неотвеченным: почему запуск кода на MRI все равно дает верный результат?
Этот вопрос послужил причиной, по которой я написал эту статью. Общее понимание GIL не дает ответа на него: ясно, что только один поток может выполнять Ruby-код в некоторый момент времени. Но ведь переключение контекста все равно может произойти посередине функции?
Но сначала...
Виной всему планировщик
Переключение контекста входит в задачи планировщика ОС. Во всех упомянутых реализациях одному Ruby-потоку соответствует один нативный поток. ОС должна гарантировать, что ни один поток не захватит все доступные ресурсы (процессорное время, например), поэтому она реализует планировние так, чтобы каждый поток получал доступ к ресурсам.
Для потока это означает, что он будет приостанавливаться и возобновляться. Каждый поток получает процессорное время, после чего приостанавливается, а доступ к ресурсам получает следующий поток. Когда приходит время, поток возобновляется, и так далее.
Это эффективно с точки зрения ОС, но вносит некоторую случайность и мотивирует пересмотреть взгляд на корректность программы. Например, при выполнении
Array#<< следует иметь в виду, что поток может быть остановлен в любой момент и другой поток может выполнять тот же код параллельно, меняя общие данные.Решение? Использовать атомарные операции
Если вы хотите быть уверенным, что поток не будет прерван в неподходящем месте, используйте атомарные операции, которым обеспечено отсутствие прерываний до завершения. Благодаря этому в нашем примере поток не будет прерван на шаге 3 и в конечном итоге не нарушит целостность данных на шаге 4.
Простейший способ использовать атомарную операцию — прибегнуть к блокировке. Следующий код даст одинаковый предсказуемый результат с MRI, JRuby и Rubinius благодаря мьютексу.
array = []
mutex = Mutex.new
5.times.map do
Thread.new do
mutex.synchronize do
1000.times do
array << nil
end
end
end
end.each(&:join)
puts array.size
Если какой-нибудь поток начинает выполнение блока
mutex.synchronize, другие потоки вынуждены ждать его завершения перед тем, как начать выполнение этого же кода. Используя атомарные операции, вы получаете гарантию, что если переключение контекста случится внутри блока, то другие потоки все равно не смогут войти в него и изменить общие данные. Планировщик это заметит и опять переключит поток. Теперь код потокобезопасен.GIL — тоже блокировка
Мы увидели, как можно использовать блокировку для создания атомарной операции и обеспечения потокобезопасности. GIL — тоже блокировка, но делает ли она код потокобезопасным? Превращает ли GIL
array << nil в атомарную операцию?Переводчик будет рад услышать замечания и конструктивную критику.
