Знакомимся с RabbitMQ
Переводы на хабре:
RabbitMQ tutorial 1 — Hello World
RabbitMQ tutorial 2 — Очередь задач
RabbitMQ tutorial 3 — Публикация/Подписка
Сразу дополню некоторые недочеты. И кратко повторю основные термины.
Принцип работы архитектуры использующей rabbitMq
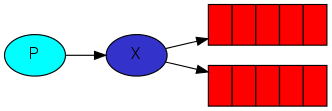
Есть приложение (клиент) генерирующее сообщения, сообщения попадают в точку обмена, в зависимости от параметров сообщения и настроек точки обмена сообщение копируется в одну или несколько очередей (или просто удаляется), после чего клиенты могут забрать сообщения из очередей.
Очередь связывается с точкой обмена по ключу маршрутизации или заголовку сообщения.
Ключ маршрутизации — значение, которое указывается при публикации сообщения в точку обмена, служит для определения очередей в которые попадет сообщение.
Заголовок сообщения — набор аргументов вида ключ-значение связанных с сообщением.
Точки обмена могут быть 4 типов:
- direct — сообщения попавшие в эту точку обмена будут скопированы только в те очереди, которые связаны с точкой обмена строгим ключом маршрутизации.
- topic — ключ маршрутизации может быть составным, и задаваться в виде паттерна, для чего существуют два специальных символа: * — обозначает одно слово, # — одно или несколько слов. Слова разделяются точкой. Пример: routingKey = "*.database" — все сообщения с ключами в которых вторым словом значится database будут скопированы в привязанные по паттерну очереди.
- headers — очередь связывается с точкой обмена не по ключу маршрутизации, а по заголовку сообщения, указывается условие, какие аргументы и их значения ожидаются, и при получении точкой обмена сообщения с заголовком содержащим аргументы из условия, очередь его получает. Пример можно посмотреть тут.
- fanout — сообщение поступившее в точку обмена копируется во все привязанные очереди, без проверки ключа маршрутизации или заголовка сообщения.
У каждой очереди есть 4 флага определяющих ее поведение:
- auto_delete — если очередь пустая и к ней нет активных подключений, очередь автоматически удаляется
- durable — устойчивая очередь, сообщения не теряются при рестарте rabbitMQ (или внезапной перезагрузке), при публикации и до окончания отдачи хранятся в базе данных
- exclusive — очередь предназначена для не более чем одного подключения единовременно
- passive — при объявлении очереди пассивной, при обращении клиента сервер будет считать что очередь уже создана, т.е. не будет автоматически создавать ее в случае отсутствия, этот вариант нужен если вы хотите обратиться к серверу не изменяя его состояние. Например, вам просто нужно проверить существует ли очередь. Для этого объявляете очередь пассивной, и если получаете ошибку, значит очередь не существует.
Теперь немного о самой работе rabbit'а, при установке и запуске в качестве службы используются настройки по-умолчанию, как пишут разработчики в официальной документации, этого должно хватить на большинство сценариев, однако я еще не встречал ситуаций в реальных продуктов когда хватало бы настроек по умолчанию. Параметры работы можно менять в рантайме используя служебные утилиты (расположены в каталоге \rabbitmq_server-3.2.0\sbin), однако изменения внесенные таким образом будут потеряны при перезапуске rabbitmq (соответственно и при перезагрузке). Переходим к следующей теме.
Конфигурация rabbitMQ
Конфигурация работы сервера RabbitMQ располагается в трех местах, это переменные окружения (задаются порты и расположения и имена файлов), файлы конфигурации (настройки доступа, кластеры, плагины), и настройки задаваемые в рантайме (политики, настройки производительности).
При установке в Windows файл конфигурации не создается, есть только его пример расположенный в каталоге \rabbitmq_server-3.2.0\etc\rabbitmq.config.example. Создаем свой файл конфигурации, называем его rabbitmq.config (расширение именно .config и никак иначе!), и заполняем простыми настройками:
%% Sample
[
{rabbit,
[
{tcp_listeners, [5672]},
{log_levels, [{connection, error}]},
{default_vhost, <<"/">>},
{default_user, <<"username">>},
{default_pass, <<"password">>},
{default_permissions, [<<".*">>, <<".*">>, <<".*">>]},
{heartbeat, 60},
{frame_max, 1048576}
]}
].
Обрамление <<>> — это не ошибка, так и должно быть.
Комментарии в настройках предваряются двойным символом процента — %%.
Теперь размещаем файл в удобном месте, например в корневой папке с установленным сервером RabbitMQ, для примера пусть будет путь:
c:\rabbitmq\rabbitmq.config
Для того чтобы RabbitMq смог увидеть файл конфигурации необходимо создать переменную окружения с его расположением
RABBITMQ_CONFIG_FILE = c:\rabbitmq\rabbitmq
Переменную стоит создать и в окружении пользователя и в окружении системы.
Пишем путь до имени файла, расширение обрезаем. Создание конфиг файла и настройку окружения лучше проводить до установки RabbitMQ сервера, или же переустановить его после. (For environment changes to take effect the service must be re-installed.) Простой перезапуск не помогает.
Теперь можно установить Эрланг и сервер RabbitMQ.
Создание и настройка кластера
Внимание
Все команды выполняемые в командной строке, выполняются в каталоге инструментов установленного RabbitMQ сервера:
RabbitMQ\RabbitMQ Server\rabbitmq_server-3.2.1\sbin
Кластер, в rabbitMQ, это связь одного и более серверов RabbitMQ друг с другом, в которой один из узлов выступает в роли мастер-сервера, остальные в роли слейв-серверов, на мастере задаются настройки кластера, которые дублируются на слейвы, к ним, в частности, относятся настройки доступа и политик. При падении мастера, один из слейвов берет на себя его роль, и становится мастером.
В первую очередь, до создания кластера нам нужно синхронизировать куки RabbitMQ узлов, куки в RabbitMQ это сгенерированный при установке хэш, который используется как идентификатор узла, т.к. кластер выступает как единый узел, на каждом сервере куки должны быть идентичны.
На мастер-сервере берем файл
%WINDOWS%\.erlang.cookie
и копируем его с заменой по пути
C:\Users\%CurrentUser%\.erlang.cookie, после чего копируем с заменой на каждый узел кластера по указанным путям.
Создание кластера проводится выполнением следующих команд на каждом слейве:
rabbitmqctl stop_app
rabbitmqctl join_cluster --ram rabbit@master
rabbitmqctl start_app
Либо указанием в файле конфигурации:
{cluster_nodes, {["rabbit@master", "rabbit@host01"], disc}}
Данную процедуру требуется выполнить только один раз, при добавлении нового узла, в дальнейшем узел будет подключаться к кластеру автоматически (например, после перезагрузки сервера на котором поднят узел).
Кластер создан, но для полноценного использования не годится, на текущем этапе очереди и сообщения на каждом узле живут отдельно, никакой синхронизации не производится, а значит если два клиента подключаться к кластеру к разным узлам, то когда один из них опубликует сообщения в очередь, второй ничего об это не узнает. Также при падении одного из узлов, все сообщения которые были на нем будут потеряны.
Политики синхронизации
Заходим в инструменты и выполняем в рантайме следующую команду:
rabbitmqctl set_policy HA ".*" "{""ha-mode"": ""all""}"
Теперь все очереди и сообщения в них будут синхронизироваться. При публикации сообщения, оно становится доступным для клиентов только после копирования на все узлы кластера.
Осталась одна проблема, при падении одного из узлов, клиенты подключенные к нему должны определять факт падения и уметь переключаться на доступные узлы, разработчики RabbitMQ пишут:
Подключение к кластеру клиентских приложений.
Клиент может подключаться к любому узлу кластера. Если узел падает в то время как остальная часть кластера продолжает работать, то клиенты подключенные к нему должны определить факт падения и должны уметь переподключаться к кластеру, к рабочим узлам. Как правило не рекомендуется вносить реальные IP всех узлов кластера в клиентские приложения, это мешает гибкости как в работе самих приложений так и в настройке кластера. Вместо этого мы рекомендуем использовать более абстрагированный подход: это может быть какой-либо DNS сервис с очень малым значением TTL, или простой TCP балансировщик, или какого-либо рода мобильный IP, или аналогичные технологии. В общем, этот аспект выходит за рамки RabbitMQ, и мы рекомендуем использовать технологии разработанные для решения этих проблем.
Т.е. рекомендуется не писать велосипед, а воспользоваться готовым решением, в своем варианте я использую NLB, как нативное встроенное в Windows решение. Этот этап остается на ваше усмотрение.
Полезности
Пингуем узел из командной строки:
rabbitmqctl eval "net_adm:ping(rabbit@hostname)."
, если узел доступен получаем ответ pong
Ссылки
www.rabbitmq.com/clustering.html
www.rabbitmq.com/ha.html
