
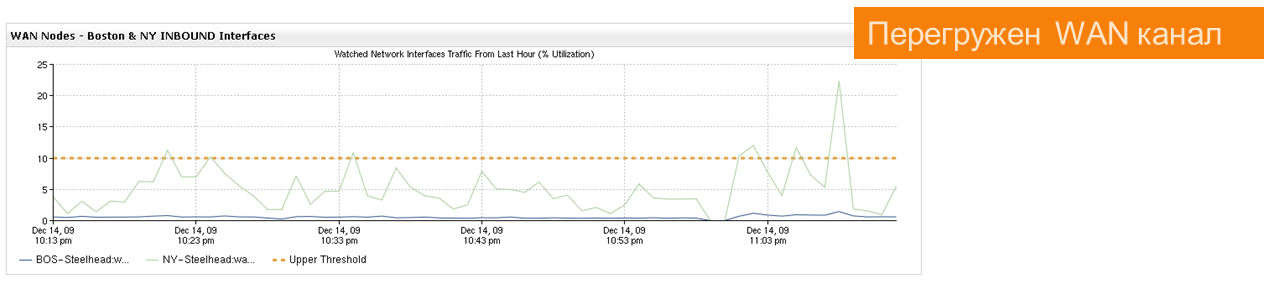
Предположим, у нас есть вот такая картина загрузки канала связи:
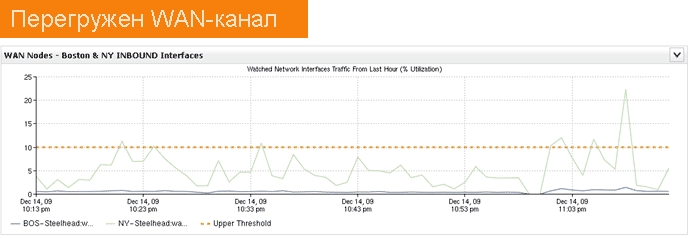
Что вызвало всплеск трафика? Что происходило в канале связи?
Действие происходит в крупном ЦОДе, например, банка. И в канале может оказаться как что угодно из тестовых сервисов, так и один из десятка бизнес-сервисов, а также — с равным успехом — бекап базы данных.
Если админ не совсем криворукий, а ситуация не очень хитрая, то минут за 10 можно будет выделить конкретные причины, создающие проблемы, и ещё минут за 15–20 проанализировать проблему. Если же ситуация сложнее (мы рассмотрим ещё пример ниже), то искать аномалии в поведении трафика можно сутками. С инструментарием обнаружения таких аномалий у нас на поиск проблемы в этом примере уйдёт 1 минута.
Вот простой пример. Был всплеск трафика в канале связи, из-за чего возникли тормоза работы приложений у юзеров.
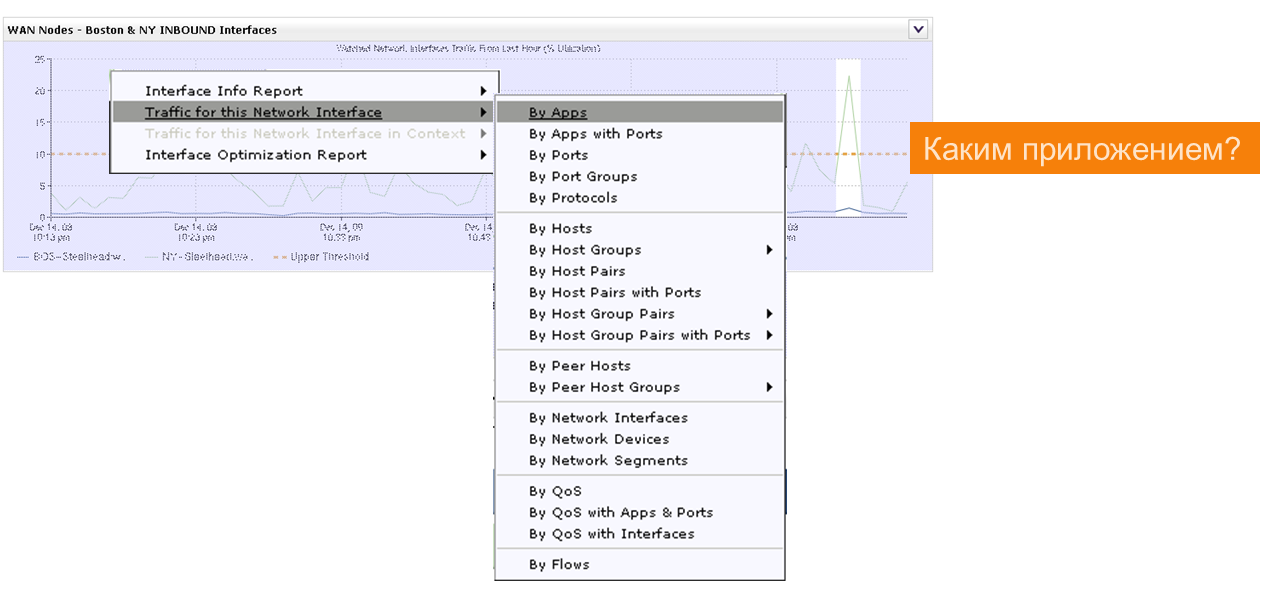
Хотим разобраться: трафик каких приложений/сервисов передаётся в канале связи и что вызвало всплеск?
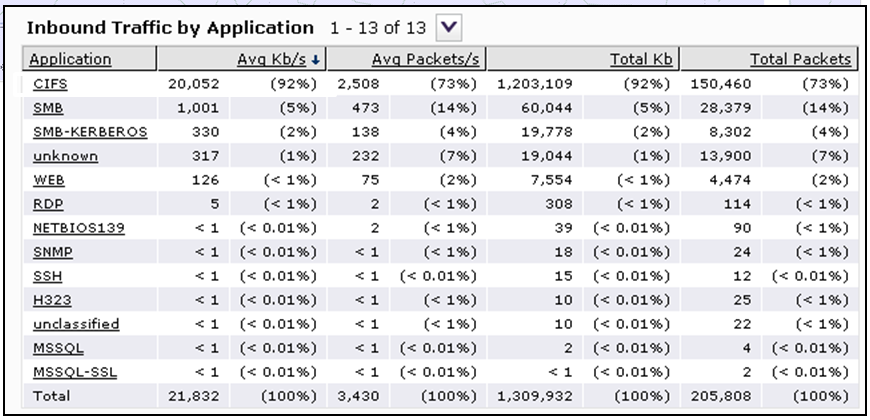
Ага, понятно… CIFS — 92% от общего объёма трафика.
Выясняем, кто там работал (какие хосты и пользователи).
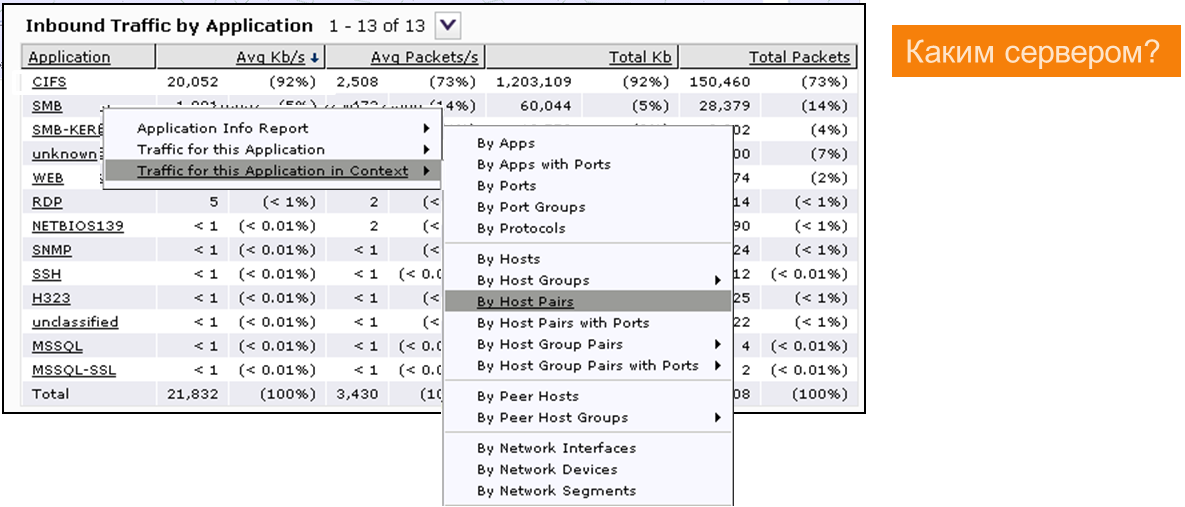
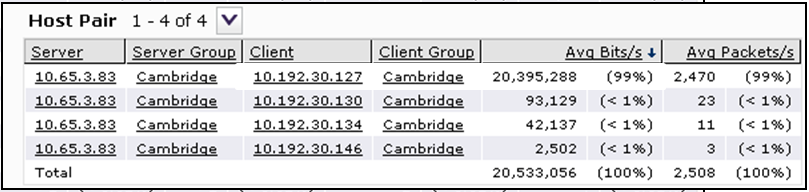
Первая пара клиент — сервер загрузила канал связи на 99% по CIFS.
Если у нас есть интеграция системы диагностики с Active Directory, мы можем выяснить, кто это. Пробуем.
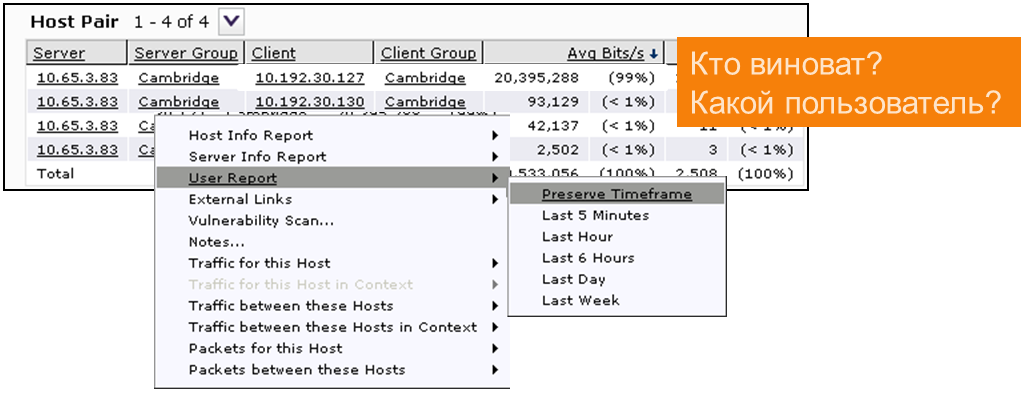
У нас это некий Джон Смит. У проблемы появилась фамилия. И всё это за 1 минуту.

Хочу добавить, что все переходы между созданными в примере отчётами выполняются по клику правой кнопки мышки и выбору отчёта из появившегося контекстного меню.
Теперь посмотрим пример посложнее, когда тормозит целая ERP-система.
Итак, есть вот такая картина:
ERP тормозит, пользователи жалуются. Почему? Куда смотреть? Где смотреть?
Конечно, можно искать причины вручную. Это интересно, но, если проблем несколько десятков, утомительно и долго. Плюс нужно использовать множество своих или сторонних модулей для анализа трафика, его сбора и оценки. К счастью, у нас есть инструмент, который позволяет получить все данные сразу и в одном месте. Это Riverbed Cascade.
Предположим, это не просто одна проблема, а целая куча разных задач анализа деградации бизнес-сервисов. В обычной сети при «разведке» нам нужно понять:
Полное решение состоит из трёх с половиной частей:
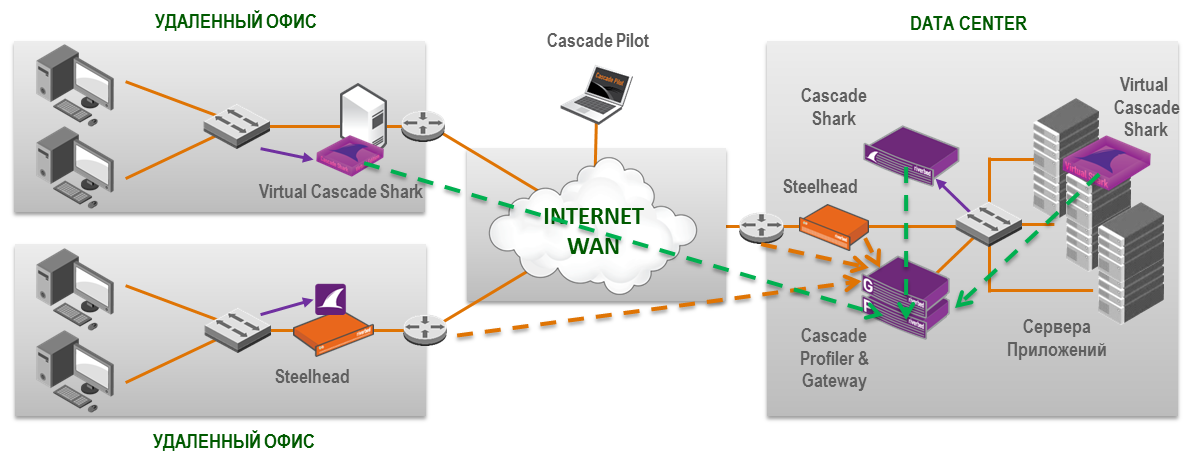
Пример для конкретного ЦОДа: установлены все три модуля. Shark Sensor принимает зеркалированные данные с коммутатора серверной фермы, Virtual Shark анализирует взаимодействия между виртуальными машинами — Gateway принимает flow с маршрутизаторов и оптимизаторов. Потом вся статистика идёт на профайлер. Pilot работает с копией трафика, хранящегося на Shark Sensor
Возвращаемся к ERP с проблемой.
Начинаем разбираться в том, что произошло на сегменте между конечными пользователями и Web-серверами, почему система просигнализировала об этом.
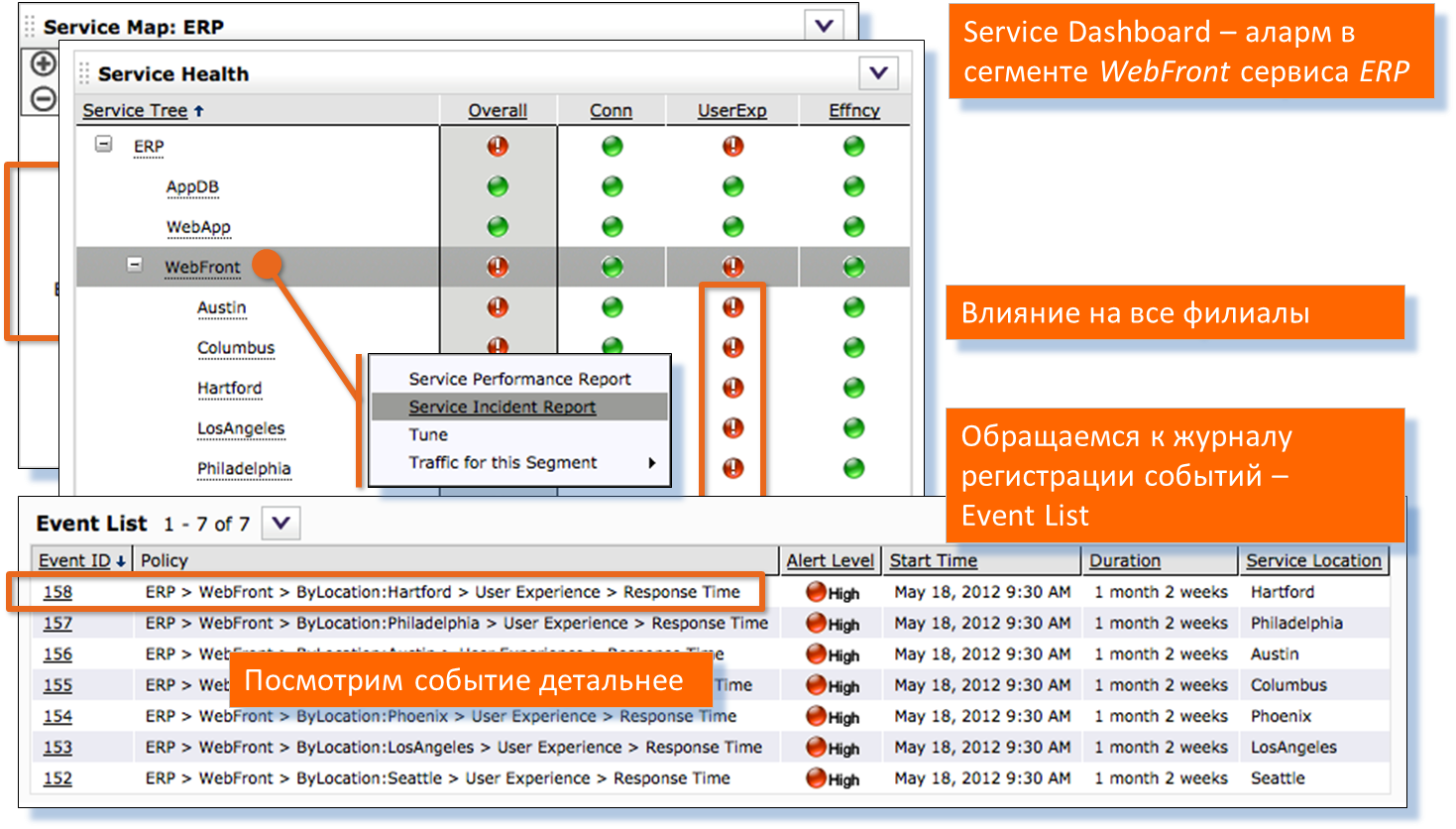
Переходим к системе семафоров на рабочем столе. Видно, что проблема есть для всех удалённых филиалов компании. Смотрим инциденты по этой проблеме. Переходим к детальному анализу — видно, что у нас увеличилось время отклика от сервера. Графики и таблицы ниже создаются в одном отчёте.
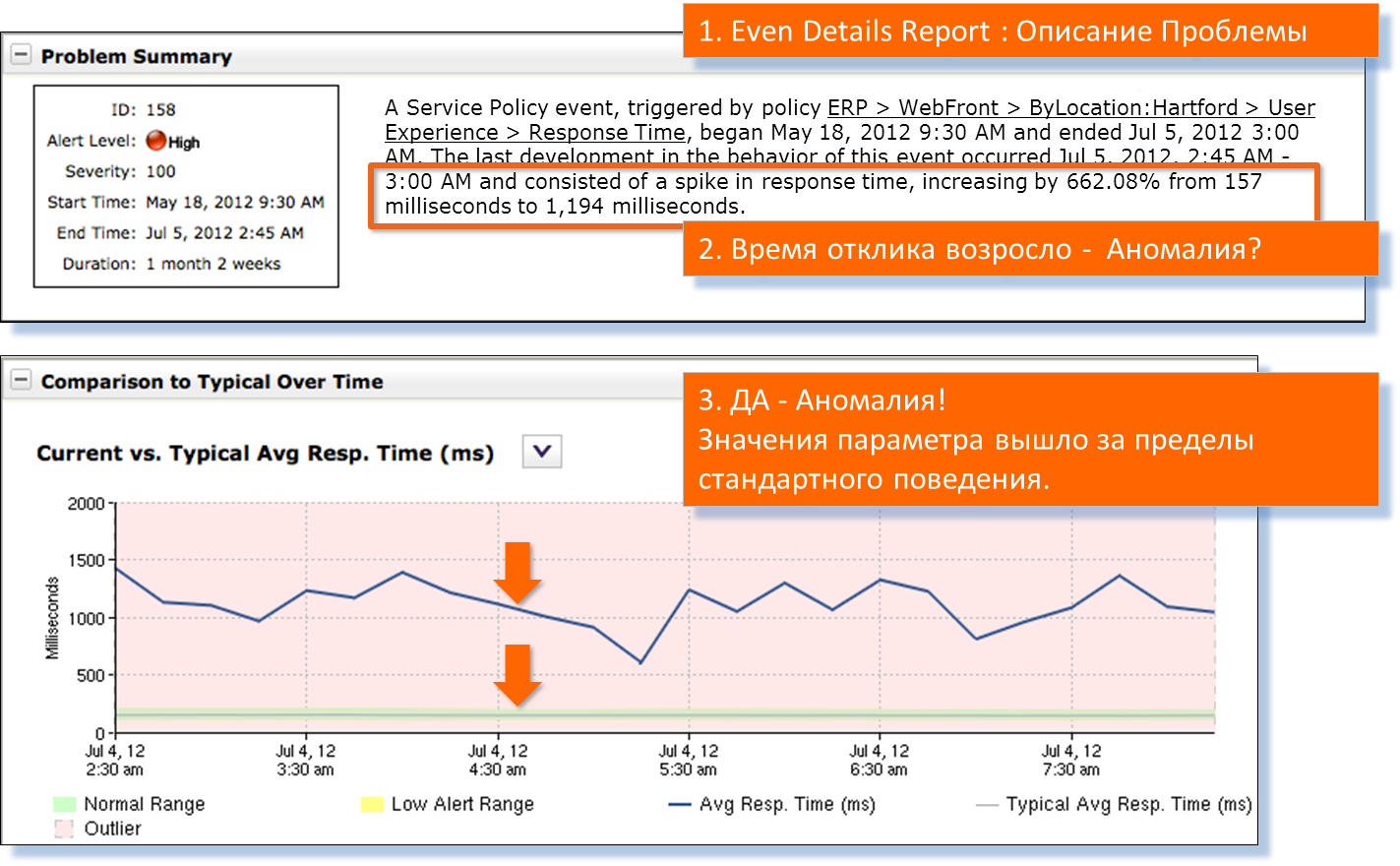
Зелёная черта внизу графика — нормальный профиль работы сервера. Такой должен быть при стабильной работе сервера.
На графике реальные значения времени отклика сервера показаны синим цветом. Прокручиваем отчёт ниже.
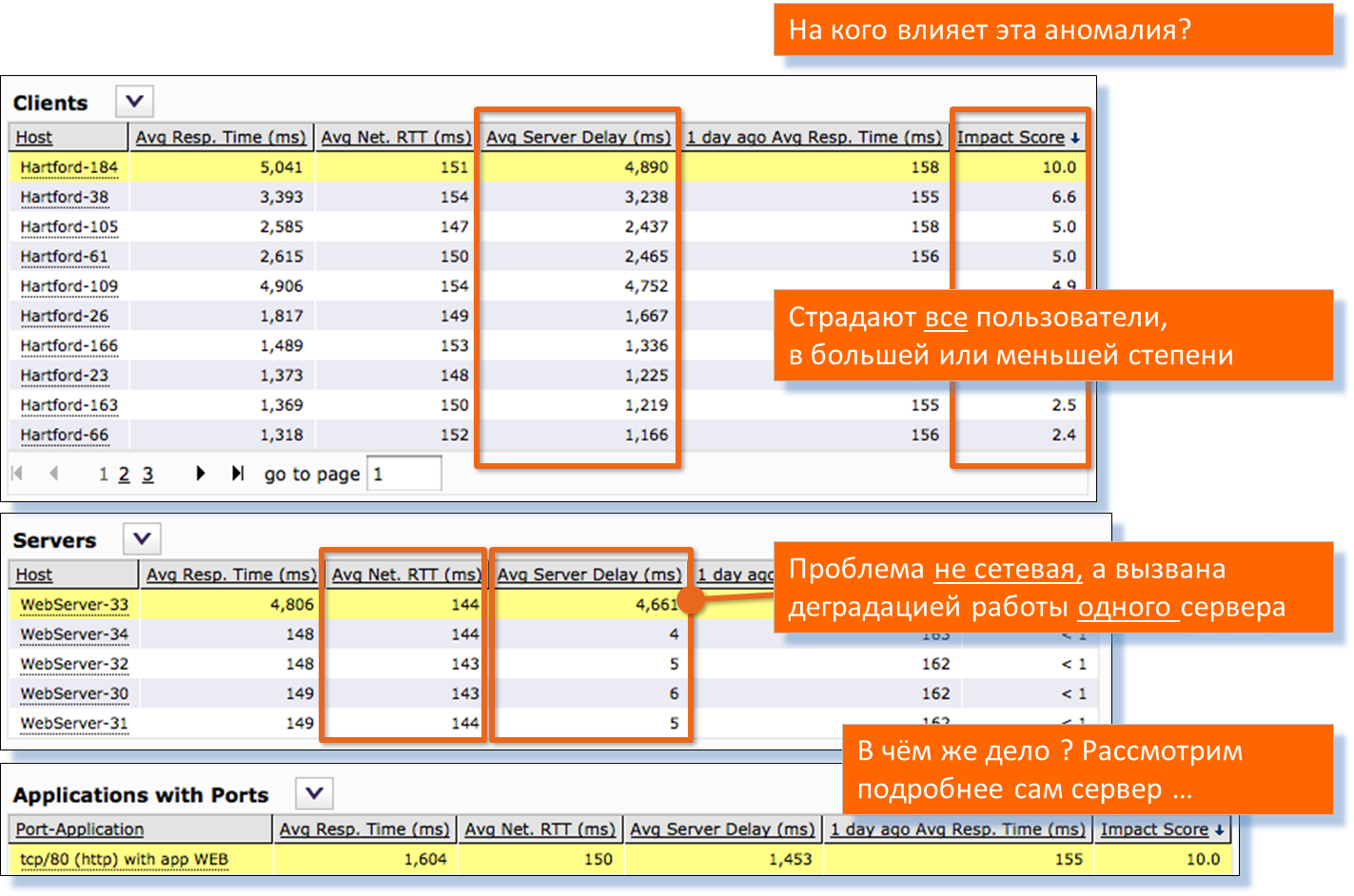
Смотрим на взаимодействие клиентов и серверов. Видно, что у всех клиентов есть проблемы в той или иной степени. При этом из кластера серверов проблема только у одного сервера.
Рассмотрим статистику проблемного сервера.
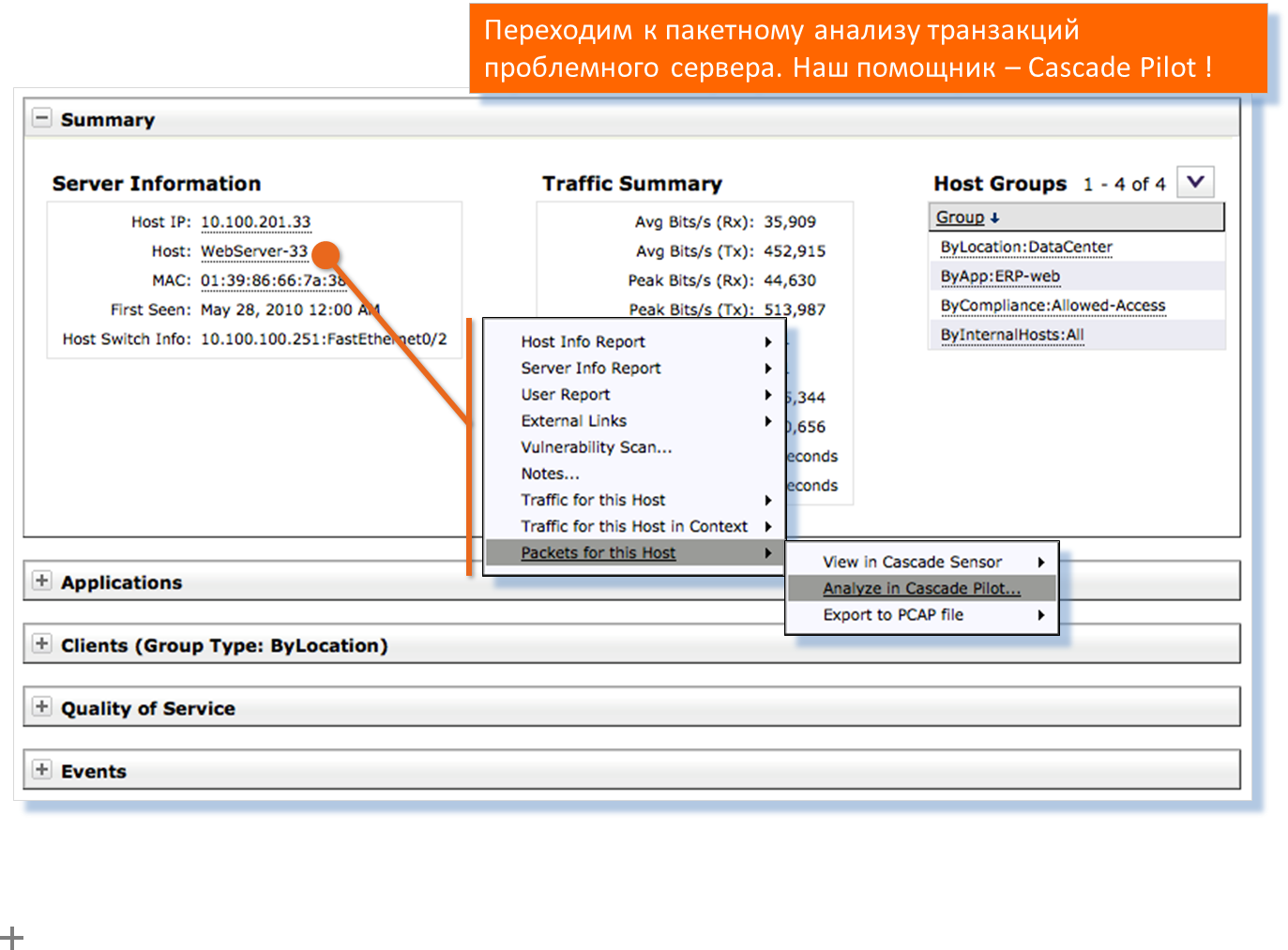
Видим MAC-адрес сервера, IP-адрес коммутатора и порт коммутатора, куда подключён сервер. Рассмотрим транзакции проблемного сервера в графической оболочке к Wireshark — Pilot Console.
На отчёте времени отклика сервера по объектам видно, что увеличено время предоставления лишь одного объекта.
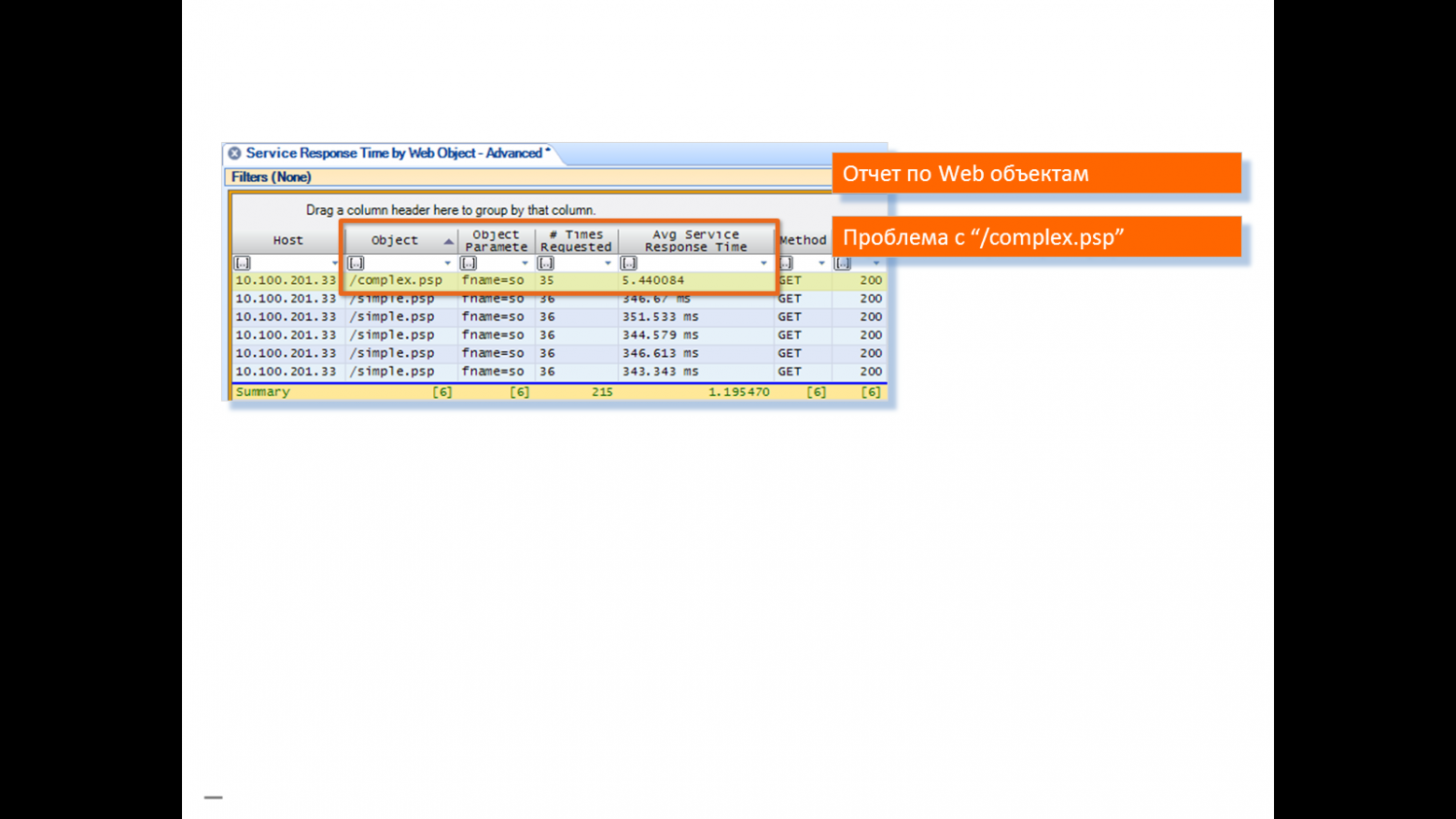
Вот он, попался: complex.psp
Проверяем. Строим диаграмму взаимодействия по транзакциям. Проверяем:
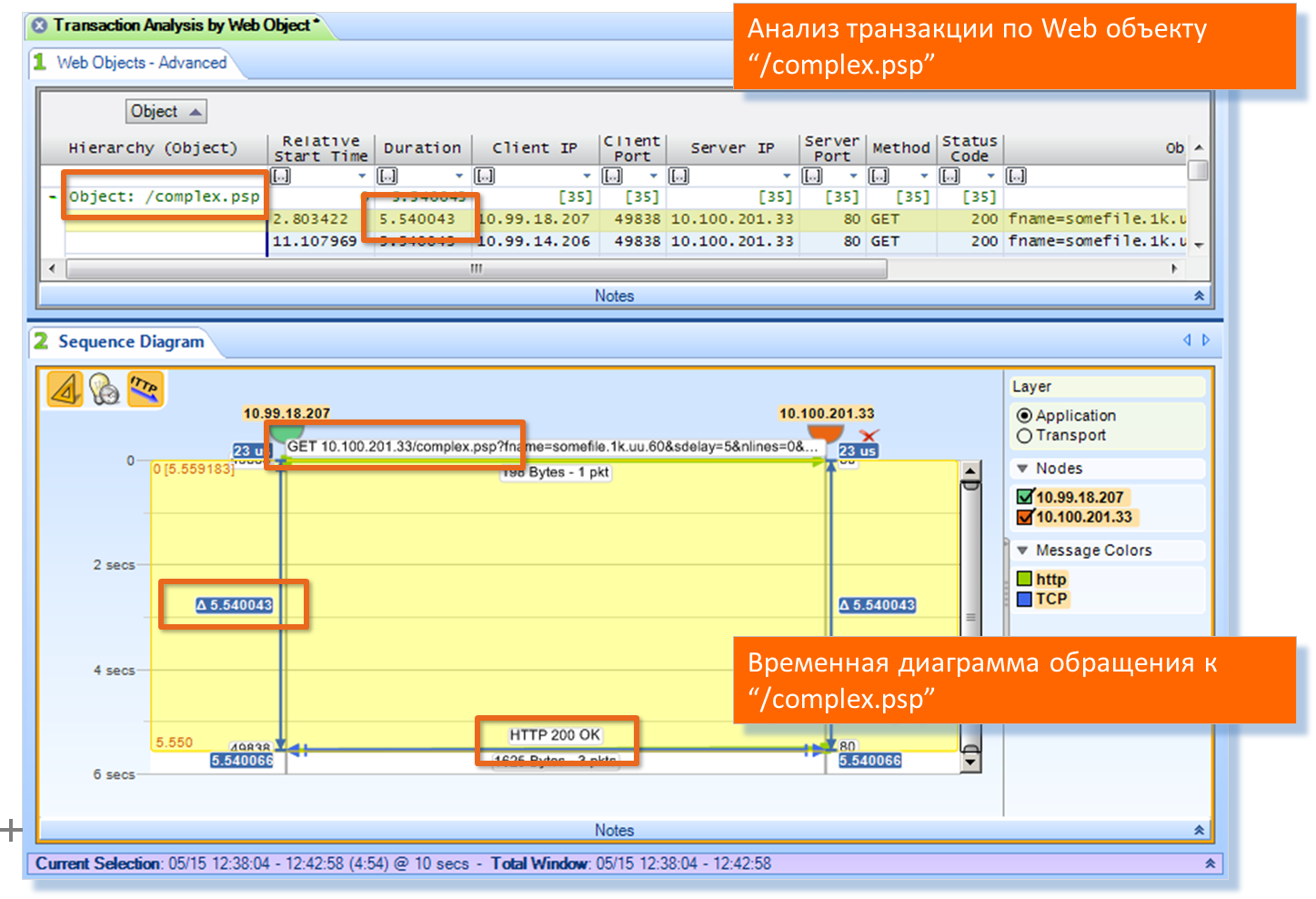
Да, это оно.
Если кто ещё не верит, пусть проверит — переходим к ручному пакетному анализу в Wireshark той же транзакции.
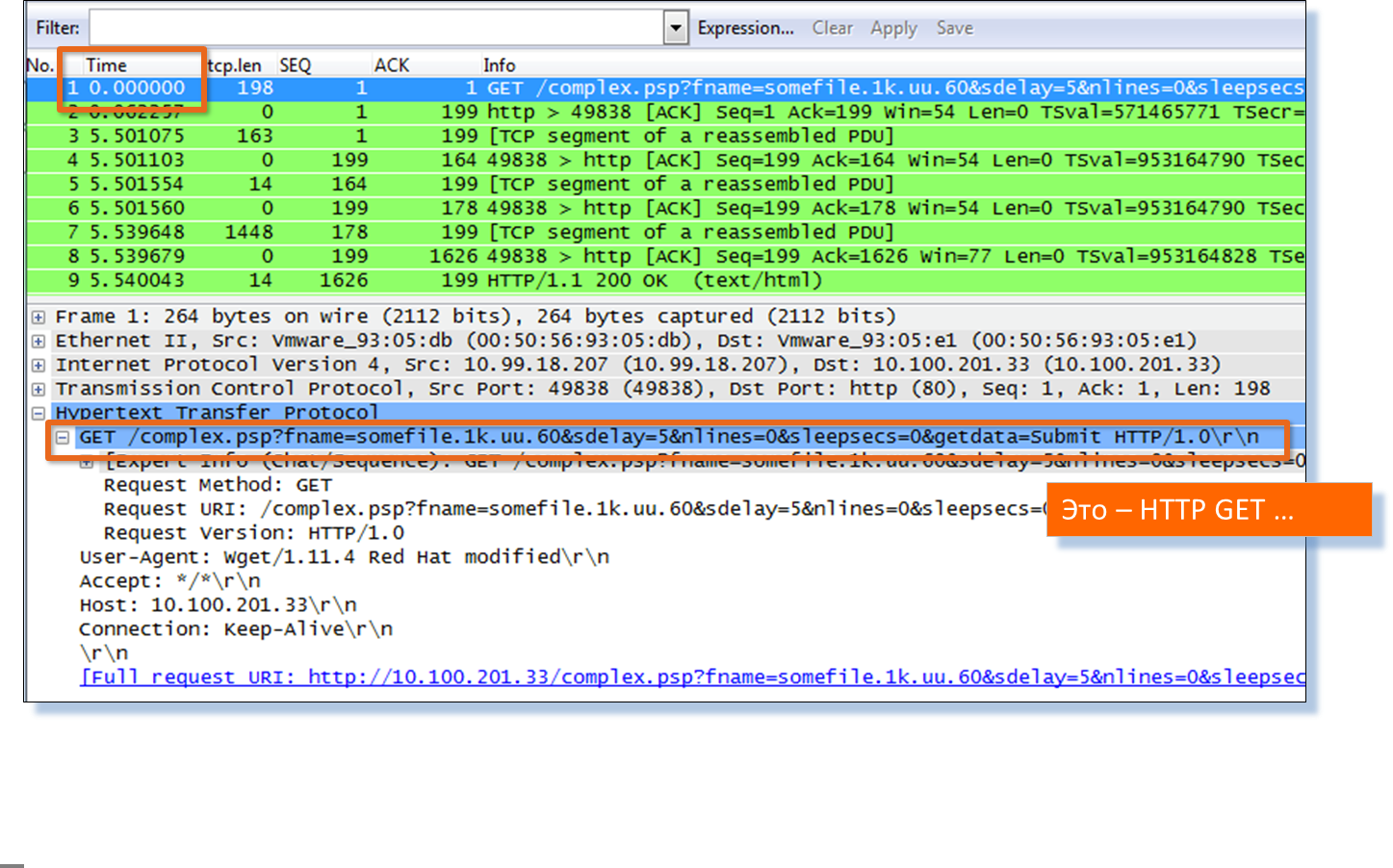
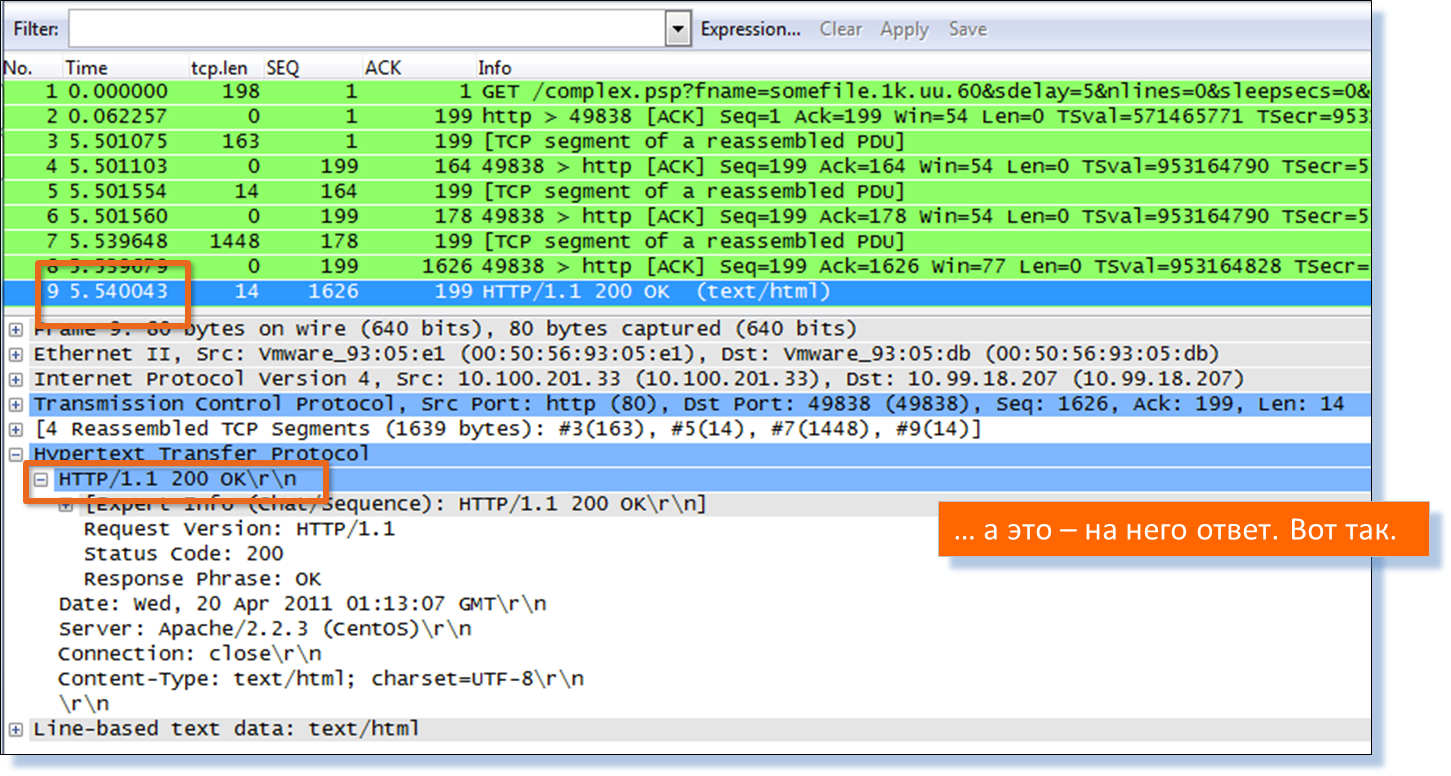
Итак, мы только что получили исчерпывающую картину взаимодействия пользователей с Web-серверами сервиса ERP, что позволило найти сбойный Web-сервер, а даже точнее, сбойный объект на сервере.
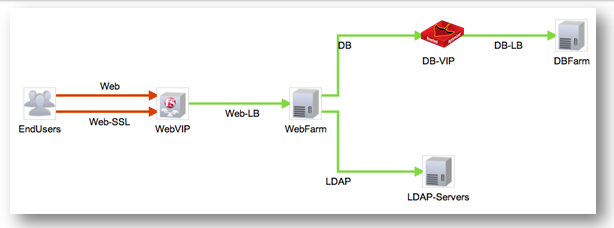
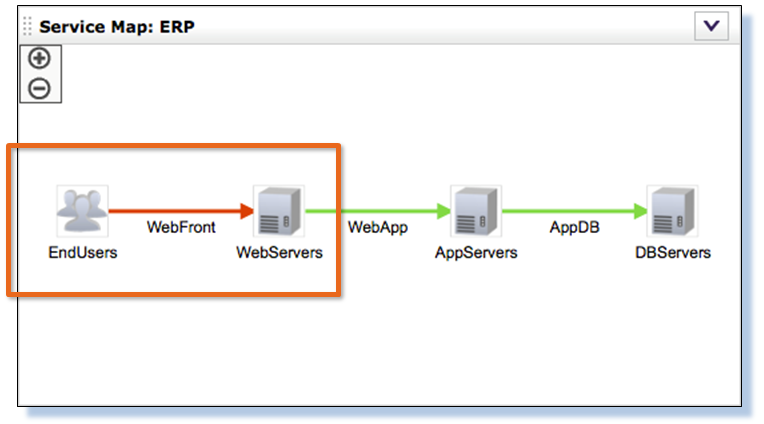
Видим картину многоуровневого приложения с указанием всех компонентов, включая балансировщики нагрузки трафика. Система визуально сразу даёт понять, на каком сегменте нужно анализировать деградацию сервиса в целом: красным цветом отмечен сегмент конечных пользователей при обращении к VIP-адресу балансировщика трафика. Дальше можно переходить к детальному анализу трафика на этом сегменте и анализу производительности балансировщика трафика. Нет необходимости анализировать каждый сегмент многоуровневого приложения вручную и разбираться, как взаимодействуют между собой компоненты этого приложения: при первом взгляде на карту взаимодействия компонентов приложения визуально всё становится понятно.
В предыдущем посте я уже писал про устройства-оптимизаторы трафика, которые умеют отлично сжимать каналы данных и часто используются банками, телеком-операторами и другими крупными компаниями, а также средним и крупным бизнесом, стремящимся эффективнее использовать канал связи и ускорить работу приложений. Так вот, поскольку оптимизаторы — продукт того же производителя, сетевая статистика с них может собираться и с помощью системы мониторинга Riverbed Cascade. Два решения отлично (и дёшево, что важно) сочетаются, что комплексно решает проблемы производительности приложений компаний.
Вот эти показатели оптимизации трафика собраны как раз Riverbed Cascade:
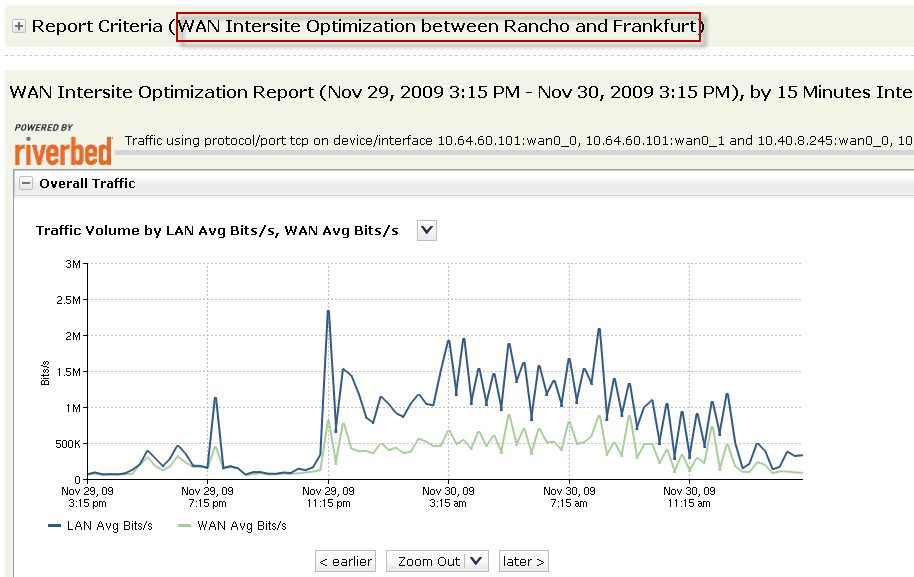
Соотношение LAN-трафика (синий график) и WAN-трафика (зелёный график) с оптимизацией. Наглядно видно, насколько уменьшился объём трафика в канале связи
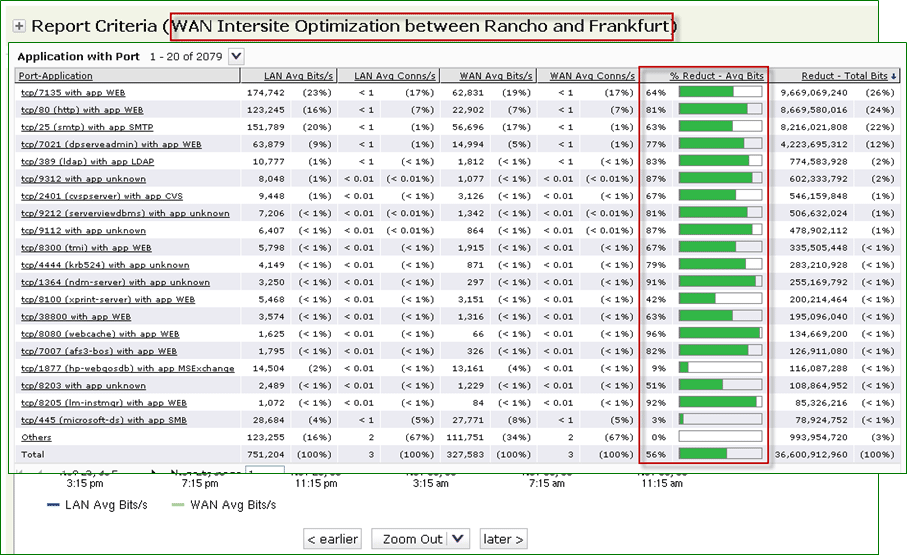
Оптимизация трафика с разбивкой по приложениям и процент уменьшения использования полосы пропускания каждого из них
Решение используется, естественно, не только для локализации проблем и аномалий в поведении трафика приложений. Очень удобно строить отчёты, например, для планирования развития инфраструктуры. К примеру, отчёт по объёмам трафика и его типам по филиалам позволяет найти город, который лидирует по трафику Citrix, и оценить пользу от оптимизации этого направления.
Можно искать проблемы как в историческом разрезе, так и в реальном времени по факту их появления (и вот здесь вы будете чертовски рады тому, что есть такой мощный помощник).
У решения Riverbed есть ещё одна прекрасная функция — поведенческая аналитика. Как известно, одной из важнейших задач является своевременное информирование заинтересованных лиц о деградации работы бизнес-сервисов. Обычно системы позволяют установить только фиксированные пороговые значения для метрик производительности работы приложений. Их должен придумать сам администратор.
Здесь же Riverbed Cascade обходит всех конкурентов: он снимает десятки метрик и строит профили нормального поведения каждой метрики. Пороговые значения ставить не надо, система соберёт историческую статистику, и на её основе будут сформированы пороговые значения. А при отклонении от нормы система проинформирует администратора или его руководителя.
Кроме аналитики производительности приложений в систему заложен функционал аналитики безопасности. А именно: система предупредит администратора в том случае, если:
И даже если установленные антивирусные системы не видят распространение нового вируса в сети, Riverbed Cascade обнаружит распространение «червя» по появившемуся аномальному трафику.
Мы реализовали это решение (в комплекте с оптимизацией трафика) для золотодобывающей компании, для территориально распределённого банка, логистической компании, закончили проект для энергетической компании и ещё десятки проектов поменьше. Такая штука нужна в каждом ЦОДе, как мне кажется. В общем, если есть вопросы — задавайте на AVrublevsky@croc.ru либо в комментариях. Цены под вашу инфраструктуру могу тоже назвать в почте.

Что вызвало всплеск трафика? Что происходило в канале связи?
Действие происходит в крупном ЦОДе, например, банка. И в канале может оказаться как что угодно из тестовых сервисов, так и один из десятка бизнес-сервисов, а также — с равным успехом — бекап базы данных.
Если админ не совсем криворукий, а ситуация не очень хитрая, то минут за 10 можно будет выделить конкретные причины, создающие проблемы, и ещё минут за 15–20 проанализировать проблему. Если же ситуация сложнее (мы рассмотрим ещё пример ниже), то искать аномалии в поведении трафика можно сутками. С инструментарием обнаружения таких аномалий у нас на поиск проблемы в этом примере уйдёт 1 минута.
Вот простой пример. Был всплеск трафика в канале связи, из-за чего возникли тормоза работы приложений у юзеров.
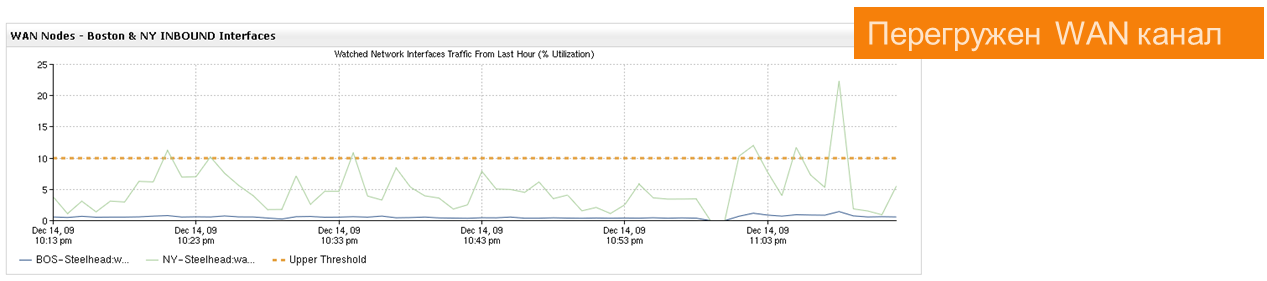
Хотим разобраться: трафик каких приложений/сервисов передаётся в канале связи и что вызвало всплеск?

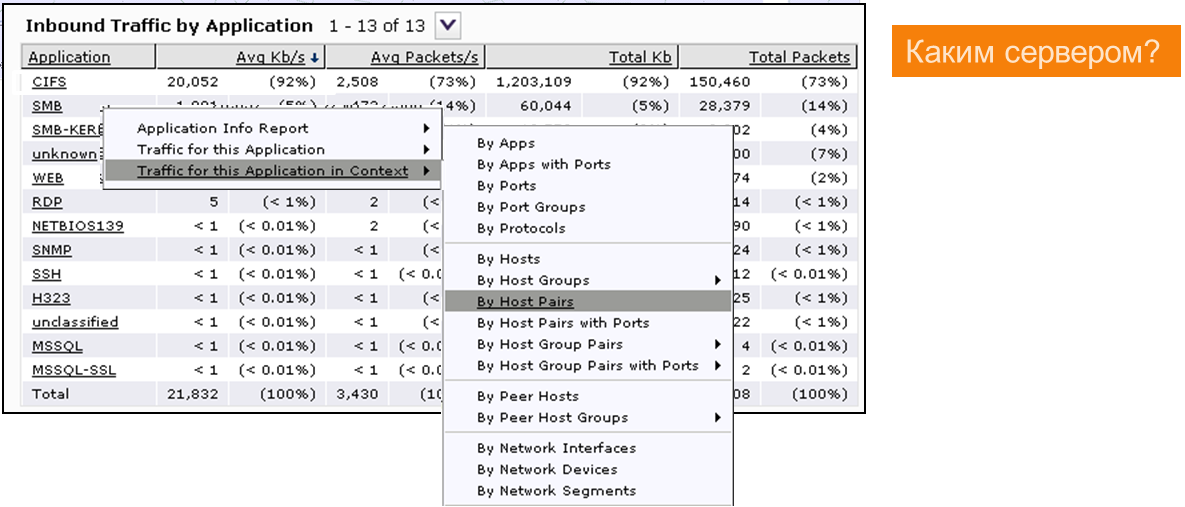
Ага, понятно… CIFS — 92% от общего объёма трафика.

Выясняем, кто там работал (какие хосты и пользователи).
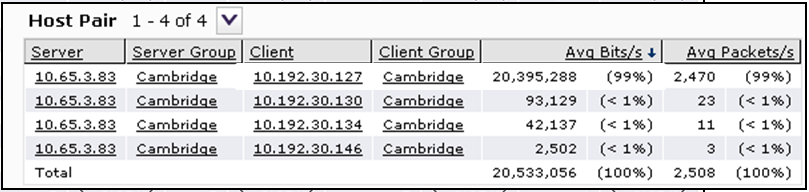
Первая пара клиент — сервер загрузила канал связи на 99% по CIFS.
Если у нас есть интеграция системы диагностики с Active Directory, мы можем выяснить, кто это. Пробуем.
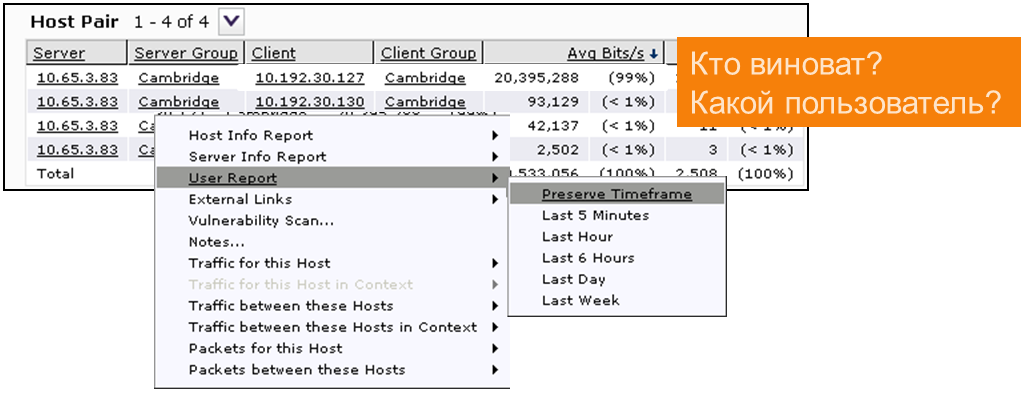
У нас это некий Джон Смит. У проблемы появилась фамилия. И всё это за 1 минуту.

Хочу добавить, что все переходы между созданными в примере отчётами выполняются по клику правой кнопки мышки и выбору отчёта из появившегося контекстного меню.
Теперь посмотрим пример посложнее, когда тормозит целая ERP-система.
Итак, есть вот такая картина:
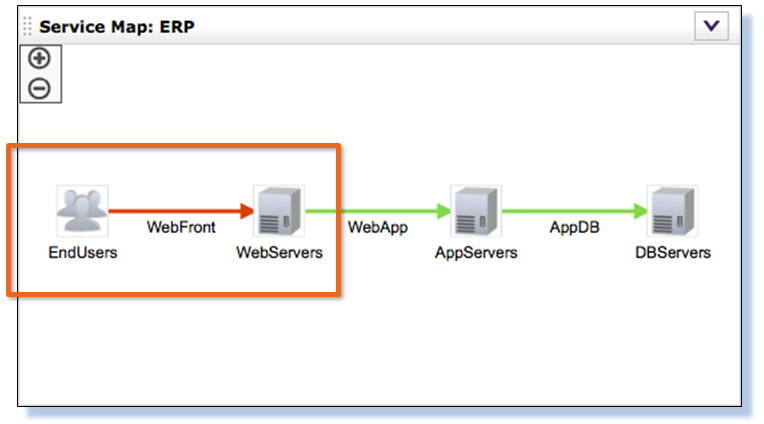
ERP тормозит, пользователи жалуются. Почему? Куда смотреть? Где смотреть?
Конечно, можно искать причины вручную. Это интересно, но, если проблем несколько десятков, утомительно и долго. Плюс нужно использовать множество своих или сторонних модулей для анализа трафика, его сбора и оценки. К счастью, у нас есть инструмент, который позволяет получить все данные сразу и в одном месте. Это Riverbed Cascade.
Общая задача
Предположим, это не просто одна проблема, а целая куча разных задач анализа деградации бизнес-сервисов. В обычной сети при «разведке» нам нужно понять:
- Как долго отвечает сервер на запросы пользователей?
- С какой скоростью пакеты проходят по сети?
- Какие данные куда ходят?
- Каков характер обмена трафика (например, много мелких частых запросов или крупные, профиль загрузки вверх-вниз, потенциальные возможности дедупликации или размещения в быстром кеше)?
- Какие и где создаются сетевые и серверные задержки?
- Как маркирован этот трафик (правильно?)
- Как взаимодействуют сервера между собой?
- Как связаны модули приложений?
Используем Riverbed Cascade
Полное решение состоит из трёх с половиной частей:
- Профайлера, отвечающего за анализ данных. Дополнение для рабочей станции Pilot Console — помощник профайлеру для быстрой обработки и анализа копии пакетов (TCP Dump), записанных на сенсорах. Если по-простому, Pilot — графический интерфейс ко всем известному Wireshark.
- Gateway — сбор данных с первичных источников типа коммутаторов, маршрутизаторов и так далее. Gateway принимает все типы flow, данные дедуплицируются и отправляются на Profiler для анализа.
- Сенсоров, наблюдающих за зеркалированными данными, измерением задержек. Также сенсоры хранят собранные пакеты у себя для исторического анализа возникших проблем. Статистика направляется на Profiler для анализа.

Пример для конкретного ЦОДа: установлены все три модуля. Shark Sensor принимает зеркалированные данные с коммутатора серверной фермы, Virtual Shark анализирует взаимодействия между виртуальными машинами — Gateway принимает flow с маршрутизаторов и оптимизаторов. Потом вся статистика идёт на профайлер. Pilot работает с копией трафика, хранящегося на Shark Sensor
Задумчивый сервер
Возвращаемся к ERP с проблемой.
Начинаем разбираться в том, что произошло на сегменте между конечными пользователями и Web-серверами, почему система просигнализировала об этом.
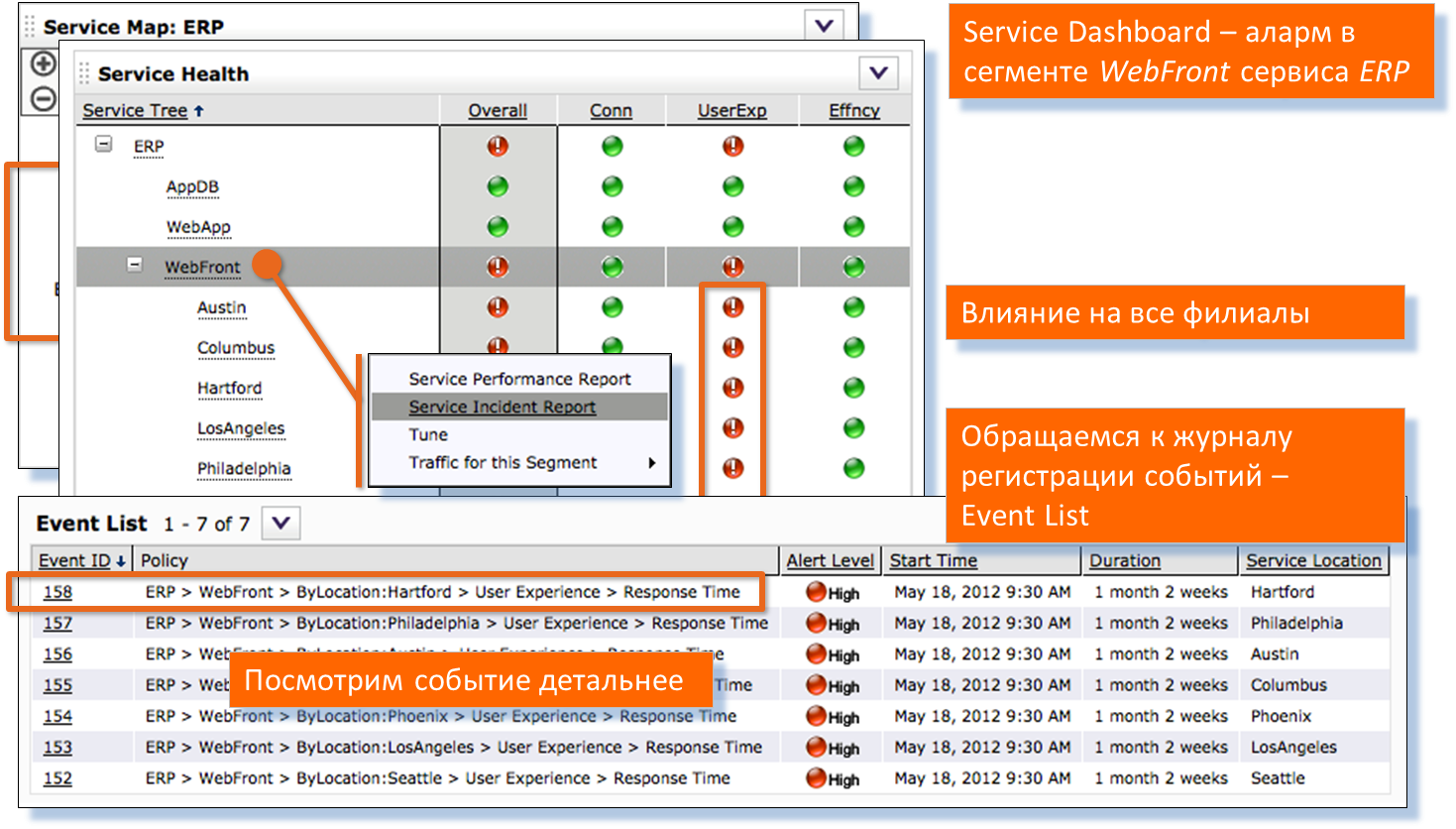
Переходим к системе семафоров на рабочем столе. Видно, что проблема есть для всех удалённых филиалов компании. Смотрим инциденты по этой проблеме. Переходим к детальному анализу — видно, что у нас увеличилось время отклика от сервера. Графики и таблицы ниже создаются в одном отчёте.
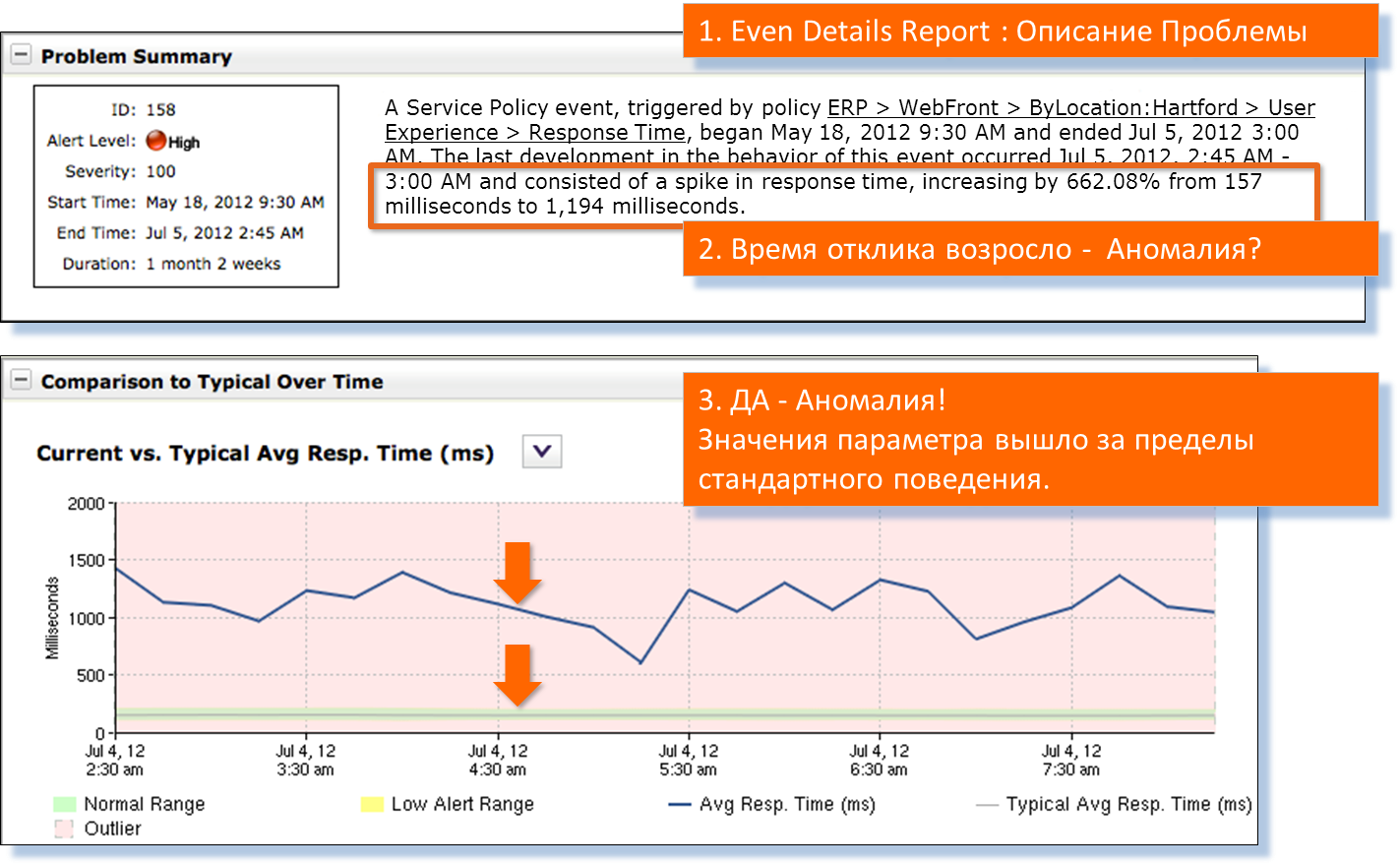
Зелёная черта внизу графика — нормальный профиль работы сервера. Такой должен быть при стабильной работе сервера.
На графике реальные значения времени отклика сервера показаны синим цветом. Прокручиваем отчёт ниже.

Смотрим на взаимодействие клиентов и серверов. Видно, что у всех клиентов есть проблемы в той или иной степени. При этом из кластера серверов проблема только у одного сервера.
Рассмотрим статистику проблемного сервера.

Видим MAC-адрес сервера, IP-адрес коммутатора и порт коммутатора, куда подключён сервер. Рассмотрим транзакции проблемного сервера в графической оболочке к Wireshark — Pilot Console.
На отчёте времени отклика сервера по объектам видно, что увеличено время предоставления лишь одного объекта.

Вот он, попался: complex.psp
Проверяем. Строим диаграмму взаимодействия по транзакциям. Проверяем:
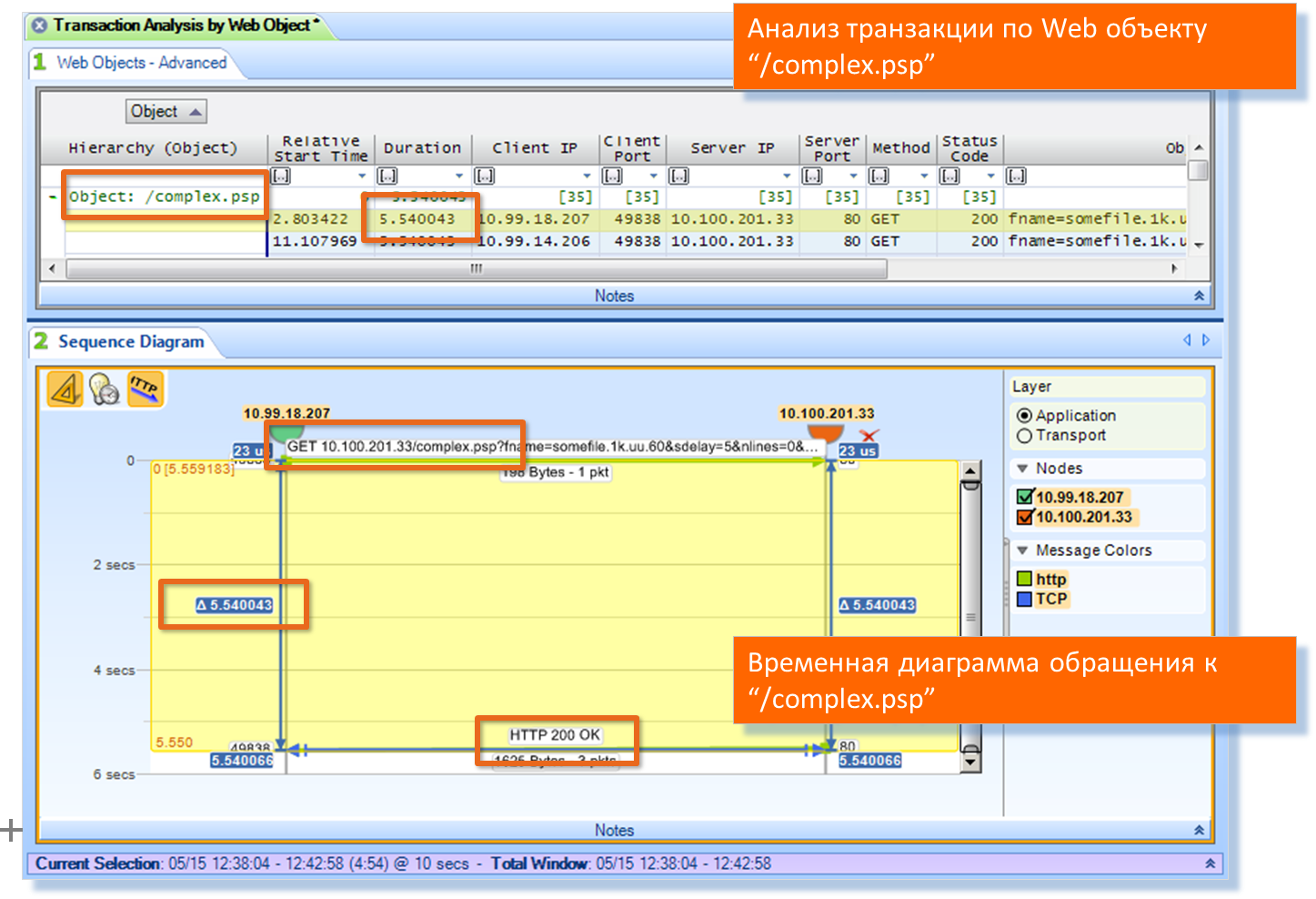
Да, это оно.
Если кто ещё не верит, пусть проверит — переходим к ручному пакетному анализу в Wireshark той же транзакции.

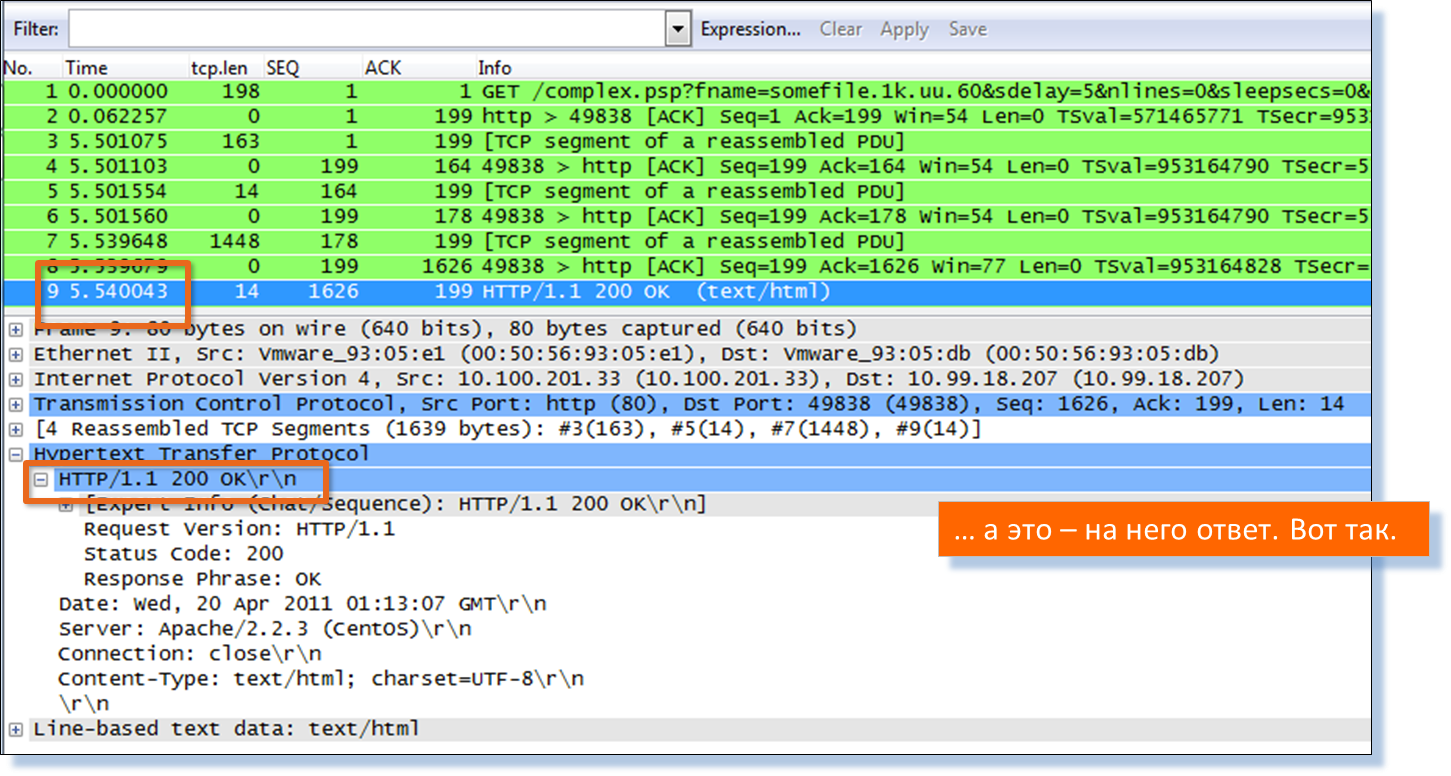
Итак, мы только что получили исчерпывающую картину взаимодействия пользователей с Web-серверами сервиса ERP, что позволило найти сбойный Web-сервер, а даже точнее, сбойный объект на сервере.
Локализация проблем с многоуровневыми приложениями
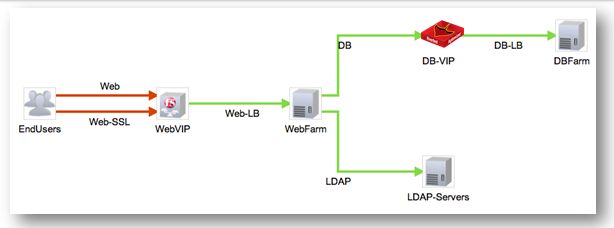
Видим картину многоуровневого приложения с указанием всех компонентов, включая балансировщики нагрузки трафика. Система визуально сразу даёт понять, на каком сегменте нужно анализировать деградацию сервиса в целом: красным цветом отмечен сегмент конечных пользователей при обращении к VIP-адресу балансировщика трафика. Дальше можно переходить к детальному анализу трафика на этом сегменте и анализу производительности балансировщика трафика. Нет необходимости анализировать каждый сегмент многоуровневого приложения вручную и разбираться, как взаимодействуют между собой компоненты этого приложения: при первом взгляде на карту взаимодействия компонентов приложения визуально всё становится понятно.
Совместимость с оптимизаторами трафика
В предыдущем посте я уже писал про устройства-оптимизаторы трафика, которые умеют отлично сжимать каналы данных и часто используются банками, телеком-операторами и другими крупными компаниями, а также средним и крупным бизнесом, стремящимся эффективнее использовать канал связи и ускорить работу приложений. Так вот, поскольку оптимизаторы — продукт того же производителя, сетевая статистика с них может собираться и с помощью системы мониторинга Riverbed Cascade. Два решения отлично (и дёшево, что важно) сочетаются, что комплексно решает проблемы производительности приложений компаний.
Вот эти показатели оптимизации трафика собраны как раз Riverbed Cascade:

Соотношение LAN-трафика (синий график) и WAN-трафика (зелёный график) с оптимизацией. Наглядно видно, насколько уменьшился объём трафика в канале связи
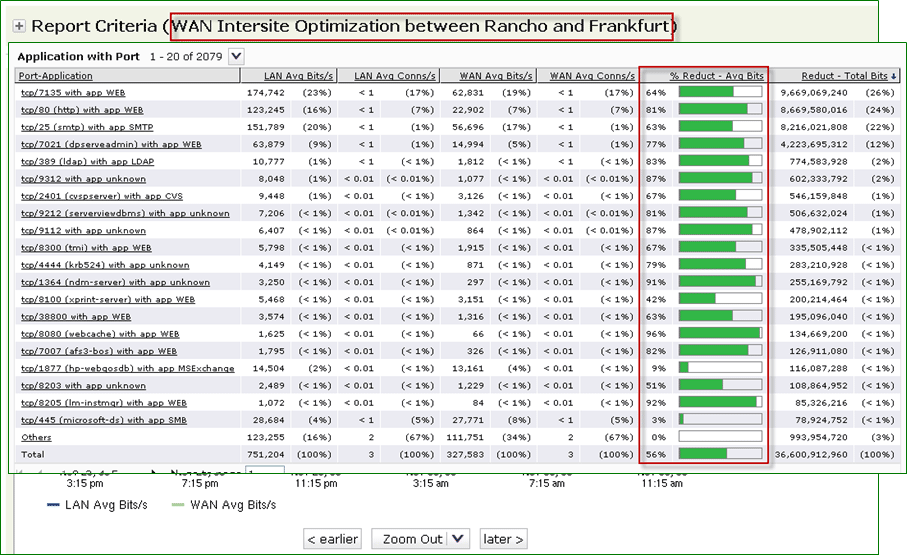
Оптимизация трафика с разбивкой по приложениям и процент уменьшения использования полосы пропускания каждого из них
Отчёты
Решение используется, естественно, не только для локализации проблем и аномалий в поведении трафика приложений. Очень удобно строить отчёты, например, для планирования развития инфраструктуры. К примеру, отчёт по объёмам трафика и его типам по филиалам позволяет найти город, который лидирует по трафику Citrix, и оценить пользу от оптимизации этого направления.
Можно искать проблемы как в историческом разрезе, так и в реальном времени по факту их появления (и вот здесь вы будете чертовски рады тому, что есть такой мощный помощник).
Экспертные системы
У решения Riverbed есть ещё одна прекрасная функция — поведенческая аналитика. Как известно, одной из важнейших задач является своевременное информирование заинтересованных лиц о деградации работы бизнес-сервисов. Обычно системы позволяют установить только фиксированные пороговые значения для метрик производительности работы приложений. Их должен придумать сам администратор.
Здесь же Riverbed Cascade обходит всех конкурентов: он снимает десятки метрик и строит профили нормального поведения каждой метрики. Пороговые значения ставить не надо, система соберёт историческую статистику, и на её основе будут сформированы пороговые значения. А при отклонении от нормы система проинформирует администратора или его руководителя.
Кроме аналитики производительности приложений в систему заложен функционал аналитики безопасности. А именно: система предупредит администратора в том случае, если:
- Пользователь сканирует сеть.
- Пользователь сканирует открытые порты.
- В сети появляется новый хост.
- Хост использует новый порт.
И даже если установленные антивирусные системы не видят распространение нового вируса в сети, Riverbed Cascade обнаружит распространение «червя» по появившемуся аномальному трафику.
Вопросы
Мы реализовали это решение (в комплекте с оптимизацией трафика) для золотодобывающей компании, для территориально распределённого банка, логистической компании, закончили проект для энергетической компании и ещё десятки проектов поменьше. Такая штука нужна в каждом ЦОДе, как мне кажется. В общем, если есть вопросы — задавайте на AVrublevsky@croc.ru либо в комментариях. Цены под вашу инфраструктуру могу тоже назвать в почте.
