Вступление
    Столкнувшись с задачей замониторить большое кол-во метрик в RabbitMQ кластере, появилось желание создать универсальный парсер для JSON данных. Задача усложнялась тем, что появляются и пропадают метрики динамически во время работы кластера, плюс к этому разработчики постоянно хотят собрать/посчитать что-то новое. К сожалению, в Zabbix нет возможности собирать данные в таком виде из коробки. Но есть такая удобная фича как zabbix_trapper, позволяющая делать гибкую кастомизацию. В статье пойдет речь о не сосвем стандартном способе использовании айтемов zabbix_trapper. Мне не хотелось каждый раз, когда разработчики попросят добавить новых метрик, изменять скрипт, который собирает данные и засылает в заббикс. Отсюда появилась идея использовать собственно сам zabbix key как инструкцию по сбору новой метрики. Суть в следующем, мы используем zabbix key как команду, с заранее заданным синтакисом. То есть zabbix key в этом случае будет служить инструкцией, подобной ключам типа zabbix_agent.
    Согласно официальной документации Zabbix, item key имеет некоторые ограничения на допустимые символы. Немного поиграв с созданием ключей типа zabbix trapper нашел, что к примеру ключ вида:
some.thing.here[one:two:three][foo=x,bar=y]
создаются в заббиксе без ошибок. То есть ограничения работают только на то, что вне [ ] скобок, также обязательно должен быть хотя бы один символ [a-z][A-Z] перед скобками. Имея возможность создавать такие ключи мы можем придумать свой синтаксис ключей и запрограммировать в нем довольно гибкую логику. Далее остается только написать обработчик придуманного синтаксиса который будет делать всю основную работу. И наконец, написав доку по этому обработчику и выложив код в паблик, у всего Zabbix community появится возможность обмениваться такими «как бы» плагинами.
    В целом статья получилась немного сложная для понимания, поэтому чтобы лучше понять концепцию, я бы советовал сначала ознакомиться с RabbitMQ API, хотя бы просто посмотреть как выглядят данные и что предоставляет API (см. офф сайт).
    Ссылки на код приведены в конце статьи.
Как это работает
    Сначала создаем в Zabbix фронт-енде айтемы типа zabbix_trapper согласно разработанному синтаксису(синтксис будет описан ниже). Далее запускаем обработчик (rmq_data_collect.pl — далее коллектор) в кроне с частотой сбора информации, скажем 1 минута. Теперь коллектор взаимодействует с Zabbix сервером и с сервером RabbitMQ как указано на схеме:
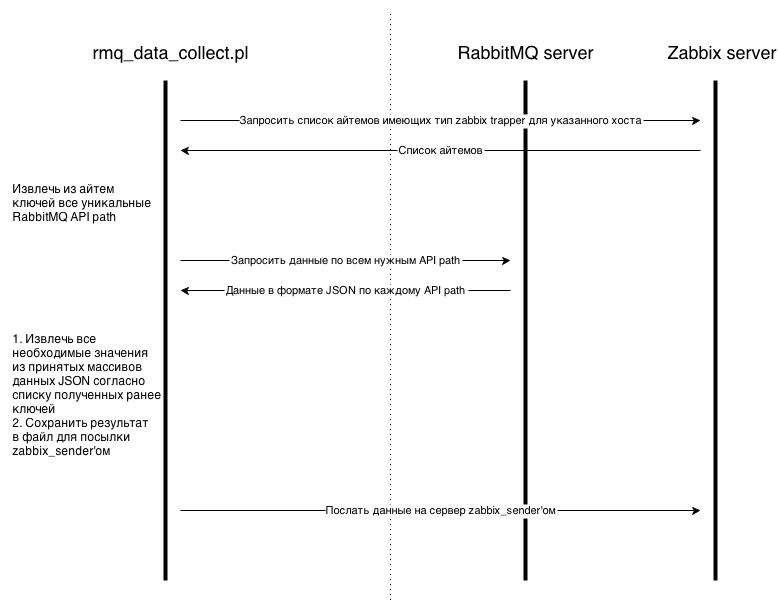
Т.е. скрипт делает 3 основных шага:
1) Запрашивает список айтемов с Zabbix сервера, которые должны быть собраны.
2) Забирает все необходимые данные с RabbitMQ согласно списку айтемов выше.
3) Отправляет все собранные данные на Zabbix сервер/прокси на соотв-ие айтемы.
    При первом обащении обработчик может взаимодействовать как через Zabbix API так и напрямую с базой. В моей реалзации взаимодействие происходит с базой Zabbix прокси. Этот подход удобней при использовании распределенного мониторинга с некоторым кол-вом Zabbix прокси серверов. В этом случае скрипт должен быть установлен на zabbix прокси сервере, а в конфигурации скрипта должны быть прописаны данные для коннекта к базе этой же прокси.
    Кроме обработчика будет также рассмотрен еще дискаверер, который используется для low level discovery. Далее пойдет речь о текущей реализации мониторинга для RabbitMQ, теория и примеры настройки.
Что реализовано
    В документации по RabbitMQ API описано 9 API url’ов + есть еще federation-links, который ставится отдельным плагином на реббит. Возможно есть и еще что-то. В текущей реализации моих скриптов возможен мониторинг следующих API path:
-nodes
-connections
-queues
-bindings
-federation-links
Для моих задач этого хватило, в случае если нужны еще какие-то API path то нужно дописать их в ф-ю map_rmq_elements (см. комментарии к коду).
Установка и настройка скриптов
    Для мониторинга RabbitMQ понадобится установить и настроить 2 скрипта (Collector и Discoverer) + ZabbixProxyDB.pm. Скрипты могут быть установлены как на Zabbix сервере так и на прокси, зависит от вашей конфигурации Zabbix.
Collector
rmq_data_collect.pl — Используется для обработки заббикс ключей и сбора данных с rabbitmq.
Использование
Имеет один входной параметр
$1 — полное имя RabbitMQ хоста в Zabbix, если RabbitMQ не запущен как кластер. В случае если реббит работает как кластер, $1 — это общая часть имени хостов в кластере, т.е. имена хостов в класере должны быть заданы по определенному правилу. Например имена хостов в кластере:
— rmq-host1
— rmq-host2
— rmq-host3
    В этом случае $1 должен быть “rmq-host". Скрипт запросит у Zabbix сервера/прокси список все хостов с именами, содержащими «rmq-host”, после чего пойдет по этому списку, запрашивая необходимые данные к RabbitMQ API. После первого успешного ответа от любого из хостов данные будут собраны и записаны в файл для отправки zabbix_sender’ом. На момент написания статьи имеется недоработка в коде, в случае если не один хост из кластера RabbitMQ не ответит то ничего не произойдет. В текущей реализации требования к именам хостов связаны с SQL запросом в базу, пока только так.
    Коллектор должен быть прописан в crontab с частотой равной частоте сбора данных с реббита. Список необходимых модулей можно посмотреть в самом скрипте.
Discoverer
rmq_data_discover.pl — Используется для низкоуровневого обнаружения в Zabbix (low level discovery или LLD).
Использование
Имеет 3 обязательных входных параметра:
$1 — полное имя RabbitMQ хоста в Zabbix, если RabbitMQ не запущен как кластер. Для кластера принцип тот же что у коллектора. После первого успешного ответа прохождение по списку остановится и начнется компиляция сообщения для низкоуровневого обнаружения (low level discovery).
$2 — regexp по которому произойдет отбор метрик в момент работы скрипта. Не путать с regexp фильтром на стороне Заббикс в настройках LLD. Такое разделение удобно в некоторых случаях.
$3 — RabbitMQ API path, любой из списка поддерживаемых (см. п. Что реализовано).
    Скрипт должен быть установлен в папку externalscripts, прописанную в конфигурации Zabbix прокси/сервера. Примеры настройки правил LLD приведены в конце статьи.
Пример конфигурации хостов в Zabbix
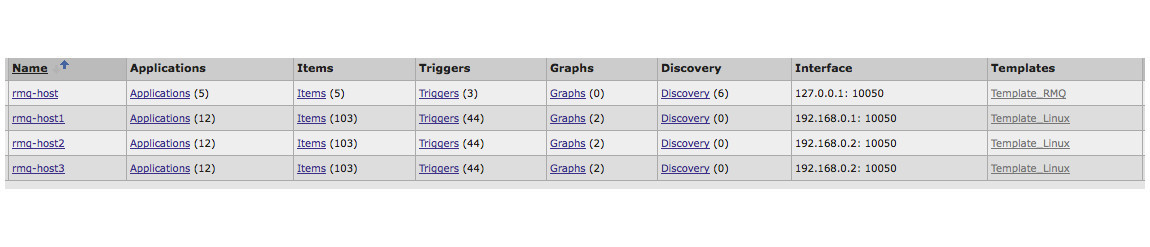
    Есть кластер rabbitmq состоящий из трех хостов. Сами хосты по отдельности мониторятся заббикс агентами, темплейт Template_Linux, где собраны стандартные метрики по CPU, memory и т.д. Для метрик кластера создан отдельный хост ”rmq-host». Имя хоста для всего кластера — общая часть имен хостов в кластере. Это обязательное условие в текущей реализации, иначе выборка из базы будет работать не корректно.
Синтаксис ключей
Теперь поговорим о разработанном мной синтаксисе для реббита. Как уже было сказано выше, в Zabbix айтемы должны иметь тип zabbix trapper.
Для мониторинга реббита Есть два типа item'ов, simple и aggregated, их синтаксис незначительно отличается. Simple айтемы используются для выборки значений отдельных параметров. Aggregated айтемы используются для выборки массива значений по заданному условию и их аггрегации. В обоих случаях условия может быть не указано(опционально).
Значения Simple
Синтаксис: <path.to.value.inside.json>[$type:$api_path:$element_name]
<path.to.value.inside.json> — Путь к значению внутри каждого элемента массива.
$type — может быть название VHOST или “general”, в случае VHOST поиск значений будет вестись по указанному VHOST, «general” — является ключевым словом, необходимым для значений, которые не относятся к конкретным VHOST’ам.
$api_path — RabbitMQ API path, любой из поддерживаемых (см. п. Что реализовано).
$element_name — это уникальный идентификатор элемента массива в указанном $api_path, для federation-links это exchange, для bindings это destination, для остальных name.
Значения Aggregated
Общий синтаксис: <path.to.value.inside.json|rmq>[aggregated:$api_path:$func][$conditions]
aggregated — является ключевым словом, после которого коллектор(rmq_data_collect.pl) понимает что синтаксис ключа должен быть разобран как для значения типа aggregated.
$api_path — путь к API, любой из поддерживаемых (см. п. Что реализовано).
$func — реализованы 2 функции, sum и count.
$conditions — опциональный параметр, если задан, то при аггрегации будут учитываться только те элементы в массиве данных, которые подходят под условие. Синтаксис условий следующий: [condition1=“cond1”,condition2=“cond2”,condition3=“cond3”,etc]. Кавычки обязательны. Само условие является Perl регекспом.
Функция sum
Синтаксис: <path.to.value.inside.json>[aggregated:$api_path:sum][$conditions]
Функция sum суммирует значения находящиеся по указанному пути <path.to.value.inside.json> внутри каждого элемента массива, полученного по $api_path, и подходящего под условие $conditions.
<path.to.value.inside.json> — Путь к значению внутри каждого элемента массива полученного по RabbitMQ API path.
Функция count
Синтаксис: rmq[aggregated:$api_path:count][$conditions]
Функция count считает кол-во элементов в массиве, полученном по $api_path, подходящих под условие .
rmq — является обязательным словом, но никак не используется(тут может быть абсолютно любой набор букв). Это связано с ограничениями Zabbix на ключ айтема типа “zabbix_trapper” — айтем не может начинаться с квадратной скобки.
Примеры
Агрегированые значения
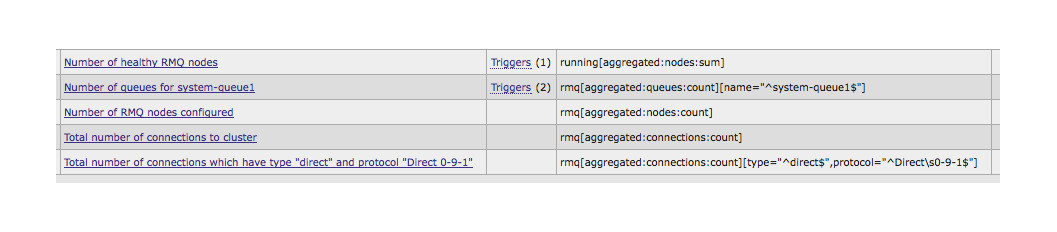
1) Считает сумму элементов running в массиве nodes. Прим: В случае если rabbitmq нода работает, running возвращает 1, соот-но на выходе получаем кол-во работающих нод.
2) Считает кол-во элементов в массиве queues, где name = ^system-queue1$. Т.к. значение условия всегда рассматривается как regexp необходимо задавать начало и конец строки (^ $) чтобы избежать ошибки в случае, если под regexp попадет что-то еще. На выходе получаем кол-во очередей с именем system-queues1
3) Считает общее кол-во элементов в массиве nodes. Т.е. кол-во настроенных нод в класетере.
4) Считает общее кол-во элементов в массиве connections. Т.е. кол-во соединений к кластеру в данный момент.
5) Считает кол-во элементов в массиве connections, у которых type=“^direct$” и protocol=»^Direct\s0-9-1$”.
Примеры для значений simple есть дальше в LLD. Т.к. задавать их статически не удобно, большинство очередей постоянно появляются и исчезают.
Low level discovery
В слуачае большой конфигурации rabbitmq кластера разумно будет использовать низкоуровневое обнаружение Zabbix. Использование rmq_data_discover.pl описано выше. Здесь я приведу примеры и значения возвращаемые скриптом.
Значение, возвращаемые скриптом и которые можно использовать в LLD:
Connections
"{#VHOST}" => $vhost,
"{#NAME}" => $name,
"{#NODE}" => $node,
Nodes
"{#NODENAME}" => $name,
Bindings
"{#SOURCE}" => $queueSource,
"{#VHOST}" => $vhost,
"{#DESTINATION}" => $queueDest,
"{#THRESHOLD}" => $threshold,
Замечание: все элементы с пустым source игнорируются.
Queues
"{#VHOST}" => $vhost,
"{#QUEUE}" => $queueName,
Federations
“{#VHOST”} => $vhost,
“{#EXCHANGE} => $name
Примеры LLD
Примеры запуска правил для каждого API path:

Примеры айтем прототипов
В API path queues мы можем собирать статистику по обработанным сообщениям, не заботясь о кол-ве очередей.
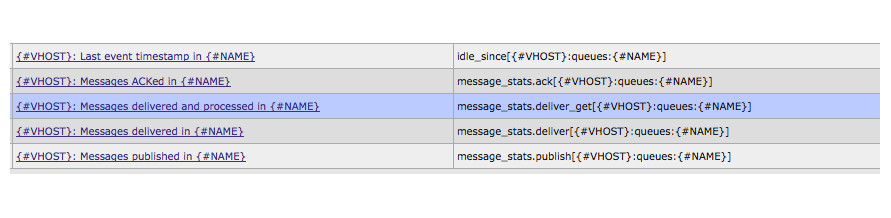
1) Значение поля idle_since. Единственное поле которое имеет обработку внутри rmq_data_collector.pl. Как результат получаем timestamp, с момента которого очередь неактивна.
2) Значение ack внутри элемента message_stats.
3) Оставшиеся значения работают с message_stats также как п.2
Пример для connections

Айтем подсчитывает кол-во элементов в массиве connections с заданными type,protocol для каждого {#VHOST}.
Пример для nodes

1) Считает кол-во соединений к каждой ноде.
2) Возвращает значение поля running для каждого элемента массива nodes. На выходе получаем health статус каждой ноды.
Подведем итог
    Надеюсь получилось не слишком запутанно. Если что то не понятно, отвечу на все вопросы в комментариях.
    Преимущество описанного подхода в создании кастомных ключей, специализированных для какого то конкретного софта, очевидно. Нет необходимости в изменении кода самого Zabbix. Уже сейчас мы можем создавать такие плагины, писать по ним документацию и обмениваться готовыми решениями в интернете. Если развивать идею создания кастомизированных ключей в Zabbix дальше, то в идеале хотелось бы видеть это, возможно, в виде новой фичи. Имея подобный плагин теперь, когда нужно добавить какуюто новую метрику по RabbitMQ, нужно просто создать соотв-ий айтем, как это делается для zabbix_agent.
    Код скриптов тут: github.com/mfocuz/zabbix_plugins
