По сути, опубликованное ниже является моим комментарием к публикации «Что такое «Понятный русский язык» с точки зрения технологий. Заглянем в метрики удобочитаемости текстов». Поскольку я не могу оставлять комментарии, то пишу в «Песочницу».
Критерии оценки понятности текстов, которые были рассмотрены в посте, опираются на практически нулевые знания о языке, на котором эти тексты написаны: достаточно знать, как он делится на слова и предложения. Этот подход удобен в плане простоты вычислений, но не позволяет использовать много релевантных данных. Как мне кажется, в случае с русским языком очевидно, что еще можно использовать, и эти данные легкодоступны.
По-моему, непонятность имеет смысл делить на два вида:
(а) глубинная непонятность (когда никак невозможно разобрать, что написано);
(б) непонятность, связанная со сложностью.
Непонятность типа (а), которой пропитан каждый второй, если не просто каждый, официальный документ, связана с тем, что люди попросту не умеют выражать свои мысли. То, что кажется понятным в голове и как-то удается объяснить «на словах», оказывается невозможно перенести на бумагу: обороты не закрываются, анафоры переплетаются, сочинение объединяет вещи, которым лучше вместе не быть, и так далее. В чистом случае отличить это автоматически от нормального текста сложно: часто даже людям, которые читают текст поверхностно, кажется, что он более или менее ничего, а потом оказывается, что это какой-то омут. Тем более невозможно автоматически это исправить: сначала приходится садиться с автором и долго у него выпытывать, что, собственно, он имел в виду. Но, к счастью, эта непонятность почти всегда влечет за собой непонятность типа (б), поэтому по крайней мере выявлять непонятные тексты можно.
Непонятность = сложность подразумевает, что люди используют какие-то нетривиальные языковые средства, которые без образования и/или приложения недюжинных усилий плохо понятны. И здесь мы сталкиваемся с опосредованной природой традиционных метрик. Длинных предложений, конечно, лучше избегать, но длинное предложение как таковое не синоним темноты: простое перечисление может сделать предложение длинным, не обязательно делая его непонятным. Использование длинных слов тоже не делает текст заведомо непонятным. В конце концов технический язык никто не отменял, и невозможно все тонкости передать простыми словами, не говоря уже о том, что в официальных документах не обойтись без «осуществления», «приведения» и тому подобных многобуквенных вещей. Другими словами, если не придумывать все время новых терминов, то постепенно люди начнут говорить на одном языке.
Мне кажется, что сложность типа (б) — это в первую очередь синтаксическая, или риторическая, сложность. Канцелярит обычно характерен тем, что дерево разбора фраз бытро пробивает потолок, и это характерно почти для любых «темных» текстов. Чтобы сделать тексты более понятными, нам надо сделать их структурно простыми. И это очень просто: в подавляющем большинстве случаев синтаксическая сложность достигается за счет использования одного-единственного средства — причастий действительного залога. Попробуйте написать запутанный текст без активных причастий, и вы увидите, что это практически невозможно. Или у вас будет получаться полный абсурд, или предложения по необходимости станут короче — и понятнее. Тезис о том, что русские люди в разговорной речи не используют причастий и деепричастий, стар как мир. Он не совсем верен — я знаю людей, которые используют в речи причастия и деепричастия, я сам их использую, — но не подлежит сомнению, что в первую очередь это принадлежность письменного языка и следствие попытки писать по-русски как Цицерон (или кого из греков копировали люди, которые запустили второе южнославянское влияние).
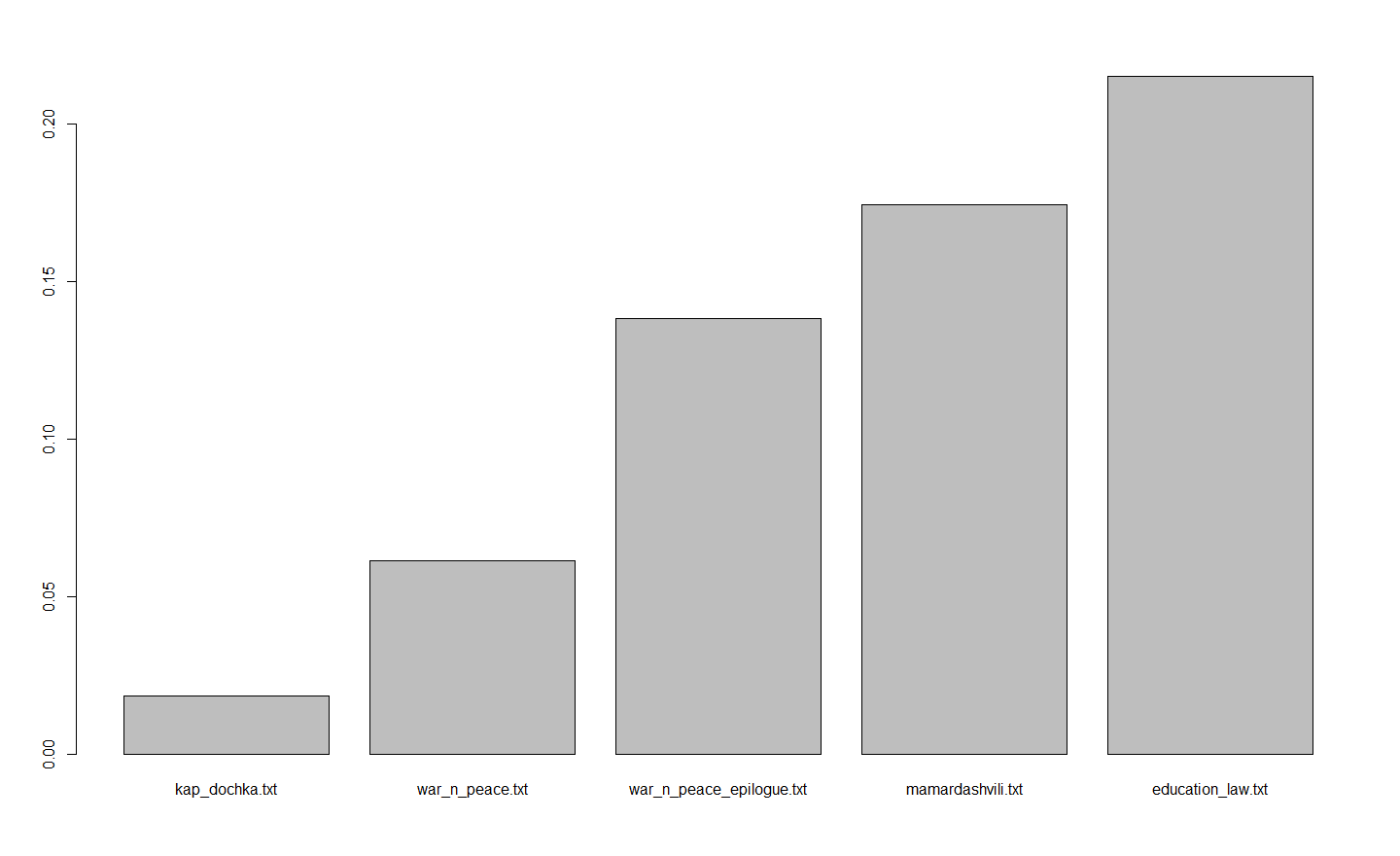
Я не утверждаю, что это единственно верный способ оценить понятность текста, но я почти уверен, что количество активных причастий выявит сложный русский текст не хуже любой другой однофакторной метрики. Для прикидочной проверки я взял пять текстов: «Капитанскую дочку», «Войну и мир», отдельно эпилог к «Войне и миру», славный своей удопонятностью, «Классический и неклассический идеалы рациональности» Мераба Мамардашвили (современный философский текст русскоязычного автора) и федеральный закон «Об образовании в Российской Федерации». Я поделил тексты на предложения и при помощи Python 3 + pymorphy2 посчитал среднее количество активных причастий в каждом из них. Результат получился предсказуемый, но все равно красноречивый:
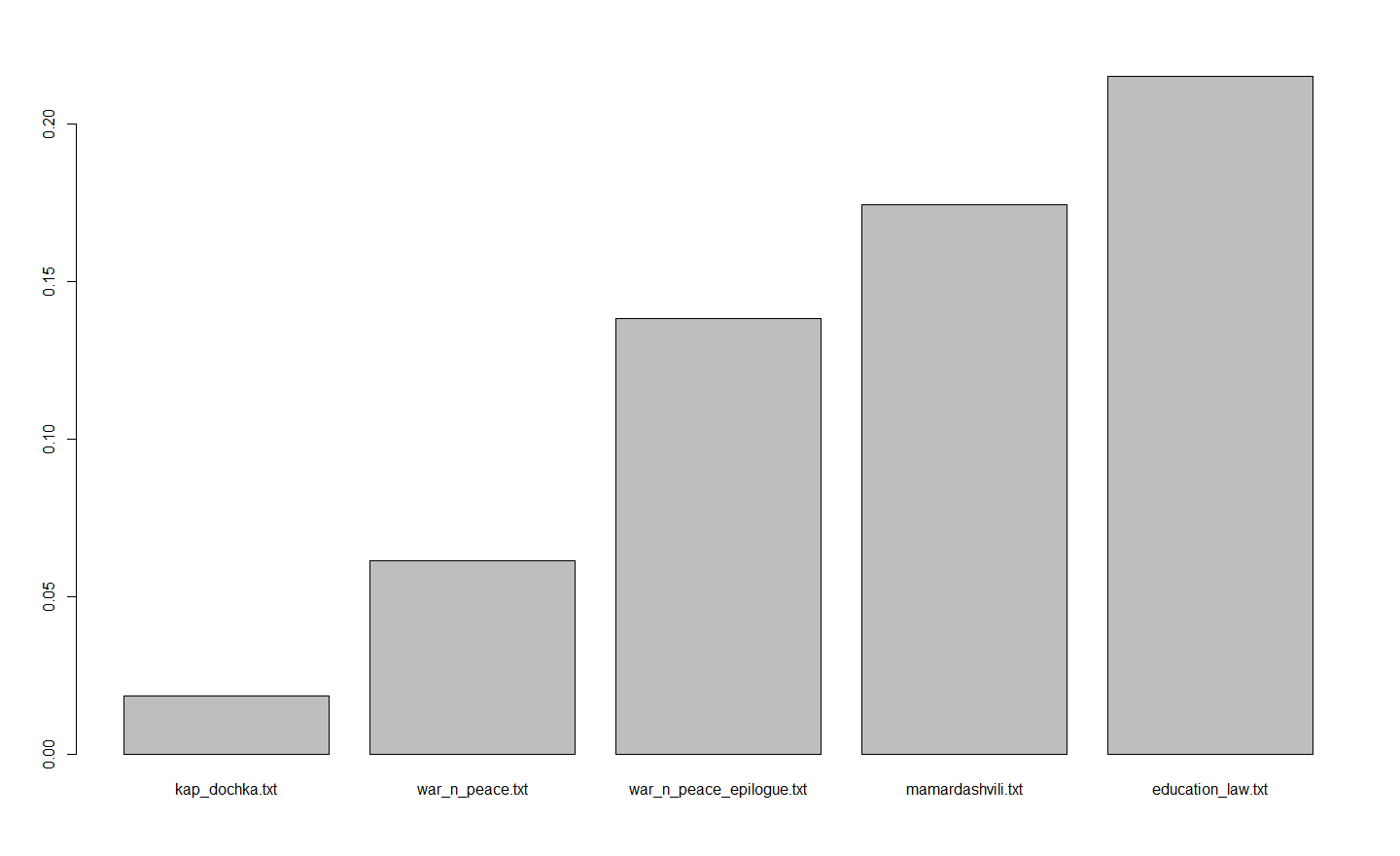
Сервис, предложенный в посте, дает следующие результаты:

С полным текстом «Войны и мира» он с двух попыток не справился — было бы интересно узнать, в чем там дело. Мы видим, что очередность в рейтинге совпадает, но если мерить по причастиям, разница между Законом об образовании и «Капитанской дочкой», а также между эпилогом к «Войне и миру» и текстом Мамардашвили оказывается выше. Не поручусь насчет абсолютных значений, но подозреваю, что текст Мамардашвили сложнее текста Толстого.
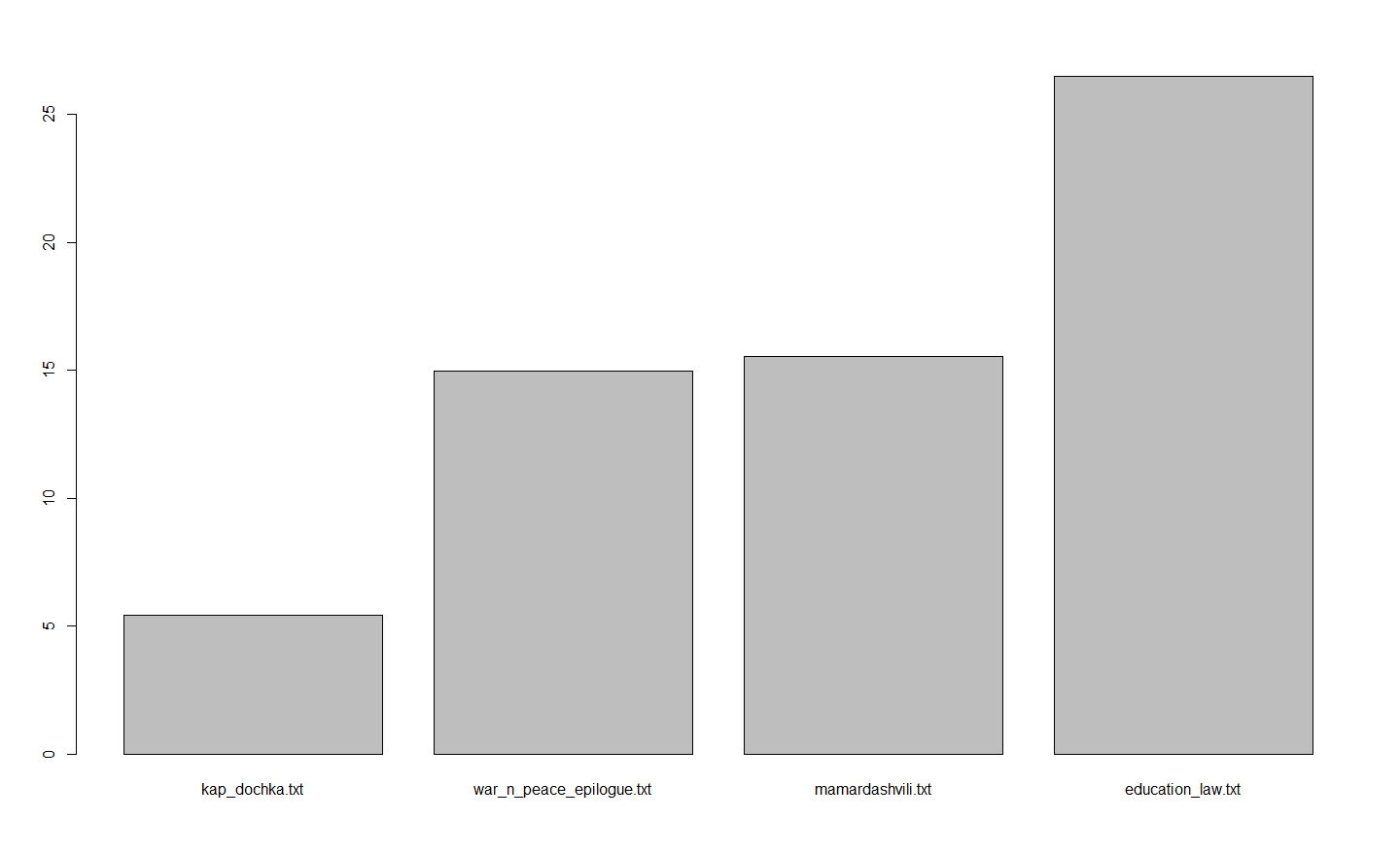
Если зайти с другой стороны, то оказывается, что текст Мамардашвили — самый сложный из всех. Сложность слов можно считать не только по их длине, но и по встречаемости в текстах. Редкое слово = сложное. Чтобы измерить редкость слов, я взял данные о частотности, опубликованные на сайте НКРЯ, и для каждого текста сделал массив, где каждому слову соответствовало число = 1 / встречаемость (т.е. редкость слова). В таблице НКРЯ самые редкие слова имеют встречаемость 3, поэтому если слова в таблице не было, оно получало редкость 1/2. Затем я посчитал среднюю словарную редкость для всех текстов. В этом рейтинге «Война и мир» целиком обогнала эпилог (там нет французского), а еще выше оказались «Капитанская дочка» (много нетривиальных написаний), Закон об образовании и, с отрывом, «Идеалы». Это немного кривой результат, но он показывает, насколько специфический текст у Мамардашвили. Если же перемножить данные по причастиям и данные по словам, получается следующий рейтинг, на мой взгляд, весьма осмысленный:
Критерии оценки понятности текстов, которые были рассмотрены в посте, опираются на практически нулевые знания о языке, на котором эти тексты написаны: достаточно знать, как он делится на слова и предложения. Этот подход удобен в плане простоты вычислений, но не позволяет использовать много релевантных данных. Как мне кажется, в случае с русским языком очевидно, что еще можно использовать, и эти данные легкодоступны.
По-моему, непонятность имеет смысл делить на два вида:
(а) глубинная непонятность (когда никак невозможно разобрать, что написано);
(б) непонятность, связанная со сложностью.
Непонятность типа (а), которой пропитан каждый второй, если не просто каждый, официальный документ, связана с тем, что люди попросту не умеют выражать свои мысли. То, что кажется понятным в голове и как-то удается объяснить «на словах», оказывается невозможно перенести на бумагу: обороты не закрываются, анафоры переплетаются, сочинение объединяет вещи, которым лучше вместе не быть, и так далее. В чистом случае отличить это автоматически от нормального текста сложно: часто даже людям, которые читают текст поверхностно, кажется, что он более или менее ничего, а потом оказывается, что это какой-то омут. Тем более невозможно автоматически это исправить: сначала приходится садиться с автором и долго у него выпытывать, что, собственно, он имел в виду. Но, к счастью, эта непонятность почти всегда влечет за собой непонятность типа (б), поэтому по крайней мере выявлять непонятные тексты можно.
Непонятность = сложность подразумевает, что люди используют какие-то нетривиальные языковые средства, которые без образования и/или приложения недюжинных усилий плохо понятны. И здесь мы сталкиваемся с опосредованной природой традиционных метрик. Длинных предложений, конечно, лучше избегать, но длинное предложение как таковое не синоним темноты: простое перечисление может сделать предложение длинным, не обязательно делая его непонятным. Использование длинных слов тоже не делает текст заведомо непонятным. В конце концов технический язык никто не отменял, и невозможно все тонкости передать простыми словами, не говоря уже о том, что в официальных документах не обойтись без «осуществления», «приведения» и тому подобных многобуквенных вещей. Другими словами, если не придумывать все время новых терминов, то постепенно люди начнут говорить на одном языке.
Мне кажется, что сложность типа (б) — это в первую очередь синтаксическая, или риторическая, сложность. Канцелярит обычно характерен тем, что дерево разбора фраз бытро пробивает потолок, и это характерно почти для любых «темных» текстов. Чтобы сделать тексты более понятными, нам надо сделать их структурно простыми. И это очень просто: в подавляющем большинстве случаев синтаксическая сложность достигается за счет использования одного-единственного средства — причастий действительного залога. Попробуйте написать запутанный текст без активных причастий, и вы увидите, что это практически невозможно. Или у вас будет получаться полный абсурд, или предложения по необходимости станут короче — и понятнее. Тезис о том, что русские люди в разговорной речи не используют причастий и деепричастий, стар как мир. Он не совсем верен — я знаю людей, которые используют в речи причастия и деепричастия, я сам их использую, — но не подлежит сомнению, что в первую очередь это принадлежность письменного языка и следствие попытки писать по-русски как Цицерон (или кого из греков копировали люди, которые запустили второе южнославянское влияние).
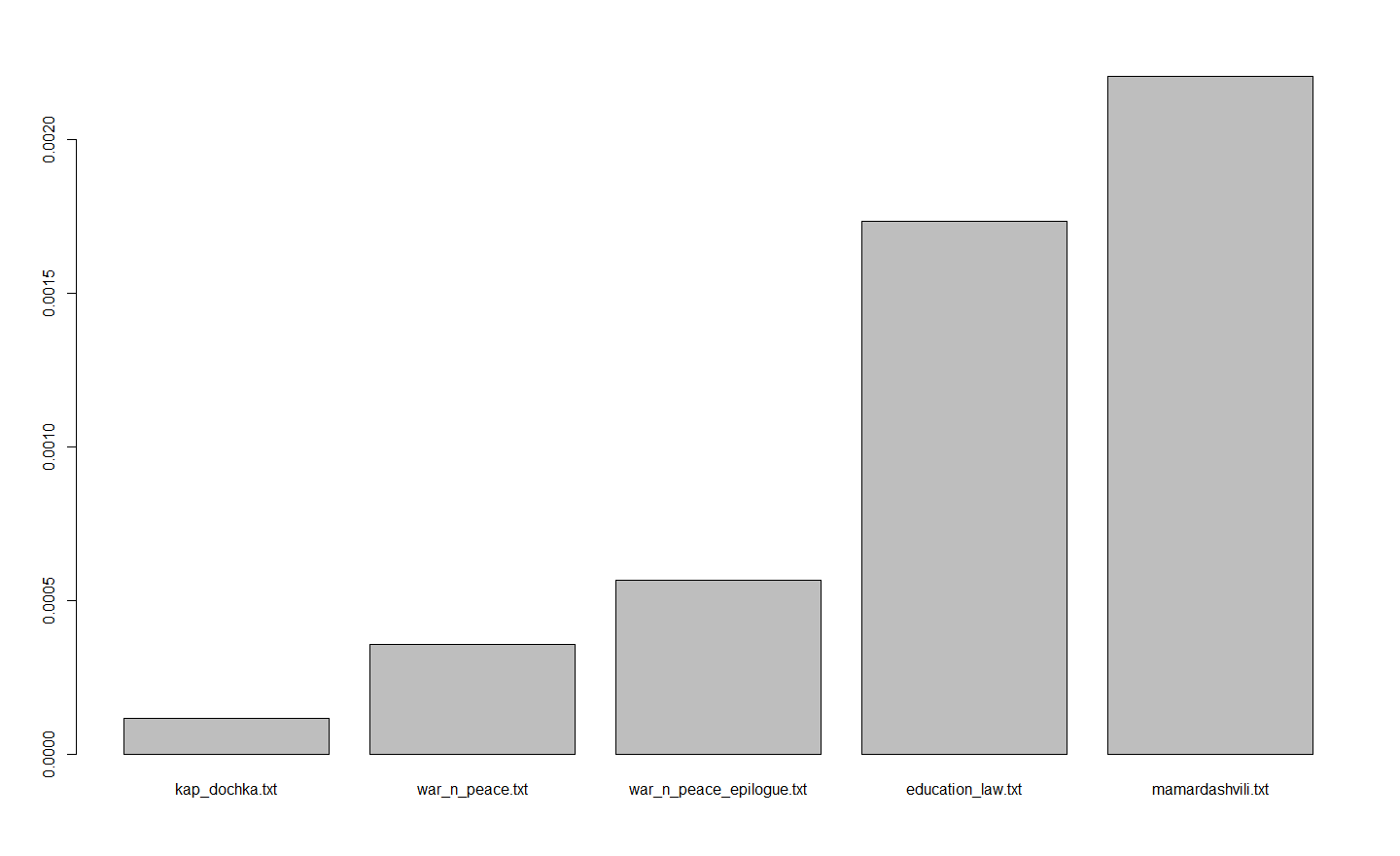
Я не утверждаю, что это единственно верный способ оценить понятность текста, но я почти уверен, что количество активных причастий выявит сложный русский текст не хуже любой другой однофакторной метрики. Для прикидочной проверки я взял пять текстов: «Капитанскую дочку», «Войну и мир», отдельно эпилог к «Войне и миру», славный своей удопонятностью, «Классический и неклассический идеалы рациональности» Мераба Мамардашвили (современный философский текст русскоязычного автора) и федеральный закон «Об образовании в Российской Федерации». Я поделил тексты на предложения и при помощи Python 3 + pymorphy2 посчитал среднее количество активных причастий в каждом из них. Результат получился предсказуемый, но все равно красноречивый:
Сервис, предложенный в посте, дает следующие результаты:
С полным текстом «Войны и мира» он с двух попыток не справился — было бы интересно узнать, в чем там дело. Мы видим, что очередность в рейтинге совпадает, но если мерить по причастиям, разница между Законом об образовании и «Капитанской дочкой», а также между эпилогом к «Войне и миру» и текстом Мамардашвили оказывается выше. Не поручусь насчет абсолютных значений, но подозреваю, что текст Мамардашвили сложнее текста Толстого.
Если зайти с другой стороны, то оказывается, что текст Мамардашвили — самый сложный из всех. Сложность слов можно считать не только по их длине, но и по встречаемости в текстах. Редкое слово = сложное. Чтобы измерить редкость слов, я взял данные о частотности, опубликованные на сайте НКРЯ, и для каждого текста сделал массив, где каждому слову соответствовало число = 1 / встречаемость (т.е. редкость слова). В таблице НКРЯ самые редкие слова имеют встречаемость 3, поэтому если слова в таблице не было, оно получало редкость 1/2. Затем я посчитал среднюю словарную редкость для всех текстов. В этом рейтинге «Война и мир» целиком обогнала эпилог (там нет французского), а еще выше оказались «Капитанская дочка» (много нетривиальных написаний), Закон об образовании и, с отрывом, «Идеалы». Это немного кривой результат, но он показывает, насколько специфический текст у Мамардашвили. Если же перемножить данные по причастиям и данные по словам, получается следующий рейтинг, на мой взгляд, весьма осмысленный:

