Недавно я познакомился с новым производителем серверного оборудования и ПО виртуализации под названием Stratus Technologies. И хотя этот рынок уже давно поделен между всем известными производителями, их решения все равно нашли свою нишу, так как они решили не изобретать велосипед, а предлагать рынку узко специализированные продукты, практически не имеющие аналогов.
На текущий момент продуктовый портфель Stratus Technologies состоит из 2 решений:
1. Аппаратное решение, заменяющее собой кластер из 2-х серверов, называющееся ftServer.
2. Программный продукт — гипервизор everRun.
Получить дистрибутив ПО для тестов намного проще, чем двух-нодовую железку, поэтому в первую очередь я смог оценить именно гипервизор everRun. Ниже вы сможете ознакомиться с результатами.

В текущие тяжелые времена во многих компаниях наблюдается дефицит бюджетирования ИТ-проектов, особенно в валютном показателе. Однако требования к надежности и отказоустойчивости критичных систем никто не отменял. И перед многими возникает вопрос: как обеспечить резервирование систем?
Рассмотрим возможный сценарий: вам необходимо обеспечить систему контроля температуры в одном конкретном хранилище сырья. Пусть это будет… цистерна с молоком. С точки зрения производительности нам вполне достаточно одного узла, допустим даже десктопа вместо полноценного сервера. Однако надежность такой системы должна быть на высоком уровне, который никакой stand-alone узел нам никогда не обеспечит.
Да, всегда можно поднять такую систему на кластере серверной виртуализации, но что делать компаниям, у которых серверная виртуализация не реализована, или же нет свободных ресурсов? Все же расширение кластера VMWare достаточно затратно, как с точки зрения железа, так и в отношении софта и лицензирования.
Именно здесь возникает достаточно логичная и, на первый взгляд, очевидная идея: взять 2 одинаковых узла из «ненужного зоопарка» (десктоп, списанный сервер и т.д.), связать их и кластеризовать. У такой системы должно быть несколько отличительных черт:
1. Возможность зеркалирования локальных дисков узлов для возможности миграции системы между узлами;
2. Возможность зеркалирования оперативной памяти и кеша процессоров для обеспечения функциии FT;
3. Данное решение должно обладать разумной стоимостью.
И на первый взгляд Stratus everRun обладает всеми перечисленными чертами
Рассмотрим подробнее, что же может наш «герой».
В основе решения лежит технология Checkpointing, позволяющая синхронизировать узлы кластера таким образом, что выход из строя одного из них не приводит к простою нашего приложения ни на долю секунды.
Главная идея, лежащая в основе технологии: репликация состояния гостевой виртуальной машины между двумя независимыми узлами при помощи чекпоинтов – контрольных точек состояния, включающих в себя абсолютно всё: регистры процессора, dirty pages, и т.д. На момент создания чекпоинта, гостевая ВМ замораживается и размораживается только после подтверждения (ACK) получения чекпоинта второй системой. Контрольная точка создается от 50 до 500 раз в секунду, в зависимости от текущей загрузки ВМ. Скорость определяется непосредственно алгоритмом и не подлежит ручной настройке. Таким образом, виртуальная машина живет на двух серверах одновременно. В случае сбоя основного узла – ВМ запускается на резервном с последнего полученного чекпоинта, без потери данных и какого-либо простоя.
Stratus everRun является bare-metal гипервизором на базе продукта KVM. Такое наследие добавляет несколько нюансов в его функциональность, но об этом позже.
Для работы данного продукта нам необходимо 2 одинаковые ноды, которые будут связаны между собой каналом Ethernet.
При этом требования к этим нодам достаточно демократичны:
• От 1 до 2 сокетов.
• От 8 Гб RAM.
• Минимум 2 жестких диска на ноду (для соблюдения отказоустойчивости на уровне 1й ноды).
• Минимум 2 порта 1 GE на ноду. Первый порт отводится для интерконнекта между нодами (называется A-link). Второй — под управляющую сеть и сеть передачи данных. При этом эти сети могут быть разнесены по разным портам при их наличии. Обязательным требованием к каналу интерконнекта является наличие задержки не более чем в 2 мс (для реализации функции FT).
Лицензирование производится по привычной для нас схеме — 1 лицензия на 2 процессора пары. Это означает, что для кластеризации 2х нод нам потребуется только 1 лицензия. Кластеризация более чем двух нод и более чем двух процессоров на ноду на текущий момент не поддерживается.
Существуют разные уровни лицензии: Express и Enterprise.
Express имеет ограниченную функциональность и позволяет обеспечивать отказоустойчивость VM на уровне HA. Это означает, что нет зеркалирования на уровне кеша процессора не применяется описанная выше технология checkpointing. Только репликация дисков и отказоустойчивость на уровне сети. Выход из строя одной из нод приведет к остановке работы VM на время ее перезапуска на втором узле.
Лицензия Enterprise обладает полной функциональностью, и обеспечивает защиту на уровне FT. Выход из строя одной из нод не приведет к простою VM. Однако, это накладывает дополнительную нагрузку на A-link, и поэтому для обеспечения FT без влияния на производительность VM рекомендуется использовать в качестве A-link канал 10 GE.
Теперь перейдем к практике — тестированию.
Для тестирования данного продукта мне были выделены 2 бюджетных сервера SuperMicro в следующей конфигурации:
Не самое лучшее железо, но и не десктоп.
Смонтировав их в одну стойку непосредственно друг над другом и скоммутировав через свитч я приступил к установке ПО.
Уже на этом этапе нас ждут интересные нюансы:
• На текущий момент в листе совместимости нет некоторых распространенных блейдовых решений. В чем причина несовместимости именно с блейдами — неизвестно. Я попробовал установить данное ПО на имеющиеся у меня в лабе IBM FlexSystem и потерпел полный крах.
• Дистрибутив обязательно должен быть записан на физический носитель DVD. Никакого монтирования ISO через консоль IPMI, никаких загрузочных USB. Только DVD, только хардкор. К счастью, у меня нашелся внешний DVD-привод.
Визард основывается на CentOS и имеет достаточно знакомый интерфейс.
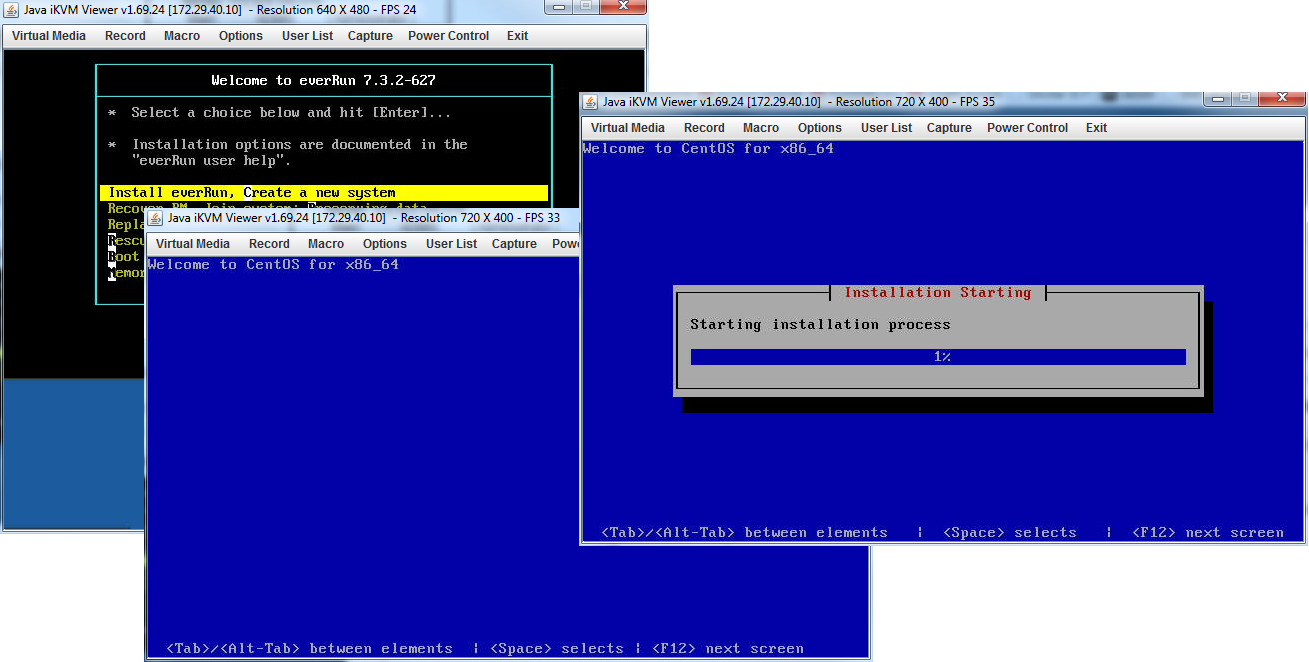
Сам по себе процесс установки достаточно прост:
• Устанавливаем ПО на первую ноду. В процессе инсталляции необходимо выбрать раздел, выбрать порты для A-link и управляющей сетей и прописать необходимые IP-адреса и root-пароль.
• Устанавливаем ПО на вторую ноду. При этом мы выбираем только установочный раздел и порты. Всю остальную информацию он копирует с основной (первой) ноды в процессе инсталляции.
После окончания установки ПО на ноды необходимо подключиться к основной ноде по IP-адресу управляющего порта. Перед нами откроется интерфейс настройки реквизитов доступа к web-интерфейсу и активации лицензии.
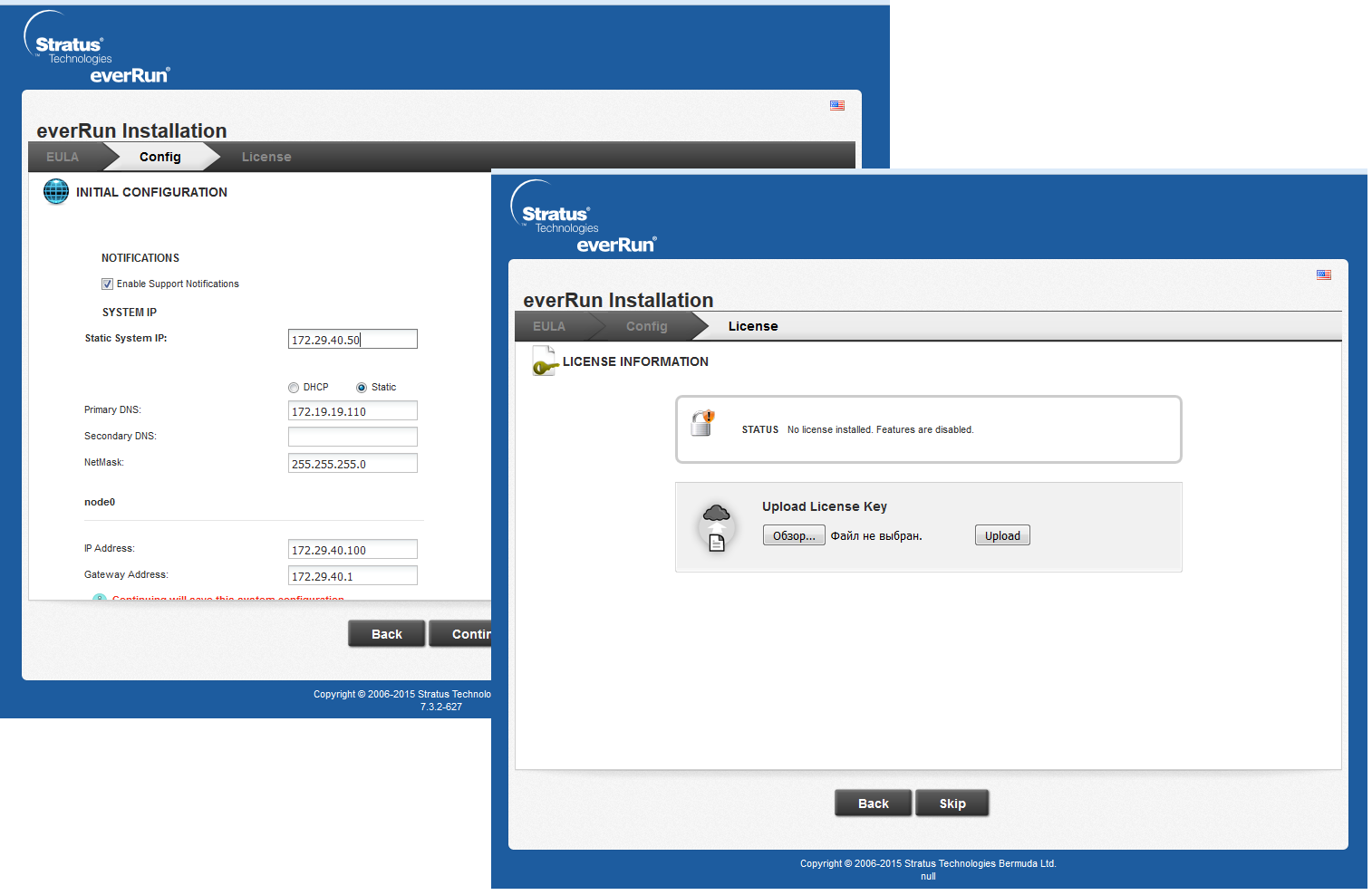
Таким образом, у нас получается пул из 5 адресов: 2 адреса IPMI-портов ноды, 2 адреса управляющих портов нод и 1 адрес web-интерфейса.
Интерфейс у everRun достаточно просто и симпатичный.

Как видно на скриншоте Dashboard у меня после установки вторая нода осталась в maintenance-режиме. С чем это связано я так и не понял, возможно какие-то неточности в установке с моей стороны. Проблема решилась переводом ноды в обычный режим руками через соответствующий раздел меню.
Как мы можем увидеть в разделе System, everRun «съедает» 2 ядра процессорных мощностей на собственные нужды. При этом допустИм overprovisioning.
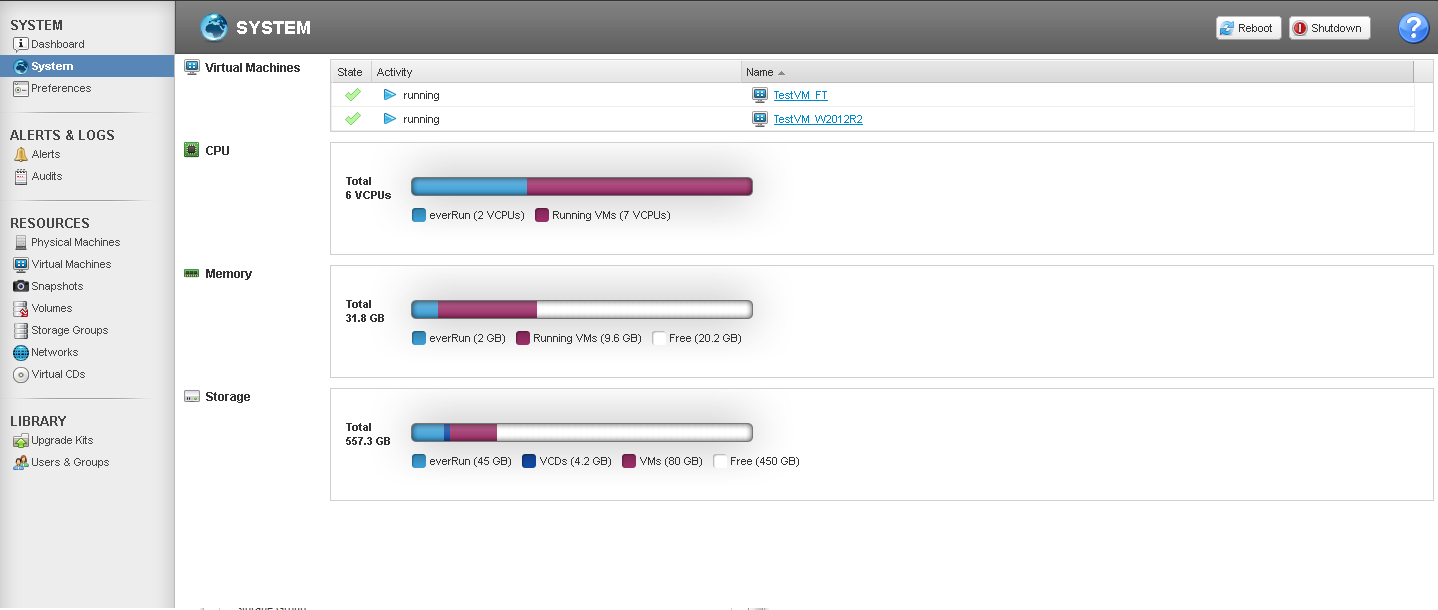
Помимо этого, присутствуют накладные расходы по ядрам, зависящие от уровня защиты. В случае с HA на VM с n ядрами будет уходить n+1 ядер кластера, а в случае с FT — n+2. Таким образом на HA VM 4 vCPU будет выделено 5 ядер кластера, а на FT VM 6 vCPU уйдет все 8 ядер (при этом в случае с многопользовательскими инсталляциями будет добавляться по n+2 на каждого пользователя).
Примечательно, что максимальное количество vCPU, поддерживаемое в FT VM — 8, а это достаточно интересный показатель. Для сравнения, vCenter Server (ver 6.x) позволяет создавать FT VM только до 4 vCPU (а в версиях 5.x — до 1 vCPU), что значительно сужает сферу использования данной функции.
Создание VM тоже имеет ряд нюансов, при этом достаточно неприятных. Для создания новой VM нам необходим ISO-образ дистрибутива ОС. Он должен обязательно находится на локальном томе кластера. Загрузить его туда можно только через web-интерфейс, нажав на соответствующую кнопку меню.
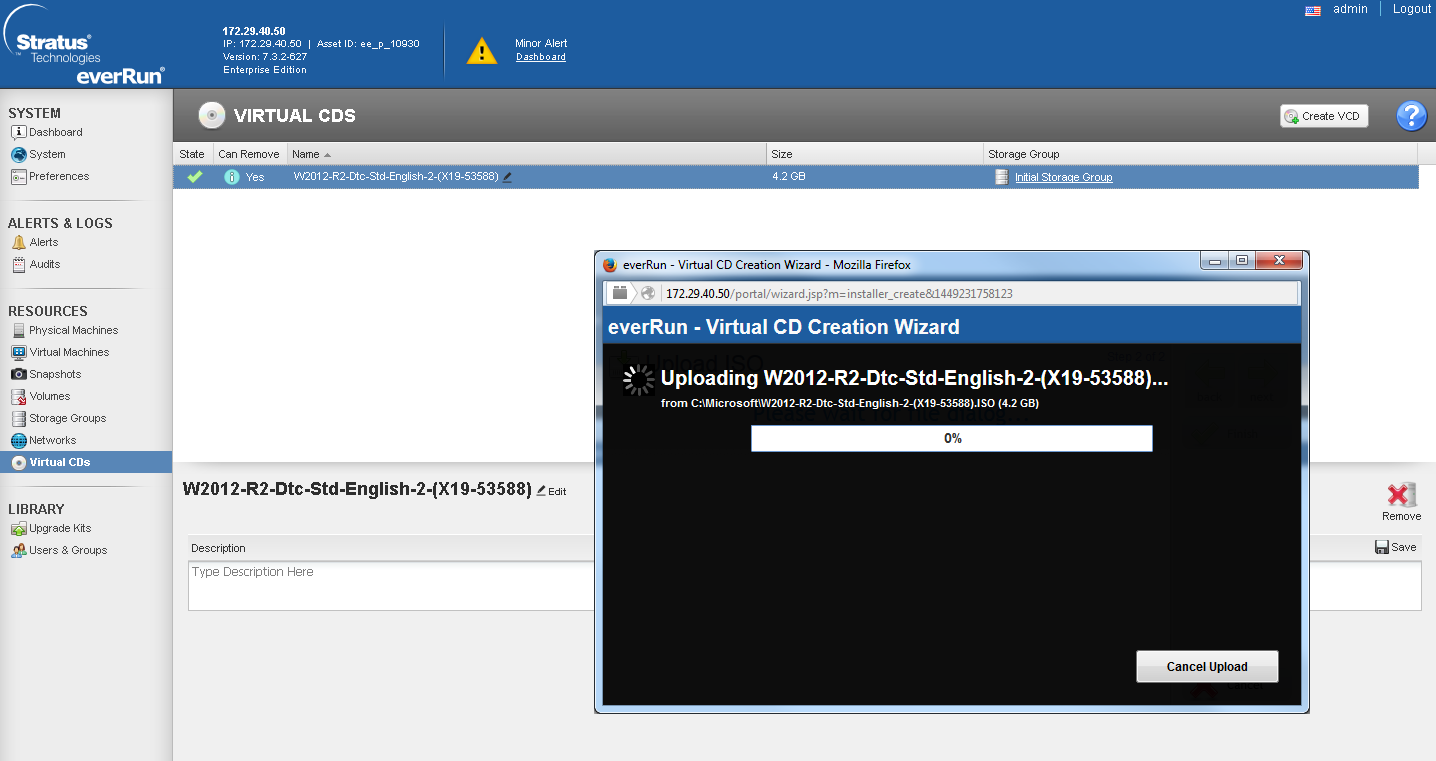
Это приводит к тому, что вы вынуждены загружать по сети ISO-образ с удаленного ПК. Это либо забьет весь канал, либо будет продолжаться неприлично долго. Например, образ Win 2012 R2 весом в 4,2 Гб я заливал ~4 часа. Отсюда вытекает и вторая неприятная особенность: everRun не позволяет пробрасывать USB носители и PCE-E устройства внутрь виртуалок. Т.е. все возможные USB-токены или GPU невозможно использовать. В защиту решения можно отметить, что проброс USB-носителей непосредственно в узел кластера заметно снижает отказоустойчивость системы (так как при выходе узла из строя вам необходимо будет вручную переподключать данные носители), а проброс GPU и дальнейшая репликация нагрузки на GPU в режиме FT является крайне затратным делом с точки зрения системы. Но все равно, этот факт резко сужает область применения данного решения.
После того как дистрибутив был загружен на хранилище кластера, мы переходим к созданию VM.
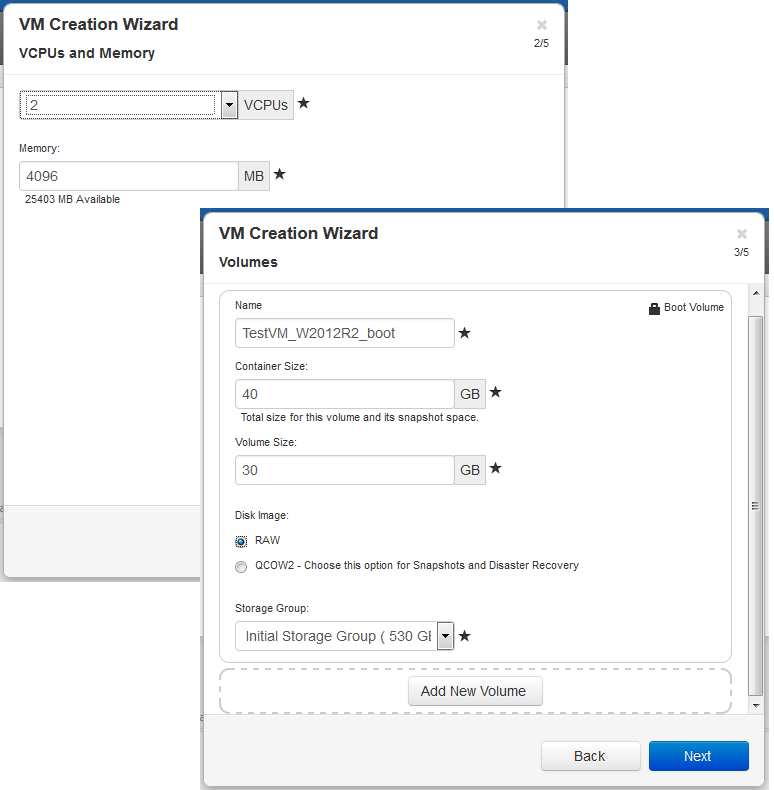
Как видно из визарда по созданию VM, одной из унаследованных «фич» KVM стало 2 типа создаваемых разделов: QCOW 2 и RAW. Основным различием является то, что тома типа RAW не поддерживают создание снэпшотов и DisasterRecovery.
При создании VM нам необходимо указать не только размер раздела, но и размер «контейнера». Контейнером является том, содержащий в себе как сам раздел, так и его снэпшоты. Таким образом, согласно мануалу по сайзингу, размер контейнера рекомендуется делать от 2,5 до 3,6 размеров раздела VM в зависимости от интенсивности изменения данных:
VolContSize = 2 * VolSize + [(# SnapshotsRetained + 1)* SnapshotSize]
Для создания консистентных снэпшотов предлагается использовать отдельно скачиваемые клиенты для Windows и Linux сред.
При тестовом создании снэпшота свежесозданной VM с разделом 30 Гб система съела 8.1 Гб. На что ушло это пространство для меня так и осталось загадкой.
После создания VM нам доступна функция Load Balancing. Вся суть балансировки заключается в том, что он равномерно распределяет все VM по обеим нодам кластера, либо в ручном режиме «привязывает» к конкретной ноде.
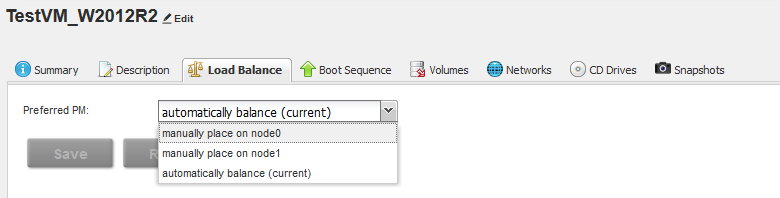
В рамках стресс-теста я создал 2 виртуальные машины: одну в режиме HA, вторую — FT, после чего принудительно погасил одну из нод.
HA VM ушла в перезагрузку, после чего автоматически поднялась на второй ноде.
FT VM продолжила штатное функционирование, при этом монитор системных ресурсов отмечает повышение нагрузки на дисковую и сетевую подсистемы.

Тестируя данное решения, я думал о сферах его применения. Так как продукт достаточно специфичен, с большим количеством нюансов, то хорошо он сможет показать себя только в узкоспециализированных проектах.
Одним из самых очевидных будет промышленное использование. Зачастую, при производстве есть определенные объекты, которые нельзя подключить к существующей ИТ-инфраструктуре, но которые имеют собственные требования по доступности и отказоустойчивости. В этом случае кластер на базе everRun будет достаточно выгодно смотреться на фоне других коммерческих систем кластеризации за счет соотношения экономичности решения и его функциональности.
Вторым типом проектов, вытекающим из особенностей первого, будет являться видеонаблюдение, особенно когда необходимо наладить систему видеонаблюдения на удаленных или изолированных площадках, например, на ж\д развязках, нефте- и газодобывающих точках и т.д. Изолированность данных объектов от основных инфраструктур компании не позволяют включать их в имеющиеся кластера, а использование stand-alone серверов видеонаблюдения повышает риск их выхода из строя и вытекающих отсюда расходов по обслуживанию.
Ценовая политика Stratus Technologies подразумевает единую рекомендованную для конечного заказчика цену на лицензии everRun по всему миру. Поставка осуществляется привычным способом – лицензия продается по договору неисключительного права, к ней идет сервисная подписка сроком минимум на 1 год, подразумевающая весь объем технической поддержки в режиме 5х8 или 24х7, включая обновление до любой актуальной версии в течение срока действия подписки.
Подводя итог, можно отметить узконаправленность данного продукта. Обладая рядом преимуществ, он не может быть использован повсеместно из-за наличия вышеупомянутых ограничений. Но если все эти ограничения вас устраивают, то настоятельно рекомендую вам изучить данное решение, благо что вендор без проблем предоставляет trial-лицензию сроком на 30-60 дней.
А для тех, кто заинтересован в личном тестировании, но не обладает возможностью самостоятельно развернуть Stratus everRun на локальных узлах, мы всегда можем предложить удаленное тестирование на базе нашего демо-стенда.
На текущий момент продуктовый портфель Stratus Technologies состоит из 2 решений:
1. Аппаратное решение, заменяющее собой кластер из 2-х серверов, называющееся ftServer.
2. Программный продукт — гипервизор everRun.
Получить дистрибутив ПО для тестов намного проще, чем двух-нодовую железку, поэтому в первую очередь я смог оценить именно гипервизор everRun. Ниже вы сможете ознакомиться с результатами.

В текущие тяжелые времена во многих компаниях наблюдается дефицит бюджетирования ИТ-проектов, особенно в валютном показателе. Однако требования к надежности и отказоустойчивости критичных систем никто не отменял. И перед многими возникает вопрос: как обеспечить резервирование систем?
Рассмотрим возможный сценарий: вам необходимо обеспечить систему контроля температуры в одном конкретном хранилище сырья. Пусть это будет… цистерна с молоком. С точки зрения производительности нам вполне достаточно одного узла, допустим даже десктопа вместо полноценного сервера. Однако надежность такой системы должна быть на высоком уровне, который никакой stand-alone узел нам никогда не обеспечит.
Да, всегда можно поднять такую систему на кластере серверной виртуализации, но что делать компаниям, у которых серверная виртуализация не реализована, или же нет свободных ресурсов? Все же расширение кластера VMWare достаточно затратно, как с точки зрения железа, так и в отношении софта и лицензирования.
Именно здесь возникает достаточно логичная и, на первый взгляд, очевидная идея: взять 2 одинаковых узла из «ненужного зоопарка» (десктоп, списанный сервер и т.д.), связать их и кластеризовать. У такой системы должно быть несколько отличительных черт:
1. Возможность зеркалирования локальных дисков узлов для возможности миграции системы между узлами;
2. Возможность зеркалирования оперативной памяти и кеша процессоров для обеспечения функциии FT;
3. Данное решение должно обладать разумной стоимостью.
И на первый взгляд Stratus everRun обладает всеми перечисленными чертами
Рассмотрим подробнее, что же может наш «герой».
Описание
В основе решения лежит технология Checkpointing, позволяющая синхронизировать узлы кластера таким образом, что выход из строя одного из них не приводит к простою нашего приложения ни на долю секунды.
Главная идея, лежащая в основе технологии: репликация состояния гостевой виртуальной машины между двумя независимыми узлами при помощи чекпоинтов – контрольных точек состояния, включающих в себя абсолютно всё: регистры процессора, dirty pages, и т.д. На момент создания чекпоинта, гостевая ВМ замораживается и размораживается только после подтверждения (ACK) получения чекпоинта второй системой. Контрольная точка создается от 50 до 500 раз в секунду, в зависимости от текущей загрузки ВМ. Скорость определяется непосредственно алгоритмом и не подлежит ручной настройке. Таким образом, виртуальная машина живет на двух серверах одновременно. В случае сбоя основного узла – ВМ запускается на резервном с последнего полученного чекпоинта, без потери данных и какого-либо простоя.
Stratus everRun является bare-metal гипервизором на базе продукта KVM. Такое наследие добавляет несколько нюансов в его функциональность, но об этом позже.
Для работы данного продукта нам необходимо 2 одинаковые ноды, которые будут связаны между собой каналом Ethernet.
При этом требования к этим нодам достаточно демократичны:
• От 1 до 2 сокетов.
• От 8 Гб RAM.
• Минимум 2 жестких диска на ноду (для соблюдения отказоустойчивости на уровне 1й ноды).
• Минимум 2 порта 1 GE на ноду. Первый порт отводится для интерконнекта между нодами (называется A-link). Второй — под управляющую сеть и сеть передачи данных. При этом эти сети могут быть разнесены по разным портам при их наличии. Обязательным требованием к каналу интерконнекта является наличие задержки не более чем в 2 мс (для реализации функции FT).
Лицензирование производится по привычной для нас схеме — 1 лицензия на 2 процессора пары. Это означает, что для кластеризации 2х нод нам потребуется только 1 лицензия. Кластеризация более чем двух нод и более чем двух процессоров на ноду на текущий момент не поддерживается.
Существуют разные уровни лицензии: Express и Enterprise.
Express имеет ограниченную функциональность и позволяет обеспечивать отказоустойчивость VM на уровне HA. Это означает, что нет зеркалирования на уровне кеша процессора не применяется описанная выше технология checkpointing. Только репликация дисков и отказоустойчивость на уровне сети. Выход из строя одной из нод приведет к остановке работы VM на время ее перезапуска на втором узле.
Лицензия Enterprise обладает полной функциональностью, и обеспечивает защиту на уровне FT. Выход из строя одной из нод не приведет к простою VM. Однако, это накладывает дополнительную нагрузку на A-link, и поэтому для обеспечения FT без влияния на производительность VM рекомендуется использовать в качестве A-link канал 10 GE.
Теперь перейдем к практике — тестированию.
Развертывание
Для тестирования данного продукта мне были выделены 2 бюджетных сервера SuperMicro в следующей конфигурации:
| PN | Description | qty |
|---|---|---|
| SYS-5018R-M | Supermicro SuperServer 1U 5018R-M no CPU(1)/ no memory(8)/ on board C612 RAID 0/1/10/ no HDD(4)LFF/ 2xGE/ 1xFH/ 1noRx350W Gold/ Backplane 4xSATA/SAS | 2 |
| SR1YC | CPU Intel Xeon E5-2609 V3 (1.90Ghz/15Mb) FCLGA2011-3 OEM | 2 |
| LSI00419 | LSI MegaRAID SAS9341-4I (PCI-E 3.0 x8, LP) SGL SAS 12G, RAID 0,1,10,5, 4port (1*intSFF8643) | 2 |
| KVR21R15D4/16 | Kingston DDR4 16GB (PC4-17000) 2133MHz ECC Reg Dual Rank, x4, 1.2V, w/TS | 4 |
| ST3300657SS | HDD SAS Seagate 300Gb, ST3300657SS, Cheetah 15K.7, 15000 rpm, 16Mb buffer | 4 |
Не самое лучшее железо, но и не десктоп.
Смонтировав их в одну стойку непосредственно друг над другом и скоммутировав через свитч я приступил к установке ПО.
Уже на этом этапе нас ждут интересные нюансы:
• На текущий момент в листе совместимости нет некоторых распространенных блейдовых решений. В чем причина несовместимости именно с блейдами — неизвестно. Я попробовал установить данное ПО на имеющиеся у меня в лабе IBM FlexSystem и потерпел полный крах.
• Дистрибутив обязательно должен быть записан на физический носитель DVD. Никакого монтирования ISO через консоль IPMI, никаких загрузочных USB. Только DVD, только хардкор. К счастью, у меня нашелся внешний DVD-привод.
Визард основывается на CentOS и имеет достаточно знакомый интерфейс.
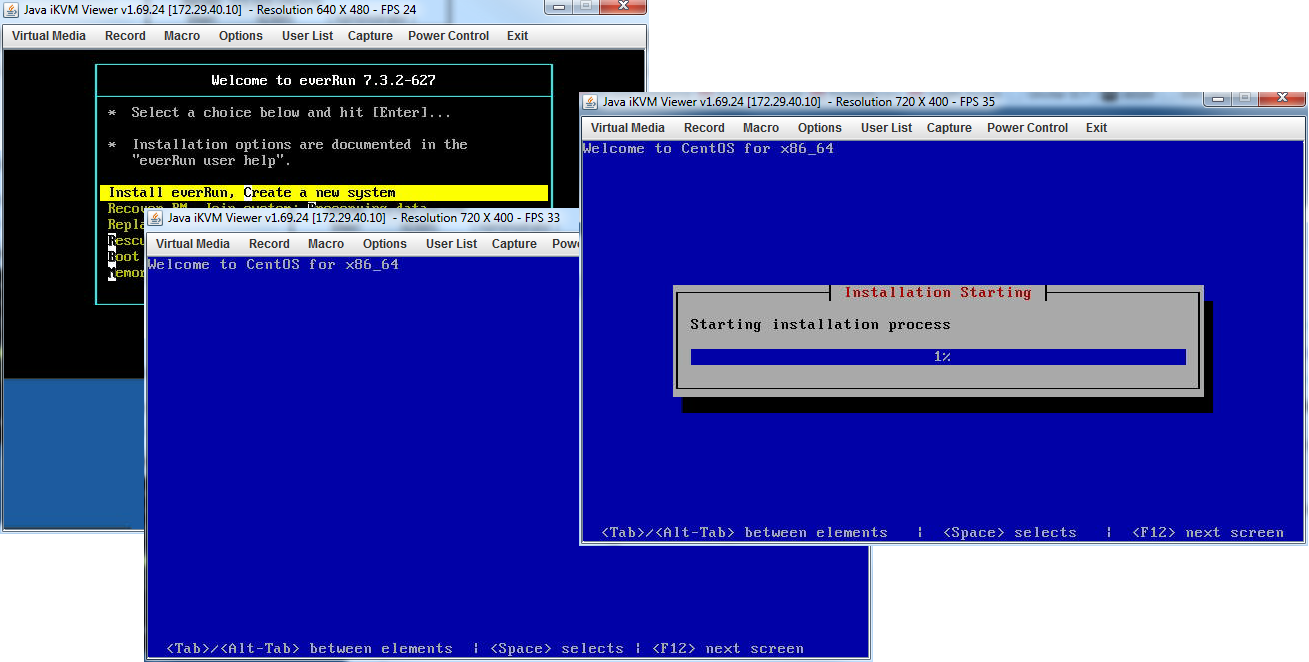
Сам по себе процесс установки достаточно прост:
• Устанавливаем ПО на первую ноду. В процессе инсталляции необходимо выбрать раздел, выбрать порты для A-link и управляющей сетей и прописать необходимые IP-адреса и root-пароль.
• Устанавливаем ПО на вторую ноду. При этом мы выбираем только установочный раздел и порты. Всю остальную информацию он копирует с основной (первой) ноды в процессе инсталляции.
После окончания установки ПО на ноды необходимо подключиться к основной ноде по IP-адресу управляющего порта. Перед нами откроется интерфейс настройки реквизитов доступа к web-интерфейсу и активации лицензии.
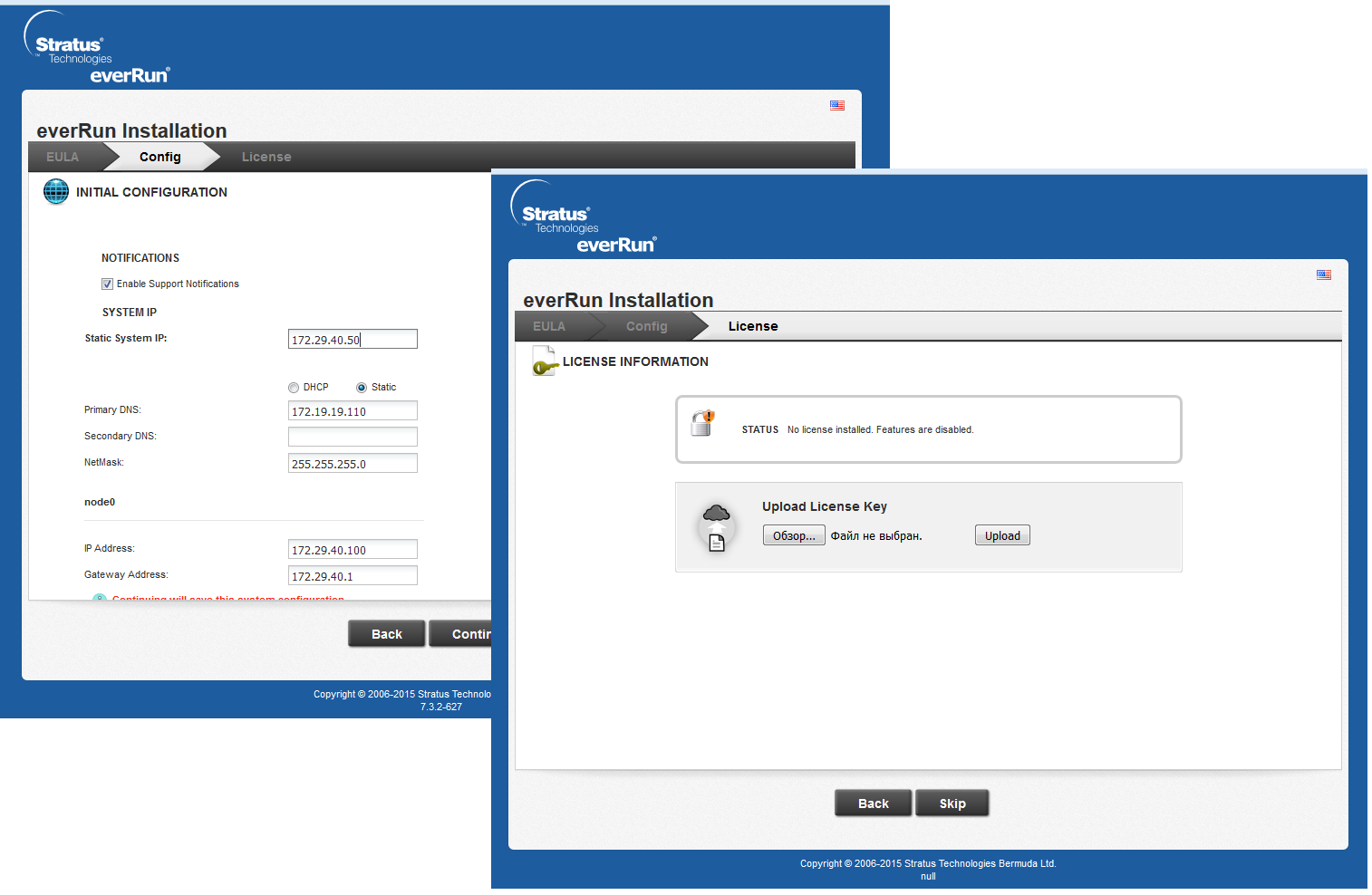
Таким образом, у нас получается пул из 5 адресов: 2 адреса IPMI-портов ноды, 2 адреса управляющих портов нод и 1 адрес web-интерфейса.
Интерфейс
Интерфейс у everRun достаточно просто и симпатичный.
Как видно на скриншоте Dashboard у меня после установки вторая нода осталась в maintenance-режиме. С чем это связано я так и не понял, возможно какие-то неточности в установке с моей стороны. Проблема решилась переводом ноды в обычный режим руками через соответствующий раздел меню.
Как мы можем увидеть в разделе System, everRun «съедает» 2 ядра процессорных мощностей на собственные нужды. При этом допустИм overprovisioning.
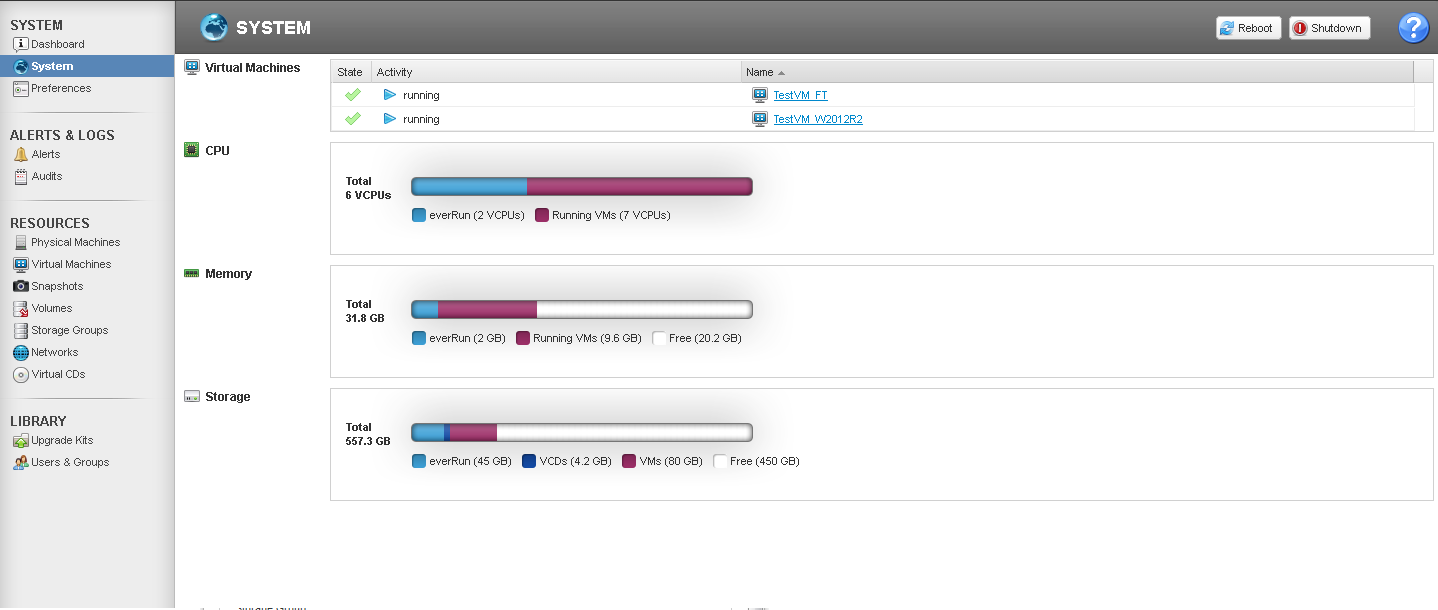
Помимо этого, присутствуют накладные расходы по ядрам, зависящие от уровня защиты. В случае с HA на VM с n ядрами будет уходить n+1 ядер кластера, а в случае с FT — n+2. Таким образом на HA VM 4 vCPU будет выделено 5 ядер кластера, а на FT VM 6 vCPU уйдет все 8 ядер (при этом в случае с многопользовательскими инсталляциями будет добавляться по n+2 на каждого пользователя).
Примечательно, что максимальное количество vCPU, поддерживаемое в FT VM — 8, а это достаточно интересный показатель. Для сравнения, vCenter Server (ver 6.x) позволяет создавать FT VM только до 4 vCPU (а в версиях 5.x — до 1 vCPU), что значительно сужает сферу использования данной функции.
Создание VM тоже имеет ряд нюансов, при этом достаточно неприятных. Для создания новой VM нам необходим ISO-образ дистрибутива ОС. Он должен обязательно находится на локальном томе кластера. Загрузить его туда можно только через web-интерфейс, нажав на соответствующую кнопку меню.
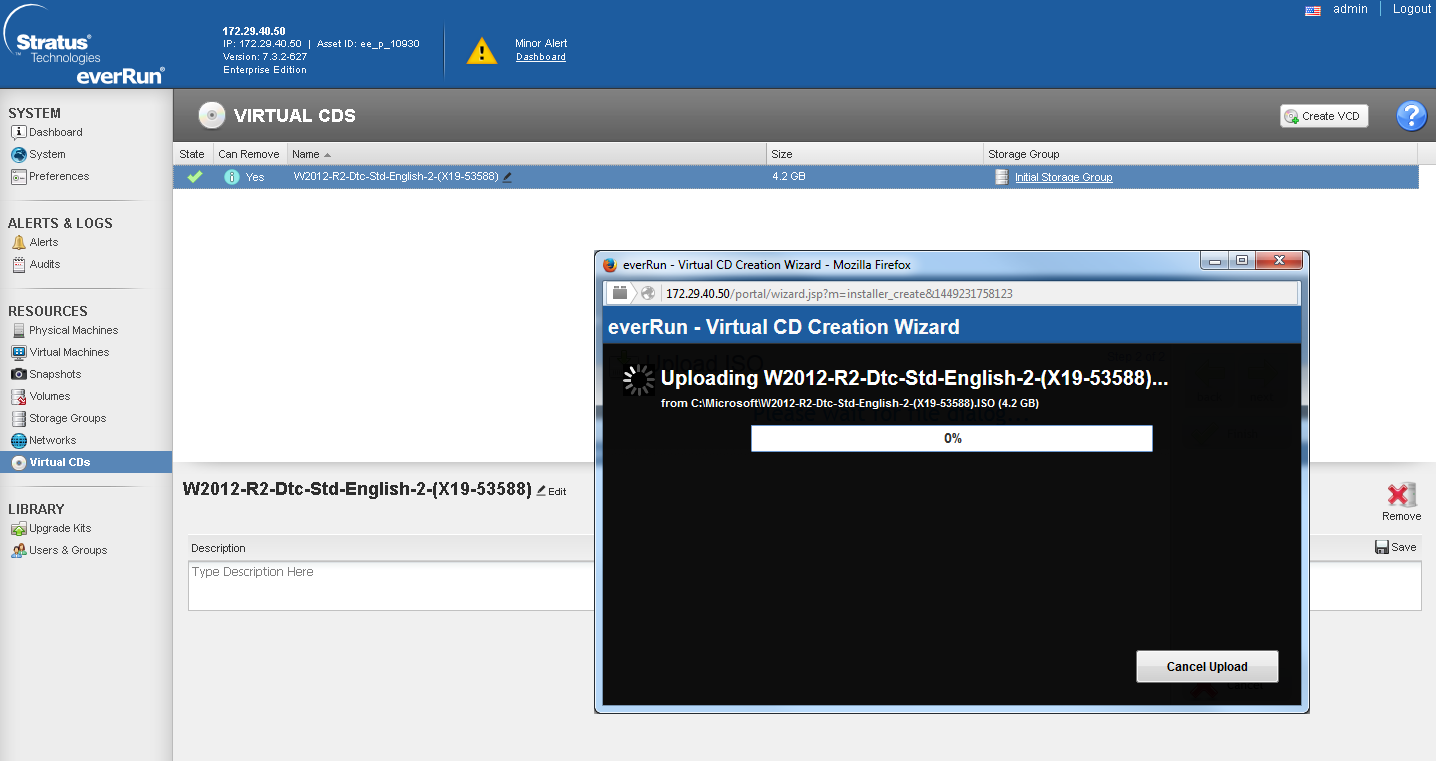
Это приводит к тому, что вы вынуждены загружать по сети ISO-образ с удаленного ПК. Это либо забьет весь канал, либо будет продолжаться неприлично долго. Например, образ Win 2012 R2 весом в 4,2 Гб я заливал ~4 часа. Отсюда вытекает и вторая неприятная особенность: everRun не позволяет пробрасывать USB носители и PCE-E устройства внутрь виртуалок. Т.е. все возможные USB-токены или GPU невозможно использовать. В защиту решения можно отметить, что проброс USB-носителей непосредственно в узел кластера заметно снижает отказоустойчивость системы (так как при выходе узла из строя вам необходимо будет вручную переподключать данные носители), а проброс GPU и дальнейшая репликация нагрузки на GPU в режиме FT является крайне затратным делом с точки зрения системы. Но все равно, этот факт резко сужает область применения данного решения.
После того как дистрибутив был загружен на хранилище кластера, мы переходим к созданию VM.
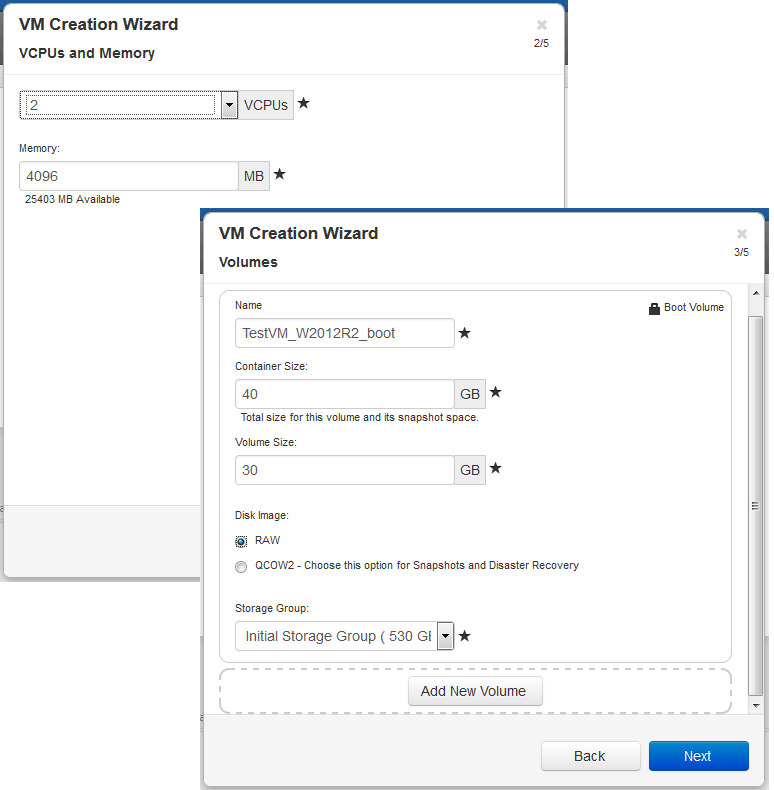
Как видно из визарда по созданию VM, одной из унаследованных «фич» KVM стало 2 типа создаваемых разделов: QCOW 2 и RAW. Основным различием является то, что тома типа RAW не поддерживают создание снэпшотов и DisasterRecovery.
При создании VM нам необходимо указать не только размер раздела, но и размер «контейнера». Контейнером является том, содержащий в себе как сам раздел, так и его снэпшоты. Таким образом, согласно мануалу по сайзингу, размер контейнера рекомендуется делать от 2,5 до 3,6 размеров раздела VM в зависимости от интенсивности изменения данных:
VolContSize = 2 * VolSize + [(# SnapshotsRetained + 1)* SnapshotSize]
Для создания консистентных снэпшотов предлагается использовать отдельно скачиваемые клиенты для Windows и Linux сред.
При тестовом создании снэпшота свежесозданной VM с разделом 30 Гб система съела 8.1 Гб. На что ушло это пространство для меня так и осталось загадкой.
После создания VM нам доступна функция Load Balancing. Вся суть балансировки заключается в том, что он равномерно распределяет все VM по обеим нодам кластера, либо в ручном режиме «привязывает» к конкретной ноде.
В рамках стресс-теста я создал 2 виртуальные машины: одну в режиме HA, вторую — FT, после чего принудительно погасил одну из нод.
HA VM ушла в перезагрузку, после чего автоматически поднялась на второй ноде.
FT VM продолжила штатное функционирование, при этом монитор системных ресурсов отмечает повышение нагрузки на дисковую и сетевую подсистемы.

Применение
Тестируя данное решения, я думал о сферах его применения. Так как продукт достаточно специфичен, с большим количеством нюансов, то хорошо он сможет показать себя только в узкоспециализированных проектах.
Одним из самых очевидных будет промышленное использование. Зачастую, при производстве есть определенные объекты, которые нельзя подключить к существующей ИТ-инфраструктуре, но которые имеют собственные требования по доступности и отказоустойчивости. В этом случае кластер на базе everRun будет достаточно выгодно смотреться на фоне других коммерческих систем кластеризации за счет соотношения экономичности решения и его функциональности.
Вторым типом проектов, вытекающим из особенностей первого, будет являться видеонаблюдение, особенно когда необходимо наладить систему видеонаблюдения на удаленных или изолированных площадках, например, на ж\д развязках, нефте- и газодобывающих точках и т.д. Изолированность данных объектов от основных инфраструктур компании не позволяют включать их в имеющиеся кластера, а использование stand-alone серверов видеонаблюдения повышает риск их выхода из строя и вытекающих отсюда расходов по обслуживанию.
Ценовая политика Stratus Technologies подразумевает единую рекомендованную для конечного заказчика цену на лицензии everRun по всему миру. Поставка осуществляется привычным способом – лицензия продается по договору неисключительного права, к ней идет сервисная подписка сроком минимум на 1 год, подразумевающая весь объем технической поддержки в режиме 5х8 или 24х7, включая обновление до любой актуальной версии в течение срока действия подписки.
Подводя итог, можно отметить узконаправленность данного продукта. Обладая рядом преимуществ, он не может быть использован повсеместно из-за наличия вышеупомянутых ограничений. Но если все эти ограничения вас устраивают, то настоятельно рекомендую вам изучить данное решение, благо что вендор без проблем предоставляет trial-лицензию сроком на 30-60 дней.
А для тех, кто заинтересован в личном тестировании, но не обладает возможностью самостоятельно развернуть Stratus everRun на локальных узлах, мы всегда можем предложить удаленное тестирование на базе нашего демо-стенда.
