Технологии Big Data создавались в качестве ответа на вопрос «как обработать много данных». А что делать, если объем информации не является единственной проблемой? В промышленности и прочих серьезных применениях часто приходится иметь дело с большими данными сложной и переменной структуры, разрозненными массивами информации. Встречаются задачи, способ решения которых наперед не известен, и аналитику необходимы средства исследования исходных данных или результатов вычислений на их основе без привлечения программиста. Нужны инструменты, сочетающие функциональную мощь систем BI (а лучше – превосходящие ее) со способностью к обработке огромных объемов информации.
Одним из способов получить такой инструмент является создание логической витрины данных. В этой статье мы расскажем о концепции этого решения, а также продемонстрируем программный прототип.
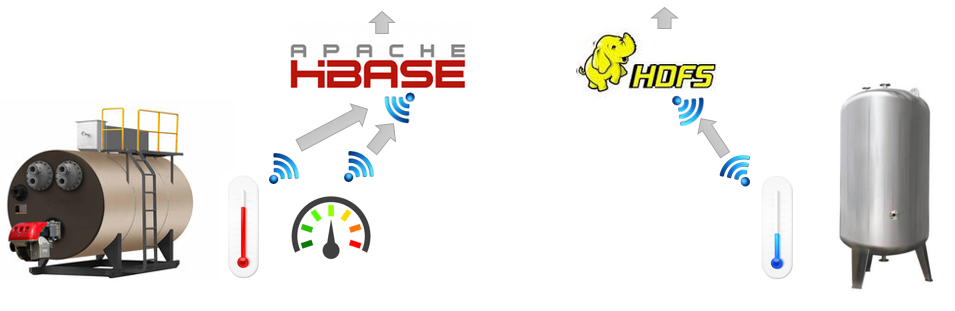
Для рассказа нам понадобится простой пример сложной задачи. Рассмотрим некий промышленный комплекс, обладающий огромным количеством оборудования, обвешанного различными датчиками и сенсорами, регулярно сообщающими сведения о его состоянии. Для простоты рассмотрим только два агрегата, котел и резервуар, и три датчика: температуры котла и резервуара, а также давления в котле. Эти датчики контролируются АСУ разных производителей и выдают информацию в разные хранилища: сведения о температуре и давлении в котле поступают в HBase, а данные о температуре в резервуаре пишутся в лог-файлы, расположенные в HDFS. Следующая схема иллюстрирует процесс сбора данных.
Кроме конкретных показаний датчиков, для анализа необходимо иметь список сенсоров и устройств, на которых они установлены. Оценим порядок числа информационных сущностей, с которыми мы имели бы дело на реальном предприятии:
Способы хранения для данных разных типов зависят от их объема, структуры и требуемого режима доступа. В данном случае мы выбрали именно такие средства для создания «разнобоя», но и на реальных предприятиях чаще всего нет возможности свободно их выбирать – все зависит от сложившегося ИТ-ландшафта. Аналитической же системе нужно собрать весь «зоопарк» под одной крышей.
Пусть мы хотим предоставить аналитику возможность делать запросы такого типа:
Заранее построить и запрограммировать все подобные запросы не получится. Выполнение любого из них требует связывания данных из разных источников, в том числе из находящихся за пределами нашего модельного примера. Извне могут поступать, например, справочные сведения о рабочих диапазонах температуры и давления для разных видов оборудования, фасетные классификаторы, позволяющие определить, какое оборудование является маслонаполненным, и др. Все подобные запросы аналитик формулирует в терминах концептуальной модели предметной области, то есть ровно в тех выражениях, в которых он думает о работе своего предприятия. Для представления концептуальных моделей в электронной форме существует стек семантических технологий: язык OWL, хранилища триплетов, язык запросов SPARQL. Не имея возможности подробно рассказывать о них в этой статье, сошлемся на русскоязычный источник.
Итак, наш аналитик будет формулировать запросы в привычных ему терминах, и получать в ответ наборы данных – независимо от того, из какого источника эти данные извлечены. Рассмотрим пример простого запроса, на который можно найти ответ в нашем наборе информации. Пусть аналитик интересуется оборудованием, установленные на котором сенсоры одновременно измерили температуру больше 4000 и давление больше 5 мПа в течение заданного периода времени. В этой фразе мы выделили жирным слова, соответствующие сущностям информационной модели: оборудование, сенсор, измерение. Курсивом выделены атрибуты и связи этих сущностей. Наш запрос можно представить в виде такого графа (под каждым типом данных мы указали хранилище, в котором они находятся):
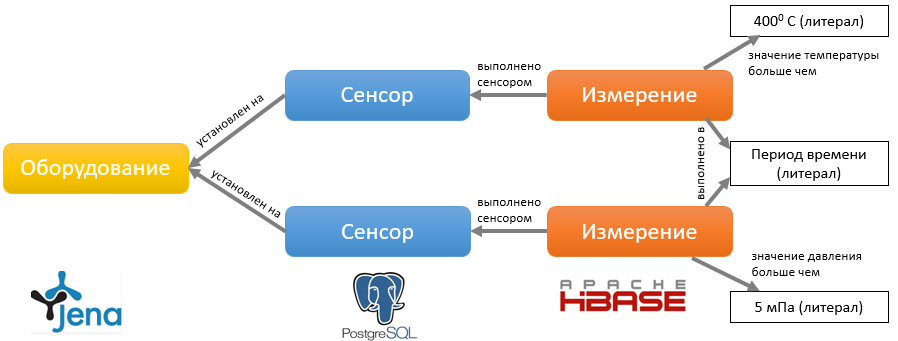
При взгляде на этот граф становится понятной схема выполнения запроса. Сначала нужно отфильтровать измерения температуры за заданный период со значением больше 4000 C, и измерения давления со значением больше 5 мПа; затем нужно найти среди них те, которые выполнены сенсорами, установленные на одной и той же единице оборудования, и при этом выполнены одновременно. Именно так и будет действовать витрина данных.
Схема нашей системы будет такой:
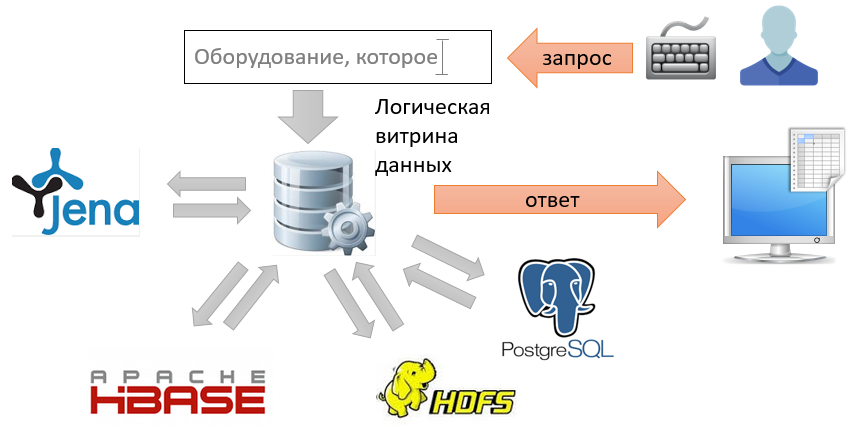
Порядок работы системы таков:
Вся «магия», конечно, происходит внутри витрины. Перечислим принципиальные моменты.
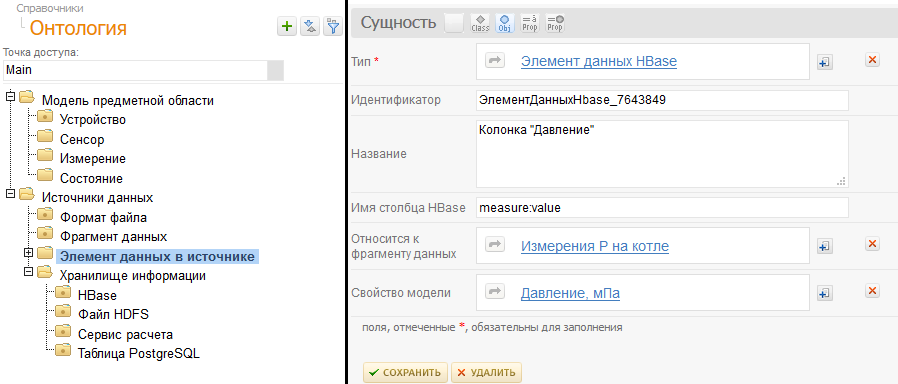
1. В хранилище триплетов Apache Jena (можно использовать и любое другое) у нас хранится как сама модель предметной области, так и настройки мэппинга на источники данных. Таким образом, через редактор информационной модели мы задаем и набор терминов, в которых строятся запросы (устройство, сенсор и т.д.), и служебные сведения о том, откуда брать соответствующую им фактическую информацию. На следующем рисунке показано, как в нашем редакторе онтологий выглядит дерево классов модели демонстрационного примера (слева), и одна из форм настройки мэппинга данных с источником (справа).
2. В нашем примере данные одного и того же типа (измерения температуры) хранятся одновременно в двух разных источниках – HBase и текстовом файле HDFS. Однако для выполнения приведенного запроса обращаться к файлу не нужно, т.к. в нем заведомо нет полезной информации: ведь в файле хранятся измерения температуры резервуара, а давление в резервуарах не измеряется. Этот момент дает представление о том, как должен работать оптимизатор выполнения запросов.
3. Витрина данных не только компонует и связывает информацию из различных источников, но и делает логические выводы на ней в соответствии с заданными правилами. Автоматизация получения логических выводов – одно из главных практических преимуществ семантики. В нашем примере с помощью правил решена проблема получения выводов о состоянии устройства на основе данных измерений. Температура и давление содержатся в двух разных сущностях типа «Измерение», а для описания состояния устройства необходимо их объединить. Логические правила применяются к содержимому временного графа результатов, и порождают в нем новую информацию, которая отсутствовала в источниках.
4. В качестве источников данных могут выступать не только хранилища, но и сервисы. В нашем примере мы спрятали за сервисом расчет предпосылок к возникновению аварийного состояния при помощи одного из алгоритмов Spark MLlib. Этот сервис получает на вход информацию о состоянии устройства, и оценивает его с точки зрения наличия предпосылок к аварии (для обучения использованы ретроспективные данные о том, какие условия предшествовали реально случившимся авариям; в качестве исходных данных нужно рассматривать не только мгновенные значения физических характеристик устройства, но и элементы основных данных – например, степень его износа).
Эта возможность очень важна, так как позволяет аналитику самому выполнять запуск расчетных модулей, подготовленных программистами, передавая им на вход различные массивы данных. В этом случае аналитик будет работать уже не с исходными данными, а с результатами вычислений на их основе.
5. Аналитик строит запросы при помощи интерфейсов нашей Системы управления знаниями, среди которых – как несколько вариантов формального конструктора запросов, так и интерфейс поиска на контролируемом естественном языке. На следующем рисунке слева показана форма построения запроса на контролируемом языке, а справа – пример результатов другого запроса.

Конечно, в любой бочке меда найдется ложка дегтя. В данном случае она состоит в том, что на действительно больших данных приведенная архитектура будет работать не так уж быстро. С другой стороны, при работе аналитика в режиме «свободного поиска» решения проблем быстродействие для него обычно не принципиально; в любом случае, витрина будет выдавать результаты куда быстрее, чем программист, к которому при ее отсутствии аналитику придется обращаться за ручным выполнением каждого своего запроса.
За рамками нашего рассказа осталось немало интересных моментов:
Разумеется, реальные промышленные применения витрины данных куда сложнее описанного примера. Нашей целью в этой статье была демонстрация того, что использование семантических технологий и концептуального моделирования в тандеме со средствами Big Data позволяет расширить число доступных аналитику способов использования данных, решать прикладные задачи в самых неординарных условиях. В сочетании с возможностями контроля прав доступа к хранилищу триплетов и выполнения триггеров на нем, о которых мы уже рассказывали, описанные средства позволяют удовлетворять весьма изысканным функциональным требованиям.
Одним из способов получить такой инструмент является создание логической витрины данных. В этой статье мы расскажем о концепции этого решения, а также продемонстрируем программный прототип.
Для рассказа нам понадобится простой пример сложной задачи. Рассмотрим некий промышленный комплекс, обладающий огромным количеством оборудования, обвешанного различными датчиками и сенсорами, регулярно сообщающими сведения о его состоянии. Для простоты рассмотрим только два агрегата, котел и резервуар, и три датчика: температуры котла и резервуара, а также давления в котле. Эти датчики контролируются АСУ разных производителей и выдают информацию в разные хранилища: сведения о температуре и давлении в котле поступают в HBase, а данные о температуре в резервуаре пишутся в лог-файлы, расположенные в HDFS. Следующая схема иллюстрирует процесс сбора данных.

Кроме конкретных показаний датчиков, для анализа необходимо иметь список сенсоров и устройств, на которых они установлены. Оценим порядок числа информационных сущностей, с которыми мы имели бы дело на реальном предприятии:
| Сущность | Порядок числа записей | Тип хранилища |
|---|---|---|
| Единицы оборудования | Тысячи | Мастер-данные |
| Датчики, сенсоры | Сотни тысяч | БД PostgreSQL |
| Показания датчиков | Десятки миллиардов в год (вопрос глубины хранения в этой статье не ставим) |
Файлы в HDFS, HBase |
Способы хранения для данных разных типов зависят от их объема, структуры и требуемого режима доступа. В данном случае мы выбрали именно такие средства для создания «разнобоя», но и на реальных предприятиях чаще всего нет возможности свободно их выбирать – все зависит от сложившегося ИТ-ландшафта. Аналитической же системе нужно собрать весь «зоопарк» под одной крышей.
Пусть мы хотим предоставить аналитику возможность делать запросы такого типа:
- Какие единицы маслонаполненного оборудования работали при температуре выше 300 градусов за последнюю неделю?
- Какое оборудование находится в состоянии, выходящем за пределы рабочего диапазона?
Заранее построить и запрограммировать все подобные запросы не получится. Выполнение любого из них требует связывания данных из разных источников, в том числе из находящихся за пределами нашего модельного примера. Извне могут поступать, например, справочные сведения о рабочих диапазонах температуры и давления для разных видов оборудования, фасетные классификаторы, позволяющие определить, какое оборудование является маслонаполненным, и др. Все подобные запросы аналитик формулирует в терминах концептуальной модели предметной области, то есть ровно в тех выражениях, в которых он думает о работе своего предприятия. Для представления концептуальных моделей в электронной форме существует стек семантических технологий: язык OWL, хранилища триплетов, язык запросов SPARQL. Не имея возможности подробно рассказывать о них в этой статье, сошлемся на русскоязычный источник.
Итак, наш аналитик будет формулировать запросы в привычных ему терминах, и получать в ответ наборы данных – независимо от того, из какого источника эти данные извлечены. Рассмотрим пример простого запроса, на который можно найти ответ в нашем наборе информации. Пусть аналитик интересуется оборудованием, установленные на котором сенсоры одновременно измерили температуру больше 4000 и давление больше 5 мПа в течение заданного периода времени. В этой фразе мы выделили жирным слова, соответствующие сущностям информационной модели: оборудование, сенсор, измерение. Курсивом выделены атрибуты и связи этих сущностей. Наш запрос можно представить в виде такого графа (под каждым типом данных мы указали хранилище, в котором они находятся):

При взгляде на этот граф становится понятной схема выполнения запроса. Сначала нужно отфильтровать измерения температуры за заданный период со значением больше 4000 C, и измерения давления со значением больше 5 мПа; затем нужно найти среди них те, которые выполнены сенсорами, установленные на одной и той же единице оборудования, и при этом выполнены одновременно. Именно так и будет действовать витрина данных.
Схема нашей системы будет такой:

Порядок работы системы таков:
- аналитик делает запрос;
- логическая витрина данных представляет его в виде запроса к графу;
- витрина определяет, где находятся данные, необходимые для ответа на этот запрос;
- витрина выполняет частные запросы исходных данных к разным источникам, используя необходимые фильтры;
- получает ответы и интегрирует их в единый временный граф;
- выполняет пост-обработку графа, заключающуюся, например, в применении правил логического вывода;
- выполняет на нем исходный запрос, и возвращает ответ аналитику.
Вся «магия», конечно, происходит внутри витрины. Перечислим принципиальные моменты.
1. В хранилище триплетов Apache Jena (можно использовать и любое другое) у нас хранится как сама модель предметной области, так и настройки мэппинга на источники данных. Таким образом, через редактор информационной модели мы задаем и набор терминов, в которых строятся запросы (устройство, сенсор и т.д.), и служебные сведения о том, откуда брать соответствующую им фактическую информацию. На следующем рисунке показано, как в нашем редакторе онтологий выглядит дерево классов модели демонстрационного примера (слева), и одна из форм настройки мэппинга данных с источником (справа).

2. В нашем примере данные одного и того же типа (измерения температуры) хранятся одновременно в двух разных источниках – HBase и текстовом файле HDFS. Однако для выполнения приведенного запроса обращаться к файлу не нужно, т.к. в нем заведомо нет полезной информации: ведь в файле хранятся измерения температуры резервуара, а давление в резервуарах не измеряется. Этот момент дает представление о том, как должен работать оптимизатор выполнения запросов.
3. Витрина данных не только компонует и связывает информацию из различных источников, но и делает логические выводы на ней в соответствии с заданными правилами. Автоматизация получения логических выводов – одно из главных практических преимуществ семантики. В нашем примере с помощью правил решена проблема получения выводов о состоянии устройства на основе данных измерений. Температура и давление содержатся в двух разных сущностях типа «Измерение», а для описания состояния устройства необходимо их объединить. Логические правила применяются к содержимому временного графа результатов, и порождают в нем новую информацию, которая отсутствовала в источниках.
4. В качестве источников данных могут выступать не только хранилища, но и сервисы. В нашем примере мы спрятали за сервисом расчет предпосылок к возникновению аварийного состояния при помощи одного из алгоритмов Spark MLlib. Этот сервис получает на вход информацию о состоянии устройства, и оценивает его с точки зрения наличия предпосылок к аварии (для обучения использованы ретроспективные данные о том, какие условия предшествовали реально случившимся авариям; в качестве исходных данных нужно рассматривать не только мгновенные значения физических характеристик устройства, но и элементы основных данных – например, степень его износа).
Эта возможность очень важна, так как позволяет аналитику самому выполнять запуск расчетных модулей, подготовленных программистами, передавая им на вход различные массивы данных. В этом случае аналитик будет работать уже не с исходными данными, а с результатами вычислений на их основе.
5. Аналитик строит запросы при помощи интерфейсов нашей Системы управления знаниями, среди которых – как несколько вариантов формального конструктора запросов, так и интерфейс поиска на контролируемом естественном языке. На следующем рисунке слева показана форма построения запроса на контролируемом языке, а справа – пример результатов другого запроса.

Конечно, в любой бочке меда найдется ложка дегтя. В данном случае она состоит в том, что на действительно больших данных приведенная архитектура будет работать не так уж быстро. С другой стороны, при работе аналитика в режиме «свободного поиска» решения проблем быстродействие для него обычно не принципиально; в любом случае, витрина будет выдавать результаты куда быстрее, чем программист, к которому при ее отсутствии аналитику придется обращаться за ручным выполнением каждого своего запроса.
За рамками нашего рассказа осталось немало интересных моментов:
- как организован сбор данных сенсоров в HBase с помощью Flume;
- запросы к источникам данных могут выполняться не просто асинхронно, но даже при отсутствии онлайн-связи с ними – на этот случай предусмотрен специальный механизм передачи запроса и получения ответа;
- результаты выполнения запроса могут не просто выдаваться пользователю в виде таблицы или выгружаться в Excel, но и попадать напрямую в BI-систему в виде набора данных для дальнейшего анализа;
- способы конвертации идентификаторов и ссылок на объекты в разных источниках, вопросы транспорта сообщений между компонентами системы, и многое другое.
Разумеется, реальные промышленные применения витрины данных куда сложнее описанного примера. Нашей целью в этой статье была демонстрация того, что использование семантических технологий и концептуального моделирования в тандеме со средствами Big Data позволяет расширить число доступных аналитику способов использования данных, решать прикладные задачи в самых неординарных условиях. В сочетании с возможностями контроля прав доступа к хранилищу триплетов и выполнения триггеров на нем, о которых мы уже рассказывали, описанные средства позволяют удовлетворять весьма изысканным функциональным требованиям.
