В связи с тематикой «Мегамозга» в своих статьях мы с вами несколько отошли от хардкорной IT тематики, но это не значит, что мы стали меньше этим интересоваться. Поэтому я решил разбавить сложившуюся атмосферу небольшой околонаучной статьей. Под катом будет несколько формул, прошу не пугаться.
В общем и целом это краткий перевод статьи, размещенной на сайте Корнелльского университета, с некоторыми моими вставками.
 Интернет стал играть более важную роль в жизни людей с момента появления Web 2.0. Взаимодействие между пользователями, дало им возможность свободно обмениваться информацией через социальные сети, форумы, блоги, википодобные сайты и другие интерактивные совместно разрабатываемые медиаресурсы.
Интернет стал играть более важную роль в жизни людей с момента появления Web 2.0. Взаимодействие между пользователями, дало им возможность свободно обмениваться информацией через социальные сети, форумы, блоги, википодобные сайты и другие интерактивные совместно разрабатываемые медиаресурсы.
С другой стороны, налицо все недостатки концепции второго веба. Контент-ориентированность стала самым важным плюсом и минусом сети одновременно. Вопросы надежности и достоверности информации в полный рост стоят перед владельцами и пользователями интерактивных сообществ. Как и в реальной жизни, в процессе общения через сеть иногда возникают ситуации, когда некоторые пользователи нарушают правила общепринятого «сетевого» этикета. Фактически, чтобы сохранить нормальную атмосферу ресурса, владельцы вынуждены вводить искусственные правила взаимодействия и следить за их соблюдением.
Одним из таких явных нарушений является «троллинг».
В данной статье предлагается новый подход для вычисления злоумышленников. Данный метод базируется на мере конфликта функций доверия между различными сообщениями ветви обсуждения. Чтобы продемонстрировать состоятельность подхода протестируем его на искусственных данных.
В последнее время пути получения информации значительно сместились в сторону ускорения, облегчения и снижения трудозатрат. Фактически, благодаря интернету исследование той или иной темы свелось к простому нажатию кнопки мыши. Хотя по некоторым вопросам сложно найти удовлетворяющий ответ с помощью традиционных поисковых систем. Вместо этого, мы предпочитаем узнавать мнение эксперта.
В результате получил широкое распространение такой инструмент информационного взаимодействия, как сообщества вопросов-ответов (далее Q&AC). Такие системы позволяют каждому пользователю внести свою посильную лепту в развитие сообщества. К сожалению, не все сообщения надежны: некоторые пользователи выдают себя за экспертов, а другие публикуют бесполезные сообщения. Поэтому очень важным процессом становится работа модераторов данных сообществ. Чаще всего увеличение «мусорных» сообщений – результат действия «троллей».
Пользователи — главные действующие лица Q&AC. Условно их можно разделить на: «экспертов», «учащихся» и «троллей».
Эксперты: пользователи, обладающие знаниями или навыками в той или иной области.
Учащиеся: пользователи пытающиеся получить информацию или опыт.
Тролли: лица любыми способами пытающиеся нарушить спокойствие сообщества. Их целью является создание контрпродуктивных обсуждений.
Многие исследования уже пытались оценить источники информации в сообществах.
В некоторых предлагаются модели оценки авторитетности пользователей, основанные на количестве лучших пользовательских ответов. Лучший ответ здесь определяется спрашивающим пользователем или методом голосования.
В других авторы концентрируются на выборе вопросов, избранных пользователем для ответа. Эксперты всегда предпочитают отвечать на вопросы, в которых более компетентны.
Некоторые авторы предлагают сложные структуры, основанные на когнитивных и поведенческих критериях пользователей, для оценки не только надежности, но и опыта поставщиков информации.
При работе с информацией, поставляемой людьми, мы сталкиваемся с несколькими уровнями неопределенности. Для Q&AC предлагается три уровня неопределенности. Первый связан с экстракцией и интеграцией неопределенности, второй — с информационными источниками неопределенности, третий — с самой сущностью информации. В нашем случае в большей степени нас интересует оценка источников и часть неопределенности связанная с этим. Действительно, в сети, когда сталкиваемся с другими пользователями (т.е. источниками информации), мы практически никогда не обладаем априорным знанием о них.
Одним из математических инструментов для моделирования и обработки неточных (интервальных) экспертных оценок, измерений или наблюдений является теория функций доверия.
Предлагаемый в статье подход предполагает использование этой теории в совокупности с введением величины, определяющей конфликт двух сочетающихся функций доверия.
Перейдем собственно к описанию метода.
Одно из важных предположений говорит о том, что «тролли» интегрируются только в популярные ветви обсуждения. Разбиваем дальнейшее описание метода на три шага.
Исследователи предлагают основные характеристики «троллей»: агрессия, обман, нарушение правил, успех. Также указывают такие поведенческие характеристики как, пренебрежение нормами морали, явные садистские и психопатические наклонности. В контексте данной работы различия между «троллями» и другими пользователями исследователи выделяли вручную из сообщений. Исходя из этого, сообщения могут быть: релевантными, оффтопиком, чепухой или руганью. Определяем рамки характеризующие сообщения:
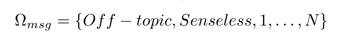 [1]
[1]
Характер сообщения определяется относительно опубликованного вопроса или топика. На этом этапе мы предполагаем, что метод однозначно определяет характер каждого сообщения.
Обнаружение нерелевантных сообщений ещё не даёт однозначного ответа на вопрос принадлежности пользователя к когорте «троллей». Может попасться пользователь всего лишь задетый и отвечающий на поддевки. Кроме того предмет обсуждения может постепенно измениться. Фактически, для того чтобы отличить «тролля» от других пользователей, мы нуждаемся в количественной оценке, насколько данный пользователь конфликтует с другими. Предлагаемый подход и предполагает измерение величины конфликта между сообщениями каждого пользователя.

– Confmsg/U: мера конфликта между kth сообщением пользователя Ui и сообщениями написанными каждым другим пользователем Uj.
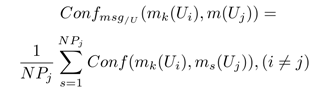 [2]
[2]
– Confmsg: мера конфликта между kth сообщением пользователя Ui и всеми сообщениями, написанными всеми другими пользователями U основанными на средневзвешенной величине. Эта величина учитывает количество сообщений, написанных каждым пользователем с целью определения уровня конфликта, особенно между «троллями» и экспертами.
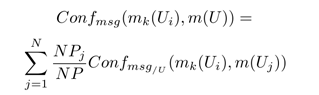 [3]
[3]
– Confuser: общая мера конфликта пользователя Ui
 [4]
[4]
Величина совокупного конфликта пользователя может увеличиваться, когда он пускается в бесконечные прения с «троллем». В данном случае пользователь становится жертвой, а модераторы приходится контролировать поведение пользователей во многих тредах.
Последний шаг состоит в классификации пользователей в соответствии с их мерами конфликта на две группы. Авторы предусмотрели для разбиения пользователей на группы использование алгоритма K-means.
Алгоритм k-means является простым повторяющимся алгоритмом кластеризации, который разделяет определенный набор данных на заданное пользователем число кластеров, k. Алгоритм прост для реализации и запуска, относительно быстрый, легко адаптируется и распространен на практике. Это исторически один из самых важных алгоритмов интеллектуального анализа данных.
В нашем случае число кластеров: k=2.
В результате работы алгоритма все пользователи разобьются на два кластера. «Тролли» попадут в группу с наибольшей мерой конфликта, а добропорядочные пользователи – с наименьшей мерой конфликта.
Рассмотрим следующий пример:
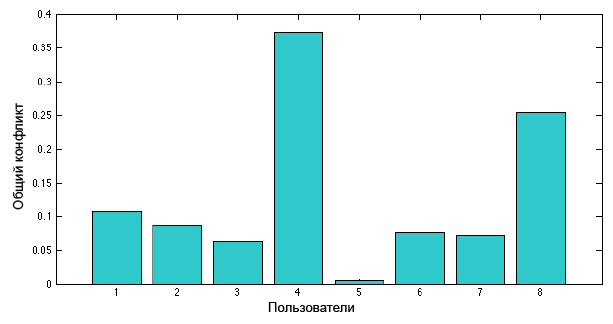
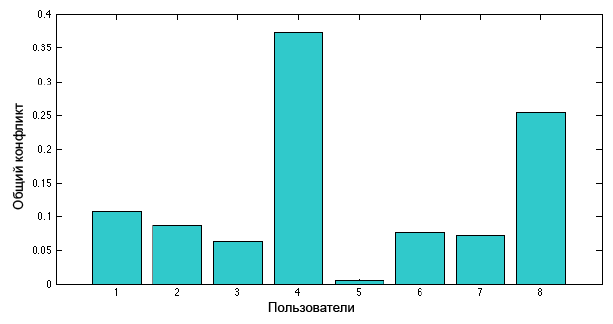
Возьмём одну из ветвей обсуждения, содержащую тридцать одно сообщение написанных восемью пользователями. Общая мера конфликта каждого пользователя, выраженная через уравнение [4] показана на рисунке ниже.
Пользователь U1 отправил три релевантных и два спорных сообщения ответом на сообщение пользователя U4.
Пользователь U2 отправил семь релевантных сообщений и два спорных сообщения ответом на сообщение пользователя U4.
Пользователь U3 отправил четыре релевантных сообщения и одно сообщение оффтопом пользователю U8.
Пользователь U4 опубликовал два спорных сообщения.
Пользователь U5 опубликовал одно релевантное сообщение.
Пользователь U6 опубликовал три релевантных сообщения.
Пользователь U7 опубликовал два релевантных сообщения.
Пользователь U8 опубликовал три сообщения: два первых оффтопом, одно спорное.
Общая мера конфликта пользователя U4 больше относительно U8, потому что второй публиковал свои сообщения после большого количества релевантных сообщений других пользователей. Таким образом, эта ситуация показала более высокую меру конфликта.
Применим алгоритм k-means, который разобьет пользователей на две группы:

Пользователи U1; U2; U3; не классифицируются как «тролли», несмотря на некоторые их сообщения, так как они публиковали и релевантные сообщения.
«Троллинг» в сети однозначно определяется как негативное и в некотором роде даже деструктивное явление, приводящее к усложнению получения информации пользователями. Во многих современных онлайн сообществах существуют рейтинговые системы саморегуляции, но, ни одна из них все равно не обходится без модерации. Что само по себе приводит к увеличению затрат владельцев сообществ. Небольшие ресурсы в основном обходятся своими силами, крупные вынуждены содержать специалистов.
В данной статье предложен новый синтезированный подход к определению качества пользователя по характеру опубликованных им сообщений. На данный момент авторы разработали методику поиска недобросовестных пользователей одной ветви обсуждений (треда), но предполагают расширить ее работу в рамках всего сообщества.
При написании топика я был вынужден упустить часть описания тяжеловесного матаппарата, чтобы сделать статью не только полезной, но и читабельной. Так как ссылки еще никто не отменял, интересующиеся темой могут восполнить это упрощение самолично.
К сожалению, в рамках одной статьи невозможно объять необъятное, поскольку данная тема весьма обширна и при детальной разработке тянет как минимум на кандидатскую. Если данную методу удастся прикрутить к кармаформуле любого сообщества, возможны перспективы избавления от нудной обязанности шерстить комментарииведь НЛО прилетит и опубликует эту запись здесь система голосования за комментарии сможет сама отбраковывать «троллячьи» потуги.
В данной работе различия между «троллями» и другими пользователями выделяли вручную, для практического применения такой вариант не подходит. Понятно, что процесс можно автоматизировать, хотя бы по оценкам комментариев. Попытка реализации алгоритма на примере Хабра не увенчалась успехом, в основном из-за того, что заминусованные комментарии затирает НЛО.
Работы в данном направлении будут продолжены.
Дополнительная информация по кластеризации на Хабре: «Кластеризация: алгоритмы k-means и c-means».
В общем и целом это краткий перевод статьи, размещенной на сайте Корнелльского университета, с некоторыми моими вставками.
Аннотация
 Интернет стал играть более важную роль в жизни людей с момента появления Web 2.0. Взаимодействие между пользователями, дало им возможность свободно обмениваться информацией через социальные сети, форумы, блоги, википодобные сайты и другие интерактивные совместно разрабатываемые медиаресурсы.
Интернет стал играть более важную роль в жизни людей с момента появления Web 2.0. Взаимодействие между пользователями, дало им возможность свободно обмениваться информацией через социальные сети, форумы, блоги, википодобные сайты и другие интерактивные совместно разрабатываемые медиаресурсы.С другой стороны, налицо все недостатки концепции второго веба. Контент-ориентированность стала самым важным плюсом и минусом сети одновременно. Вопросы надежности и достоверности информации в полный рост стоят перед владельцами и пользователями интерактивных сообществ. Как и в реальной жизни, в процессе общения через сеть иногда возникают ситуации, когда некоторые пользователи нарушают правила общепринятого «сетевого» этикета. Фактически, чтобы сохранить нормальную атмосферу ресурса, владельцы вынуждены вводить искусственные правила взаимодействия и следить за их соблюдением.
Одним из таких явных нарушений является «троллинг».
«Троллинг» — нагнетание участником общения («троллем») гнева, конфликта путём скрытого или явного задирания, принижения, оскорбления другого участника или участников, зачастую с нарушением правил сайта и, иногда неосознанно для самого «тролля», этики сетевого взаимодействия. Выражается в форме агрессивного, издевательского и оскорбительного поведения. Используется как персонифицированными участниками, заинтересованными в большей узнаваемости, публичности, эпатаже, так и анонимными пользователями без возможности их идентификации. В частном случае «троллинг» — провокация «жертвы» с целью обратить на себя внимание.
В данной статье предлагается новый подход для вычисления злоумышленников. Данный метод базируется на мере конфликта функций доверия между различными сообщениями ветви обсуждения. Чтобы продемонстрировать состоятельность подхода протестируем его на искусственных данных.
В последнее время пути получения информации значительно сместились в сторону ускорения, облегчения и снижения трудозатрат. Фактически, благодаря интернету исследование той или иной темы свелось к простому нажатию кнопки мыши. Хотя по некоторым вопросам сложно найти удовлетворяющий ответ с помощью традиционных поисковых систем. Вместо этого, мы предпочитаем узнавать мнение эксперта.
В результате получил широкое распространение такой инструмент информационного взаимодействия, как сообщества вопросов-ответов (далее Q&AC). Такие системы позволяют каждому пользователю внести свою посильную лепту в развитие сообщества. К сожалению, не все сообщения надежны: некоторые пользователи выдают себя за экспертов, а другие публикуют бесполезные сообщения. Поэтому очень важным процессом становится работа модераторов данных сообществ. Чаще всего увеличение «мусорных» сообщений – результат действия «троллей».
– Q&AC: беглый обзор
А. Пользователи Q&AC
Пользователи — главные действующие лица Q&AC. Условно их можно разделить на: «экспертов», «учащихся» и «троллей».
Эксперты: пользователи, обладающие знаниями или навыками в той или иной области.
Учащиеся: пользователи пытающиеся получить информацию или опыт.
Тролли: лица любыми способами пытающиеся нарушить спокойствие сообщества. Их целью является создание контрпродуктивных обсуждений.
Б. Выявление источников в Q&AC
Многие исследования уже пытались оценить источники информации в сообществах.
В некоторых предлагаются модели оценки авторитетности пользователей, основанные на количестве лучших пользовательских ответов. Лучший ответ здесь определяется спрашивающим пользователем или методом голосования.
В других авторы концентрируются на выборе вопросов, избранных пользователем для ответа. Эксперты всегда предпочитают отвечать на вопросы, в которых более компетентны.
Некоторые авторы предлагают сложные структуры, основанные на когнитивных и поведенческих критериях пользователей, для оценки не только надежности, но и опыта поставщиков информации.
В. Неопределенность в Q&AC
При работе с информацией, поставляемой людьми, мы сталкиваемся с несколькими уровнями неопределенности. Для Q&AC предлагается три уровня неопределенности. Первый связан с экстракцией и интеграцией неопределенности, второй — с информационными источниками неопределенности, третий — с самой сущностью информации. В нашем случае в большей степени нас интересует оценка источников и часть неопределенности связанная с этим. Действительно, в сети, когда сталкиваемся с другими пользователями (т.е. источниками информации), мы практически никогда не обладаем априорным знанием о них.
– Математический аппарат
Одним из математических инструментов для моделирования и обработки неточных (интервальных) экспертных оценок, измерений или наблюдений является теория функций доверия.
Теория функций доверия или теория Демпстера – Шейфера использует математические объекты, называемые «функциями доверия». Обычно их основная цель заключается в моделировании степени доверия некоторого субъекта к чему-либо. В то же время в литературе имеется большое количество интерпретаций «функций доверия», которые могут использоваться в различных прикладных задачах.
Предлагаемый в статье подход предполагает использование этой теории в совокупности с введением величины, определяющей конфликт двух сочетающихся функций доверия.
Перейдем собственно к описанию метода.
Одно из важных предположений говорит о том, что «тролли» интегрируются только в популярные ветви обсуждения. Разбиваем дальнейшее описание метода на три шага.
1. Пользовательские сообщения
Исследователи предлагают основные характеристики «троллей»: агрессия, обман, нарушение правил, успех. Также указывают такие поведенческие характеристики как, пренебрежение нормами морали, явные садистские и психопатические наклонности. В контексте данной работы различия между «троллями» и другими пользователями исследователи выделяли вручную из сообщений. Исходя из этого, сообщения могут быть: релевантными, оффтопиком, чепухой или руганью. Определяем рамки характеризующие сообщения:
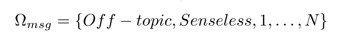
Характер сообщения определяется относительно опубликованного вопроса или топика. На этом этапе мы предполагаем, что метод однозначно определяет характер каждого сообщения.
2. Пользовательский конфликт
Обнаружение нерелевантных сообщений ещё не даёт однозначного ответа на вопрос принадлежности пользователя к когорте «троллей». Может попасться пользователь всего лишь задетый и отвечающий на поддевки. Кроме того предмет обсуждения может постепенно измениться. Фактически, для того чтобы отличить «тролля» от других пользователей, мы нуждаемся в количественной оценке, насколько данный пользователь конфликтует с другими. Предлагаемый подход и предполагает измерение величины конфликта между сообщениями каждого пользователя.
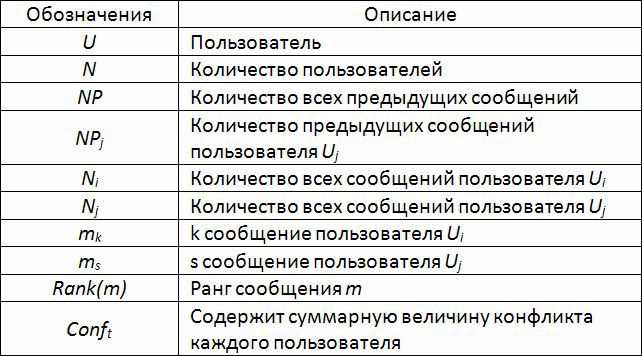
– Confmsg/U: мера конфликта между kth сообщением пользователя Ui и сообщениями написанными каждым другим пользователем Uj.
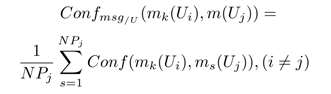
– Confmsg: мера конфликта между kth сообщением пользователя Ui и всеми сообщениями, написанными всеми другими пользователями U основанными на средневзвешенной величине. Эта величина учитывает количество сообщений, написанных каждым пользователем с целью определения уровня конфликта, особенно между «троллями» и экспертами.
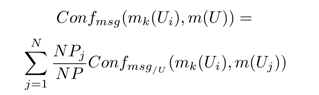
– Confuser: общая мера конфликта пользователя Ui
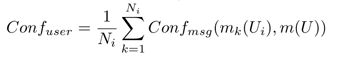
Величина совокупного конфликта пользователя может увеличиваться, когда он пускается в бесконечные прения с «троллем». В данном случае пользователь становится жертвой, а модераторы приходится контролировать поведение пользователей во многих тредах.
3. Кластеризация пользователей
Последний шаг состоит в классификации пользователей в соответствии с их мерами конфликта на две группы. Авторы предусмотрели для разбиения пользователей на группы использование алгоритма K-means.
Алгоритм k-means является простым повторяющимся алгоритмом кластеризации, который разделяет определенный набор данных на заданное пользователем число кластеров, k. Алгоритм прост для реализации и запуска, относительно быстрый, легко адаптируется и распространен на практике. Это исторически один из самых важных алгоритмов интеллектуального анализа данных.
В нашем случае число кластеров: k=2.
В результате работы алгоритма все пользователи разобьются на два кластера. «Тролли» попадут в группу с наибольшей мерой конфликта, а добропорядочные пользователи – с наименьшей мерой конфликта.
– Пример
Рассмотрим следующий пример:
Возьмём одну из ветвей обсуждения, содержащую тридцать одно сообщение написанных восемью пользователями. Общая мера конфликта каждого пользователя, выраженная через уравнение [4] показана на рисунке ниже.
Пользователь U1 отправил три релевантных и два спорных сообщения ответом на сообщение пользователя U4.
Пользователь U2 отправил семь релевантных сообщений и два спорных сообщения ответом на сообщение пользователя U4.
Пользователь U3 отправил четыре релевантных сообщения и одно сообщение оффтопом пользователю U8.
Пользователь U4 опубликовал два спорных сообщения.
Пользователь U5 опубликовал одно релевантное сообщение.
Пользователь U6 опубликовал три релевантных сообщения.
Пользователь U7 опубликовал два релевантных сообщения.
Пользователь U8 опубликовал три сообщения: два первых оффтопом, одно спорное.
Общая мера конфликта пользователя U4 больше относительно U8, потому что второй публиковал свои сообщения после большого количества релевантных сообщений других пользователей. Таким образом, эта ситуация показала более высокую меру конфликта.
Применим алгоритм k-means, который разобьет пользователей на две группы:

Пользователи U1; U2; U3; не классифицируются как «тролли», несмотря на некоторые их сообщения, так как они публиковали и релевантные сообщения.
– Выводы
«Троллинг» в сети однозначно определяется как негативное и в некотором роде даже деструктивное явление, приводящее к усложнению получения информации пользователями. Во многих современных онлайн сообществах существуют рейтинговые системы саморегуляции, но, ни одна из них все равно не обходится без модерации. Что само по себе приводит к увеличению затрат владельцев сообществ. Небольшие ресурсы в основном обходятся своими силами, крупные вынуждены содержать специалистов.
В данной статье предложен новый синтезированный подход к определению качества пользователя по характеру опубликованных им сообщений. На данный момент авторы разработали методику поиска недобросовестных пользователей одной ветви обсуждений (треда), но предполагают расширить ее работу в рамках всего сообщества.
При написании топика я был вынужден упустить часть описания тяжеловесного матаппарата, чтобы сделать статью не только полезной, но и читабельной. Так как ссылки еще никто не отменял, интересующиеся темой могут восполнить это упрощение самолично.
К сожалению, в рамках одной статьи невозможно объять необъятное, поскольку данная тема весьма обширна и при детальной разработке тянет как минимум на кандидатскую. Если данную методу удастся прикрутить к кармаформуле любого сообщества, возможны перспективы избавления от нудной обязанности шерстить комментарии
Не выполнено:
В данной работе различия между «троллями» и другими пользователями выделяли вручную, для практического применения такой вариант не подходит. Понятно, что процесс можно автоматизировать, хотя бы по оценкам комментариев. Попытка реализации алгоритма на примере Хабра не увенчалась успехом, в основном из-за того, что заминусованные комментарии затирает НЛО.
Работы в данном направлении будут продолжены.
Дополнительная информация по кластеризации на Хабре: «Кластеризация: алгоритмы k-means и c-means».
