Shinken
Согласно официальному сайту, Shinken — фреймворк мониторинга; переписанный с нуля на питоне Nagios Core, с улучшенной поддержкой больших окружений и более гибкий.
Масштабируемость
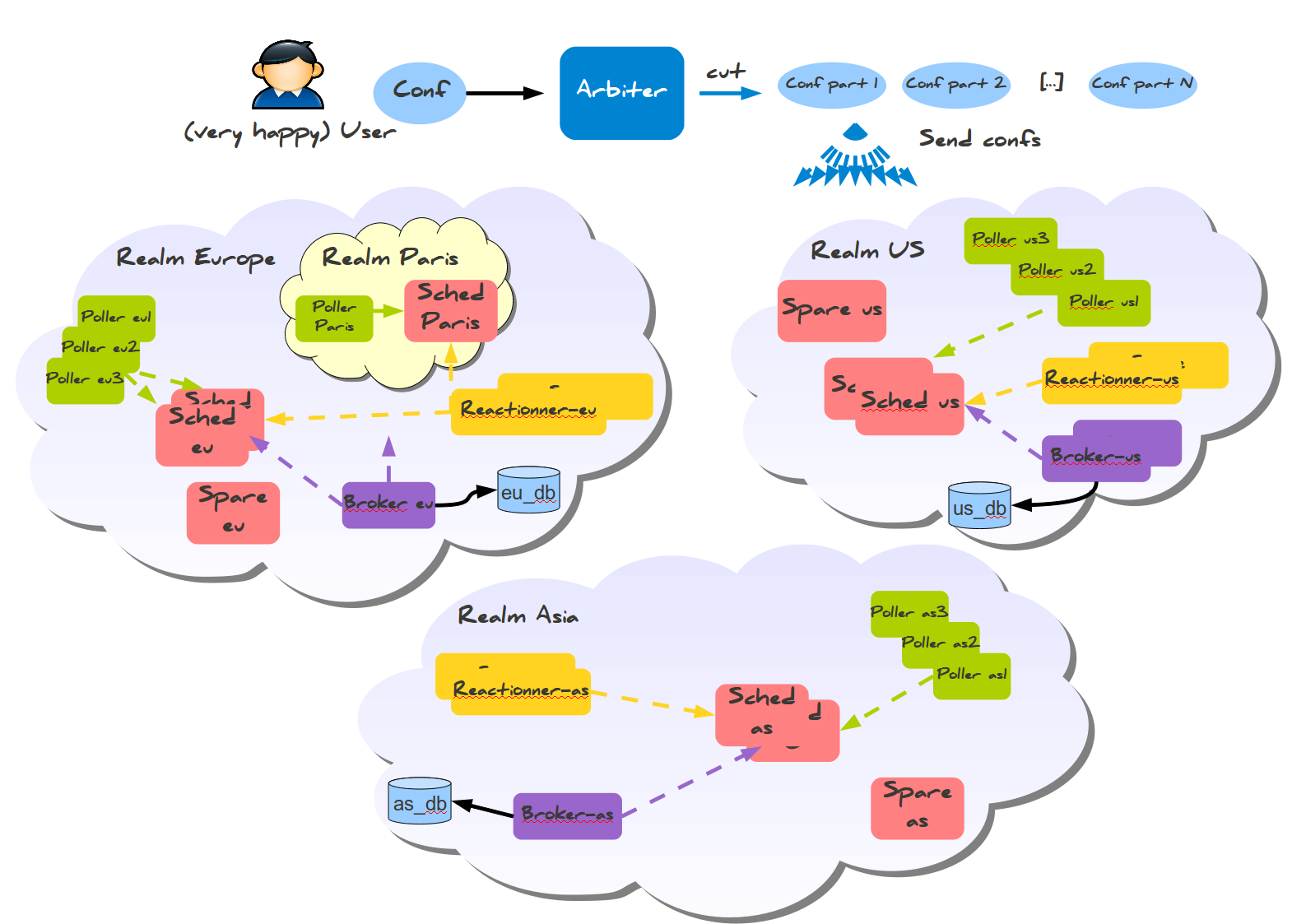
Согласно документации, каждый тип используемых процессов может запускаться на отдельном хосте. Это очень полезная возможность, поскольку вы можете захотеть иметь базу данных в самом дешёвом месте, процессы сбора информации в каждом датацентре, и процессы рассылки уведомлений ближе к своему физическому расположению. Пользователь Shinken на схеме счастлив, это точно является хорошим признаком:
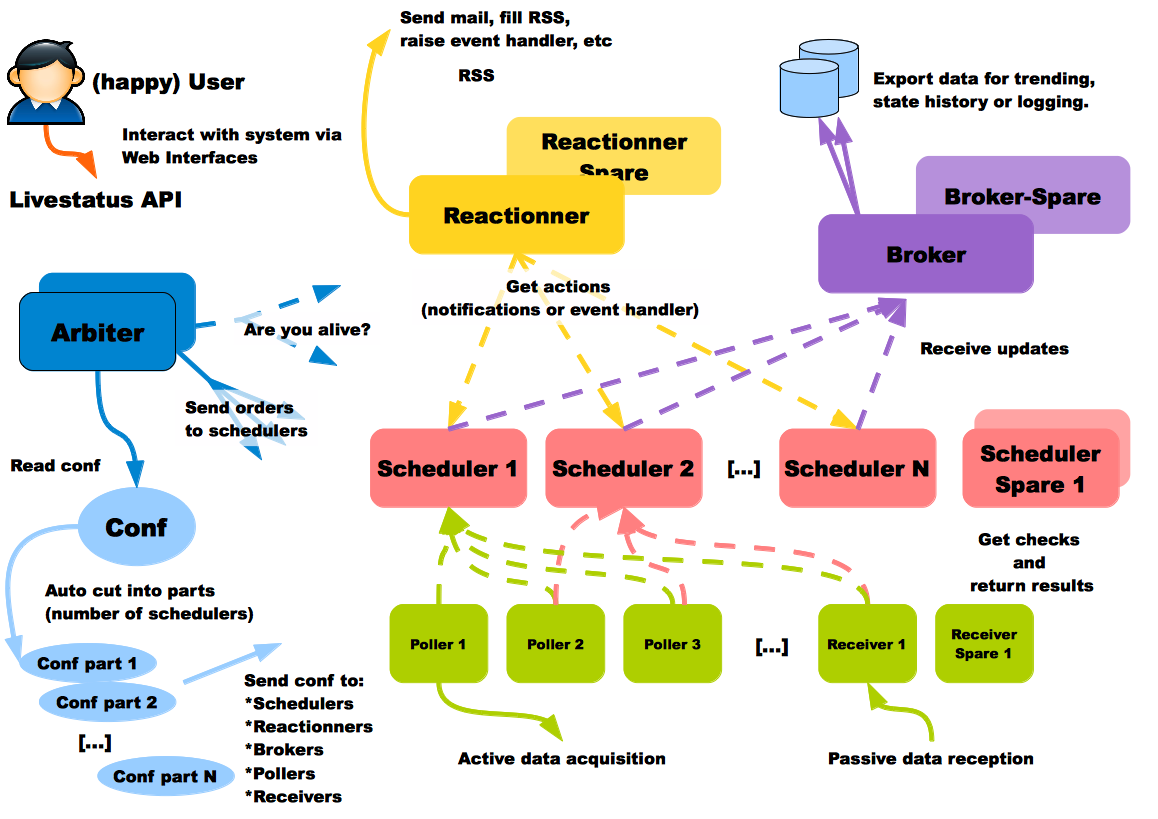
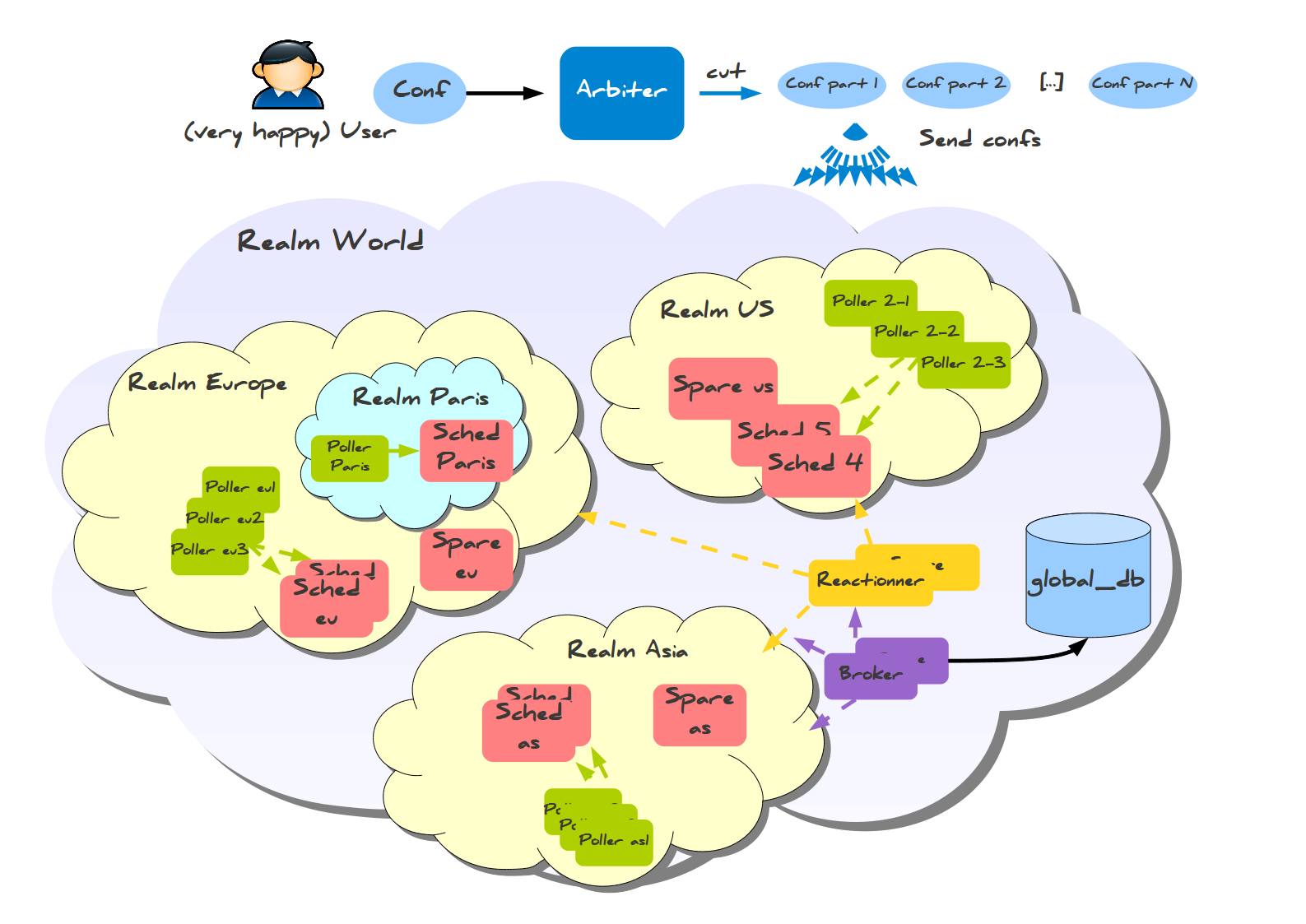
Эта система также имеет готовую конфигурацию для межрегионального мониторинга, называемая Realms (Сферы).
Здесь вы можете заметить кое-что изумительное: информация собирается в региональные базы данных, а не в одну мастер-базу. Также существует меньшая разновидность конфигурации со сферами для меньших распределённых конфигураций, которая требует всего одну базу данных и несколько хостов для установки:
Ещё одной болевой точкой при оценке масштабируемости является отказоустойчивость. Эту информацию я процитирую из документации:
Никто не идеален. Сервер может упасть, как и приложение, поэтому администраторы имеют подмены: они могут взять конфигурацию упавших элементов и переподнять их. На текущий момент единственный процесс, который не имеет подмены — Арбитр, но в будущем он будет доработан. Армибр регулярно проверяет, доступны ли все остальные процессы, и если планировщик или другой процесс мертвы, он посылает их конфигурацию на другую ноду, определённую администратором. Все процессы оповещаются об этом изменении, так что они могут использовать новую ноду для доступа к процессу, и не будут пытаться использовать зазбоившую. Если нода была потеряна из-за сетевых проблем, и вернулась в строй, Арбитр заметит это и попросит ноду, выступавшую заменой, сбросить свою временную роль.
Интеграция с системами управления конфигурацией
Автоматическое нахождение хостов и сервисов хорошо покрывается документацией, и, поскольку конфигурация хранится в файлах, вы довольно просто можете генерировать её с помощью Chef\Puppet, основываясь на информации, уже имеющейся в системе конфигурации (например, PuppetDB).
Логирование действий
Поскольку конфигурация хранится в файлах, вы можете использовать имеющиеся инструменты типа системы контроля версий (Git, Mercurial) для отслеживания изменений и их владельцев. В документации я не нашёл никаких подтверждений того, что Shinken записывает куда-либо действия пользователя в веб-интерфейсе.
UI
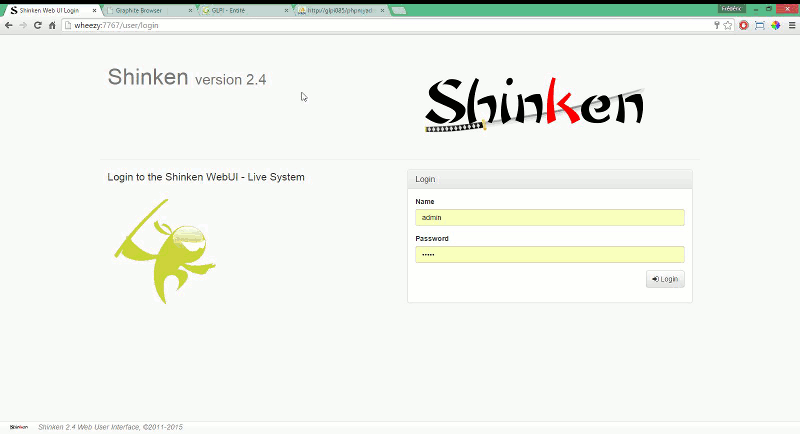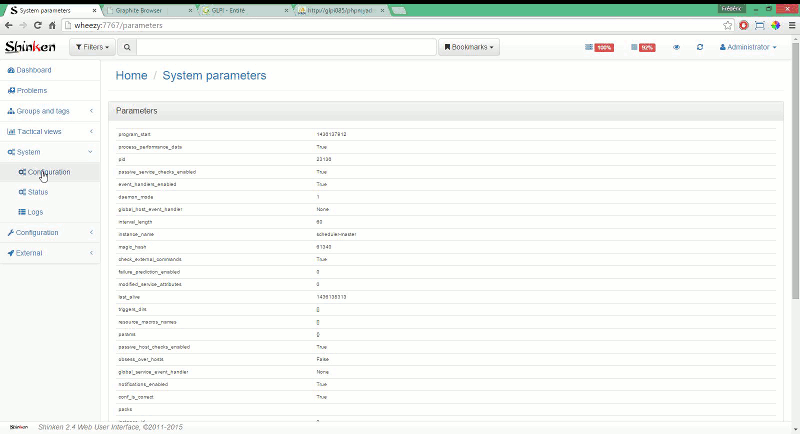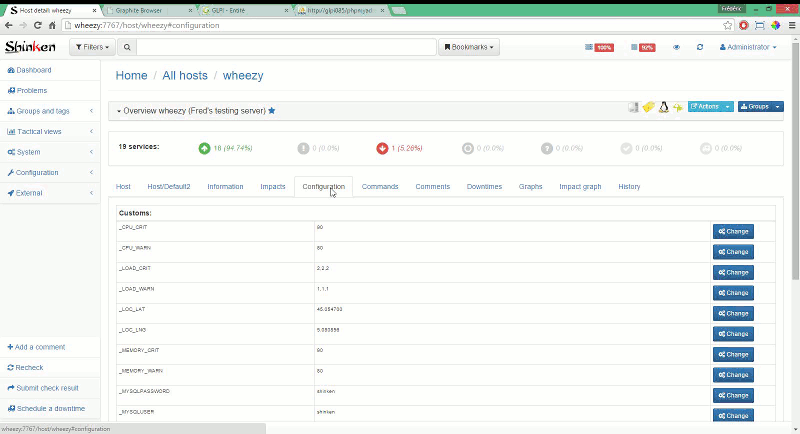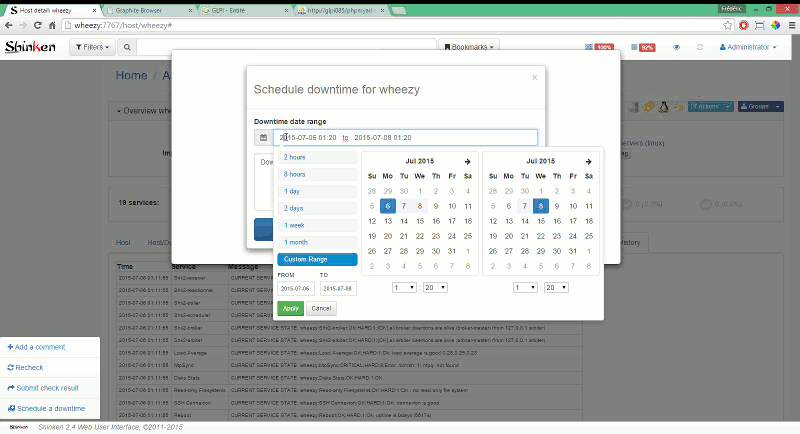
Shinken WebUI по заверениям использующих его людей хорошо показал себя при работе с тысячами машин и десятками групп.
Недостатки
Прошерстив документацию, я не нашёл видимых недостатков. Единственная вещь, которая меня смущает, это стремительная разработка в прошлом и очень медленный темп коммитов в настоящем: около 40 в этом году, большинство — вливание пулл-реквестов с багфиксами. Система или слишком хороша для дальнейшего развития (чего не бывает в природе, даже такие старички, как vim и emacs получают новые релизы), или теперь это ещё один открытый проект с недостаточно большим сообществом или проблемами с мейнтейнером — это такая информация, которую хотелось бы знать до начала использования такой комплексной вещи, как система мониторинга.
Frédéric Mohier, бывший когда-то в команде разработки Shinken любезно предоставил информацию по этому вопросу: больше года назад несколько разработчиков из команды, будучи несогласными с политикой разработки, покинуло проект и сделало форк, названный Alignak, в данный момент активно разрабатываемый, первый стабильный релиз (1.0) планируется на декабрь 2016.
Ссылки
Sensu
Sensu — фреймворк для мониторинга (или платформа, как они сами о себе говорят), но не готовая система мониторинга.
Её сильные стороны включают:
- Интеграция с Puppet \ Chef — определяйте, что проверять, и куда отправлять уведомления прямо в вашей системе управления конфигурацией
- Использование имеющихся технических решений там, где это возможно, вместо изобретения велосипедов (Redis, RabbitMQ)
Sensu вытягивает события из очереди и выполняет на них обработчики, вот и всё. Обработчики (Handlers) могут посылать сообщения, выполнять что-то на сервере, или делать что угодно ещё, чему вы их научите.
Масштабируемость
Sensu имеет гибкую архитектуру, поскольку каждый компонент может быть продублирован и заменён несколькими путями. Пример простой отказоустойчивой системы описан в следующей презентации; вот общая схема:
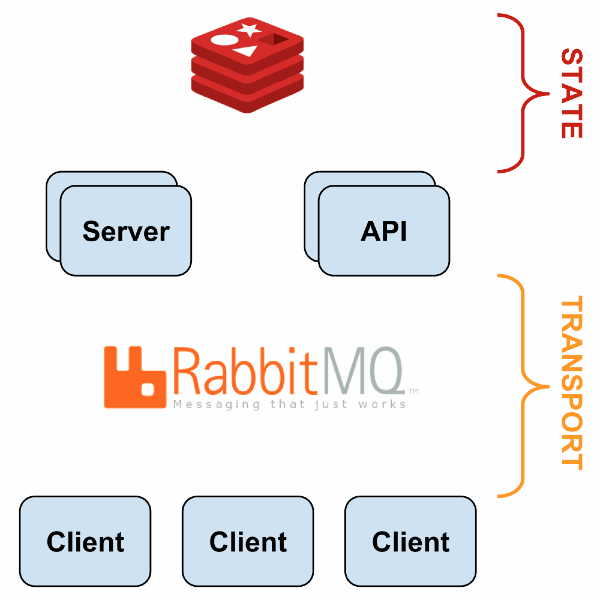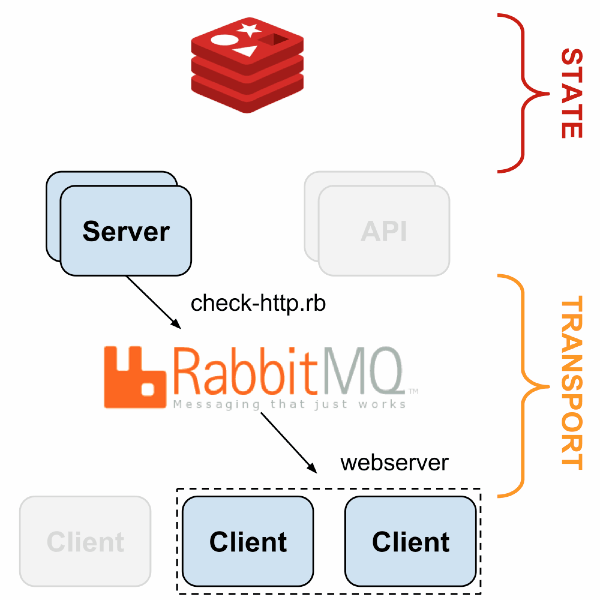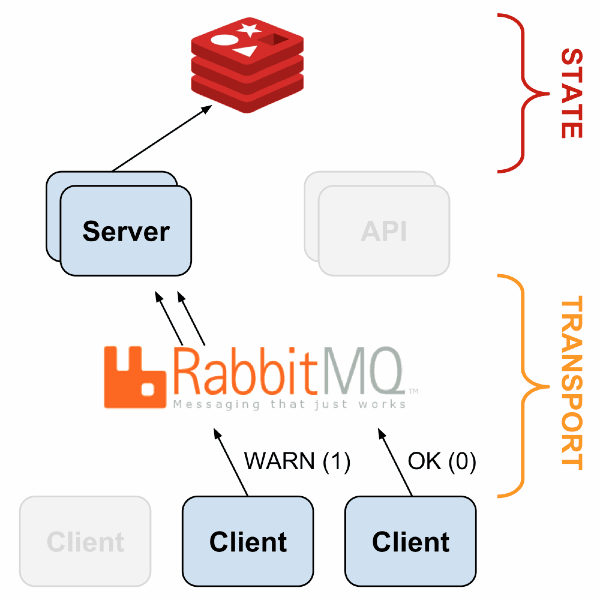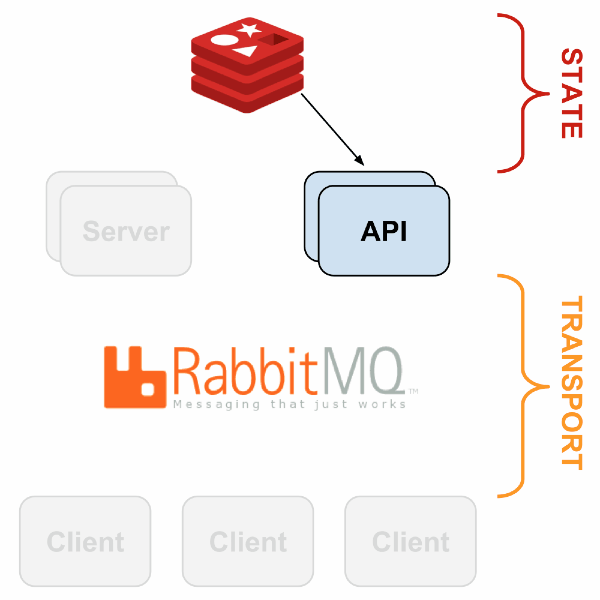
С HAProxy и Redis-sentinel вы можете построить систему, в которой, при наличии хотя бы одной живой машины каждого типа (Sensu API, Sensu Dashboard, RabbitMQ, Redis) мониторинг будет продолжать работать без какого-либо ручного вмешательства.
Интеграция с системами управления конфигурацией
Встроенная (Puppet, Chef, EC2?!) но только в платной версии, что плохо, особенно если у вас тысячи серверов и вы не хотите платить за что-то, имеющее бесплатные аналоги.
Логирование действий
Встроенное, однако только в платной редакции.
UI
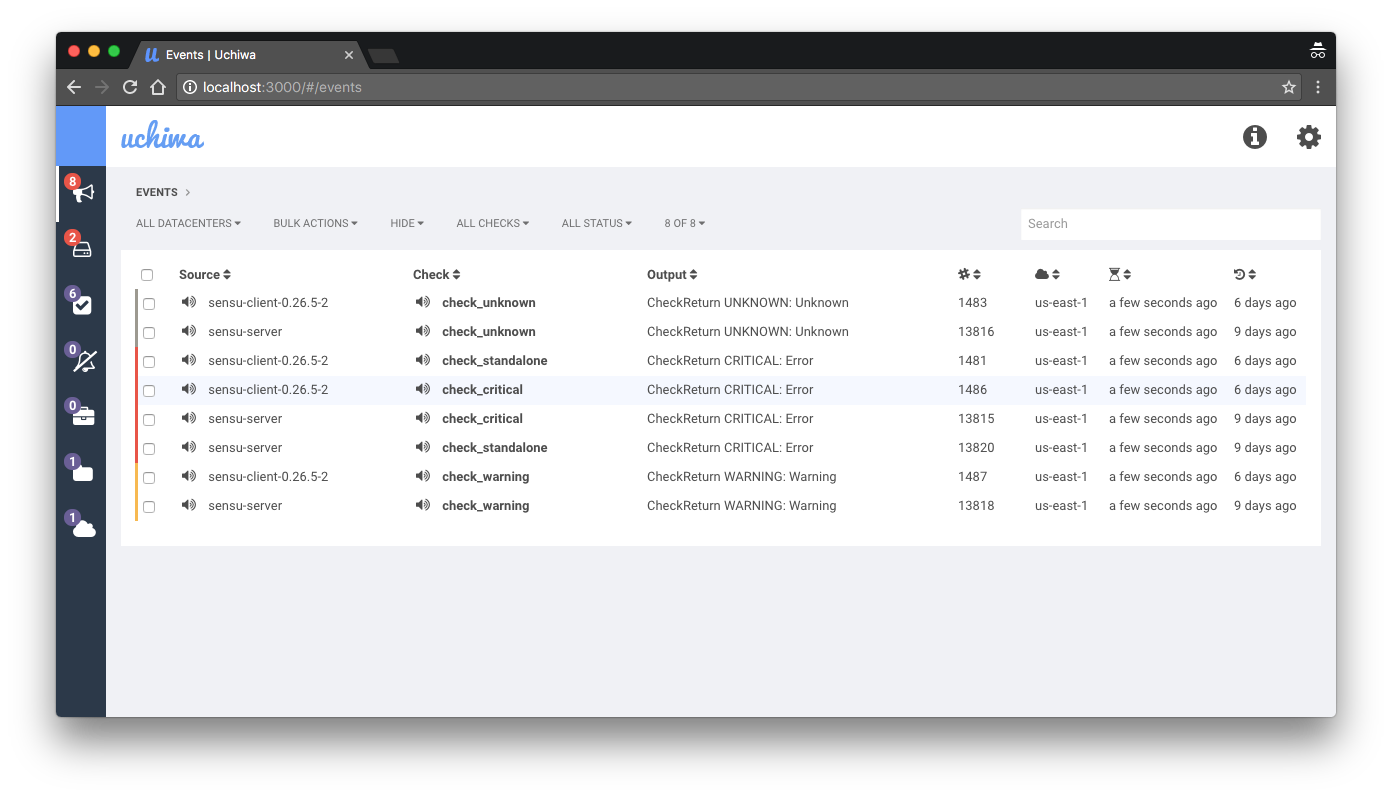
Интерфейс по-умолчанию для Sensu, Uchiwa, имеет много ограничений. Он выглядит слишком простым для окружения с тысячами хостов, которые имеют большой разброс по ролям. Платная версия имеет свой собственный дашборд, однако он не сильно отличается от бесплатной редакции, и только добавляет несколько выключенных из-коробки возможностей открытой версии.
Недостатки
- Отсутствие исторической информации и очень ограниченные возможности создания проверок, основанной на ней;
- Подход "сделай сам" — нет готового мониторинга, который можно было бы включить для вашей системы сразу после установки;
- Агрегирование событий нетривиально;
Замудрёная отправка сообщений, что страшно (потому что это та часть системы, которая должна быть самой простой и надёжной)— неправда, я получил неправильное впечатление от документации, спасибо x70b1 за разъяснение;- Путь "мы не хотим изобретать колесо" имеет свои ограничения, которые могут быть вам знакомы, если вы когда-либо использовали подобные системы (в моём случае, это была система мониторинга Prometheus, которая оставляла ряд функций на откуп пользователю, например, авторизацию\аутентификацию\идентификацию).
Ссылки
Icinga 2
Icinga это форк Nagios'а, во второй версии переписанный с нуля. В отличии от Shinken, этот живой, часто обновляющийся проект.
Масштабируемость
Общая архитектура:
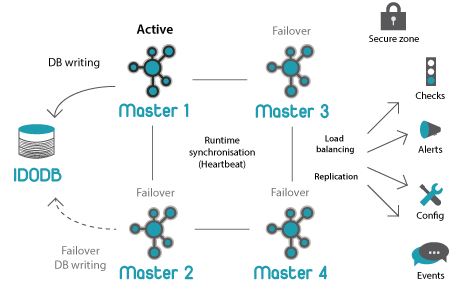
Icinga 2 имеет хорошо продуманную схему распределённого мониторинга. Единственный минус, который я обнаружил при поднятии тестового кластера — сложная изначальная настройка даже самой простейшей распределённой схемы.
Интеграция с системами управления конфигурацией
Интеграция довольно хороша, вот две презентации по теме: The Road to Lazy Monitoring with Icinga 2 and Puppet от Tom de Vylder, и Icinga 2 and Puppet: Automated Monitoring от Walter Heck. Ключевой особенностью Icinga является хранение конфигурации в файлах, что позволяет легко генерировать конфигурацию средствами Puppet, что в моём случае получилось, используя PuppetDB в качестве источника информации о всех хостах и сервисах.
Логирование действий
Как я обнаружил, логирование действий представлено в модуле director. Встроенной поддержки аудита в IcingaWeb2 в данный момент нет.
UI
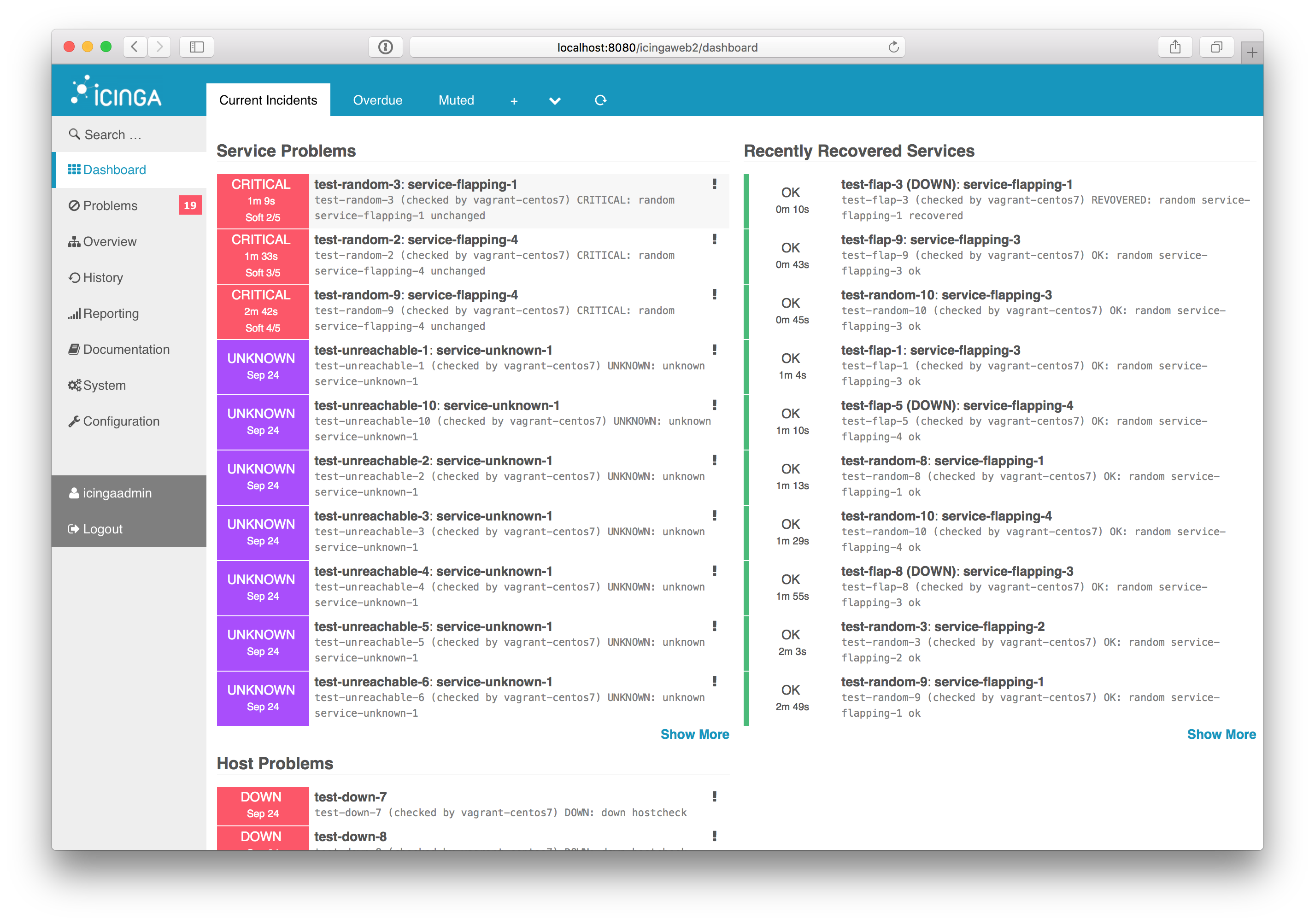
IcingaWeb2 выглядит неплохим UI с большим количеством дополнений под разные нужды. Из того, что я видел, он выглядит самым гибким и расширяемым, в то же время из коробки поддерживая все возможности, которые вы можете ожидать.
Недостатки
Единственным недостатком, который я встретил, является сложность изначальной настройки. Непросто понять взгляд Icinga на мониторинг, если вы до этого использовали что-то совершенно иное, как, в моём случае, Zabbix.
Zabbix
Zabbix — стабильная и надёжная система мониторинга с устойчивой скоростью развития. Он имеет огромное сообщество пользователей и большинство вопросов, которыми вы зададитесь, уже где-то отвечены, так что вам не прийдётся лишний раз волноваться, а возможно ли то или иное в Zabbix.
Масштабируемость
Сервер работает с единственной базой данных, и вне зависимости от ваших действий, с любыми другими ресурсами на руках (память, сеть, CPU), вы в какой-то момент упрётесь в ограничения IO на диске, используемом базой данных. С 6000 IOPS в Amazon мы поддерживаем около двух тысяч nvps, новых значений в секунду, что неплохо, но всё же оставляет желать лучшего. Прокси и partitioning базы данных улучшает производительность, однако с точки зрения отказаустойчивости вы всё ещё имеете одну-единственную БД, которая является точкой отказа для всей системы.
Интеграция с системами управления конфигурацией
Zabbix слабо подготовлен для разнообразного окружения, которое управляется системой управления конфигураций. Он имеет встроенные возможности для low-level обнаружения хостов и сервисов, но они имеют свои ограничения и не имеют привязки к системе конфигурации. Единственная возможность для подобной интеграции — собственное решение, использующее API.
Логирование действий
Zabbix хорошо логирует действия пользователей, за исключением одного слепого пятна: изменения, сделанные через API, большей частью не логгируются, что может быть или может не быть проблемой для вас. Ещё одна вещь, которую я хотел бы упомянуть, это то, что все проблемы с Zabbix записаны где-то в баг-трекере, и, если они получают достаточно внимания со стороны сообщества, то рано или поздно устраняются.
UI
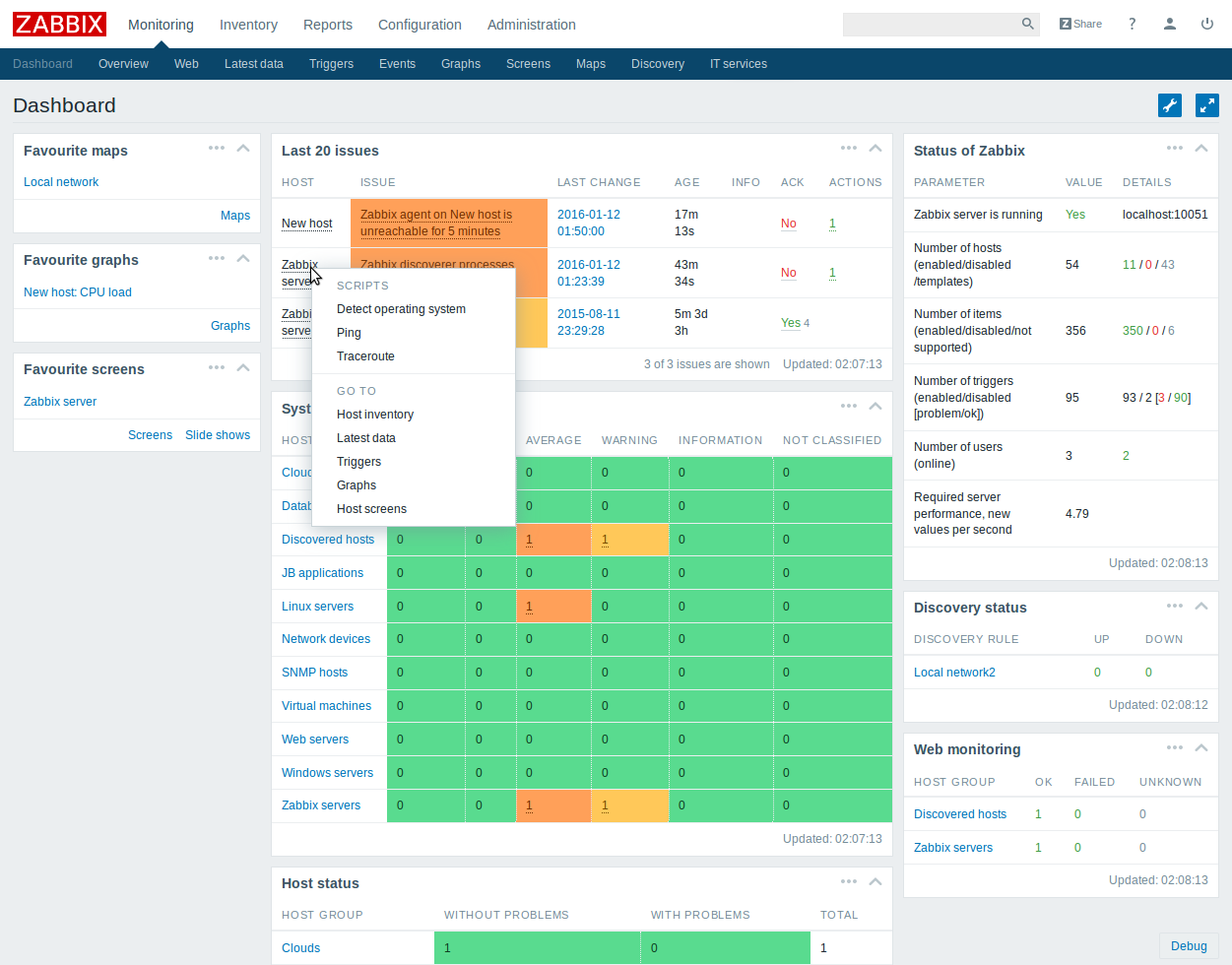
UI Zabbix'а удобен и включает в себя много возможностей. Обратная сторона — он практически не расширяем, вы или смиряетесь с тем, что предлагает вам стандартный dashboard, либо создаёте свой собственный. Доработка стандартного UI является очень нетривиальной задачей из-за его сложности.
Недостатки
- Только базовая аналитика о том, что происходит в данный момент (не в плане текущих проблем, а частоты из происхождения и подобной информации). Ситуация сильно улучшилась с появлением "топ 100 стреляющих триггеров" в 3.0;
- Настройка плановых работ (maintenance), в отличии от систем, основанных на Nagios, не может быть выставлена на уровне триггера, и была довольно сложной до недавней переделки 3.2;
- Генерация алертов из-коробки оставляет желать лучшего (что, впрочем, является проблемой всех до единой систем мониторинга). В нашем случае пришлось разработать внешнюю систему аггрегации алертов (возможно, когда-нибудь она будет опубликована в opensource);
- Расследование проблем с производительностью без соответствующего опыта превращается в беспорядок, потому что у вас есть один неделимый сервер, который вам необходимо диагностировать.
Disclaimer
Это длинная запись с большим количеством картинок и ещё большим количеством текста. Здесь вы не найдёте однозначного ответа на простые вопросы наподобие "что лучше", но информацию для ответа на эти вопросы, основываясь на вашем опыте и желаниях. Я рассматриваю условия работы в Linux и слежения за Linux-хостами, поэтому поддержка системой разных платформ в расчёт не принималась. Также за условие принималось требование возможности следить за тысячами машин и тысячами сервисов.
По моему мнению, только Zabbix и Icinga 2 являются достаточно зрелыми для использования в "энтерпрайзе", главный вопрос, который должен задать себе тот, кто выбирает систему — какая философия мониторинга ему ближе, поскольку обе они позволяют получить один и тот же результат, используя совершенно разные подходы.

{kind=link}