
Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени :)

10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
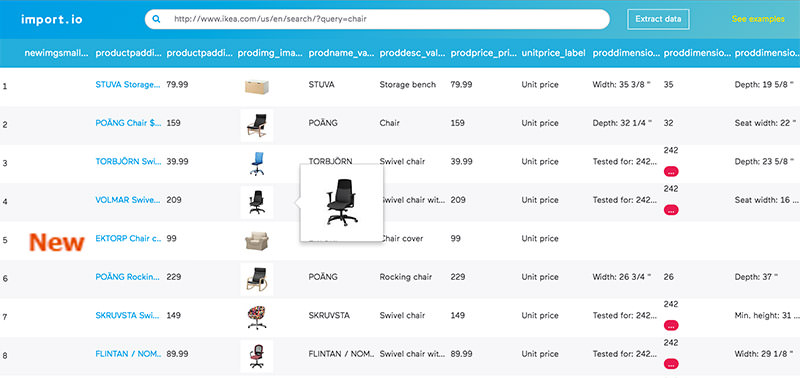
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.

Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.

Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.

ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
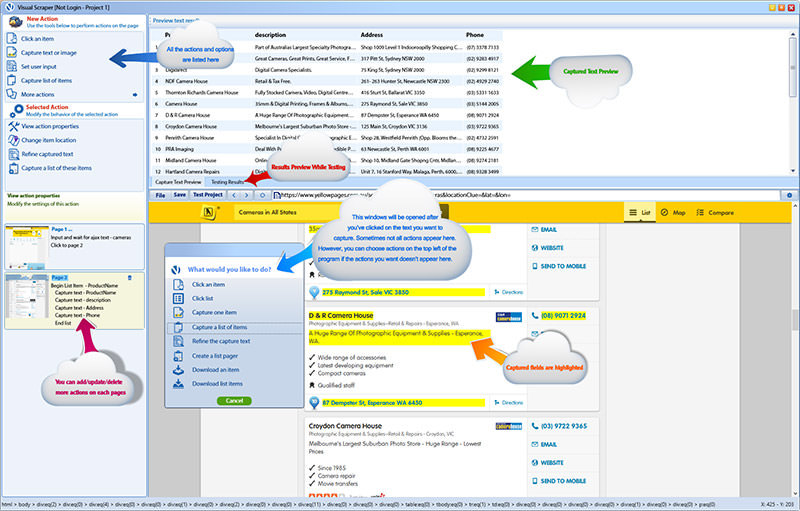
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
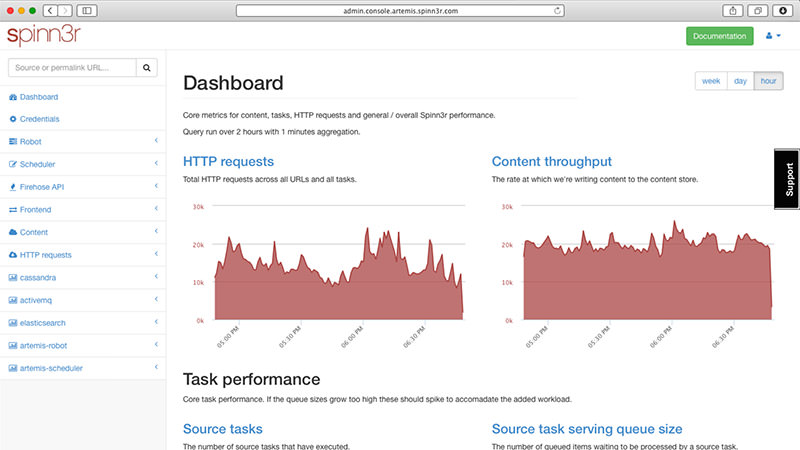
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.

Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
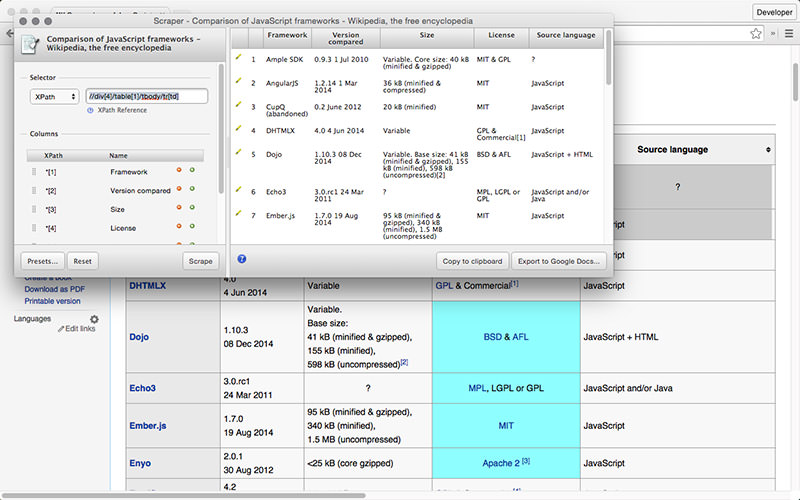
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
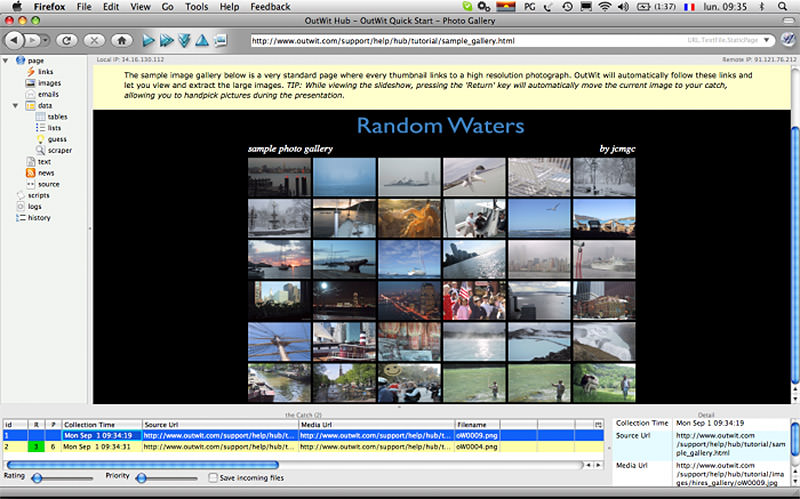
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
