Apache Ignite – распределенная база данных в памяти, подобные БД получают распространение и хочется сравнить с тем что уже есть и зарекомендовало себя, например реляционная СУБД Oracle. Ignite имеет широкие возможности распределенных вычислений, также есть поддержка SQL на уровне ANSI-99, в производительности SQL и хочется сделать некоторое сравнение. Настройка БД будет в обоих случаях во многом по умолчанию, в случае Oracle это XE, а в случае Ignite это два узла(node) на одном компьютере. Компьютер i5 7400 (4-ядра) 3.5Ггц, 8Гб ОЗУ, SSD диск.
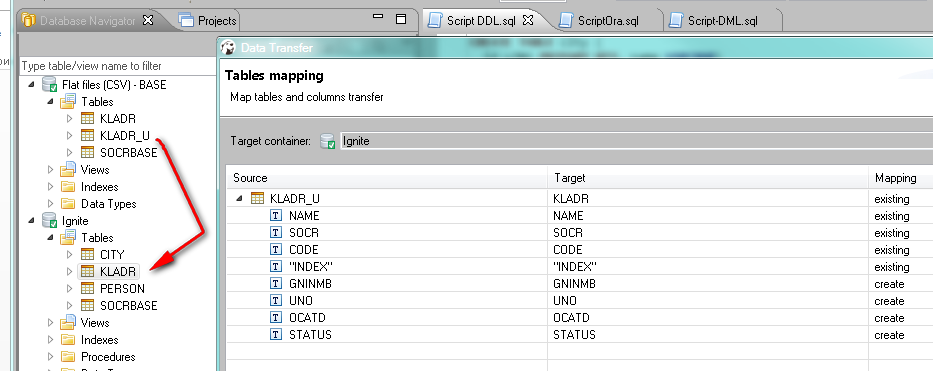
В качестве тестовых данных буду использовать данные КЛАДР (~223 тыс. записей) в качестве среды выполнения запросов DBeaver в котором настроены два подключения к Ignite и Oracle. И первое что сделаю импортирую данные в таблицы, Данные КЛАДР из DBF переведу в CSV, а затем средствами DBeaver выполню импорт в таблицы.
Ignite сконфигурирован так же для хранение данных в постоянном хранилище.
config\default-config.xml
Структура таблицы Kladr
affinityKey=CODE — означает что данные в Ignite будут распределены по partition и еще распределены по двум узлам. Два узла обеспечены запуском двух экземпляров Ignite.
Еще одна не большая таблица SOCRBASE, это справочник сокращений, у него другое правило хранения в распределенной сети.
WITH «template=replicated» — таблица будет в полном объеме на каждом узле. Тогда каждый узел когда получив join запрос сможет соединить свои данные с этим справочником, при другой модели хранения нужно было бы обеспечить согласованность partition таблиц.
Вот запущенные две node
первая:

вторая:

Для Orcale структура та же, за исключением partition.
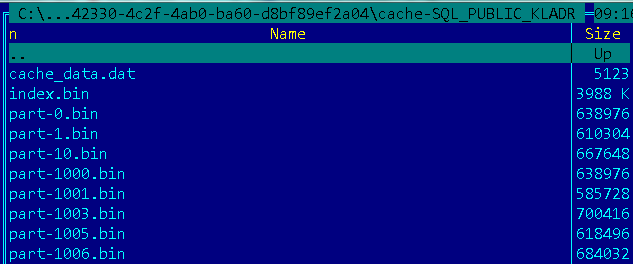
Persistent — хранилище Ignite на диске выглядит как распределение по партициям (файлам), всего их для каждого узла 1024, т.е. все данные для узла распределены в 1024 блока, причем какие то из них находятся на первом узле, а другие на втором.
Пример одного узла
Во время выполнения запросов Ignite будет делать распределенный запрос на узлы, те в свою очередь собирать те данные которые у них есть, затем данные будут консолидироваться и отправляться в итоговой выборке.
Итак первое — это импорт данных средствами DBeaver из CSV, 223 тыс. записей. Вот первый результат.
Далее выполню несколько несложных запросов на поиск данных для сравнения, за результат буду брать второе выполнение подряд (оно всегда меньше для двух БД).
Да в последнем случае именно 13 сек. показал Ignite запрос, что то с join не все хорошо, правда введение условия ограничивающего данные, уменьшает это время.
Наверное этих сравнений достаточно, не буду делать пока вывод, продолжу изучение Ignite…
Материалы:
Ignite
Getting Started
Getting Started SQL
В качестве тестовых данных буду использовать данные КЛАДР (~223 тыс. записей) в качестве среды выполнения запросов DBeaver в котором настроены два подключения к Ignite и Oracle. И первое что сделаю импортирую данные в таблицы, Данные КЛАДР из DBF переведу в CSV, а затем средствами DBeaver выполню импорт в таблицы.

Ignite сконфигурирован так же для хранение данных в постоянном хранилище.
config\default-config.xml
<!-- Enabling Apache Ignite Persistent Store. -->
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
</bean>
</property> Структура таблицы Kladr
CREATE TABLE Kladr (
NAME VARCHAR,
CODE VARCHAR,
SOCR varchar,
INDEX VARCHAR, PRIMARY KEY (CODE))
WITH "affinityKey=CODE"; affinityKey=CODE — означает что данные в Ignite будут распределены по partition и еще распределены по двум узлам. Два узла обеспечены запуском двух экземпляров Ignite.
Еще одна не большая таблица SOCRBASE, это справочник сокращений, у него другое правило хранения в распределенной сети.
CREATE TABLE Socrbase (
LEVEL LONG,
SCNAME VARCHAR,
SOCRNAME VARCHAR,
KOD_T_ST LONG,
PRIMARY KEY (KOD_T_ST))
WITH "template=replicated";
WITH «template=replicated» — таблица будет в полном объеме на каждом узле. Тогда каждый узел когда получив join запрос сможет соединить свои данные с этим справочником, при другой модели хранения нужно было бы обеспечить согласованность partition таблиц.
Вот запущенные две node
первая:

вторая:

Для Orcale структура та же, за исключением partition.
Persistent — хранилище Ignite на диске выглядит как распределение по партициям (файлам), всего их для каждого узла 1024, т.е. все данные для узла распределены в 1024 блока, причем какие то из них находятся на первом узле, а другие на втором.
Пример одного узла
Во время выполнения запросов Ignite будет делать распределенный запрос на узлы, те в свою очередь собирать те данные которые у них есть, затем данные будут консолидироваться и отправляться в итоговой выборке.
Итак первое — это импорт данных средствами DBeaver из CSV, 223 тыс. записей. Вот первый результат.
| Импорт данных 223 тыс. записей (КЛАДР) | |
| Ignite 12 мин | Oracle 5 сек. |
Далее выполню несколько несложных запросов на поиск данных для сравнения, за результат буду брать второе выполнение подряд (оно всегда меньше для двух БД).
Получить 100 записей КЛАДР по любым 100 CODE, по CODE есть индекс |
|
| Ignite 30 мсек. | Oracle 6 мсек. |
Получить 100 записей КЛАДР по любым 100 NAME, по NAME нет индекса |
|
| Ignite 80 мсек. | Oracle 6 мсек. |
Посчитать количество субъектов в регионе |
|
| Ignite 30 мсек. | Oracle 6 мсек. |
Количество субъектов в регионе более 1000 |
|
| Ignite 150 мсек. | Oracle 60 мсек. |
Join запрос. Получить 100 субъектов первого уровня |
|
| Ignite 280 мсек. | Oracle 2 мсек. |
Join запрос. Количество субъектов на уровнях |
|
| Ignite 13 сек. | Oracle 140 мсек. |
Да в последнем случае именно 13 сек. показал Ignite запрос, что то с join не все хорошо, правда введение условия ограничивающего данные, уменьшает это время.
Наверное этих сравнений достаточно, не буду делать пока вывод, продолжу изучение Ignite…
Материалы:
Ignite
Getting Started
Getting Started SQL
