
По встроенным механизмам безопасности ASP .NET Core написано мало статей. Даже официальная документация имеет пробелы. В этой статье мы пройдём по всем основным компонентам, имеющим отношение к безопасности, и разберём, как это работает внутри.
Если вы используете старый добрый ASP .NET, то для вас будет полезна информация по внутреннему устройству компонентов безопасности и лучшим практикам их использования. Здесь вы найдёте ответы на следующие вопросы: как реализованы современные анти-XSS механизмы и как их правильно использовать в ASP .NET Core? Как правильно работать с cookies и какие подводные камни там могут встретиться? Как был переписан механизм защиты от CSRF? Как правильно работать с криптографическими алгоритмами? Кроме того, рассказывается про опыт участия в Bug Bounty по поиску уязвимостей в ASP .NET Core.
Перед чтением рекомендуется освежить в памяти атаки из списка OWASP Top 10.
Прототипом статьи является доклад Михаила Щербакова на конференции DotNext 2017 Moscow. Михаил — Microsoft .NET MVP, участник .NET Core Bug Bounty Program, соорганизатор сообщества .NET программистов (Московское комьюнити называется MskDotNet, питерское — SpbDotNet). По работе последние 5 лет занимается безопасностью. Работал в Positive Technologies, в Cezurity, сейчас как консультант работает напрямую с заказчиками, по большей части в этой же сфере. Профессиональные интересы: статический и динамический анализ кода, информационная безопасность, автоматизация отладки кода, исследование внутреннего устройства .NET CLR.
В этом тексте огромное количество картинок со слайдов. Осторожно, трафик!

В этой статье мы поговорим про атаки и механизмы защиты, а именно про Open Redirect, про изменения в Crypto API в .NET Core, про XSS и Client-side атаки, про настройку CSP, CSRF, CORS и вообще про правильные паттерны использования cookies.
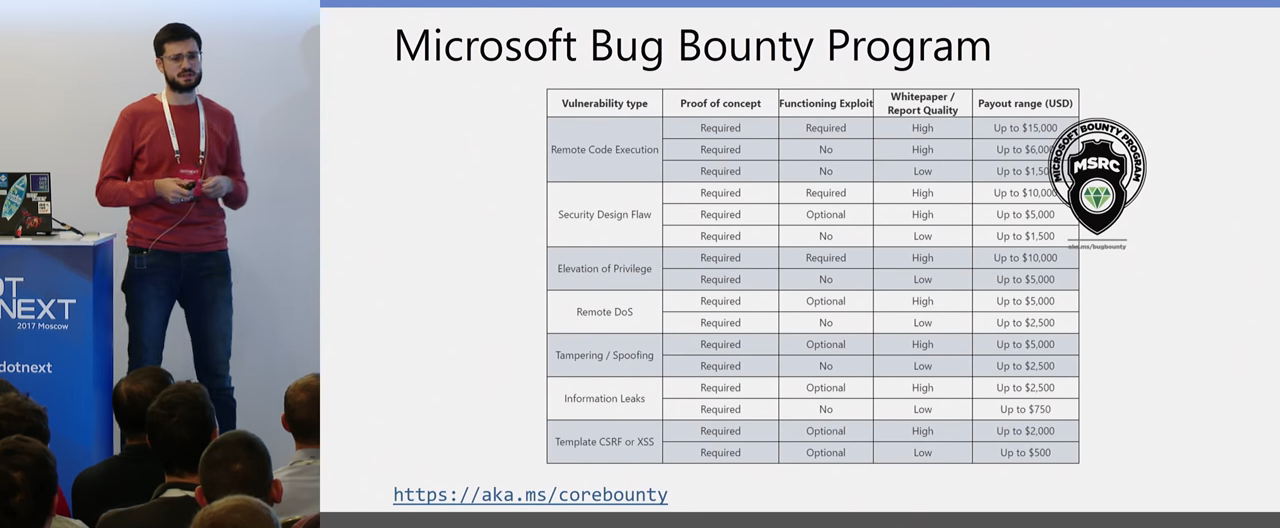
У Microsoft сейчас открыта бессрочная Bug Bounty программа, и я в ней участвую. Если кто-то из вас интересуется и занимается безопасностью, вы можете поискать уязвимости в .NET-платформе, отправить им report. У них приятное вознаграждение, где-то в среднем 5- 10 тысяч они готовы платить за найденную верифицированную уязвимость. И это приятно, что Microsoft сейчас вкладывает довольно большие усилия в безопасность .NET-платформы и .NET Core в частности.

Начнем с предотвращения атаки Open Redirect. Я думаю, многие про него знают, но не знают, что именно это называется Open Redirect. Давайте посмотрим на демку. Я думаю, большинство из вас сходу поймут, в чём заключается атака.

Итак, у нас есть некий сайт, который написан на ASP.NET, он называется my-telegram.com, у нас есть некий злоумышленник, который составляет следующий url на форму логина. Это совершенно стандартная ASP.NET форма логина. Атакующий отправляет эту ссылку жертве и каким-то образом заставляет по этой ссылке перейти.

Обычно это несложно, с помощью социальной инженерии или чего-то еще. Жертва, переходя по ссылке, видит знакомый сайт, my-telegram, вводит свой логин и пароль. Это совершенно валидные для пользователя действия. После того, как он логинится, он получает следующее сообщение:
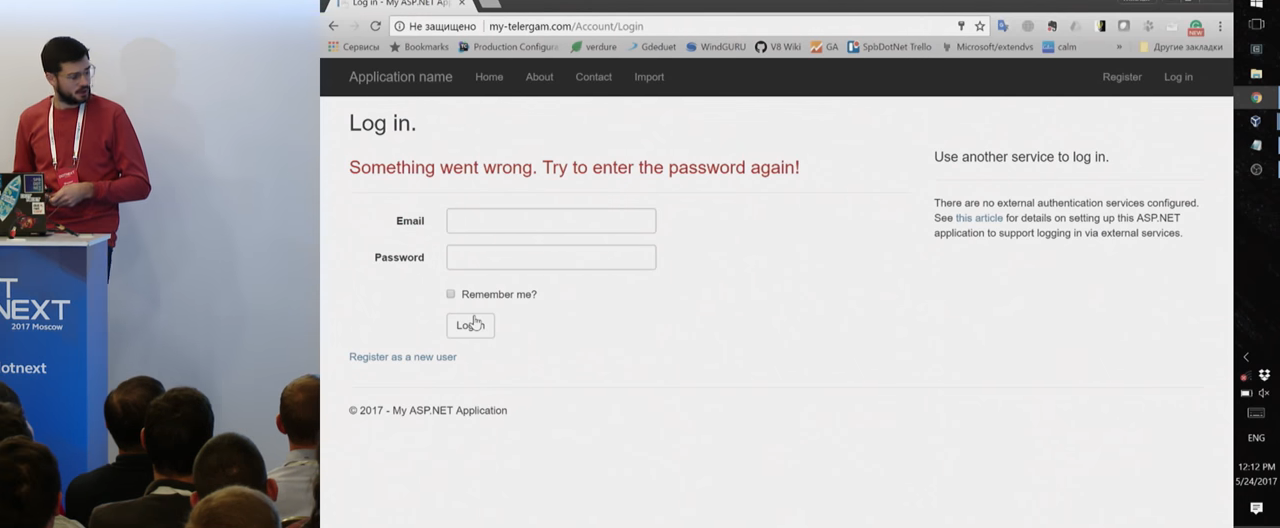
«Что-то пошло не так, введите заново пароль и логин». Обычная реакция — «наверное, я где-то неправильно что-то ввел», и пользователь повторяет ввод. Но если вы обратили внимание, в верхней строчке уже не my-telegram, а my-telergam, небольшая игра с символами. Что произошло? Первая форма логина на доверенном сайте совершенно нормально залогинила пользователя на этом сайте, дальше был редирект. А в редиректе был url вот на этот сайт. Если мы не проверяем url в редиректе, то он вполне себе валидно отправляет нас на другой сайт, где уже с помощью некой социальной инженерии заставляет нас повторно ввести логин и пароль, которые уходят на сайт атакующего, и дальше атакующий уже может с этим работать.

Как это предотвратить? У ASP.NET в контроллере есть метод, LocalRedirect, я думаю, все его видели, он как раз защищает от таких случаев, проверяет, что у вас не абсолютный путь, что он относительный и может редиректить только на этот сайт.

Либо вы можете сами написать реализацию, если хотите, чтобы она по дефолту, когда сайт неверный, не выбрасывала исключения, а просто редиректила на home-страничку. Это вся защита от этой атаки. Теперь вы все знаете, что такое Open Redirect.

В этом году OWASP собирал свою статистику, по ссылке на GitHub можно посмотреть. При всей простоте защиты, Open Redirect стоит на третьем месте по популярности в мире.
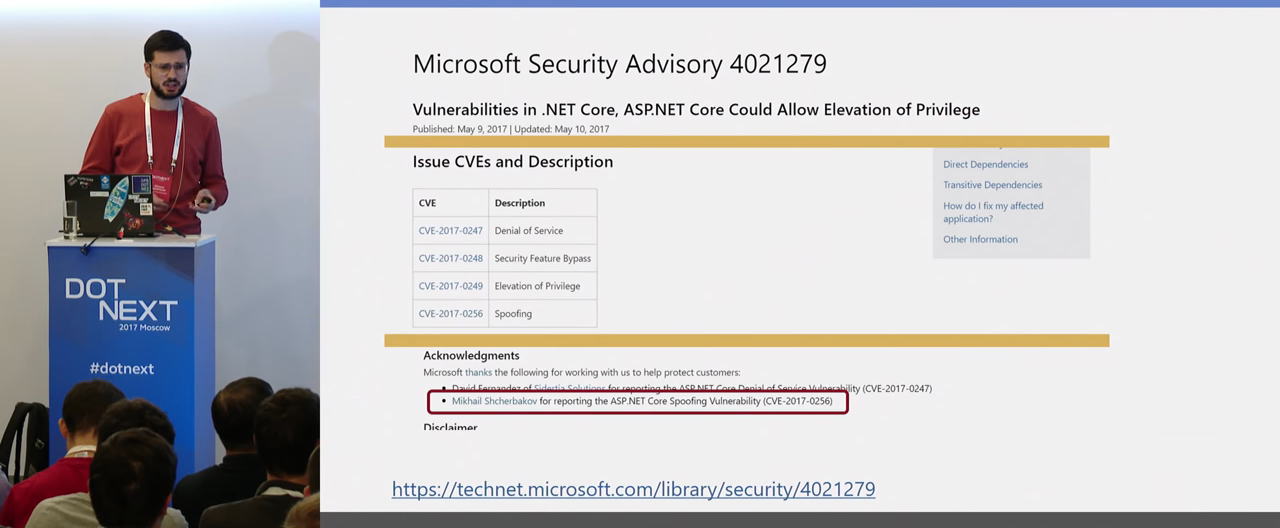
С этой же атаки началось мое участие в Bug Bounty. Мой первый репорт, который был пофиксен и оплачен, был как раз про обход встроенного механизма Open redirect. Но сейчас там все нормально, он пофиксен. LocalRedirect действительно защищает на 100% от возможного редиректа на сторонний сайт.
Следующее, про что хотелось бы поговорить, — это Data Protection. В Crypto API были огромные изменения в .NET Core. По сути, всё API было полностью переписано, поэтому давайте быстро пройдемся по основным моментам и посмотрим, что поменялось.

Во-первых, отказались от использования Machine Keys. Machine Keys раньше являлся master key для всей криптографии. С этим было много проблем, особенно в распределенной системе, вам нужно было сочинять какое-то свое хранилище ключей, чтобы то, что зашифровала одна нода, было возможно расшифровать другой нодой. Также не было нормальной возможности отозвать, например, зашифрованные cookies. Вам нужно было бы менять Machine Keys. Было очень много всяких неудобств. Сейчас от этого отказались, сделали нормальные высокоуровневые API из коробки. Раньше System.Security.Cryptography представляла из себя некий набор инструментов, используя которые очень легко было сделать ошибку.
Частый правильный кейс — использовать некую стороннюю библиотеку, которая уже предоставляет высокоуровневые API, и вам не нужно заботиться обо всех нюансах. Сейчас это есть в .NET Core из коробки. Есть хранилище ключей из коробки: вы можете сконфигурировать какое-то удаленное хранилище, где у вас будут лежать все ключики, и все ноды будут туда за ними ходить. Оно легко расширяется, вы можете использовать как уже существующие в Redis или в Azure, так и написать своё. Поддерживается ротация ключей, раз в 90 дней ключик меняется, и для создания нового шифротекста уже будет использоваться новый ключ, а старый — только для расшифровки старого. Также предоставляется изоляция подсистем из коробки. Можно кастомизировать, то есть использовать свои кастомные алгоритмы шифрования, чуть позже я покажу пример.
Итак, как выглядит новый Crypto API?

Довольно-таки примитивно, легко, так как у нас есть DI в .NET Core, вы можете просто в конструктор контроллера передать IDataProtectionProvider, создать из него протектор и использовать метод Protect и Unprotect для шифровки и расшифровки. Всё, больше вам ни о чем заботиться не нужно. И еще один параметр, на котором я ещё хотел остановиться, — это как раз та самая изоляция на уровне протекторов, где каждый протектор с разными строковыми идентификаторами может расшифровывать данные, которые только он зашифровал. Если вы хотите шифровать данные для разных пользователей и быть уверенным, что они не смогут чьи-то чужие зашифрованные данные расшифровать в своём аккаунте, то это удобная фича, которая доступна из коробки.
Есть еще такая вот вишенка:

Вы можете использовать time-limited протектор для создания токенов. Когда вам нужно определить время жизни вашего ключа, например, токена, вы просто его шифруете time-limited протектором, определяете его время жизни, и при расшифровке, если это время истекло, вы просто получите эксепшн.
Следующий момент — хранение паролей. Как все знают, в открытом виде мы пароли не храним никогда, вопрос, как сделать это правильно. Опять же, у нас есть механизм в .NET Core, паттерн для правильного создания хэшей:
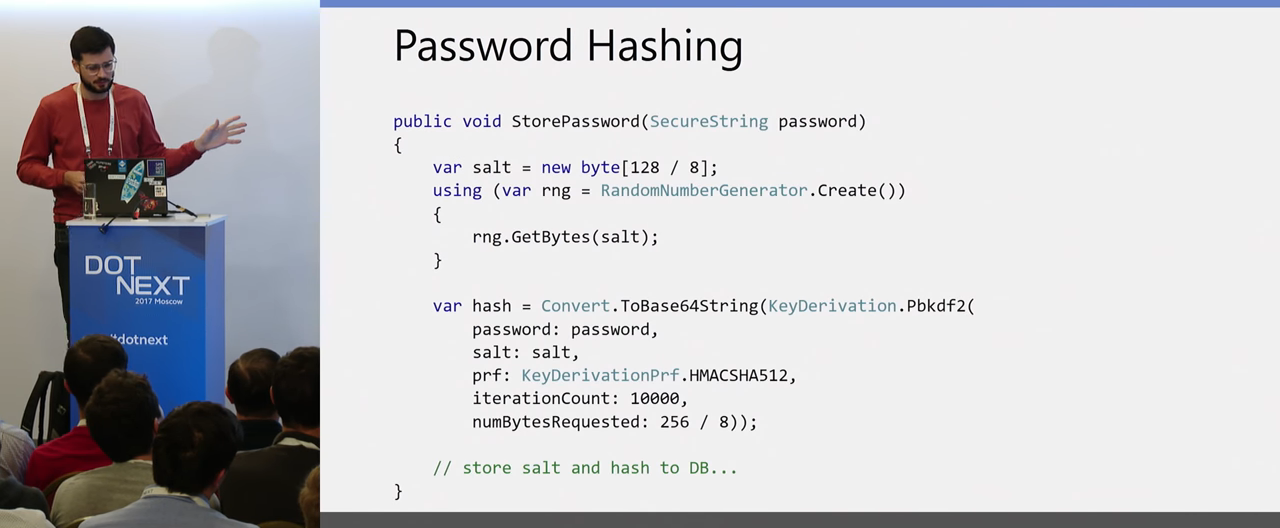
Во-первых, вы используете для создания соли рандомный генератор из Crypto API. Созданная им соль передается вместе с ключом в метод, который, используя заданную хэширующую функцию, создает вам хэш. Этот хэш вместе с солью вы уже спокойно сохраняйте в базу данных и уже используете эту пару дальше для верификации введенных пользователем паролей.

Все это конфигурится стандартным методом в ConfigureServices. Вы можете задавать уровень изоляции для всего приложения, чтобы разные приложения не могли расшифровывать данные друг другу, если это необходимо. Можете устанавливать время жизни мастер-ключа, можете настроить, где у вас будут храниться ключи.

Можете кастомизировать алгоритмы шифрования, которые вы хотите использовать. По умолчанию будет использована AES-256 с дополнением CBC. Это блочные алгоритмы шифрования, и без дополнительной подписи они уязвимы к атакам Padding Oracle. Эта проблема была как раз в .NET в большом фреймворке из-за неправильного использования System.Security.Cryptography. Здесь же из коробки шифротекст будет подписан еще хэшом, и в этой ситуации Padding Oracle невозможен, так что можете об этом не думать. Есть еще нюанс: каждый шифротекст будет иметь заголовок, который состоит из 32-битного magic header, следом за которым идет айдишник ключа. Это иногда бывает полезно для отладки, когда вы хотите понять, каким ключом был зашифрован текст. Вы просто смотрите на первые 20 байт и видите, одинаковыми или разными ключами они зашифрованы в зависимости от того, одинаковые или разные эти хедеры.

Перейдем к большой части, посвященной Client-side уязвимостям. Начнем с XSS. Все знают, что такое XSS. Но всё равно начнем с самых азов, потому что понимание, как работает в браузере Same-origin policy (SOP) очень важно для полного понимания атак на Client-side. Рассмотрим вот такой кейс:

У нас есть браузер, в одной вкладке открыт сайт foo-example с JavaScript-кодом, который выполняет GET-запрос на другой домен. Есть другой сайт по этому домену bar.other, который у нас возвращает Json на этот запрос, какие-то цены на продукты. И вот вопрос — отправит ли браузер этот запрос? В этом случае выглядит логично, что хорошо бы отправить этот запрос и получить ответ. Какая проблема с этим есть?

Если в нашем примере мы просто поменяем сайты, и вместо провайдера данных у нас какой-то mail.google, а здесь у нас какой-то сайт атакующего, который атакующий заставил нас открыть в своем браузере, то если бы этот запрос был отправлен и ответ получен, атакующий бы получил данные из нашего почтовый ящика, что плохо. Поэтому и существует Same-origin policy, который предотвращает чтение данных в подобном случае. А правильный ответ на мой изначальный вопрос, отправит ли браузер запрос — да, отправит. Браузер отправляет POST/GET-запросы в этой ситуации, но не позволяет JavaScript прочитать ответ этого запроса, поэтому утечки данных здесь произойти не может из-за Same-origin policy. Но на самом деле запросы будут отправлены, это будет важно для понимания других Client-side атак.

Что же такое вообще Same-origin policy? Это некие ограничения, которые накладываются на загруженный документ или скрипт из одного источника на взаимодействие с ресурсами из другого источника.

Что же такое источник, что такое origin? Origin представляет из себя набор схемы http, https либо какой-то другой, домена и порта. То есть скрипт, выполняющийся на одном домене, на одном Origin с портом и схемой, не может получить данные с другого Origin без каких-то дополнительных действий. Как атакующий может всё-таки получить данные, какие атаки на Client-side существуют?
Первая — это XSS, с которой мы начали. Суть атаки — если мы не можем с другого Origin получить данные, то давайте наш скрипт заинжектим прямо в Origin сайта, сделаем инъекцию нашего вредоносного скрипта на доверенную веб-страницу, и тогда из Origin мы уже можем делать запрос внутри этого Origin и получать данные страницы. Это суть XSS.

При всей известности и простоте это остается самой популярной атакой в мире. Она является очень хорошей точкой входа для других атак. Существует много атак, которые можно развернуть, начиная с XSS. Она является общеизвестной, при этом очень много проектов, где разработчики недостаточно используют встроенные средства защиты от XSS. И вообще не придают ей серьезное значение.
Давайте посмотрим, что у нас есть в ASP.NET, чтобы правильно построить защиту от этого вида атак. Возьмем два таких синтетических примера варианта XSS:

Первый вариант: у нас есть некий скрипт, у него есть source, в source вставлен какой-то путь. Если атакующий может манипулировать этим путем (загрузить свой source) или заинжектить всю эту строчку в документ, соответственно, он заинжектит свой скрипт. Это и есть XSS-атака.

Второй вариант — когда у нас фигурирует не параметр скрипта, а атакующий может в какой-то тег html заинжектить свой код, например, напрямую в <script>, либо в атрибуты тегов, либо куда-то ещё. Контекст сейчас нам не важен, важно, что это две принципиально разные атаки. Что с этим делать? Как я уже сказал, XSS-атака – это атака типа инъекций. Что делать с инъекциями? Кратко — валидировать на входе, санитизировать на выходе.

Валидация и фильтрация данных на входе, желательно по белым спискам, если нет — то по строгим бизнес-требованиям к этим данным. Санитизация — в зависимости от контекста грамматики, в котором мы вставляем эти данные, чтобы не выйти за пределы одного токена этой грамматики.

Кратко о том, какие у нас есть энкодеры для санитизации. Есть встроенный HtmlEncoder, JavaScriptEncoder, UrlEncoder, и есть сторонние санитизаторы — это, например, HtmlSanitizer, который позволяет вам иметь довольно много настроек, вы можете четко описать правила для грамматики, куда эти данные будут вставлены. Библиотека, которая вам может сильно помочь с пониманием, как под конкретную грамматику можно заэнкодить данные, — это LibProtection. Она берёт часть работы на себя.

Вернемся к нашим двум первым примерам. Валидация данных, санитизация данных — хорошо, но это всё равно остаётся на стороне разработчика, а это значит, что мы должны полагаться на хороший уровень разработчика, что он потрудится и использует нужные санитизаторы и сделает нужную валидацию. На дворе 21 век, и хотелось бы уже раз и навсегда забыть про XSS, вырубить их на уровне браузера. Есть ли для этого возможности? Да.
Есть такая штука, называется Content Security Policy. Как браузер руководствуется Same-origin policy, определяя, какие запросы возможны и невозможны, так и вы можете настроить ещё одну политику, Content Security Policy, объясняя, откуда ему можно загружать скрипты и выполнять. Эта политика настраивается через хедеры. В ASP.NET у вас настройки будут выглядеть примерно вот так:

Вы просто прописываете в ответ хедер Content Security Policy, указываете, с каких доменов можно загружать ресурсы. Настроек здесь по ресурсам намного больше, я не стал приводить все, у них сложные иерархии наследования. Сейчас немножко не про это. Еще у вас есть возможность задать report-uri. Это некий uri, по которому браузер будет отстукиваться, есть что-то пошло не так. Например, он хотел загрузить скрипт, но этот источник не был прописан в Content Security Policy, и поэтому он его загрузить не может. Это особенно актуально на начальном этапе, когда вы встраиваете Content Security Policy, и у вас периодически просто где-то перестает работать JavaScript, а вы не совсем понимаете, почему, где и что с этим делать. Это удобно использовать в ситуации, когда скрипт не загрузился. Браузер отстучится на ваш сервер.

Чтобы этот запрос принять, проще всего сделать такой класс, который распарсит данные, которые прислал браузер:

И создать метод в контроллере, которые уже эти данные получит. Дальше вы либо залогируете эти данные, либо как-то будете их анализировать. Пришедший запрос в этот контроллер говорит вам о возможных двух вещах: либо у вас плохо настроен Content Security Policy, кто-то добавил скрипт из источника, который не был прописан, либо вас сейчас атакуют, то есть атакующий сейчас пытается сделать XSS. Поэтому, когда вы будете это делать, если у вас сильно посещаемый сайт, будьте внимательны: у вас может прийти очень много запросов в момент реальной атаки. Если будет какая-то хранимая XSS и будет попытка выполнения на десятках тысяч браузеров, вы сами себе сделаете такой DDoS. То есть либо переносить этот контроллер на отдельную ноду, либо, как минимум, не забывать об этой опасности DDoS’а.

Есть такой удобный инструмент — cspvalidator.org. Если у вас будут какие-то особенно сложные настройки Content Security Policy, он поможет найти противоречия в этих настройках и дать какой-то репорт о настроенных вами политиках.

Как всегда, серебряной пули не существует. Но правильно настроенный Content Security Policy защищает вас от XSS. Однако это не говорит о том, что вообще никакие инъекции в код страницы невозможны. Например, вот стандартная логин-форма из ASP.NET, у неё есть action, стандартный относительный путь:

И если атакующий может в тело этой же страницы заинжектить тег base, который определяет префикс для всех относительных путей на странице, то если пользователь воспользуется этой логин-формой и отправит логин и пароль, они уйдут на сайт атакующего из-за этой инъекции.

Это не XSS, здесь не происходит выполнение скрипта, но это работающая инъекция. Если вы настроили Content Security Policy, забивать на валидацию и санитизацию конечно же не стоит. Эти методы только дополняют друг друга.

Еще один механизм браузерной защиты, который вам доступен и который вы можете настроить — это XSS-protection на стороне браузера. Все современные браузеры имеют встроенный фильтр от XSS. Чтобы его включить, вам нужно отправить это в хедер. Когда вы это сделаете, обязательно тестируйте, потому что это некие эвристики на стороне браузера, когда он пытается защититься от XSS.

Следующая тема продолжает Client-side атаки — это CSRF (Cross-Site Request Forgery).

Помните, когда мы говорили про Same-origin policy, мы задались вопросом — отправит ли запрос GET и POST. И выяснили, что отправит, но ответ не получит. Так вот на этой особенности и строится атака CSRF. Если POST-запрос можно отправить (а POST-запросами у нас обычно является запросы от форм), то атакующему не всегда важно получить ответ, ему достаточно, что действие произойдет на сервере. Как выглядит эта атака: у нас есть пользователь, он логинится в какой-то системе. Для упрощения возьмем интернет-банкинг. Он залогинился, получил авторизационные cookies.
После этого у нас на сцене появляется атакующий, который отправляет некую ссылку пользователю. Пользователь открывает ее в своем том же самом браузере получает некую страницу от сервера, подконтрольного атакующему. Теперь в браузере, где пользователь залогинен в своем интернет-банке, он получил некую страницу, на которой скрипт атакующего может выполнить POST-запрос к этому интернет-банку.

Так как запрос выполняется к домену банка, он берёт cookies, относящиеся к этому домену, и отправляет их вместе с запросом. POST-запрос может, например, перевести деньги с одного счёта на другой, нам не важно получить результат этого запроса. Если этот факт произойдет — это уже успешная атака.
Как от этого защищаться? Атака тоже очень стара, и встроенные механизмы есть практически во всех веб-фреймворках, в том числе и в ASP.NET Core. Главное, не забыть их включить. Защита построена на принципе, что у вас браузер в GET-запросе возвращает два одинаковых токена. Один в cookies, защищенный, который прочитать из JavaScript-кода нельзя, другой в скрытом поле формы. Он отправляет эти два токена, и, когда пользователь нажимает на кнопку «отправить» в форме, эти два токена прилетают назад. Один из скрытого поля, другой прилетает в cookies. Сервер сравнивает эти токены и, если они сошлись, значит, цепочка GET-POST была осуществлена, пользователь нажал на кнопку, произвел это действие, и оно корректное. Тогда сервер продолжает выполнение запроса.

Соответственно, если здесь сайт атакующего, выполняется скрипт, загруженный с другого домена. Этот скрипт не может получить доступ к контенту другой страницы. Это другой Origin, и тут от чтения токенов нас как раз спасает Same-origin policy, поэтому эта защита и работает. Как это настраивается?
В ASP.NET Core это выглядит следующим образом. Есть AntiForgery cookies, которые содержат токен, и есть те самые скрытые поля, про которые я говорил (но они должны быть во всех формах, которые отправляют POST-запросы на ваш сервер).

Сам токен представляет из себя некий рандомный токен, который генерируется рандомным генератором, а потом криптуется, используя тот самый Crypto API, про который мы говорили.

Поэтому, если у вас распределенные системы, вам нужно обязательно иметь удалённое хранилище ключей, чтобы у вас токены могли раскриптовываться на разных нодах. Одна нода может создать этот токен, а другая — раскриптовать.
Следующий момент: формы, которые не имеют явно заданного экшена, например, атрибута asp-action в CSHTML, автоматически добавляют токен, вам на этот счёт беспокоиться не нужно.

Либо вы можете добавить этот токен вручную, если это вам необходимо.

Как настроить проверку на уровне middleware, если y вас MVC? Самый простой способ — это задать AutoValidateAntiforgeryTokenAttribute на уровне фильтра (по умолчанию он не задан). Он говорит о том, что у вас все запросы, кроме GET, OPTIONS, HEAD и TRACE, будут обязательно валидироваться на соответствие этих токенов, и CSRF-атака будет невозможна.
По умолчанию используются атрибуты для конкретного контроллера, для конкретного действия. Ещё раз: проще задать для всего, и, если вам где-то это не нужно, отключать.

Также у вас есть вариант вручную задавать атрибутами:

Вы можете, например, для контроллера показать, какой именно игнорировать метод, если необходимо. Но стоит учитывать, что при автоматической валидации GET-запросы не будут валидироваться, и это правильно. Поэтому если у вас метод обрабатывает POST-запрос, он не должен при этом обрабатывать GET-запрос. Ваш роутинг не должен быть так настроен.
Следующий частый вопрос, который возникает — если у меня AJAX, JavaScript, и запросы часто уходят не из формы, а из, например, AJAX-запроса, что с этим делать?
Зависит от того, как у вас сделана авторизация. Если у вас нет cookies, вы используете токены. Каждая страничка имеет некий токен, который используется для авторизации для отправки вот этого AJAX-запроса. Тогда у вас нет и проблем, этот токен не может считать атакующий, и он не может быть использован для атаки, потому что не может быть считан.

Если же вы используете аутентификационные cookies, тогда вы можете в хедере явно указать, какой параметр будет содержать этот токен.

Вот таким C# кодом получить значение текущего токена для пользователя и добавить его во все запросы. Вам нужно будет прописать на сервере, что вот по этому хедеру вам нужно брать токен и сличать его. Но это один конфигурационный параметр при настройке механизма AntiXsrf.

Следующая тема, которую хочется затронуть — Cross-origin запросы. Если вам всё-таки нужно для чего-то осуществлять запросы между доменами — что с этим делать, как настроить, какие вообще инструменты у нас есть?
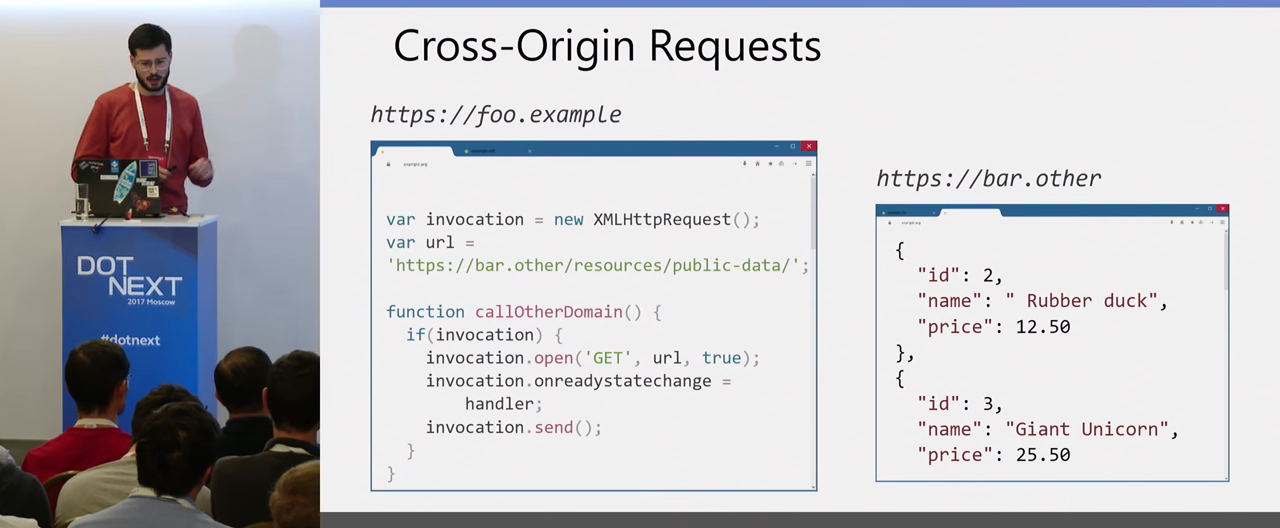
Тот самый первый пример. Он выглядит вполне себе валидно. Если у вас есть какой-то провайдер данных, и вы хотите туда подгружать из JavaScript какие-то данные в режиме реального времени, показывать их, а провайдер у вас при этом на другом домене, то почему бы и нет, но как это можно настроить?
Есть такой инструмент, CORS (Cross-Origin Request Sharing). Это вещь, которую поддерживают, опять же, все современные браузеры. Суть в том, что вы можете настроить свой сервер, чтобы он разрешал чтение данных в браузере для определённых Origin или для всех. Например, для нашего прошлого примера может быть настроен следующий ответ сервера. Когда браузер присылает POST-запрос, у нас сервер валидирует Origin и отправляет Access-Control-Allow-Origin, указывая, для конкретного Origin или для всех, как в этой ситуации.

Тогда браузер позволяет JavaScript распарсить эти данные, обработать их и вывести, например, на страницу.

Здесь есть следующий момент. А как же оно работает для put-запросов, для delete-запросов? Мы помним, что Same-origin policy может нам разрешать отсылать только GET и POST-запросы. На самом деле он может разрешать отсылать запросы, которые соответствуют этим требованиям, которые называются простыми запросами. Это GET, head, POST, у которого нет каких-то дополнительных хедеров, у которого content-type не соответствуют перечисленным. Есть еще несколько исключений, но они пока нам не нужны. Как браузер себя ведёт для остальных запросов:

В остальных случаях он сначала отправляет запрос options и спрашивает, разрешено ли для POST-запроса с дополнительным хедером (или для put-запроса) выполнить кроссдоменные взаимодействия. На что ваш сервер должен верифицировать Origin и переданные параметры хедер и метод, и в случае, если кроссдоменный запрос разрешен, должен отправить следующие хедеры: Access-Control-Allow-Origin для какого Origin, для каких методов разрешен, для каких хедеров.

Браузер на своей стороне этот ответ валидирует. Если он совпадает, то он уже шлет честный POST-запрос c дополнительным хедером, либо put-запрос, в общем, тот запрос, который вы указали. И уже на свой основной запрос получает ответ от сервера.

Как это настраивается? К счастью, в .NET Core вам не нужно заботиться об этих нюансах — что есть разные типы запросов, что вам нужно валидировать Origin. У вас есть middleware по настройке CORS, который вы добавляете в свой проект, и с помощью UseCors-методов в Configure можете позволить либо всем Origin к вашему серверу получать доступ, либо написать только те Origin, которым этот доступ разрешен.

Есть второй вариант настройки. Вы можете определить некую политику либо набор политик с разными разрешениями. Например, для разных Origin открыть какие-то определенные контроллеры и с помощью атрибутов уже на уровне контроллера вы можете присваивать ту или иную политику конкретному методу в контроллере или всему контролеру. И тогда все его методы будут доступны, в соответствии с политикой, для тех Origin.
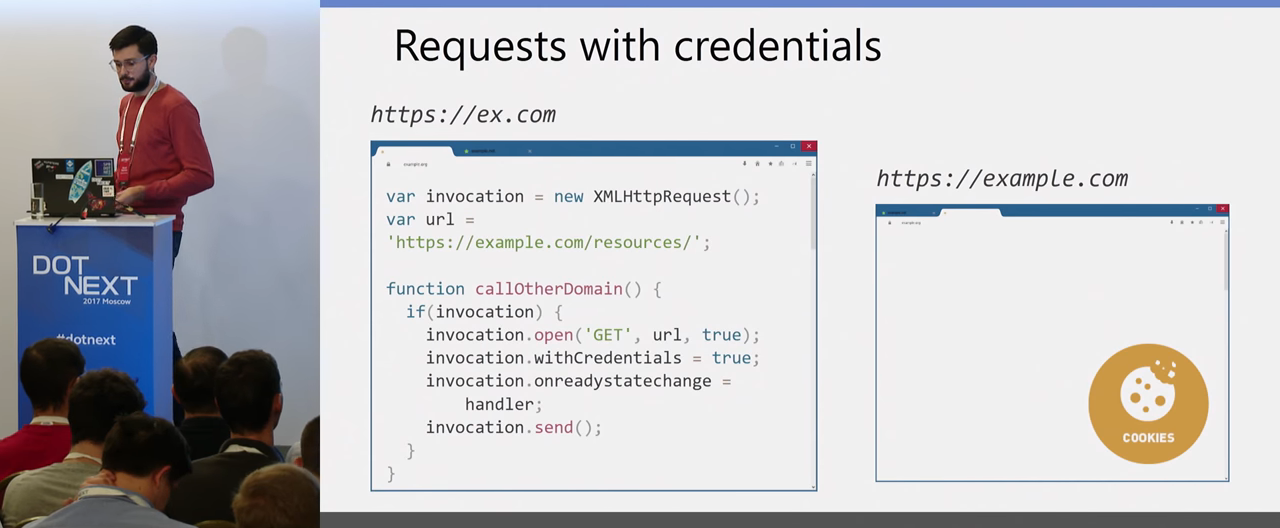
Более интересный пример, когда у нас есть какая-то авторизация на том самом втором сайте, к которому мы хотим обращаться кроссдоменно из JavaScript. Этот сайт может установить некую cookie: пользователь залогинился на этом сайте, получил cookie и теперь у нас сторонний сайт хочет обратиться к получению данных из этого сайта. Например, у вас есть какой-то короткий домен ex.com, и он хочет считать данные из вашего основного сайта, где авторизован пользователь из example.com. Для этого ему нужно задать в параметры withCredentials=true, то есть сказать браузеру, что он хочет отправить запрос со всеми Credentials, со всеми cookies, которые существуют.
К вам придет этот запрос, и вам на стороне сервера нужно ответить, что вы позволяете для конкретного Origin этот ответ и ещё Access-Control-Allow-Credentials передать.

Здесь есть важный нюанс: когда вы передаете Credentials к серверу, вам нужно обязательно четко передать тот Origin, которому это позволено. Здесь уже нельзя поставить звездочку, в этой ситуации у браузера включается дополнительная защита, он считает, что запросы с Credentials для всех — нельзя, никогда. Здесь вы явно должны проверифицировать Origin. Если вы ему доверяете (например, это какой-то ваш сайт, но находящийся в другом домене), вы тогда уже явно указываете, что для этого сайта этот запрос возможен, и отправляйте результат.

Конфигурится это опять же проще, чем работает. Вы просто указываете, для какого Origin, и указываете, что это AllowCredentials, и это работает.
Кроме CORS, про который мы поговорили, есть и другие механизмы междоменного взаимодействия. Я думаю, все знают про WebSockets. Ещё JSONP, механизмы POSTMessage, когда у вас есть iframe на той же страничке, и вы можете слать из него Message другому домену, но он на этой же страничке. Про них мы сейчас подробно говорить не будем, но есть здесь важный момент которые стоит отметить, он касается валидации Origin.

Если вы используете всё, что справа, вам нужно обязательно валидировать Origin, чтобы не отправить данные кому-то еще. Чтобы атакующий, например, не мог создать свою страничку со своим скриптом, который работает с вашими веб-сокетами, и подключиться туда. Если у вас аутентификация сделана также по cookies, это тоже будет возможно. Вам обязательно нужно проверить Origin, который поставит браузер, — откуда пришел этот запрос, доверяете ли вы этому домену, ваш ли это домен. В случае JSONP, вам нужно уже навернуть несколько другую защиту, обязательно использовать токены в запросах, по которым вы также верифицируете, что запрос пришёл от вас (от сайта, которому вы доверяете).
Финальная часть Client-side атак — это best practices по использованию cookies.
Cookies – это небольшой кусок данных, который сервер отправляет в ответе, в хедере Set-cookie, эти данные содержат название cookie, некое значение и параметры. Браузер же, руководствуясь этими параметрами, сохраняет cookie и использует в зависимости от этих параметров. Сейчас мы эти параметры разберем подробно.

Для чего cookies используется в целом? Это может быть некий Client-side storage. Когда вы не хотите хранить какие-то небольшие данные у себя на сервере, вы можете просто отдать их клиенту, он пришлет их вам назад в cookies, и вы таким образом используете это как некое хранилище. Это может быть использовано для Session management, про это я сегодня не успею рассказать, но там принципы работы с cookies примерно такие же.
Давайте разберем, как правильно делать Client-side storage, как правильно передавать данные на сторону клиента, учитывая, что cookies для вас — некое недоверенное хранилище. Итак, начнем с параметров.

У вас есть стандартный набор параметров — это Domain, Path для которых cookie валидна, браузер будет проверять перед отправкой любого запроса, есть ли у него для этого домена cookies. Если есть, только в этой ситуации будет ее отправлять. Та же самая проверка на Path. По дефолту значения для этих параметров не определены в ASP.NET Core и в ASP.NET, что порождает некие сложности, связанные не столько с Security, сколько вообще с процессом аутентификации. Например, до недавнего времени поведение в Internet Explorer отличалось от поведения в Chrome. И он использовал при неопределенном домене, когда явно пользователь его не задал, домен для текущего домена и всех субдоменов, а Chrome и Mozilla только для текущего домена. Поэтому, например, бывали некоторые ситуации, когда вы авторизовались на субдомене и потом переходили на другой субдомен, у вас в Chrome уже пользователь выглядит как неавторизованный, а в Internet Explorer это работало. Этих ньюансов можно избежать, явно задав эти параметры. Но в ASP.NET Core также есть небольшой нюанс в задаче этих параметров. Если у вас значение cookie будет санитизироваться внутри перед добавлением в ответ (и вы можете не беспокоиться, что там какие-то управляющие символы будут переданы), то Domain и Path не санитизируются, и вам нужно брать это на себя, если вы откуда-то берете эти недоверенные данные. Это уже в зависимости от вашего приложения.
Пример чтения cookies (думаю, все знают):

Про Domain и Path мы поговорили.

Это код установки cookies в ASP.NET Core. Как я уже сказал, у нас key и value санитизируются. Делается вызов метода Uri.EscapeDataString, а Domain и Pass кладутся как есть.

Следующие два параметра — это Secure и HttpOnly. Secure говорит о том, что cookie должна быть валидна только для https, чтобы избежать атаки Man in the Middle и похищения этой cookie через http. HttpOnly говорит о том, что у вас эта cookie может читаться только на стороне сервера. Любой JavaScript-код на стороне клиента не может ни читать, ни писать эту cookie. Здесь есть нюанс.
Возникает вопрос, достаточно ли использования HttpOnly в системе.

Как минимум, вы должны ещё закриптовать эти данные, которые вы отдаете на Client-side, чтобы у вас атакующий не мог установить эту cookie раньше, чем вы установите ее для жертвы. Сейчас чуть подробнее опишу.
И второй вопрос, достаточно ли просто криптовать.

На самом деле нет, вам нужно ещё указать, для какого пользователя эта cookie валидна. Какой смысл это имеет? Например, у вас есть HttpOnly cookie, ваш сервер устанавливает ее не сразу, а через какое-то время. Эта ситуация есть с session cookies, они устанавливаются в момент первого обращения к сессии в ASP.NET Core. При этом у вас атакующий может попробовать произвести атаку фиксации сессии. То есть сначала получить корректную session cookie. Мы помним, что она должна быть закриптована, но ничто не мешает ему, если cookie у нас является неким токеном, залогиниться в системе под своей учетной записью, получить свою cookie, подставить ее жертве, и тем самым этот токен также корректно расшифруется и будет валиден для жертвы. Хотя cookie и HttpOnly, но на момент установки она еще не была возвращена сервером. Это открывает небольшую лазейку для манипуляции cookies, которые как бы HttpOnly. Чтобы избежать этого, вы должны в тело cookie добавить некий ID пользователя, то есть либо username, либо Claim ID.

На картинке выше показан пример anti-XSRF токенов, которые добавляют как раз либо Claim ID, либо username в cookie, которые возвращают после расшифровки полученных cookie. Сервер сверяет, что cookie была выдана именно этому пользователю и она валидна, мы можем продолжать работу с ней.
Если эта тема вас заинтересовала, можно почитать замечательную книгу Михала Залевски про Client-side атаки, про безопасность браузеров. Она уже немножко устарела, так как давно была выпущена, но всё равно является самым подробным трудом на эту тему. Обратите внимание на то, как описанные в ней какие-то экспериментальные фичи в большинстве своем стали уже стандартом.
Есть также книга Стена Драпкина про Security .NET, она не очень известна, но довольно-таки хороша. Она не про .NET Core, там много про криптографию, про основной фреймворк, довольно полезная книга.
Есть OWASP Developer Guide — некие гайды по разработке защищенного кода, с которыми тоже интересно ознакомиться.
У OWASP также есть замечательный Testing Guide, в котором собраны различные атаки, принципы и методы атак, то есть это гайд для пентестеров. Если вам эта тема интересна и вы еще не смотрели, очень рекомендую, хороший ресурс, чтобы познакомиться со всеми возможными атаками.
Минутка рекламы. Как вы, наверное, знаете, мы делаем конференции. Ближайшая конференция про .NET — DotNext 2018 Piter, которая пройдет 22-23 апреля 2018 года в Санкт-Петербурге. Можно туда прийти, послушать доклады (какие доклады там бывают — вы уже увидели в этой статье), вживую пообщаться с практикующими экспертами и разработчиками разных моднейших технологий. Короче, заходите, мы вас ждём!
