Ни для кого не секрет, что .net сейчас используется в большинстве случаев как инструмент бэкенд разработки, а в клиентской разработке последние лет 5 правит js сообщество с своей экосистемой и инструментами для разработки. Это все безобразие с каждым годом усиливает пропасть между фронтэндом и бэкендом, и планка вхождения в область становится все выше и выше, разработчики начинают делиться на два лагеря и уходит такое понятие как фуллстек.
Да, под Node.js можно написать сервер, но для бэковой разработки, все же, .net бесспорный лидер. На js, на мой взгляд, очень сложно написать гибкий и легко поддерживаемый бэкенд, хотя возможно многие со мной и не согласятся.
Давайтеударим автопробегом по бездорожью попытаемся вопреки всему этому написать SPA приложение с бэком на .net core и клиентом на js, из инструментов разработки будем использовать горячо любимую Visual Studio.
После этого туториала, я надеюсь, веб и бэк разработчикам будет проще найти почву под ногами в вражьей области и понять в какую сторону двигаться для более углубленного изучения. Поехали!
1. Visual Studio 2017 (с проставленной галочкой при установке .NET Core cross platform development). Сервер мы будем писать на .net core 2.0 поэтому нам понадобиться студия именно >=2017, т.к. поддержка в 2015 студии закончилась на версии core 1.1
2. Node.js с установленным Node Package Manager (NPM). Node.js в нашем проекте нам нужна только для 2 мастхэв тулзов веб.разработки – это Webpack(для сборки и обработки различными прелоадерами нашего клиентского кода) и NPM(для установки js утилит/компонентов/пакетов)
Разбираться будем на примере разработки очень простого блога, который умеет выводить список постов на главной странице, переходить на отдельную страницу с комментариями (с возможностью комментировать), выполнять авторизацию его владельца и давать ему возможность написать новый пост.
Бэк из себя будет представлять набор restful api для клиента, базу будем использовать ms sql. Для работы с базой – EntityFramework Core, Code First подход.
Создаем пустой ASP.NET Core Web Application проект, будем дописывать в дальнейшем все необходимое руками.
В новом проекте, в классе Startup (файл Startup.cs), который является основным конфигурационным файлом в asp.net core, подключим сервис и middleware МVС (подробнее про цепочку middleware и обработку запроса пользователя с помощью слоев middleware, можно почитать в документации microsoft). Как известно в asp.net core весь статический контент(js/css/img) должен лежать в папке wwwroot (по умолчанию, если не указана другая папка), для того чтобы этот контент отдать конечному пользователю мы должны прописать еще один слой middleware – вызывать extension метод UseStaticFiles. В итоге у нас получится класс Startup с следующим кодом:
Теперь займемся бизнес логикой. Создадим в нашем solution два новых проекта Class Library (.NET Standart):
И добавим references в DBRepository на проект Models, а в проект ASP.NET PersonalPortal на проекты DBRepository и Models.
Таким образом мы изолируем репозиторий, приложение и модель друг от друга. И в дальнейшем, например, можем заменить сборку работы с базой DBRepository на другую сборку, которая работает с базой не через EF Core, а через какую либо другую ORM или через ado.net. Или, например, сможем подключить сборку репозитория и модели, не к веб приложению, а к десктоп.

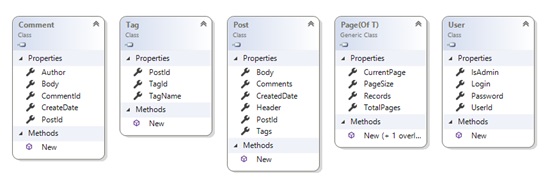
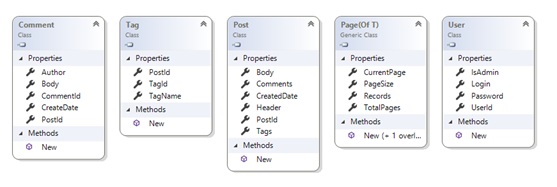
Далее, добавим в проект Models классы, которые будут в дальнейшем мапиться на таблицы в базе, останавливаться на этом подробно я не буду, на диаграмме классов, по-моему, все говорит само за себя:
Теперь перейдем в проект DBRepository и установим два nuget пакета, которые нам понадобяться для работы с EF Core — Microsoft.EntityFrameworkCore и провайдер бд MS SQL Server Microsoft.EntityFrameworkCore.SqlServer

Создадим наследника от класса DBContext, основого класса EF — точки входа для работы с данными. И фабрику (интерфейс+реализация), которая будет создавать этот контекст. Для чего нам понадобится фабрика мы разберемся позже.
Код очень простой – в фабрике мы конфигурируем dbcontext для работы с SQL Server и передаем строку подключения к бд(без connection string никуда…). Extension метод UseSqlServer к нам пришел из пакета Microsoft.EntityFrameworkCore.SqlServer.
Воспользуемся популярным паттерном «Репозиторий» и создадим классы-посредники, которые будут «отгораживать» наши конечные классы-потребители от работы с базой и EntityFramework в частности.
Добавим класс BaseRepository, интерфейс IBlogRepository и его реализацию BlogRepository.
BaseRepository будет являться, как видно из названия, базовым классом для всех созданных нами классов-посредников. В конструктор он принимает строку подключения и фабрику для создания EF контекста.
В классе BlogRepository, не откладывая в долгий ящик, мы уже реализовали метод для получения списка постов с постраничным выводом.
В строке 1 мы наконец то создаем контекст для работы с БД. В строке 2, используя методы LINQ, которые EF транслирует в sql скрипты, мы пишем запрос для получения нужной нам страницы постов вместе с тегами (с помощью метода Include). Важно помнить, что LINQ методы выполняются lazy, и поэтому само обращение к базе будет только после вызова метода ToListAsync в строке 3 (и CountAsync). После того как данные были получены, контекст работы с бд необходимо закрыть (обернуть его создание в using, как сделано в данном случае).
Вернемся в проект с веб-приложением и добавим конфигурационный файл. Созданный файл уже будет содержать поле с строкой подключения, нам нужно лишь отредактировать ее и указать актуальную базу и сервер.

В классе Startup зарегистрируем реализацию классов репозитория и фабрики. В .NET Core IoC контейнер идет уже из коробки, поэтому воспользуемся им. И добавим конструктор Startup(IConfiguration configuration) для доступа к файлу конфигурации, экземпляр конфигурации будет уже инжектиться WebHostBuilder-м. Далее ConnectionString берем из конфигурационного файла.
В строках 1 и 2 регистрируем реализации с помощью метода AddScope.
Вообще существуют 3 метода регистрации реализации – AddScope, AddTransient, AddSingleton, они различаются лишь временем жизни регистрируемого инстанса.
AddScope – инстанс создается 1 раз на каждый request от клиента к серверу.
AddTransient — каждый раз при резолве зависимости создается новый инстанс
AddSingleton – инстанс создается в единственном экземпляре и не меняется между запросами.
Подробнее можно прочитать в документации.
Теперь создадим контроллер с API методом и уже можно что-то щупать руками.
Зависимость IBlogRepository автоматически зарезолвится IoC контейнером.
Нажимаем F5, забиваем в адресную строку браузера урл к нашему api методу — localhost:64422/api/blog/page и… получаем следующий эксепшен, если конечно мы верно изменили строку подключения:

Дело в том, что нашей базы еще нет, и естественно EF не может открыть несуществующую базу. Нужно каким-то образом сообщить, что в случае если бд нет, EF должен ее создавать.
Можно просто вызывать метод context.Database.EnsureCreated перед обращением к базе, но чаще используют механизм миграций. Он позволяет, в случае если у нас была изменена схема данных, аккуратно применить ее на базу без потери существующих данных. Давайте попробуем.
Для работы утилиты миграции необходимо, чтобы наследник класса DBContext (в нашем случае класс RepositoryContext) был доступен из вне, и утилита миграций при запуске смогла его «вытащить» и использовать для своих нужд. Для этого мы должны:
либо зарегистрировать RepositoryContext в сервисах, но мы не очень хотим завязываться в нашем проекте на контекст, не зря же мы создавали классы-посредники к репозиториям
либо реализовать следующий интерфейс
Выберем последний вариант.
Пускай вас не смущает еще одна фабрика для создания контекста, она нужна ТОЛЬКО для утилиты миграции.
Итак, реализуем интерфейс:
Реализация очень проста — вытаскиваем строку подключения из конфига, создаем и возвращаем DBContext.
Теперь открываем Powershell консоль, выбираем проект DBRepository и добавляем миграцию.

Вуаля, миграция создалась, в проект DBRepository добавилась папка Migrations, содержащая новые файлы с автоматически сгенерированными классами и методами Up для инкремента миграции, Down для декремента.

Предыдущей командой мы лишь создали классы в нашем проекте, теперь необходимо применить миграцию на базу.

Давайте пропишем в коде автоматическое применение к базе, чтобы каждый раз, при очередной миграции, вручную не вызывать команду Update-Database и чтобы у тех кто в дальнейшем будет работать с нашим кодом применились все миграции и создалась база.
Перейдем в файл Program.cs и напишем следующие заветные строки.
В строке 1 мы создаем конфиг, в строке 2 создаем новый scope, чтобы получить экзмпляр RepositoryContextFactory (мы же помним, что зарегистрировали его с временем жизни scope? Без scope не будет и экземпляра), в строке 3 Метод DBContext.Database.Migrate() накатывает на базу все миграции, которых еще нет в базе. И если это первый вызов, когда базы еще нет, то создает ее. Далее диспозим скоуп, т.к. нам он больше не нужен.
А как механизм миграции узнает, какие миграции уже есть в базе, а каких еще нет? Все очень просто. При выполнении создается таблица __EFMigrationsHistory, где записаны имена всех миграций которые были применены.

Следующие миграции добавляются по аналогии – вносятся изменения в дата модель, выполняется команда Add-Migration <migration_name>, утилита сравнивает новые изменения с снепшотом предыдущей миграции и по результатам генерирует новый класс с миграцией.
С бэком, на данном этапе, мы практически разобрались, можно перейти к фронту, но перед нами возникает дилемма – разрабатывать фронт в отдельном проекте и в дальнейшем хостить раздельно или оставить его в том же проекте, что и web api, что конечно облегчит разработку и деплой. Также уже есть готовые темплейты в Visual Studio, которые рутинные вещи такие как роутинг и сборку webpack превращают в middleware магию, с помощью nuget-пакета Microsoft.AspNetCore.SpaServices.
Первый вариант вариант безусловно гибче, он позволяет отдельно деплоить веб и бэк, разрабатывать их в разных средах, но второй вариант тоже вполне имеет право на существование, в нашем случае, все же перевешивает простота и наглядность, поэтому, сделаем над собой усилие, и мужественно пойдем по второму, более легкому пути.
Создадим вьюху-контейнер клиентского приложения (Views/Home/Index.cshtml), контроллер, что будет ее отдавать и пропишем роутинг.
Пришло времяудивительных историй приступить к визуальной части нашего приложения. Node.js с менеджером пакетов (NPM) у нас уже должна стоять, если нет, то необходимо поставить (https://nodejs.org).
Тут надо оговориться, что в Visual Studio есть темплейт по созданию SPA приложения в связке с asp.net core, но мы будем руководствоваться принципом, если хочешь в чем-то разобраться, сделай это своими руками. К тому же, на мой взгляд, тот темплейт несколько избыточен и многое там придется удалять.
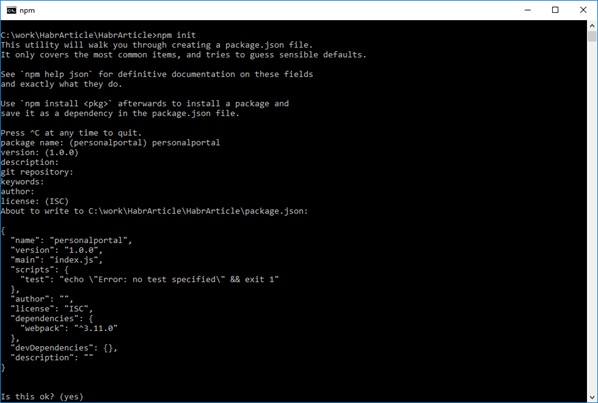
Создадим веб.проект. Откроем командную строку, перейдем в папку, где у нас лежит, созданный в студии .net core web application, и выполним команду npm init. Заполните ряд параметров которые будет спрашивать утилита, ну или просто понажимайте enter и на выходе вы получите файл package.json который будет являться аналогом “*.csproj “ для веба.
Далее вам необходимо скачать ряд npm пакетов, которые must have для нашей дальнейшей разработки. Можно ставить каждый пакет в отдельности выполняя команду npm i <package_name> [--save-dev], или сразу прописать все зависимости в нашем проектном файле и выполнить npm install. Для экономии времени и места в статье приведу package.json с всеми зависимостями.
В этом файле, помимо стандартно сгенерированных полей, мы видим 2 секции – devDependencies и dependencies, это список пакетов которые мы ставим. Отличие одной секции от другой состоит в том, что в секции devDependencies мы прописываем пакеты, которые необходимы ТОЛЬКО для сборки нашего приложения – различные лоадеры, прелоадеры, преобразователи, упаковщики, а в секции dependencies – пакеты необходимые именно для разработки, которые мы будем импортировать и использовать для написания кода.
Кратко пробежимся по пакетам:
После выполнения команды npm install у нас будет создана папка node_modules, в каталоге с веб-приложением, и туда скачаются все прописанные пакеты и их зависимости. Также должен создастся файл package-lock.json с описанием всех зависимостей.
Ну и Visual Studio должна увидеть эти пакеты и отобразить их у себя под вкладкой Dependencies
Далее перейдем в файл Startup.cs и пропишем middleware магию, о которой говорилось выше. Для этого нам необходимо поставить пакет Microsoft.AspNetCore.SpaServices, ну или он уже есть в составе пакета Microsoft.AspNetCore.All.
В строке 1 мы включаем поддержку webpack, теперь у нас не будет болеть голова за сборку клиентских ресурсов и нам не нужно будет каждый раз вручную ее запускать, прописывать куда нибудь в PostBuildEvents или держать открытым окошко консоли с запущенной webpack –watch. Этой строкой мы создаем инстанс webpack-а в памяти, который будет отслеживать изменения в файлах и запускать инкрементальную сборку.
В строке 2 мы включаем поддержку клиентского роутинга. Попробую вкратце описать проблему, которую решает данная строка. Как вы знаете философия SPA такова, что пользователю в браузер всегда загружена одна станица и новые данные подгружаются ajax запросами. И весь роутинг, который меняется в строке запроса браузера, это на самом деле не ресурсы сервера, а клиентская «эмуляция запросов» к данным ресурсам. Пользователь все равно остается на одной и той же странице. Проблем нет, если пользователь последовательно переходит к нужному ресурсу, но, если он решит сразу перейти к этому ресурсу напрямую, тогда проблемы появятся.
Например, ваше приложение располагается по адресу www.mytestsite.com. Пользователь нашел интересный контент на странице www.mytestsite.com/home/news?id=1 и решил скинуть ссылку другу или подруге. Друг/подруга получает эту ссылку, копирует в браузер, и получает 404 ошибку. Проблема тут в том, что на сервере физически нет этого ресурса и веб-сервер понятия не имеет как роутить данный url, потому что у нас SPA приложение и потому что был организован клиентский роутинг.
Так вот строка 2 в Startup.cs на все подобные запросы отдает страницу контейнер, та приезжает клиенту и уже на клиенте приложение разруливает роутинг.
Теперь нам нужно создать файл-конфиг для webpack(webpack.config.js), руководствуясь которым, webpack будет применить различные препроцессоры и собирать наше приложение. Создадим его там же где у нас лежит package.json.
Кратко пробежимся по конфигу. За подробной документацией лучше обратиться к официальным источникам. Также есть отличный скринкаст по вебпаку, к сожалению, он только по webpack 1.x, но основные вещи и концепции вполне можно посмотреть и там.
Итак, первым делом нам нужно указать точку входа webpack в наши исходники — значение поля entry, это и есть она родимая.
Далее в output указываем куда webpack должен положить результат своей работы (bundle).
В devtool указываем, что нужно создать source-map, чтобы при отладке не лазить по огромному бандлу, а была привязка к исходникам.
И наконец в секции module указываем какие лоадеры нужно подключить. Пока подключим только модуль babel и пресеты для него – react для трансформации jsx синтаксиса, es2015 для поддержки ES6, stage-0 для использования новых js фич
Ну что же, мы закончили с настройкой, и наконец то готовы приступить к самой разработке.
Давайте создадим директорию App в корне нашего asp.net core приложения, и в ней добавим файл index.jsx. Приведу ниже скрин из solution explorer, чтобы вы не заплутали.
В index.jsx напишем следующее:
Это будет входной точкой в наше клиентское приложение. Вкратце, в 2 верхних строчках мы импортируем все для разработки на React, в 3-й строке мы импортируем наш компонент-контейнер App, который напишем ниже. В 4-й строке рендерим этот компонент в DOM элемент с id=”content”.
Запись вида <App /> это и есть JSX, таким образом мы можем работать с компонентами как с xml и писать разметку в js файлах. Без обработки соответствующим пресетом babel, нам необходимо было бы каждый раз вызывать метод React.createElement, что в разы ухудшило бы читаемость и усложнило написание компонентов.
Создадим файл app.jsx, про который я упоминал выше:
Что тут интересного. Во-первых, мы объявили новый компонент строкой export default class App extends React.Component и экспортировали его, чтобы он был доступен извне.
Во-вторых, мы импортировали набор компонентов из пакета react-router-dom для организации клиентского роутинга. Router – это root компонент роутинга, в который должны быть вложены все остальные, а Switch и Route это сама организация роутинга. В данном случае мы хотим, чтобы при обращении к корневому пути (для примера — www.mytestsite.com) выводился наш компонент Blog, а при обращении к пути /about (www.mytestsite.com/about) выводился компонент About.
Header, About, Blog это наши пользовательские компоненты, давайте быстро накидаем их фейки. Создайте 3 директории в том же каталоге, что и app.jsx, в новых каталогах создайте по файлу и скопипастите следующий код, изменив имя класса, ну и текст в div
Теперь перейдем в новосозданный header.jsx и сделаем навигацию.
Тут ничего нового, за исключением компонента Link. Компонент будет генерировать ссылку, которая не будет отсылать вас на сервер, а будет изменять строку запроса в браузере, добавлять запись в историю, в общем вести себя как обычная ссылка, но без перезагрузки страницы.
Теперь давайте запустим проект и посмотрим, что у нас получилось. Не забудем подключить итоговый бандл, результат работы webpack, на нашу страницу-контейнер Index.cshtml

Конечно визуальной красоты пока мало, но css, стили, картинки и прочее наведение марафета, не входит в рамки этой статьи.
Пощелкаем на ссылки и убедимся, что страница не перезагружается, а строка запросов в браузере изменяет свой url. Работает? Поехали дальше.
Теперь пришло время подумать над архитектурой нашего клиентского приложения, да и в целом над организацией расположения файлов, компонентов и т.д. На эту тему конечно сломано много копий, прошло много холиваров, и один из подходов, что файлы удобно группировать вокруг функций(фич). Давайте придерживаться этого правила и в нашем фронтенд проекте.
Что касается архитектуры мы будем использовать популярный сейчас Redux. Когда мы настраивали webpack мы уже установили все необходимые пакеты для него (redux, redux-thunk, react-redux). Подробнее про Redux лучше почитать в документации. Есть ее полный перевод на русский.
Итак, давайте займемся нашим блогом, а именно выводом ленты сообщений.
Тут надо сказать несколько слов о архитектуре Redux. Вся архитектура построена вокруг ключевых понятий – action/reducer/store/view. Основной идей этой архитектуры, является то, что состояние нашего приложения хранится в одном месте(store) и влиять на это состояние могут лишь так называемые чистые функции(reducers), которые просто берут предыдущее состояние, по флагу(ключу) определяют, как нужно его изменить и возвращают новое состояние.
В свою очередь view, на какое-либо действие от пользователя, вызывают так называемые actions, которые выполняют обработку этих действий (выполняют/получают реквесты на сервер, бизнес логику и т.д.) и новые данные вместе с флагом отдают reducers, которые знают, как применить эти данные к состоянию приложения.
Таким образом у нас получается разделение ответственности и однонаправленный поток данных, что удобно поддерживать в дальнейшем и покрывать тестами.
Пока, возможно, это звучит не очень понятно, но на примере получения/отображения ленты сообщений мы разберем архитектуру подробнее.
В директории app/blog/ создадим redux-инфраструктурные файлы. blogActions.jsx, blogReducer.jsx, blogConstants.jsx (для хранения ключей действий).

Перейдем в blogActions.jsx и напишем метод получения списка постов с сервера.
С помощью метода getPosts мы получаем данные, а с помощью метода state.dispath() мы сообщаем reducers о том, что произошло действие и результатом стали некие данные. В нашем случае действия это recievePosts и errorReceive. GET_POSTS_SUCCESS, GET_POSTS_ERROR, это константы по которым reducer будет идентифицировать действие.
Теперь перейдем в blogReducer.jsx и напишем код, который изменяет состояние нашего приложения по этим действиям.
Все просто, метод-reducer получает на вход текущее состояние и действие. По switch определяет какое действие произошло, изменяет состояние и возвращает новую его копию. initialState, как не трудно догадаться, состояние по умолчанию.
Ок, теперь нам нужно собрать все это воедино и заставить работать.
Перейдем в файл blog.jsx, накидаем разметку и подключим нашу redux инфраструктуру.
Что мы имеем?
1. Класс Blog, с простой разметкой, который при инициализации запрашивает посты и отображает их.
2. Функцию mapProps, которая маппит состояние приложения на переменные-параметры.
3. Функцию mapDispath, которая маппит action на переменные-методы.
4. Функция connect, которая оборачивает класс-компонент Blog в redux-инфраструктуру и передает ему замапленные параметры в – this.props, с которыми мы уже и работает в самом компоненте.
Чтобы все окончательно заработало нам необходимо обернуть наше приложение в react-redux компонент Provider и создать хранилище приложения store.
Теперь добавим несколько записей-постов в базу и протестируем, что у нас получилось.

Работает!
Я не буду рассматривать создание остальных компонентов, так как пишутся они по аналогии с компонентом блога, который мы рассмотрели — создаются actions/reducer и все это применяется методом connect к react-компоненту.
Единственно стоит упомянуть, что для создания хранилища createStore, требуется передать один редьюсер, но мы можем(и обязательно захотим для удобства) разбить общий редьюсер на редьюсеры по фичам, и чтобы store корректно создавался необходимо будет их потом объединить. В этом нам поможет метод combineReducers.
Последняя тема, которую мы кратко рассмотрим в этой статье будет аутентификация. Будем использовать популярную аутентификацию на основе JSON Web Token (JWT).
Принцип действия прост:
1. Мы передаем логин пароль серверу
2. Сервер, в случае если они корректны, генерирует токен, который включает в себя данные необходимые для последующей авторизации сервером и возвращает его клиенту.
3. Клиент сохраняет токен, например в localStorage и при каждом запросе, требующем авторизацию, прикрепляет токен к хедеру запроса.
4. Сервер проверяет токен на корректность, просрочку, если все ОК, то возвращает данные.
Поставим соответствующий nuget пакет для asp.net core — Microsoft.AspNetCore.Authentication.JwtBearer, или убедимся, что он у нас стоит вместе Microsoft.AspNetCore.All.
Регистрируем в сервисах аутентификацию и укажем схему аутентификации на основе JWT токенов. Следующим экстеншен методом (AddJwtBearer) конфигурируем ее.
Встраиваем аутентификацию в конвейер обработки запросов.
Добавляем API метод генерации токена. В GetIdentity мы идем в базу (или куда либо еще где у нас лежат пользователи), сверяем логин/пароль, если все ок, то создаем токен и возвращаем пользователю, иначе возвращаем 401 ошибку.
Использование. АПИ метод будет доступен только авторизированным пользователям. Ну или атрибут можно повесить на контроллер.
На клиенте, перед каждым запросом, который требует авторизации, необходимо добавлять заголовок в формате ‘Bearer’ + token
Статья получилась несколько больше чем я рассчитывал, но несмотря на это она не затрагивает некоторые важные вещи, необходимые для разработки. Это конечно логи, написание тестов, как на бэке, так и на клиенте, библиотеки для этого, серверный рендеринг клиентских компонентов, CI/CD и еще кучу всего. Но все же надеюсь то, что я написал в этой статье, кому-то будет полезно и найдет свою целевую аудиторию.
Приложение, которое мы писали всю эту статью можно посмотреть ТУТ.
Исходники можно скачать с github.
Спасибо!
Да, под Node.js можно написать сервер, но для бэковой разработки, все же, .net бесспорный лидер. На js, на мой взгляд, очень сложно написать гибкий и легко поддерживаемый бэкенд, хотя возможно многие со мной и не согласятся.
Давайте
После этого туториала, я надеюсь, веб и бэк разработчикам будет проще найти почву под ногами в вражьей области и понять в какую сторону двигаться для более углубленного изучения. Поехали!
Итак, нам понадобятся
1. Visual Studio 2017 (с проставленной галочкой при установке .NET Core cross platform development). Сервер мы будем писать на .net core 2.0 поэтому нам понадобиться студия именно >=2017, т.к. поддержка в 2015 студии закончилась на версии core 1.1
2. Node.js с установленным Node Package Manager (NPM). Node.js в нашем проекте нам нужна только для 2 мастхэв тулзов веб.разработки – это Webpack(для сборки и обработки различными прелоадерами нашего клиентского кода) и NPM(для установки js утилит/компонентов/пакетов)
Что будем писать?
Разбираться будем на примере разработки очень простого блога, который умеет выводить список постов на главной странице, переходить на отдельную страницу с комментариями (с возможностью комментировать), выполнять авторизацию его владельца и давать ему возможность написать новый пост.
Часть 1. Бэкенд
Бэк из себя будет представлять набор restful api для клиента, базу будем использовать ms sql. Для работы с базой – EntityFramework Core, Code First подход.
Создаем пустой ASP.NET Core Web Application проект, будем дописывать в дальнейшем все необходимое руками.
В новом проекте, в классе Startup (файл Startup.cs), который является основным конфигурационным файлом в asp.net core, подключим сервис и middleware МVС (подробнее про цепочку middleware и обработку запроса пользователя с помощью слоев middleware, можно почитать в документации microsoft). Как известно в asp.net core весь статический контент(js/css/img) должен лежать в папке wwwroot (по умолчанию, если не указана другая папка), для того чтобы этот контент отдать конечному пользователю мы должны прописать еще один слой middleware – вызывать extension метод UseStaticFiles. В итоге у нас получится класс Startup с следующим кодом:
Startup.cs
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
}
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseStaticFiles();
app.UseMvc();
}
}
Теперь займемся бизнес логикой. Создадим в нашем solution два новых проекта Class Library (.NET Standart):
- DBRepository где будем работать с базой через EntityFramework Core
- Models, где будут лежать дата классы нашего приложения
И добавим references в DBRepository на проект Models, а в проект ASP.NET PersonalPortal на проекты DBRepository и Models.
Таким образом мы изолируем репозиторий, приложение и модель друг от друга. И в дальнейшем, например, можем заменить сборку работы с базой DBRepository на другую сборку, которая работает с базой не через EF Core, а через какую либо другую ORM или через ado.net. Или, например, сможем подключить сборку репозитория и модели, не к веб приложению, а к десктоп.
Далее, добавим в проект Models классы, которые будут в дальнейшем мапиться на таблицы в базе, останавливаться на этом подробно я не буду, на диаграмме классов, по-моему, все говорит само за себя:
Теперь перейдем в проект DBRepository и установим два nuget пакета, которые нам понадобяться для работы с EF Core — Microsoft.EntityFrameworkCore и провайдер бд MS SQL Server Microsoft.EntityFrameworkCore.SqlServer
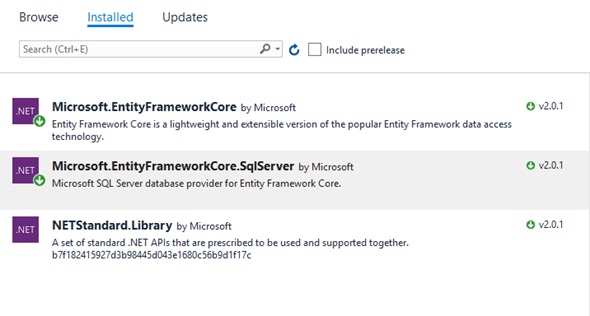
Создадим наследника от класса DBContext, основого класса EF — точки входа для работы с данными. И фабрику (интерфейс+реализация), которая будет создавать этот контекст. Для чего нам понадобится фабрика мы разберемся позже.
RepositoryContext.cs
public class RepositoryContext : DbContext
{
public RepositoryContext(DbContextOptions<RepositoryContext> options) : base(options)
{
}
public DbSet<Post> Posts { get; set; }
public DbSet<Comment> Comments { get; set; }
public DbSet<Tag> Tags { get; set; }
public DbSet<User> Users { get; set; }
}
RepositoryContextFactory.cs
public class RepositoryContextFactory : IRepositoryContextFactory
{
public RepositoryContext CreateDbContext(string connectionString)
{
var optionsBuilder = new DbContextOptionsBuilder<RepositoryContext>();
optionsBuilder.UseSqlServer(connectionString);
return new RepositoryContext(optionsBuilder.Options);
}
}
Код очень простой – в фабрике мы конфигурируем dbcontext для работы с SQL Server и передаем строку подключения к бд(без connection string никуда…). Extension метод UseSqlServer к нам пришел из пакета Microsoft.EntityFrameworkCore.SqlServer.
Воспользуемся популярным паттерном «Репозиторий» и создадим классы-посредники, которые будут «отгораживать» наши конечные классы-потребители от работы с базой и EntityFramework в частности.
Добавим класс BaseRepository, интерфейс IBlogRepository и его реализацию BlogRepository.
BaseRepository.cs
public abstract class BaseRepository
{
protected string ConnectionString { get; }
protected IRepositoryContextFactory ContextFactory { get; }
public BaseRepository(string connectionString, IRepositoryContextFactory contextFactory)
{
ConnectionString = connectionString;
ContextFactory = contextFactory;
}
}
BaseRepository будет являться, как видно из названия, базовым классом для всех созданных нами классов-посредников. В конструктор он принимает строку подключения и фабрику для создания EF контекста.
BlogRepository.cs
public class BlogRepository : BaseRepository, IBlogRepository
{
public BlogRepository(string connectionString, IRepositoryContextFactory contextFactory) : base(connectionString, contextFactory) { }
public async Task<Page<Post>> GetPosts(int index, int pageSize, string tag = null)
{
var result = new Page<Post>() { CurrentPage = index, PageSize = pageSize };
using (var context = ContextFactory.CreateDbContext(ConnectionString)) // 1
{
var query = context.Posts.AsQueryable();
if (!string.IsNullOrWhiteSpace(tag))
{
query = query.Where(p => p.Tags.Any(t => t.TagName == tag));
}
result.TotalPages = await query.CountAsync();
query = query.Include(p => p.Tags).Include(p => p.Comments).OrderByDescending(p => p.CreatedDate).Skip(index * pageSize).Take(pageSize); // 2
result.Records = await query.ToListAsync(); //3
}
return result;
}
}
В классе BlogRepository, не откладывая в долгий ящик, мы уже реализовали метод для получения списка постов с постраничным выводом.
В строке 1 мы наконец то создаем контекст для работы с БД. В строке 2, используя методы LINQ, которые EF транслирует в sql скрипты, мы пишем запрос для получения нужной нам страницы постов вместе с тегами (с помощью метода Include). Важно помнить, что LINQ методы выполняются lazy, и поэтому само обращение к базе будет только после вызова метода ToListAsync в строке 3 (и CountAsync). После того как данные были получены, контекст работы с бд необходимо закрыть (обернуть его создание в using, как сделано в данном случае).
Вернемся в проект с веб-приложением и добавим конфигурационный файл. Созданный файл уже будет содержать поле с строкой подключения, нам нужно лишь отредактировать ее и указать актуальную базу и сервер.
В классе Startup зарегистрируем реализацию классов репозитория и фабрики. В .NET Core IoC контейнер идет уже из коробки, поэтому воспользуемся им. И добавим конструктор Startup(IConfiguration configuration) для доступа к файлу конфигурации, экземпляр конфигурации будет уже инжектиться WebHostBuilder-м. Далее ConnectionString берем из конфигурационного файла.
Startup.cs
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddScoped<IRepositoryContextFactory, RepositoryContextFactory>(); // 1
services.AddScoped<IBlogRepository>(provider => new BlogRepository(Configuration.GetConnectionString("DefaultConnection"), provider.GetService<IRepositoryContextFactory>())); // 2
}
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseStaticFiles();
app.UseMvc();
}
В строках 1 и 2 регистрируем реализации с помощью метода AddScope.
Вообще существуют 3 метода регистрации реализации – AddScope, AddTransient, AddSingleton, они различаются лишь временем жизни регистрируемого инстанса.
AddScope – инстанс создается 1 раз на каждый request от клиента к серверу.
AddTransient — каждый раз при резолве зависимости создается новый инстанс
AddSingleton – инстанс создается в единственном экземпляре и не меняется между запросами.
Подробнее можно прочитать в документации.
Теперь создадим контроллер с API методом и уже можно что-то щупать руками.
Controllers/BlogController.cs
[Route("api/[controller]")]
public class BlogController : Controller
{
IBlogRepository _blogRepository;
public BlogController(IBlogRepository blogRepository)
{
_blogRepository = blogRepository;
}
[Route("page")]
[HttpGet]
public async Task<Page<Post>> GetPosts(int pageIndex, string tag)
{
return await _blogRepository.GetPosts(pageIndex, 10, tag);
}
}
Зависимость IBlogRepository автоматически зарезолвится IoC контейнером.
Нажимаем F5, забиваем в адресную строку браузера урл к нашему api методу — localhost:64422/api/blog/page и… получаем следующий эксепшен, если конечно мы верно изменили строку подключения:
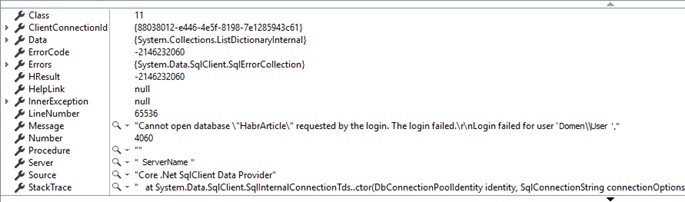
Дело в том, что нашей базы еще нет, и естественно EF не может открыть несуществующую базу. Нужно каким-то образом сообщить, что в случае если бд нет, EF должен ее создавать.
Можно просто вызывать метод context.Database.EnsureCreated перед обращением к базе, но чаще используют механизм миграций. Он позволяет, в случае если у нас была изменена схема данных, аккуратно применить ее на базу без потери существующих данных. Давайте попробуем.
Для работы утилиты миграции необходимо, чтобы наследник класса DBContext (в нашем случае класс RepositoryContext) был доступен из вне, и утилита миграций при запуске смогла его «вытащить» и использовать для своих нужд. Для этого мы должны:
либо зарегистрировать RepositoryContext в сервисах, но мы не очень хотим завязываться в нашем проекте на контекст, не зря же мы создавали классы-посредники к репозиториям
services.AddDbContext<RepositoryContext>(options => options.UseSqlServer(Configuration.GetConnectionString("DefaultConnection")));
либо реализовать следующий интерфейс
public interface IDesignTimeDbContextFactory<out TContext> where TContext : DbContext
{
TContext CreateDbContext([NotNullAttribute] string[] args);
}
Выберем последний вариант.
Пускай вас не смущает еще одна фабрика для создания контекста, она нужна ТОЛЬКО для утилиты миграции.
Итак, реализуем интерфейс:
DesignTimeRepositoryContextFactory.cs
public class DesignTimeRepositoryContextFactory :
IDesignTimeDbContextFactory<RepositoryContext>
{
public RepositoryContext CreateDbContext(string[] args)
{
var builder = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddJsonFile("appsettings.json");
var config = builder.Build();
var connectionString = config.GetConnectionString("DefaultConnection");
var repositoryFactory = new RepositoryContextFactory();
return repositoryFactory.CreateDbContext(connectionString);
}
}
Реализация очень проста — вытаскиваем строку подключения из конфига, создаем и возвращаем DBContext.
Теперь открываем Powershell консоль, выбираем проект DBRepository и добавляем миграцию.
Add-Migration InitialCreate -Project DBRepository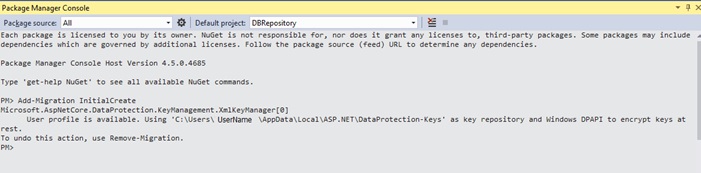
Вуаля, миграция создалась, в проект DBRepository добавилась папка Migrations, содержащая новые файлы с автоматически сгенерированными классами и методами Up для инкремента миграции, Down для декремента.
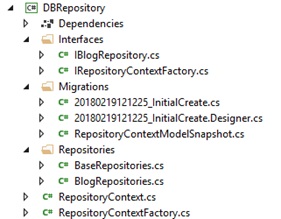
Предыдущей командой мы лишь создали классы в нашем проекте, теперь необходимо применить миграцию на базу.
Update-Database
Давайте пропишем в коде автоматическое применение к базе, чтобы каждый раз, при очередной миграции, вручную не вызывать команду Update-Database и чтобы у тех кто в дальнейшем будет работать с нашим кодом применились все миграции и создалась база.
Перейдем в файл Program.cs и напишем следующие заветные строки.
Program.cs
public static void Main(string[] args)
{
var host = BuildWebHost(args);
var builder = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddJsonFile("appsettings.json"); //1
var config = builder.Build(); // 1
using (var scope = host.Services.CreateScope()) //2
{
var services = scope.ServiceProvider;
var factory = services.GetRequiredService<IRepositoryContextFactory>();
factory.CreateDbContext(config.GetConnectionString("DefaultConnection")).Database.Migrate(); // 3
}
host.Run();
}
public static IWebHost BuildWebHost(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.UseStartup<Startup>()
.Build();
В строке 1 мы создаем конфиг, в строке 2 создаем новый scope, чтобы получить экзмпляр RepositoryContextFactory (мы же помним, что зарегистрировали его с временем жизни scope? Без scope не будет и экземпляра), в строке 3 Метод DBContext.Database.Migrate() накатывает на базу все миграции, которых еще нет в базе. И если это первый вызов, когда базы еще нет, то создает ее. Далее диспозим скоуп, т.к. нам он больше не нужен.
А как механизм миграции узнает, какие миграции уже есть в базе, а каких еще нет? Все очень просто. При выполнении создается таблица __EFMigrationsHistory, где записаны имена всех миграций которые были применены.
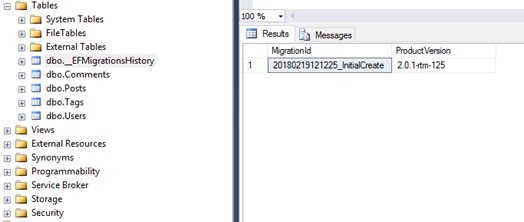
Следующие миграции добавляются по аналогии – вносятся изменения в дата модель, выполняется команда Add-Migration <migration_name>, утилита сравнивает новые изменения с снепшотом предыдущей миграции и по результатам генерирует новый класс с миграцией.
С бэком, на данном этапе, мы практически разобрались, можно перейти к фронту, но перед нами возникает дилемма – разрабатывать фронт в отдельном проекте и в дальнейшем хостить раздельно или оставить его в том же проекте, что и web api, что конечно облегчит разработку и деплой. Также уже есть готовые темплейты в Visual Studio, которые рутинные вещи такие как роутинг и сборку webpack превращают в middleware магию, с помощью nuget-пакета Microsoft.AspNetCore.SpaServices.
Первый вариант вариант безусловно гибче, он позволяет отдельно деплоить веб и бэк, разрабатывать их в разных средах, но второй вариант тоже вполне имеет право на существование, в нашем случае, все же перевешивает простота и наглядность, поэтому, сделаем над собой усилие, и мужественно пойдем по второму, более легкому пути.
Создадим вьюху-контейнер клиентского приложения (Views/Home/Index.cshtml), контроллер, что будет ее отдавать и пропишем роутинг.
Startup.cs
...
app.UseMvc(routes =>
{
routes.MapRoute(
name: "DefaultApi",
template: "api/{controller}/{action}");
});
...
Часть 2. Фронтенд
Пришло время
Тут надо оговориться, что в Visual Studio есть темплейт по созданию SPA приложения в связке с asp.net core, но мы будем руководствоваться принципом, если хочешь в чем-то разобраться, сделай это своими руками. К тому же, на мой взгляд, тот темплейт несколько избыточен и многое там придется удалять.
Создадим веб.проект. Откроем командную строку, перейдем в папку, где у нас лежит, созданный в студии .net core web application, и выполним команду npm init. Заполните ряд параметров которые будет спрашивать утилита, ну или просто понажимайте enter и на выходе вы получите файл package.json который будет являться аналогом “*.csproj “ для веба.
Далее вам необходимо скачать ряд npm пакетов, которые must have для нашей дальнейшей разработки. Можно ставить каждый пакет в отдельности выполняя команду npm i <package_name> [--save-dev], или сразу прописать все зависимости в нашем проектном файле и выполнить npm install. Для экономии времени и места в статье приведу package.json с всеми зависимостями.
package.json
{
"name": "personalportal",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"devDependencies": {
"babel-core": "^6.26.0",
"babel-loader": "^7.1.2",
"babel-preset-env": "^1.6.0",
"babel-preset-es2015": "^6.24.1",
"babel-preset-react": "^6.16.0",
"babel-preset-stage-0": "^6.24.1",
"aspnet-webpack": "^2.0.3",
"css-loader": "^0.28.7",
"file-loader": "^1.1.6",
"style-loader": "^0.19.1",
"webpack": "^3.11.0"
},
"dependencies": {
"babel-polyfill": "^6.26.0",
"isomorphic-fetch": "^2.2.1",
"query-string": "^5.0.1",
"react": "^16.2.0",
"react-dom": "^16.2.0",
"react-redux": "^5.0.6",
"react-router-dom": "^4.2.2",
"redux": "^3.7.2",
"redux-thunk": "^2.2.0"
}
}
В этом файле, помимо стандартно сгенерированных полей, мы видим 2 секции – devDependencies и dependencies, это список пакетов которые мы ставим. Отличие одной секции от другой состоит в том, что в секции devDependencies мы прописываем пакеты, которые необходимы ТОЛЬКО для сборки нашего приложения – различные лоадеры, прелоадеры, преобразователи, упаковщики, а в секции dependencies – пакеты необходимые именно для разработки, которые мы будем импортировать и использовать для написания кода.
Кратко пробежимся по пакетам:
- Пакеты babel-* нам необходимы, во-первых, чтобы использовать jsx синтаксис при написании React компонентов, вместо унылых вызовов js функций (ниже, когда будем писать нашу фронт часть, мы разберемся что такое jsx синтаксис), во-вторых, чтобы использовать современный, радующий глаз, js синтаксис и не волноваться по поводу совместимости его с старыми (в разумных пределах) браузерами.
- Пакет webpack – основной, невероятно мощный инструмент сборки нашего веб-приложения.
- Пакеты react/react-dom для разработки на React.
- Пакет react-router-dom для клиентского роутинга в нашем SPA приложении.
- redux/react-redux/redux-thunk – пакеты для организации архитектуры нашей фронт части.
- Isomorphic-fetch, query-string – просто удобные пакеты упрощающие работу с query строкой браузера и запросами к серверу.
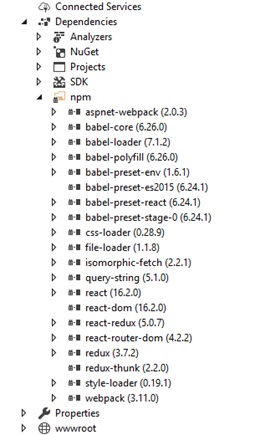
После выполнения команды npm install у нас будет создана папка node_modules, в каталоге с веб-приложением, и туда скачаются все прописанные пакеты и их зависимости. Также должен создастся файл package-lock.json с описанием всех зависимостей.
Ну и Visual Studio должна увидеть эти пакеты и отобразить их у себя под вкладкой Dependencies
Далее перейдем в файл Startup.cs и пропишем middleware магию, о которой говорилось выше. Для этого нам необходимо поставить пакет Microsoft.AspNetCore.SpaServices, ну или он уже есть в составе пакета Microsoft.AspNetCore.All.
Startup.cs
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseWebpackDevMiddleware(); // 1
}
app.UseStaticFiles();
app.UseMvc(routes =>
{
routes.MapRoute(
name: "DefaultApi",
template: "api/{controller}/{action}");
routes.MapSpaFallbackRoute("spa-fallback", new { controller = "Home", action = "Index" }); // 2
});
}
В строке 1 мы включаем поддержку webpack, теперь у нас не будет болеть голова за сборку клиентских ресурсов и нам не нужно будет каждый раз вручную ее запускать, прописывать куда нибудь в PostBuildEvents или держать открытым окошко консоли с запущенной webpack –watch. Этой строкой мы создаем инстанс webpack-а в памяти, который будет отслеживать изменения в файлах и запускать инкрементальную сборку.
В строке 2 мы включаем поддержку клиентского роутинга. Попробую вкратце описать проблему, которую решает данная строка. Как вы знаете философия SPA такова, что пользователю в браузер всегда загружена одна станица и новые данные подгружаются ajax запросами. И весь роутинг, который меняется в строке запроса браузера, это на самом деле не ресурсы сервера, а клиентская «эмуляция запросов» к данным ресурсам. Пользователь все равно остается на одной и той же странице. Проблем нет, если пользователь последовательно переходит к нужному ресурсу, но, если он решит сразу перейти к этому ресурсу напрямую, тогда проблемы появятся.
Например, ваше приложение располагается по адресу www.mytestsite.com. Пользователь нашел интересный контент на странице www.mytestsite.com/home/news?id=1 и решил скинуть ссылку другу или подруге. Друг/подруга получает эту ссылку, копирует в браузер, и получает 404 ошибку. Проблема тут в том, что на сервере физически нет этого ресурса и веб-сервер понятия не имеет как роутить данный url, потому что у нас SPA приложение и потому что был организован клиентский роутинг.
Так вот строка 2 в Startup.cs на все подобные запросы отдает страницу контейнер, та приезжает клиенту и уже на клиенте приложение разруливает роутинг.
Теперь нам нужно создать файл-конфиг для webpack(webpack.config.js), руководствуясь которым, webpack будет применить различные препроцессоры и собирать наше приложение. Создадим его там же где у нас лежит package.json.
webpack.config.js
'use strict';
const webpack = require('webpack');
const path = require('path');
const bundleFolder = "./wwwroot/assets/";
const srcFolder = "./App/"
module.exports = {
entry: [
srcFolder + "index.jsx"
],
devtool: "source-map",
output: {
filename: "bundle.js",
publicPath: 'assets/',
path: path.resolve(__dirname, bundleFolder)
},
module: {
rules: [
{
test: /\.jsx$/,
exclude: /(node_modules)/,
loader: "babel-loader",
query: {
presets: ["es2015", "stage-0", "react"]
}
}
]
},
plugins: [
]
};
Кратко пробежимся по конфигу. За подробной документацией лучше обратиться к официальным источникам. Также есть отличный скринкаст по вебпаку, к сожалению, он только по webpack 1.x, но основные вещи и концепции вполне можно посмотреть и там.
Итак, первым делом нам нужно указать точку входа webpack в наши исходники — значение поля entry, это и есть она родимая.
Далее в output указываем куда webpack должен положить результат своей работы (bundle).
В devtool указываем, что нужно создать source-map, чтобы при отладке не лазить по огромному бандлу, а была привязка к исходникам.
И наконец в секции module указываем какие лоадеры нужно подключить. Пока подключим только модуль babel и пресеты для него – react для трансформации jsx синтаксиса, es2015 для поддержки ES6, stage-0 для использования новых js фич
Ну что же, мы закончили с настройкой, и наконец то готовы приступить к самой разработке.
Давайте создадим директорию App в корне нашего asp.net core приложения, и в ней добавим файл index.jsx. Приведу ниже скрин из solution explorer, чтобы вы не заплутали.
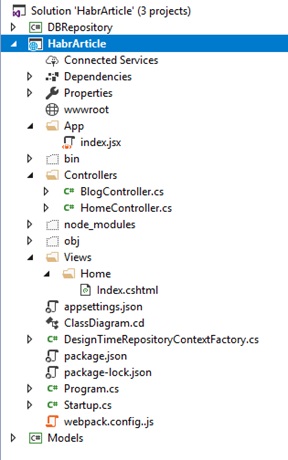
В index.jsx напишем следующее:
index.jsx
import React from 'react' //1
import { render } from 'react-dom' //2
import App from './containers/app.jsx' //3
render(
<App />,
document.getElementById('content')
) //4
Это будет входной точкой в наше клиентское приложение. Вкратце, в 2 верхних строчках мы импортируем все для разработки на React, в 3-й строке мы импортируем наш компонент-контейнер App, который напишем ниже. В 4-й строке рендерим этот компонент в DOM элемент с id=”content”.
Запись вида <App /> это и есть JSX, таким образом мы можем работать с компонентами как с xml и писать разметку в js файлах. Без обработки соответствующим пресетом babel, нам необходимо было бы каждый раз вызывать метод React.createElement, что в разы ухудшило бы читаемость и усложнило написание компонентов.
render(
React.createElement(App, null, null),
document.getElementById('content')
)
Создадим файл app.jsx, про который я упоминал выше:
app.jsx
import React from 'react';
import ReactDOM from 'react-dom';
import { BrowserRouter as Router, Route, Switch} from 'react-router-dom';
import Header from './header/header.jsx';
import About from './about/about.jsx';
import Blog from './blog/blog.jsx';
export default class App extends React.Component {
render() {
return (
<Router>
<div>
<Header />
<main>
<Switch>
<Route path="/about" component={About} />
<Route path="/" component={Blog} />
</Switch>
</main>
</div>
</Router>
);
}
};
Что тут интересного. Во-первых, мы объявили новый компонент строкой export default class App extends React.Component и экспортировали его, чтобы он был доступен извне.
Во-вторых, мы импортировали набор компонентов из пакета react-router-dom для организации клиентского роутинга. Router – это root компонент роутинга, в который должны быть вложены все остальные, а Switch и Route это сама организация роутинга. В данном случае мы хотим, чтобы при обращении к корневому пути (для примера — www.mytestsite.com) выводился наш компонент Blog, а при обращении к пути /about (www.mytestsite.com/about) выводился компонент About.
Header, About, Blog это наши пользовательские компоненты, давайте быстро накидаем их фейки. Создайте 3 директории в том же каталоге, что и app.jsx, в новых каталогах создайте по файлу и скопипастите следующий код, изменив имя класса, ну и текст в div
about.jsx
import React from 'react';
export default class About extends React.Component {
render() {
return (
<div>Обо мне</div>
);
}
};
Теперь перейдем в новосозданный header.jsx и сделаем навигацию.
header.jsx
import React from 'react';
import { Link } from 'react-router-dom';
export default class Header extends React.Component {
render() {
return (
<header>
<menu>
<ul>
<li>
<Link to="/">Блог</Link>
</li>
<li>
<Link to="/about">Обо мне</Link>
</li>
</ul>
</menu>
</header>
);
}
};
Тут ничего нового, за исключением компонента Link. Компонент будет генерировать ссылку, которая не будет отсылать вас на сервер, а будет изменять строку запроса в браузере, добавлять запись в историю, в общем вести себя как обычная ссылка, но без перезагрузки страницы.
Теперь давайте запустим проект и посмотрим, что у нас получилось. Не забудем подключить итоговый бандл, результат работы webpack, на нашу страницу-контейнер Index.cshtml
Index.cshtml
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width" />
<script type="text/javascript">
constants = {
getPage: '@Url.RouteUrl("DefaultApi", new {controller = "Blog", action = "page" })'
}
</script>
<title>Index</title>
</head>
<body>
<div id="content">
</div>
<script type="text/javascript" src="@Url.Content("~/assets/bundle.js")"></script>
</body>
</html>

Конечно визуальной красоты пока мало, но css, стили, картинки и прочее наведение марафета, не входит в рамки этой статьи.
Пощелкаем на ссылки и убедимся, что страница не перезагружается, а строка запросов в браузере изменяет свой url. Работает? Поехали дальше.
Теперь пришло время подумать над архитектурой нашего клиентского приложения, да и в целом над организацией расположения файлов, компонентов и т.д. На эту тему конечно сломано много копий, прошло много холиваров, и один из подходов, что файлы удобно группировать вокруг функций(фич). Давайте придерживаться этого правила и в нашем фронтенд проекте.
Что касается архитектуры мы будем использовать популярный сейчас Redux. Когда мы настраивали webpack мы уже установили все необходимые пакеты для него (redux, redux-thunk, react-redux). Подробнее про Redux лучше почитать в документации. Есть ее полный перевод на русский.
Итак, давайте займемся нашим блогом, а именно выводом ленты сообщений.
Тут надо сказать несколько слов о архитектуре Redux. Вся архитектура построена вокруг ключевых понятий – action/reducer/store/view. Основной идей этой архитектуры, является то, что состояние нашего приложения хранится в одном месте(store) и влиять на это состояние могут лишь так называемые чистые функции(reducers), которые просто берут предыдущее состояние, по флагу(ключу) определяют, как нужно его изменить и возвращают новое состояние.
В свою очередь view, на какое-либо действие от пользователя, вызывают так называемые actions, которые выполняют обработку этих действий (выполняют/получают реквесты на сервер, бизнес логику и т.д.) и новые данные вместе с флагом отдают reducers, которые знают, как применить эти данные к состоянию приложения.
Таким образом у нас получается разделение ответственности и однонаправленный поток данных, что удобно поддерживать в дальнейшем и покрывать тестами.
Пока, возможно, это звучит не очень понятно, но на примере получения/отображения ленты сообщений мы разберем архитектуру подробнее.
В директории app/blog/ создадим redux-инфраструктурные файлы. blogActions.jsx, blogReducer.jsx, blogConstants.jsx (для хранения ключей действий).
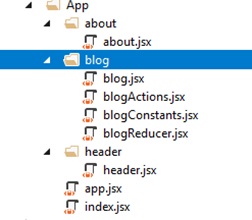
Перейдем в blogActions.jsx и напишем метод получения списка постов с сервера.
blogActions.jsx
import { GET_POSTS_SUCCESS, GET_POSTS_ERROR } from './blogConstants.jsx'
import "isomorphic-fetch"
export function receivePosts(data) {
return {
type: GET_POSTS_SUCCESS,
posts: data
}
}
export function errorReceive(err) {
return {
type: GET_POSTS_ERROR,
error: err
}
}
export function getPosts(pageIndex = 0, tag) {
return (dispatch) => {
let queryTrailer = '?pageIndex=' + pageIndex;
if (tag) {
queryTrailer += '&tag=' + tag;
}
fetch(constants.getPage + queryTrailer)
.then((response) => {
return response.json()
}).then((data) => {
dispatch(receivePosts(data))
}).catch((ex) => {
dispatch(errorReceive(err))
});
}
}
С помощью метода getPosts мы получаем данные, а с помощью метода state.dispath() мы сообщаем reducers о том, что произошло действие и результатом стали некие данные. В нашем случае действия это recievePosts и errorReceive. GET_POSTS_SUCCESS, GET_POSTS_ERROR, это константы по которым reducer будет идентифицировать действие.
blogConstants.jsx
export const GET_POSTS_SUCCESS = 'GET_POSTS_SUCCESS'
export const GET_POSTS_ERROR = 'GET_POSTS_ERROR'
Теперь перейдем в blogReducer.jsx и напишем код, который изменяет состояние нашего приложения по этим действиям.
blogReducer.jsx
import { GET_POSTS_SUCCESS, GET_POSTS_ERROR } from './blogConstants.jsx'
const initialState = {
data: { currentPage: 0, totalPages: 0, pageSize: 0, records: [] },
error: ''
}
export default function blog(state = initialState, action) {
switch (action.type) {
case GET_POSTS_SUCCESS:
return { ...state, data: action.posts, error: '' }
case GET_POSTS_ERROR:
return { ...state, error: action.error }
default:
return state;
}
}
Все просто, метод-reducer получает на вход текущее состояние и действие. По switch определяет какое действие произошло, изменяет состояние и возвращает новую его копию. initialState, как не трудно догадаться, состояние по умолчанию.
Ок, теперь нам нужно собрать все это воедино и заставить работать.
Перейдем в файл blog.jsx, накидаем разметку и подключим нашу redux инфраструктуру.
blog.jsx
import React from 'react';
import ReactDOM from 'react-dom';
import { connect } from 'react-redux';
import { getPosts } from './blogActions.jsx'
class Blog extends React.Component {
componentDidMount() {
this.props.getPosts(0);
}
render() {
let posts = this.props.posts.records.map(item => {
return (
<div key={item.postId} className="post">
<div className="header">{item.header}</div>
<div className="content">{item.body}</div>
<hr />
</div>
);
});
return (
<div id="blog">
{posts}
</div>
);
}
};
let mapProps = (state) => {
return {
posts: state.data,
error: state.error
}
}
let mapDispatch = (dispatch) => {
return {
getPosts: (index, tags) => dispatch(getPosts(index, tags))
}
}
export default connect(mapProps, mapDispatch)(Blog)
Что мы имеем?
1. Класс Blog, с простой разметкой, который при инициализации запрашивает посты и отображает их.
2. Функцию mapProps, которая маппит состояние приложения на переменные-параметры.
3. Функцию mapDispath, которая маппит action на переменные-методы.
4. Функция connect, которая оборачивает класс-компонент Blog в redux-инфраструктуру и передает ему замапленные параметры в – this.props, с которыми мы уже и работает в самом компоненте.
Чтобы все окончательно заработало нам необходимо обернуть наше приложение в react-redux компонент Provider и создать хранилище приложения store.
index.jsx
import React from 'react'
import { render } from 'react-dom'
import { createStore, applyMiddleware } from 'redux'
import { Provider } from 'react-redux'
import thunk from 'redux-thunk'
import App from './app.jsx'
import blogReducer from './blog/blogReducer.jsx'
function configureStore(initialState) {
return createStore(blogReducer, initialState, applyMiddleware(thunk))
}
const store = configureStore()
render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('content')
)
Теперь добавим несколько записей-постов в базу и протестируем, что у нас получилось.
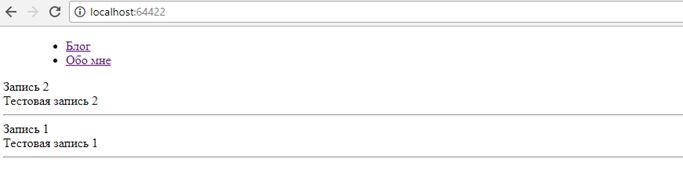
Работает!
Я не буду рассматривать создание остальных компонентов, так как пишутся они по аналогии с компонентом блога, который мы рассмотрели — создаются actions/reducer и все это применяется методом connect к react-компоненту.
Единственно стоит упомянуть, что для создания хранилища createStore, требуется передать один редьюсер, но мы можем(и обязательно захотим для удобства) разбить общий редьюсер на редьюсеры по фичам, и чтобы store корректно создавался необходимо будет их потом объединить. В этом нам поможет метод combineReducers.
rootReducer.jsx
import { combineReducers } from 'redux'
import blog from './blog/blogReducer.jsx'
import header from './header/headerReducer.jsx'
export default combineReducers({
blog,
header
})
index.jsx
…
import rootReducer from './rootReducer.jsx'
function configureStore(initialState) {
return createStore(rootReducer, initialState, applyMiddleware(thunk))
}
…
Часть 3. Аутентификация
Последняя тема, которую мы кратко рассмотрим в этой статье будет аутентификация. Будем использовать популярную аутентификацию на основе JSON Web Token (JWT).
Принцип действия прост:
1. Мы передаем логин пароль серверу
2. Сервер, в случае если они корректны, генерирует токен, который включает в себя данные необходимые для последующей авторизации сервером и возвращает его клиенту.
3. Клиент сохраняет токен, например в localStorage и при каждом запросе, требующем авторизацию, прикрепляет токен к хедеру запроса.
4. Сервер проверяет токен на корректность, просрочку, если все ОК, то возвращает данные.
Поставим соответствующий nuget пакет для asp.net core — Microsoft.AspNetCore.Authentication.JwtBearer, или убедимся, что он у нас стоит вместе Microsoft.AspNetCore.All.
Регистрируем в сервисах аутентификацию и укажем схему аутентификации на основе JWT токенов. Следующим экстеншен методом (AddJwtBearer) конфигурируем ее.
Startup.cs
...
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddAuthentication(JwtBearerDefaults.AuthenticationScheme)
.AddJwtBearer(options =>
{
options.RequireHttpsMetadata = false;
options.SaveToken = true;
options.TokenValidationParameters = new TokenValidationParameters
{
ValidIssuer = "ValidIssuer",
ValidAudience = "ValidateAudience",
IssuerSigningKey = new SymmetricSecurityKey(Encoding.UTF8.GetBytes("IssuerSigningSecretKey")),
ValidateLifetime = true,
ValidateIssuerSigningKey = true,
ClockSkew = TimeSpan.Zero
};
});
services.AddScoped<IRepositoryContextFactory, RepositoryContextFactory>();
services.AddScoped<IBlogRepository>(provider => new
BlogRepository(Configuration.GetConnectionString("DefaultConnection"),
provider.GetService<IRepositoryContextFactory>()));
}
...
Встраиваем аутентификацию в конвейер обработки запросов.
Startup.cs
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory
loggerFactory)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseWebpackDevMiddleware();
}
app.UseStaticFiles();
app.UseAuthentication();
…
}
Добавляем API метод генерации токена. В GetIdentity мы идем в базу (или куда либо еще где у нас лежат пользователи), сверяем логин/пароль, если все ок, то создаем токен и возвращаем пользователю, иначе возвращаем 401 ошибку.
IdentityController.cs
[Route("token")]
[HttpPost]
public async Task<IActionResult> Token([FromBody]IdentityViewModel model)
{
var identity = await GetIdentity(model.Username, model.Password);
if (identity == null)
{
return Unauthorized();
}
var now = DateTime.UtcNow;
var jwt = new JwtSecurityToken(
issuer: AuthOptions.ISSUER,
audience: AuthOptions.AUDIENCE,
notBefore: now,
claims: identity,
expires: now.Add(TimeSpan.FromMinutes(AuthOptions.LIFETIME)),
signingCredentials: new SigningCredentials(AuthOptions.GetSymmetricSecurityKey(), SecurityAlgorithms.HmacSha256));
var encodedJwt = new JwtSecurityTokenHandler().WriteToken(jwt);
return Ok(encodedJwt);
}
private async Task<IReadOnlyCollection<Claim>> GetIdentity(string userName, string password)
{
List<Claim> claims = null;
var user = await _service.GetUser(userName);
if (user != null)
{
var sha256 = new SHA256Managed();
var passwordHash = Convert.ToBase64String(sha256.ComputeHash(Encoding.UTF8.GetBytes(password)));
if (passwordHash == user.Password)
{
claims = new List<Claim>
{
new Claim(ClaimsIdentity.DefaultNameClaimType, user.Login),
};
}
}
return claims;
}
Использование. АПИ метод будет доступен только авторизированным пользователям. Ну или атрибут можно повесить на контроллер.
BlogController.cs
[Authorize]
[Route("post")]
[HttpPost]
public async Task AddPost([FromBody] AddPostRequest request)
{
await _blogService.AddPost(request);
}
На клиенте, перед каждым запросом, который требует авторизации, необходимо добавлять заголовок в формате ‘Bearer’ + token
fetch(constants.post, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + token
},
body: JSON.stringify({ header: header, body: body, tags: tags })
Заключение
Статья получилась несколько больше чем я рассчитывал, но несмотря на это она не затрагивает некоторые важные вещи, необходимые для разработки. Это конечно логи, написание тестов, как на бэке, так и на клиенте, библиотеки для этого, серверный рендеринг клиентских компонентов, CI/CD и еще кучу всего. Но все же надеюсь то, что я написал в этой статье, кому-то будет полезно и найдет свою целевую аудиторию.
Приложение, которое мы писали всю эту статью можно посмотреть ТУТ.
Исходники можно скачать с github.
Спасибо!
