На самом деле я писал возможно самую медленную функцию мемоизации, да получилась быстрая. Моей вины тут нет. Все дело в балансе.
В балансе между тем насколько долго будет исполнятся мемоизируемая функция, сколько дополнительного времени потребует сахар мемоизации, и (про это все забывают) сколько програмистов потребуется, чтобы эту мемоизацию правильно прикрутить.

Но начнем с простого — что же это за слово такое странно — «мемоизация».
По скорости работы библиотеки ОЧЕНЬ сильно различаются — в тысячи раз. Но весь секрет в том что и как они измеряют, конечно же каждый автор найдет случай, который для его творения подходит лучше всего, найдет свои хитрости.
Lodash.memoize, например, по умолчанию работает с одним аргументом функции. Fast-memoize – имеет разный код для фунций одного или более чем одного аргумента. Memoize-one или reselect молча сохраняют один последний ответ, и сравнивают только с ним. Что очень плохо в одних случаях (расчет чисел фибоначи, например), и очень хорошо в других (React/Redux), за исключением некоторых особенностей (больше одного экземляра компонента).
В общем — везде есть свои хитрости. Без этого было бы не интересно. Давайте остановимся на последнем кейсе, который за последние пару лет был ОЧЕНЬ хорошо расжеван – Redux. Да вот не до конца.
^ вот тут я немного накосячил. Я хотел отфильтровать только активные TODO, но буду получать уникальный массив (с неуникальными значениями), при каждом вызове функции. Это очень, очень плохая идея, так как потом возвращаемое значение сравнивается по shallowequal, а оно не equal.
^ вот тут я это поправил, и теперь ответ будет меняться только если сам массив поменяется.
^ а вот тут бы я очень хотел, чтобы ответ менялся только при изменении текста в активных TODO, но хотеть не вредно. Это практически не возможно сделать.
Redux — очень хороший инструмент, и я его люблю всем сердцем. Но когда дело доходит до разбора стейта на каскад селекторов, с последущей сборкой в ответ, с одной только целью – мемоизировать результат так чтобы лишний раз React не дергать. Нет ребят – я в такие игры не играю.
Тут дело уже не в скорости работы функции мемоизации, а в самом процессе «правильной» мемоизации, времени на нее затраченом и ожидаемом конечном результате.
Memoize-state – библиотека мемоизации, основанная на немного других принципах, которая делает мемоизацию проще, и быстрее. Несмотря на то, что кода в ней раз в 10 больше чем в обычной функции мемоизации.
Начнем с примеров
^ конечный результат будет меняться только если изменился текст в активных TODO.
^ совершенно индентичный результат. Неожиданно?
Memoize-state работает на принципах схожих с MobX или Immer.js – ES6 Proxy, WeakMaps, Reflection и другая современная лабуда, которая и делает эту магию возможной.
Вкратце — memoize-state следит за тем как вы используете переданные аргументы, и что возвращаете как ответ. После чего понимает на какие изменения ей следует реагировать, а на какие — нет. (потребовался почти месяц, чтобы понять как это на самом деле должно работать)
Другими словами — вы можете написать любую функцию, обернуть ее в memoize-state(хоть 10 раз), и они будет мемоизированна по теоритическому максимуму.
Раз разговор про скорость, давайте сравним:
1. Расчет чисел фибоначи. Тест из библиотеки fast-memoize
Ну — не самый худший вариант.
2. Расчет «медленной» функции от трех integer аргументов. Тест из библиотеки memoize-state
Уже лучше.
3. Расчет «mapStateToProps» — обьект на вход, рандомно меняются(или не меняются) значения.
Совсем хорошо. memoize-state просто рвет в клочья. fast-memoize и lodash.memoize, как основанные на JSON.stringify обрабатывают случаи когда обьект дали новый, но значения в нем старые.
Там еще тест, когда на вход подается просто большой обьект, и накладные расходы на JSON.stringify взлетают до небес. Там разница еще больше.
В итоге получается — самая медленная, потому что самая сложная, функция мемоизации совсем не такая уж медленная. Да и накладные расходы на обеспечение своей работы позволяют ей запускаться 16 миллионов в секунду, что конечно же не так круто как 200 для лидеров мемоизации, но в сто тысяч раз больше чем нужно react/redux приложению.
Memoize-state отличается от обычных функций мемоизации тем, что не требует настройки, дружит в мемоизациями которые вы уже имеете(они же будут выбирать из общего state нужные им ключи), что в итоге позволяет назвать ее «внешней мемоизацией».
В результате становиться возможным еще более магическая магия — beautiful-react-redux.
beautiful-react-redux – это врапер для react-redux, который молча обернет mapStateToProps два раза в memoize-state, тем самым обеспечит автоматическую мемоизацию, как для одного, так и для множества компонентов (до свидания re-reselect). Одна строчка — и все приложение стало немного(или много) быстрее. Без какой либо работы с вашей стороны, и это главное.
По факту реализация немного отличается. Просто потому что «селекторы» более не нужны, и повилась возможность «просто писать код».
Просто передайте какие-то пропсы, просто как-то что-то на их основе посчитатайте, и дело в шляпе.
И это опять таки работает просто, и полностью автомагически.
Второй важный вариант — оригинальные тесты memoize-state не только сравнивают скорость, но и сравнивают cache hit/miss. Так вот — мемоизируются 99 из 100 случаев когда нужно мемоизировать, и 0 случаев из 100 когда не надо. Работает почти идеально. И конечно же это все покрыто тестами в три слоя, так как memoize-state состоит из трех частей — memoize-state для самой мемоизации, proxyequal для заворачивания, разворачивания и сравнения обьектов и search-trie для ускорения поиска тех использованных частей обьектов, которые следует сравнивать по значения, и тех которых не следует.
Минус у всего этого только один — для IE11 и Android(React Navite) требует полифил для прокси, что несколько замедляет работу. Но лучше уж так, чем никак.
Впереди еще непаханное поле, например можно увеличить скорость проверки на мемоизацию раза в два. Да и react-redux интеграцию можно избавить от каких либо расчетов в некоторых случаях.
В общем — все заинтересованные приглашаются к yarn add memoize-state, и экспериментам.
GitHub
В балансе между тем насколько долго будет исполнятся мемоизируемая функция, сколько дополнительного времени потребует сахар мемоизации, и (про это все забывают) сколько програмистов потребуется, чтобы эту мемоизацию правильно прикрутить.

Но начнем с простого — что же это за слово такое странно — «мемоизация».
Мемоизация (от англ. memoization) — это один из способов оптимизации, применяемый для увеличения скорости выполнения компьютерных программ —сохранение результатов выполнения функций для предотвращения повторных вычислений .– Спасибо Википедия.Библиотек которые обеспечивают эту самую мемоизацию — ОЧЕНЬ много, но у всех есть свои различные детали реализации — то как они работают с колличеством аргументов, то как они хранят результаты и сколько, ну, конечно же, насколько они быстры.
По скорости работы библиотеки ОЧЕНЬ сильно различаются — в тысячи раз. Но весь секрет в том что и как они измеряют, конечно же каждый автор найдет случай, который для его творения подходит лучше всего, найдет свои хитрости.
Lodash.memoize, например, по умолчанию работает с одним аргументом функции. Fast-memoize – имеет разный код для фунций одного или более чем одного аргумента. Memoize-one или reselect молча сохраняют один последний ответ, и сравнивают только с ним. Что очень плохо в одних случаях (расчет чисел фибоначи, например), и очень хорошо в других (React/Redux), за исключением некоторых особенностей (больше одного экземляра компонента).
В общем — везде есть свои хитрости. Без этого было бы не интересно. Давайте остановимся на последнем кейсе, который за последние пару лет был ОЧЕНЬ хорошо расжеван – Redux. Да вот не до конца.
В мире React/Redux есть функция mapStateToProps, которая «выбирает» из большого общего стейта некоторые значения для конкретного элемента. Если результат работы функции отличается от ранее сохраненного — компонент будет перерисован с новыми данными.
const mapStateToProps = state => ({
todos: state.todos.filter(todo => todo.active)
});^ вот тут я немного накосячил. Я хотел отфильтровать только активные TODO, но буду получать уникальный массив (с неуникальными значениями), при каждом вызове функции. Это очень, очень плохая идея, так как потом возвращаемое значение сравнивается по shallowequal, а оно не equal.
const filterTodos = memoize(todos => todos.filter(todo => todo.active));
const mapStateToProps = state => ({
todos: filterTodos(state.todos)
});^ вот тут я это поправил, и теперь ответ будет меняться только если сам массив поменяется.
const filterTodos = memoize(todos => todos.filter(todo => todo.active));
const getTodos = memoize(todos => todos.map(todo => todo.text ))
const mapStateToProps = state => ({
todos: getTodos(filterTodos(state.todos))
});^ а вот тут бы я очень хотел, чтобы ответ менялся только при изменении текста в активных TODO, но хотеть не вредно. Это практически не возможно сделать.
Redux — очень хороший инструмент, и я его люблю всем сердцем. Но когда дело доходит до разбора стейта на каскад селекторов, с последущей сборкой в ответ, с одной только целью – мемоизировать результат так чтобы лишний раз React не дергать. Нет ребят – я в такие игры не играю.
Тут дело уже не в скорости работы функции мемоизации, а в самом процессе «правильной» мемоизации, времени на нее затраченом и ожидаемом конечном результате.
Ну и конечно не стоит забывать, что далеко не все должно быть мемоизированно. Очень часто проще что-то посчитать «по-настоящему», чем посчитать что считать ничего не надо. Сахар мемоизации далеко не бесплатен.Но! В среде React/Redux скорость мемоизации практически ничего не значит. Важем сам факт мемоизации. Если вы смогли вовремя понять, что результат у вас уже есть, и ничего обновлять не надо — вы пропускаете гиганский кусок React кода, который впустую обновил бы часть приложения.
И даже самая маленькая оптимизация будет в десятки раз превышать «лишние» вычисления в сахаре мемоизации, который сделал эту оптимизацию возможной.Ну а если получается, что использовать «сложные» функции мемоизации очень даже можно, когда не фибоначи считаем, а что-то попроще,– то давайте поиспользуем.
Memoize-state
Memoize-state – библиотека мемоизации, основанная на немного других принципах, которая делает мемоизацию проще, и быстрее. Несмотря на то, что кода в ней раз в 10 больше чем в обычной функции мемоизации.
Начнем с примеров
const filterTodos = memoizeState(todos => todos.filter(todo => todo.active));
const getTodos = memoizeState(todos => todos.map(todo => todo.text ))
const mapStateToProps =state => ({
todos: getTodos(filterTodos(state.todos))
});^ конечный результат будет меняться только если изменился текст в активных TODO.
const filterTodos =todos => todos.filter(todo => todo.active);
const getTodos = todos => todos.map(todo => todo.text )
const mapStateToProps = memoizeState (state => ({
todos: getTodos(filterTodos(state.todos))
}));^ совершенно индентичный результат. Неожиданно?
Memoize-state работает на принципах схожих с MobX или Immer.js – ES6 Proxy, WeakMaps, Reflection и другая современная лабуда, которая и делает эту магию возможной.
Вкратце — memoize-state следит за тем как вы используете переданные аргументы, и что возвращаете как ответ. После чего понимает на какие изменения ей следует реагировать, а на какие — нет. (потребовался почти месяц, чтобы понять как это на самом деле должно работать)
Другими словами — вы можете написать любую функцию, обернуть ее в memoize-state(хоть 10 раз), и они будет мемоизированна по теоритическому максимуму.
PS:!!! функция должна быть pure, иначе фокус не получится. Функция должна принимать на вход «обьекты», работать с ключами в обьектах и возвращать обьект, иначе будет фигня, а не фокус.memoize-state идеально походит для сложных случаев, и особенно для mapStateToProps и любых аналогов. Не пытайтесь использовать ее для расчета фибоначи – в недрах СЛИШКОМ много логики, многократно превышающей сложность самого расчета фибоначи.
Скорость
Раз разговор про скорость, давайте сравним:
1. Расчет чисел фибоначи. Тест из библиотеки fast-memoize
0. base line x 123.592 (операций в секунду)
2. fast-memoize x 203.342.420
3. lodash x 25.877.616
4. underscore x 20.518.294
5. memoize-state x 16.834.719
6. ramda x 1.274.908
Ну — не самый худший вариант.
2. Расчет «медленной» функции от трех integer аргументов. Тест из библиотеки memoize-state
0. base line x 10.646 (операций в секунду)
1. memoize-one x 4.605.161
2. memoize-state x 2.494.236
3. lodash.memoize x 2.148.475
4. fast-memoize x 647.231
Уже лучше.
3. Расчет «mapStateToProps» — обьект на вход, рандомно меняются(или не меняются) значения.
0. base line x 2.921 (операций в секунду)
1. memoize-state x 424.303
3. fast-memoize x 29.811
2. lodash.memoize x 20.664
4. memoize-one x 2.592
Совсем хорошо. memoize-state просто рвет в клочья. fast-memoize и lodash.memoize, как основанные на JSON.stringify обрабатывают случаи когда обьект дали новый, но значения в нем старые.
Там еще тест, когда на вход подается просто большой обьект, и накладные расходы на JSON.stringify взлетают до небес. Там разница еще больше.
В итоге получается — самая медленная, потому что самая сложная, функция мемоизации совсем не такая уж медленная. Да и накладные расходы на обеспечение своей работы позволяют ей запускаться 16 миллионов в секунду, что конечно же не так круто как 200 для лидеров мемоизации, но в сто тысяч раз больше чем нужно react/redux приложению.
Memoize-state отличается от обычных функций мемоизации тем, что не требует настройки, дружит в мемоизациями которые вы уже имеете(они же будут выбирать из общего state нужные им ключи), что в итоге позволяет назвать ее «внешней мемоизацией».
В результате становиться возможным еще более магическая магия — beautiful-react-redux.
beautiful-react-redux – это врапер для react-redux, который молча обернет mapStateToProps два раза в memoize-state, тем самым обеспечит автоматическую мемоизацию, как для одного, так и для множества компонентов (до свидания re-reselect). Одна строчка — и все приложение стало немного(или много) быстрее. Без какой либо работы с вашей стороны, и это главное.
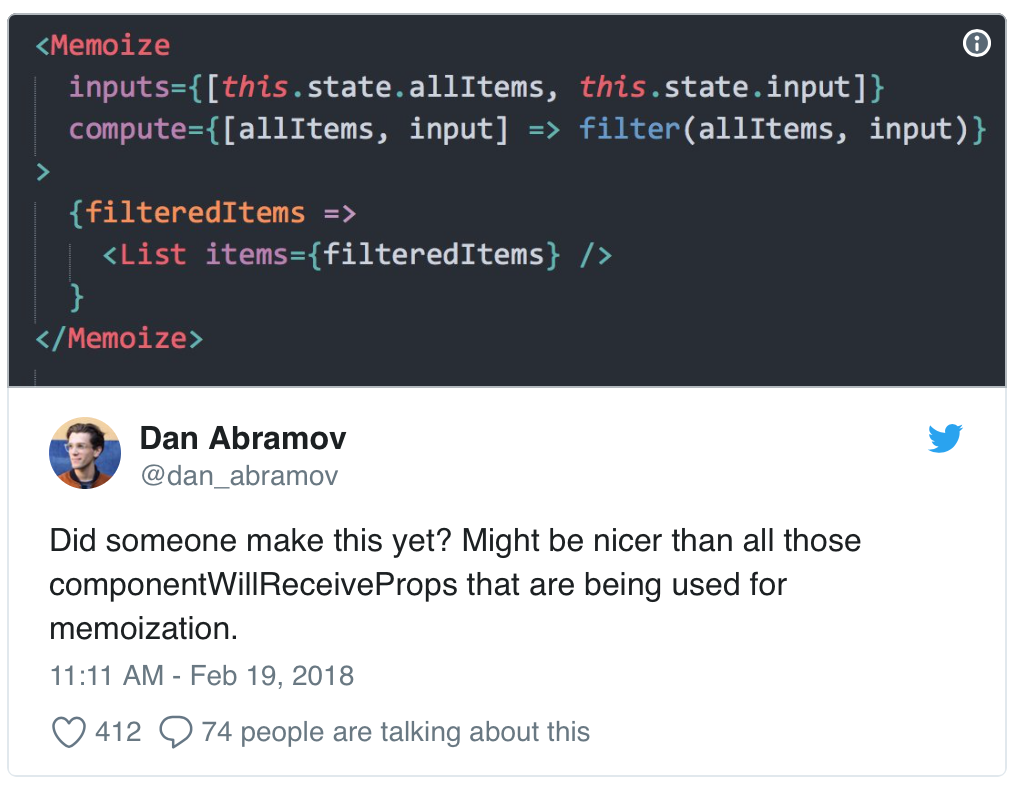
PS: beautiful-react-redux так же предоставляет инструмент для тестирования приложение на «правильность» мемоизации БЕЗ активации memoize-state. Те можно использовать эту магию для проверки более низкоуровнего, более сложного, но более быстрого подхода — стандартных билблиотек. Подробнее в репозитации.Второй прекрасный пример использования — react-memoize — библиотека на основе твита Дэна Абрамова(и так бывает), которая мемоизирует рендер, позволяя фактически отказаться от какой либо логики в componentWillReceiveProps.
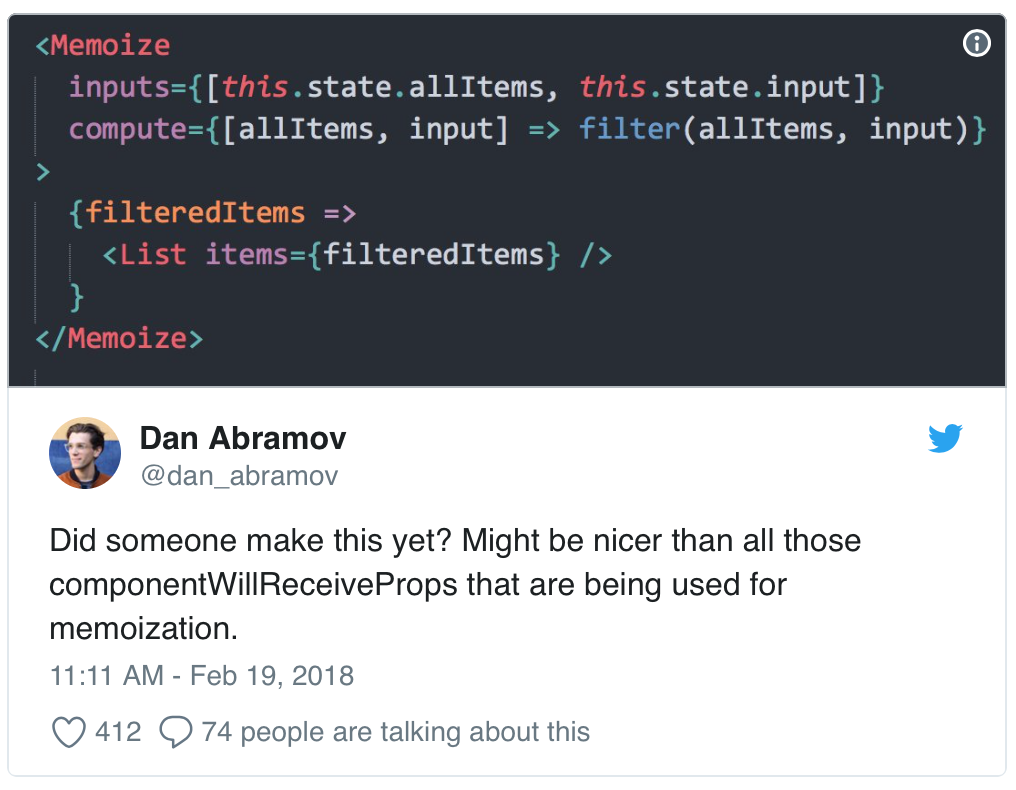
По факту реализация немного отличается. Просто потому что «селекторы» более не нужны, и повилась возможность «просто писать код».
Просто передайте какие-то пропсы, просто как-то что-то на их основе посчитатайте, и дело в шляпе.
<Memoize
prop1 = "theKey"
state = {this.state}
compute={({prop1, state}) => heavyComputation(state[prop1])}
>
{ result => <Display>{result}</Display>}
</Memoize>И это опять таки работает просто, и полностью автомагически.
Второй важный вариант — оригинальные тесты memoize-state не только сравнивают скорость, но и сравнивают cache hit/miss. Так вот — мемоизируются 99 из 100 случаев когда нужно мемоизировать, и 0 случаев из 100 когда не надо. Работает почти идеально. И конечно же это все покрыто тестами в три слоя, так как memoize-state состоит из трех частей — memoize-state для самой мемоизации, proxyequal для заворачивания, разворачивания и сравнения обьектов и search-trie для ускорения поиска тех использованных частей обьектов, которые следует сравнивать по значения, и тех которых не следует.
Совместимость
Минус у всего этого только один — для IE11 и Android(React Navite) требует полифил для прокси, что несколько замедляет работу. Но лучше уж так, чем никак.
Время действовать
Впереди еще непаханное поле, например можно увеличить скорость проверки на мемоизацию раза в два. Да и react-redux интеграцию можно избавить от каких либо расчетов в некоторых случаях.
В общем — все заинтересованные приглашаются к yarn add memoize-state, и экспериментам.
GitHub
