Популярная сегодня методология разработки программного обеспечения DevOps (development и operations) нацелена на активное взаимодействие и интеграцию специалистов по разработке и специалистов по информационно-технологическому обслуживанию. Характерно, что в ходе DevOps генерируются большие объемы данных, которые можно использовать для упрощения рабочих процессов, оркестрации, мониторинга, диагностики неисправностей или других задач. Проблема в том, что данных этих слишком много. Одни только серверные логи могут накапливать несколько сотен мегабайт в неделю. Если используются инструменты мониторинга, то за короткий промежуток времени генерируются мегабайты и гигабайты данных.
Результат предсказуем: разработчики не просматривают непосредственно сами данные, а устанавливают пороговые значения, то есть ищут исключения, а не занимаются аналитикой данных. Но даже с помощью современных аналитических инструментов вы должны знать, что искать.

Большая часть данных, создаваемых в процессах DevOps, связана с развертыванием приложений. Мониторинг приложения пополняет логи сервера, генерирует сообщения об ошибках, трассировку транзакций. Единственный разумный способ проанализировать эти данные и прийти к каким-то выводам в режиме реального времени — использование машинного обучения (ML).
В большинстве систем машинного обучения используются нейронные сети, которые представляют собой набор многоуровневых алгоритмов для обработки данных. Их обучают, вводя предыдущие данные с известным результатом. Приложение сравнивает алгоритмически полученные результаты с известными результатами. Затем корректируются коэффициенты алгоритма, чтобы попытаться смоделировать результаты.
Это может занять некоторое время, но если алгоритмы и сетевая архитектура будут выстроены корректно, система машинного обучения начнет давать результаты, которые соответствуют фактическим. По сути, нейронная сеть «изучила» или смоделировала взаимосвязь между данными и результатами. Затем эту модель можно использовать для оценки будущих данных.
Алгоритмы машинного анализа и обучения позволяют следить за информационными объектами (базами данных, приложениями и пр.) и строить профили нормального (без сбоев) функционирования системы. В случае каких-либо отклонений (аномалий), например, при увеличении времени отклика, «зависании» приложения или замедлении транзакций, система фиксирует данную ситуацию и отправляет уведомление об этом, что позволяет выстраивать превентивные политики, предупреждающие подобные аномалии.

DevOps — комбинация процессов разработки и эксплуатации ПО. Ее составляющие – процессы, люди и продукты.
Насколько сложно обучить такую систему, много ли для этого потребуется времени, усилий экспертов? По существу, никакого обучения не нужно – она обучается самостоятельно на наборах данных без помощи программирования и может прогнозировать взаимосвязи наборов данных. Это дает возможность устранить «человеческий фактор», тем самым ускорив работу системы за счет исключения ручных процессов (таких как выявление корреляции данных, зависимостей и пр.).
Система сама строит профили нормального функционирования объекта, а для дополнительной подстройки достаточно механизмов параметризации. Однако, хотя машинное обучение — очень мощный инструмент, он нуждается в накоплении данных. Со временем уменьшается число ложных срабатываний (false positive). Их число можно почти на порядок уменьшить и с помощью «тонкой настройки».
Механизмы настройки помогают сделать алгоритмы более точными, адаптировать их под конкретные потребности. Таким образом, со временем точность еще более возрастает благодаря накапливаемой статистике.
Синергия DevOps и машинного обучения (ML) открывает новые возможности предиктивной аналитики, IT Operations Analytics (ITOA), Algorithmic IT Operations (AIOps) и др.
Алгоритмические подходы нацелены на выявление аномалий, кластеризацию и корреляцию данных, прогнозирование. Они помогают найти ответы на множество вопросов. В чем причина проблемы? Как ее предотвратить? Нормальное это поведение или аномальное? Что можно в приложении улучшить? На что следует немедленно обратить внимание? Как сбалансировать нагрузку? Машинному обучению в DevOps можно найти множество сфер применения.
DevOps и ML: анализ сложных наборов данных, выявление зависимостей и шаблонов, предиктивная аналитика, операционная аналитика, искусственный интеллект и пр.
Машинное обучение позволяет задействовать большие массивы данных и помогает делать обоснованные выводы. Выявление статистически значимых аномалий дает возможность выявлять ненормальное поведение объектов инфраструктуры. Кроме того, машинное обучение дает возможность выявлять не только различные аномалии в процессах, но и неправомерные действия.
Распознавание и группирование записей, основанных на общих шаблонах, помогает сосредоточиться на важных данных и «отсечь» второстепенную информацию. Анализ записей, предшествующих ошибке и следующих за ней, повышает эффективность поиска первопричин проблем, постоянный мониторинг приложений для выявления проблем способствует их быстрому устранению при эксплуатации.
Идентификационные, пользовательские данные, данные ИБ, диагностические, транзакционные данные, метрики (приложений, хостов, виртуальных машин, контейнеров, серверов) — данные уровня пользователя, приложения, связующего слоя, уровня виртуализации и инфраструктуры — все они хорошо подходят для машинного обучения и имеют предсказуемый формат.
Независимо от того, покупаете ли вы коммерческое приложение или сами его создаете, есть несколько способов применения машинного обучения для совершенствования DevOps.
Конечная цель состоит в том, чтобы усовершенствовать измеряемым образом методы DevOps от концепции до развертывания и вывода из эксплуатации.

Системы машинного обучения способны обрабатывать разнообразные данные в реальном времени и давать ответ, который разработчики DevOps могут применять для усовершенствования процессов и лучшего понимания поведения приложения.
Результатом будет ускорение DevOps — комбинации процессов разработки и эксплуатации ПО. Вместо недель и месяцев они сокращаются до дней.
Цикл DevOps (идея, создание, выпуск продукта, измерение, сбор данных, изучение) требует ускорения.
«Человеческий фактор» значительно влияет и на процессы эксплуатации (Ops). На человека возлагается задача анализа данных из разных источников, их корреляции и интерпретации. При этом применяются разные инструментальные средства. Такая задача сложна, трудоемка и отнимает немало времени. Ее автоматизация не только ускоряет процесс, но и исключает разную интерпретацию данных. Вот почему так важно применение современных алгоритмов машинного обучения к данным DevOps.

Машинное обучение реализует единый интерфейс для разработчиков и специалистов по эксплуатации (Dev и Ops).
Корреляция пользовательских данных, данных транзакций и пр. – важнейший инструмент выявления аномалий в поведении различных программных компонентов. А прогнозирование крайне важно с точки зрения управления, мониторинга производительности приложений. Оно позволяет принять упреждающие меры, понять, на что нужно обратить внимание уже сейчас, а что произойдет завтра, или выяснить, как сбалансировать нагрузку.
Цикл поставки продукта должен быть простым, прозрачным и быстрым, однако в «точке пересечения» Dev и Ops нередко возникают конфликты.
Кроме того, система с механизмами машинного обучения позволяет устранить барьеры между разработчиками и службами эксплуатации (Dev и Ops). Благодаря диагностике производительности приложений разработчики получают доступ к ценным диагностическим данным.

Служба эксплуатации и команды разработки работают совместно, дополняя друг друга. Циклы выпуска укорачиваются и ускоряются, улучшается координация и обратная связь, сокращается время тестирования.
Внедрение Docker, микросервисов, облачных технологий и API-интерфейсов для развертывания приложений и обеспечения высокой надежности требует новых подходов. Поэтому важно использовать интеллектуальные инструменты, и поставщики инструментальных средств DevOps интегрируют в свои продукты интеллектуальные функции для дальнейшего упрощения и ускорения процессов разработки ПО.
Конечно, ML не заменит интеллекта, опыта, творчества и тяжелой работы. Но мы уже сегодня видим широкие возможности его применения и еще больший потенциал в будущем.
Результат предсказуем: разработчики не просматривают непосредственно сами данные, а устанавливают пороговые значения, то есть ищут исключения, а не занимаются аналитикой данных. Но даже с помощью современных аналитических инструментов вы должны знать, что искать.

Большая часть данных, создаваемых в процессах DevOps, связана с развертыванием приложений. Мониторинг приложения пополняет логи сервера, генерирует сообщения об ошибках, трассировку транзакций. Единственный разумный способ проанализировать эти данные и прийти к каким-то выводам в режиме реального времени — использование машинного обучения (ML).
В большинстве систем машинного обучения используются нейронные сети, которые представляют собой набор многоуровневых алгоритмов для обработки данных. Их обучают, вводя предыдущие данные с известным результатом. Приложение сравнивает алгоритмически полученные результаты с известными результатами. Затем корректируются коэффициенты алгоритма, чтобы попытаться смоделировать результаты.
Это может занять некоторое время, но если алгоритмы и сетевая архитектура будут выстроены корректно, система машинного обучения начнет давать результаты, которые соответствуют фактическим. По сути, нейронная сеть «изучила» или смоделировала взаимосвязь между данными и результатами. Затем эту модель можно использовать для оценки будущих данных.
ML в помощь DevOps
Алгоритмы машинного анализа и обучения позволяют следить за информационными объектами (базами данных, приложениями и пр.) и строить профили нормального (без сбоев) функционирования системы. В случае каких-либо отклонений (аномалий), например, при увеличении времени отклика, «зависании» приложения или замедлении транзакций, система фиксирует данную ситуацию и отправляет уведомление об этом, что позволяет выстраивать превентивные политики, предупреждающие подобные аномалии.
DevOps — комбинация процессов разработки и эксплуатации ПО. Ее составляющие – процессы, люди и продукты.
Насколько сложно обучить такую систему, много ли для этого потребуется времени, усилий экспертов? По существу, никакого обучения не нужно – она обучается самостоятельно на наборах данных без помощи программирования и может прогнозировать взаимосвязи наборов данных. Это дает возможность устранить «человеческий фактор», тем самым ускорив работу системы за счет исключения ручных процессов (таких как выявление корреляции данных, зависимостей и пр.).
Система сама строит профили нормального функционирования объекта, а для дополнительной подстройки достаточно механизмов параметризации. Однако, хотя машинное обучение — очень мощный инструмент, он нуждается в накоплении данных. Со временем уменьшается число ложных срабатываний (false positive). Их число можно почти на порядок уменьшить и с помощью «тонкой настройки».
Механизмы настройки помогают сделать алгоритмы более точными, адаптировать их под конкретные потребности. Таким образом, со временем точность еще более возрастает благодаря накапливаемой статистике.
Синергия DevOps и машинного обучения (ML) открывает новые возможности предиктивной аналитики, IT Operations Analytics (ITOA), Algorithmic IT Operations (AIOps) и др.
Алгоритмические подходы нацелены на выявление аномалий, кластеризацию и корреляцию данных, прогнозирование. Они помогают найти ответы на множество вопросов. В чем причина проблемы? Как ее предотвратить? Нормальное это поведение или аномальное? Что можно в приложении улучшить? На что следует немедленно обратить внимание? Как сбалансировать нагрузку? Машинному обучению в DevOps можно найти множество сфер применения.
| Область применения машинного обучения |
Пояснение |
|---|---|
| Отслеживание поставки приложений |
Данные по активности инструментов DevOps (например, Jira, Git, Jenkins, SonarQube, Puppet, Ansible и т.д.) обеспечивают прозрачность процесса поставки. Применение ML может выявить аномалии в этих данных — большие объемы кода, длительное время сборки, увеличение сроков выпуска и проверки кода, выявить многие «отклонения» в процессах разработки программного обеспечения, включая неэффективное использование ресурсов, частое переключение задач или замедление процесса. |
| Обеспечение качества приложения |
Анализируя результаты тестирования, ML может выявить новые ошибки и создать библиотеку тестовых шаблонов на основе такого обнаружения. Это помогает обеспечить всестороннее тестирование каждого релиза, повышая качество поставляемых приложений (QA). |
| Шаблоны поведения |
Шаблоны поведения пользователя могут быть такими же уникальными, как отпечатки пальцев. Применение поведения ML к Dev и Ops может помочь выявить аномалии, которые представляют собой вредоносную активность. Например, аномальные шаблоны доступа к важным репозиториям или пользователей, которые намеренно или случайно используют известные «плохие» шаблоны (например, с бэкдором), развертывание несанкционированного кода или кражу интеллектуальной собственности. |
| Управление эксплуатацией |
Анализ приложения в процессе эксплуатации — это та область, где машинное обучение действительно может проявить себя, поскольку приходится иметь дело с большими объемами данных, количеством пользователей, транзакций и т. д. Специалисты DevOps могут использовать ML для анализа поведения пользователей, использования ресурсов, пропускной способности транзакций и т.д. с целью последующего обнаружения «ненормальных» шаблонов (например, атак типа DDoS, утечек памяти и пр.). |
| Управление уведомлениями |
Простое и практичное использование ML заключается в управлении массовым потоком предупреждений (alarm) в эксплуатируемых системах. Это может быть связано с общим идентификатором транзакции, общим набором серверов или общей подсетью, либо причина более сложна и требует «обучения» систем с течением времени, чтобы распознавать «известные хорошие» и «известные плохие» предупреждения. Это позволяет фильтровать предупреждения. |
| Устранение неполадок и аналитика |
Это еще одна область, где отлично себя проявляют современные технологии машинного обучения. ML может автоматически обнаруживать и сортировать «известные проблемы» и даже некоторые неизвестные. Например, инструменты ML могут обнаруживать аномалии в «нормальной» обработке, а затем дополнительно анализировать журналы, чтобы соотнести эту проблему с новой конфигурацией или развертыванием. Другие средства автоматизации могут использовать ML для предупреждения операций, открытия тикета (или окна чата) и назначения его соответствующему ресурсу. Со временем ML сможет даже предложить лучшее решение. |
| Предотвращение сбоев в процессе эксплуатации |
ML позволяет выходить далеко за рамки простого планирования ресурсов для предотвращения сбоев. Оно может использоваться для прогнозирования, например, наилучшей конфигурации для достижения желаемого уровня производительности; числа клиентов, которые будут использовать новую функцию; требований к инфраструктуре и пр. ML выявляет «ранние признаки» в системах и приложениях, позволяя разработчикам начинать исправление или заранее избегать проблем. |
| Анализ влияния на бизнес |
Понимание влияния релиза кода на бизнес-цели имеет решающее значение для успеха в DevOps. Синтезируя и анализируя реальные показатели использования, системы ML могут обнаруживать хорошие и плохие модели для реализации «системы раннего предупреждения», когда у приложений возникают проблемы (например, посредством сообщения об увеличении частоты случаев отказа от покупательской корзины или увеличении «маршрута» покупателя). |
DevOps и ML: анализ сложных наборов данных, выявление зависимостей и шаблонов, предиктивная аналитика, операционная аналитика, искусственный интеллект и пр.
Машинное обучение позволяет задействовать большие массивы данных и помогает делать обоснованные выводы. Выявление статистически значимых аномалий дает возможность выявлять ненормальное поведение объектов инфраструктуры. Кроме того, машинное обучение дает возможность выявлять не только различные аномалии в процессах, но и неправомерные действия.
Распознавание и группирование записей, основанных на общих шаблонах, помогает сосредоточиться на важных данных и «отсечь» второстепенную информацию. Анализ записей, предшествующих ошибке и следующих за ней, повышает эффективность поиска первопричин проблем, постоянный мониторинг приложений для выявления проблем способствует их быстрому устранению при эксплуатации.
Идентификационные, пользовательские данные, данные ИБ, диагностические, транзакционные данные, метрики (приложений, хостов, виртуальных машин, контейнеров, серверов) — данные уровня пользователя, приложения, связующего слоя, уровня виртуализации и инфраструктуры — все они хорошо подходят для машинного обучения и имеют предсказуемый формат.
Усовершенствование DevOps
Независимо от того, покупаете ли вы коммерческое приложение или сами его создаете, есть несколько способов применения машинного обучения для совершенствования DevOps.
| Способ |
Что он означает |
|---|---|
| От пороговых значений к аналитике данных |
Поскольку данных очень много, разработчики DevOps редко просматривают и анализируют весь набор данных. Вместо этого они устанавливают пороговые значения — условие для каких-то действий. Фактически они отбрасывают большую часть собираемых данных и фокусируются на отклонениях. Приложения машинного обучения способны на большее. Их можно обучать по всем данным, и в рабочем режиме эти приложения могут просматривать весь поток данных и делать выводы. Это поможет применять предиктивную аналитику. |
| Поиск тенденций, а не ошибок |
Из вышеизложенного следует, что при обучении по всем данным система машинного обучения может показывать не только выявленные проблемы. Анализируя тенденции данных, специалисты DevOps могут выявлять, что будет происходить с течением времени, то есть делать прогнозы. |
| Анализ и корреляция наборов данных |
Значительная часть данных — это временные ряды, и одну переменную проследить нетрудно. Но многие тенденции — это следствие взаимодействия нескольких факторов. Например, время отклика может снизиться, когда несколько транзакций одновременно выполняют одно и то же действие. Подобные тенденции практически невозможно обнаружить «невооруженным глазом» или с помощью традиционной аналитики. Но надлежащим образом обученные приложения учтут эти корреляции и тенденции. |
| Новые метрики разработки |
По всей вероятности, вы собираете данные по скорости поставки, показатели поиска и исправления ошибок, плюс данные, полученные из системы непрерывной интеграции. Возможности для поиска любой комбинации данных огромны. |
| Исторический контекст данных |
Одна из самых больших проблем в DevOps в том, чтобы учиться на собственных ошибках. Даже если и есть стратегия постоянной обратной связи, то, скорее всего, это что-то типа вики, где описываются проблемы, с которыми мы столкнулись, и что мы сделали, чтобы исследовать их. Распространенное решение проблемы – перезагрузка сервера или перезапуск приложения. Системы машинного обучения могут анализировать данные и четко показывать, что произошло за последний день, неделю, месяц или год. Можно видеть сезонные или ежедневные тенденции. Они будут в любой момент давать нам картину нашего приложения. |
| Поиск первопричин |
Эта функция важна для повышения качества приложений и позволяет разработчикам устранять проблемы доступности или производительности. Часто сбои и другие проблемы, расследуют не полностью, потому что оперативно решают задачу восстановления работоспособности приложения. Подчас перезагрузка восстанавливает работу, но основная причина проблемы теряется. |
| Корреляция между инструментами мониторинга |
В DevOps для просмотра и обработки данных нередко используют несколько инструментов. Каждый из них контролирует работоспособность и производительность приложения по-разному, но не хватает способности находить взаимосвязи между этими данными разных инструментов. Системы машинного обучения могут собирать все эти разрозненные потоки данных, использовать их в качестве исходных данных и создавать более точную и надежную картину состояния приложения. |
| Эффективность оркестрации |
При наличии метрик процесса оркестрации машинное обучение можно использовать, чтобы определить, насколько эффективно эта оркестрация выполняется. Неэффективность может быть результатом неверных методов или плохой оркестрации, поэтому изучение этих характеристик может помочь как в выборе инструментов, так и в организации процессов. |
| Предсказание сбоя в определенный момент времени |
Если вы знаете, что системы мониторинга дают во время сбоя определенные показания, то приложение машинного обучения может искать эти шаблоны как предпосылку к конкретному типу сбоя. Если вы понимаете причину этого сбоя, то можете принять меры, чтобы избежать его. |
| Оптимизация конкретной метрики |
Хотите увеличить время безотказной работы? Поддерживать стандарт производительности? Сократить время между развертываниями? Может помочь адаптивная система машинного обучения. Адаптивные системы – системы без конкретного ответа или результата. Их целью является получение входных данных и оптимизация определенной характеристики. Например, системы продажи авиабилетов пытаются заполнить самолеты и оптимизировать доходы, изменяя цены билетов до трех раз в день. Можно аналогичным образом оптимизировать процессы DevOps. Нейронную сеть обучают так, чтобы максимизировать (или минимизировать) значение, а не достигать известного результата. Это позволяет системе изменять свои параметры во время работы, чтобы постепенно достигать наилучшего результата. |
Конечная цель состоит в том, чтобы усовершенствовать измеряемым образом методы DevOps от концепции до развертывания и вывода из эксплуатации.

Системы машинного обучения способны обрабатывать разнообразные данные в реальном времени и давать ответ, который разработчики DevOps могут применять для усовершенствования процессов и лучшего понимания поведения приложения.
Ускорение процессов
Результатом будет ускорение DevOps — комбинации процессов разработки и эксплуатации ПО. Вместо недель и месяцев они сокращаются до дней.
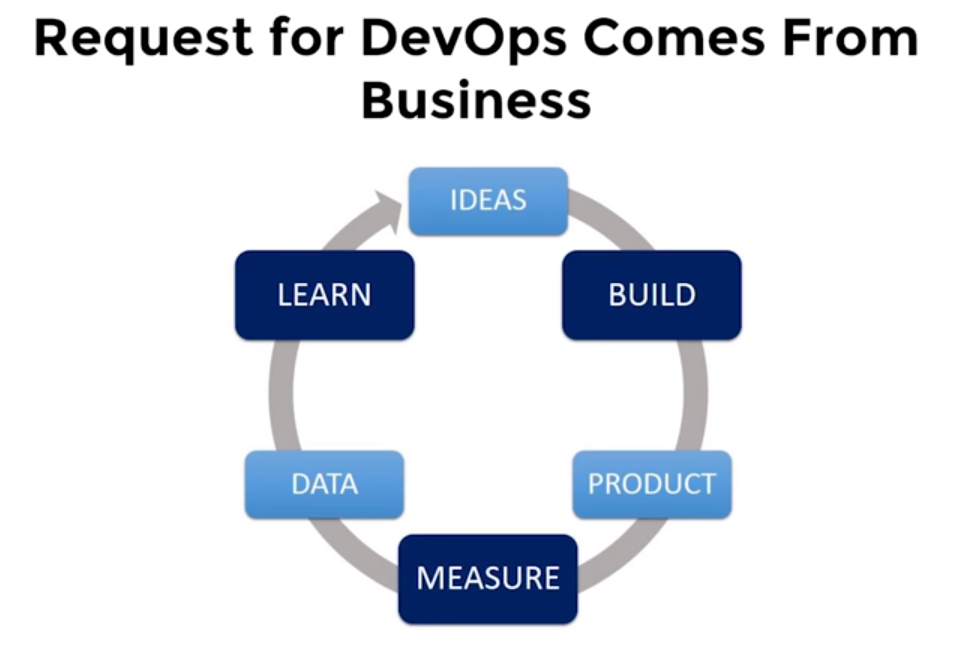
Цикл DevOps (идея, создание, выпуск продукта, измерение, сбор данных, изучение) требует ускорения.
«Человеческий фактор» значительно влияет и на процессы эксплуатации (Ops). На человека возлагается задача анализа данных из разных источников, их корреляции и интерпретации. При этом применяются разные инструментальные средства. Такая задача сложна, трудоемка и отнимает немало времени. Ее автоматизация не только ускоряет процесс, но и исключает разную интерпретацию данных. Вот почему так важно применение современных алгоритмов машинного обучения к данным DevOps.

Машинное обучение реализует единый интерфейс для разработчиков и специалистов по эксплуатации (Dev и Ops).
Корреляция пользовательских данных, данных транзакций и пр. – важнейший инструмент выявления аномалий в поведении различных программных компонентов. А прогнозирование крайне важно с точки зрения управления, мониторинга производительности приложений. Оно позволяет принять упреждающие меры, понять, на что нужно обратить внимание уже сейчас, а что произойдет завтра, или выяснить, как сбалансировать нагрузку.
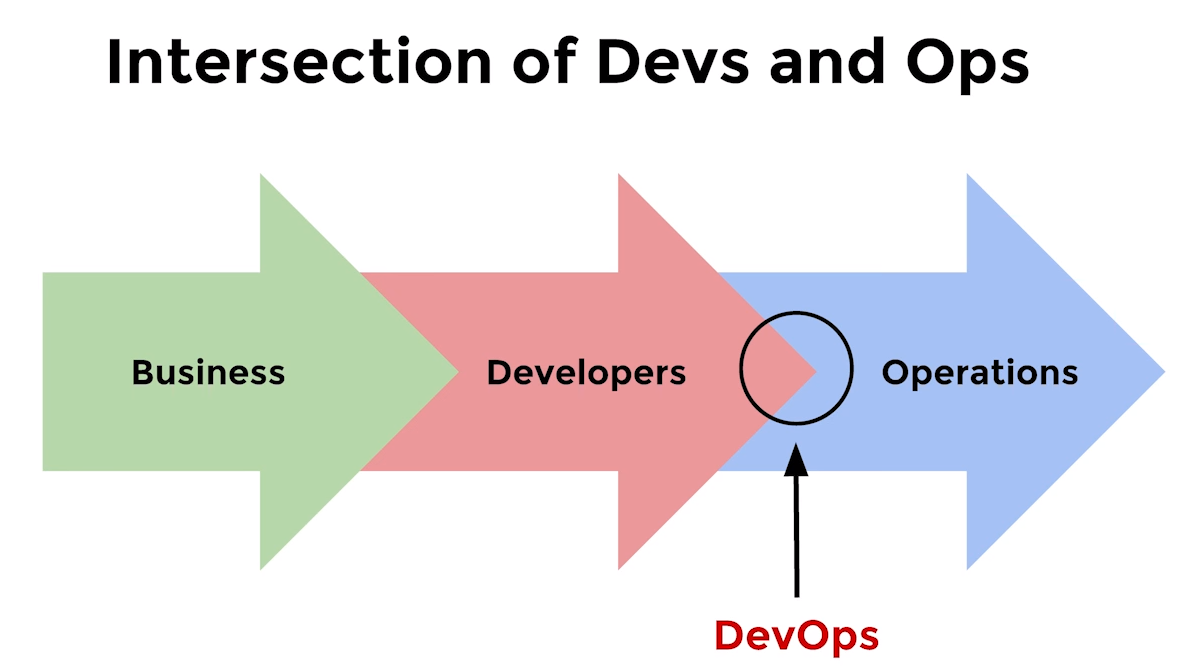
Цикл поставки продукта должен быть простым, прозрачным и быстрым, однако в «точке пересечения» Dev и Ops нередко возникают конфликты.
Кроме того, система с механизмами машинного обучения позволяет устранить барьеры между разработчиками и службами эксплуатации (Dev и Ops). Благодаря диагностике производительности приложений разработчики получают доступ к ценным диагностическим данным.
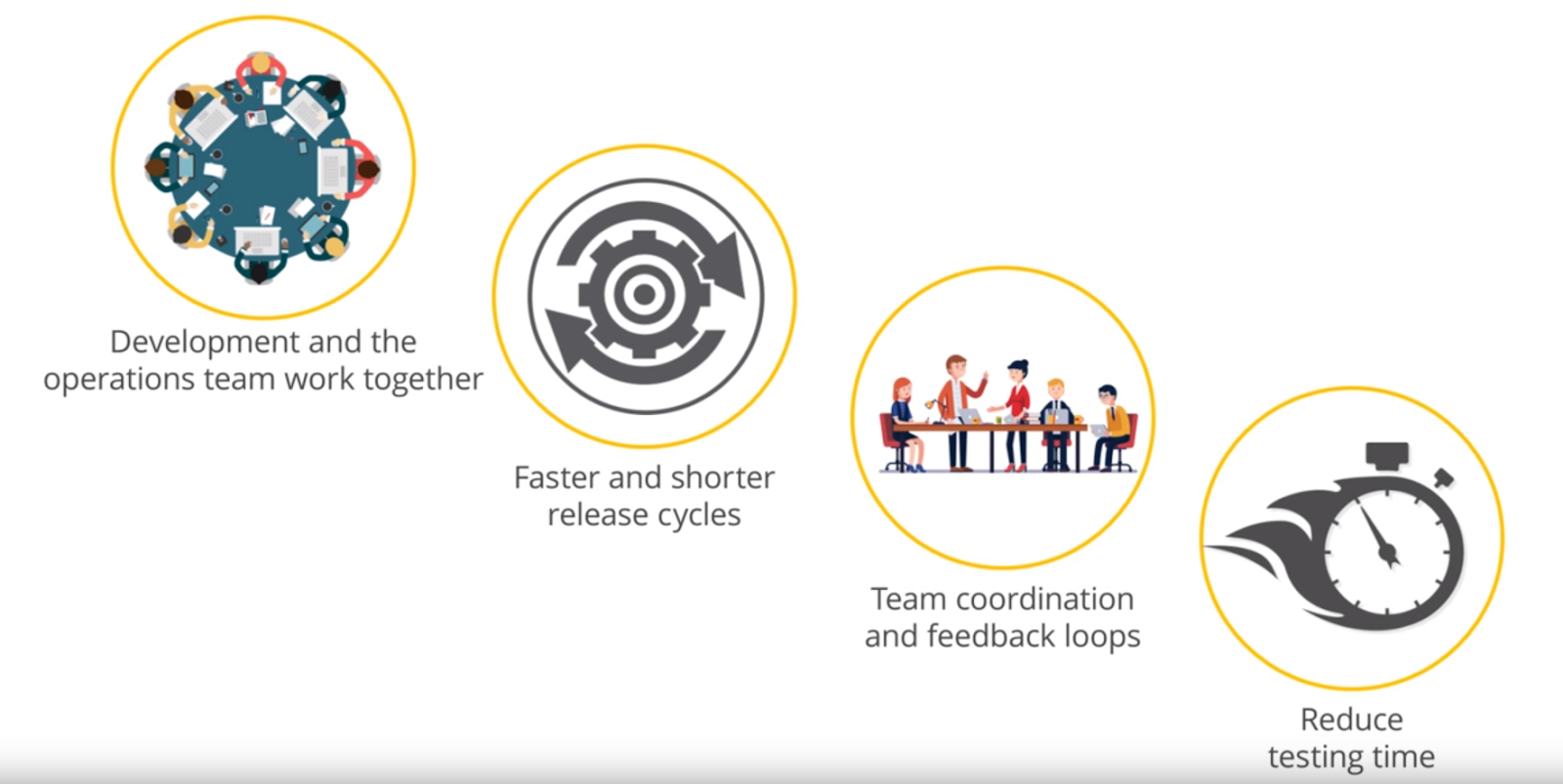
Служба эксплуатации и команды разработки работают совместно, дополняя друг друга. Циклы выпуска укорачиваются и ускоряются, улучшается координация и обратная связь, сокращается время тестирования.
Внедрение Docker, микросервисов, облачных технологий и API-интерфейсов для развертывания приложений и обеспечения высокой надежности требует новых подходов. Поэтому важно использовать интеллектуальные инструменты, и поставщики инструментальных средств DevOps интегрируют в свои продукты интеллектуальные функции для дальнейшего упрощения и ускорения процессов разработки ПО.
Конечно, ML не заменит интеллекта, опыта, творчества и тяжелой работы. Но мы уже сегодня видим широкие возможности его применения и еще больший потенциал в будущем.
