Начну издалека. Прошлой зимой довелось мне делать USB-устройство с ядром, размещаемым в ПЛИС. Само собой, очень мне хотелось проверить реальную пропускную способность этой шины. Ведь в контроллере — там слишком много всего наверчено. Всегда можно сказать, что вот тут внесена задержка, или вон там. В случае же с ПЛИС — я вижу блок, прокачивающий данные, вот он сказал мне, что в нём данные есть. А вот я выставил, что всё обработано, и я готов принимать новую порцию (при этом, он уже принимает данные во второй буфер этой же конечной точки). Отлично, ставим готовность с первого же такта и смотрим, что получается, когда USB может «молотить» без остановки.

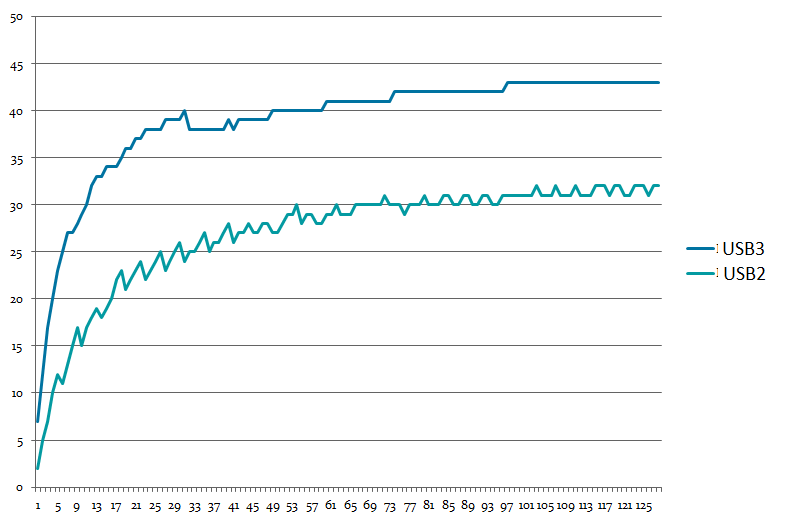
А получается удивительная вещь. Если USB 2.0 устройство воткнуто в «голубенький» разъём (это который USB 3.0), то скорость получается одна. Если в «чёрненький» — другая. Вот мой график зависимости скорости записи в USB от длины передаваемых данных. USB3 и USB2 — это тип разъёма, устройство всегда USB 2.0 HS.

Я пробовал в разных машинах. Результат — близок. Никто не мог объяснить мне этот феномен. Уже потом я нашёл наиболее вероятную причину. А причина очень проста. Вот свойства контроллера USB 2.0:
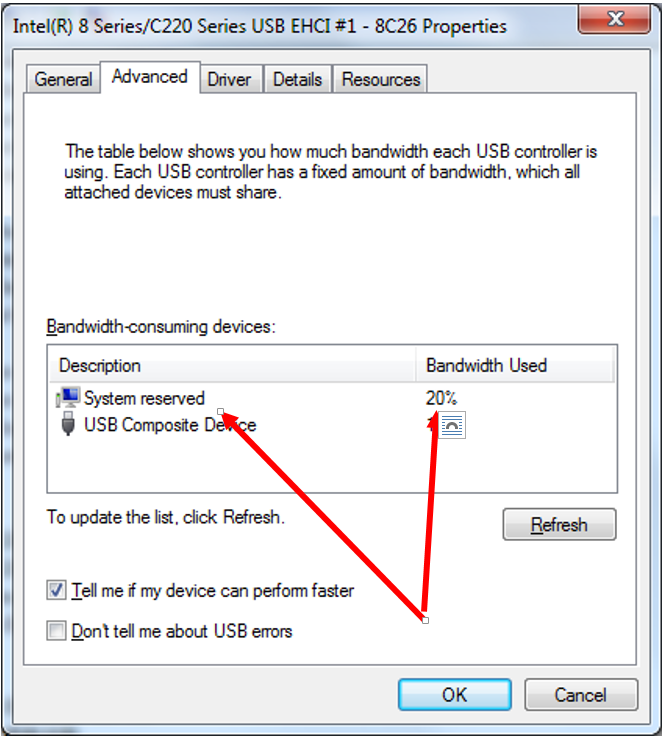
У контроллеров, управляющих «голубеньким» разъёмом такого нет. А разница — как раз примерно процентов 20.
Из этого мы делаем вывод, что не всегда ограничения пропускной способности определяются физическими свойствами шины. Иногда накладываются ещё какие-то вещи. Переходим с этими знаниями в наши дни.
Итак. Всё начиналось весьма буднично. Шла проверка одной программы. Проверялся процесс записи данных одновременно на несколько дисков. Аппаратура простая: имеется материнская плата с четырьмя PCIe-слотами. Во все слоты воткнуты совершенно одинаковые карточки с AHCI-контроллерами, каждый из которых поддерживает исключительно PCIe x1.

Каждая карта обслуживает 4 накопителя.
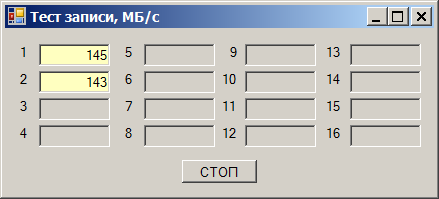
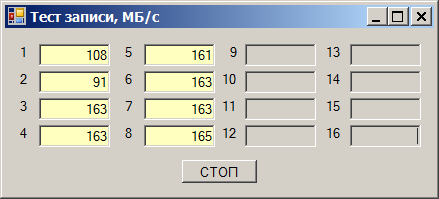
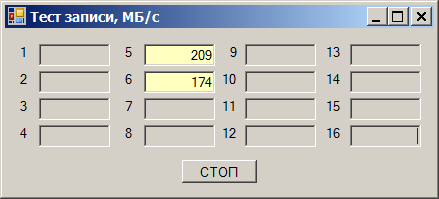
И вот выясняется следующий эффект. Берём один диск и начинаем записывать на него данные. Получаем скорость от 180 до 220 мегабайт в секунду (здесь и далее, мегабайт — это 1024*1024 байт):

Берём второй накопитель. Скорость записи на него — от 170 до 190 МБ/с:

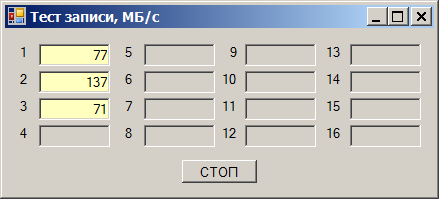
Пишем сразу на оба — получаем просадку скорости:
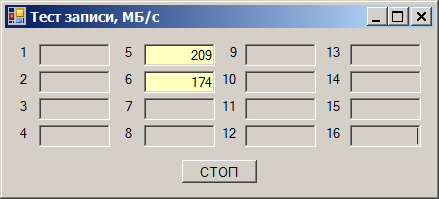
Суммарная скорость получается в районе 290 МБ/с. Но удивительность состоит в том, что отлаживали (так получилось) эту программу мы на тех же накопителях, но на других каналах. И там всё было хорошо. Быстро перетыкаем в те каналы (они будут идти через другую карту), получаем прекрасную работу:
Сразу скажу, что винить во всём какие-то чужие компоненты не стоит. Здесь всё написано нами, начиная от самой программы, заканчивая драйверами. Так что весь путь прохождения данных может быть проконтролирован. Неизвестность наступает только когда запрос ушёл в аппаратуру.
После первичного разбора выяснилось, что скорость не ограничивается в «длинных» слотах PCIe и ограничивается в «коротких». Длинные — это куда можно вставить карты x16 (правда, один из них работает в режиме не выше x4), а короткие — только для карт x1.

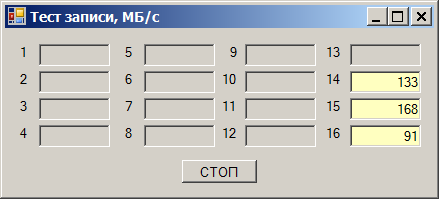
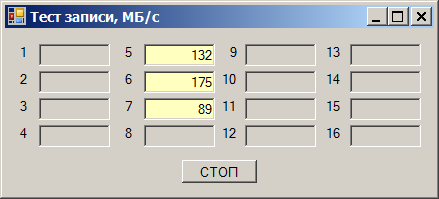
Всё бы ничего, но контроллеры в текущих картах в принципе не могут работать в режиме, отличном от PCIex1. То есть, все контроллеры должны быть в абсолютно идентичных условиях, независимо от длины слота! Ан нет. Кто живёт в «длинном» — работает быстро, кто в «коротком» — медленно. Хорошо. А быстро — насколько быстро? Добавляем третий накопитель, пишем на все три.
В «коротких» слотах ограничение всё ещё в районе 290 МБ/с:
В «длинных» — в районе 400 МБ/с:

Я перерыл весь Интернет. Во-первых, через некоторое время я уже смеялся со статей, где говорится о том, что пропускная способность PCIe gen 1 и gen 2 для x1 составляет 250 и 500 МБ/с. Это «сырые» мегабайты. За счёт оверхеда (я использую это нерусское слово, чтобы обозначить служебный обмен, идущий по тем же линиям, что и основные данные) для gen 2 получается именно 400 мегабайт в секунду полезного потока. Во-вторых, я упорно не мог найти ничего про магическую цифру 290 (забегая вперёд — до сих пор не нашёл).
Отлично. Пытаемся глянуть на топологию включения наших контроллеров. Вот она (013-015 — это суффиксы имён устройств, по которым я сопоставил их, чтобы как-то различать). Зелёные —быстрые, красные — медленные.
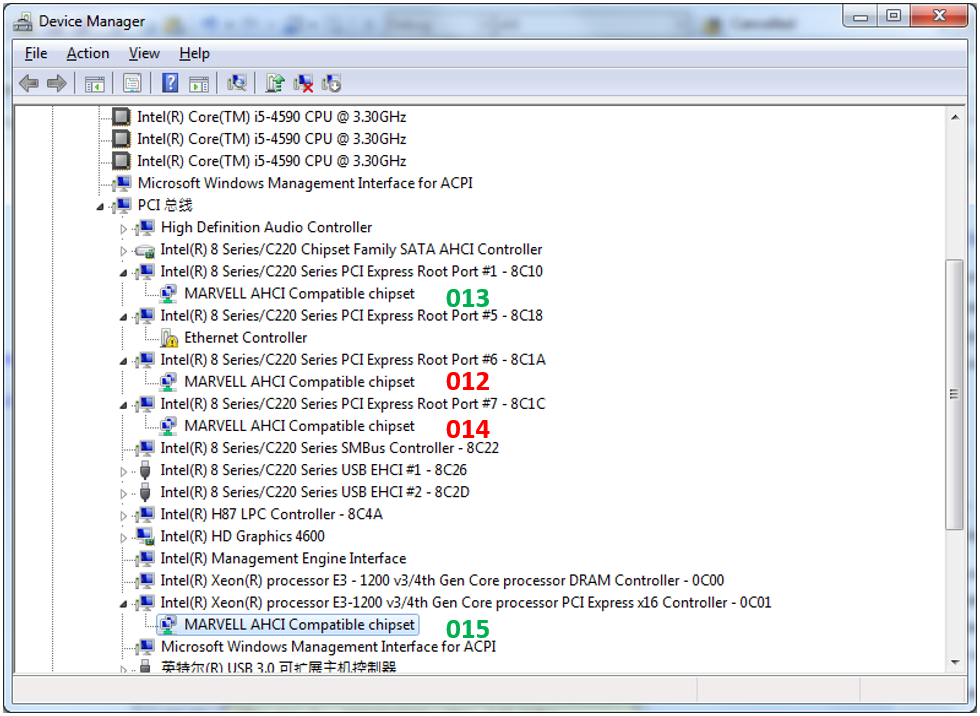
Контроллер «015» мы даже не рассматриваем. Он живёт в привилегированном слоте, предназначенном для видеокарты. Но 013-й подключён к тому же коммутатору, что и 012-й с 014-м. Чем он отличается?
Отдельные статьи говорят, что разные карты могут отличаться параметрами Max Payload. Я изучил конфигурационное пространство всех карт — этот параметр стоит у всех в одном и том же, минимально возможном значении. Мало того, в документации на чипсет этой материнки сказано, что иного значения и быть не может.
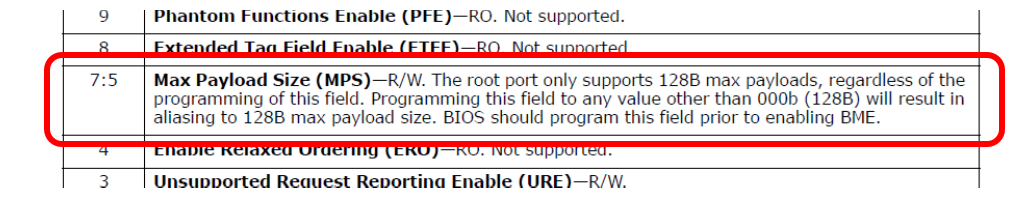
В общем, я перерыл всё в конфигурационном пространстве — всё настроено идентично. А скорость разная! Многократно перечитал документацию на чипсет — никаких настроек пропускной способности. Приоритеты — да, что-то про них написано, но тесты же ведутся при полном отсутствии нагрузки по другим каналам! То есть дело не в них.
На всякий случай, я даже отключил работу программы по прерываниям. Нагрузка на процессор возросла до безумных величин, ведь теперь он постоянно тупо читает бит готовности, но показания скорости не изменились. Так что обвинить в проблемах эту подсистему тоже нельзя.
Попробовали поменять материнскую плату на точно такую же. Никаких изменений. Попробовали заменить процессор (были основания считать, что он барахлит). Тоже никаких изменений скорости (но старый процессор и правда барахлил). Поставили материнскую плату более нового поколения — всё просто летает на всех слотах. Причём предельная скорость уже не 400, а 418 мегабайт в секунду, хоть в «длинных», хоть в «коротких» слотах:
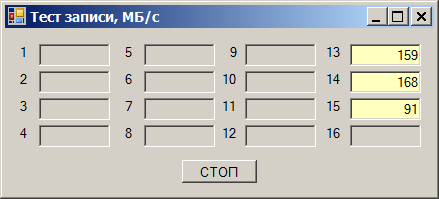
Но здесь — никаких чудес. Привычным движением руки (за эти дни уже привык) считываем конфигурационное пространство и видим, что параметр Max Payload установлен не на 128, а на 256 байт.
Больше размер пакета — меньше количество пакетов. Меньше оверхед на их пересылку — больше полезных данных успевает пробежать за то же время. Всё верно.
Точного ответа на вопрос из заголовка, со ссылкой на документы, я не дам. Но мысль моя пошла по следующему пути: допустим, что ограничение потока задано внутри чипсета. Его нельзя программировать, оно задано намертво, но оно есть. Например, оно равно 290 мегабайт в секунду на каждую дифф. пару. Больше — режется уже где-то внутри чипсета на его внутренних механизмах. Поэтому в «длинном» слоте (куда можно воткнуть карты вплоть до x4) внутри чипсета для нашей карты ничего не режется, а мы упираемся в физический предел шины x1. В «коротком» же разъёме мы упираемся в это ограничение.
На самом деле, проверить это не просто, а очень просто. Втыкаем в 013-й слот не AHCI, а SAS-контроллер, который обслуживает сразу 8 накопителей и может работать в режимах PCIe вплоть до x4. Подключаем ему 4 шустрых SSD накопителя. Смотрим скорость записи — аж душа радуется:

Теперь добавляем те 4 диска, которые фигурировали в первых тестах. Скорость работы SSD предсказуемо просела:
Вычисляем суммарную скорость, проходящую через SAS-контроллер, получаем 1175 мегабайт в секунду. Делим на 4 (столько линий идёт в «длинный» слот), получаем… Барабанная дробь… 293 мегабайта в секунду. Где-то я это число уже видел!
Итак, в рамках данного проекта было доказано, что дело не в нашей программе или драйвере, а в странных ограничениях чипсета, которые наверняка «зашиты» намертво. Была выведена методика подбора материнских плат, которые могут быть использованы в проекте. А в целом, выводы делаем следующие.
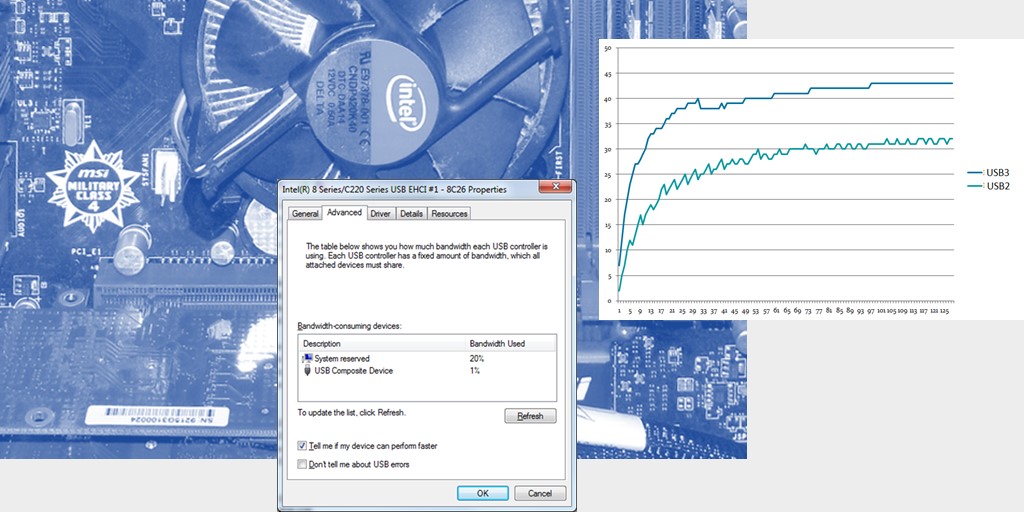
А получается удивительная вещь. Если USB 2.0 устройство воткнуто в «голубенький» разъём (это который USB 3.0), то скорость получается одна. Если в «чёрненький» — другая. Вот мой график зависимости скорости записи в USB от длины передаваемых данных. USB3 и USB2 — это тип разъёма, устройство всегда USB 2.0 HS.
Я пробовал в разных машинах. Результат — близок. Никто не мог объяснить мне этот феномен. Уже потом я нашёл наиболее вероятную причину. А причина очень проста. Вот свойства контроллера USB 2.0:

У контроллеров, управляющих «голубеньким» разъёмом такого нет. А разница — как раз примерно процентов 20.
Из этого мы делаем вывод, что не всегда ограничения пропускной способности определяются физическими свойствами шины. Иногда накладываются ещё какие-то вещи. Переходим с этими знаниями в наши дни.
Первичный эксперимент
Итак. Всё начиналось весьма буднично. Шла проверка одной программы. Проверялся процесс записи данных одновременно на несколько дисков. Аппаратура простая: имеется материнская плата с четырьмя PCIe-слотами. Во все слоты воткнуты совершенно одинаковые карточки с AHCI-контроллерами, каждый из которых поддерживает исключительно PCIe x1.

Каждая карта обслуживает 4 накопителя.
И вот выясняется следующий эффект. Берём один диск и начинаем записывать на него данные. Получаем скорость от 180 до 220 мегабайт в секунду (здесь и далее, мегабайт — это 1024*1024 байт):

Берём второй накопитель. Скорость записи на него — от 170 до 190 МБ/с:

Пишем сразу на оба — получаем просадку скорости:
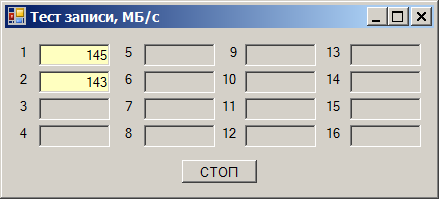
Суммарная скорость получается в районе 290 МБ/с. Но удивительность состоит в том, что отлаживали (так получилось) эту программу мы на тех же накопителях, но на других каналах. И там всё было хорошо. Быстро перетыкаем в те каналы (они будут идти через другую карту), получаем прекрасную работу:
Куплю слот в хорошем районе
Сразу скажу, что винить во всём какие-то чужие компоненты не стоит. Здесь всё написано нами, начиная от самой программы, заканчивая драйверами. Так что весь путь прохождения данных может быть проконтролирован. Неизвестность наступает только когда запрос ушёл в аппаратуру.
После первичного разбора выяснилось, что скорость не ограничивается в «длинных» слотах PCIe и ограничивается в «коротких». Длинные — это куда можно вставить карты x16 (правда, один из них работает в режиме не выше x4), а короткие — только для карт x1.

Всё бы ничего, но контроллеры в текущих картах в принципе не могут работать в режиме, отличном от PCIex1. То есть, все контроллеры должны быть в абсолютно идентичных условиях, независимо от длины слота! Ан нет. Кто живёт в «длинном» — работает быстро, кто в «коротком» — медленно. Хорошо. А быстро — насколько быстро? Добавляем третий накопитель, пишем на все три.
В «коротких» слотах ограничение всё ещё в районе 290 МБ/с:

В «длинных» — в районе 400 МБ/с:

Я перерыл весь Интернет. Во-первых, через некоторое время я уже смеялся со статей, где говорится о том, что пропускная способность PCIe gen 1 и gen 2 для x1 составляет 250 и 500 МБ/с. Это «сырые» мегабайты. За счёт оверхеда (я использую это нерусское слово, чтобы обозначить служебный обмен, идущий по тем же линиям, что и основные данные) для gen 2 получается именно 400 мегабайт в секунду полезного потока. Во-вторых, я упорно не мог найти ничего про магическую цифру 290 (забегая вперёд — до сих пор не нашёл).
Отлично. Пытаемся глянуть на топологию включения наших контроллеров. Вот она (013-015 — это суффиксы имён устройств, по которым я сопоставил их, чтобы как-то различать). Зелёные —быстрые, красные — медленные.
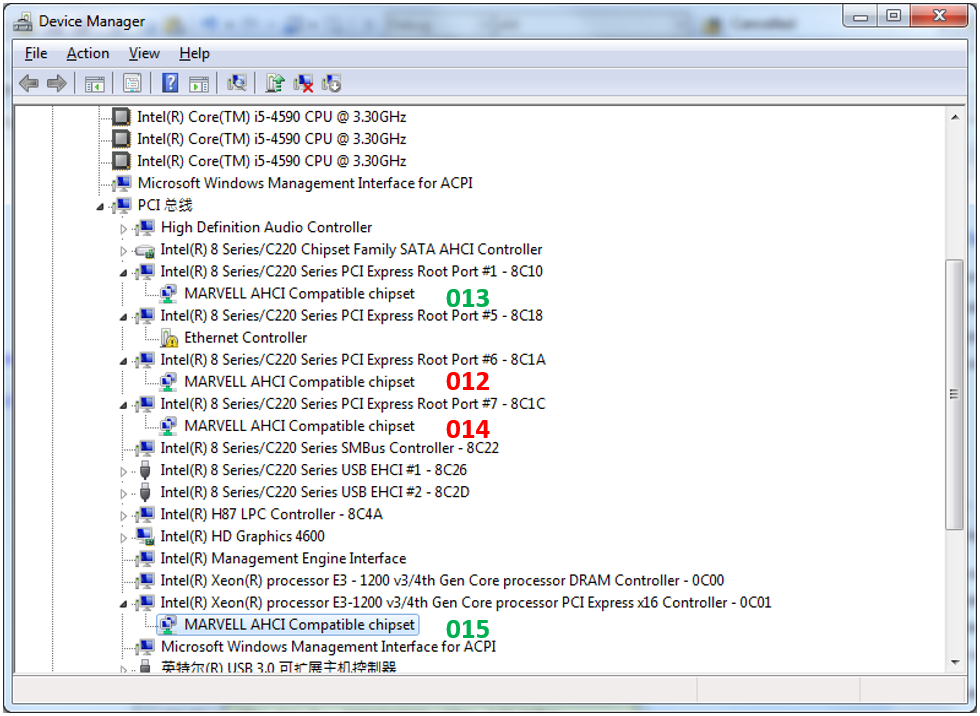
Контроллер «015» мы даже не рассматриваем. Он живёт в привилегированном слоте, предназначенном для видеокарты. Но 013-й подключён к тому же коммутатору, что и 012-й с 014-м. Чем он отличается?
Отдельные статьи говорят, что разные карты могут отличаться параметрами Max Payload. Я изучил конфигурационное пространство всех карт — этот параметр стоит у всех в одном и том же, минимально возможном значении. Мало того, в документации на чипсет этой материнки сказано, что иного значения и быть не может.

В общем, я перерыл всё в конфигурационном пространстве — всё настроено идентично. А скорость разная! Многократно перечитал документацию на чипсет — никаких настроек пропускной способности. Приоритеты — да, что-то про них написано, но тесты же ведутся при полном отсутствии нагрузки по другим каналам! То есть дело не в них.
На всякий случай, я даже отключил работу программы по прерываниям. Нагрузка на процессор возросла до безумных величин, ведь теперь он постоянно тупо читает бит готовности, но показания скорости не изменились. Так что обвинить в проблемах эту подсистему тоже нельзя.
А что там у других плат?
Попробовали поменять материнскую плату на точно такую же. Никаких изменений. Попробовали заменить процессор (были основания считать, что он барахлит). Тоже никаких изменений скорости (но старый процессор и правда барахлил). Поставили материнскую плату более нового поколения — всё просто летает на всех слотах. Причём предельная скорость уже не 400, а 418 мегабайт в секунду, хоть в «длинных», хоть в «коротких» слотах:

Но здесь — никаких чудес. Привычным движением руки (за эти дни уже привык) считываем конфигурационное пространство и видим, что параметр Max Payload установлен не на 128, а на 256 байт.
Больше размер пакета — меньше количество пакетов. Меньше оверхед на их пересылку — больше полезных данных успевает пробежать за то же время. Всё верно.
Так кто же виноват?
Точного ответа на вопрос из заголовка, со ссылкой на документы, я не дам. Но мысль моя пошла по следующему пути: допустим, что ограничение потока задано внутри чипсета. Его нельзя программировать, оно задано намертво, но оно есть. Например, оно равно 290 мегабайт в секунду на каждую дифф. пару. Больше — режется уже где-то внутри чипсета на его внутренних механизмах. Поэтому в «длинном» слоте (куда можно воткнуть карты вплоть до x4) внутри чипсета для нашей карты ничего не режется, а мы упираемся в физический предел шины x1. В «коротком» же разъёме мы упираемся в это ограничение.
На самом деле, проверить это не просто, а очень просто. Втыкаем в 013-й слот не AHCI, а SAS-контроллер, который обслуживает сразу 8 накопителей и может работать в режимах PCIe вплоть до x4. Подключаем ему 4 шустрых SSD накопителя. Смотрим скорость записи — аж душа радуется:

Теперь добавляем те 4 диска, которые фигурировали в первых тестах. Скорость работы SSD предсказуемо просела:

Вычисляем суммарную скорость, проходящую через SAS-контроллер, получаем 1175 мегабайт в секунду. Делим на 4 (столько линий идёт в «длинный» слот), получаем… Барабанная дробь… 293 мегабайта в секунду. Где-то я это число уже видел!
Итак, в рамках данного проекта было доказано, что дело не в нашей программе или драйвере, а в странных ограничениях чипсета, которые наверняка «зашиты» намертво. Была выведена методика подбора материнских плат, которые могут быть использованы в проекте. А в целом, выводы делаем следующие.
Заключение
- Зачастую в реальной жизни аппаратура имеет меньшую производительность, чем теоретически возможная. Ограничения могут накладываться даже драйверами, как показано в случае USB. Иногда удаётся подобрать такую аппаратуру, которая (или драйверы которой) не имеет таких ограничений.
- Ограничения могут быть даже недокументированными, но чётко выраженными.
- Масса статей, в которых говорится, что одна дифференциальная пара PCIe gen. 1 и gen 2 даёт примерно 250 и 500 мегабайт в секунду, ошибочны. Они копируют друг у друга одну и ту же ошибку — мегабайт «сырых» данных в секунду. Оверхед накапливается на нескольких уровнях интерфейса. При Max Payload 128 байт, на PCIe gen2 реально получается около 400 мегабайт в секунду. В более новых поколениях PCIe всё должно быть чуть лучше, так как там физическое кодирование не 8b/10b, а более экономичное, но пока не найдено ни одного контроллера дисков, на которых можно было бы проверить это на практике.
