Сегодня я опишу еще несколько свойств прогнозирования временных рядов.
А именно цикличность и усложнение варианта с подобием отрезков.

Вернемся к графику из предыдущей статьи. Тот график очень периодический (см. картинку дальше), и правильным будет его сначала прогнозировать расчетом цикличностей. От использования одного только расчета цикличности у меня получился прогноз 4.1% ошибки (mape) вместо 5% для прежней экспериментальной точки.
После расчета цикличностей, делаем вычитание из исходных значений графика, значений прогноза от цикличностей, и получившийся график ошибки уже пытаемся прогнозировать корреляциями. В результате для той же точки получил уже 3.7% ошибки.
Программа и ее исходники текущей версии здесь. Теперь она больше похожа на самостоятельную утилиту прогнозирования рядов, чем на тестирование одного метода и одного графика. И может выполнять прогноз для последней точки, для которой отсутствует фактическое прогнозируемое значение.
ape — Absolute percentage error — abs(forecast-fact)/fact
mape — Mean absolute percentage error
Если взять несколько ape за период и посчитать арифметическое среднее значение, то получим mape.
Сам по себе процент ошибки прогноза для неизвестного графика мало что говорит. Потому что не известно на сколько график обычно меняется, и соответственно много ли это спрогнозировали или мало. Удобно брать для сравнения mape от прогноза, который делается из предположения, что следущее значение будет таким же как последнее известное.
Для экспериментальной точки это значение 9.2%. Напомню, что там цифры приводились как прогноз на сутки вперед. Т.е. колебания графика за сутки составляет 9.2%. В результате применения прогнозирования эта ошибка сократилась до 3.7%.
Вот так вот выглядит исследуемый график за несколько дней, с сильными суточными колебаниями:
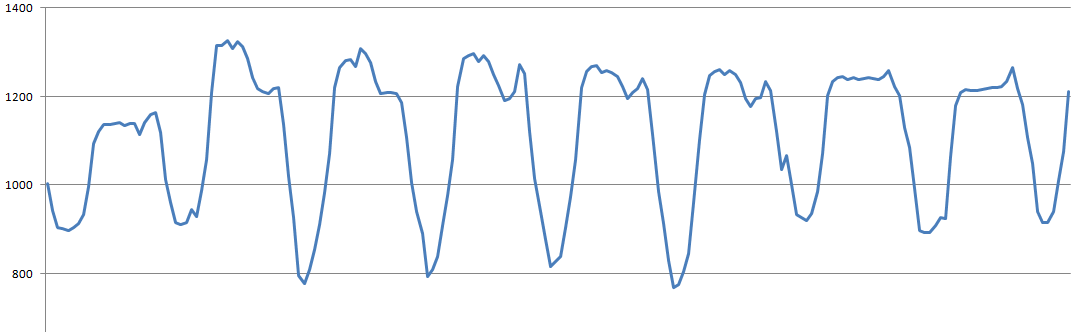
Очевидно, что если такой график пытать корреляциями, то корреляция будет видеть в основном дневные колебания, а все более мелкие нюансы будут утопать.
Вот так вот выглядит прогноз на сутки вперед:

Красным отображен фактический график, синим прогноз, зеленым граница трех стандартных отклонений прогноза от центра — если бы колебания графика имели бы стандартное распределение, то это было бы 99% вероятного коридора графика.
Для того, что бы осуществлять прогноз по цикличностям, был организован класс Cicling в файлах cicling.h и cicling.cpp. Объект данного класса накапливает N элементов средних, количество которых соответствуют длине цикла. Средние накапливаются по подстраивающейся формуле, их называют скользящими средними.
В моей интерпретации, эта формула имеет длину подстраивания, что удобней чем если просто безликий коэффициент. Данный механизм содержится в компактном классе MeanAdapt в файле dispersion.h и dispersion.cpp.
В среднем суть механизма такова:
В том классе есть еще усложнение с отрицательно интерпретацией cnt_adapt, если интересно смотрите исходники.
В общем, в классе Cicling есть N элементов подстраивающихся средних, среди них есть текущий элемент, в который добавляется очередное значение, и указатель сдвигается на следующий элемент средних. При достижении последнего элемента, указатель перемещается на начало. И так по кругу. Точнее в классе сделано просто ar_means[cnt_values % size_cicling], где cnt_values — количество добавленных значений.
Прежде чем добавить в текущий элемент средних новое значение, из нового значения делается вычитание текущего среднего значения, тем самым формируется значение ошибки. Класс Cicling может рекурсивно содержать следующий уровень цикличности Cicling* ne_level, если это так, то ошибка текущего уровня передается дальше для суммирования следующих цикличностей, иначе ошибка возвращается. Для текущего графика основные цикличности это суточная — 24 часа и недельная — 168 часов.
Тем самым образуется разница между переданным фактическим значением и текущим значением цикличных средних. Если на этот механизм в обратном направлении подать ноль, и подобавлять к нему все средние текущего шага, но только без модификации элементов MeanAdapt, то получим значение прогноза из предположения, что будущая ошибка ноль. Сдвигаем текущей элемент средних на следующий, все так же без модификации, и снова в обратном порядке подаем ноль. В результате получается график прогноза исходя из суммирования всех средних.
Для этого механизма остается два вопроса, как определять периодичность возможных цикличностей, и как определять лучшую длину адаптации.
Я это сделал просто перебором по тестовым данным. В программе есть кнопка сканирования цикличностей, которая сканирует все возможные периоды цикличностей размерностью до двух тысяч, и выдает из них лучший.
Этот лучший вручную дописывается в поле «Периоды цикличностей» и при следующем запуске поиска цикличностей уже будет сканироваться за вычетом новой дописанной цикличности. Только если будете проверять на текущем графике, то в поле уже вписаны по умолчанию лучшие цикличности и больше не найдется. Поэтому их сотрите и запускайте.
Длина адаптации так же выбирается перебором, но указывать нигде не нужно, программа каждый раз при запуске ее сканирует заново, т.к. это не долго. Последовательность указания периодов в поле «Периоды цикличностей» так же не важны, т.к. при запуске будет выбрана лучшая последовательность.
С цикличностями вроде все. Они считаются, из графика вычитаются, получаем график ошибки.
Этот график ошибки представляет собой колебания со средней близкой к нулю — плюсовые и минусовые ошибки. Он может содержать корреляции, а может быть оставшейся рандомной составляющей. К нему уже и применим корреляцию отрезков.
И по этому вопросу скажу, что считать ее по корреляции Пирсона не лучший вариант. Для этого есть и логические рассуждения — эта корреляция подгребает под подобие разной интенсивности графики, хотя при разной интенсивности последующее поведение совсем не означает что будет таким же, только с переносом. И практические показания — после применения цикличностей, попытка применить корреляцию Пирсона только ухудшает результат. А так же и при применении ее без цикличности, она получает прогноз хуже, чем это делает цикличность.
В результате экспериментов, пришел к выводу, что самый лучший расчет подобий это просто квадратичная разница между графиками. В случае если график уже за вычетом цикличностей, то график болтается вокруг нуля, и достаточно просто квадратичную разницу между ними.
Если цикличность не вычиталась, то лучше квадратичную разницу но с предварительным вычитанием средней:
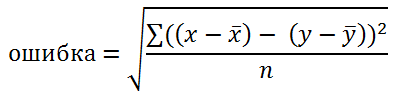
Хоть я здесь и пишу, что это корреляция отрезков, но на самом деле подразумеваю квадратичную разницу между ними.
В демонстрационной программе можно выбрать разные варианты подобий/корреляций которые я проверял, и проверить их для других графиков которые захотите. Реализация расчета подобий в программе осуществляется классом CorrSlide в файлах corr_slide.h и corr_slide.spp. Формулы разных подобий считаются в методе CorrSlide::Res CorrSlide::get_res(...).
Кроме указанных выше разных вариантов расчетов, этот класс включает в себя оптимизацию, что бы не приходилось пересчитывать расчет для смежных отрезков описанных далее свойств.
Я сделал, что для каждой позиции сканируется множество различных длин корреляции. Берется первая длина, скажем 6 точек, следующий вариант длины длиннее в два раза, т.е. 12, потом следующая 24, и т.д… Для каждой длины накапливается пачка лучших подобных отрезков и считает средний прогноз и дисперсия. После чего, из всех посчитанных пачек, каждая из которых отвечает за разную длину, выбирается та, которая лучше всего прогнозирует текущую точку. Та, которая имеет наименьшую дисперсию прогноза, та и лучше.
Неверно считать, что лучшей будет самый длинный отрезок. Во первых для длинного отрезка может не набраться достаточного количества совсем подобных отрезков, или совсем не найтись. И брать один лучший по подобию, как я упоминал в предыдущей статье будет неправильно. Во вторых, прогноз может коррелировать от существенно более близких значений к прогнозируемой точке, а последующее удлинение отрезка не даст лучшего ответа, а лишь разбавит пачку лучших не нужными отрезками.
Но самый короткий отрезок, как вы понимаете, то же не будет лучшим. В результате, просто собираются несколько пачек коррелирующих отрезков разных длин, и смотрится, которая из пачек имеет наиболее определенный прогноз — наименьшую дисперсию.
Так же, сделал вариант расчета подобия с увеличением значимости значений более близких к прогнозируемой точке. Там для каждого увеличения длины в два раза, тот отрезок, который был короче в два раза, добавляется дважды.
Плюс еще сделал механизм исключения выбросов. В принципе, выбросы на самом деле должны учитываться, как элементы графика или как вероятные ошибки. Но они должны учитываться на уровне формирования распределений характерных для текущего графика. Сейчас же я основал вычисления в основном на принципах правильно работающих на стандартных распределениях. Поэтому в текущей версии просто указывается, сколько крайних точек исключать. Указывается в поле «Кол-во выбросов», и применяются это в нескольких моментах вычисления, которые заметно искажали результат.
Так же проблема с распределениями влияет на коэффициент прогнозирования, про который я написал в предыдущей статье, он получается не наглядным. Разбор этих вопросов оставил на следующую версию программы.
В итоге, все это многообразие и безобразие приводит к тому, что после вычитания цикличности, этот график еще чуть лучше можно спрогнозировать.
Если пробовать различные варианты длины подобных отрезков, то успех прогноза может несколько меняться. Т.е. результат не стабилен. Если при этом использовать подобие по квадратичному отклонению, то он впринципе всегда улучшает результат после обработки цикличностей, в отличии от корреляции Пирсона. Так же чуть лучшие результаты дает использование длин подобия отрезков кратных 24 — минимальной цикличности.
Расчет осуществляется достаточно быстро, что можно указать что бы посчиталось тысяча или более позиций и посмотреть средний прогноз за этот отрезок, убедиться, что не только в экспериментальной точке прогноз удачен. Хотя и не везде настолько бросается в глаза.
Для примера, за период 1000 позиций, с прогнозированием каждого шага на 1 шаг вперед, результат получается:
средняя ошибка за выбранный период 1.76473%
сред.ошиб только по цикличности 1.78332%
сред.ошиб при условии что прогноз это последняя известная позиция 4.19216%
Если поле «К-во позиций прогноза» оставить пустым, то расчет будет осуществляться для каждой позиции начиная от «Дата/позиция начала прогноза» до конца графика.
Если будет интересно увидеть цифры которые я привел относительно экспериментальной точки, то в настройках по умолчанию нужно поменять «К-во позиций прогноза» = 1, «К-во одной позиции» = 24.
Стоит заметить, что все эти улучшения не позволили сдвинуть ни на малейшую долю прогнозирование EURUSD. Оно похоже ну совсем не зависимо от своей прошлой истории. Хотя я его еще буду проверять следующими версиями программы.
Как упоминал, программа универсальна, в ней можно выбрать свои файлы данных, и указать прогнозируемую колонку и колонку даты если есть таковая. Разделителем колонок может быть запятая или точка с запятой. В программе по возможности приведены описания элементов управления.

Программа и ее исходники.
Пока все, в следующий раз еще улучшу результат прогнозирования новыми свойствами.
А именно цикличность и усложнение варианта с подобием отрезков.

Вернемся к графику из предыдущей статьи. Тот график очень периодический (см. картинку дальше), и правильным будет его сначала прогнозировать расчетом цикличностей. От использования одного только расчета цикличности у меня получился прогноз 4.1% ошибки (mape) вместо 5% для прежней экспериментальной точки.
После расчета цикличностей, делаем вычитание из исходных значений графика, значений прогноза от цикличностей, и получившийся график ошибки уже пытаемся прогнозировать корреляциями. В результате для той же точки получил уже 3.7% ошибки.
Программа и ее исходники текущей версии здесь. Теперь она больше похожа на самостоятельную утилиту прогнозирования рядов, чем на тестирование одного метода и одного графика. И может выполнять прогноз для последней точки, для которой отсутствует фактическое прогнозируемое значение.
А теперь подробней про алгоритмы и смыслы
ape — Absolute percentage error — abs(forecast-fact)/fact
mape — Mean absolute percentage error
Если взять несколько ape за период и посчитать арифметическое среднее значение, то получим mape.
Сам по себе процент ошибки прогноза для неизвестного графика мало что говорит. Потому что не известно на сколько график обычно меняется, и соответственно много ли это спрогнозировали или мало. Удобно брать для сравнения mape от прогноза, который делается из предположения, что следущее значение будет таким же как последнее известное.
Для экспериментальной точки это значение 9.2%. Напомню, что там цифры приводились как прогноз на сутки вперед. Т.е. колебания графика за сутки составляет 9.2%. В результате применения прогнозирования эта ошибка сократилась до 3.7%.
Вот так вот выглядит исследуемый график за несколько дней, с сильными суточными колебаниями:
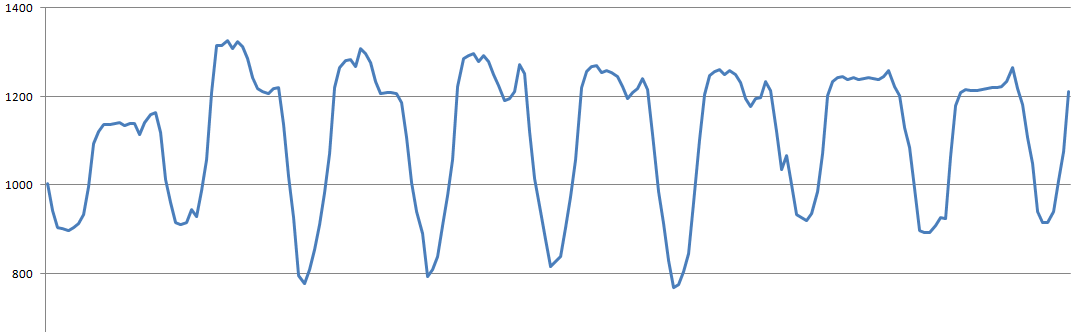
Очевидно, что если такой график пытать корреляциями, то корреляция будет видеть в основном дневные колебания, а все более мелкие нюансы будут утопать.
Вот так вот выглядит прогноз на сутки вперед:
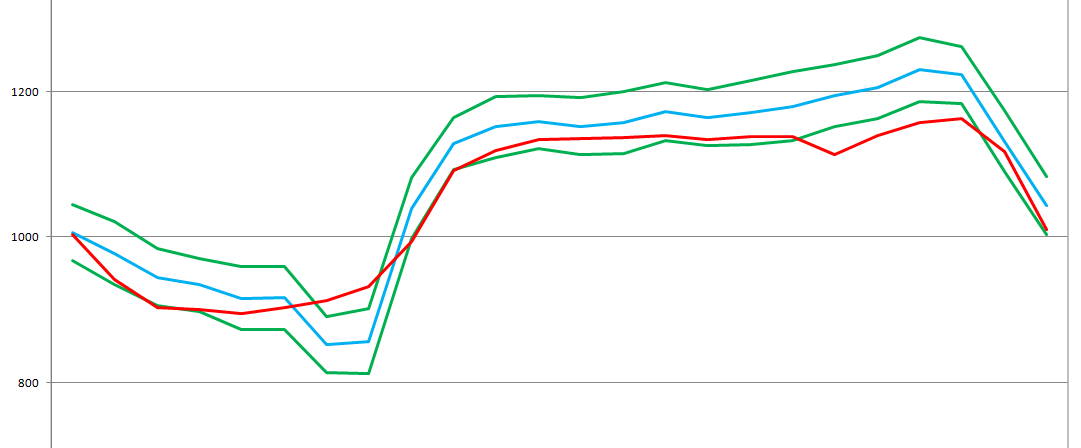
Красным отображен фактический график, синим прогноз, зеленым граница трех стандартных отклонений прогноза от центра — если бы колебания графика имели бы стандартное распределение, то это было бы 99% вероятного коридора графика.
Расчет цикличностей
Для того, что бы осуществлять прогноз по цикличностям, был организован класс Cicling в файлах cicling.h и cicling.cpp. Объект данного класса накапливает N элементов средних, количество которых соответствуют длине цикла. Средние накапливаются по подстраивающейся формуле, их называют скользящими средними.
В моей интерпретации, эта формула имеет длину подстраивания, что удобней чем если просто безликий коэффициент. Данный механизм содержится в компактном классе MeanAdapt в файле dispersion.h и dispersion.cpp.
В среднем суть механизма такова:
cnt_vals = cnt_vals + 1;
if (cnt_vals > cnt_adapt)
su = su - su / (double)cnt_adapt + new_value;
else
su = su + new_value;
mean = su / (double)min(cnt_vals, cnt_adapt);
В том классе есть еще усложнение с отрицательно интерпретацией cnt_adapt, если интересно смотрите исходники.
В общем, в классе Cicling есть N элементов подстраивающихся средних, среди них есть текущий элемент, в который добавляется очередное значение, и указатель сдвигается на следующий элемент средних. При достижении последнего элемента, указатель перемещается на начало. И так по кругу. Точнее в классе сделано просто ar_means[cnt_values % size_cicling], где cnt_values — количество добавленных значений.
Прежде чем добавить в текущий элемент средних новое значение, из нового значения делается вычитание текущего среднего значения, тем самым формируется значение ошибки. Класс Cicling может рекурсивно содержать следующий уровень цикличности Cicling* ne_level, если это так, то ошибка текущего уровня передается дальше для суммирования следующих цикличностей, иначе ошибка возвращается. Для текущего графика основные цикличности это суточная — 24 часа и недельная — 168 часов.
Тем самым образуется разница между переданным фактическим значением и текущим значением цикличных средних. Если на этот механизм в обратном направлении подать ноль, и подобавлять к нему все средние текущего шага, но только без модификации элементов MeanAdapt, то получим значение прогноза из предположения, что будущая ошибка ноль. Сдвигаем текущей элемент средних на следующий, все так же без модификации, и снова в обратном порядке подаем ноль. В результате получается график прогноза исходя из суммирования всех средних.
Для этого механизма остается два вопроса, как определять периодичность возможных цикличностей, и как определять лучшую длину адаптации.
Я это сделал просто перебором по тестовым данным. В программе есть кнопка сканирования цикличностей, которая сканирует все возможные периоды цикличностей размерностью до двух тысяч, и выдает из них лучший.
Этот лучший вручную дописывается в поле «Периоды цикличностей» и при следующем запуске поиска цикличностей уже будет сканироваться за вычетом новой дописанной цикличности. Только если будете проверять на текущем графике, то в поле уже вписаны по умолчанию лучшие цикличности и больше не найдется. Поэтому их сотрите и запускайте.
Длина адаптации так же выбирается перебором, но указывать нигде не нужно, программа каждый раз при запуске ее сканирует заново, т.к. это не долго. Последовательность указания периодов в поле «Периоды цикличностей» так же не важны, т.к. при запуске будет выбрана лучшая последовательность.
С цикличностями вроде все. Они считаются, из графика вычитаются, получаем график ошибки.
Мой вариант реализации подобия отрезков
Этот график ошибки представляет собой колебания со средней близкой к нулю — плюсовые и минусовые ошибки. Он может содержать корреляции, а может быть оставшейся рандомной составляющей. К нему уже и применим корреляцию отрезков.
И по этому вопросу скажу, что считать ее по корреляции Пирсона не лучший вариант. Для этого есть и логические рассуждения — эта корреляция подгребает под подобие разной интенсивности графики, хотя при разной интенсивности последующее поведение совсем не означает что будет таким же, только с переносом. И практические показания — после применения цикличностей, попытка применить корреляцию Пирсона только ухудшает результат. А так же и при применении ее без цикличности, она получает прогноз хуже, чем это делает цикличность.
В результате экспериментов, пришел к выводу, что самый лучший расчет подобий это просто квадратичная разница между графиками. В случае если график уже за вычетом цикличностей, то график болтается вокруг нуля, и достаточно просто квадратичную разницу между ними.
Если цикличность не вычиталась, то лучше квадратичную разницу но с предварительным вычитанием средней:

Хоть я здесь и пишу, что это корреляция отрезков, но на самом деле подразумеваю квадратичную разницу между ними.
В демонстрационной программе можно выбрать разные варианты подобий/корреляций которые я проверял, и проверить их для других графиков которые захотите. Реализация расчета подобий в программе осуществляется классом CorrSlide в файлах corr_slide.h и corr_slide.spp. Формулы разных подобий считаются в методе CorrSlide::Res CorrSlide::get_res(...).
Кроме указанных выше разных вариантов расчетов, этот класс включает в себя оптимизацию, что бы не приходилось пересчитывать расчет для смежных отрезков описанных далее свойств.
Я сделал, что для каждой позиции сканируется множество различных длин корреляции. Берется первая длина, скажем 6 точек, следующий вариант длины длиннее в два раза, т.е. 12, потом следующая 24, и т.д… Для каждой длины накапливается пачка лучших подобных отрезков и считает средний прогноз и дисперсия. После чего, из всех посчитанных пачек, каждая из которых отвечает за разную длину, выбирается та, которая лучше всего прогнозирует текущую точку. Та, которая имеет наименьшую дисперсию прогноза, та и лучше.
Неверно считать, что лучшей будет самый длинный отрезок. Во первых для длинного отрезка может не набраться достаточного количества совсем подобных отрезков, или совсем не найтись. И брать один лучший по подобию, как я упоминал в предыдущей статье будет неправильно. Во вторых, прогноз может коррелировать от существенно более близких значений к прогнозируемой точке, а последующее удлинение отрезка не даст лучшего ответа, а лишь разбавит пачку лучших не нужными отрезками.
Но самый короткий отрезок, как вы понимаете, то же не будет лучшим. В результате, просто собираются несколько пачек коррелирующих отрезков разных длин, и смотрится, которая из пачек имеет наиболее определенный прогноз — наименьшую дисперсию.
Так же, сделал вариант расчета подобия с увеличением значимости значений более близких к прогнозируемой точке. Там для каждого увеличения длины в два раза, тот отрезок, который был короче в два раза, добавляется дважды.
Вот так это выглядит...
Вот так это выглядит, указанные ниже суммы это компоненты формул корреляций:
void CorrSlide::make_res_2() {
for (int i_len = 0; i_len < c_lens-1; ++i_len) {
Calc& calc = ar_calc_2[i_len];
if (i_len == 0)
calc = ar_calc[i_len];
else
calc = ar_calc_2[i_len-1];
Calc& calc_plus = ar_calc[i_len+1];
calc.cnt += calc_plus.cnt;
calc.su_s += calc_plus.su_s;
calc.su_s_pow2 += calc_plus.su_s_pow2;
calc.su_m += calc_plus.su_m;
calc.su_m_pow2 += calc_plus.su_m_pow2;
calc.su_s_m += calc_plus.su_s_m;
calc.div_s = dbl(calc.cnt) * calc.su_s_pow2 - calc.su_s * calc.su_s;
}
}
И немножко про выбросы
Плюс еще сделал механизм исключения выбросов. В принципе, выбросы на самом деле должны учитываться, как элементы графика или как вероятные ошибки. Но они должны учитываться на уровне формирования распределений характерных для текущего графика. Сейчас же я основал вычисления в основном на принципах правильно работающих на стандартных распределениях. Поэтому в текущей версии просто указывается, сколько крайних точек исключать. Указывается в поле «Кол-во выбросов», и применяются это в нескольких моментах вычисления, которые заметно искажали результат.
Так же проблема с распределениями влияет на коэффициент прогнозирования, про который я написал в предыдущей статье, он получается не наглядным. Разбор этих вопросов оставил на следующую версию программы.
Что получилось в итоге
В итоге, все это многообразие и безобразие приводит к тому, что после вычитания цикличности, этот график еще чуть лучше можно спрогнозировать.
Если пробовать различные варианты длины подобных отрезков, то успех прогноза может несколько меняться. Т.е. результат не стабилен. Если при этом использовать подобие по квадратичному отклонению, то он впринципе всегда улучшает результат после обработки цикличностей, в отличии от корреляции Пирсона. Так же чуть лучшие результаты дает использование длин подобия отрезков кратных 24 — минимальной цикличности.
Расчет осуществляется достаточно быстро, что можно указать что бы посчиталось тысяча или более позиций и посмотреть средний прогноз за этот отрезок, убедиться, что не только в экспериментальной точке прогноз удачен. Хотя и не везде настолько бросается в глаза.
Для примера, за период 1000 позиций, с прогнозированием каждого шага на 1 шаг вперед, результат получается:
средняя ошибка за выбранный период 1.76473%
сред.ошиб только по цикличности 1.78332%
сред.ошиб при условии что прогноз это последняя известная позиция 4.19216%
Если поле «К-во позиций прогноза» оставить пустым, то расчет будет осуществляться для каждой позиции начиная от «Дата/позиция начала прогноза» до конца графика.
Если будет интересно увидеть цифры которые я привел относительно экспериментальной точки, то в настройках по умолчанию нужно поменять «К-во позиций прогноза» = 1, «К-во одной позиции» = 24.
Стоит заметить, что все эти улучшения не позволили сдвинуть ни на малейшую долю прогнозирование EURUSD. Оно похоже ну совсем не зависимо от своей прошлой истории. Хотя я его еще буду проверять следующими версиями программы.
Как упоминал, программа универсальна, в ней можно выбрать свои файлы данных, и указать прогнозируемую колонку и колонку даты если есть таковая. Разделителем колонок может быть запятая или точка с запятой. В программе по возможности приведены описания элементов управления.

Программа и ее исходники.
Пока все, в следующий раз еще улучшу результат прогнозирования новыми свойствами.
