Привет, Хабр! На тему архитектуры хранилищ данных написано немало, но так лаконично и емко как в статье, на которую я случайно натолкнулся, еще не встречал.
Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!

(Источник картинки)
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
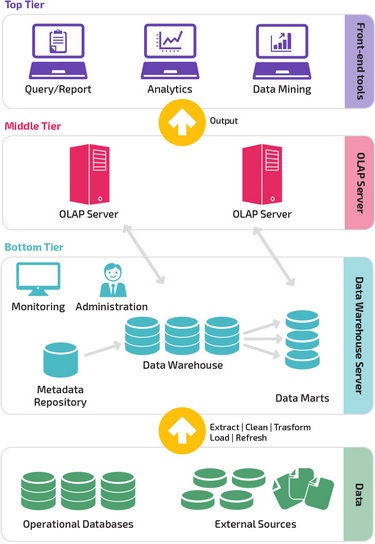
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона основывается на том, что хранилище данных является централизованным хранилищем всех корпоративных данных. При таком подходе организация сначала создает нормализованную модель хранилища данных. Затем создаются витрины размерных данных на основе модели хранилища. Это известно как нисходящий подход к хранилищу данных.
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
Схемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.

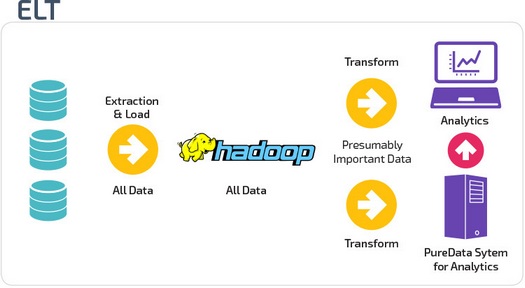
ETL и ELT — два разных способа загрузки данных в хранилище.
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
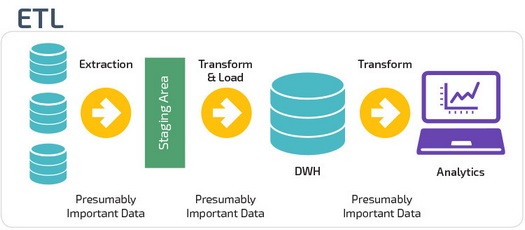
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.

Структура хранилища данных организации также зависит от его текущей ситуации и потребностей.
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.

Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.
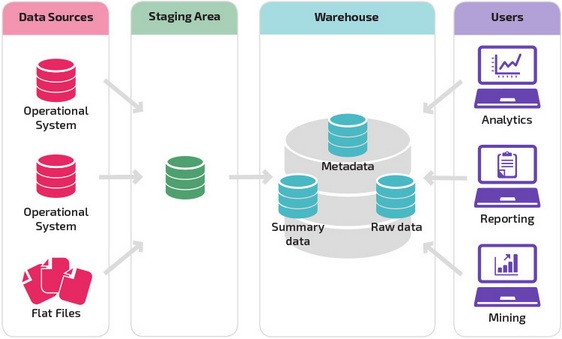
Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.

В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift — это облачное представление традиционного хранилища данных.
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.

Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно. Узел Leader Node объединяет результаты и возвращает их клиентскому приложению.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.

Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:

Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
Ссылка на оригинальный текст: panoply.io/data-warehouse-guide/data-warehouse-architecture-traditional-vs-cloud
Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!
(Источник картинки)
Введение
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
- Нет необходимости покупать физическое оборудование;
- Облачные хранилища данных быстрее и дешевле настроить и масштабировать;
- Облачные хранилища данных обычно могут выполнять сложные аналитические запросы гораздо быстрее, потому что они используют массовую параллельную обработку.
Традиционная архитектура хранилища данных
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
Трехуровневая архитектура
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
- Нижний уровень: этот уровень содержит сервер базы данных, используемый для извлечения данных из множества различных источников, например, из транзакционных баз данных, используемых для интерфейсных приложений.
- Средний уровень: средний уровень содержит сервер OLAP, который преобразует данные в структуру, лучше подходящую для анализа и сложных запросов. Сервер OLAP может работать двумя способами: либо в качестве расширенной системы управления реляционными базами данных, которая отображает операции над многомерными данными в стандартные реляционные операции (Relational OLAP), либо с использованием многомерной модели OLAP, которая непосредственно реализует многомерные данные и операции.
- Верхний уровень: верхний уровень — это уровень клиента. Этот уровень содержит инструменты, используемые для высокоуровневого анализа данных, создания отчетов и анализа данных.

Kimball vs. Inmon
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона основывается на том, что хранилище данных является централизованным хранилищем всех корпоративных данных. При таком подходе организация сначала создает нормализованную модель хранилища данных. Затем создаются витрины размерных данных на основе модели хранилища. Это известно как нисходящий подход к хранилищу данных.
Модели хранилищ данных
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
- Виртуальное хранилище данных — это набор отдельных баз данных, которые можно использовать совместно, чтобы пользователь мог эффективно получать доступ ко всем данным, как если бы они хранились в одном хранилище данных;
- Модель витрины данных используется для отчетности и анализа конкретных бизнес-линий. В этой модели хранилища – агрегированные данные из ряда исходных систем, относящихся к конкретной бизнес-сфере, такой как продажи или финансы;
- Модель корпоративного хранилища данных предполагает хранение агрегированных данных, охватывающих всю организацию. Эта модель рассматривает хранилище данных как сердце информационной системы предприятия с интегрированными данными всех бизнес-единиц
Звезда vs. Снежинка
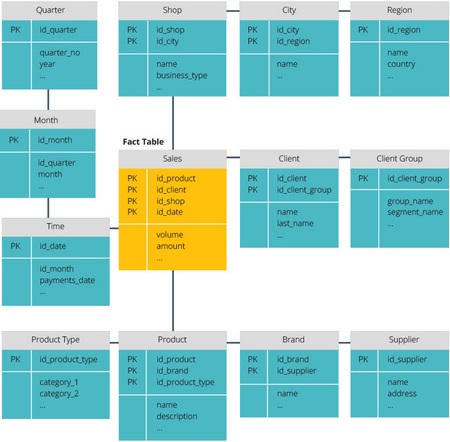
Схемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
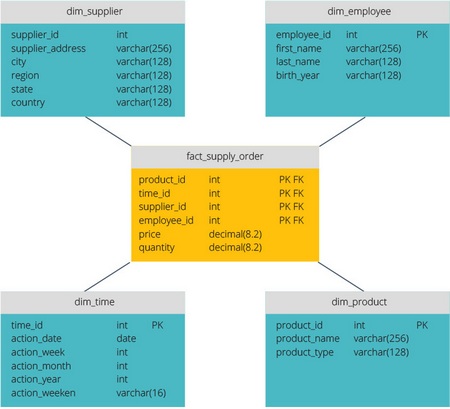
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.
ETL vs. ELT
ETL и ELT — два разных способа загрузки данных в хранилище.
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
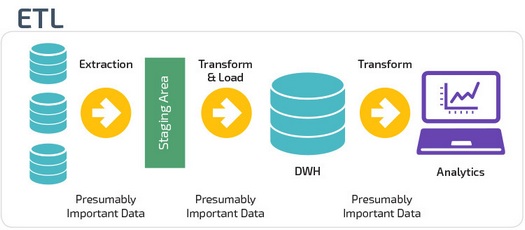
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.
Организационная зрелость
Структура хранилища данных организации также зависит от его текущей ситуации и потребностей.
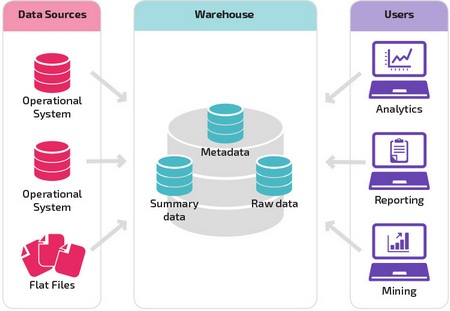
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.
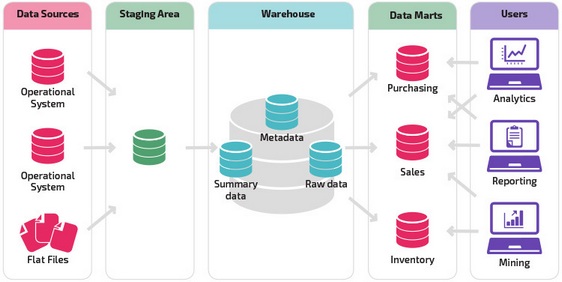
Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.

Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.
Новые архитектуры хранилищ данных
В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift
Amazon Redshift — это облачное представление традиционного хранилища данных.
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.
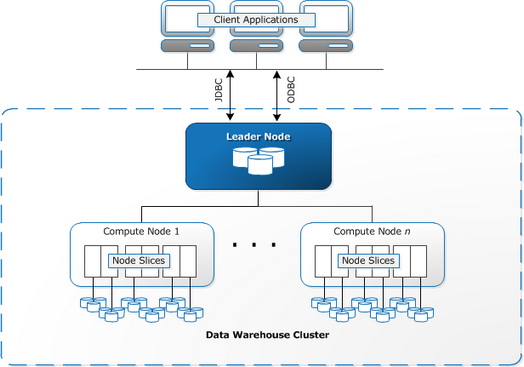
Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно. Узел Leader Node объединяет результаты и возвращает их клиентскому приложению.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Google BigQuery
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.

Panoply
Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:
- Анализ запросов и данных — определение наилучшей конфигурации для каждого варианта использования, корректировка ее с течением времени и создание индексов, сортировочных ключей, дисковых ключей, типов данных, вакуумирование и разбиение.
- Идентификация запросов, которые не следуют передовым методам — например, те, которые включают вложенные циклы или неявное приведение — и переписывает их в эквивалентный запрос, требующий доли времени выполнения или ресурсов.
- Оптимизация конфигурации сервера с течением времени на основе шаблонов запросов и изучения того, какая настройка сервера работает лучше всего. Платформа плавно переключает типы серверов и измеряет итоговую производительность.

По ту сторону облачных хранилищ данных
Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
- Загрузка данных в облачные хранилища данных нетривиальна, а для крупномасштабных конвейеров данных требуется настройка, тестирование и поддержка процесса ETL. Эта часть процесса обычно выполняется сторонними инструментами;
- Обновления, вставки и удаления могут быть сложными и должны выполняться осторожно, чтобы не допустить снижения производительности запросов;
- С полуструктурированными данными трудно иметь дело — их необходимо нормализовать в формате реляционной базы данных, что требует автоматизации больших потоков данных;
- Вложенные структуры обычно не поддерживаются в облачных хранилищах данных. Вам необходимо преобразовать вложенные таблицы в форматы, понятные хранилищу данных;
- Оптимизация кластера. Существуют различные варианты настройки кластера Redshift для запуска ваших рабочих нагрузок. Различные рабочие нагрузки, наборы данных или даже различные типы запросов могут потребовать иной настройки. Для достижения оптимальной работы, необходимо постоянно пересматривать и при необходимости дополнительно настраивать конфигурацию;
- Оптимизация запросов — пользовательские запросы могут не соответствовать передовым методам и, следовательно, будут выполняться намного дольше. Вы можете работать с пользователями или автоматизированными клиентскими приложениями для оптимизации запросов, чтобы хранилище данных могло работать так, как ожидалось
- Резервное копирование и восстановление — несмотря на то, что поставщики хранилищ данных предоставляют множество возможностей для резервного копирования ваших данных, их нетривиально настроить и они требуют мониторинга и пристального внимания
Ссылка на оригинальный текст: panoply.io/data-warehouse-guide/data-warehouse-architecture-traditional-vs-cloud
