Краткая заметка по теме business process mining в контексте роста интереса к концепции "digital twin". В силу периодического выплывания этой темы считаю целесообразным поделиться подходами к решению.
Постановка задачи
Ситуация предельно проста.
- Есть компания X (Y, Z, ...).
- В компании есть бизнес-процессы, автоматизированные различными ИТ системами.
- Есть бизнес-аналитики, которые нарисовали bpmn диаграммы по этим процессам. Если говорить точнее, их собственное "bpmn представление" о том, как эти процессы должны были бы выглядеть.
- Бизнес пользователи хотят иметь какое-то представление (KPI) по этим процессам.
Как докопаться до истины и посчитать эти метрики?
Является продолжением предыдущих публикаций.
Формулируем задачу в понятных для компьютера требованиях
Базисные постулаты:
- Есть временнОй лог событий (это могут разнообразные логи ИТ систем, cdr\xdr, просто записи событий в БД) разной степени чистоты, полноты и согласованности.
- ИТ системы действуют как конечный автомат и "гуляют" между различными состояниями в соответствии с действиями пользователей и бизнес-логикой, заложенной программистами в них.
- Взаимодействие пользователей осуществляется в транзакционном виде.
Корректировки физического мира:
- Количество внесенных изменений в ИТ системы таково, что bpmn диаграммы бизнес-аналитиков не имеют почти ничего общего с реальностью.
- Данные могут быть сильно неструктурированными (например, логи приложений).
- "Транзакционность" является логическим понятием. Сами записи событий содержат только атрибуты, присущие этому состоянию и нет никакого сквозного идентификатора транзакции.
- Число записей в сутки составляет десятки-сотни-тысячи миллионов штук.
Решение "поставил-посчитал"
Для решения подобных задач необходимо:
- реконструировать транзакции;
- реконструировать реальные бизнес-процессы;
- провести расчеты;
- сформировать результаты в human-readable формате.
Можно начать искать вендорские решения и платить миллионы. Но у нас же в руках есть R. Он вполне прекрасно позволяет решить эту задачу. Краткие соображения ниже.
Вроде все просто и в R есть хороший согласованный набор пакетов bupaR. Но ложка дегтя присутствует и она отравляет все. Этот набор за приемлемое время справляется только с небольшим количеством событий (сотни тысяч — несколько миллионов).
Для больших объемов надо использовать иные подходы.
Добавляем скорости!
Эмулируем входной набор данных
Для демонстрации идей необходимо сформировать некий тестовый набор данных. Возьмем в качестве физического исходника мат.модели пример федеральной сети магазинов, благо это понятно абсолютно всем. Хотя с таким же успехом это могут быть банкоматы, колл-центры, общественный транспорт, водоснабжение и т.д.
- Есть магазины разного масштаба (маленькие, средние и большие).
- В магазинах есть кассы (pos терминалы).
- Номера магазинов могут быть цифробуквенными, номера терминалов — цифровые.
- В магазины ходят покупатели и делают покупки чего-нибудь и при этом оплачивают картой.
- Взаимодействие pos терминала с картой и банком описывается определенным набором состояний и правилами перехода между ними.
- Операции бывают успешные, неуспешные, отложенные и незавершенные (банк недоступен, например).
- Транзакции обладают таймаутами.
Берем следующий набор паттернов бизнес-операций:
"INIT-REQUEST-RESPONSE-SUCCESS"
"INIT-REQUEST-RESPONSE-ERROR"
"INIT-REQUEST-RESPONSE-DEFFERED"
"INIT-REQUEST"
"INIT"Для демонстрации подхода создадим малый семпл, но это все прекрасно работает и на миллиардах записей (для такого объема без суперглубокой оптимизации характерное время измеряется всего сотнями секунд на одном сервере весьма посредственной производительности).
Сразу спойлеры для больших объемов:
- во многих местах средствами
tidyverseможно ответа и не дождаться; - оптимизация даже микрошагов полезна и может дать значимый вклад.
library(tidyverse)
library(datapasta)
library(tictoc)
library(data.table)
library(stringi)
library(anytime)
library(rTRNG)
data.table::setDTthreads(0) # отдаем все ядра в распоряжение data.table
data.table::getDTthreads() # проверим доступное количество потоков
set.seed(46572)
RcppParallel::setThreadOptions(numThreads = parallel::detectCores() - 1)
# Важное допущение -- нет параллельных бизнес-транзакций, все выполняется строго последовательно
# Есть 5 типа паттернов бизнес-операций, 2 последних -- глобальные сбои
bo_pattern <- tibble::tribble(
# маркеры паттерна, частота в пуле операций, средняя длительность транзакции
~pattern, ~prob, ~mean_duration,
"INIT-REQUEST-RESPONSE-SUCCESS", 0.7, 5,
"INIT-REQUEST-RESPONSE-ERROR", 0.15, 5,
"INIT-REQUEST-RESPONSE-DEFFERED", 0.07, 8,
"INIT-REQUEST", 0.05, 2,
"INIT", 0.03, 0.5
)
# Проверка корректности данных + расчет абсолютных частот событий
checkmate::assertTRUE(sum(bo_pattern$prob) == 1)
df <- bo_pattern %>%
separate_rows(pattern) %>%
# нормировочный коэффициент
mutate(coeff = sum(prob)) %>%
group_by(pattern) %>%
# переведем в проценты
summarise(event_prob = sum(prob/coeff)*100) %>%
ungroup()
checkmate::assertTRUE(sum(df$event_prob) == 100)
# Пусть есть 3 типа магазинов: маленькие (4 кассы), средние (12 касс), большие (30 касс)
df1 <- tribble(
~type, ~n_pos, ~n_store,
"small", 4, 10,
"medium", 12, 5,
"large", 30, 2
) %>%
# генерируем номера магазинов для каждой группы
mutate(store = map2(row_number(), n_store,
~sample(x = .x * 1000 + 1:.y, size = .y, replace = FALSE))) %>%
unnest(store) %>%
# генерируем номера терминалов для каждого магазина
mutate(pos = map(n_pos, ~sample(x = .x, size = .x, replace = FALSE))) %>%
unnest(pos) %>%
mutate(pattern = sample(bo_pattern$pattern, n(), replace = TRUE, prob = bo_pattern$prob))
tic("Generate transactions")
# транзакции идут одна за другой, в параллель ничего не исполняется
# для упрощения задачи мы сгенерируем количество записей с запасом, а потом отсечем по временнЫм границам
df2 <- df1 %>%
# для каждой транзакции случайным образом сгенерируем общую продолжительность
select(-matches("duration")) %>%
left_join(bo_pattern, by = "pattern") %>%
# раздуем сэмплы
sample_frac(size = 200, replace = TRUE) %>%
mutate(duration = rnorm(n(), mean = mean_duration, sd = mean_duration * .25)) %>%
select(-prob, -mean_duration) %>%
# отбрасываем все транзакции, которые имеют отрицательную длительность или > таймаута
# таймаут устанавливаем равным 30 секунд
filter(duration > 0.5 & duration < 30) %>%
# теперь для каждого POS сгенерим поток событий на основе паттернов
mutate(session_id = row_number()) %>%
# расщепляем транзакции на отдельные состояния, при этом порядок следования состояний сохраняется
separate_rows(pattern) %>%
rename(event = pattern)
toc()
tic("Generate time markers, data.table way")
samples_tbl <- data.table::as.data.table(df2) %>%
# setkey(session_id, duration, physical = FALSE) %>%
# на каждую транзакцию надо навесить времена между каждой отдельным состоянием
# 1-ая операция тоже имеет дельту от конца предыдущей, полагаем, что она будет не менее 5 секунд
# .[, ticks := base::sort(runif(.N, 5, 5 + duration)), by = .(session_id, duration)] %>%
# при малом объеме данных очень большие накладные расходы на match.arg у функции base::order!!
# делаем в два захода
# сначала просто генерируем случайные числа от 0 до 1 для каждой записи отдельно
# и масштабируем одним вектором
# .[, tshift := runif(.N, 0, 1)] %>%
# в таком расладе trng быстрее в несколько раз (может даже на порядок получиться)
# фактически, здесь мы считаем случайные соотношения времен между операциями внутри транзакции
.[, trand := runif_trng(.N, 0, 1, parallelGrain = 100L) * duration] %>%
# делаем сортировку вектора внутри каждой сессии, простая сортировка будет ОЧЕНЬ долгой
# .[, ticks := sort(tshift), by = .(session_id)] %>%
# делаем трюк, формируем составной индекс из session_id, который является монотонным, и смещением по времени
.[, t_idx := session_id + trand / max(trand)/10] %>%
# подтягиваем в колонку сортированное значение вектора с реконструкцией
# session_id в целой части гарантирует сортировку пропорций в рамках каждой транзакции без доп. группировок
.[, tshift := (sort(t_idx) - session_id) * 10 * max(trand)] %>%
# добавим дополнительной реалистичности, между транзакциями на одном POS должны быть большие паузы (60 сек)
.[event == "INIT", tshift := tshift + runif_trng(.N, 0, 60, parallelGrain = 100L)] %>%
# удаляем весь промежуточный мусор
.[, `:=`(duration = NULL, trand = NULL, t_idx = NULL,
n_store = NULL, n_pos = NULL,
timestamp = as.numeric(anytime("2019-03-11 08:00:00 MSK")))] %>%
# переводим все в физическое время, начиная от 01.03.2019 для каждой кассы отдельно
.[, timestamp := timestamp + cumsum(tshift), by = .(store, pos)] %>%
# фильтруем по текущему рабочему дню
.[timestamp <= as.numeric(anytime("2019-04-11 23:00:00 MSK")), ] %>%
# и обратно одним действием преобразуем числа во время для вектора
.[, timestamp := anytime(timestamp, tz = "Europe/Moscow")] %>%
as_tibble() %>%
select(store, pos, event, timestamp, session_id)
toc()Для чистоты эксперимента оставим только значащие параметры и все перемешаем. В реальной жизни надо еще случайным образом выкинуть часть фрагментов (возможно отдельными временными блоками), эмулируя тем самым потери в получении данных.
# перемешиваем данные
log_tbl <- samples_tbl %>%
select(store, pos, state = event, timestamp_msk = timestamp) %>%
sample_n(n())
# посмотрим графически
log_tbl %>%
mutate(timegroup = lubridate::ceiling_date(timestamp_msk, unit = "10 mins")) %>%
ggplot(aes(timegroup)) +
# geom_bar(width = 0.7*600) +
geom_bar(colour = "white", size = 1.3) +
theme_bw()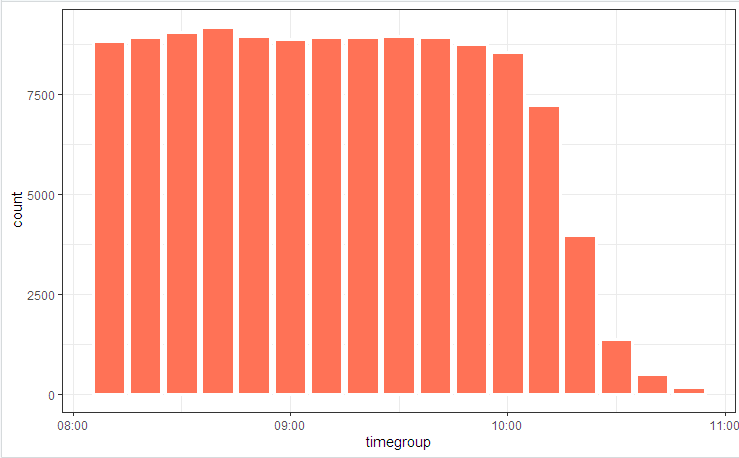
Проиллюстрируем картинкой схему процесса

и распределение по состояниям

Незначительные флуктуации обусловлены тем, что таблица считается вначале (есть во включенном коде), а bupaR::process_map работал в конце, когда часть случайно сгенерированных данных, не подходящих под интегральные ограничения, была срезана элементами фильтрации.
Реконструкция транзакций
Первое, что обычно предлагают, когда приходится собирать\разбирать\сопоставлять временные ряды, это группировки и циклы сравнений. В демонстрационных примерах на 100 записей этот поход сработает, но миллионных списках — нет. Чтобы справиться с этой задачей надо локализовать точки потери времени (внутренние циклы, промежуточные выделения памяти и копирование) и постараться устранить их до минимума.
В итоге эту задачу можно свести к десятку строчек.
clean_dt <- as.data.table(log_tbl) %>%
# все транзакции начинаются с INIT
.[, start := (state == "INIT")] %>%
# синтетический session_id будем строить в рамках одного дня, поэтому
# для кардинального сокращения времени преобразования перевод даты в строку сделаем по группам
.[, event_date := lubridate::as_date(timestamp_msk)] %>%
.[, date_str := format(.BY[[1]], "%y%m%d"), by = event_date] %>%
# временнУю сортировку от прошлого к будущему сделаем один раз для всех
# timestamp_msk уже содержит миллисекунды
setorder(store, pos, timestamp_msk) %>%
# есть еще одна беда -- разрыв в поступлении данных может приводить к искажению правильного шаблона путем приклейки огрызков
.[, session_id := paste(date_str, store, pos, cumsum(start), sep = "_")] %>%
# попробуем подкорректировать путем введения разрешенного транзакционного окна (возьмем 30 сек)
# .[, time_shift := timestamp_msk - shift(timestamp_msk), by = .(store, pos)] %>%
# в отсортированном списке событий протягиваем куммулятивный максимум времени, ориентируясь на INIT
.[, time_locf := cummax(as.numeric(timestamp_msk) * as.numeric(start)), by = .(store, pos)] %>%
.[, time_shift := as.numeric(timestamp_msk) - time_locf] %>%
# маркируем транзакционное окно, при генерации мы его установили равным 30 секунд
.[, lost_chain := time_shift > 30] %>%
# .[, time_shift := as.numeric(!start) * as.numeric(timestamp_msk - shift(timestamp_msk, fill = 0))] %>%
# INIT зануляет куммулятивную дельту
# .[, time_accu := cumsum(time_shift)] %>%
.[, date_str := NULL]
# агрегируем и потом считаем объемные показатели на уровне транзакций
# для больших объемов tidyverse не годится, дождаться конца исполнения не получилось
dt <- as.data.table(clean_dt) %>%
# исключаем огрызки из транзакционного анализа!!!
.[lost_chain != TRUE] %>%
# делаем глобальную сортировку для прямой отсылки к 1-му и последнему элементу
.[order(timestamp_msk, store, pos)] %>%
.[, bp_pattern := stri_join(state, collapse = "-"), by = session_id]
# проверим статистику по паттернам
as_tibble(dt) %>%
distinct(session_id, bp_pattern) %>%
count(session_id, sort = TRUE)Через несколько секунд имеем реконструированную картину бизнес-процессов.
И (кто бы мог подумать!!!) по факту оказывается, что автоматизированные в ИТ системах бизнес-процессы работают несколько не так (или совсем не так), как всех убеждали бизнес-аналитики. Удивления и споры "владельцев процесса" будут сопровождать изучение финальной картинки.
Активно применяем трюки
Когда скорость вычисления становится важной величиной мало просто написать рабочий код. Необходимо обратить внимание на все уровни. Также есть ряд алгоритмических трюков, которые позволяют существенно сократить время выполнения.
В частности, в этой задаче можно упомянуть следующее:
- Для основного процессинга только
data.table(скорость, работа по ссылкам), + учет внутренней оптимизации запросов. POSIXctможет содержать миллисекунды (хоть штатно и не отображается, но можно подправить с помощьюoptions(digits.secs=X)), прячем их туда, проще будет сравнивать и сортировать.- Избегаем физической сортировки внутри групп! Однократная физическая сортировка всего вектора гарантирует сортировку данных в группировках.
- Избегаем вычислений внутри групп. Все что можно, стараемся выполнить на исходных данных (применяем векторизацию, снижаем накладные на вызовы функций).
- Используем таймаут на транзакции, чтобы бороться с временными разрывами.
- Методы locf (Last Observation Carried Forward) работают медленно. Для переноса свойств по шкале времени используем
cumsum,cummax. - Трудоемкие операции, такие как преобразование POSIX -> строка, поиск по регуляркам и т.п. делаем не поэлементно, а на свертках. Накладные на внутреннюю индексацию и группировку преобразуемого поля несопоставимо меньше.
- Активно используем многопоточность (в т.ч. внутрипакетную).
- Не пренебрегаем микрооптимизацией. Например,
stri_cв несколько раз быстрееpaste0.
# Тест 1
log <- getLog(fileName)
bench::mark(
paste0 = paste0(log$value, collapse = "\n"),
stringi = stri_c(log$value, collapse = "\n")
)
# # A tibble: 2 x 13
# expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc total_time
# <bch:expr> <bch:> <bch:> <dbl> <bch:byt> <dbl> <int> <dbl> <bch:tm>
# 1 paste0 58ms 59.1ms 16.9 496KB 0 9 0 533ms
# 2 stringi 16.9ms 17.5ms 57.1 0B 0 29 0 508msПредыдущая публикация — Швейцарский нож для обработки json.
