В процессе работы над большим проектом, заимствование чужих модулей и готовых решений экономит огромное количество времени разработчиков и денег инвесторов. Одним из самых больших хранилищ таких решений безусловно является github.
Под катом маленькая хитрость, которую я использую при поиске и выборе решений github.
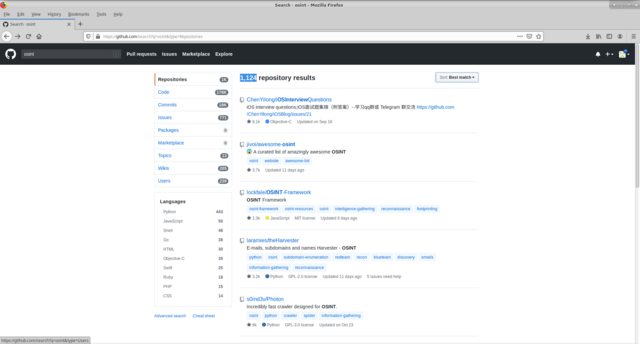
Представим задачу по разработки большой OSINT системы, допустим нам нужно посмотреть все имеющиеся решения на github по этому направлению. пользуемся стандартным глобальным поиском github по ключевому слову osint. Получаем 1124 репозиториев, возможность фильтровать по месту поиска ключевого слова (code, commits, issuse, etc), по языку исполнения. И сортировать по различным признакам(таким как most/fewest starts, forks, etc).
Выбор решения осуществляется по нескольким критериям: функционалу, количеству звезд, поддерживаемости проекта, языка разработки.

Интересующие меня решения сводились в таблицу, где заполнялись указные выше поля, делались соответствующие пометки по результатам того или иного тестирования.
Недостатком такого представления, как мне кажется являются, отсутствие возможности одновременной сортировка и фильтрации по нескольким полям.
Посредством api_github и python3 набросаем несложный простой скрипт который формирует нам csv документ с интересующими нас полями.
Запускаем скрипт
получаем

мне кажется так работать с информацией удобней, предварительно скрыв ненужные столбцы.
Код тут
Надеюсь кому-то пригодится.
Под катом маленькая хитрость, которую я использую при поиске и выборе решений github.
Представим задачу по разработки большой OSINT системы, допустим нам нужно посмотреть все имеющиеся решения на github по этому направлению. пользуемся стандартным глобальным поиском github по ключевому слову osint. Получаем 1124 репозиториев, возможность фильтровать по месту поиска ключевого слова (code, commits, issuse, etc), по языку исполнения. И сортировать по различным признакам(таким как most/fewest starts, forks, etc).
Выбор решения осуществляется по нескольким критериям: функционалу, количеству звезд, поддерживаемости проекта, языка разработки.
Интересующие меня решения сводились в таблицу, где заполнялись указные выше поля, делались соответствующие пометки по результатам того или иного тестирования.
Недостатком такого представления, как мне кажется являются, отсутствие возможности одновременной сортировка и фильтрации по нескольким полям.
Посредством api_github и python3 набросаем несложный простой скрипт который формирует нам csv документ с интересующими нас полями.
#!/usr/bin/env python3
from requests import get
from sys import argv
def print_to_csv(out_file,massive):
open(out_file,'a').writelines('id;name;full_name;language;description;created_at;updated_at;html_url;homepage;fork'
';pushed_at;stargazers_count;has_wiki;has_pages;archived;license;score;stargazers_count\n')
for i in massive:
open(out_file,'a').writelines(i+'\n')
def string_to_csv_string(my_dict):
csv_string=''
keys=['id', 'name', 'full_name','language', 'description','created_at', 'updated_at', 'html_url', 'homepage','fork',
'pushed_at', 'stargazers_count','has_wiki', 'has_pages', 'archived', 'license', 'score','stargazers_count']
for i in keys:
csv_string+=(str(my_dict[i])+';')
return csv_string
def dicts_to_dictsString(dicts):
strings=set()
for dict in dicts:
string=string_to_csv_string(dict)
strings.add(string)
return strings
def search_to_git(keyword):
item_all=set()
req=get('https://api.github.com/search/repositories?q={}&per_page=100&sort=stars'.format(keyword))
item_all=item_all|dicts_to_dictsString(req.json()['items'])
page_all=req.json()['total_count']/100
if page_all>=10:
page_all=10
for i in range(2,int(page_all)+1):
req = get('https://api.github.com/search/repositories?q={}&per_page=100&sort=stars&page={}'.format(keyword,i))
try:
item_all=item_all|dicts_to_dictsString(req.json()['items'])
except KeyError:
return item_all
return item_all
if __name__ == '__main__':
try:
strings=list(search_to_git(argv[1]))
print_to_csv(argv[1]+'.csv',strings)
except IndexError:
print('''exemple:
./git_search_info keyword_for_search out_file
''')
Запускаем скрипт
python3 git_repo_search.py osintполучаем
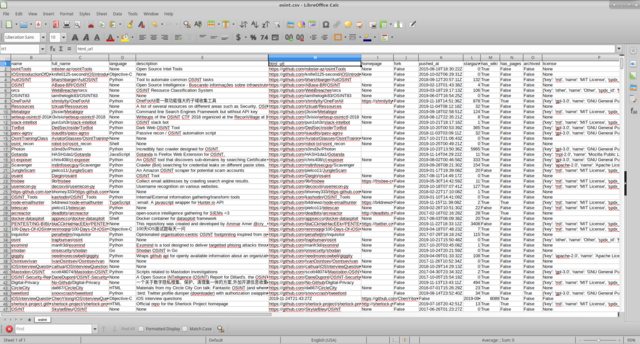
мне кажется так работать с информацией удобней, предварительно скрыв ненужные столбцы.
Код тут
Надеюсь кому-то пригодится.
