Привет. Меня зовут Тигран Петросян, я ведущий инженер по технической поддержке Docsvision, и сегодня расскажу о применении технологии MS SQL AlwaysOn. Это вторая статья из мини-серии «Масштабируемость системы ECM на предприятии», в которой первая статья моего коллеги была посвящена технологии масштабирования поиска Elasticsearch.
Оба материала могут быть интересны не только тем, кто работает с Docsvision, но и всем, интересующимся технологиями масштабирования.
Последняя версия СЭД/ECM платформы Docsvision, разработкой которой мы занимаемся, отличается принципиально от предыдущих версий своей модульной архитектурой. Было важно обеспечить возможность масштабировать систему (причём практически неограниченно) с сохранением скорости работы. Одна из технологий, положенных в основу новых возможностей платформы, — MS SQL AlwaysOn.
Мои коллеги уже рассказывали о технологиях масштабирования, положенных в основу новых возможностей платформы: есть серия из 4-х мини-вебинаров на YouTube, серия из 3-х статей на Medium (статья №1, статья 2, а статья №3 как раз посвящена теме масштабирования БД). В этих материалах более чётко обозначено, какие проблемы мы решали и чего достигли в их решении.
Я же рассмотрю одну конкретную функцию MS SQL AlwaysOn, повышающую надёжность и производительность сервера БД.
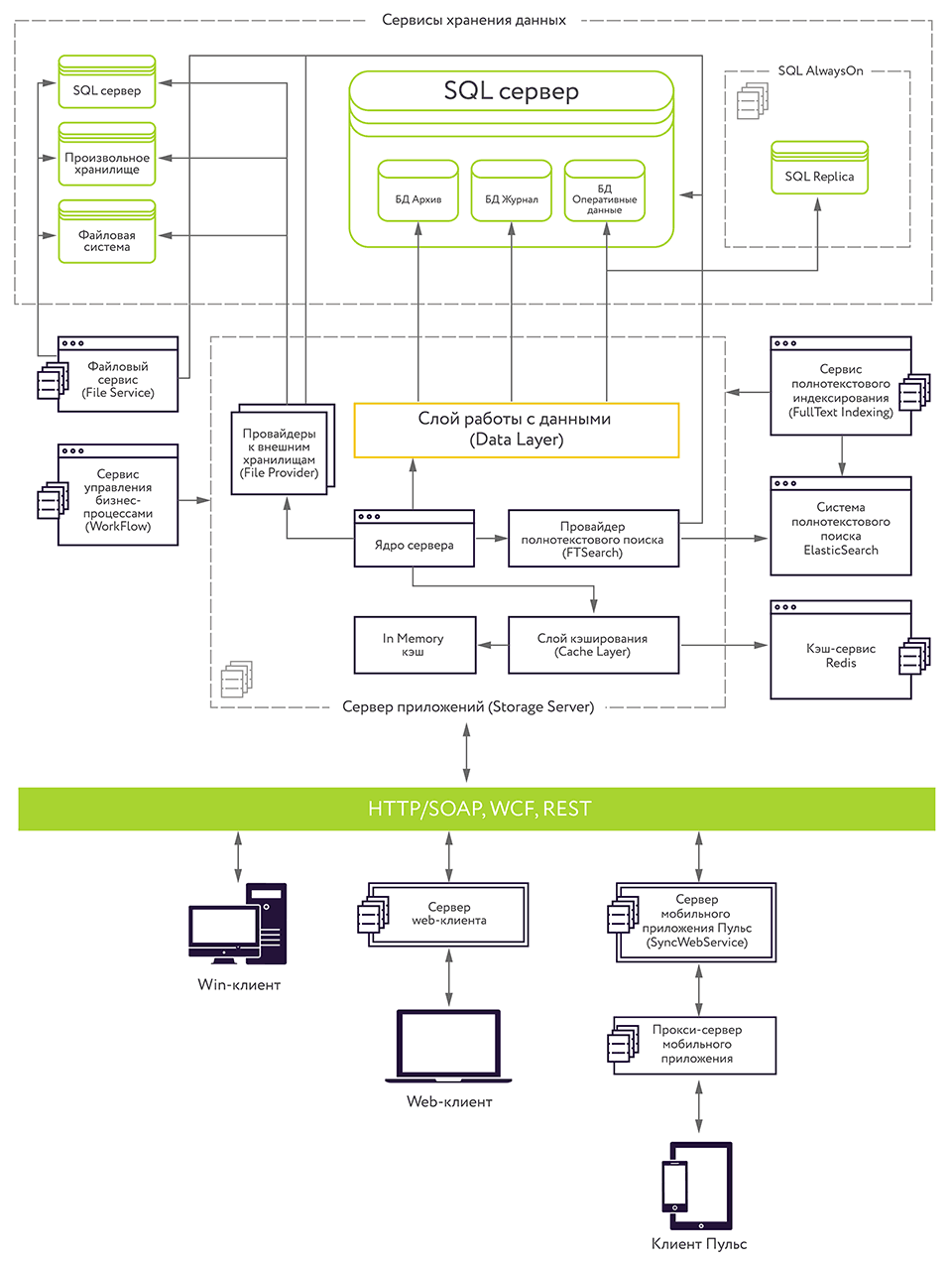
Рис. 1. Сегодня архитектура платформы Docsvision выглядит так.
В инструменты повышения производительности и масштабирования сервиса базы данных нашей платформы Docsvision вошла возможность создания кластеров серверов БД. Эту возможность обеспечивает технология MS SQL AlwaysOn.
Группы доступности AlwaysOn в рамках БД Docsvision может выполнять сразу две задачи:
Принцип работы режима Always On заключается в создании кластера серверов, среди которых выбирается:
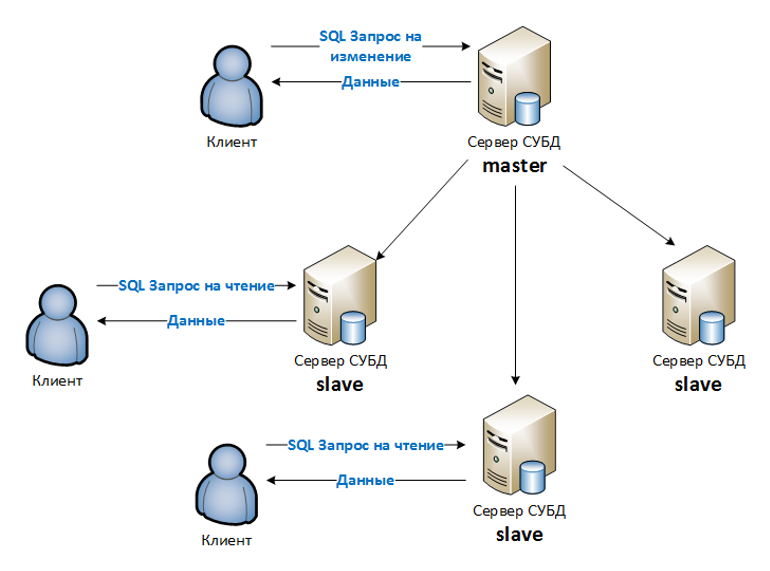
Рис. 2. Распределение нагрузки между серверами.
Как видно на схеме, мы распределяем именно нагрузку на чтение, поскольку подавляющая часть операций пользователей в системе — это операции чтения (поиск, отчёты, открытие документов).
В ходе тестирования изначально master-сервер у нас был мощнее, чем slave-сервер. Однако, при преодолении цифры примерно в 40 тысяч пользователей, мы увидели, что slave-сервера не справляются, а master, наоборот, недогружен. Это было практическим подтверждением того, что запросов на чтение больше, нагрузки они генерят больше, поэтому в первую очередь мы распределяем её между узлами.
При работе режима Always On различают несколько видов запросов пользователей:
Особенности работы slave-серверов:
Использование технологии MS SQL Always позволяет плавно увеличивать серверные мощности и распределять повышенную нагрузку. На тестах мы добились нагрузки 100 000+ одновременно работающих пользователей, во многом именно благодаря масштабированию на уровне БД.
Буду рад ответить на вопросы.
Оба материала могут быть интересны не только тем, кто работает с Docsvision, но и всем, интересующимся технологиями масштабирования.
Пара слов о том, почему мы об этом говорим
Последняя версия СЭД/ECM платформы Docsvision, разработкой которой мы занимаемся, отличается принципиально от предыдущих версий своей модульной архитектурой. Было важно обеспечить возможность масштабировать систему (причём практически неограниченно) с сохранением скорости работы. Одна из технологий, положенных в основу новых возможностей платформы, — MS SQL AlwaysOn.
Мои коллеги уже рассказывали о технологиях масштабирования, положенных в основу новых возможностей платформы: есть серия из 4-х мини-вебинаров на YouTube, серия из 3-х статей на Medium (статья №1, статья 2, а статья №3 как раз посвящена теме масштабирования БД). В этих материалах более чётко обозначено, какие проблемы мы решали и чего достигли в их решении.
Я же рассмотрю одну конкретную функцию MS SQL AlwaysOn, повышающую надёжность и производительность сервера БД.
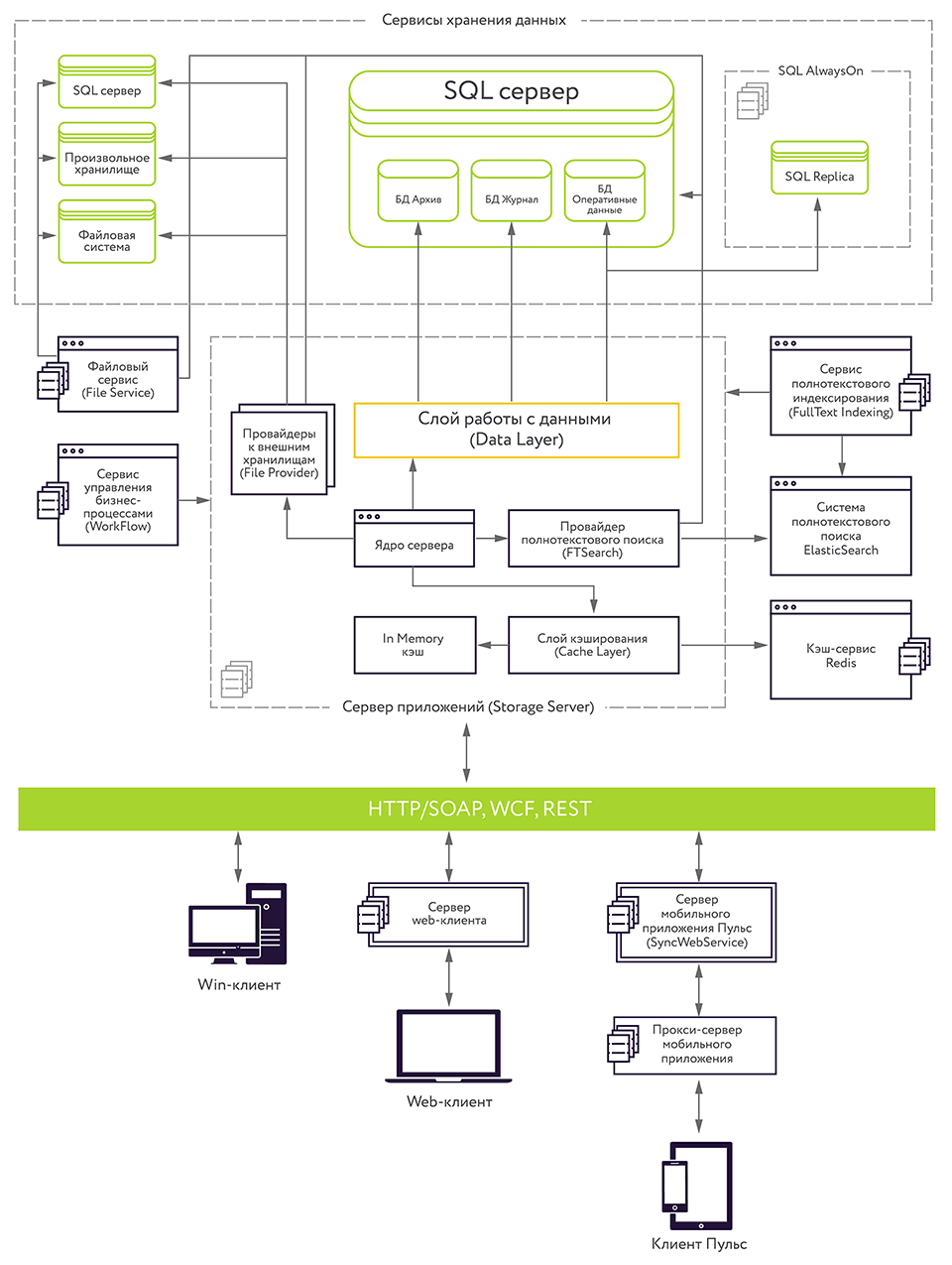
Рис. 1. Сегодня архитектура платформы Docsvision выглядит так.
Масштабирование сервиса баз данных. MS SQL AlwaysOn
В инструменты повышения производительности и масштабирования сервиса базы данных нашей платформы Docsvision вошла возможность создания кластеров серверов БД. Эту возможность обеспечивает технология MS SQL AlwaysOn.
Группы доступности AlwaysOn в рамках БД Docsvision может выполнять сразу две задачи:
- Высокий уровень доступности обеспечивает бесперебойную работу системы;
- Нагрузка по чтению из БД частично выполняется на репликах.
Принцип работы режима Always On заключается в создании кластера серверов, среди которых выбирается:
- Master-сервер – основной сервер, который фиксирует все изменения в системе (чтение, запись);
- Slave-сервер – репликационный сервер, который дублирует все изменения в системе, но доступен только для чтения. На каждом репликационном сервере хранится БД (Metadata) для хранения промежуточных данных для работы поисковых запросов и представлений.

Рис. 2. Распределение нагрузки между серверами.
Как видно на схеме, мы распределяем именно нагрузку на чтение, поскольку подавляющая часть операций пользователей в системе — это операции чтения (поиск, отчёты, открытие документов).
В ходе тестирования изначально master-сервер у нас был мощнее, чем slave-сервер. Однако, при преодолении цифры примерно в 40 тысяч пользователей, мы увидели, что slave-сервера не справляются, а master, наоборот, недогружен. Это было практическим подтверждением того, что запросов на чтение больше, нагрузки они генерят больше, поэтому в первую очередь мы распределяем её между узлами.
При работе режима Always On различают несколько видов запросов пользователей:
- Запрос отчета. В случае, если у отчета, хранящегося в БД, выставлен признак «Read Only», сервер приложений берет информацию по запросу, хранящуюся на одном из slave-серверов, не нагружая master-сервер работой. Если же у отчета не указан признак «Read Only», то сервер приложений отправляет запрос на master-сервер, т.к. в данном случае будут вноситься изменения в БД.
- Получение данных карточки. В данном случае используется временная метка «Timestamp», которая присваивается каждой карточке при внесении в нее изменений. При каждом новом изменении в карточке счетчик «Timestamp» повышается. При запросе карточки выбирается место чтения, в котором метка «Timestamp» у карточки имеет наивысшее значение: из распределенного кэша (если там тот же Timestamp), какой-то из реплик (если Timestamp реплики больше Timestamp карточки – это означает, что на реплику уже переданы актуальные данные карточки), иначе – с мастера. Если карточка изменялась в текущей сессии, и информация о ней хранится в кэше, система смотрит значение метки «Timestamp» в кэше, а затем ищет на slave-серверах и master-сервере нужную карточку, у которой «Timestamp» соответствует значению в кэше.
- Выполнение поисковых запросов, работа с представлениями. При выполнении данных запросов сервер приложений получает информацию с одного из slave-серверов из области БД «Metadata» (хранилище временной информации о работе поисковых запросов и представлений). Выбор slave-сервера для работы с представлением фиксируется в кэше и при загрузке новых страниц представления и использования остальных методов, которые работают с поисками и представлениями, используется выбранный сервер.
Особенности работы slave-серверов:
- Сервер приложений хранит счетчик вызова каждого slave-сервера, значение которого увеличивается при каждом новом запросе к реплике. Для оптимальной нагрузки и скорости работы серверов используется алгоритм Round Robin, т.е. при каждом новом запросе отчета, представления, поиска выбирается slave-сервер с минимальным счетчиком вызова.
- При репликации существует задержка, связанная со скоростью работы сети. При настройке режима Always On можно задать приемлемое время этой задержки и период проверки соответствия реальной задержки работы slave-сервера заданному значению. Если реальное значение превышает заданное, то slave-сервер становится временно недоступным для запросов. При следующей проверке, если реальное значение задержки будет соответствовать заданному значению, slave-сервер вновь станет доступным для запросов.
- Выполнение запросов к БД может быть перенаправлено с master-а на slave при использовании следующих методов:
- GetCardXmlData – серверный метод, возвращает XML запрошенной карточки;
- SectionReadRowsData – серверный метод, возвращает содержимое строки секции карточки;
- SearchCreateProcessor – все методы поисков;
- ViewCreateProcessor – все методы представлений;
- CardGetState – возвращает состояние карточки;
- ReportGetData – получает результат выполнения отчета;
- RowGetData – возвращает содержимое строки секции карточки;
- RowGetHierarchy – возвращает идентификаторы всех родительских строк в секции для подчиненной строки;
- CardGetType – серверный метод, возвращает тип карточки;
- SessionGetIdList;
- UserGetInfo.
Использование технологии MS SQL Always позволяет плавно увеличивать серверные мощности и распределять повышенную нагрузку. На тестах мы добились нагрузки 100 000+ одновременно работающих пользователей, во многом именно благодаря масштабированию на уровне БД.
Буду рад ответить на вопросы.
