"Много инструментов для отладки не бывает!" - подумал топикстартер, выполняя в терминале
go mod initи предвкушая более чем тривиальный, но тем не менее любопытный пет-проект.
Как показывает собственный опыт - если разработчик пишет код, который взаимодействует с внешним миром, то закон Мерфи сработает быстрее, чем хотел бы того этот самый разработчик. И дело даже не в том, что в этом случае появляются зависимости от доступности внешнего мира и стороны принимающей данные - часто ошибки появляются на стороне кода отправляющего данные из-за недостаточной его проверки, полагаясь на "ну, код вроде выглядит нормально, да и unit-тест есть на это". Но должного ли качества этот самый тест, и фиксирует ли он то, что надо? А что будет, если состав данных будет совсем не такой, как в тесте?
В этот момент появляется желание посмотреть "так что же на самом деле отправляет my-awesome-lib?", и если это желание возникает и у тебя, мой дорогой читатель, и отправка происходит посредством протокола HTTP - то, возможно, у меня для тебя есть "ещё одна тулзовина для отладки HTTP запросов" в твою коллекцию.
Предыстория проекта
Разумеется что такие штуки уже есть в сети, например - webhook.site (MIT, self-hosted/premium cloud versions), webhookapp.com (cloud only), requestbin.com (cloud only). Но почти всё, что попадалось на глаза - требовало регистрации, редко что можно было запустить "у себя" (да и внешний вид не очень радовал глаз).
Разумеется, что потребность в таком инструменте у меня возникла довольно остро и в самый неожиданный момент. Нужно было быстро что-то поднять и отдать своей команде в пользование, так как именно в тот момент реализовывали модуль внешней интеграции по HTTP, и его нужно было отлаживать перед боем. Тогда выбор остановился на проекте webhook.site, и в процессе его поднятия "у себя" было выявлено несколько неприятных моментов, а именно:
Проект написан на PHP (ничего не имею против PHP, он всё ещё довольно динамично развивается, и для ряда задач он является просто отличным инструментом), но его применимость именно для такого проекта вызывает некоторые вопросы
Необходимость в 3rd party solutions для уведомлений браузера о том, что произошло событие в приложении ("пришел" новый запрос и его необходимо отобразить) силами
pusher.comилиlaravel-echo-serverНеобходимость в
nginx+php-fpmдля обслуживания HTTP запросов несколько усложняют его быстрый запуск, так как контейнеры нужно между собой связать да в нужном порядке запустить, а потом ещё и мониторить ихНеудобство в настройке (субъективно)
Суммарный вес всех необходимых образов и потребляемые ими CPU + RAM вызывали некоторую печаль
Но не смотря на все эти недостатки - проект выглядел очень удачным! Спустя довольно короткое время после его успешного запуска и был выполнен в терминале go mod init , после чего томными вечерами в любимой IDE появлялась имплементация этого-же проекта, включающая весь базовый функционал но уже на Go + Vue.js со стороны front-end.
Особенности реализации
В этой части поста я хотел бы поделиться мыслями относительно подходов, что были применены в этом простом проекте. Скорее всего, их понимание будет затруднено отсутствием возможности их обсуждения "как на code-review ветки с фичей", но я постараюсь донести основные мысли (если в комментариях вы выскажете свои веские и аргументированные замечания по их поводу - я буду чертовски признателен).
InMemory имплементации внешних зависимостей. Если есть какая-либо служба, от которой зависит работоспособность приложения - очень желательно иметь её "альтернативный" вариант, который работает только с памятью "внутри" вашего приложения. Например - хранилище данных имеет имплементацию что пишет и читает данные в Redis, и рядом с ней - что использует только память. Декларативное качество хранилища при использовании 1+N (N >= 1) имплементаций возрастает в разы, тестирование становится простым и понятным, и в unit-тестах когда нам нужно передать "что-то, что умеет читать или писать в хранилище" - мы смело "подсовываем" нашу inmemory имплементацию. Более того, реализация работы inmemory выступает в роли спецификации "что мы вообще хотим от хранилища", и у нас появляется приятный бонус при запуске приложения в режиме single-node (не кластере, а именно в единичном экземпляре) - не надо поднимать никакие дополнительные зависимости, всё есть "из коробки". Естественно что это не всегда применимо (особенно когда от хранения требуются сложные транзакции), но если возможность реализации inmemory имеется - вы вряд ли пожалеете что потратили на неё своё время.
HTTP пробы /live, /ready ; /metrics в формате prometheus. Они должны быть всегда, если ваше приложение умеет в HTTP (а если не умеет - то подумайте о том, чтоб научить). /live может всегда возвращать 200 код, что означает "я запустился, но могу ли обрабатывать трафик - не знаю", /ready же возвращает 200 код только тогда, когда хэндлер этой пробы убедится в доступности всех зависимых служб (СУБД, exchanges, etc), что означает "я всё проверил и смогу обрабатывать трафик". Про метрики уточнять, думаю, не требуется - они должны быть всегда, хотя бы просто данные рантайма. Классным подходом ещё можно считать возможность запуска сервера pprof на отдельном порту, если приложение запускается, например, с флагом --debug, но в этом проекте этого не реализовывал (возможно сделаю позже). Запускать пробы и метрики на отдельном порту или "основном" - тема дискуссионная (считаю что лучше на отдельном, но для этого проекта этим пренебрёг).
Docker образ, основанный на scratch(distroless). От образа мы хотим наше приложение, а не дистрибутив Linux, в который оно доставлено. Это не только малый вес итогового образа, но и "однозначность" окружения, от которого зависит работа нашего приложения. Да, у вас не будет возможности где-то на проде выполнить docker exec -ti container-hash sh и "поковыряться" там, но если у вас такие необходимости возникают то, возможно, вы делаете что-то не так. И так же не забывайте использовать не привилегированного пользователя, где это только только возможно.
Конфиги. Ох, сколько же копий сломано сторонниками кланов "только флаги", "только файлы", "только внешние хранилища" в междоусобных войнах.. Для себя вывод сделан следующий - "делай так, как надо тебе сейчас и в чуть-чуть обозримой перспективе". Сперва всё делается на флагах, если их не хватает - то те штуки что флагами описывать сложно - переезжают в конфиг; и только когда ops-товарищи попросят что-то придумать для управления ими отдельно от манифестов деплоя - тогда выносить куда-то. Так как этот сервис простой и настройки с использованием флагов достаточно - всё сделано при их помощи (значения флагов всегда могут быть перекрыты переменными окружения).
Front-end на Vue.js без необходимости в сборщике. Так как не являюсь front-end разработчиком от слова совсем, но очень хочется "реактивности" и компонентного подхода - был использован http-vue-loader - он позволяет очень быстро и просто, не вникая в то "как, чем, и с какими конфигами собирать фронты" получить всю силу Vue прямо в браузере. Это кажется каким-то безумием, что браузер сам загружает .vue файлы и их успешно использует. Применимо это, естественно, только для совсем небольших SPA проектов, и здесь он в очередной раз пришелся как никогда кстати. В устаревших браузерах он работать будет вряд ли, но их ниша крайне мала, поэтому ими пренебрёг.
Обслуживаем WebSocket соединения самостоятельно. Так как это первый проект, где вебсоветы были имплементированы с обоих сторон самостоятельно - полученное удовольствие описать сложно. Для этого проекта не требуется ни pusher, ни socket.io - весь функционал есть "из коробки".
Как им пользоваться?
Для начала, его необходимо запустить:
$ docker run --rm -p 8080:8080/tcp tarampampam/webhook-tester:X.X.X serveВ качестве
X.X.Xукажите версию приложения (тег docker-образа), полный список которых можно найти по этой ссылке.
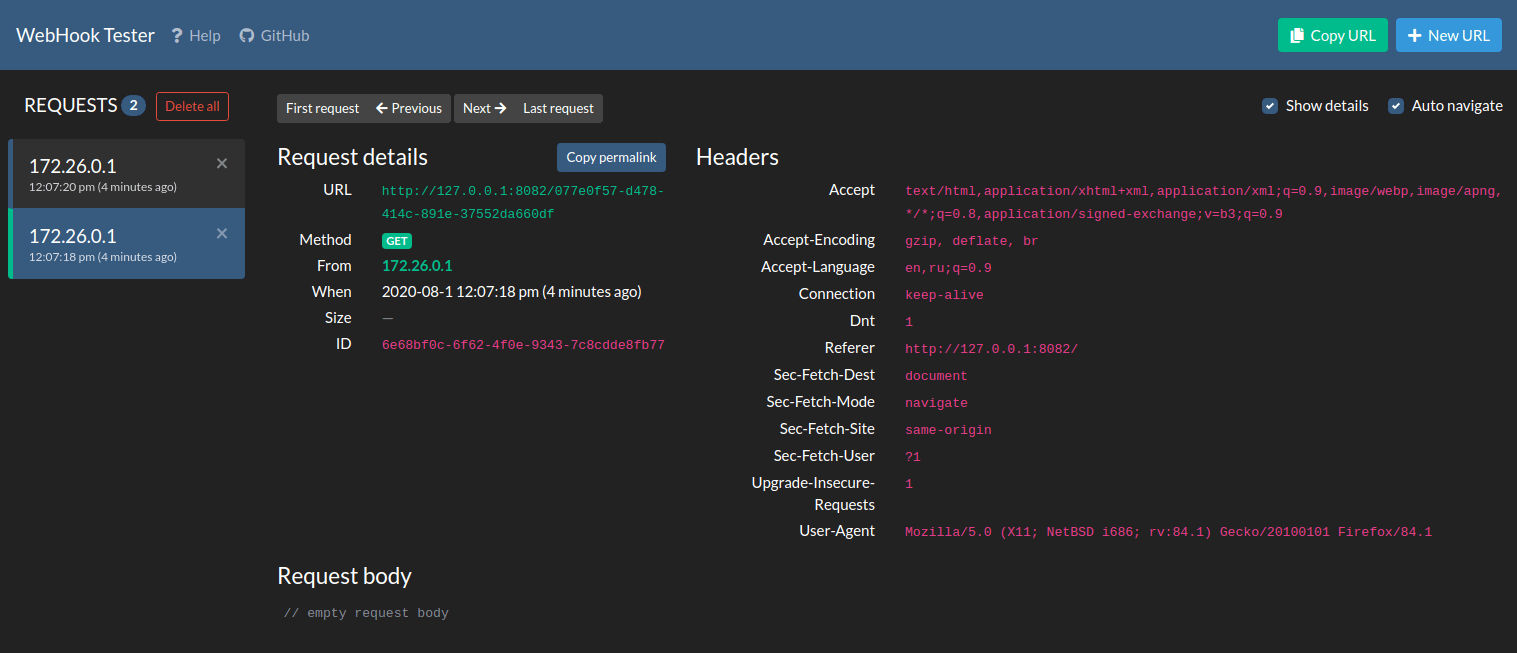
После этого нужно открыть в браузере http://127.0.0.1:8080/ и вуа-ля! Для вас уже создана сессия и вы можете отправлять HTTP запросы по уникальной ссылке для того, чтоб визуально посмотреть "а что там было фактически отправлено":

Другими словами - если у вас есть некоторый участок кода, который должен обращаться по HTTP к 3rd-party сервису, то укажите в качестве точки обращения к этому сервису полученный URL из приложения, и запускайте свой код.
Вы можете кастомизировать контент ответа и HTTP код по своему усмотрению (он может быть указан и в URL запроса - порою это удобнее чем пересоздавать сессии). Можете выставить и задержку ответа, тем самым имитируя сетевые задержки, и смотреть как ваш код на них реагирует "на самом деле" (не падает ли по таймауту, и корректно ли его обрабатывает).
Если захотите запустить его в нескольких экземплярах за балансировщиком нагрузки - вам понадобится Redis сервер (укажите storage и pubsub драйверы redis), конфигурация подробно описана в readme файле проекта.
Docker-образ с приложением весит (в сжатом виде) всего ~4.4 Mb, а само приложение очень аскетично к потребляемым ресурсам.
Все детали всегда могут быть найдены в репозитории проекта - tarampampam/webhook-tester, а поиграться с демо можно тут - web.hook.sh.
Вместо заключения
Проект абсолютно бесплатный, и распространяется под лицензией MIT. Это просто пет-проект, который возможно окажется полезным кому-то ещё. Цель публикации - привлечь внимание к проекту, собрать опыт использования, сделать его лучше.
Если вы найдете какие-то ошибки или недостающий функционал - просто создайте issue в репозитории с ним (используя английский язык, пожалуйста). При наличии возможности обязательно внесу необходимые изменения.
Отдельное спасибо товарищу под ником fredsted за его webhook.site - "делать так-же" было значительно проще, чем придумывать идею с нуля.
UPD: НЛО перенесло этот пост из хаба "Я пиарюсь" в хабы "Разработка веб-сайтов, Go, Управление разработкой"
