У данной статьи тяжёлая история. Мне надо было сделать USB-устройства, не выполняющие никакой функции, но работающие на максимальной скорости. Это были бы эталоны для проверки некоторых вещей. HS-устройство я сделал на базе ПЛИС и ULPI, загрузив туда «прошивку» на базе проекта Daisho. Для FS-устройства, разумеется, была взята «голубая пилюля». Скорость получалась смешная. Прямо скажем, черепашья скорость.
Но я же крутой, у меня теперь есть USB-анализатор (его разработка была описана в блоке из нескольких предыдущих статей). Посмотрев логи, я понял, что похоже, знаю, почему скорость невозможно поднять, даже если STM32F103 обслуживает исключительно USB и ничего больше. Даже начал писать о результатах… Но потом решил, что кому-то это будет не интересно, а кто-то скажет, что и так это знал.
Но неожиданно, с тех пор мне по работе уже трижды приходилось пересказывать эти результаты то Заказчикам, то коллегам. Все они считали, что этот контроллер может больше. И мне приходилось вновь и вновь показывать физическую суть. Поэтому сделать документ было нужно хотя бы чтобы давать его прочесть тем, кто вновь будет говорить, что шина шустрая, контроллер быстрый… Ну, а если и делать документ, то почему бы не оформить его в виде статьи и не выложить на всеобщее обозрение?
Итак, давайте выясним, почему именно STM32F103C8T6 не может прокачать по шине USB данные на скорости 12 мегабит, заняв всю ширину предоставленного канала, и можно ли с этим что-то сделать.
Я буду показывать свои рассуждения шаг за шагом. Возможно, где-то я ошибаюсь, и в комментариях меня поправят (но вроде, всё выглядит довольно правдоподобно), поэтому сущности будут добавляться одна за одной. Начнём с измерительного стенда.
Итак. Чтобы все могли повторить мои действия, я скачал самую свежую на момент написания статьи версию CubeMX – 6.2. Правда, они выходят с такой частотой, что на момент, когда всё будет выложено на Хабр, всё может уже измениться. Но так или иначе. Скачиваем, устанавливаем.
Создаём новый проект для STM32F103C8Tx. Добавляем туда USB-Device.
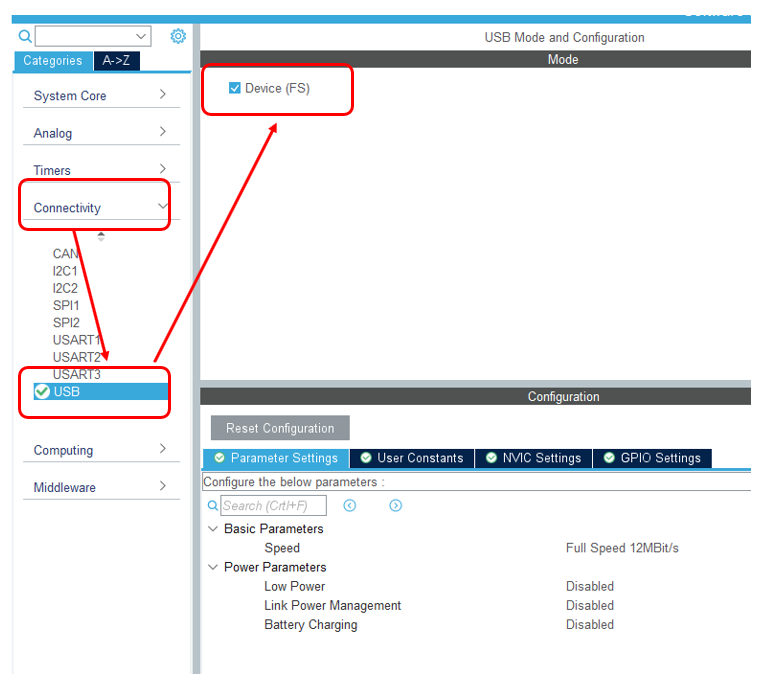
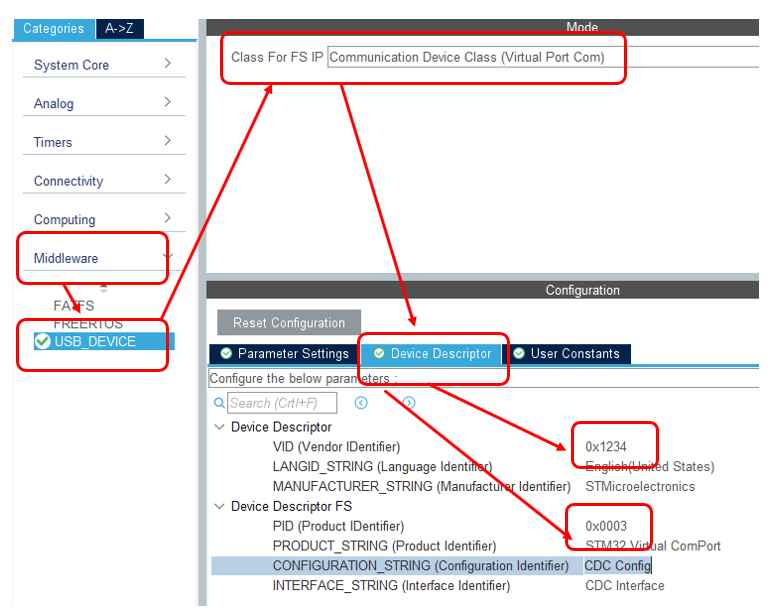
Теперь, когда есть USB, добавляем CDC-устройство. При этом заменим ему VID и PID. Дело в том, что у меня есть inf Файл, который ставит драйвер winusb именно на эту пару идентификаторов. При работе через драйвер usbser скорость была ещё ниже. Я решил исключить всё, что может влиять. Буду замерять скорость без каких-либо прослоек.
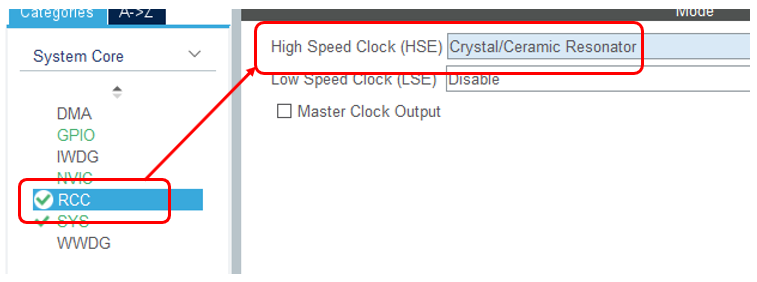
Теперь добавляем RCC для работы с тактовыми сигналами:
После всего этого (добавили USB и добавили RCC) можно и тактовые частоты настроить, но сначала спасём себя от самоотключающегося блока отладки. Он спрятан надёжно! Вот так сейчас всё выглядит по умолчанию:
А вот так – надо
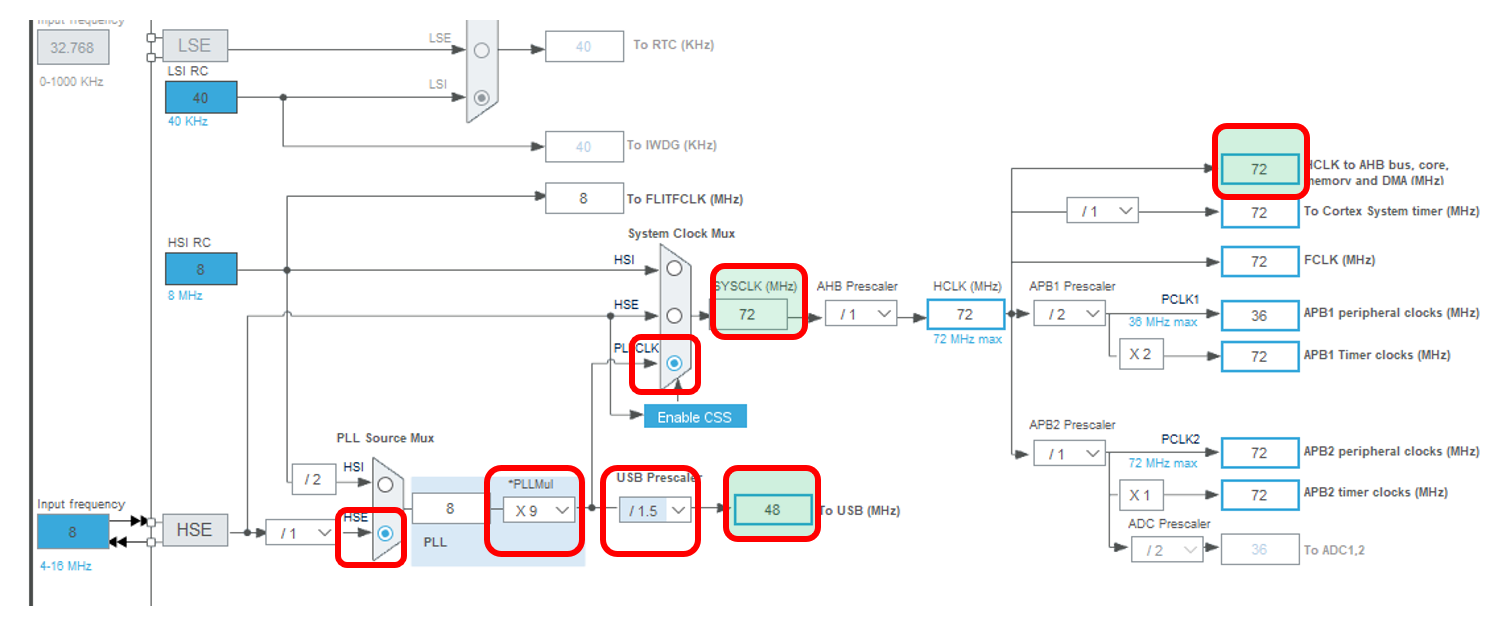
Прекрасно! Теперь можно настроить тактовые частоты. Я всегда это делаю опытным путём. Системная частота должна стать 72 МГц, а частота USB – 48 МГц. Это я в состоянии запомнить. Остальное каждый раз заново вывожу.
Ну всё. Для тестового проекта настроек, вроде, достаточно. Заполняем свойства проекта и сохраняем. Лично я – в формате MDK ARM. Он же Кейл. Мне так проще.
Надеюсь, я ничего не забыл сделать. Я специально показываю все шаги, чтобы внимательная общественность проверила меня.
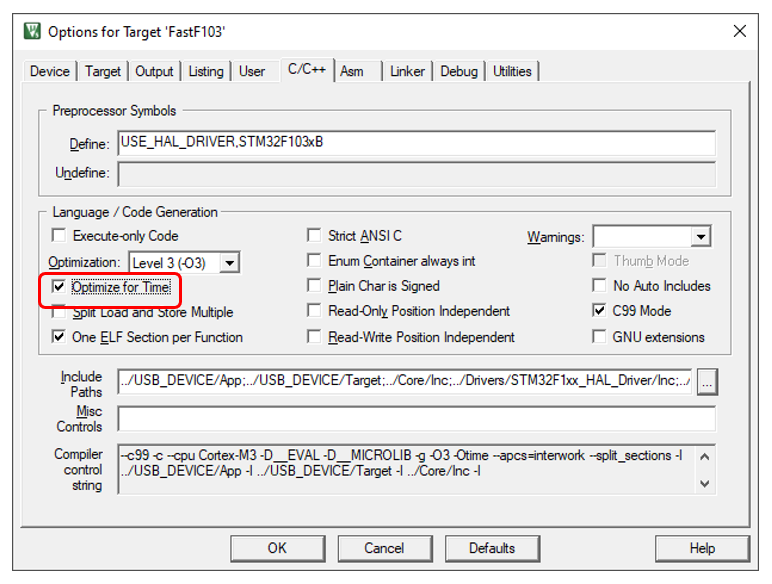
В Кейле я убеждаюсь, что стоит максимальный уровень оптимизации, и дополнительно ставлю оптимизацию по времени. Тогда функции будут по максимуму… Не люблю англицизмы, но инлайниться они будут. А у нас вопросы быстродействия под конец рассуждений выйдут на первое место, так что автоматические инлайны – это то, что нам нужно.
Наш проект должен просто принимать данные из USB и… И всё! Принимать, принимать, принимать! Не будем тратить время на какую-то обработку этих данных. Просто приняли и забыли, приняли и забыли. Обработчик события «данные приняты» в типовом CDC проекте живёт здесь:
А собственно, в текущей версии Кубика всё делается так, что нам и дописывать ничего не надо. Если бы мы хотели обрабатывать приходящие пакеты – да, пришлось бы. А так – для того, чтобы контроллер начал приём нового пакета, уже всё готово. Так что можно собирать первую версию, заливать в контроллер и начинать испытания.
Вариант честной работы с UART мы опустим. Дело в том, что совсем скоро мы будем искать причины тормозов. А вдруг они вызваны драйвером usbser.sys? Нет. Мы возьмём проверенный временем драйвер winusb и будем работать с ним через библиотеку libusb. Кому нравится Linux – сможет работать через эту же библиотеку там. Мы тренировались работать с нею в этой статье. А в этой – учились работать с нею в асинхронном режиме.
Сначала я вёл работу через блокирующие функции, так как их написать было проще. Мало того, черновые замеры, которые я делал ещё до начала работы над текстом, были вполне красивые. Это ещё не всё, первая метрика, снятая для статьи, тоже была прекрасна и полностью отражала черновые результаты! Потом что-то случилось. График стал каким-то удивительным, правда, чуть ниже я эту удивительность объясню. При работе с блоками меньше чем 64 байта программа съедала 25% процессорного времени, а именно на блоке 64 байта был излом. Мне казалось, что кто-то обязательно напишет в комментариях, что сделай я всё на асинхронных функциях, всё станет намного лучше. В итоге, я взял и всё переписал на асинхронный вариант. Процент потребления процессорного времени на малых блоках действительно изменился. Теперь программа потребляет 28% вместо двадцати пяти… Цифры скоростей же не изменились… Но асинхронная работа более правильная сама по себе, так что я покажу именно её. Вся теория уже рассматривалась мною в тех статьях про libusb.
Я завожу всё ту же вспомогательную структуру:
Но, как видно, в ней добавлены параметры «Таймер» и «последнее значение таймера». Дело в том, что момент конца передачи данных удобнее всего ловить в функции обратного вызова. Поэтому она должна иметь и сам объект «таймер», и возможность занести его показания для последующего использования в основной программе.
Ну, и указатели на объекты «передача» имеются, куда же без них:
Функция обратного вызова отличается от описанной в предыдущих статьях как раз тем, что она считывает показание таймера, если передавать больше нечего. Это произойдёт не единожды, а для каждой из передач (тридцати двух в случае мелких блоков, если блоки крупные – их будет меньше, но всё равно не одна). Но на самом деле, это не страшно. Мы это значение будем анализировать только после последнего вызова этой функции. В остальном – там всё то же, что и раньше, так что просто покажу код, не объясняя его. Объяснения все были в предыдущих статьях.
Основная функция имеет одну хитрость. Скорость достаточно сильно плавает. Поэтому я усредняю показания. Последний аргумент как раз задаёт число попыток, за которое следует всё усреднить. Ещё во времена блокирующей работы, разброс скоростей был довольно высок (а потом я просто логику усреднения не трогал). Поэтому я беру все полученные результаты, усредняю их, а затем – откидываю значения, которые существенно отличаются от среднего. И оставшиеся значения – снова усредняю.
Ну, а параметр blockSize у функции – это я в своих статьях уже набил оскомину высказыванием, что при работе с USB скорость зависит от размера блока. До определённого значения она ниже нормальной. Это связано с тем, что хост посылает пакеты медленнее, чем их может обработать устройство. Поэтому я всегда строю графики и смотрю, где они входят в насыщение. Сегодня я буду делать то же самое. Правда, сегодня график в дополнение к банальному росту, имеет непривычную для меня форму, что и сподвигло меня на переделку программы с блокирующего на асинхронный режим. Итак, функция, измеряющая скорость, выглядит так:
Сборку статистики в файл csv я делаю так:
Итак. У нас есть прошитое устройство, у нас есть программа для его тестирования. Строим статистику для разных размеров блока, чтобы быть уверенными, что проблемы не зависят от этого значения.
Где-то после размера блока 4 килобайта, скорость упирается в 560 килобайт в секунду. Давайте я грубо умножу это на 8. Получаю условные 4.5 мегабита в секунду. Условность состоит в том, что на самом деле, там ещё бывают вставные биты, да и на пакеты оверхед имеется. Но всё равно, это отстоит очень далеко от 12 мегабит в секунду, положенных на скорости Full Speed (кстати, именно поэтому на вступительном рисунке стоит знак «120», он символизирует данный теоретический предел).
Будучи человеком вооружённым (не зря же я всех полгода пытал статьями про изготовление анализатора), я взял и рассмотрел детали трафика. И вот что у меня получилось (данные я чуть обрезал, там реально всегда уходит по 64 байта):

И так до бесконечности на всех участках, что я смог осмотреть глазами, возвращается то ACK, то NAK. Причём в режиме FS каждая пачка данных передаётся целиком. Принялась она или нет, а всё равно передаётся целиком. Хорошо, что это не роняет всю шину USB, так как до последнего хаба данные бегут на скорости HS в виде SPLIT транзакции. А дальше – уже хаб мелко шинкует её на пакеты по 64 байта и пытается отослать на скорости FS.
Подобные чередования ACK-NAK я нашёл и в сети, когда пытался проверить, у одного ли меня такой результат. Нет, не у одного.
Причины падения скорости, честно говоря, написаны прямо под носом. А именно – в комментариях к функции, где нам следует вставлять обработку данных. Вот их текст:
Нам честно говорят, что пока мы находимся в этой функции, будет посылаться NAK. Вышли из неё – снова начинается работа шины.
А почему при блоке 64 байта скорость выше? Я долго думал, и нашёл следующее объяснение: 64 байта – это тот размер блока, после которого при работе с FS-устройствами через HS-хабы начинается использование SPLIT-транзакций. Что это такое – можно посмотреть в стандарте, там этому посвящён не один десяток страниц. Но если коротко: до хаба запрос идёт на скорости HS, а уже хаб обеспечивает снижение скорости и нарезание данных на FS-блоки. Основная шина при этом не тормозит.
Выше мы видели, что уже через 5 микросекунд после прихода примитива ACK, пошёл следующий пакет, который не был обработан контроллером. А что будет, если мы будем работать блоками по 64 байта? Я начну с примитива SOF.
Вот и разгадка! Как видим, быстрее – не всегда лучше. Время между пакетами больше. Особенность работы хоста такая.
По этой же причине, если мы воткнём между материнской платой и устройством дешёвый USB2-хаб, марку которого я не скажу, так как сильно поругался с магазином, владеющим именем бренда, но судя по ID, чип там VID_05E3&PID_0608, то статистика окажется намного лучше, чем при прямом подключении к материнке:
Здесь уже скорость стремится к условным семи мегабитам в секунду при любых размерах блока, выше 64 байт. Но всё равно это чуть больше половины теоретической скорости!
Будучи опытным программистом для микроконтроллеров, я знаю, что обычно такая проблема решается путём применения двухбуферной схемы. Пока обрабатывается один буфер, данные передаются во второй. А какая схема используется здесь? Ответ на мой вопрос мы получим из следующего кода:
Тут, везде написано PCD_SNG_BUF. Вообще, в статье про DMA я уже рассуждал, что если разработчики этой библиотеки что-то не используют, значит и не стоит этого использовать. Но всё же, я попробовал заменить SNG_BUF на DBL_BUF. Результат остался прежним. Тогда я нашёл в сети следующее утверждение:
Попробовал разнести точки – результат тот же. В общем, анализ показал, что для точек типа BULK это если и возможно, то только путём переписывания MiddleWare. Короче, не зря там везде одиночные буферы выбраны. Разработчики знали, что делают.
Теперь подойдём к проблеме с уже имеющимися данными, но с другой стороны. Выше в комментариях мы видели, что пока мы находимся в обработчике прерывания, система будет слать NAK. А как велик этот обработчик?
Немного потрассируем код. Давайте я поставлю точку останова в функции CDC_Receive_FS, в которую мы попадаем ради каждого блока в 64 байта или меньше. Ну, потому что транзакции, больше чем на 64 байта, будут разрезаны на пакеты такого размера. Вот такой у нас получается стек возвратов в обработчик прерываний. А это ещё часть функций заинлайнилась!
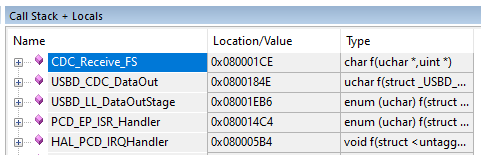
В самой глубокой функции выполняется довольно серьёзная работа. Прочие функции – это просто слои. Каждый слой как-то перекладывает данные (зачем?), после чего – вызывает следующий слой.
Но и это ещё не всё. В функции PCD_EP_ISR_Handler (кстати, в стеке возвратов её не видно, но она есть) мы изымаем данные из FIFO в буфер. В дальнейшем, если бы у нас был свой код, мы бы ещё раз скопировали данные из системного буфера к себе. Имейте в виду, что логичнее сразу задавать указатель на свой массив, двигаясь по нему, благо такая возможность имеется.
Но и это ещё не всё! Ради всё тех же каждых 64 байт, мы вызываем функцию USBD_CDC_SetRxBuffer(), а затем — USBD_CDC_ReceivePacket(), которая также расслоится на кучку вызовов, каждый из которых всего лишь чуть-чуть перетасовывает данные. Оцените стек возвратов, когда мы находимся в самом глубоком слое!
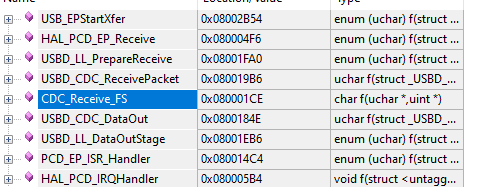
А если вы попробуете рассмотреть код функции USB_EPStartXfer(), то вам совсем станет грустно. А ведь всё это безобразие вызывается ради каждого блока в 64 байта. Вот так 64 байта пробежало – начинается чехарда с многократной (правда, в нашем случае с отсутствующим функционалом — однократной) пересылкой этих данных, а также с вызовом кучи слоёв. Некоторые из них тратят массу тактов процессора на свою важную работу, но некоторые – просто слои. Они просто зачем-то перекладывают байтики из структуры в структуру и передают управление дальше. А такты на это – всё равно расходуются!
Вспоминается жаркий спор, когда во время одного проекта я требовал от архитектора, да и других программистов, не увлекаться расслоением программы. Они там наплодили слоёв «на всякий случай». А на все мои нападки отвечали, что современные вычислительные системы настолько быстродействующие, что всё будет хорошо. Наверное, тут разработчики тоже думали, что всё будет хорошо… Вот и додумались… Но давайте проведём профилирование и узнаем, сколько именно микросекунд ядро находится в обработчике прерывания.
Имея стек возвратов, а также известные времянки посылки транзакций, мы можем проверить всё с другой стороны, чтобы быть уверенными, что нигде не ошиблись. Давайте я на входе в прерывание буду взводить какой-либо порт, а на выходе – сбрасывать. Как всегда, я буду делать это через библиотеку mcucpp Константина Чижова.
Объявим, скажем, ножку Pa0 для этой цели:
За что люблю эту библиотеку, так за её простоту. Инициализация ножки выглядит так:
Включили тактирование аппаратных блоков, назначили ножку на выход. Собственно, всё.
И добавим пару строк в функцию обработки прерывания (первая взведёт ножку в единицу, вторая – сбросит в ноль):

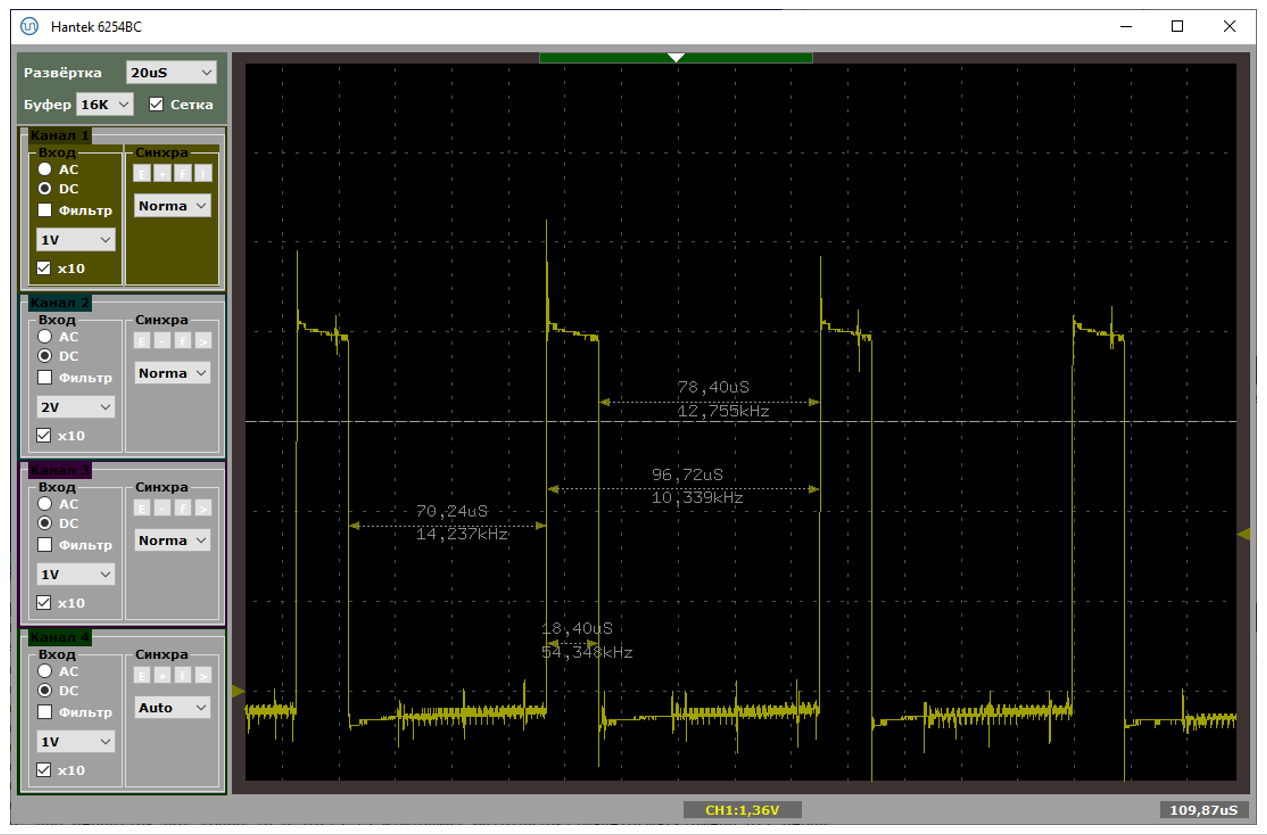
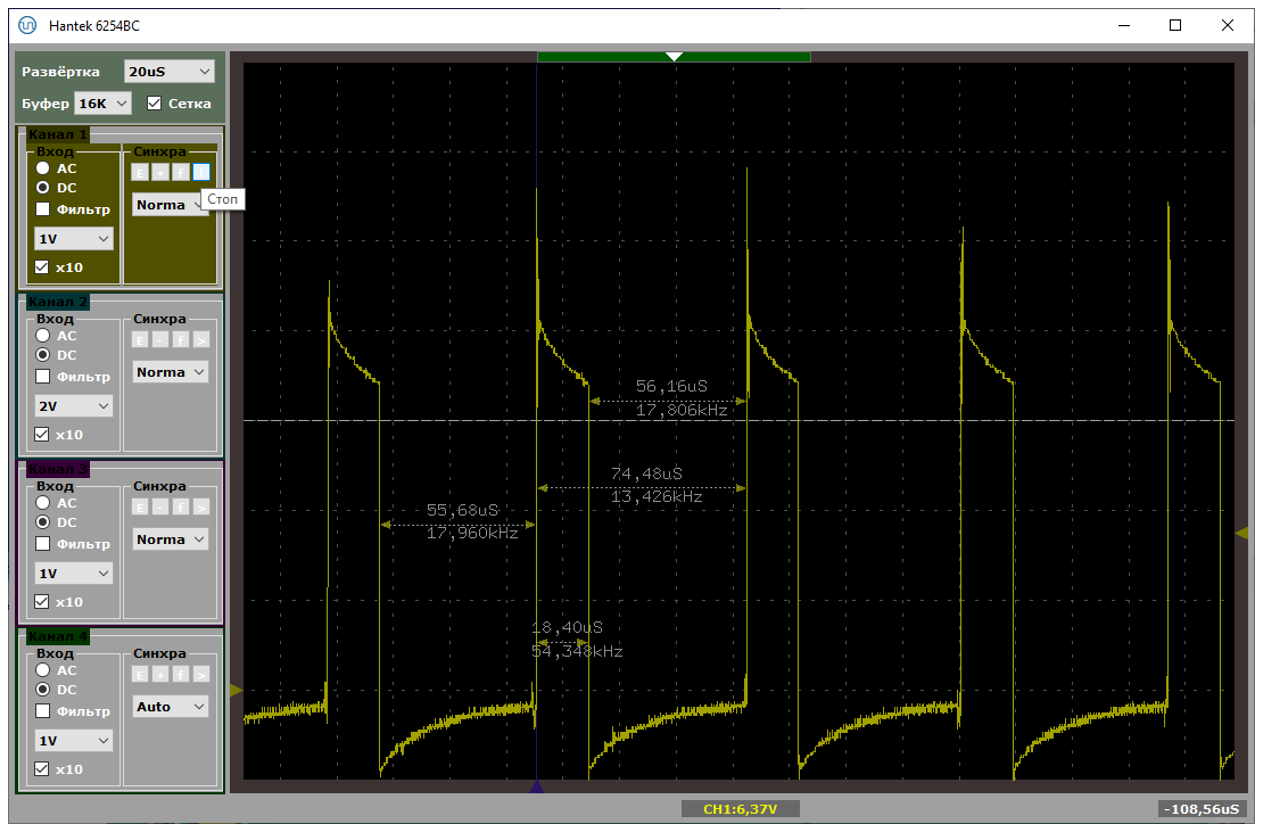
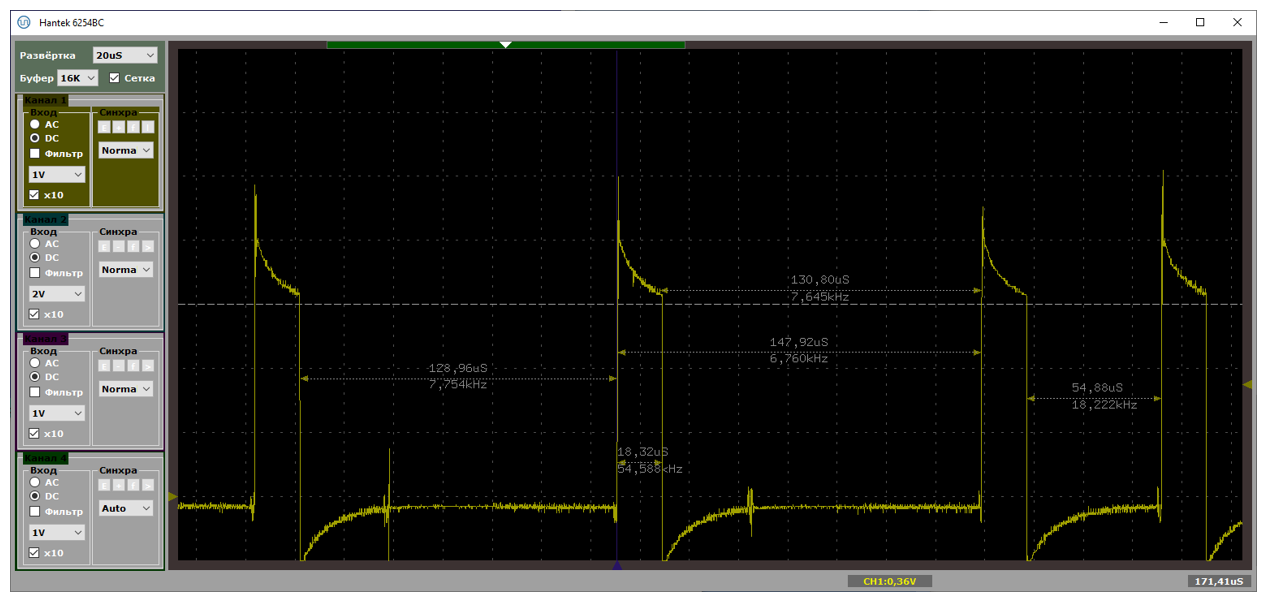
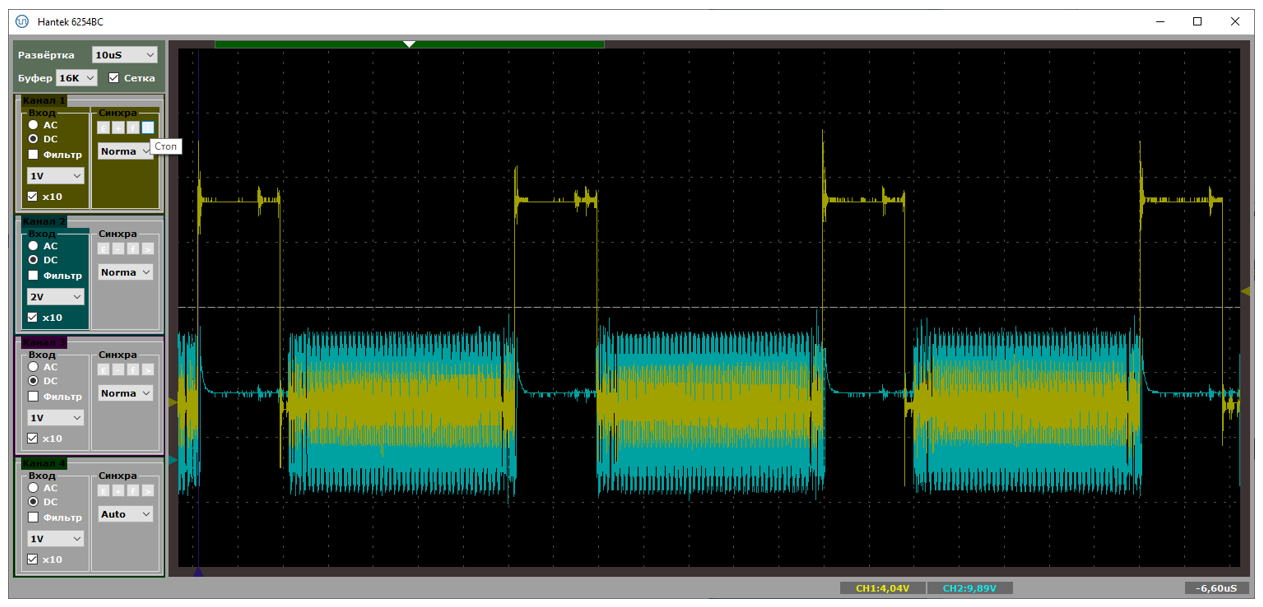
Типичный период следования прерываний – от 70 до 100 микросекунд. При этом в прерывании мы находимся чуть меньше чем 19 микросекунд. На первом рисунке показан случай, когда данные идут помедленнее (расстояния велики), на втором – побыстрее (расстояния меньше). Обе осциллограммы сняты при подключении через хаб.
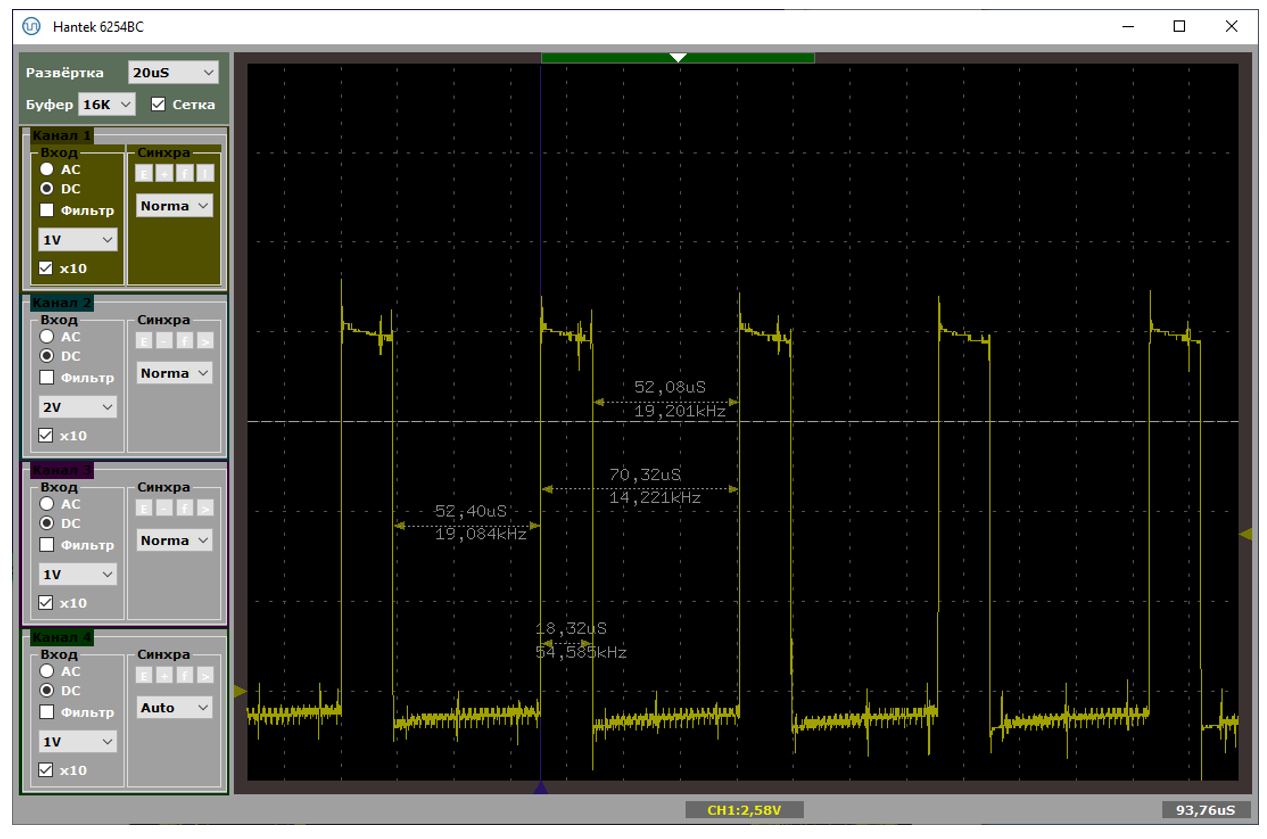
А вот – хорошая и не очень хорошая ситуации, снятые при прямом подключении к материнке. Собственно, на плохом варианте видно, что расстояния удваиваются. Один из пакетов уходит с NAKом, в прерывание мы не попадаем.
Осталось понять, как эти прерывания располагаются относительно USB-примитивов. В этом нам поможет Reference Manual. Момент прихода прерывания я выделил.
Вот теперь всё сходится. После формирования ACKа мы не готовы принимать новые пакеты на протяжении 18 микросекунд. Когда они приходят через 3-5 микросекунд (а именно это мы видим в текстовом логе анализатора выше для плохого случая), контроллер их просто игнорирует, посылая NAK. Когда через 30-40 (что мы наблюдаем в текстовом логе для случая хорошего, хотя, точно подойдёт любое значение, больше чем 19) – обрабатывает.
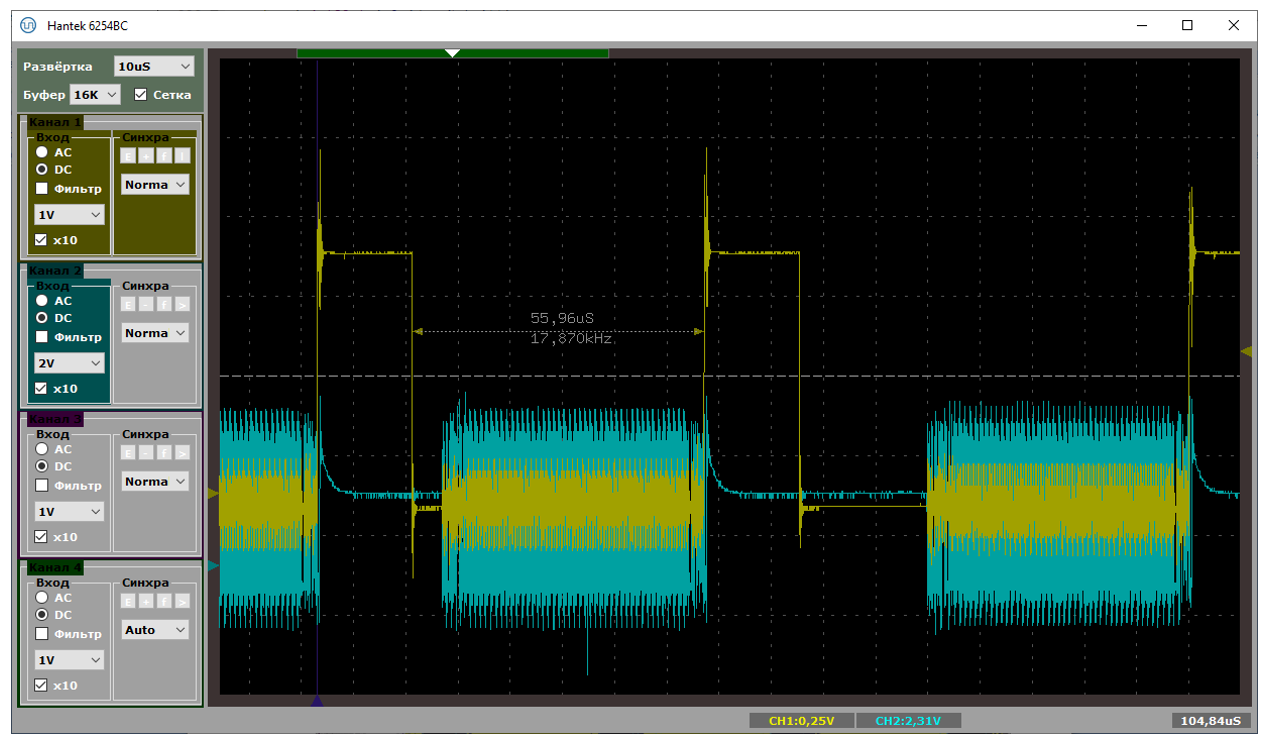
Плюс из текстовых логов мы видим, что влево от прерывания около пятидесяти микросекунд занимает сама OUT-транзакция на аппаратном уровне. Кстати. У нас же скорость FS. Такие сигналы можно ловить обычным осциллографом. Давайте я добавлю активность на шине USB в виде голубого луча. Что получим?
Вот тут мне удалось поймать SOF (в правой части экрана). Видно, что сразу после него начинают идти данные. В конце кадра (то есть, от последнего пакета прошлого кадра до SOFа) имеется тишина (там по стандарту что-то такое требуется).
Вот такая картинка была, когда я получил производительность 814037 байт в секунду. Извините, но быстрее – никак. Либо по шине идут данные, либо мы обрабатываем прерывание. Простоев нет!
Причём 64 байта, с учётом, что я передаю все нули, а значит там может быть вставленный бит – это примерно 576 бит. При частоте 12 МГц их передача займёт 48 микросекунд. То есть, когда между пакетами примерно по 50 микросекунд, мы имеем дело с пределом скорости. Тут даже NAKов нет.
NAKи – вот они, когда хост пытается что-то передавать, пока мы заняты, что совпадает с выводами, сделанными при анализе текстовых логов. Вот тут прямо видны два пакета, первый из которых начался, когда аппаратура ещё не готова его принимать.
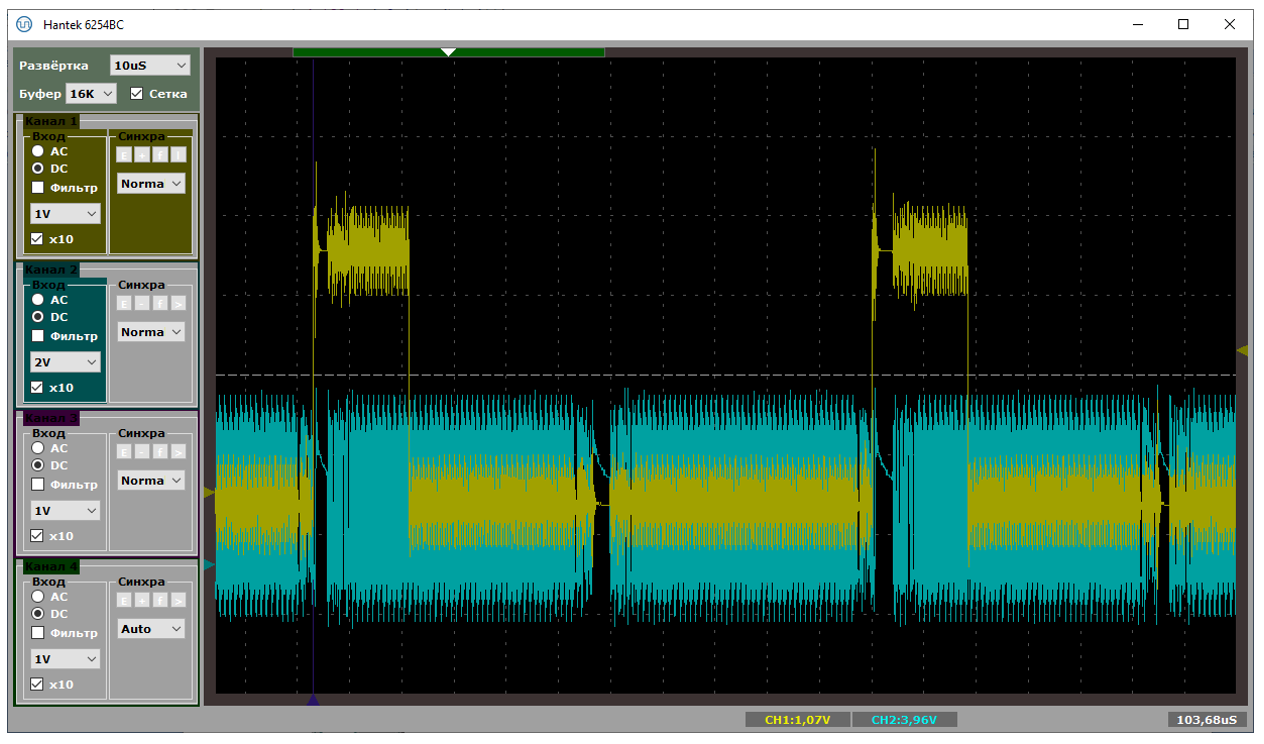
Всё спасла бы двойная буферизация, но она для BULK случая, как я понял из описаний в сети, не работает, так как на аппаратном уровне заложено, что пока находимся в обработчике прерывания – надо слать NAK и всё тут. Только в логике изохронных транзакций этого нет. Поняв всё это, я сумел сформулировать правильный поисковый запрос и нашёл интересную китайскую статью.
Мне показалось, что там они решили проблему, полностью переделав логику работы Middleware USB. Они там рассуждают, что дико сократили время пребывания внутри прерывания. Но если честно, у меня не стояло задачи выжать из этого контроллера всё. Так что я даже сильно не вчитывался в доводы авторов. Правда, при работе через хаб всё попроще. Короче, результаты у китайских специалистов если и есть, они также будут работать только на определённой конфигурации, ведь на паузы от хаба повлиять не сможет никто.
И раз уж я снял осциллограммы, предлагаю посмотреть на процесс, когда пакеты идут по шине, с точки зрения не оптимизатора, а простого программиста. Вот осциллограмма. Единичное значение – контроллер находится в обработчике прерывания. Все остальные задачи в это время не могут работать. Каково?
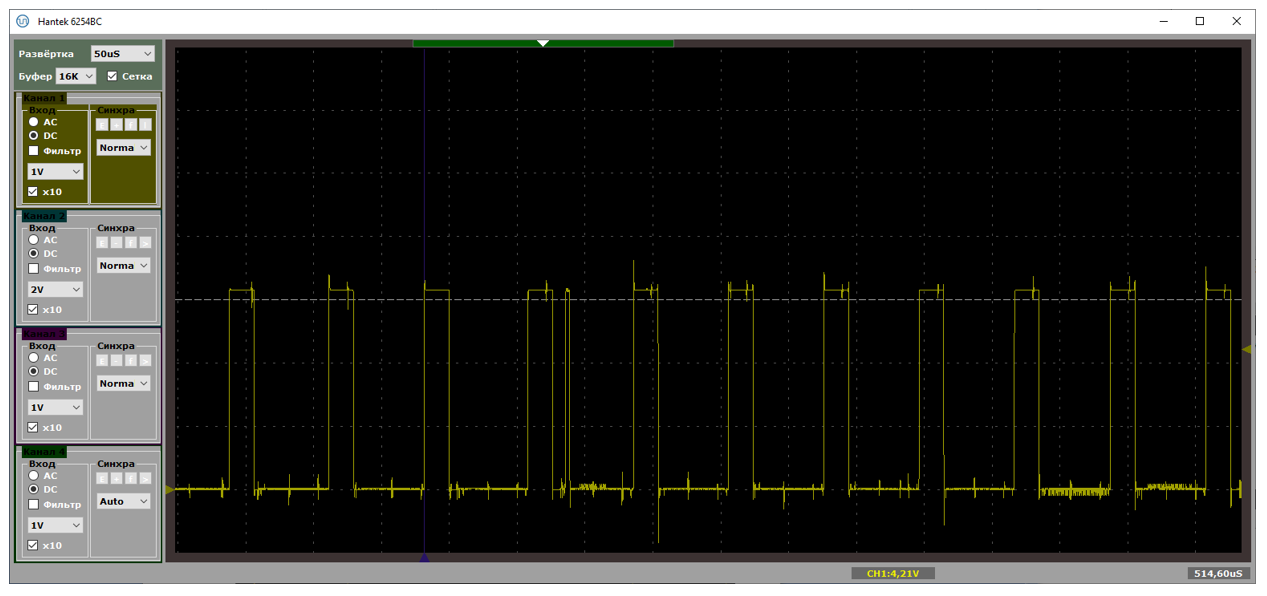
А при коротких пакетах, бывает и такое:
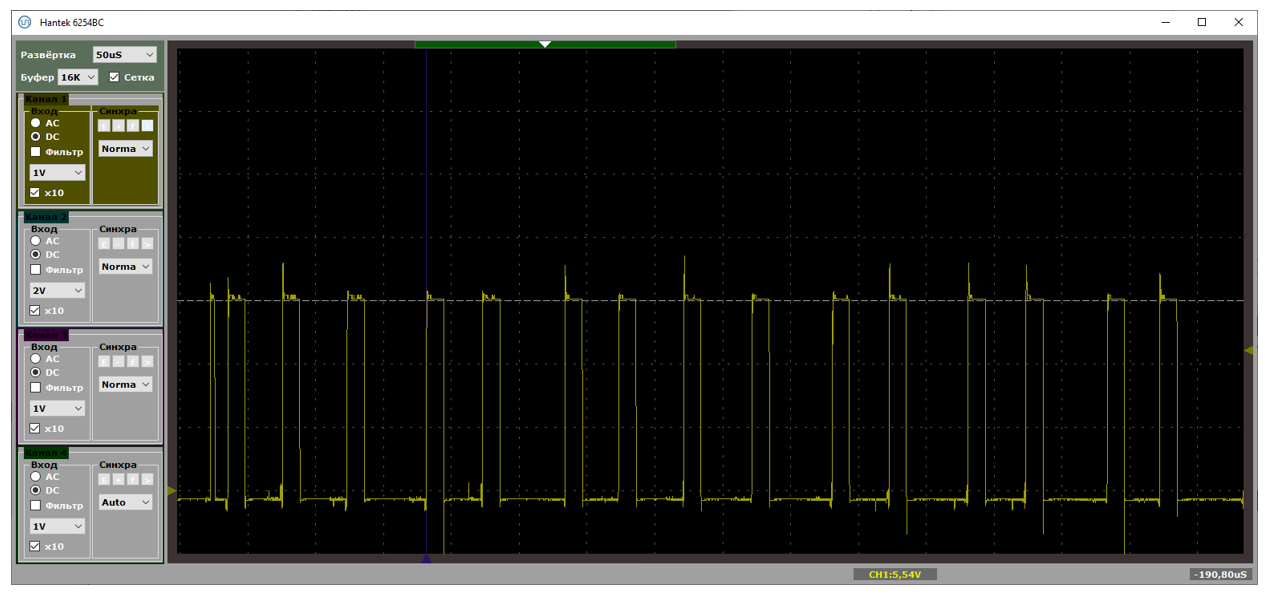
Правда, это только во время передачи данных. Если передача не идёт, мы видим только SOFы (на предыдущей осциллограмме короткая иголка слева – это как раз SOF). Но когда идёт обмен данными, процентов 20 времени контроллер не готов нас обслуживать. Он находится в контексте прерывания. Так что если и обслужит, то только прерывания с бОльшим приоритетом.
Ну что, пришла пора делать выводы. Как видим, контроллер STM32F103C8T6 не может выжать всю производительность даже из шины USB 2.0 FS.
Хорошо это или плохо? Ни то, ни другое. Есть тысяча и одна задача, где не надо гнаться за производительностью USB, и этот копеечный контроллер прекрасно с ними справляется. Вот там его и надо использовать. (Дополнение: пока статья лежала «в столе», на Хабре появилась статья, что уже не копеечный. Цена у местных поставщиков, согласно той статье, выросла в 10 раз. Надеюсь, это временное явление.)
Просто, как я уже отмечал, мне надо было получить материалы, которые я буду предлагать прочесть всем, кто будет пытаться просить меня или кого-то ещё выжать из этой шины все соки на подобных малютках. Не стоит даже надеяться. Сову на глобус натягивать не стоит!
А для производительных вещей я в ближайшее время собираюсь изучить контроллер, у которого USB обрабатывается по стандарту EHCI. Там всё на дескрипторах. Заполнил адрес, длину… Когда пришло прерывание – данные уже готовы… Надеюсь… Если будет что-то интересное – сделаю статью. А здесь сам подход к обработке приходящих данных (они помещаются в выделенную память, а затем – программно изымаются оттуда, причём в контексте прерывания) не даёт развить высоких скоростей. По крайней мере, на кристалле F103.
Следующий вывод: добавленный в систему дешёвый USB-хаб даёт неожиданный прирост производительности. Это связано с тем, что он шлёт пакеты с паузами 20-25 микросекунд (в статье подтверждающий лог не приводится для экономии места, но его можно скачать здесь для самостоятельного изучения). Получаем грубо 20 микросекунд задержки, 50 микросекунд передачи. Итого 5/7 от полной производительности. Как раз 700-800 килобайт в секунду при теоретическом максимуме 1000-1100. Так что любой FS-контроллер, включённый через этот хаб, не сможет выдать больше.
Дальше: видно, что, когда по USB передаются данные, контроллер довольно большой процент времени находится в обработчике прерывания USB. Это также надо иметь в виду, проектируя систему. Прерываниям UART, SPI и прочим, где данные ждать невозможно, а обработка будет быстрой, стоит задавать приоритет выше, чем у прерывания USB. Ну, или использовать DMA.
И, наконец, мы выяснили, что для FS устройств на базе STM32 нет чёткого критерия оптимальной работы со стороны прикладной программы. Одна и та же система, в которую то добавляли, то исключали внешний USB-хаб, работала с максимальной производительностью либо при длине блока 64 байта (без хаба), либо более четырёх килобайт (с хабом). При разработке прикладных программ для PC, требующих высокой производительности, следует учитывать и этот аспект. Вплоть до калибровки параметров под конкретную конфигурацию оборудования.
В комментариях к статье пользователь EddyEm оставил суровый комментарий, что не надо пользоваться библиотеками Кубика. Ну, это я и в основном тексте говорил, но чем пользоваться? Есть у меня привычка, просматривать профили резких комментаторов. И вот, среди его высказываний под другими статьями я нашёл ссылку на такой проект: stm32samples/F1-nolib/CDC_ACM at master · eddyem/stm32samples · GitHub. Он как раз под пилюлю, и не использует сторонних библиотек. Чуть доработал, выкинув всю полезную работу (мои тесты же тоже просто гоняют пакеты, не пользуясь их содержимым), и получил такой результат:
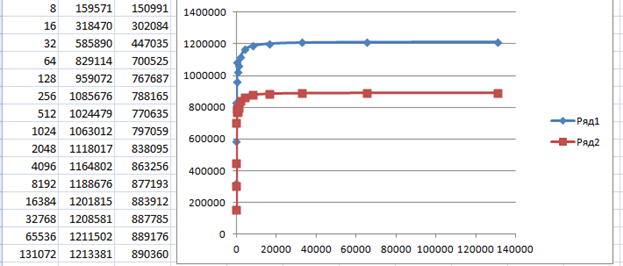
С хабом предсказуемо скорость осталась прежней (коричневый график, последний столбец таблицы), а вот при подключении напрямую к разъёму материнской платы – всё стало замечательно! Потому что российский автор, как и китайские, достаточно быстро выходит из обработчика прерываний. Только там есть лишь описание, а тут – работающий код.
Проверяем по приборам. Вот так выглядит осциллограмма при работе через хаб. Если раньше новые данные упирались в конец обработчика прерывания, то теперь они отстоят от него на огромнейшую дистанцию
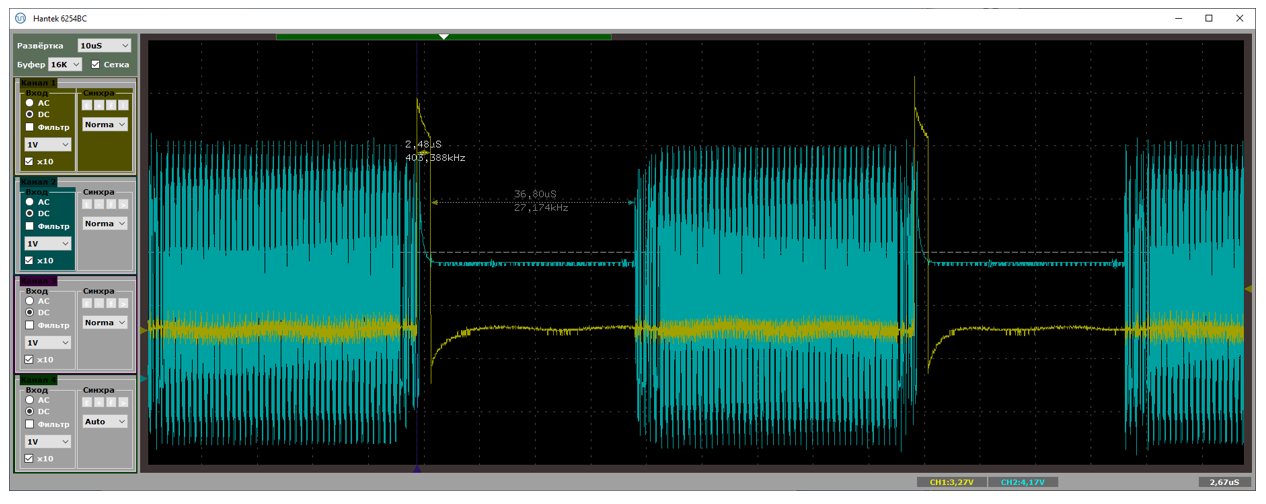
При прямой работе с разъёмом на материнской плате, получаем такую красоту:
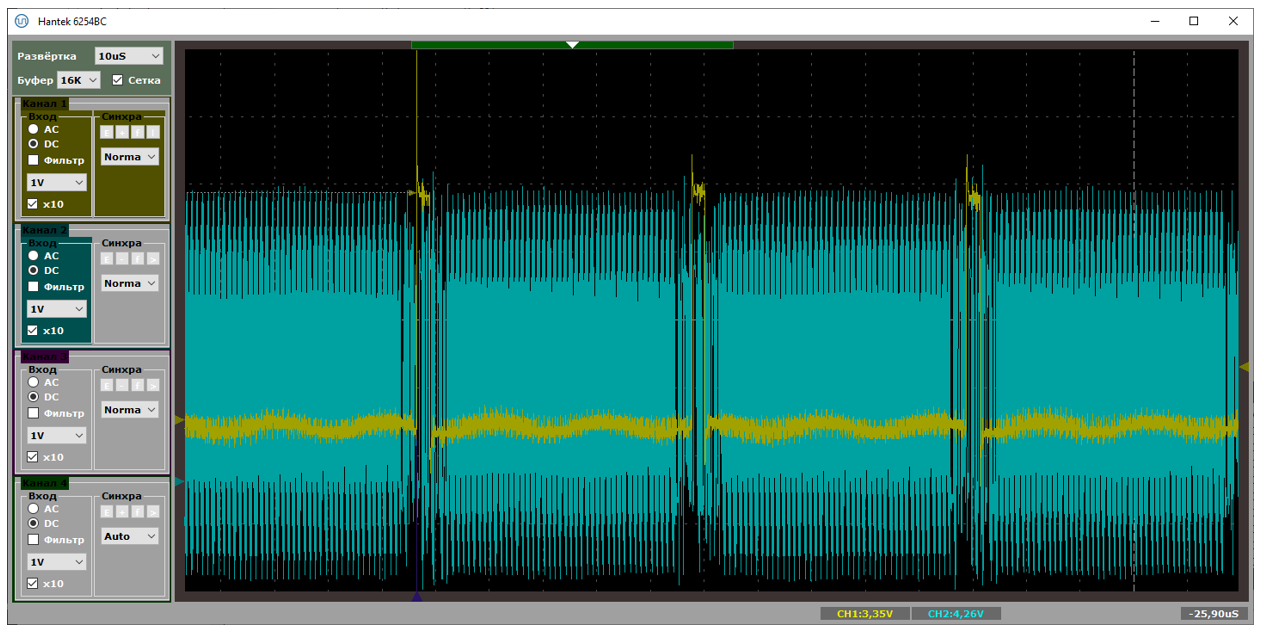
Собственно, мы видим, что полоса используется полностью.
Затем пользователь COKPOWEHEU прислал ссылку на свою библиотеку usb/5.CDC_L1 at main · COKPOWEHEU/usb · GitHub. В целом, она тоже работает. Вот скорости при прямом подключении к разъёму материнской платы:
Но если у первой библиотеки время обработки прерывания занимает две с половиной микросекунды, то тут – на малых блоках – от пяти до шести:
А на больших – могут быть даже десять и одиннадцать микросекунд. Получается вот такая страшная осциллограмма:
Как же это соотносится с тем, что данные спокойно идут во время обработки прерывания? Просто автор реализовал корректную работу с двойной буферизацией. Всё работает исключительно благодаря ей.
В общем, не зря я статью написал. В итоге, теперь есть знание, где живёт и код с минимальным временем нахождения в обработчике прерывания, и код, где обработчик более долгоиграющий, но зато реализована двойная буферизация. Огромное спасибо всем авторам, которые прислали свои варианты библиотек. Теперь ссылки на них будут жить в одном месте. Можно изучать их и либо брать любую, либо создавать что-то на их основе.
Ради интереса приведу результаты, снятые для HS-устройства на базе ПЛИС. Второй столбец – скорость при прямом подключении к материнской плате, третий – через тот самый дешёвый хаб. Мне уже интересно, почему там хаб даёт такую просадку, но с этим я разберусь как-нибудь в другой раз.
А пока статья лежала «в столе», я взял типовой пример CDC-прошивки от NXP, немного доработал его (без доработки он «зависнет» при односторонней передаче), залил в плату Teensy 4.1 и снял метрики там. У него контроллер EHCI и скорость HS.
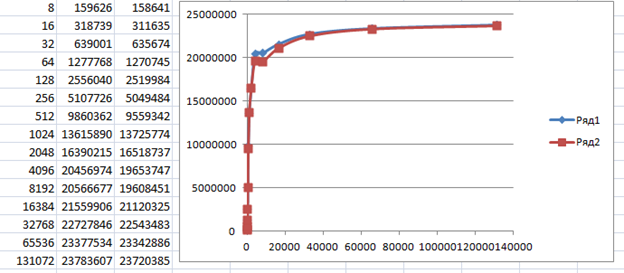
Причина – та же самая. Аппаратура, вроде, позволяет поставить в очередь несколько запросов (как для асинхронной работы), но увы, программная часть это явно запрещает:
Правда, там, за счёт резервов аппаратуры, удалось с минимальной доработкой улучшить графики до таких:
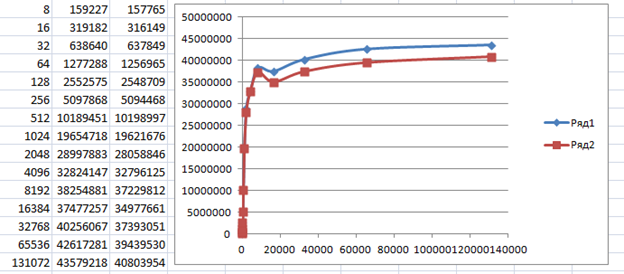
Но это уже тема для другой статьи.
Но я же крутой, у меня теперь есть USB-анализатор (его разработка была описана в блоке из нескольких предыдущих статей). Посмотрев логи, я понял, что похоже, знаю, почему скорость невозможно поднять, даже если STM32F103 обслуживает исключительно USB и ничего больше. Даже начал писать о результатах… Но потом решил, что кому-то это будет не интересно, а кто-то скажет, что и так это знал.
Но неожиданно, с тех пор мне по работе уже трижды приходилось пересказывать эти результаты то Заказчикам, то коллегам. Все они считали, что этот контроллер может больше. И мне приходилось вновь и вновь показывать физическую суть. Поэтому сделать документ было нужно хотя бы чтобы давать его прочесть тем, кто вновь будет говорить, что шина шустрая, контроллер быстрый… Ну, а если и делать документ, то почему бы не оформить его в виде статьи и не выложить на всеобщее обозрение?
Итак, давайте выясним, почему именно STM32F103C8T6 не может прокачать по шине USB данные на скорости 12 мегабит, заняв всю ширину предоставленного канала, и можно ли с этим что-то сделать.
Я буду показывать свои рассуждения шаг за шагом. Возможно, где-то я ошибаюсь, и в комментариях меня поправят (но вроде, всё выглядит довольно правдоподобно), поэтому сущности будут добавляться одна за одной. Начнём с измерительного стенда.
Подготовка проекта STM32
Создаём проект
Итак. Чтобы все могли повторить мои действия, я скачал самую свежую на момент написания статьи версию CubeMX – 6.2. Правда, они выходят с такой частотой, что на момент, когда всё будет выложено на Хабр, всё может уже измениться. Но так или иначе. Скачиваем, устанавливаем.
Создаём новый проект для STM32F103C8Tx. Добавляем туда USB-Device.
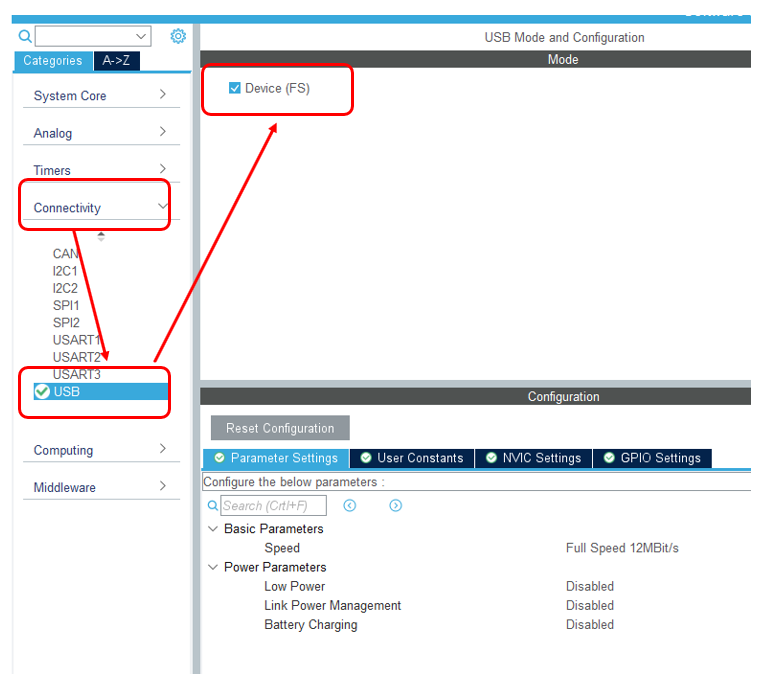
Теперь, когда есть USB, добавляем CDC-устройство. При этом заменим ему VID и PID. Дело в том, что у меня есть inf Файл, который ставит драйвер winusb именно на эту пару идентификаторов. При работе через драйвер usbser скорость была ещё ниже. Я решил исключить всё, что может влиять. Буду замерять скорость без каких-либо прослоек.
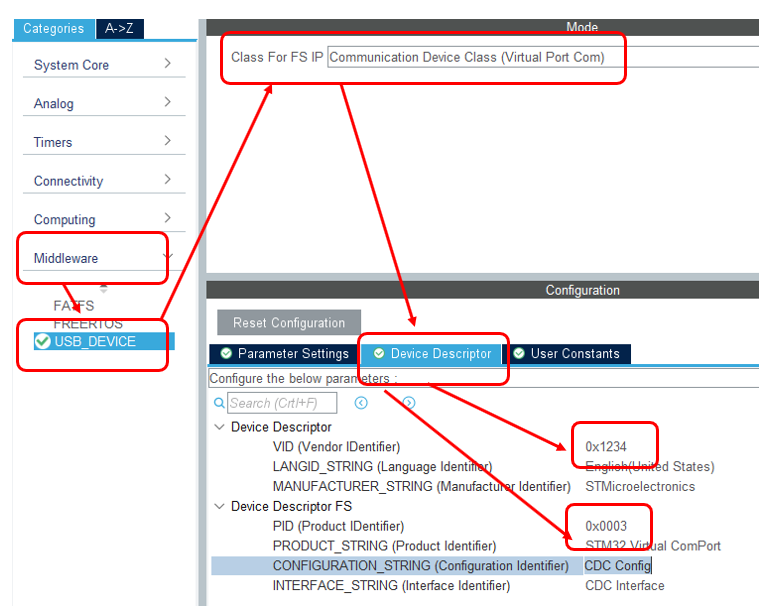
Теперь добавляем RCC для работы с тактовыми сигналами:
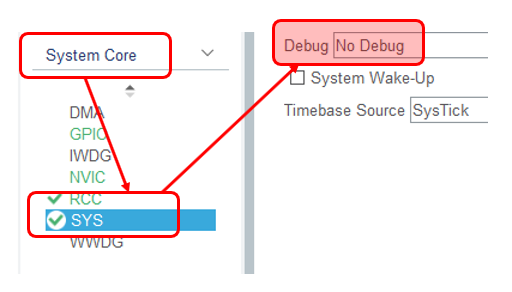
После всего этого (добавили USB и добавили RCC) можно и тактовые частоты настроить, но сначала спасём себя от самоотключающегося блока отладки. Он спрятан надёжно! Вот так сейчас всё выглядит по умолчанию:
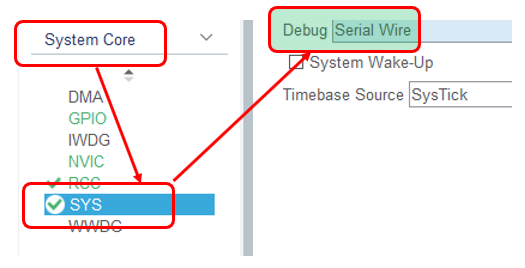
А вот так – надо
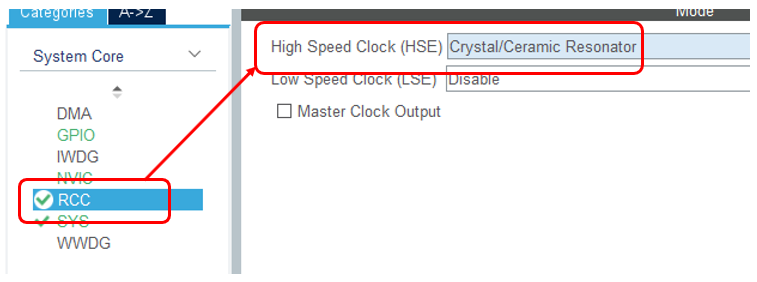
Прекрасно! Теперь можно настроить тактовые частоты. Я всегда это делаю опытным путём. Системная частота должна стать 72 МГц, а частота USB – 48 МГц. Это я в состоянии запомнить. Остальное каждый раз заново вывожу.
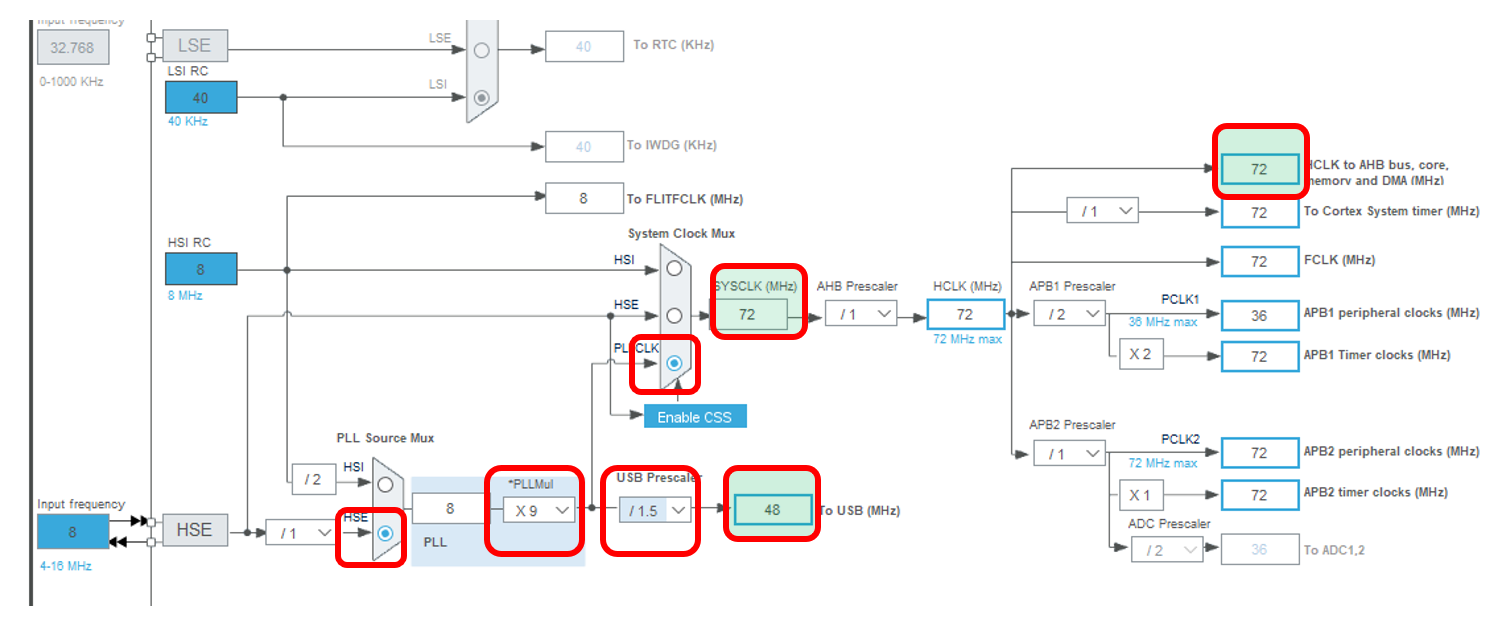
Ну всё. Для тестового проекта настроек, вроде, достаточно. Заполняем свойства проекта и сохраняем. Лично я – в формате MDK ARM. Он же Кейл. Мне так проще.
Надеюсь, я ничего не забыл сделать. Я специально показываю все шаги, чтобы внимательная общественность проверила меня.
Донастраиваем проект в среде разработки
В Кейле я убеждаюсь, что стоит максимальный уровень оптимизации, и дополнительно ставлю оптимизацию по времени. Тогда функции будут по максимуму… Не люблю англицизмы, но инлайниться они будут. А у нас вопросы быстродействия под конец рассуждений выйдут на первое место, так что автоматические инлайны – это то, что нам нужно.

Дописываем код проекта
Наш проект должен просто принимать данные из USB и… И всё! Принимать, принимать, принимать! Не будем тратить время на какую-то обработку этих данных. Просто приняли и забыли, приняли и забыли. Обработчик события «данные приняты» в типовом CDC проекте живёт здесь:

А собственно, в текущей версии Кубика всё делается так, что нам и дописывать ничего не надо. Если бы мы хотели обрабатывать приходящие пакеты – да, пришлось бы. А так – для того, чтобы контроллер начал приём нового пакета, уже всё готово. Так что можно собирать первую версию, заливать в контроллер и начинать испытания.
Подготовка проекта под Windows
Вариант честной работы с UART мы опустим. Дело в том, что совсем скоро мы будем искать причины тормозов. А вдруг они вызваны драйвером usbser.sys? Нет. Мы возьмём проверенный временем драйвер winusb и будем работать с ним через библиотеку libusb. Кому нравится Linux – сможет работать через эту же библиотеку там. Мы тренировались работать с нею в этой статье. А в этой – учились работать с нею в асинхронном режиме.
Сначала я вёл работу через блокирующие функции, так как их написать было проще. Мало того, черновые замеры, которые я делал ещё до начала работы над текстом, были вполне красивые. Это ещё не всё, первая метрика, снятая для статьи, тоже была прекрасна и полностью отражала черновые результаты! Потом что-то случилось. График стал каким-то удивительным, правда, чуть ниже я эту удивительность объясню. При работе с блоками меньше чем 64 байта программа съедала 25% процессорного времени, а именно на блоке 64 байта был излом. Мне казалось, что кто-то обязательно напишет в комментариях, что сделай я всё на асинхронных функциях, всё станет намного лучше. В итоге, я взял и всё переписал на асинхронный вариант. Процент потребления процессорного времени на малых блоках действительно изменился. Теперь программа потребляет 28% вместо двадцати пяти… Цифры скоростей же не изменились… Но асинхронная работа более правильная сама по себе, так что я покажу именно её. Вся теория уже рассматривалась мною в тех статьях про libusb.
Я завожу всё ту же вспомогательную структуру:
struct asyncParams
{
uint8_t* pData;
uint32_t dataOffset;
uint32_t dataSizeInBytes;
uint32_t transferLen;
uint32_t actualTranfered;
QElapsedTimer timer;
quint64 timerAfter;
};
asyncParams m_asyncParams;
Но, как видно, в ней добавлены параметры «Таймер» и «последнее значение таймера». Дело в том, что момент конца передачи данных удобнее всего ловить в функции обратного вызова. Поэтому она должна иметь и сам объект «таймер», и возможность занести его показания для последующего использования в основной программе.
Ну, и указатели на объекты «передача» имеются, куда же без них:
static const int m_nTransfers = 32;
libusb_transfer* m_transfers [m_nTransfers];
Функция обратного вызова отличается от описанной в предыдущих статьях как раз тем, что она считывает показание таймера, если передавать больше нечего. Это произойдёт не единожды, а для каждой из передач (тридцати двух в случае мелких блоков, если блоки крупные – их будет меньше, но всё равно не одна). Но на самом деле, это не страшно. Мы это значение будем анализировать только после последнего вызова этой функции. В остальном – там всё то же, что и раньше, так что просто покажу код, не объясняя его. Объяснения все были в предыдущих статьях.
void MainWindow::WriteDataTranfserCallback(libusb_transfer *transfer)
{
MainWindow* pClass = (MainWindow*) transfer->user_data;
switch (transfer->status )
{
case LIBUSB_TRANSFER_COMPLETED:
pClass->m_asyncParams.actualTranfered += transfer->length;
// Still need transfer data
if (pClass->m_asyncParams.dataOffset < pClass->m_asyncParams.dataSizeInBytes)
{
transfer->buffer = pClass->m_asyncParams.pData+pClass->m_asyncParams.dataOffset;
pClass->m_asyncParams.dataOffset += pClass->m_asyncParams.transferLen;
libusb_submit_transfer(transfer);
} else
{
pClass->m_asyncParams.timerAfter = pClass->m_asyncParams.timer.nsecsElapsed();
}
break;
/* case LIBUSB_TRANSFER_CANCELLED:
{
pClass->m_cancelCnt -= 1;
}*/
default:
break;
}
}
Основная функция имеет одну хитрость. Скорость достаточно сильно плавает. Поэтому я усредняю показания. Последний аргумент как раз задаёт число попыток, за которое следует всё усреднить. Ещё во времена блокирующей работы, разброс скоростей был довольно высок (а потом я просто логику усреднения не трогал). Поэтому я беру все полученные результаты, усредняю их, а затем – откидываю значения, которые существенно отличаются от среднего. И оставшиеся значения – снова усредняю.
Ну, а параметр blockSize у функции – это я в своих статьях уже набил оскомину высказыванием, что при работе с USB скорость зависит от размера блока. До определённого значения она ниже нормальной. Это связано с тем, что хост посылает пакеты медленнее, чем их может обработать устройство. Поэтому я всегда строю графики и смотрю, где они входят в насыщение. Сегодня я буду делать то же самое. Правда, сегодня график в дополнение к банальному росту, имеет непривычную для меня форму, что и сподвигло меня на переделку программы с блокирующего на асинхронный режим. Итак, функция, измеряющая скорость, выглядит так:
Её текст я скрыл под катом.
quint64 MainWindow::MeasureSpeed2(uint32_t totalSize, uint32_t blockSize, uint32_t avgCnt)
{
std::vector<qint64> gist;
gist.resize(avgCnt);
QByteArray data;
data.resize(totalSize);
m_asyncParams.dataSizeInBytes = totalSize;
m_asyncParams.transferLen = blockSize;
uint32_t nTranfers = m_nTransfers;
if (totalSize/blockSize < nTranfers)
{
nTranfers = totalSize/blockSize;
}
for (uint32_t i=0;i<avgCnt;i++)
{
m_asyncParams.dataOffset = 0;
m_asyncParams.actualTranfered = 0;
m_asyncParams.pData = (uint8_t*)data.constData();
// Готовим структуры для передач
for (uint32_t i=0;i<nTranfers;i++)
{
m_transfers[i] = libusb_alloc_transfer(0);
libusb_fill_bulk_transfer (m_transfers[i],m_usb.m_hUsb,0x02,//,0x01,
m_asyncParams.pData+m_asyncParams.dataOffset,m_asyncParams.transferLen,WriteDataTranfserCallback,
// No need use timeout! Let it be as more as possibly
this,0x7fffffff);
m_asyncParams.dataOffset += m_asyncParams.transferLen;
}
m_asyncParams.timerAfter = 0;
m_asyncParams.timer.start();
for (uint32_t i=0;i<nTranfers;i++)
{
int res = libusb_submit_transfer(m_transfers[i]);
if (res != 0)
{
qDebug() << libusb_error_name(res);
}
}
timeval tv;
tv.tv_sec = 0;
tv.tv_usec = 500000;
while (m_asyncParams.actualTranfered < totalSize)
{
libusb_handle_events_timeout (m_usb.m_ctx,&tv);
}
quint64 size = totalSize;
size *= 1000000000;
gist [i] = size/m_asyncParams.timerAfter;
}
for (uint32_t i = 0;i<nTranfers;i++)
{
libusb_free_transfer(m_transfers[i]);
m_transfers[i] = 0;
}
qint64 avgSpeed = 0;
for (uint32_t i=0;i<avgCnt;i++)
{
avgSpeed += gist [i];
}
avgSpeed /= avgCnt;
if (avgCnt < 4)
{
return avgSpeed;
}
for (uint32_t i=0;i<avgCnt;i++)
{
if (gist [i] < (avgSpeed * 3)/4)
{
gist [i] = 0;
}
if (gist [i] > (avgSpeed * 5)/4)
{
gist [i] = 0;
}
}
avgSpeed = 0;
int realAvgCnt = 0;
for (uint32_t i=0;i<avgCnt;i++)
{
if (gist[i]!= 0)
{
avgSpeed += gist [i];
realAvgCnt += 1;
}
}
if (realAvgCnt == 0)
{
return 0;
}
return avgSpeed/realAvgCnt;
}
Сборку статистики в файл csv я делаю так:
void MainWindow::on_m_btnWriteStatistics_clicked()
{
QFile file ("speedMEasure.csv");
if (!file.open(QIODevice::WriteOnly))
{
QMessageBox::critical(this,"Error","Cannot create csv file");
return;
}
QTextStream out (&file);
QApplication::setOverrideCursor(Qt::WaitCursor);
for (int blockSize=0x8;blockSize<=0x20000;blockSize *= 2)
{
quint64 speed = MeasureSpeed(0x100000,blockSize,10);
out << blockSize << "," << speed << Qt::endl;
}
out.flush();
file.close();
QApplication::restoreOverrideCursor();
}
Первый результат
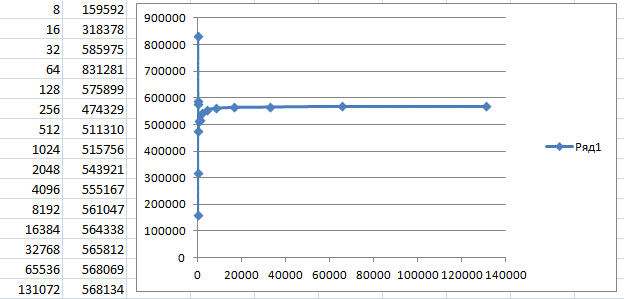
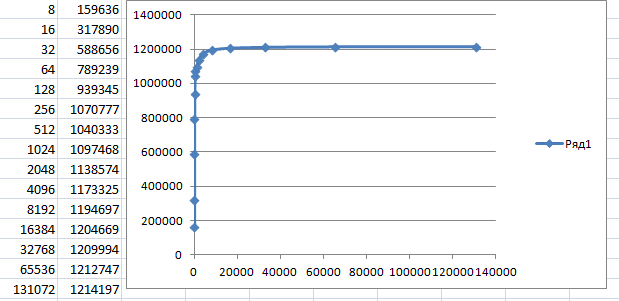
Итак. У нас есть прошитое устройство, у нас есть программа для его тестирования. Строим статистику для разных размеров блока, чтобы быть уверенными, что проблемы не зависят от этого значения.

Где-то после размера блока 4 килобайта, скорость упирается в 560 килобайт в секунду. Давайте я грубо умножу это на 8. Получаю условные 4.5 мегабита в секунду. Условность состоит в том, что на самом деле, там ещё бывают вставные биты, да и на пакеты оверхед имеется. Но всё равно, это отстоит очень далеко от 12 мегабит в секунду, положенных на скорости Full Speed (кстати, именно поэтому на вступительном рисунке стоит знак «120», он символизирует данный теоретический предел).
Почему результат именно такой
Будучи человеком вооружённым (не зря же я всех полгода пытал статьями про изготовление анализатора), я взял и рассмотрел детали трафика. И вот что у меня получилось (данные я чуть обрезал, там реально всегда уходит по 64 байта):

То же самое текстом.
*** +4 us
OUT Addr: 16 (0x10), EP: 1
E1 90 40
*** +3 us
DATA0
C3 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD …
*** +45 us
ACK
D2
*** +4 us
OUT Addr: 16 (0x10), EP: 1
E1 90 40
*** +3 us
DATA1
4B 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD …
*** +45 us
NAK
5A
*** +4 us
OUT Addr: 16 (0x10), EP: 1
E1 90 40
*** +3 us
DATA1
4B 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD…
*** +45 us
ACK
D2
*** +5 us
OUT Addr: 16 (0x10), EP: 1
E1 90 40
*** +3 us
DATA0
C3 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD BA 0D F0 AD…
*** +45 us
NAK
5A
И так до бесконечности на всех участках, что я смог осмотреть глазами, возвращается то ACK, то NAK. Причём в режиме FS каждая пачка данных передаётся целиком. Принялась она или нет, а всё равно передаётся целиком. Хорошо, что это не роняет всю шину USB, так как до последнего хаба данные бегут на скорости HS в виде SPLIT транзакции. А дальше – уже хаб мелко шинкует её на пакеты по 64 байта и пытается отослать на скорости FS.
Подобные чередования ACK-NAK я нашёл и в сети, когда пытался проверить, у одного ли меня такой результат. Нет, не у одного.
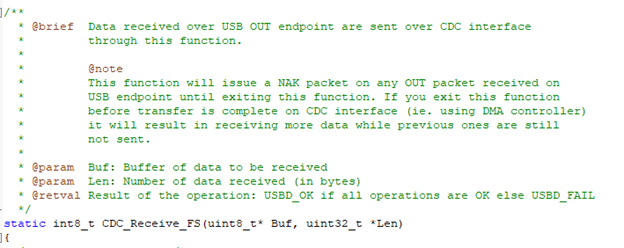
Причины падения скорости, честно говоря, написаны прямо под носом. А именно – в комментариях к функции, где нам следует вставлять обработку данных. Вот их текст:

Нам честно говорят, что пока мы находимся в этой функции, будет посылаться NAK. Вышли из неё – снова начинается работа шины.
А почему при блоке 64 байта скорость выше? Я долго думал, и нашёл следующее объяснение: 64 байта – это тот размер блока, после которого при работе с FS-устройствами через HS-хабы начинается использование SPLIT-транзакций. Что это такое – можно посмотреть в стандарте, там этому посвящён не один десяток страниц. Но если коротко: до хаба запрос идёт на скорости HS, а уже хаб обеспечивает снижение скорости и нарезание данных на FS-блоки. Основная шина при этом не тормозит.
Выше мы видели, что уже через 5 микросекунд после прихода примитива ACK, пошёл следующий пакет, который не был обработан контроллером. А что будет, если мы будем работать блоками по 64 байта? Я начну с примитива SOF.
Смотреть код.
*** +1000 us
SOF 42.0 (0x2a)
A5 2A 50
*** +3 us
OUT Addr: 29 (0x1d), EP: 1
E1 9D F0
*** +3 us
DATA0
C3 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00…
*** +45 us
ACK
D2
*** +37 us
OUT Addr: 29 (0x1d), EP: 1
E1 9D F0
*** +3 us
DATA1
4B 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00…
*** +45 us
ACK
D2
*** +43 us
OUT Addr: 29 (0x1d), EP: 1
E1 9D F0
*** +3 us
DATA0
C3 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00…
*** +45 us
ACK
D2
Вот и разгадка! Как видим, быстрее – не всегда лучше. Время между пакетами больше. Особенность работы хоста такая.
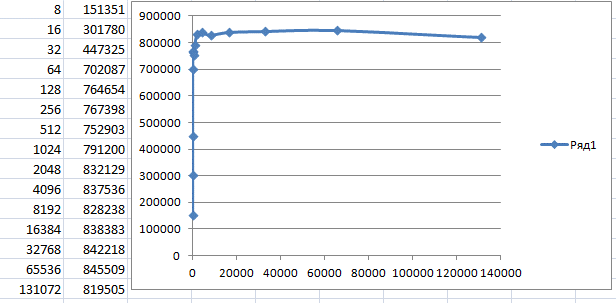
По этой же причине, если мы воткнём между материнской платой и устройством дешёвый USB2-хаб, марку которого я не скажу, так как сильно поругался с магазином, владеющим именем бренда, но судя по ID, чип там VID_05E3&PID_0608, то статистика окажется намного лучше, чем при прямом подключении к материнке:

Здесь уже скорость стремится к условным семи мегабитам в секунду при любых размерах блока, выше 64 байт. Но всё равно это чуть больше половины теоретической скорости!
Пробуем двухбуферную систему
Будучи опытным программистом для микроконтроллеров, я знаю, что обычно такая проблема решается путём применения двухбуферной схемы. Пока обрабатывается один буфер, данные передаются во второй. А какая схема используется здесь? Ответ на мой вопрос мы получим из следующего кода:
USBD_StatusTypeDef USBD_LL_Init(USBD_HandleTypeDef *pdev)
{
…
/* USER CODE BEGIN EndPoint_Configuration */
HAL_PCDEx_PMAConfig((PCD_HandleTypeDef*)pdev->pData , 0x00 , PCD_SNG_BUF, 0x18);
HAL_PCDEx_PMAConfig((PCD_HandleTypeDef*)pdev->pData , 0x80 , PCD_SNG_BUF, 0x58);
/* USER CODE END EndPoint_Configuration */
/* USER CODE BEGIN EndPoint_Configuration_CDC */
HAL_PCDEx_PMAConfig((PCD_HandleTypeDef*)pdev->pData , 0x81 , PCD_SNG_BUF, 0xC0);
HAL_PCDEx_PMAConfig((PCD_HandleTypeDef*)pdev->pData , 0x01 , PCD_SNG_BUF, 0x110);
HAL_PCDEx_PMAConfig((PCD_HandleTypeDef*)pdev->pData , 0x82 , PCD_SNG_BUF, 0x100);
Тут, везде написано PCD_SNG_BUF. Вообще, в статье про DMA я уже рассуждал, что если разработчики этой библиотеки что-то не используют, значит и не стоит этого использовать. Но всё же, я попробовал заменить SNG_BUF на DBL_BUF. Результат остался прежним. Тогда я нашёл в сети следующее утверждение:
The USB peripheral's HAL driver (PCD) has a known limitation: it directly maps EPnR register numbers with endpoint addresses. This works if all OUT and IN endpoints with the same number (e.g. 0x01 and 0x81) are the same type, and not double buffered. However, isochronous endpoints have to be double buffered, therefore you have to use an endpoint number that's unused in the other direction. E.g. in your case, set AUDIO_OUT_EP1 to 0x01, and AUDIO_IN_EP1 to 0x82. (Or you can drop this USB stack altogether as I did.)
Попробовал разнести точки – результат тот же. В общем, анализ показал, что для точек типа BULK это если и возможно, то только путём переписывания MiddleWare. Короче, не зря там везде одиночные буферы выбраны. Разработчики знали, что делают.
Тормоза в обработчике прерывания
Теперь подойдём к проблеме с уже имеющимися данными, но с другой стороны. Выше в комментариях мы видели, что пока мы находимся в обработчике прерывания, система будет слать NAK. А как велик этот обработчик?
Немного потрассируем код. Давайте я поставлю точку останова в функции CDC_Receive_FS, в которую мы попадаем ради каждого блока в 64 байта или меньше. Ну, потому что транзакции, больше чем на 64 байта, будут разрезаны на пакеты такого размера. Вот такой у нас получается стек возвратов в обработчик прерываний. А это ещё часть функций заинлайнилась!

В самой глубокой функции выполняется довольно серьёзная работа. Прочие функции – это просто слои. Каждый слой как-то перекладывает данные (зачем?), после чего – вызывает следующий слой.
Но и это ещё не всё. В функции PCD_EP_ISR_Handler (кстати, в стеке возвратов её не видно, но она есть) мы изымаем данные из FIFO в буфер. В дальнейшем, если бы у нас был свой код, мы бы ещё раз скопировали данные из системного буфера к себе. Имейте в виду, что логичнее сразу задавать указатель на свой массив, двигаясь по нему, благо такая возможность имеется.
Но и это ещё не всё! Ради всё тех же каждых 64 байт, мы вызываем функцию USBD_CDC_SetRxBuffer(), а затем — USBD_CDC_ReceivePacket(), которая также расслоится на кучку вызовов, каждый из которых всего лишь чуть-чуть перетасовывает данные. Оцените стек возвратов, когда мы находимся в самом глубоком слое!

А если вы попробуете рассмотреть код функции USB_EPStartXfer(), то вам совсем станет грустно. А ведь всё это безобразие вызывается ради каждого блока в 64 байта. Вот так 64 байта пробежало – начинается чехарда с многократной (правда, в нашем случае с отсутствующим функционалом — однократной) пересылкой этих данных, а также с вызовом кучи слоёв. Некоторые из них тратят массу тактов процессора на свою важную работу, но некоторые – просто слои. Они просто зачем-то перекладывают байтики из структуры в структуру и передают управление дальше. А такты на это – всё равно расходуются!
Вспоминается жаркий спор, когда во время одного проекта я требовал от архитектора, да и других программистов, не увлекаться расслоением программы. Они там наплодили слоёв «на всякий случай». А на все мои нападки отвечали, что современные вычислительные системы настолько быстродействующие, что всё будет хорошо. Наверное, тут разработчики тоже думали, что всё будет хорошо… Вот и додумались… Но давайте проведём профилирование и узнаем, сколько именно микросекунд ядро находится в обработчике прерывания.
Проверяем теорию осциллографом
Имея стек возвратов, а также известные времянки посылки транзакций, мы можем проверить всё с другой стороны, чтобы быть уверенными, что нигде не ошиблись. Давайте я на входе в прерывание буду взводить какой-либо порт, а на выходе – сбрасывать. Как всегда, я буду делать это через библиотеку mcucpp Константина Чижова.
Объявим, скажем, ножку Pa0 для этой цели:
#include <iopins.h>
…
typedef Mcucpp::IO::Pa0 oscOut; //PC13
За что люблю эту библиотеку, так за её простоту. Инициализация ножки выглядит так:
oscOut::ConfigPort::Enable();
oscOut::SetDirWrite();
Включили тактирование аппаратных блоков, назначили ножку на выход. Собственно, всё.
И добавим пару строк в функцию обработки прерывания (первая взведёт ножку в единицу, вторая – сбросит в ноль):

То же самое текстом.
void USB_LP_CAN1_RX0_IRQHandler(void)
{
/* USER CODE BEGIN USB_LP_CAN1_RX0_IRQn 0 */
oscOut::Set();
/* USER CODE END USB_LP_CAN1_RX0_IRQn 0 */
HAL_PCD_IRQHandler(&hpcd_USB_FS);
/* USER CODE BEGIN USB_LP_CAN1_RX0_IRQn 1 */
oscOut::Clear();
/* USER CODE END USB_LP_CAN1_RX0_IRQn 1 */
}
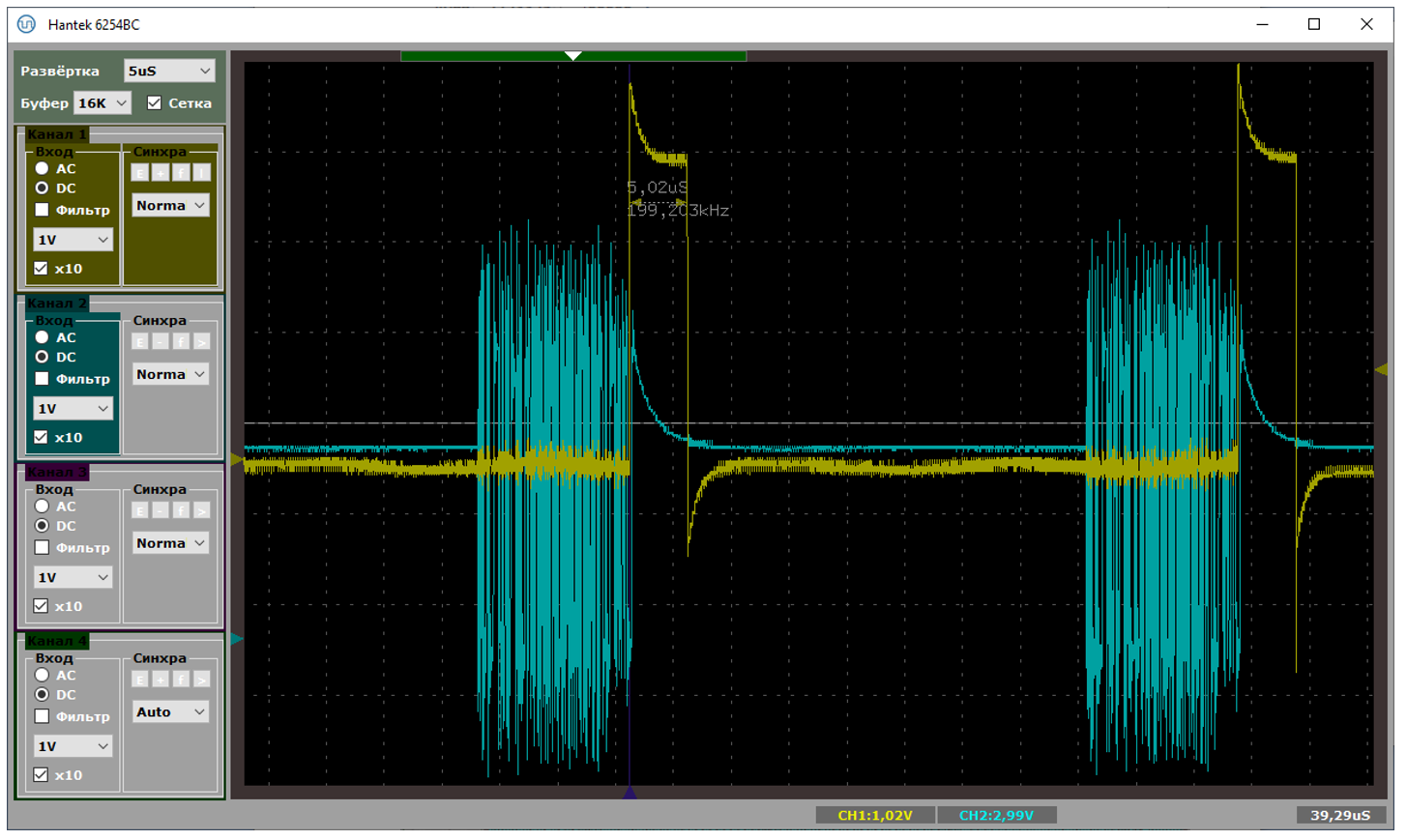
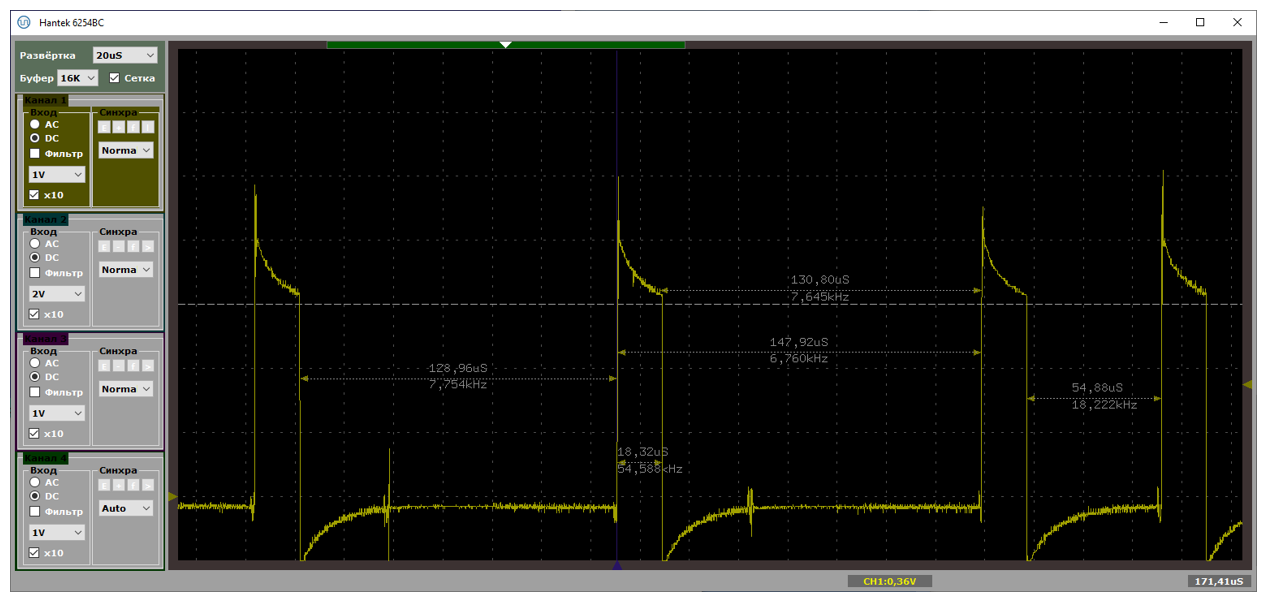
Типичный период следования прерываний – от 70 до 100 микросекунд. При этом в прерывании мы находимся чуть меньше чем 19 микросекунд. На первом рисунке показан случай, когда данные идут помедленнее (расстояния велики), на втором – побыстрее (расстояния меньше). Обе осциллограммы сняты при подключении через хаб.
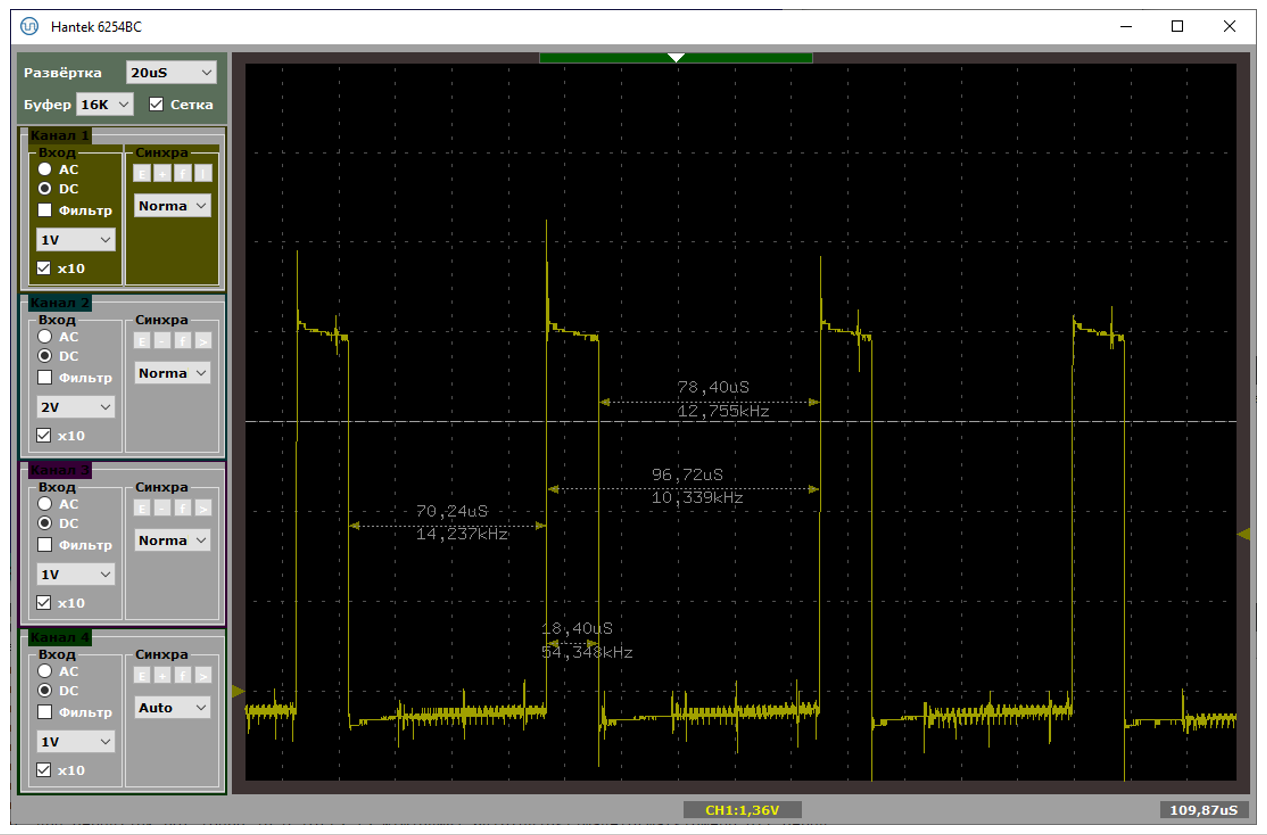
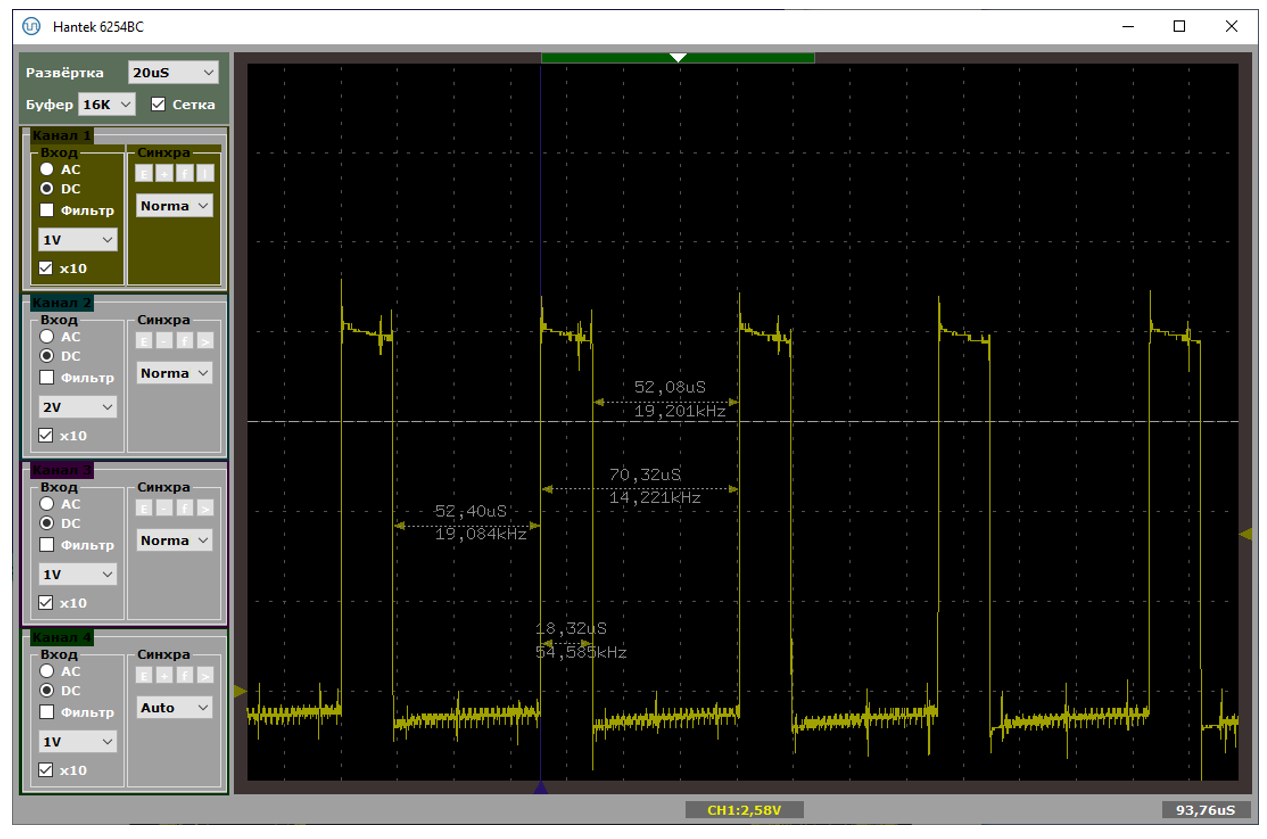
А вот – хорошая и не очень хорошая ситуации, снятые при прямом подключении к материнке. Собственно, на плохом варианте видно, что расстояния удваиваются. Один из пакетов уходит с NAKом, в прерывание мы не попадаем.
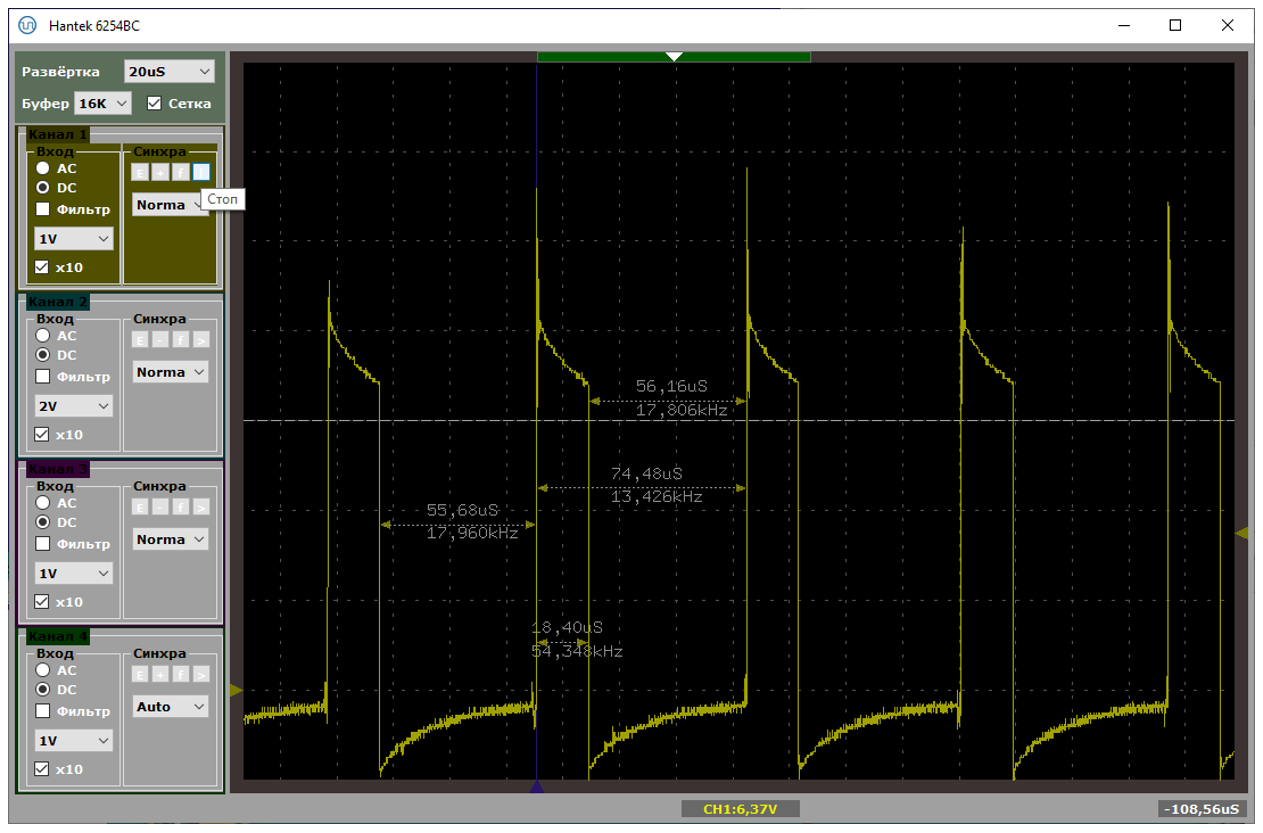
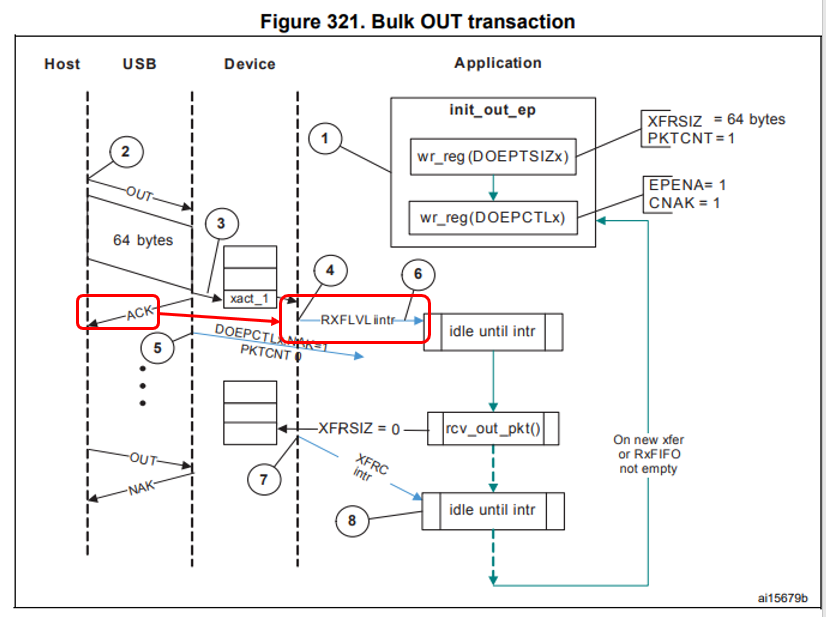
Осталось понять, как эти прерывания располагаются относительно USB-примитивов. В этом нам поможет Reference Manual. Момент прихода прерывания я выделил.
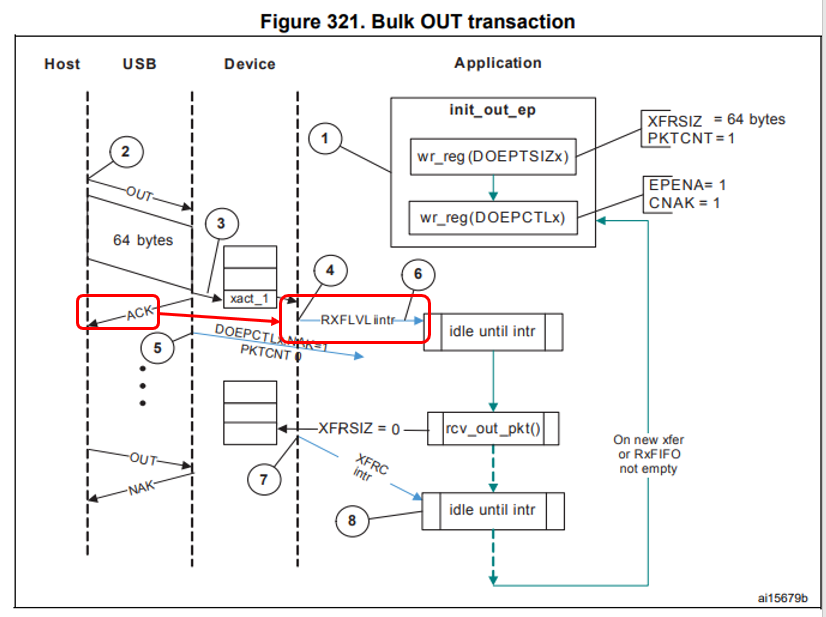
Вот теперь всё сходится. После формирования ACKа мы не готовы принимать новые пакеты на протяжении 18 микросекунд. Когда они приходят через 3-5 микросекунд (а именно это мы видим в текстовом логе анализатора выше для плохого случая), контроллер их просто игнорирует, посылая NAK. Когда через 30-40 (что мы наблюдаем в текстовом логе для случая хорошего, хотя, точно подойдёт любое значение, больше чем 19) – обрабатывает.
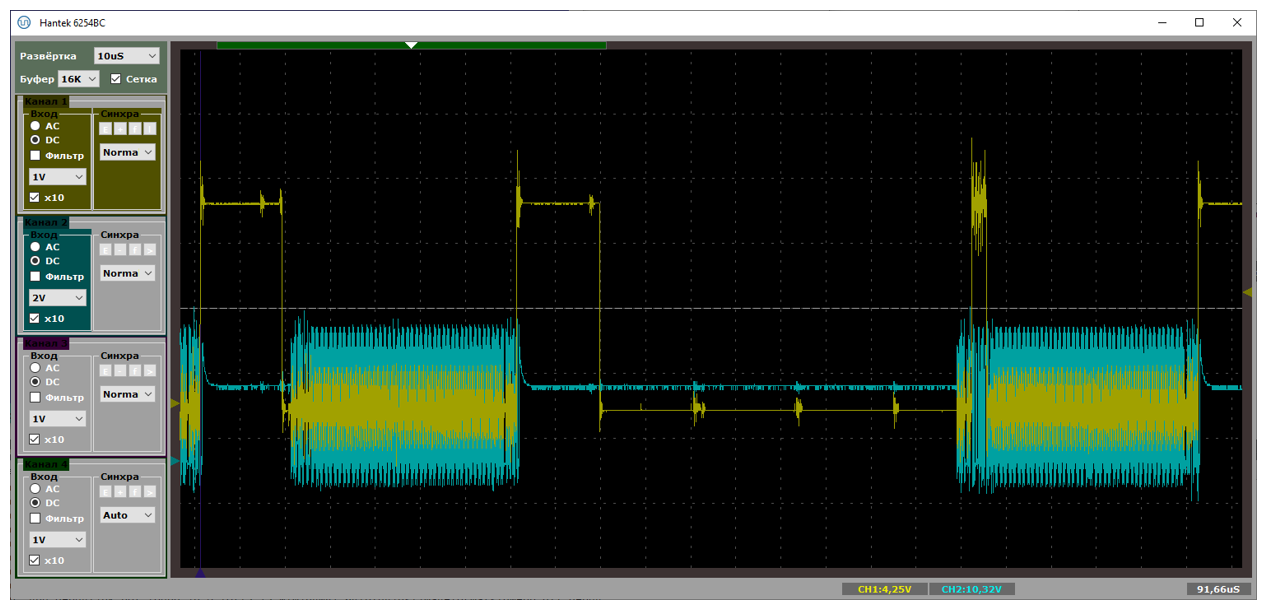
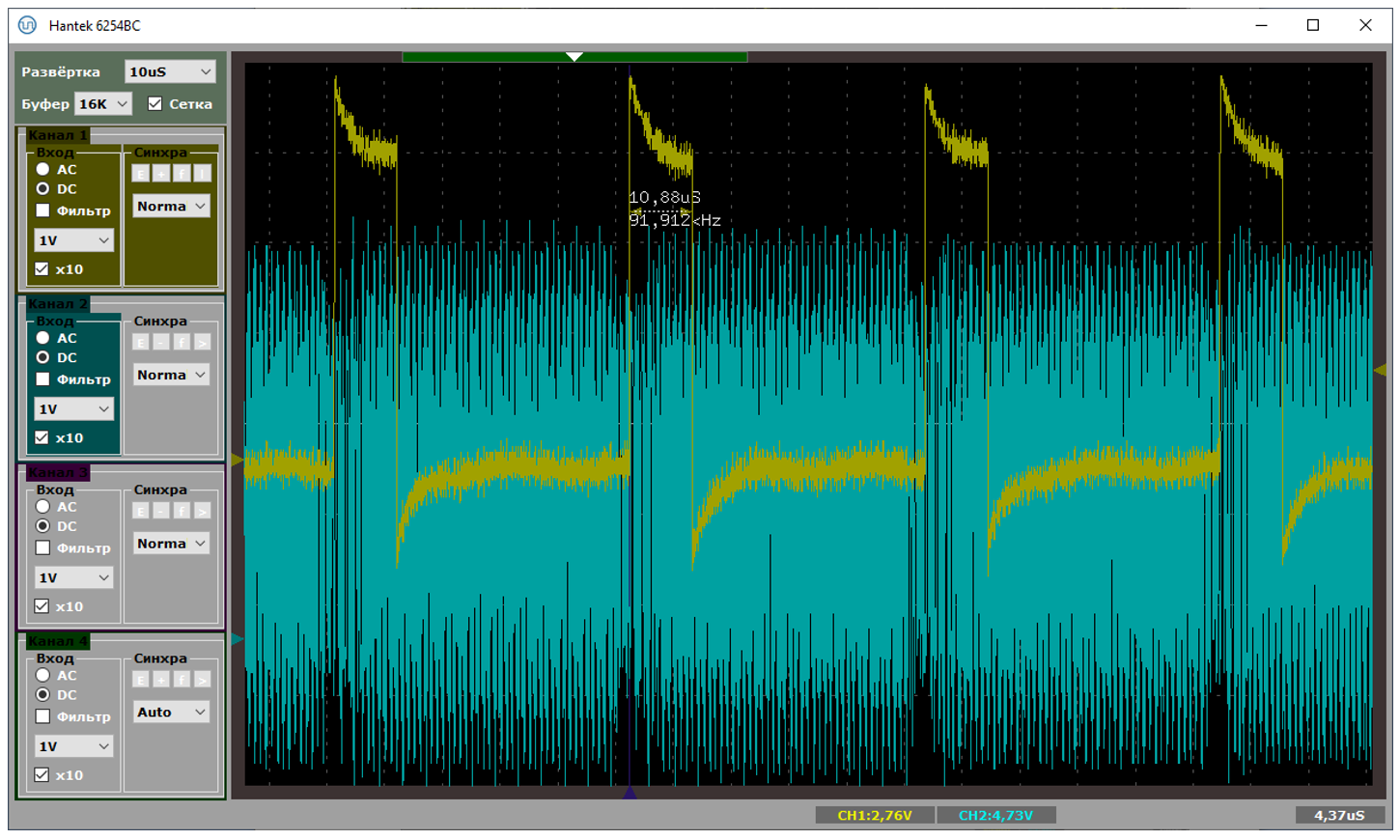
Плюс из текстовых логов мы видим, что влево от прерывания около пятидесяти микросекунд занимает сама OUT-транзакция на аппаратном уровне. Кстати. У нас же скорость FS. Такие сигналы можно ловить обычным осциллографом. Давайте я добавлю активность на шине USB в виде голубого луча. Что получим?
Вот тут мне удалось поймать SOF (в правой части экрана). Видно, что сразу после него начинают идти данные. В конце кадра (то есть, от последнего пакета прошлого кадра до SOFа) имеется тишина (там по стандарту что-то такое требуется).

Вот такая картинка была, когда я получил производительность 814037 байт в секунду. Извините, но быстрее – никак. Либо по шине идут данные, либо мы обрабатываем прерывание. Простоев нет!
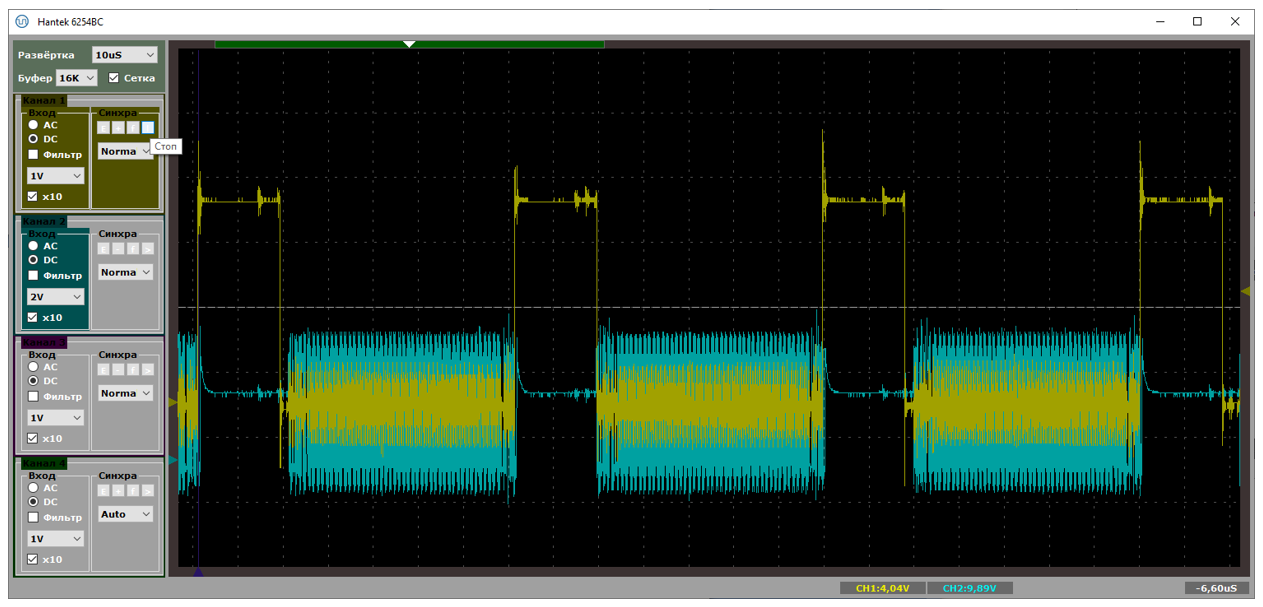
Причём 64 байта, с учётом, что я передаю все нули, а значит там может быть вставленный бит – это примерно 576 бит. При частоте 12 МГц их передача займёт 48 микросекунд. То есть, когда между пакетами примерно по 50 микросекунд, мы имеем дело с пределом скорости. Тут даже NAKов нет.
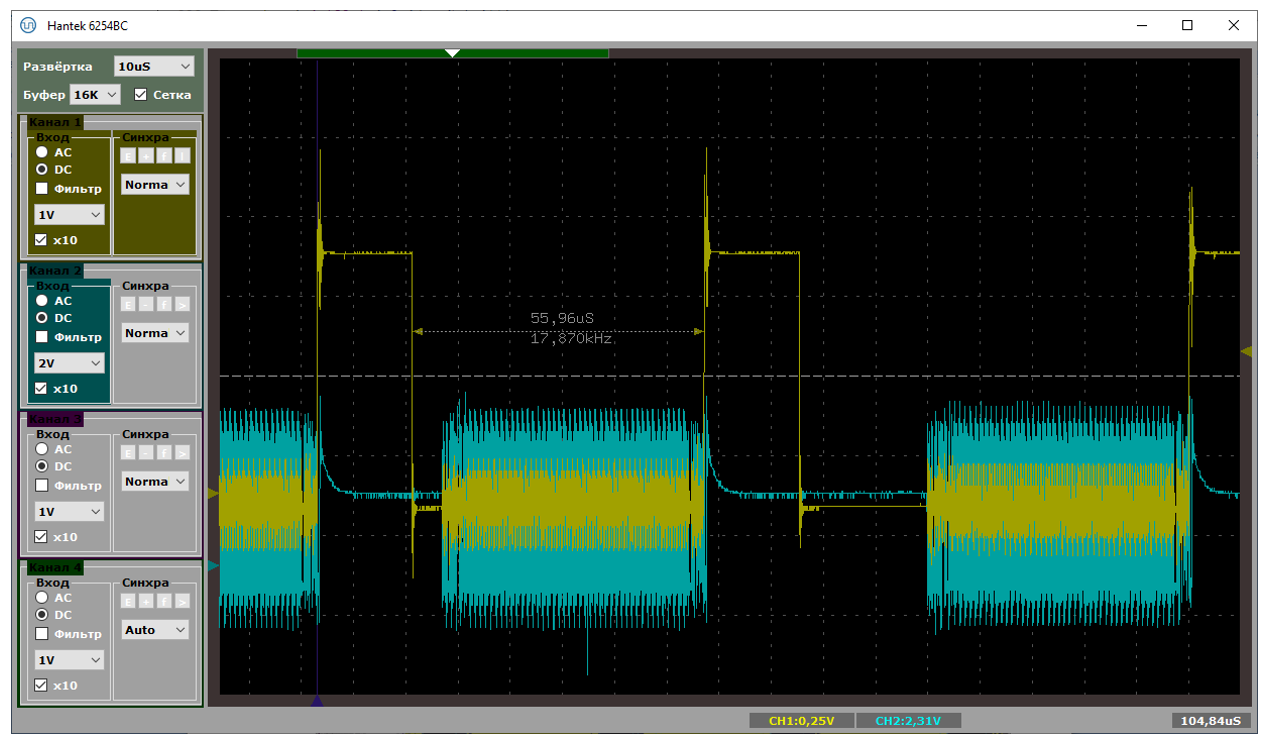
NAKи – вот они, когда хост пытается что-то передавать, пока мы заняты, что совпадает с выводами, сделанными при анализе текстовых логов. Вот тут прямо видны два пакета, первый из которых начался, когда аппаратура ещё не готова его принимать.

Всё спасла бы двойная буферизация, но она для BULK случая, как я понял из описаний в сети, не работает, так как на аппаратном уровне заложено, что пока находимся в обработчике прерывания – надо слать NAK и всё тут. Только в логике изохронных транзакций этого нет. Поняв всё это, я сумел сформулировать правильный поисковый запрос и нашёл интересную китайскую статью.
Мне показалось, что там они решили проблему, полностью переделав логику работы Middleware USB. Они там рассуждают, что дико сократили время пребывания внутри прерывания. Но если честно, у меня не стояло задачи выжать из этого контроллера всё. Так что я даже сильно не вчитывался в доводы авторов. Правда, при работе через хаб всё попроще. Короче, результаты у китайских специалистов если и есть, они также будут работать только на определённой конфигурации, ведь на паузы от хаба повлиять не сможет никто.
Неожиданное следствие из снятой осциллограммы
И раз уж я снял осциллограммы, предлагаю посмотреть на процесс, когда пакеты идут по шине, с точки зрения не оптимизатора, а простого программиста. Вот осциллограмма. Единичное значение – контроллер находится в обработчике прерывания. Все остальные задачи в это время не могут работать. Каково?
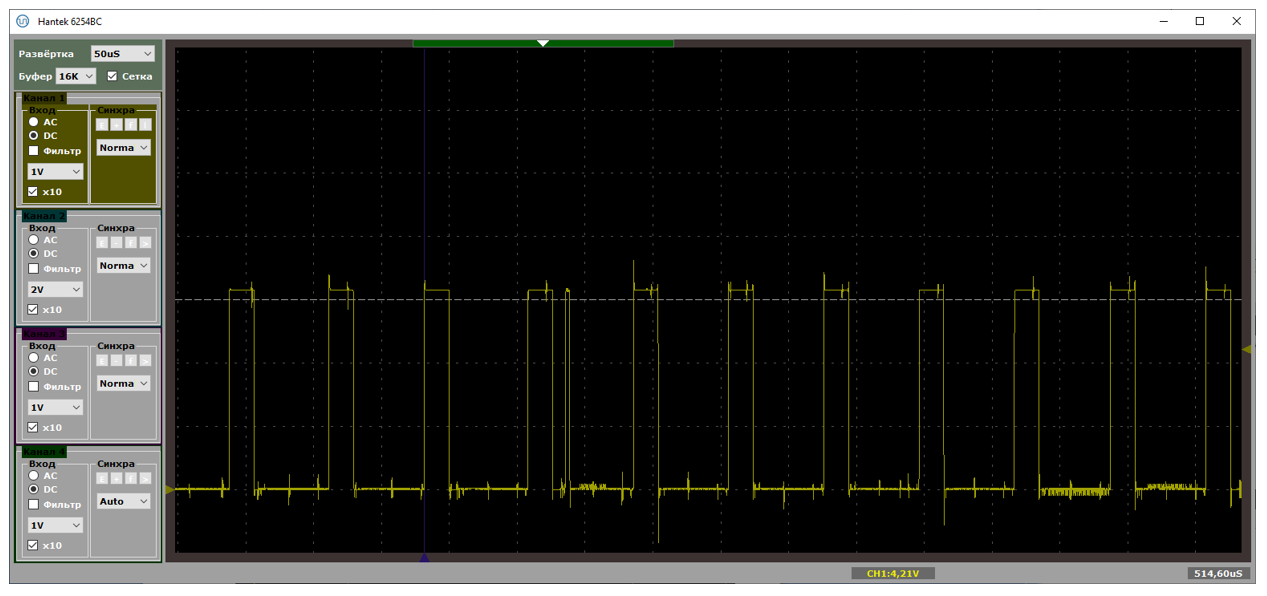
А при коротких пакетах, бывает и такое:
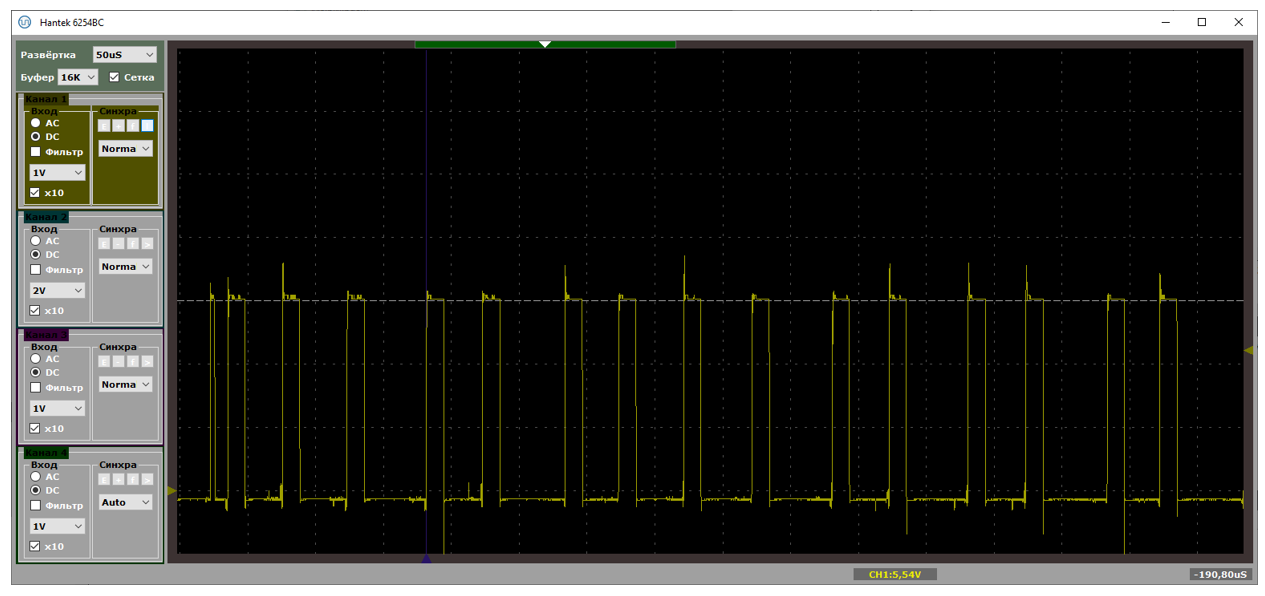
Правда, это только во время передачи данных. Если передача не идёт, мы видим только SOFы (на предыдущей осциллограмме короткая иголка слева – это как раз SOF). Но когда идёт обмен данными, процентов 20 времени контроллер не готов нас обслуживать. Он находится в контексте прерывания. Так что если и обслужит, то только прерывания с бОльшим приоритетом.
Выводы
Ну что, пришла пора делать выводы. Как видим, контроллер STM32F103C8T6 не может выжать всю производительность даже из шины USB 2.0 FS.
Хорошо это или плохо? Ни то, ни другое. Есть тысяча и одна задача, где не надо гнаться за производительностью USB, и этот копеечный контроллер прекрасно с ними справляется. Вот там его и надо использовать. (Дополнение: пока статья лежала «в столе», на Хабре появилась статья, что уже не копеечный. Цена у местных поставщиков, согласно той статье, выросла в 10 раз. Надеюсь, это временное явление.)
Просто, как я уже отмечал, мне надо было получить материалы, которые я буду предлагать прочесть всем, кто будет пытаться просить меня или кого-то ещё выжать из этой шины все соки на подобных малютках. Не стоит даже надеяться. Сову на глобус натягивать не стоит!
А для производительных вещей я в ближайшее время собираюсь изучить контроллер, у которого USB обрабатывается по стандарту EHCI. Там всё на дескрипторах. Заполнил адрес, длину… Когда пришло прерывание – данные уже готовы… Надеюсь… Если будет что-то интересное – сделаю статью. А здесь сам подход к обработке приходящих данных (они помещаются в выделенную память, а затем – программно изымаются оттуда, причём в контексте прерывания) не даёт развить высоких скоростей. По крайней мере, на кристалле F103.
Следующий вывод: добавленный в систему дешёвый USB-хаб даёт неожиданный прирост производительности. Это связано с тем, что он шлёт пакеты с паузами 20-25 микросекунд (в статье подтверждающий лог не приводится для экономии места, но его можно скачать здесь для самостоятельного изучения). Получаем грубо 20 микросекунд задержки, 50 микросекунд передачи. Итого 5/7 от полной производительности. Как раз 700-800 килобайт в секунду при теоретическом максимуме 1000-1100. Так что любой FS-контроллер, включённый через этот хаб, не сможет выдать больше.
Дальше: видно, что, когда по USB передаются данные, контроллер довольно большой процент времени находится в обработчике прерывания USB. Это также надо иметь в виду, проектируя систему. Прерываниям UART, SPI и прочим, где данные ждать невозможно, а обработка будет быстрой, стоит задавать приоритет выше, чем у прерывания USB. Ну, или использовать DMA.
И, наконец, мы выяснили, что для FS устройств на базе STM32 нет чёткого критерия оптимальной работы со стороны прикладной программы. Одна и та же система, в которую то добавляли, то исключали внешний USB-хаб, работала с максимальной производительностью либо при длине блока 64 байта (без хаба), либо более четырёх килобайт (с хабом). При разработке прикладных программ для PC, требующих высокой производительности, следует учитывать и этот аспект. Вплоть до калибровки параметров под конкретную конфигурацию оборудования.
Дополнение: не только в Китае дорабатывают библиотеки
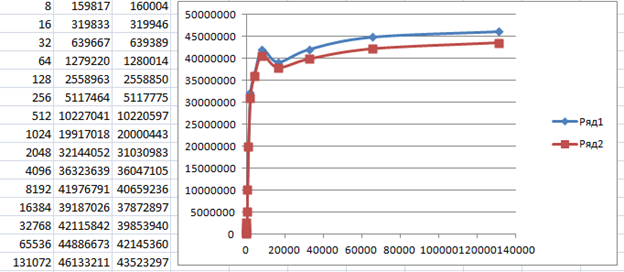
В комментариях к статье пользователь EddyEm оставил суровый комментарий, что не надо пользоваться библиотеками Кубика. Ну, это я и в основном тексте говорил, но чем пользоваться? Есть у меня привычка, просматривать профили резких комментаторов. И вот, среди его высказываний под другими статьями я нашёл ссылку на такой проект: stm32samples/F1-nolib/CDC_ACM at master · eddyem/stm32samples · GitHub. Он как раз под пилюлю, и не использует сторонних библиотек. Чуть доработал, выкинув всю полезную работу (мои тесты же тоже просто гоняют пакеты, не пользуясь их содержимым), и получил такой результат:

С хабом предсказуемо скорость осталась прежней (коричневый график, последний столбец таблицы), а вот при подключении напрямую к разъёму материнской платы – всё стало замечательно! Потому что российский автор, как и китайские, достаточно быстро выходит из обработчика прерываний. Только там есть лишь описание, а тут – работающий код.
Проверяем по приборам. Вот так выглядит осциллограмма при работе через хаб. Если раньше новые данные упирались в конец обработчика прерывания, то теперь они отстоят от него на огромнейшую дистанцию

При прямой работе с разъёмом на материнской плате, получаем такую красоту:

Собственно, мы видим, что полоса используется полностью.
Затем пользователь COKPOWEHEU прислал ссылку на свою библиотеку usb/5.CDC_L1 at main · COKPOWEHEU/usb · GitHub. В целом, она тоже работает. Вот скорости при прямом подключении к разъёму материнской платы:

Но если у первой библиотеки время обработки прерывания занимает две с половиной микросекунды, то тут – на малых блоках – от пяти до шести:
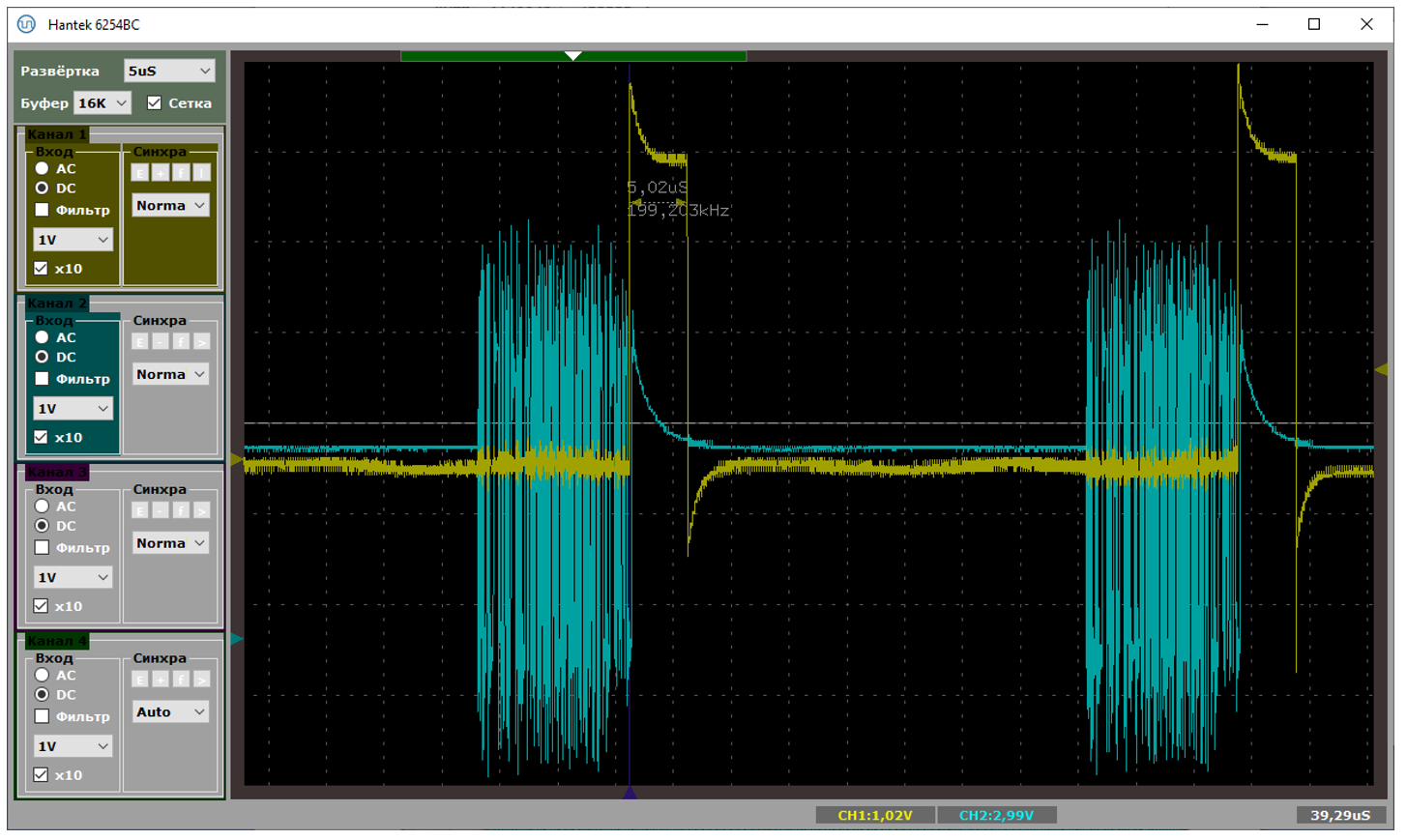
А на больших – могут быть даже десять и одиннадцать микросекунд. Получается вот такая страшная осциллограмма:
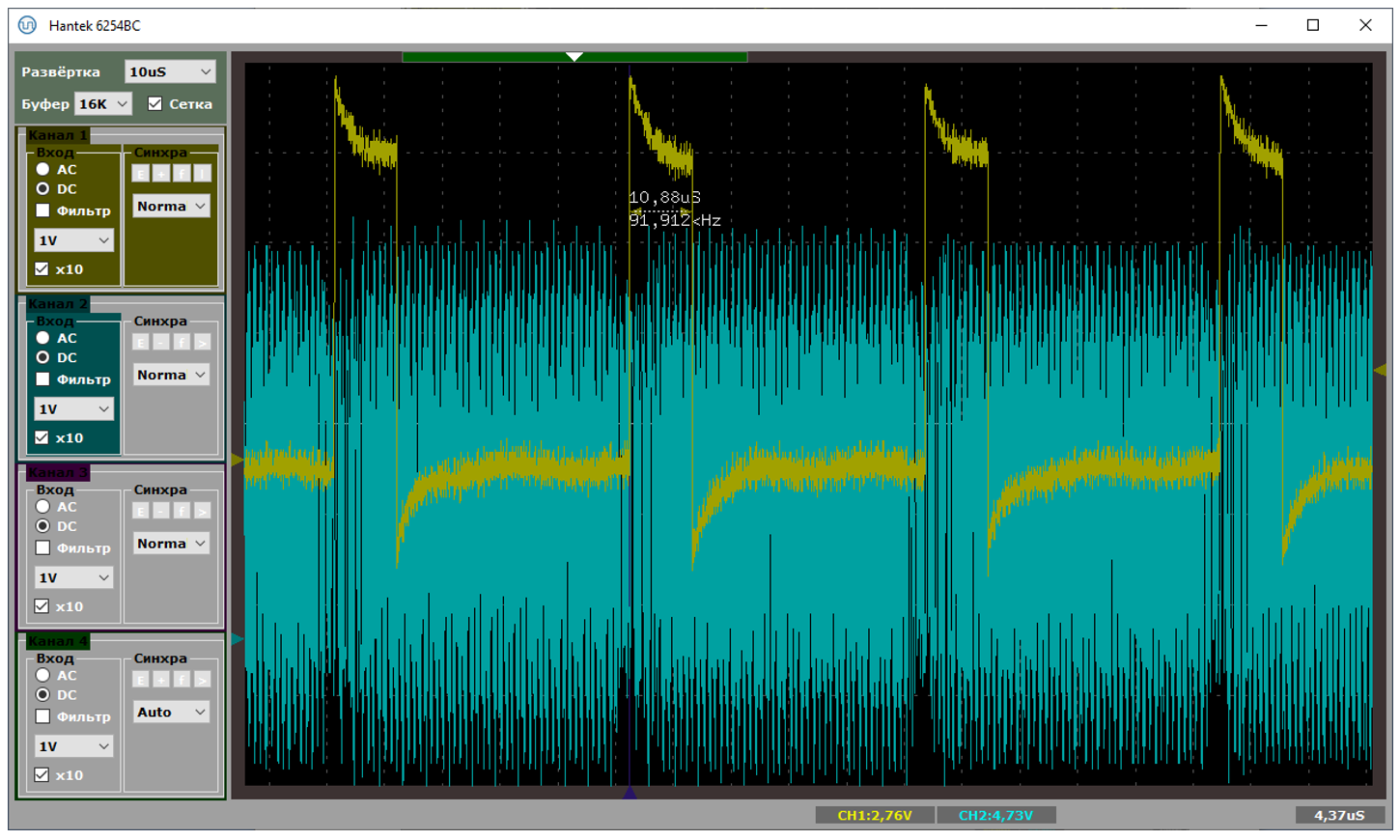
Как же это соотносится с тем, что данные спокойно идут во время обработки прерывания? Просто автор реализовал корректную работу с двойной буферизацией. Всё работает исключительно благодаря ей.
В общем, не зря я статью написал. В итоге, теперь есть знание, где живёт и код с минимальным временем нахождения в обработчике прерывания, и код, где обработчик более долгоиграющий, но зато реализована двойная буферизация. Огромное спасибо всем авторам, которые прислали свои варианты библиотек. Теперь ссылки на них будут жить в одном месте. Можно изучать их и либо брать любую, либо создавать что-то на их основе.
Послесловие. А что там в режиме HS?
Ради интереса приведу результаты, снятые для HS-устройства на базе ПЛИС. Второй столбец – скорость при прямом подключении к материнской плате, третий – через тот самый дешёвый хаб. Мне уже интересно, почему там хаб даёт такую просадку, но с этим я разберусь как-нибудь в другой раз.

А пока статья лежала «в столе», я взял типовой пример CDC-прошивки от NXP, немного доработал его (без доработки он «зависнет» при односторонней передаче), залил в плату Teensy 4.1 и снял метрики там. У него контроллер EHCI и скорость HS.
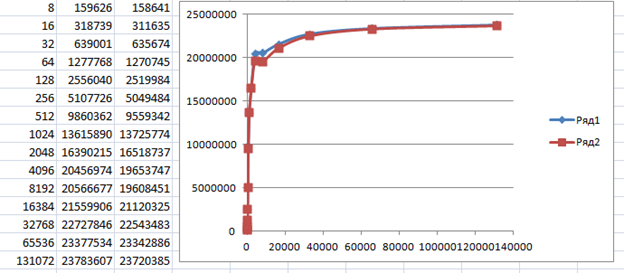
Причина – та же самая. Аппаратура, вроде, позволяет поставить в очередь несколько запросов (как для асинхронной работы), но увы, программная часть это явно запрещает:
usb_status_t USB_DeviceCdcAcmRecv(class_handle_t handle, uint8_t ep, uint8_t *buffer, uint32_t length)
{
…
if (1U == cdcAcmHandle->bulkOut.isBusy)
{
return kStatus_USB_Busy;
}
cdcAcmHandle->bulkOut.isBusy = 1U;
…
Правда, там, за счёт резервов аппаратуры, удалось с минимальной доработкой улучшить графики до таких:
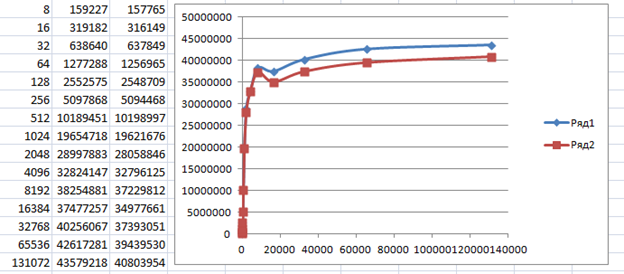
Но это уже тема для другой статьи.
