Итак, по горячим следам продолжаю публиковать материалы, касающиеся основ управления конфигурацией программных средств. Прочитайте предыдущую заметку, если вдруг пропустили.
Ниже речь пойдет о следующих вещах:
— Рабочие продукты и конфигурации;
— Компонентная разработка;
— Продуктовые линейки;
— Стабилизация результатов работы;
— Baselines AKA базовые конфигурации;
— Конфигурации при компонентной разработке;
— Конфигурации при наличии продуктовых линеек.
Что же будет являться рабочими продуктами в рамках проекта? Понятно, что для маркетинга и менеджмента продукт будет ровно один – тот, за который компания получит деньги. Ну, или несколько, по числу видов коробок, выдаваемых на рынок. Нас же интересует «нижний уровень» – то, чем будут оперировать постановщики задач, разработчики, тестеры и вообще каждый участник проекта. Задача CM – определить множество тех элементов, которые будут создаваться и изменяться командой. На этом этапе появляется понятие «configuration item» («элемент конфигурации») – это атомарный элемент, которым наиболее удобно управлять в рамках разработки. В дальнейшем будем называть его просто «CI».
К нему относятся такие объекты, как:
Получается, что CI – это любой файл в рамках проекта? Нет, нас интересуют только те файлы, которые необходимы и достаточны для создания конечного продукта для заказчика. Поэтому нам не нужны будут служебные и промежуточные файлы, генерируемые компиляторами, интерпретаторами и IDE. Нам также вряд ли будут интересны записи в блогах и форумах, проектная переписка и прочие продукты общения. Конечно, проектный документ по CM опишет средства общения внутри команды – но не более того.
К объектам, попадающим под действие CM, относятся и любые объекты, поставляемые вовне (инсталяторы, маркетинговые материалы и т.п.). Хоть их и можно получить из перечисленных выше рабочих продуктов, но конечный продукт, выдаваемый пользователю, также нуждается в идентификации.
Как же эти элементы конфигурации, атомарные единицы учета, организуются внутри проекта?
Складываются они вместе согласно архитектуре самого приложения. Ведь разработчики, как правило, стремятся уменьшить сложность производимых систем. С этой целью они раскладывают создаваемое на взаимосвязанные части – классы, компоненты, библиотеки, подсистемы и т.п. Упростим терминологию и в дальнейшем любые составные части создаваемых систем будем называть компонентами. CM же берёт эту организацию за основу и структурирует рабочие продукты соответствующим образом с помощью своих инструментов и политик.
Компоненты становятся новыми элементами конфигурации. Они становятся самостоятельными рабочими единицами, так же подлежащими единому контролю. Кроме того, они могут устанавливать даже собственный процесс разработки. CM’ные практики в этом случае нужны для того, чтобы эти отдельные блоки контролировать самостоятельным образом, получать промежуточные версии, стабилизировать и выпускать для интеграции в продукт более высокого уровня.
Итак, создаем систему, строим её из кирпичиков-компонентов. И нередка ситуация, когда одна система поставляется сразу в нескольких вариантах. За примерами далеко ходить не надо, взгляните на варианты поставки «Висты». И зачастую всё отличие разных вариантов/версий/редакций продуктов – всего в одном или нескольких компонентах, а то и вовсе в настройках. Как быть? Для этого создается то, что для простоты дальнейшего изложения будем называть продуктовыми линейками. Продуктовая линейка – это ответвление в истории развития продукта, дающее возможность изменять часть компонент независимо от других подобных ответвлений. (Здесь понятие «продукт» употребляется с маркетинговой точки зрения.)
Всё по теории эволюции – одноклеточное остается одноклеточным, но в результате мутаций и цепи случайностей (или же по злому умыслу) дает жизнь многоклеточным. Была линейка человекообразных приматов – от неё отделилась линейка homo sapience, но начальная порода обезьян продолжила жить своей жизнью. «Компоненты» у каждой «линейки» – почти на 99% совпадают. И только несколько процентов (мозги и ещё кое-что по мелочи) разрабатываются эволюцией независимо от родительской линейки и отличают одни виды от других.
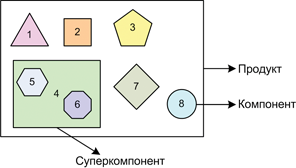
Схема 1. Соотношение компонентов, суперкомпонента и продукта.
На схеме 1 образно показан компонентный состав продукта. 1-8 — это компоненты, 4 — это «суперкомпонент», включающий в себя компоненты 5 и 6. В рамках интеграции продукта работа с ним ведется, как с обычным компонентом.
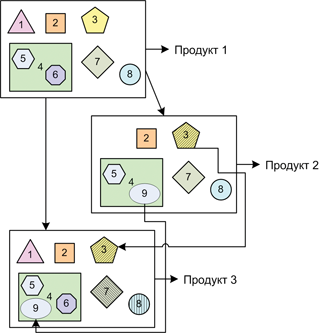
Схема 2. Соотношение компонент и продуктов при использовании продуктовых линеек.
На схеме 2 показано, как одни и те же компоненты могут быть использованы при работе с продуктовыми линейками. Например, имеется Продукт 1, состоящий из нескольких компонентов и суперкомпонента. На его основе производятся продукты 2 и 3.
Продукт 2 берет все те же компоненты, за исключением 1 и 6 — они исключаются из работы (или игнорированием соответствующих директорий, или выключением директив компиляции). В дополнение, изменяется компонент 3 — он становится 3' (штрих не проглядите). Также в единственный суперкомпонент добавляется новый компонент за номером 9.
Продукт 3 также берет за основу кодовую базу Продукта 1, однако берет в себя ещё и изменения из Продукта 2 — компоненты 9 и 3'. Также изменениям подвергаются компоненты 7 и 8, которые теперь называются 7' и 8' соответственно (да, тоже со штрихами).
Что в итоге? В итоге имеем несколько компонентов, интегрируемых одновременно в два-три разных продукта. Возьмем, к примеру, номер 2 – он неизменен во всех трёх продуктах. Напрашивается вывод – выпустить его один раз и просто «вставить» везде, где потребуют. Так и делается – компонентная команда в лице CM-инженера стабилизирует работу и передает на дальнейшую интеграцию трём «продуктовым» командам. Аналогично поступает CM-команда компонента 3’ – после внесения изменений поверх «предка» 3, полученный релиз компонента 3’ отдается в два продукта.
Причем использование одного компонента в разных продуктах – это не копирование исходников из директорий одного продукта в другой. Нет, смысл заключается именно в том, чтобы выпущенная конфигурация компонента находилась в системе контроля версий и все заинтересованные просто обращались к нему по мере включения в свой код.
А что же СМ?
В технической плоскости CM является связующим звеном между компонентами и линейками. В управленческой плоскости, где принимаются архитектурные решения, рулят менеджеры, тим-лиды, архитекторы, а всю техническую поддержку этого разделения возлагают на CM-инженеров. Именно они дают конечным разработчикам инструкции («политики») о том, в какие системы контроля складывать свой код, как именно его туда складывать, как регистрировать изменения в системах багтрекинга, каков порядок объединения компонент, что в каком виде давать тестерам и как выпускать продукт заказчику. Сами же продукты становятся новыми элементами конфигурации.
Основной вывод: CM помогает определить, из каких кирпичей мы будем складывать продукт и дает цементный раствор для их скрепления. Какими методами определяет и скрепляет – рассмотрим дальше.
Итак, определили рабочие продукты, компоненты, линейки – пора и за дело браться. Начинается цикл разработки. Работа идет, рабочие продукты появляются, изменяются, создаются новые компоненты, разделяются линейки – жизнь кипит. Как всегда, в определенный момент хочется остановиться, оглянуться назад и понять – в какой точке находится продукт, что и как уже сделано, каковы планы. Для того чтобы получить полную картину, нужно привести разработку к какому-то общему знаменателю. С точки зрения менеджмента это может быть сделано по-разному – можно, например, посмотреть прогресс работ, получить срез метрик и т.п. – и далее принять какое-то решение, касающееся распределения задач.
С точки зрения CM’а это означает, что надо стабилизировать конфигурацию рабочих продуктов. Например, имея команду из 20 человек, нужно взять все наработанные разными людьми куски функциональности – документы, код и друге результаты – и свести их воедино.
Стабилизация конфигурации – это процесс получения новой конфигурации из имеющихся промежуточных конфигураций. Для этого процесса также используются также термины «выпуск», «release» или «релиз». Результат стабилизации также может быть назван, в свою очередь, релизом или выпуском.
Например, есть основная конфигурация – версия продукта 1.0. Есть промежуточная конфигурация – разработанная девелопером новая «фича». Есть также 2 другие конфигурации – поправленные ошибки от двух других разработчиков. Стабилизацией в данном случае будет объединение результатов работы всех трех разработчиков и создание из них новой конфигурации, т.е. набора CI, которые образуют готовый продукт.
Полученная конфигурация проверяется на соответствие требованиям к составляющим её рабочим продуктам. Требования могут быть разнообразными, как правило, это количественные критерии качества. Скажем, в приведенном примере с 3 девелоперами, подобное требование к коду – это успешное прохождение 98% регрессионных тестов. Код от всех разработчиков интегрируется, конфигурация стабилизируется, продукт собирается (например, отстраивается) и отдается на тесты.
Для релиза также делаются release notes. На русский этот термин переводится как «заметки о выпуске» или «дополнительные сведения» – так этот термин звучит в глоссарии Microsoft. Также может быть использовано «описание выпуска».
В заметках о выпуске подробно указывается:
Если конфигурация соответствует требованиям, предъявляемым к стабильным релизам, то конфигурация считается стабильной. Например, если процент пройденных регрессионных тестов – 98%. По выбору менеджмента или CM-инженера, она становится тем, что называется «baseline».
Baseline – это конфигурация, выбранная и закрепленная на любом этапе жизненного цикла разработки как основа для дальнейшей работы. Переводом термина могут быть фразы «базовая конфигурация», «базовый уровень», «базовая версия» или «стабильная база». В дальнейшем будет преимущественно использован термин «базовая конфигурация».
Если вернуться обратно к нашему примеру про трёх разработчиков, то там стабилизированная конфигурация прошла оценку качества. То же самое обязательно и при выпуске базовой конфигурации. Менеджмент (тим-лид или SQA) смотрит на показатели качества, а также на другие факторы – например, на результаты инспекций кода или что-то ещё, что может вызвать сомнения. После чего принимает решение о том, что релиз должен быть взят за основу для работы всех остальных разработчиков, быть базой для разработки. Далее CM-инженер выполняет разного рода действия (например, навешивает метку и отстраивает код продукта) и выбранная конфигурация становится базовой. При этом она (как минимум, в виде исходников) выкладывается в открытый для всей команды доступ.
Возможен вариант, когда конфигурация не проходит по критериям качества и вообще не может быть использована для сборки конечного продукта. Например, продукт только начал разрабатываться и готов только код отдельных компонентов, да и у тех – заглушки вместо работающих функций. Нужно сделать конфигурацию основой работы для всей команды, но при этом миновать процедуру релиза – просто потому, что пока нельзя ничего собрать воедино. Такая конфигурация также имеет право быть использованной в качестве базовой, главное — четко обозначить имеющиеся ограничения по использованию в заметках о выпуске.
Любой выпуск базовой конфигурации обязательно снабжается заметками о выпуске. Участник команды, берущий подобную конфигурацию для работы, должен знать – от чего именно он будет отталкиваться в работе. Также надо знать, есть ли в новой конфигурации те новые функции или исправления ошибок, от которых может зависеть его работа. Не лишним будет также знать, нужны ли какие-то специальные процедуры апгрейда его экземпляра системы перед использованием новой базы для разработки. Вся перечисленная информация как раз дается в заметках о выпуске.
Во многих командах результаты интеграционной работы (появляющиеся релизы и базовые конфигурации) выкладываются в специально отведенное место – область релизов, или release area. Организация этой области и поддержание её в актуальном виде – задача CM-инженеров.
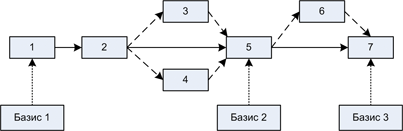
Схема 3. Связь конфигураций, релизов и базовых конфигураций.
На Схеме 3 показан небольшой пример появления конфигураций во времени. Начальное состояние проекта – конфигурация 1. Она же является первым базисом, от которого будет идти дальнейшая разработка. Предположим, проект на начальной стадии. Через какое-то время появляется обновленная конфигурация 2. Разработка только началась и мы выпустили релиз, чтобы выдать команде хоть какую-то основу для дальнейшей работы. В ходе проверки выяснилось, что базой для работы этот выпуск служить не может – есть непонятные и противоречивые места.
Для их устранения группы разработки делают доработки. В результате них появляются конфигурации 3 и 4 – оба они разработаны на основе 2, но друг с другом они пока не согласуются, поскольку не включают изменения друг от друга. CM-инженер создает итоговую конфигурацию 5, сделанную на основе 2, 3 и 4. После проверки менеджмент дает отмашку – базовой конфигурации быть! По этому сигналу CM-команда выпускает этот релиз как официальную базовую конфигурацию и разработчики берут уже её за основу.
Далее история повторяется – группа разработки вносит изменения – появляется конфигурация 5. Её, в свою очередь, интегрирует CM-инженер и она получает номер 7. Он также становится официальной базой для разработки.
Аналогичный подход используется и при компонентной разработке. Внутри каждого компонента идет работа, в рабочих продуктах и их элементах конфигурации постоянно появляются изменения, надо их периодически, или же по требованию менеджмента, стабилизировать. Каждый компонент делает это в общем случае самостоятельно и с тем графиком, который требуется именно для него. Поэтому, например, для одной команды стабилизация и выпуск релиза делается 5 раз в неделю, для другой – 1 раз в 2 недели.
Поскольку компоненты объединяются в единое целое, должны существовать отдельные процедуры и ресурсы для подобной системной интеграции. В этом случае работа интеграционной команды вышестоящего компонента или всей системы лишь немногим отличается от работы интеграторов компонентов. Отличается только масштаб, а также, возможно, инструменты и критерии оценки зрелости получаемых релизов.
В частности, после интеграции всей системы нужно не просто пройти регрессионное тестирование каждого входящего компонента. Надо ещё прогнать системные тесты, проверяющие взаимодействие разных частей системы между собой – как правило, это не входит в область тестирования каждой отдельной подсистемы. Кроме того, от CM’ной команды всего продукта может потребоваться сбор дополнительных метрик. Всё это требует больших ресурсов и некоторой доработки политик CM-команды вышестоящего компонента.
Как меняются политики CM в случае, когда у нас не один продукт, а целое их множество, т.е. продуктовая линейка? Всё становится гораздо интереснее. Конечно, работа внутри компонентных команд продолжается так же, как и в других случаях. Изменяется их взаимодействие друг с другом.
Во-первых, компонентной команде надо учитывать все возможные зависимости их кода от других компонентов. И учитывать, что от продукта к продукту могут меняться интерфейсы и поведение каких-то функций. Отслеживание зависимостей – отдельная большая тема, так что пока не будем трогать её.
Во-вторых, изменяется порядок интеграции каждого компонента в конечные продукты. Теперь каждая базовая конфигурация должна отдаваться на интеграцию только в те продукты, которые требуют функциональность, разрабатываемую в ней. Или же необходимо проверять, чтобы новая функциональность, предназначенная для одного продукта, не начала вдруг работать в другом и вызывать поломки.
В-третьих, разработчик должен постоянно думать о том, как будут работать его изменения на разных продуктах. Ведь в них могут быть задействованы совершенно разные наборы функциональности – поэтому в коде надо делать соответствующие проверки.
Отсюда следуют две возможные линии поведения компонентных команд:
1. Выпуск стольких линеек компонентов, сколько продуктов сейчас находится в работе и сопровождении. Накладный вариант с точки зрения отслеживания изменений и конфигураций, а также сложно с точки зрения интеграции одних и тех же изменений в разные компонентные линейки.
2. Поддержка всех продуктов и их наборов функциональности одновременно в одной линейке компонента. При этом надо организовать код таким образом, чтобы можно было гибко «включать» и «выключать» функциональность через настройки во время «отстройки» системы или во время её инсталляции и запуска в эксплуатацию. Также появляются накладные расходы для разработчиков, которые, ожидая каждого вносимого изменения, вынуждены учитывать, как это изменение повлияет на работу каждой из фич, затронутых измененным кодом.
Отсюда же следует и поведение команды CM. Надо учитывать то, как идет работа в командах и вести стабилизацию компонентов/продуктов и выпуск их базовых конфигураций соответствующим образом. В целом же тема эта обширна и стоит отдельной статьи с большим числом примеров из жизни. Пока что просто примем за данность следующее обстоятельство — продукты и компоненты имеют свойства разветвляться и политики, а проектная документация по CM должна это учитывать.
Итак, из всех задач CM’а, упомянутых в первой заметке, были подробно рассмотрены:
Многие вещи были рассмотрены декларативно — мол, вот так вот надо делать. Чуть позже, в других заметках, я расскажу о практическом значении введенных терминов, которые могли показаться чисто теоретическими.
Для самостоятельного ознакомления по-прежнему рекомендую ссылки из прошлой заметки, плюс вот эту Вики-статью:
Следующие заметки будут посвящены более практическим вещам — контролю версий и отслеживанию запросов на изменениями.
Продолжение следует.
Ниже речь пойдет о следующих вещах:
— Рабочие продукты и конфигурации;
— Компонентная разработка;
— Продуктовые линейки;
— Стабилизация результатов работы;
— Baselines AKA базовые конфигурации;
— Конфигурации при компонентной разработке;
— Конфигурации при наличии продуктовых линеек.
Рабочие продукты и конфигурации
Что же будет являться рабочими продуктами в рамках проекта? Понятно, что для маркетинга и менеджмента продукт будет ровно один – тот, за который компания получит деньги. Ну, или несколько, по числу видов коробок, выдаваемых на рынок. Нас же интересует «нижний уровень» – то, чем будут оперировать постановщики задач, разработчики, тестеры и вообще каждый участник проекта. Задача CM – определить множество тех элементов, которые будут создаваться и изменяться командой. На этом этапе появляется понятие «configuration item» («элемент конфигурации») – это атомарный элемент, которым наиболее удобно управлять в рамках разработки. В дальнейшем будем называть его просто «CI».
К нему относятся такие объекты, как:
- рабочие документы;
- файлы исходных кодов;
- файлы ресурсов;
- файлы, создаваемые в результате сборки (исполняемые файлы, dll'ки);
- инструменты, используемые для разработки (их мы тоже должны учитывать для стандартизации и упрощения взаимодействия в команде);
Получается, что CI – это любой файл в рамках проекта? Нет, нас интересуют только те файлы, которые необходимы и достаточны для создания конечного продукта для заказчика. Поэтому нам не нужны будут служебные и промежуточные файлы, генерируемые компиляторами, интерпретаторами и IDE. Нам также вряд ли будут интересны записи в блогах и форумах, проектная переписка и прочие продукты общения. Конечно, проектный документ по CM опишет средства общения внутри команды – но не более того.
К объектам, попадающим под действие CM, относятся и любые объекты, поставляемые вовне (инсталяторы, маркетинговые материалы и т.п.). Хоть их и можно получить из перечисленных выше рабочих продуктов, но конечный продукт, выдаваемый пользователю, также нуждается в идентификации.
Компонентная разработка и продуктовые линейки
Как же эти элементы конфигурации, атомарные единицы учета, организуются внутри проекта?
Складываются они вместе согласно архитектуре самого приложения. Ведь разработчики, как правило, стремятся уменьшить сложность производимых систем. С этой целью они раскладывают создаваемое на взаимосвязанные части – классы, компоненты, библиотеки, подсистемы и т.п. Упростим терминологию и в дальнейшем любые составные части создаваемых систем будем называть компонентами. CM же берёт эту организацию за основу и структурирует рабочие продукты соответствующим образом с помощью своих инструментов и политик.
Компоненты становятся новыми элементами конфигурации. Они становятся самостоятельными рабочими единицами, так же подлежащими единому контролю. Кроме того, они могут устанавливать даже собственный процесс разработки. CM’ные практики в этом случае нужны для того, чтобы эти отдельные блоки контролировать самостоятельным образом, получать промежуточные версии, стабилизировать и выпускать для интеграции в продукт более высокого уровня.
Итак, создаем систему, строим её из кирпичиков-компонентов. И нередка ситуация, когда одна система поставляется сразу в нескольких вариантах. За примерами далеко ходить не надо, взгляните на варианты поставки «Висты». И зачастую всё отличие разных вариантов/версий/редакций продуктов – всего в одном или нескольких компонентах, а то и вовсе в настройках. Как быть? Для этого создается то, что для простоты дальнейшего изложения будем называть продуктовыми линейками. Продуктовая линейка – это ответвление в истории развития продукта, дающее возможность изменять часть компонент независимо от других подобных ответвлений. (Здесь понятие «продукт» употребляется с маркетинговой точки зрения.)
Всё по теории эволюции – одноклеточное остается одноклеточным, но в результате мутаций и цепи случайностей (или же по злому умыслу) дает жизнь многоклеточным. Была линейка человекообразных приматов – от неё отделилась линейка homo sapience, но начальная порода обезьян продолжила жить своей жизнью. «Компоненты» у каждой «линейки» – почти на 99% совпадают. И только несколько процентов (мозги и ещё кое-что по мелочи) разрабатываются эволюцией независимо от родительской линейки и отличают одни виды от других.
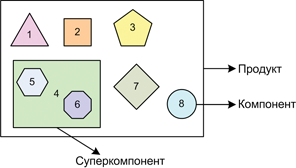
Схема 1. Соотношение компонентов, суперкомпонента и продукта.
На схеме 1 образно показан компонентный состав продукта. 1-8 — это компоненты, 4 — это «суперкомпонент», включающий в себя компоненты 5 и 6. В рамках интеграции продукта работа с ним ведется, как с обычным компонентом.
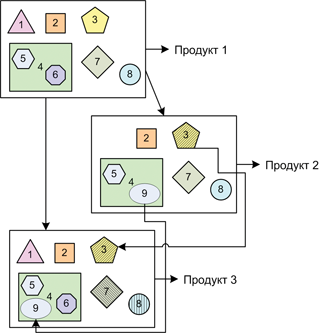
Схема 2. Соотношение компонент и продуктов при использовании продуктовых линеек.
На схеме 2 показано, как одни и те же компоненты могут быть использованы при работе с продуктовыми линейками. Например, имеется Продукт 1, состоящий из нескольких компонентов и суперкомпонента. На его основе производятся продукты 2 и 3.
Продукт 2 берет все те же компоненты, за исключением 1 и 6 — они исключаются из работы (или игнорированием соответствующих директорий, или выключением директив компиляции). В дополнение, изменяется компонент 3 — он становится 3' (штрих не проглядите). Также в единственный суперкомпонент добавляется новый компонент за номером 9.
Продукт 3 также берет за основу кодовую базу Продукта 1, однако берет в себя ещё и изменения из Продукта 2 — компоненты 9 и 3'. Также изменениям подвергаются компоненты 7 и 8, которые теперь называются 7' и 8' соответственно (да, тоже со штрихами).
Что в итоге? В итоге имеем несколько компонентов, интегрируемых одновременно в два-три разных продукта. Возьмем, к примеру, номер 2 – он неизменен во всех трёх продуктах. Напрашивается вывод – выпустить его один раз и просто «вставить» везде, где потребуют. Так и делается – компонентная команда в лице CM-инженера стабилизирует работу и передает на дальнейшую интеграцию трём «продуктовым» командам. Аналогично поступает CM-команда компонента 3’ – после внесения изменений поверх «предка» 3, полученный релиз компонента 3’ отдается в два продукта.
Причем использование одного компонента в разных продуктах – это не копирование исходников из директорий одного продукта в другой. Нет, смысл заключается именно в том, чтобы выпущенная конфигурация компонента находилась в системе контроля версий и все заинтересованные просто обращались к нему по мере включения в свой код.
А что же СМ?
В технической плоскости CM является связующим звеном между компонентами и линейками. В управленческой плоскости, где принимаются архитектурные решения, рулят менеджеры, тим-лиды, архитекторы, а всю техническую поддержку этого разделения возлагают на CM-инженеров. Именно они дают конечным разработчикам инструкции («политики») о том, в какие системы контроля складывать свой код, как именно его туда складывать, как регистрировать изменения в системах багтрекинга, каков порядок объединения компонент, что в каком виде давать тестерам и как выпускать продукт заказчику. Сами же продукты становятся новыми элементами конфигурации.
Основной вывод: CM помогает определить, из каких кирпичей мы будем складывать продукт и дает цементный раствор для их скрепления. Какими методами определяет и скрепляет – рассмотрим дальше.
Стабилизация результатов работы
Итак, определили рабочие продукты, компоненты, линейки – пора и за дело браться. Начинается цикл разработки. Работа идет, рабочие продукты появляются, изменяются, создаются новые компоненты, разделяются линейки – жизнь кипит. Как всегда, в определенный момент хочется остановиться, оглянуться назад и понять – в какой точке находится продукт, что и как уже сделано, каковы планы. Для того чтобы получить полную картину, нужно привести разработку к какому-то общему знаменателю. С точки зрения менеджмента это может быть сделано по-разному – можно, например, посмотреть прогресс работ, получить срез метрик и т.п. – и далее принять какое-то решение, касающееся распределения задач.
С точки зрения CM’а это означает, что надо стабилизировать конфигурацию рабочих продуктов. Например, имея команду из 20 человек, нужно взять все наработанные разными людьми куски функциональности – документы, код и друге результаты – и свести их воедино.
Стабилизация конфигурации – это процесс получения новой конфигурации из имеющихся промежуточных конфигураций. Для этого процесса также используются также термины «выпуск», «release» или «релиз». Результат стабилизации также может быть назван, в свою очередь, релизом или выпуском.
Например, есть основная конфигурация – версия продукта 1.0. Есть промежуточная конфигурация – разработанная девелопером новая «фича». Есть также 2 другие конфигурации – поправленные ошибки от двух других разработчиков. Стабилизацией в данном случае будет объединение результатов работы всех трех разработчиков и создание из них новой конфигурации, т.е. набора CI, которые образуют готовый продукт.
Полученная конфигурация проверяется на соответствие требованиям к составляющим её рабочим продуктам. Требования могут быть разнообразными, как правило, это количественные критерии качества. Скажем, в приведенном примере с 3 девелоперами, подобное требование к коду – это успешное прохождение 98% регрессионных тестов. Код от всех разработчиков интегрируется, конфигурация стабилизируется, продукт собирается (например, отстраивается) и отдается на тесты.
Для релиза также делаются release notes. На русский этот термин переводится как «заметки о выпуске» или «дополнительные сведения» – так этот термин звучит в глоссарии Microsoft. Также может быть использовано «описание выпуска».
В заметках о выпуске подробно указывается:
- наименование нового релиза;
- базис, на котором он основан (см. «базовая конфигурация»);
- изменения, вошедшие в релиз;
- описание процедуры апгрейда рабочей копии системы, если необходимо,;
- также, если необходимо, включается описание процедуры самостоятельной подготовки исполнимых файлов.
Если конфигурация соответствует требованиям, предъявляемым к стабильным релизам, то конфигурация считается стабильной. Например, если процент пройденных регрессионных тестов – 98%. По выбору менеджмента или CM-инженера, она становится тем, что называется «baseline».
Базовая конфигурация
Baseline – это конфигурация, выбранная и закрепленная на любом этапе жизненного цикла разработки как основа для дальнейшей работы. Переводом термина могут быть фразы «базовая конфигурация», «базовый уровень», «базовая версия» или «стабильная база». В дальнейшем будет преимущественно использован термин «базовая конфигурация».
Если вернуться обратно к нашему примеру про трёх разработчиков, то там стабилизированная конфигурация прошла оценку качества. То же самое обязательно и при выпуске базовой конфигурации. Менеджмент (тим-лид или SQA) смотрит на показатели качества, а также на другие факторы – например, на результаты инспекций кода или что-то ещё, что может вызвать сомнения. После чего принимает решение о том, что релиз должен быть взят за основу для работы всех остальных разработчиков, быть базой для разработки. Далее CM-инженер выполняет разного рода действия (например, навешивает метку и отстраивает код продукта) и выбранная конфигурация становится базовой. При этом она (как минимум, в виде исходников) выкладывается в открытый для всей команды доступ.
Возможен вариант, когда конфигурация не проходит по критериям качества и вообще не может быть использована для сборки конечного продукта. Например, продукт только начал разрабатываться и готов только код отдельных компонентов, да и у тех – заглушки вместо работающих функций. Нужно сделать конфигурацию основой работы для всей команды, но при этом миновать процедуру релиза – просто потому, что пока нельзя ничего собрать воедино. Такая конфигурация также имеет право быть использованной в качестве базовой, главное — четко обозначить имеющиеся ограничения по использованию в заметках о выпуске.
Любой выпуск базовой конфигурации обязательно снабжается заметками о выпуске. Участник команды, берущий подобную конфигурацию для работы, должен знать – от чего именно он будет отталкиваться в работе. Также надо знать, есть ли в новой конфигурации те новые функции или исправления ошибок, от которых может зависеть его работа. Не лишним будет также знать, нужны ли какие-то специальные процедуры апгрейда его экземпляра системы перед использованием новой базы для разработки. Вся перечисленная информация как раз дается в заметках о выпуске.
Во многих командах результаты интеграционной работы (появляющиеся релизы и базовые конфигурации) выкладываются в специально отведенное место – область релизов, или release area. Организация этой области и поддержание её в актуальном виде – задача CM-инженеров.
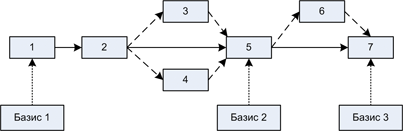
Схема 3. Связь конфигураций, релизов и базовых конфигураций.
На Схеме 3 показан небольшой пример появления конфигураций во времени. Начальное состояние проекта – конфигурация 1. Она же является первым базисом, от которого будет идти дальнейшая разработка. Предположим, проект на начальной стадии. Через какое-то время появляется обновленная конфигурация 2. Разработка только началась и мы выпустили релиз, чтобы выдать команде хоть какую-то основу для дальнейшей работы. В ходе проверки выяснилось, что базой для работы этот выпуск служить не может – есть непонятные и противоречивые места.
Для их устранения группы разработки делают доработки. В результате них появляются конфигурации 3 и 4 – оба они разработаны на основе 2, но друг с другом они пока не согласуются, поскольку не включают изменения друг от друга. CM-инженер создает итоговую конфигурацию 5, сделанную на основе 2, 3 и 4. После проверки менеджмент дает отмашку – базовой конфигурации быть! По этому сигналу CM-команда выпускает этот релиз как официальную базовую конфигурацию и разработчики берут уже её за основу.
Далее история повторяется – группа разработки вносит изменения – появляется конфигурация 5. Её, в свою очередь, интегрирует CM-инженер и она получает номер 7. Он также становится официальной базой для разработки.
Конфигурации при компонентной разработке
Аналогичный подход используется и при компонентной разработке. Внутри каждого компонента идет работа, в рабочих продуктах и их элементах конфигурации постоянно появляются изменения, надо их периодически, или же по требованию менеджмента, стабилизировать. Каждый компонент делает это в общем случае самостоятельно и с тем графиком, который требуется именно для него. Поэтому, например, для одной команды стабилизация и выпуск релиза делается 5 раз в неделю, для другой – 1 раз в 2 недели.
Поскольку компоненты объединяются в единое целое, должны существовать отдельные процедуры и ресурсы для подобной системной интеграции. В этом случае работа интеграционной команды вышестоящего компонента или всей системы лишь немногим отличается от работы интеграторов компонентов. Отличается только масштаб, а также, возможно, инструменты и критерии оценки зрелости получаемых релизов.
В частности, после интеграции всей системы нужно не просто пройти регрессионное тестирование каждого входящего компонента. Надо ещё прогнать системные тесты, проверяющие взаимодействие разных частей системы между собой – как правило, это не входит в область тестирования каждой отдельной подсистемы. Кроме того, от CM’ной команды всего продукта может потребоваться сбор дополнительных метрик. Всё это требует больших ресурсов и некоторой доработки политик CM-команды вышестоящего компонента.
Конфигурации продуктовых линеек
Как меняются политики CM в случае, когда у нас не один продукт, а целое их множество, т.е. продуктовая линейка? Всё становится гораздо интереснее. Конечно, работа внутри компонентных команд продолжается так же, как и в других случаях. Изменяется их взаимодействие друг с другом.
Во-первых, компонентной команде надо учитывать все возможные зависимости их кода от других компонентов. И учитывать, что от продукта к продукту могут меняться интерфейсы и поведение каких-то функций. Отслеживание зависимостей – отдельная большая тема, так что пока не будем трогать её.
Во-вторых, изменяется порядок интеграции каждого компонента в конечные продукты. Теперь каждая базовая конфигурация должна отдаваться на интеграцию только в те продукты, которые требуют функциональность, разрабатываемую в ней. Или же необходимо проверять, чтобы новая функциональность, предназначенная для одного продукта, не начала вдруг работать в другом и вызывать поломки.
В-третьих, разработчик должен постоянно думать о том, как будут работать его изменения на разных продуктах. Ведь в них могут быть задействованы совершенно разные наборы функциональности – поэтому в коде надо делать соответствующие проверки.
Отсюда следуют две возможные линии поведения компонентных команд:
1. Выпуск стольких линеек компонентов, сколько продуктов сейчас находится в работе и сопровождении. Накладный вариант с точки зрения отслеживания изменений и конфигураций, а также сложно с точки зрения интеграции одних и тех же изменений в разные компонентные линейки.
2. Поддержка всех продуктов и их наборов функциональности одновременно в одной линейке компонента. При этом надо организовать код таким образом, чтобы можно было гибко «включать» и «выключать» функциональность через настройки во время «отстройки» системы или во время её инсталляции и запуска в эксплуатацию. Также появляются накладные расходы для разработчиков, которые, ожидая каждого вносимого изменения, вынуждены учитывать, как это изменение повлияет на работу каждой из фич, затронутых измененным кодом.
Отсюда же следует и поведение команды CM. Надо учитывать то, как идет работа в командах и вести стабилизацию компонентов/продуктов и выпуск их базовых конфигураций соответствующим образом. В целом же тема эта обширна и стоит отдельной статьи с большим числом примеров из жизни. Пока что просто примем за данность следующее обстоятельство — продукты и компоненты имеют свойства разветвляться и политики, а проектная документация по CM должна это учитывать.
Вместо заключения
Итак, из всех задач CM’а, упомянутых в первой заметке, были подробно рассмотрены:
- идентификация рабочих продуктов;
- стабилизация результатов работы и определение базы для дальнейшей работы;
Многие вещи были рассмотрены декларативно — мол, вот так вот надо делать. Чуть позже, в других заметках, я расскажу о практическом значении введенных терминов, которые могли показаться чисто теоретическими.
Для самостоятельного ознакомления по-прежнему рекомендую ссылки из прошлой заметки, плюс вот эту Вики-статью:
- Baseline (configuration management). en.wikipedia.org/wiki/Baseline_%28configuration_management%29
Следующие заметки будут посвящены более практическим вещам — контролю версий и отслеживанию запросов на изменениями.
Продолжение следует.
