Продолжая статью “Использование Hadoop для решения реальных задач”, хочу напомнить, что в прошлой статье мы остановились на том, что посчитали такую характеристику как tf(t,d), и сказали, что в следующем посте мы будем считать idf(t) и завершим процесс вычисления значения TF-IDF для данного документа и термина. Поэтому предлагаю долго не откладывать и переходить к этой задаче.
Важно заметить, что idf(t) не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
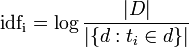
Вероятно, она нуждается в некоторых пояснениях. Итак, |D| это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество таких документов d которые содержат интересующий нас токен t_i.
Как это можно посчитать? Способов тут немало, но я предлагаю следующий. В качестве входных данных мы будем использовать результат задачи, которая расчитала нам ненормализованные значения tf(t,d), напомню, что они выглядили вот так:
В чем будет заключаться наша задача? Мы хотим понять: сколько, например, документов содержат слово
Делая это для всех документов, мы получим данные следующего формата:
Дальше все более или менее очевидно: reduce-таск получает эти данные (получает он термин и список единиц), считает количество этих самых единиц и выдает нам:
Что и требовалось доказать. Теперь задача посчитать непосредственно idf(t) становится тривиальной (впрочем, и ее можно делать на гриде, просто потому, что список слов может быть очень большой).
На последнем шаге мы считаем непосредственно TF-IDF. Вот тут-то и начинаются неприятности! Все дело в том, что у нас есть два файла — один со значениями TF, другой — со значениями IDF. В общем случае ни тот, ни другой в память не полезут. Что делать? Тупик!
Тупик, да не совсем. Здесь помогает такое странное, но весьма популярное в Map/Reduce решени как проброс данных (passthrough). Поясню свою идею на примере. Если обрабатывая наш файл со значениями TF (смотри выше), вместо единицы в вывод map-таска мы запишем комбинацию
Мы по-прежнему можем посчитать количество документов, в который входит то или иное слово — и действительно, мы же не суммировали единицы а просто считали их количество! В то же время, у нас есть некоторые дополнительные данные, а значит, мы можем модифицировать вывод reduce-таска следующим образом:
Имеем следующую забавную ситуацию — reducer на самом деле количество данных не уменьшил, но добавил некоторую новую характеристику к ним! Что мы можем сделать теперь? Да практически все что угодно! Предполагая, что мы знаем значения N и |D| (то есть количество токенов и количество документов в корпусе) мы можем реализовать простейшую Map/Reduce программу (которой и Reduce-то не понадобится). Для каждого входящей строки она будет представлять данные в следующем виде
Я надеюсь, вы понимаете, что псевдокод весьма и весьма условен (так же, как условно и использование символа подчеркнивания для разделения значений) — но суть, как мне кажется, ясна. Теперь мы можем сделать следующее:
Что у нас получилось? У нас получилось значение TF-IDF.
В рамках этой статьи мы закончили пример с расчетом значения TF-IDF для корпусов текста. Важно отметить, что увеличение мощности корпуса не приведет к возможным проблемам с нехваткой памяти, а всего лишь увеличит время расчетов (что может быть решено добавлением новых узлов в кластер). Мы рассмотрели одну из популярных техник data passthrough, часто применяемую для решения комплексных задач в Map/Reduce. Мы изучили некоторые принципы дизайна Map/Reduce приложений в целом. В дальнейших статьях мы рассмотрим решение этой и других задач для реальных данных, с примерами работающего кода.
P.S. как всегда, вопросы, комментарии, уточнения и отзывы приветствуются! Я постарался сделать это все как можно понятнее, но возможно не вполне преуспел — напишите мне об этом!
Для домашнего чтения рекомендую просмотреть слайды, выложенные товарищами из Cloudera на Scribd:
Для интересующихся также напоминаю, что английская версия статьи (целиком) доступна вот здесь: romankirillov.info/hadoop.html — там же можно скачать и PDF версию.
Важно заметить, что idf(t) не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
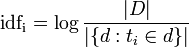
Вероятно, она нуждается в некоторых пояснениях. Итак, |D| это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество таких документов d которые содержат интересующий нас токен t_i.
Как это можно посчитать? Способов тут немало, но я предлагаю следующий. В качестве входных данных мы будем использовать результат задачи, которая расчитала нам ненормализованные значения tf(t,d), напомню, что они выглядили вот так:
1_the 3 1_to 1 ... 2_the 2 2_from 1 ... 37_london 1
В чем будет заключаться наша задача? Мы хотим понять: сколько, например, документов содержат слово
the? Решение, в общем-то, интуитивно: мы берем каждое значение, такое как 2_the, делим его на пару (2, the) и пишем в вывод map-задачи, что у нас есть как минимум один документ, который содержит слово the:the 1
Делая это для всех документов, мы получим данные следующего формата:
the 1 to 1 the 1 from 1 london 1
Дальше все более или менее очевидно: reduce-таск получает эти данные (получает он термин и список единиц), считает количество этих самых единиц и выдает нам:
the 2 to 1 from 1 london 1
Что и требовалось доказать. Теперь задача посчитать непосредственно idf(t) становится тривиальной (впрочем, и ее можно делать на гриде, просто потому, что список слов может быть очень большой).
На последнем шаге мы считаем непосредственно TF-IDF. Вот тут-то и начинаются неприятности! Все дело в том, что у нас есть два файла — один со значениями TF, другой — со значениями IDF. В общем случае ни тот, ни другой в память не полезут. Что делать? Тупик!
Тупик, да не совсем. Здесь помогает такое странное, но весьма популярное в Map/Reduce решени как проброс данных (passthrough). Поясню свою идею на примере. Если обрабатывая наш файл со значениями TF (смотри выше), вместо единицы в вывод map-таска мы запишем комбинацию
docID_tfValue? Получится что-то вроде:the 1_3 to 1_3 the 2_2 from 2_1 ... london 37_1
Мы по-прежнему можем посчитать количество документов, в который входит то или иное слово — и действительно, мы же не суммировали единицы а просто считали их количество! В то же время, у нас есть некоторые дополнительные данные, а значит, мы можем модифицировать вывод reduce-таска следующим образом:
the 2_1_3 # количество документов с the - идентификатор документа - количество the в этом док-те the 2_2_2 to 1_1_3 from 1_2_1 ... london 1_37_1
Имеем следующую забавную ситуацию — reducer на самом деле количество данных не уменьшил, но добавил некоторую новую характеристику к ним! Что мы можем сделать теперь? Да практически все что угодно! Предполагая, что мы знаем значения N и |D| (то есть количество токенов и количество документов в корпусе) мы можем реализовать простейшую Map/Reduce программу (которой и Reduce-то не понадобится). Для каждого входящей строки она будет представлять данные в следующем виде
term = key
(docCount, docId, countInDoc) = value.split("_")Я надеюсь, вы понимаете, что псевдокод весьма и весьма условен (так же, как условно и использование символа подчеркнивания для разделения значений) — но суть, как мне кажется, ясна. Теперь мы можем сделать следующее:
tf = countInDoc / TOTAL_TOKEN_COUNT idf = log(TOTAL_DOC_COUNT / docCount) result = tf * idf output(key = docId + "_" + term, value = result)
Что у нас получилось? У нас получилось значение TF-IDF.
В рамках этой статьи мы закончили пример с расчетом значения TF-IDF для корпусов текста. Важно отметить, что увеличение мощности корпуса не приведет к возможным проблемам с нехваткой памяти, а всего лишь увеличит время расчетов (что может быть решено добавлением новых узлов в кластер). Мы рассмотрели одну из популярных техник data passthrough, часто применяемую для решения комплексных задач в Map/Reduce. Мы изучили некоторые принципы дизайна Map/Reduce приложений в целом. В дальнейших статьях мы рассмотрим решение этой и других задач для реальных данных, с примерами работающего кода.
P.S. как всегда, вопросы, комментарии, уточнения и отзывы приветствуются! Я постарался сделать это все как можно понятнее, но возможно не вполне преуспел — напишите мне об этом!
Для домашнего чтения рекомендую просмотреть слайды, выложенные товарищами из Cloudera на Scribd:
- Hadoop Training #1: Thinking at Scale
- Hadoop Training #2: MapReduce & HDFS
- … и остальные презентации из этой серии.
Для интересующихся также напоминаю, что английская версия статьи (целиком) доступна вот здесь: romankirillov.info/hadoop.html — там же можно скачать и PDF версию.
