Здравствуйте, уважаемые хабражители!
Это продолжение вводной статьи о персонализации Интернета. Ниже кратко описана технология, на которой основаны реализованные компанией продукты по персонализации Интернета.
Компанией Avvea разработана технология переписывания контента динамических интернет-страниц. Такая технология не нова и известна как reverse proxy. Примерами качественных reverse proxy серверов в сфере бизнеса являются разработки компаний F5 и Juniper. Технологии разработки reverse proxy серверов каждой из этих компаний прошли более чем десятилетний путь развития и направлены на поддержку ограниченного количества сложных приложений корпоративных клиентов.
Примером reversy-proxy любительского уровня можно считать свободно распространяемую разработку Glype. Таких серверов достаточно много, среди них наиболее популярны так называемые анонимайзеры.
Рассмотрим некоторые технические особенности. Главная задача reverse proxy сервера — создание виртуальной прослойки между интерфейсом браузера и клиентским программным кодом. И чем лучше эта задача решена, тем лучше итоговый reverse proxy сервер.

Наша технология подразумевает перехват и переписывание всех интерфейсных свойств и методов всех активных элементов интернет-страницы (HTML, JavaScript, Adobe Flash, Java и других). Тем самым внутри реального браузера создается своеобразный «виртуальный браузер».
Если с HTML все просто, и даже бесплатные анонимайзеры неплохо справляются с переписью статического HTML, то, например, с JavaScript дела обстоят гораздо сложнее. До сих пор не существовало единого подхода к решению этой задачи. Наша разработка изменила положение дел.
Основную идею нового подхода покажем на примере машины по переписыванию JavaScript нашего reverse proxy сервера. Схематично машина состоит из 3 частей: лексер (lexer), парсер (parser) и патчер (patcher), каждая из которых является самостоятельным элементом системы.

Лексер — это синтаксическая основа машины, отвечающая за распознавание элементов языка в потоке символов. Парсер, основываясь на лексере, разбирает входящий поток на составляющие: переменные, функции, операции, сам язык и т.д. Патчер применяется к найденным интерфейсным свойствам и методам.
Входные потоки обрабатываются, основываясь на выражениях — элементарных, неделимых конструкциях пользовательского программного кода с точки зрения их обработки парсером. В парсере применяется специализированный двухстековый метод разборки/сборки. В одном стеке — операнды, в другом — операции с их приоритетами. Один цикл заполнения стеков — одно выражение. Благодаря этому система получилась однопроходной и потоковой. Это значит, что код отдаются браузеру по мере его загрузки. Т.е. выражения, встреченные в начале, обрабатываются сразу, как только они полностью появились в буфере патчера, без ожидания, когда загрузится весь код целиком. Все это положительно сказалось на производительности и «легкости» системы. В сочетании с разумным кэшированием запатченного кода можно иногда наблюдать эффект, когда сайт, переписанный reverse proxy сервером, работает быстрее, чем напрямую.
Таким образом, впервые создан reverse proxy сервер, который корректно работает с сайтами реального интернета, а не с ограниченным набором браузерных приложений. Это значит, что технологией уже можно успешно пользоваться.
О способах применения нашей технологии для решения конкретных задач мы напишем более подробно в следующих статьях.
Это продолжение вводной статьи о персонализации Интернета. Ниже кратко описана технология, на которой основаны реализованные компанией продукты по персонализации Интернета.
Компанией Avvea разработана технология переписывания контента динамических интернет-страниц. Такая технология не нова и известна как reverse proxy. Примерами качественных reverse proxy серверов в сфере бизнеса являются разработки компаний F5 и Juniper. Технологии разработки reverse proxy серверов каждой из этих компаний прошли более чем десятилетний путь развития и направлены на поддержку ограниченного количества сложных приложений корпоративных клиентов.
Примером reversy-proxy любительского уровня можно считать свободно распространяемую разработку Glype. Таких серверов достаточно много, среди них наиболее популярны так называемые анонимайзеры.
Рассмотрим некоторые технические особенности. Главная задача reverse proxy сервера — создание виртуальной прослойки между интерфейсом браузера и клиентским программным кодом. И чем лучше эта задача решена, тем лучше итоговый reverse proxy сервер.
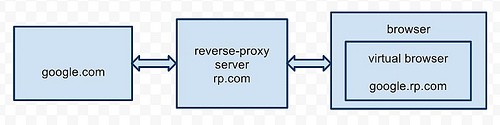
Наша технология подразумевает перехват и переписывание всех интерфейсных свойств и методов всех активных элементов интернет-страницы (HTML, JavaScript, Adobe Flash, Java и других). Тем самым внутри реального браузера создается своеобразный «виртуальный браузер».
Если с HTML все просто, и даже бесплатные анонимайзеры неплохо справляются с переписью статического HTML, то, например, с JavaScript дела обстоят гораздо сложнее. До сих пор не существовало единого подхода к решению этой задачи. Наша разработка изменила положение дел.
Основную идею нового подхода покажем на примере машины по переписыванию JavaScript нашего reverse proxy сервера. Схематично машина состоит из 3 частей: лексер (lexer), парсер (parser) и патчер (patcher), каждая из которых является самостоятельным элементом системы.

Лексер — это синтаксическая основа машины, отвечающая за распознавание элементов языка в потоке символов. Парсер, основываясь на лексере, разбирает входящий поток на составляющие: переменные, функции, операции, сам язык и т.д. Патчер применяется к найденным интерфейсным свойствам и методам.
Несколько слов о том, как это работает.
Входные потоки обрабатываются, основываясь на выражениях — элементарных, неделимых конструкциях пользовательского программного кода с точки зрения их обработки парсером. В парсере применяется специализированный двухстековый метод разборки/сборки. В одном стеке — операнды, в другом — операции с их приоритетами. Один цикл заполнения стеков — одно выражение. Благодаря этому система получилась однопроходной и потоковой. Это значит, что код отдаются браузеру по мере его загрузки. Т.е. выражения, встреченные в начале, обрабатываются сразу, как только они полностью появились в буфере патчера, без ожидания, когда загрузится весь код целиком. Все это положительно сказалось на производительности и «легкости» системы. В сочетании с разумным кэшированием запатченного кода можно иногда наблюдать эффект, когда сайт, переписанный reverse proxy сервером, работает быстрее, чем напрямую.
Таким образом, впервые создан reverse proxy сервер, который корректно работает с сайтами реального интернета, а не с ограниченным набором браузерных приложений. Это значит, что технологией уже можно успешно пользоваться.
О способах применения нашей технологии для решения конкретных задач мы напишем более подробно в следующих статьях.
