
Мониторинг IT-систем – это то, в чем рано или поздно (и в этом случае чем раньше, тем лучше) возникает острая необходимость для понимания того, а что, собственно, с нашей системой происходит? И зачастую такая необходимость идет рука об руку с другими вопросами, такими как: как это внедрить? Что мониторить? Как это развивать и поддерживать? Более того, на них становится все сложнее ответить с увеличением масштаба IT-системы.
В этой статье описан один из вариантов реализации решения такого мониторинга с использованием open-source продуктов на основе опыта внедрения его в промышленную эксплуатацию для потока событий в высоконагруженной IT-системе с микросервисной архитектурой. Под потоком событий подразумеваются, например, звонки в контактный центр, выпуск деталей, заказы на доставку еды или в общем запросы, поступающие на «вход» IT-системы.
«Идеальный мониторинг»
Когда мы говорим о назначении мониторинга в высоконагруженных системах, то подразумеваем, что это должно быть решение, которое позволяло бы в режиме реального времени оценить текущее состояние системы, проанализировать динамику ее параметров во времени и по итогу совершить какие-то целевые действия, например оповещение службы поддержки об инциденте. И вместе с тем самой важной задачей при работе с большими объемами данных является именно автоматизация этого процесса. Но на какие параметры для решения этой задачи нужно обратить внимание, если мы попробуем представить себе некую «идеальную систему мониторинга»?
- Сложность интеграции с другими компонентами
Или отсутсвие необходимости выделять большие ресурсы на интеграцию с другими компонентами. В нашем примере далее используется Prometheus со встроенным механизмом http-запросов для сбора метрик. При его использовании в части интеграции нужно только обеспечить обработку таких запросов, т.е. по сути публиковать метрики в определенном формате (подробнее в следующих разделах).
- Сложность внедрения
Хорошей практикой было бы внедрение максимально простой системы мониторинга для решения минимального круга проблем, которую можно было бы постепенно развивать в соответствии с новыми задачами и новыми потребностями бизнеса.
Например, для начала можно использовать мониторинг показателей «из коробки», т.е. набор показателей, являющихся стандартными для этого рода систем, которые уже хорошо показали себя на практике. Далее можно подключить систему оповещений, начать мониторить и другие инфраструктурные компоненты, разработать кастомные метрики и т.д.
- Минимальный time-to-market
Когда появляется потребность в расширении и развитии системы мониторинга, обычно необходимо, чтобы это было сделано уже «вчера», а не через 3 месяца или пол года, поэтому время вывода в эксплуатацию новой версии мониторинга должно быть минимально.
В случае наличия разработчиков в штате предпочтительнее использовать решение на основе open-source компонентов, в которые можно оперативно своими силами внести и опубликовать изменения. Однако, когда нет таких ресурсов, вендорские решения «из коробки» тоже хорошо себя показывают, т.к. обычно имеют схожий цикл публикации изменений.
- Возможность кастомизации
Рано или поздно возникает необходимость не только регистрировать те или иные события и наблюдать их в динамике, используя при этом стандартные показатели конкретного решения, но и также в режиме реального времени анализировать их параметры: на примере вызовов в контактный центр это могут быть распределение интенсивности звонков в контактный центр в течение дня, средняя длительность звонков (или лучше 95-ый и 99-ый перцентили длительности), количество звонков в разрезе обслуживающих их операторов и т.д. Работа с такими показателями, как правило, требует от системы возможности ее кастомной доработки, и разнообразие таких показателей обычно ограничено только воображением и здравым смыслом
По аналогии с предыдущим пунктом, open-source решения дают большую гибкость, но сегодня и в некоторые коробочные вендорские продукты включены разнообразные возможности кастомизации, но они как правило скорее удовлетворяют стандартные отраслевые потребности, что не всегда работает в отдельном конкретном случае.
- Кроссплатформенность и сложность использования
Система мониторинга может использоваться и службой поддержки, и бизнес-пользователями, и в целях тестирования и т.д., и наличие у нее, например, web-интерфейса устраняет ряд возможных проблем с зависимостью от среды.
В случае Prometheus и Grafana есть свои web-интерфейсы, которые позволяют пользователям не только, собственно, мониторить процессы, но и работать с базой и вносить изменения в графики без непосредственного написания кода.
- Условия распространения
Вопрос условий распространения решения мониторинга всегда актуален: это какое-то open-source решение с бесплатным распространением или лицензированный продукт? Если лицензированный продукт, то насколько условия лицензии подходят для внедрения его в конкретном проекте? Ответы на эти вопросы зачастую могут играть и вовсе ключевую роль при выборе одного из продуктов.
В соответствии с этими показателями в качестве системы мониторинга были выбраны Prometheus и Grafana, которые хорошо зарекомендовали себя на рынке и при использовании в других проектах заказчика. Ниже рассматривается пример внедрения системы мониторинга в микросервисную архитектуру с использованием этих продуктов.
Prometheus – это open-source решение, которое записывает метрики в реальном времени в базу данных временных рядов, построенную с использованием модели HTTP-запроса, с гибкими запросами и оповещениями в режиме реального времени. Взято и переведено с prometheus.io/docs/introduction/overview
Grafana – это open-source веб-приложение для аналитики и интерактивной визуализации с открытым исходным кодом. В рассматриваемом примере используется для в качестве пользовательского интерфейса для работы с графиками, построенными на данных из Prometheus. Подробнее на grafana.com/grafana)
Архитектура решения и особенности реализации при работе с микросервисами
В решении с микросервисной архитектурой самым главным, хоть и не единственным, объектом мониторинга являются, конечно, сами микросервисы. В данном примере это spring boot приложения (Business Service 1, Monitoring Service, …), развернутые в Openshift кластере в нескольких проектах (Namespace 1, Namespace 2, …). Каждый проект служит отдельной средой и используется для какой-то одной конкретной цели: параллельной разработки, разных видов тестирования и т.д.
Внутри каждого проекта, помимо самих бизнес-сервисов, которые могут существовать в нескольких экземплярах на разных подах, находятся Prometheus Service, который взаимодействует с остальными микросервисами напрямую, собирая общие для всех них метрики, такие как потребление CPU, дискового пространства и т.д., и Monitoring Service, который собирает данные по остальным сервисам и формирует уже кастомные метрики, такие как количество вызовов внутри системы с определенным признаком, параметры длительности этих вызовов и т.д. Подробнее о примерах метрик остановимся в следующем разделе.
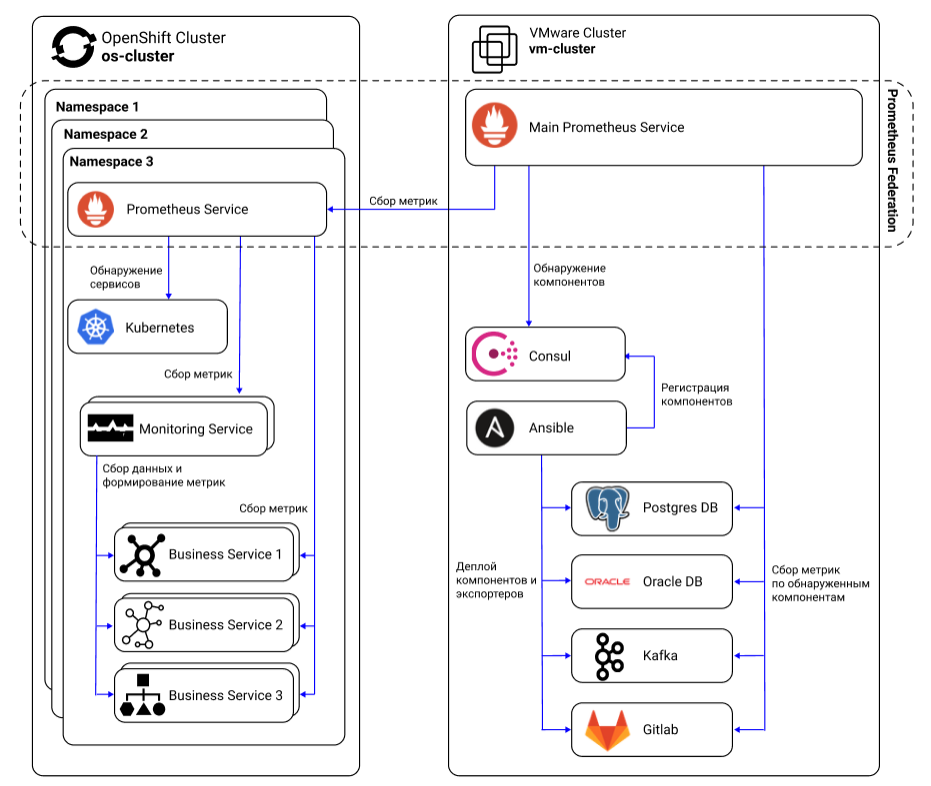
Есть несколько особенностей взаимодействия компонентов внутри проекта:
- Микросервисы отдают метрики в «пассивом» режиме
Внутри проекта каждый под микросервиса по адресу host:port/actuator/prometheus, где в host указан внутренний ip адрес пода в Openshift, публикует метрики с помощью экспортера Prometheus, для spring boot приложения это может быть Micrometer. Раз в n секунд Prometheus Service, расположенный в этом же проекте, с помощью http-запроса обращается по этим адресам всех подов микросервисов и сохраняет полученные значения метрик к себе в базу данных, при этом добавляя в них дополнительную информацию (метки) о имени пода, внутреннему ip, имени проекта и т.д.
Немного подробнее о сборе метрик внутри Openshift: внутри каждого проекта тоже может быть огромное множество компонентов с которых Prometheus должен собрать данные. Помогает ему в этом в автоматическом режиме service discovery, поставляемый Openshift’ом, который посредством Kubernetes API обнаруживает все компоненты в конкретном проекте (namespace). Обнаруженные компоненты формируют список источников (targets), по которому локальный для этого проекта Prometheus собирает данные.
Таким образом, средства мониторинга в автоматическом режиме подстраиваются под меняющуюся архитектуру проекта для сбора данных и не затрагивают работу других компонентов системы, а их отказ не приводит к блокирующим ошибкам или и вовсе остановке работы всей системы.

На изображении приведен пример отдаваемых сервисом стандартных для Micrometer метрик jvm_memory_max_bytes. Возле # HELP приведено кратное описание метрики, а возле # TYPE указан тип метрики (gauge, counter и т.д.). Более подробно о типах метриках и их формировании можно узнать на официальном сайте Prometheus prometheus.io/docs/concepts/metric_types.
- Prometheus Service’ы в Openshift проектах и главный Prometheus Service формируют федерацию
Проекты в Openshift могут появляться и исчезать, а, помимо самих микросервисов, может возникнуть необходимость мониторить базы данных (Oracle DB, Postgres DB), брокеры сообщений (Kafka), репозитории (Gitlab), поэтому удобно объединить похожие компоненты в федерацию и агрегировать данные в каком-то одном Prometheus Service, который является главным для остальных. Тогда источники данных (targets) в главном Prometheus Service будут выглядеть вот так:

Но что делать, если счет источников данных идет на сотни, тысячи? К счастью, руками все это настраивать не придется, так как можно использовать «service discovery» инструменты, например Consul, который хорошо показывает себя на практике.
Это работает так: при деплое сервиса Ansible дополнительно устанавливает экспортер метрик, проводит регистрацию в Consul и прописывает job в настройках главного Prometheus Service. Далее главный Prometheus Service по job’ам в своих настройках, которые ведут в Consul, обнаруживает все объекты для сбора метрик (targets), попадающие под условие, и добавляет уже к себе в targets. Таким образом, главный Prometheus Service может для сбора метрик динамически формировать список target’ов в зависимости от появления или исчезновения сервисов.
Примеры метрик
Итак, данные по компонентам IT-системы собираются, в Prometheus Service мы видим значения метрик за длительные периоды. Но какие метрики вообще бывают, как их удобнее и проще всего визуализировать и настроить оповещения? Обо всем этом далее по порядку.
Ранее в статье упоминалось, что Prometheus Service в проекте может собирать метрики напрямую со всех микросервисов, и чаще всего это какой-то список метрик, которые являются общими для всех компонентов системы. В примере ниже это технические показатели микросервисов, данные по которым собираются с использованием Micrometer micrometer.io/docs/registry/prometheus, например графики используемой памяти:

Также на базе Micrometer можно разрабатывать собственные метрики которые могут быть как минимум двух типов:
- Собственные метрики сервиса
В этом случае метрика используется для мониторинга конкретных событий, происходящих в этом сервисе. Например, если мы говорим о компонентах, которые являются точкой входа внешних запросов в систему, то обычно в них реализован функционал валидации входящих извне сообщений. Тогда собственной метрикой таких компонент может быть счетчик ошибок валидации входящих сообщений, а на прирост этого счетчика можно выставить порог, при превышении которого будут формироваться уведомления, например, на службу поддержки.

Разработка таких кастомных метрик может вестись с использованием инструментов, идущих вместе с Micrometer, что сэкономит много времени на разработке и введении их в эксплутацию.
- Метрики сервиса, агрегирующие данные по остальным компонентам решения
Ярким примером здесь будет Monitoring Service, который упоминался в разделе с описанием архитектуры решения. Такой сервис анализирует межсервисное взаимодействие: какими сообщениями и в каком количестве обмениваются сервисы, какие параметры содержат эти сообщения, сколько раз встречался тот или иной параметр и т.д., рассчитывает внутри себя необходимые метрики и отдает их при запросе в Prometheus Service.

Это может быть очень полезно для анализа именно бизнес-процесса вашего решения, т.к. позволит формировать такие метрики, как, например, количество вызовов, пришедших с разных каналов за вчера с 9:30 до 10:00. В этом случае в Monitoring Service создан счетчик, который увеличивается для каждого значения параметра «канал», которое появляется в межсервисном взаимодействии.
В самом Prometheus встроено достаточно много функций, позволяющих формировать средние, максимум, минимум по значениям метрик, а также суммировать показатели по какому-то признаку, например, если запросы приходят с нескольких подов в рамках одного проекта, то можно посчитать сумму запросов на всех подах в проекте, лишь бы данные были.
Оповещения
Механизм оповещений встроен в Prometheus и представляет собой достаточно удобный и простой функционал. Его подробное описание приведено на официальном сайте Prometheus prometheus.io/docs/alerting/latest/overview. Но самым сложным вопросом в настройке оповещений все же является не технический, а именно то, какие пороги для какой метрики выбрать: при скольких ошибках валидации отправлять оповещение на поддержку или какая длительность вызова является слишком низкой и пора бить тревогу? К сожалению, ответ крайне зависит от конкретной системы и задач, которые она решает, а оптимальные значения порогов зачастую подбираются опытным путем.
Также здесь важно отметить еще один момент: возникают ситуации, когда необходимо использовать не встроенные возможности Prometheus, а какое-то стороннее решение. Например, для рассылки уведомлений в закрытом контуре с использованием своего почтового сервера. В этом случае можно воспользоваться Prometheus API prometheus.io/docs/prometheus/latest/querying/api. С его помощью можно настроить, например, получение всех значений метрики за какой-то период и вести обработку их во внешней системе, либо периодически запрашивать значение метрики в текущий момент и сравнивать полученное значение с настроенным порогом, при превышении которого отправляется запрос на отправку уведомлений.
