На Python можно работать с данными и визуализировать их. Пользуются этим не только программисты, но и ученые: биологи, физики, социологи. Сегодня мы вместе с shwars, куратором нашего курса Python jumpstart for AI, ненадолго превратимся в метеорологов и изучим климат городов России. Из библиотек для визуализации и работы с данными используем Pandas, Matplotlib и Bokeh.

Сами исследования мы проводим в Azure Notebooks — облачной версии Jupyther Notebook. Таким образом для начала работы с Python нам не потребуется ничего устанавливать себе на компьютер и работать можно будет прямо из браузера. Необходимо лишь осуществить вход со своим Microsoft Account, создать библиотеку и в ней — новый ноутбук Python 3. После чего можно брать фрагменты кода из этой статьи и экспериментировать!
В первую очередь импортируем основные библиотеки, которые нам понадобятся. Pandas — это библиотека для работы с табличными данными, или так называемыми фреймами данных, а pyplot позволит нам строить графики.
Исходные данные легко найти в интернете, но мы уже подготовили для вас данные в удобном формате CSV. CSV — это текстовый формат, в котором все столбцы разделены запятыми. Отсюда и название — Comma Separated Values.
Pandas умеет сам открывать CSV-файлы как с локального диска, так и сразу из интернета. Сами данные лежат в нашем репозитории на GitHub, поэтому нам достаточно просто указать правильный URL.

Переименуем столбцы таблицы, чтобы к ним удобнее было обращаться по имени. Также нам необходимо преобразовать строки в численные значения, чтобы оперировать ими. Когда мы попробуем это сделать с помощью функции
Из этой проблемы следует важная мораль: данные обычно приходят в «грязном» виде, неудобном для использования, и задача data scientist’а в том, чтобы эти данные привести к хорошему виду.
Можно видеть, что некоторые столбцы нашей таблицы имеют тип
Теперь, когда мы получили чистые данные, можно попробовать построить интересные графики.
Например, посмотрим, как зависит средняя температура от широты.

Из графика видно, что чем ближе к экватору — тем теплее.
Теперь взглянем на города, которые являются температурными рекордсменами, и посмотрим, есть ли корреляция между минимальной и максимальной температурой в городе.
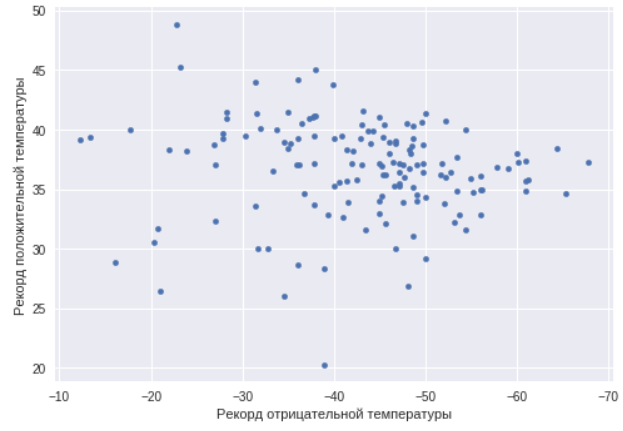
Как можно видеть, в этом случае такой корреляции нет. Есть города как с резко континентальным климатом, так и просто теплые и холодные города. Найдем города с максимальным температурным разбросом, то есть как раз города с резко континентальным климатом.

В этот раз мы брали не рекордные показатели, а средние самого теплого и самого холодного месяца. Как и ожидалось, самый большой разброс у городов из Республики Саха (Якутия).
Для дальнейшего исследования рассмотрим города в радиусе 300 км от Москвы. Для вычисления расстояния между точками по широте и долготе используем библиотеку geopy, которую предварительно необходимо установить при помощи помощи
Добавим к таблице еще один столбец — расстояние до Москвы.

Используем выражение, чтобы отобрать только интересующие нас строки.

Для этих городов построим график минимальной, среднегодовой и максимальной температур.
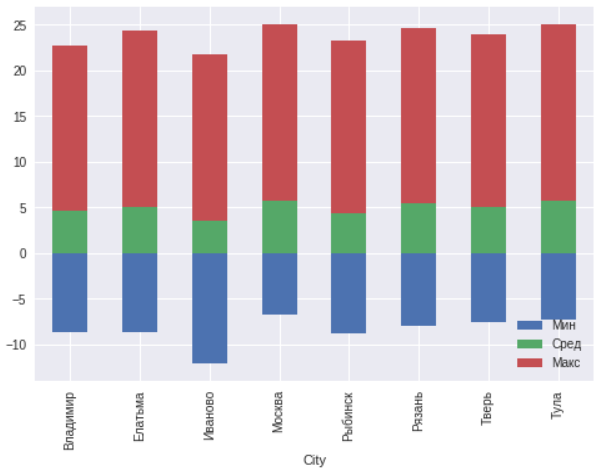
В целом в пределах 300 километров вокруг Москвы никаких аномалий не наблюдается. Иваново находится севернее остальных городов, поэтому и температуры там на несколько градусов ниже.
Теперь попробуем отобразить на карте среднегодовое количество осадков с привязкой к городам и посмотреть, как зависят осадки от географического расположения. Для этого используем другую библиотеку визуализации — Bokeh. Ее также необходимо установить.
Затем вычисляем еще один столбец — размер кружочка, который будет показывать количество осадков. Коэффициент подбираем опытным путем.
Для работы с картой потребуется ключ Google Maps API. Его необходимо самостоятельно получить на сайте.
Более подробные инструкции по использованию Bokeh для построения графиков на картах можно найти тут и тут.
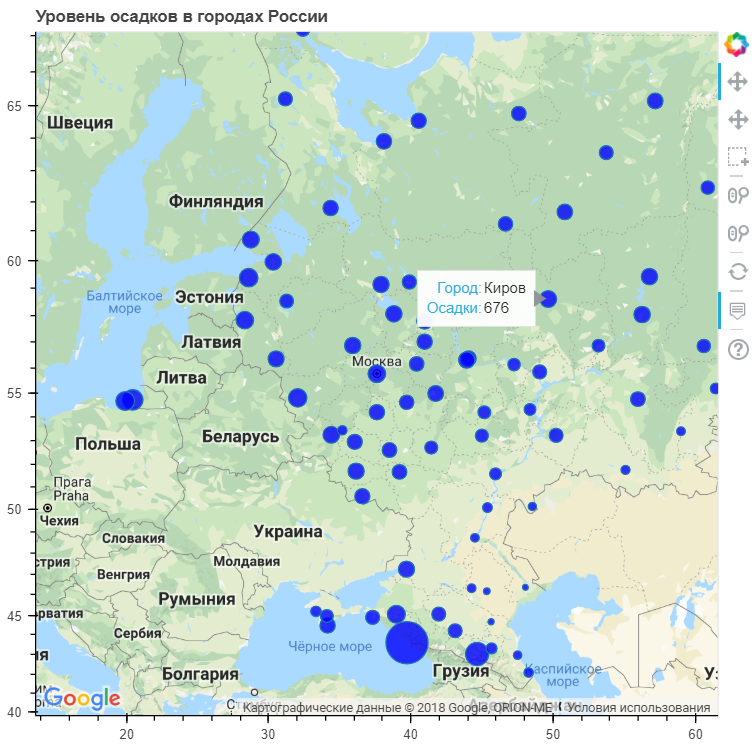
Как можно заметить, наибольшее количество осадков выпадает в приморских городах. Хотя есть достаточно большое количество таких городов, где уровень осадков среднее или даже ниже общероссийского.
Весь код с комментариями, написанный Дмитрием Сошниковым, вы можете самостоятельно посмотреть и запустить здесь.
Мы показали возможности языка без использования сложных алгоритмов, специфических библиотек или написания сотни строк кода. Однако даже вооружившись стандартными инструментами можно проанализировать свои данные и сделать какие-то выводы.
Датасеты далеко не всегда бывают идеально составлены, поэтому прежде чем начать работать с визуализацией необходимо привести их в порядок. Качество визуализации будет во многом зависеть от качества используемых данных.
Всевозможных типов диаграмм и графиков огромное количество, и необязательно ограничиваться одними только стандартными библиотеками.
Существует Geoplotlib, Plotly, минималистичный Leather и другие.
Если вы хотите узнать о работе с данными в Python больше, а также познакомиться с искусственным интеллектом, то приглашаем вас на однодневный интенсив от Binary District — Python jumpstart for AI.

Сами исследования мы проводим в Azure Notebooks — облачной версии Jupyther Notebook. Таким образом для начала работы с Python нам не потребуется ничего устанавливать себе на компьютер и работать можно будет прямо из браузера. Необходимо лишь осуществить вход со своим Microsoft Account, создать библиотеку и в ней — новый ноутбук Python 3. После чего можно брать фрагменты кода из этой статьи и экспериментировать!
Получаем данные
В первую очередь импортируем основные библиотеки, которые нам понадобятся. Pandas — это библиотека для работы с табличными данными, или так называемыми фреймами данных, а pyplot позволит нам строить графики.
import pandas as pd
import matplotlib.pyplot as pltИсходные данные легко найти в интернете, но мы уже подготовили для вас данные в удобном формате CSV. CSV — это текстовый формат, в котором все столбцы разделены запятыми. Отсюда и название — Comma Separated Values.
Pandas умеет сам открывать CSV-файлы как с локального диска, так и сразу из интернета. Сами данные лежат в нашем репозитории на GitHub, поэтому нам достаточно просто указать правильный URL.
data = pd.read_csv("https://raw.githubusercontent.com/shwars/PythonJump/master/Data/climat_russia_cities.csv")
data
Переименуем столбцы таблицы, чтобы к ним удобнее было обращаться по имени. Также нам необходимо преобразовать строки в численные значения, чтобы оперировать ими. Когда мы попробуем это сделать с помощью функции
pd.to_numeric, то обнаружим, что возникает странная ошибка. Это связано с тем, что вместо минуса в тексте используется знак длинного тире.data.columns=["City","Lat","Long","TempMin","TempColdest","AvgAnnual","TempWarmest","AbsMax","Precipitation"]
data["TempMin"] = pd.to_numeric(data["TempMin"])---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
pandas/_libs/src/inference.pyx in pandas._libs.lib.maybe_convert_numeric()
ValueError: Unable to parse string "−38.0"
...
...
...
ValueError: Unable to parse string "−38.0" at position 0Из этой проблемы следует важная мораль: данные обычно приходят в «грязном» виде, неудобном для использования, и задача data scientist’а в том, чтобы эти данные привести к хорошему виду.
Можно видеть, что некоторые столбцы нашей таблицы имеют тип
object, а не числовой тип float64. В таких столбцах произведем замену тире на минус и затем преобразуем всю таблицу в числовой формат. Столбцы, которые не могут быть преобразованы (названия городов) останутся в неизменном виде (для этого мы использовали ключ errors=’ignore’).print(data.dtypes)
for x in ["TempMin","TempColdest","AvgAnnual"]:
data[x] = data[x].str.replace('−','-')
data = data.apply(pd.to_numeric,errors='ignore')
print(data.dtypes)City object
Lat float64
Long float64
TempMin object
TempColdest object
AvgAnnual object
TempWarmest float64
AbsMax float64
Precipitation int64
dtype: object
City object
Lat float64
Long float64
TempMin float64
TempColdest float64
AvgAnnual float64
TempWarmest float64
AbsMax float64
Precipitation int64
dtype: objectИсследуем данные
Теперь, когда мы получили чистые данные, можно попробовать построить интересные графики.
Среднегодовая температура
Например, посмотрим, как зависит средняя температура от широты.
ax = data.plot(x="Lat",y="AvgAnnual",kind="Scatter")
ax.set_xlabel("Широта")
ax.set_ylabel("Среднегодовая температура")
Из графика видно, что чем ближе к экватору — тем теплее.
Города-рекордсмены
Теперь взглянем на города, которые являются температурными рекордсменами, и посмотрим, есть ли корреляция между минимальной и максимальной температурой в городе.
ax=data.plot(x="TempMin",y="AbsMax",kind="scatter")
ax.set_xlabel("Рекорд отрицательной температуры")
ax.set_ylabel("Рекорд положительной температуры")
ax.invert_xaxis()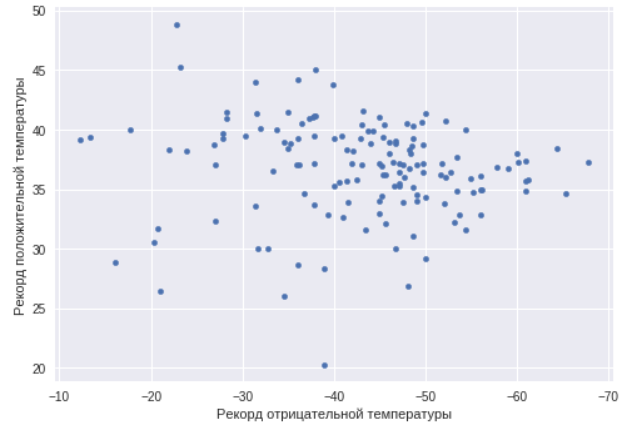
Как можно видеть, в этом случае такой корреляции нет. Есть города как с резко континентальным климатом, так и просто теплые и холодные города. Найдем города с максимальным температурным разбросом, то есть как раз города с резко континентальным климатом.
data['spread'] = data['TempWarmest'] - data['TempColdest']
data.nlargest(3,'spread')
В этот раз мы брали не рекордные показатели, а средние самого теплого и самого холодного месяца. Как и ожидалось, самый большой разброс у городов из Республики Саха (Якутия).
Зимой и летом
Для дальнейшего исследования рассмотрим города в радиусе 300 км от Москвы. Для вычисления расстояния между точками по широте и долготе используем библиотеку geopy, которую предварительно необходимо установить при помощи помощи
pip install.!pip install geopy
import geopy.distanceДобавим к таблице еще один столбец — расстояние до Москвы.
msk_coords = tuple(data.loc[data["City"]=="Москва"][["Lat","Long"]].iloc[0])
data["DistMsk"] = data.apply(lambda row : geopy.distance.distance(msk_coords,(row["Lat"],row["Long"])).km,axis=1)
data.head()
Используем выражение, чтобы отобрать только интересующие нас строки.
msk = data.loc[data['DistMsk']<300]
msk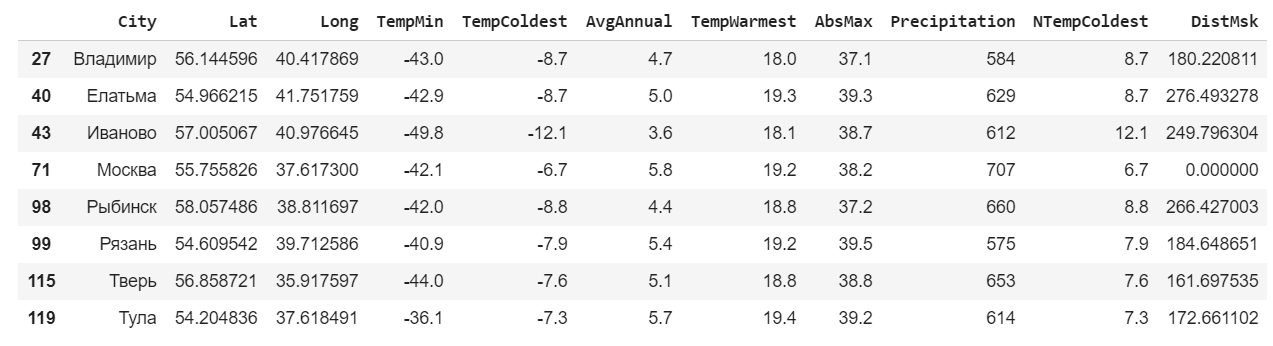
Для этих городов построим график минимальной, среднегодовой и максимальной температур.
ax=msk.plot(x="City",y=["TempColdest","AvgAnnual","TempWarmest"],kind="bar",stacked="true")
ax.legend(["Мин","Сред","Макс"],loc='lower right')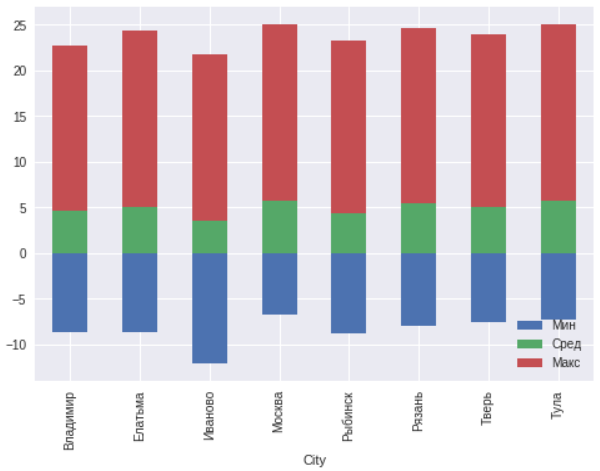
В целом в пределах 300 километров вокруг Москвы никаких аномалий не наблюдается. Иваново находится севернее остальных городов, поэтому и температуры там на несколько градусов ниже.
Работа с гео-данными
Теперь попробуем отобразить на карте среднегодовое количество осадков с привязкой к городам и посмотреть, как зависят осадки от географического расположения. Для этого используем другую библиотеку визуализации — Bokeh. Ее также необходимо установить.
Затем вычисляем еще один столбец — размер кружочка, который будет показывать количество осадков. Коэффициент подбираем опытным путем.
!pip install bokeh
from bokeh.io import output_file, output_notebook, show
from bokeh.models import (
GMapPlot, GMapOptions, ColumnDataSource, Circle, LogColorMapper, BasicTicker, ColorBar,
DataRange1d, PanTool, WheelZoomTool, BoxSelectTool, HoverTool
)
from bokeh.models.mappers import ColorMapper, LinearColorMapper
from bokeh.palettes import Viridis5
from bokeh.plotting import gmapДля работы с картой потребуется ключ Google Maps API. Его необходимо самостоятельно получить на сайте.
Более подробные инструкции по использованию Bokeh для построения графиков на картах можно найти тут и тут.
google_key = "<INSERT YOUR KEY HERE>"
data["PrecipSize"] = data["Precipitation"] / 50.0
map_options = GMapOptions(lat=msk_coords[0], lng=msk_coords[1], map_type="roadmap", zoom=4)
plot = gmap(google_key,map_options=map_options)
plot.title.text = "Уровень осадков в городах России"
source = ColumnDataSource(data=data)
my_hover = HoverTool()
my_hover.tooltips = [('Город', '@City'),('Осадки','@Precipitation')]
plot.circle(x="Long", y="Lat", size="PrecipSize", fill_color="blue", fill_alpha=0.8, source=source)
plot.add_tools(PanTool(), WheelZoomTool(), BoxSelectTool(), my_hover)
output_notebook()
show(plot)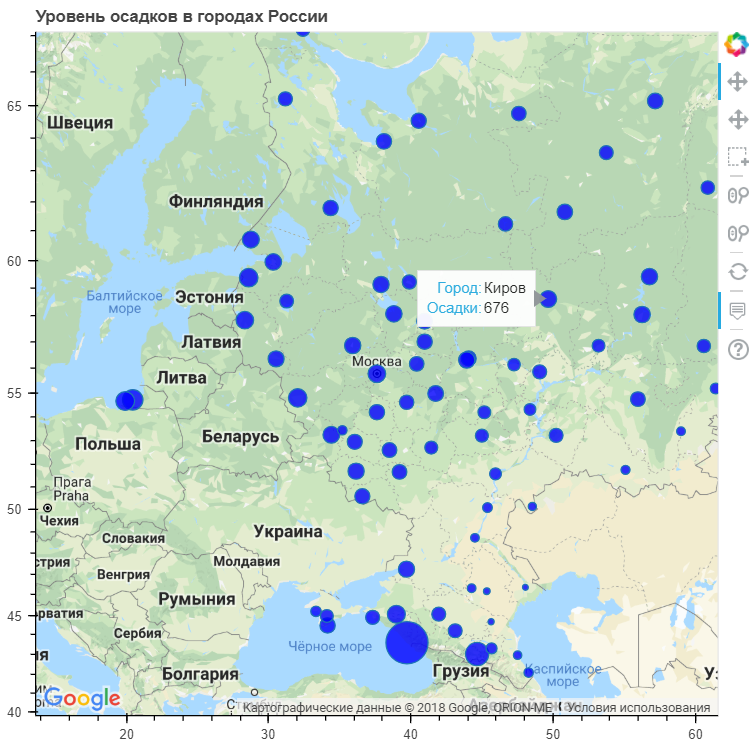
Как можно заметить, наибольшее количество осадков выпадает в приморских городах. Хотя есть достаточно большое количество таких городов, где уровень осадков среднее или даже ниже общероссийского.
Весь код с комментариями, написанный Дмитрием Сошниковым, вы можете самостоятельно посмотреть и запустить здесь.
Итоги
Мы показали возможности языка без использования сложных алгоритмов, специфических библиотек или написания сотни строк кода. Однако даже вооружившись стандартными инструментами можно проанализировать свои данные и сделать какие-то выводы.
Датасеты далеко не всегда бывают идеально составлены, поэтому прежде чем начать работать с визуализацией необходимо привести их в порядок. Качество визуализации будет во многом зависеть от качества используемых данных.
Всевозможных типов диаграмм и графиков огромное количество, и необязательно ограничиваться одними только стандартными библиотеками.
Существует Geoplotlib, Plotly, минималистичный Leather и другие.
Если вы хотите узнать о работе с данными в Python больше, а также познакомиться с искусственным интеллектом, то приглашаем вас на однодневный интенсив от Binary District — Python jumpstart for AI.
