Комментарии 29
Как думаете, какая судьба ждет OpenCL? CUDA хорошо, но по сути поддерживает только NVIDIA карты. AMD развивает rocm/hip, но выглядит это странно. Из документации мне показалось, что их основной упор — это транслятор уже написаных на CUDA приложений во что-то свое, что потом уже можно скомпилировать под целевую платформу. А раз так, то это выглядит и как пересечение с intel oneAPI. В общем, все сложно и хотелось бы услышать мнение компетентных людей.
Мое личное мнение, может быть и не столь компетентное, что OpenCL будет еще долго жить, т.к.
1. Как минимум, развивается, есть таргет на 2020 год
2. Уже поддерживается многими производителями (жаль что Apple депрекейтят)
3. Есть спрос на кроссплатформенный фреймворк, если речь идет о массовом продукте с поддержкой GPU, то покупателя сложно убедить, что вдобавок ему нужно еще и карту конкретную купить. А с OpenCL о вендоре карты можно не особо переживать.
4. Не стоит забывать о конкурирующих решения на FPGA (которые я не упомянул в статье). В описании OpenCL заявлена поддержка FPGA, что теоретически должно позволить легко мигрировать на эти железяки (хотя не очень верится, что легко), это так же должно поддерживать «жизнь» OpenCL
1. Как минимум, развивается, есть таргет на 2020 год
2. Уже поддерживается многими производителями (жаль что Apple депрекейтят)
3. Есть спрос на кроссплатформенный фреймворк, если речь идет о массовом продукте с поддержкой GPU, то покупателя сложно убедить, что вдобавок ему нужно еще и карту конкретную купить. А с OpenCL о вендоре карты можно не особо переживать.
4. Не стоит забывать о конкурирующих решения на FPGA (которые я не упомянул в статье). В описании OpenCL заявлена поддержка FPGA, что теоретически должно позволить легко мигрировать на эти железяки (хотя не очень верится, что легко), это так же должно поддерживать «жизнь» OpenCL
Мы сейчас переходим с OpenCL на Вулкан и его compute pipeline. Мне кажется, это более перспективная и долговечная технология.
Если не секрет, у вас коробочный продукт, который клиентам продаете или внутренний? И какие аргументы в пользу Vulkan?
Коробочный. В первую очередь, надоели проблемы с переносимостью скомпиленных бинарников (кернелов). Мы не хотим включать в продукт исходный код и компилить его на лету, вместо этого включаем предварительно транслированные бинарники. Но промежуточное представление отличается для разных поколений видеокарт, поэтому получается, что для поддержки серии Х нам физически нужна видеокарта из этой серии, это накладно. Вулкан использует spir-v, что решает проблему переносимости. И вторая причина — субъективное ощущение какого-то застоя в развитии и поддержке OpenCL, особенно со стороны Nvidia, плюс потенциальные проблемы на маке, тогда как Вулкан, наоборот, активно развивается, и для него есть транслятор в Metal как средство борьбы с закидонами Apple.
Дружище, не могли бы Вы описать в отдельной статье, или подсказать где понятными словами уже описана вычислительная модель GPU. Для обычного однопоточного компьютера, например, используют RAM модель — и это чертовски удобно: у всех программистов (и математиков), независимо от конкретного языка их программ есть стандарт описания алгоритмов и универсальный способ оценки их вычислительной сложности.
Под вычислительной моделью я понимаю описание работы вычислительной машины, пусть упрощенное, скрывающее ненужные технические подробности, однако позволяющее оценить сложность реализации алгоритмов и узкие места, с которыми выполнение этих алгоритмов может столкнуться на практике.
Заранее благодарю.
Под вычислительной моделью я понимаю описание работы вычислительной машины, пусть упрощенное, скрывающее ненужные технические подробности, однако позволяющее оценить сложность реализации алгоритмов и узкие места, с которыми выполнение этих алгоритмов может столкнуться на практике.
Заранее благодарю.
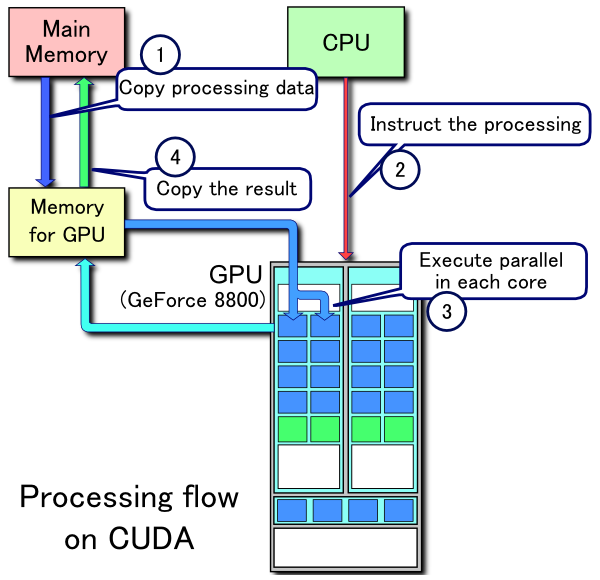
Наверное, в самом простом виде, вот эта картинка описывает, что происходит при работе с GPU:
Про узкие места 1 и 4 по пересылке данных написано в статье и есть графики для оценки оверхеда на пересылку данных
2 — это загрузка исполняемой программы (ядра) на видеокарту. Перед тем как запустить программу на видеокарте, ее нужно туда загрузить.
3 — это то самый SIMD (или SIMT для NVIDIA), много параллельных потоков, одни и те же инструкции, разные данные — в статье так же есть примеры. Этот пункт, наверное, ключевой для оценки эффективности алгоритма. Но, яркие примеры — сортировка и трансформация. Трансформация хорошо параллелится, но, тем не менее, работает медленнее на GPU, а сортировка на GPU выглядит очень сложно, по сравнению с CPU, но работает быстрее. Как оценить теоретически, какой алгоритм быстрее на GPU, или GPU vs CPU, я не нашел общепринятого способа. Оценка O-большое здесь не работает, как вы понимаете.
Вообще, цель статьи как раз и была, дать теоретический минимум для того, чтобы подступиться к GPU, но вместо теоретической оценки, попробовать на практике с минимальными трудозатратами.
Processing flow on CUDA
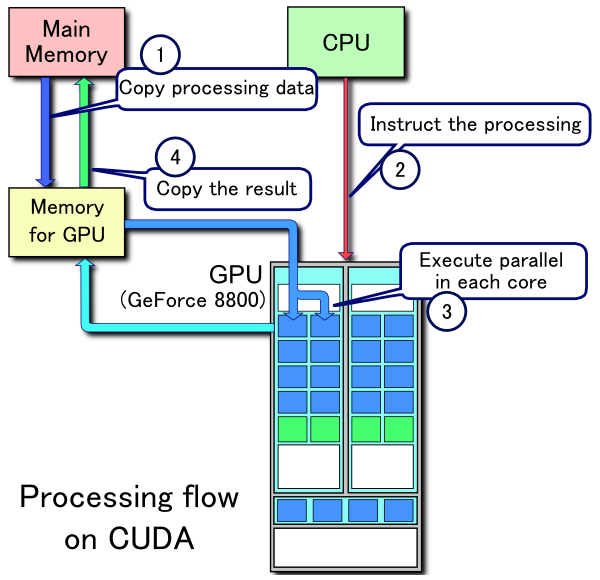
Про узкие места 1 и 4 по пересылке данных написано в статье и есть графики для оценки оверхеда на пересылку данных
2 — это загрузка исполняемой программы (ядра) на видеокарту. Перед тем как запустить программу на видеокарте, ее нужно туда загрузить.
3 — это то самый SIMD (или SIMT для NVIDIA), много параллельных потоков, одни и те же инструкции, разные данные — в статье так же есть примеры. Этот пункт, наверное, ключевой для оценки эффективности алгоритма. Но, яркие примеры — сортировка и трансформация. Трансформация хорошо параллелится, но, тем не менее, работает медленнее на GPU, а сортировка на GPU выглядит очень сложно, по сравнению с CPU, но работает быстрее. Как оценить теоретически, какой алгоритм быстрее на GPU, или GPU vs CPU, я не нашел общепринятого способа. Оценка O-большое здесь не работает, как вы понимаете.
Вообще, цель статьи как раз и была, дать теоретический минимум для того, чтобы подступиться к GPU, но вместо теоретической оценки, попробовать на практике с минимальными трудозатратами.
Простите, что долго не отвечал. Я подбирал слова, точнее аналогию, которая бы раскрыла суть моего вопроса лучше.
Смотрите. Если Вы захотите спроектировать устройство на кристалле, скажем новую видеокарту, то оказывается Вам совсем не обязательно знать, как устроен транзистор, защелки, и дерево тактовой частоты, потому что разработана более абстрактная модель.
Эта модель включает в себя понятия
бинарный канал,
бинарный сигнал,
такт,
элемент комбинационной логики,
и регистр.
Такт — это шаг дискретного времени, единый для всех элементов на кристалле.
Бинарный канал каждый такт передает ровно одно значение бинарной переменной.
Регистр — это место хранения для бинарной переменной. К регистру подходит один бинарный канал и от него уходит один бинарный канал. Сигнал, посылаемый регистром в следующем такте, равен сигналу, полученному им на предыдущем.
Модуль комбинационной логики имеет некоторое число входящих бинарных каналов и некоторое число исходящих. Он осуществляет некоторое простое функциональное отображение входящих сигналов на исходящие, делая это «мгновенно» в пределах одного такта.
Я только что описал модель работы полупроводниковой техники. Вы можете рассказать о ней любому человеку, который даже не знает, что такое электричество, но если он спроектирует какое-то модельное устройство, решающее некоторую задачу (процессор или быстрый фурье-преобразователь), то на заводе такой проект поймут и смогут воплотить устройство в жизнь. Здесь также важно, что описанный мной уровень абстракции дает возможность посчитать реальное количество тактов, которое требуется на решение задачи и даже оценить с точностью до константы площадь кристалла.
Картинка и высокоуровневое описание в Вашем ответе пока не дает мне возможностей писать программы и понимать в ограничения ресурсов. Составить вычислительную модель видеокарты — может оказаться непростой задачей, но если у Вас получится, большой респект и 50 плюсов к статье Вы точно заслужите.
Смотрите. Если Вы захотите спроектировать устройство на кристалле, скажем новую видеокарту, то оказывается Вам совсем не обязательно знать, как устроен транзистор, защелки, и дерево тактовой частоты, потому что разработана более абстрактная модель.
Эта модель включает в себя понятия
бинарный канал,
бинарный сигнал,
такт,
элемент комбинационной логики,
и регистр.
Такт — это шаг дискретного времени, единый для всех элементов на кристалле.
Бинарный канал каждый такт передает ровно одно значение бинарной переменной.
Регистр — это место хранения для бинарной переменной. К регистру подходит один бинарный канал и от него уходит один бинарный канал. Сигнал, посылаемый регистром в следующем такте, равен сигналу, полученному им на предыдущем.
Модуль комбинационной логики имеет некоторое число входящих бинарных каналов и некоторое число исходящих. Он осуществляет некоторое простое функциональное отображение входящих сигналов на исходящие, делая это «мгновенно» в пределах одного такта.
Я только что описал модель работы полупроводниковой техники. Вы можете рассказать о ней любому человеку, который даже не знает, что такое электричество, но если он спроектирует какое-то модельное устройство, решающее некоторую задачу (процессор или быстрый фурье-преобразователь), то на заводе такой проект поймут и смогут воплотить устройство в жизнь. Здесь также важно, что описанный мной уровень абстракции дает возможность посчитать реальное количество тактов, которое требуется на решение задачи и даже оценить с точностью до константы площадь кристалла.
Картинка и высокоуровневое описание в Вашем ответе пока не дает мне возможностей писать программы и понимать в ограничения ресурсов. Составить вычислительную модель видеокарты — может оказаться непростой задачей, но если у Вас получится, большой респект и 50 плюсов к статье Вы точно заслужите.
Вы привели отличный пример, спасибо! Но, я понимаю, если вы заказываете специализированное оборудование, имеет (может быть) смысл все потактово считать, но если вы хотите сравнить, какой алгоритм, например, сортировки быстрее работает на CPU, теоретически, вы можете все потактово разложить, но на сколько результат будет близок к реальности, и на сколько это трудоемко сделать?
>> Вашем ответе пока не дает мне возможностей писать программы и понимать в ограничения ресурсов
В статье есть ссылка на книгу по CUDA, там большинство ограничений расписано, но это опять же актуально для конкретной архитектуры, а не для всех GPU. Честно говоря, не очень понятно насколько детально вы хотите разобраться, ведь эти ограничения будут отличаться для каждой модели карты, если лезть в детали.
Боюсь, я не тот, кто сможет в данный момент помочь с таким описанием, у разработчиков плат это выйдет однозначно лучше.
>> Вашем ответе пока не дает мне возможностей писать программы и понимать в ограничения ресурсов
В статье есть ссылка на книгу по CUDA, там большинство ограничений расписано, но это опять же актуально для конкретной архитектуры, а не для всех GPU. Честно говоря, не очень понятно насколько детально вы хотите разобраться, ведь эти ограничения будут отличаться для каждой модели карты, если лезть в детали.
Боюсь, я не тот, кто сможет в данный момент помочь с таким описанием, у разработчиков плат это выйдет однозначно лучше.
Честно говоря, не очень понятно насколько детально вы хотите разобраться, ведь эти ограничения будут отличаться для каждой модели карты, если лезть в детали.
Однопоточные процессоры тоже все разные, но модель РАМ или РАСП — есть нечто общее между ними, концентрат концепции свободный от подробностей реализации. Эти две модели позволили математикам разработать абстрактные алгоритмы не привязанные ни к конкретному языку, ни к конкретной модели процессора, а затем написать учебники, понятные прикладным программистам. Книги Ахо, Ульмана и Хопфорта, учебник Кнута излагают хорошо известные алгоритмы именно в терминах этих моделей.
Я хотел бы получить нечто подобное для GPU-подобных процессоров, проичем эта модель не обязательно должна быть потактовой. Если вдруг у Вас найдется время, я бы мог присоединится к работе и написать статью вместе. Думаю моих навыков в логике и мета-математике будет достаточно. В любом случае — спасибо за ответ и то, что Вы уже сделали.
Здали вы мне задачку:) Можете скинуть ссылку на примеры описания РАМ или РАСП, которые считаете наиболее удачными?
Наверное, здесь неплохо описано: Ахо Ульман Хопфорт «Алгоритмы Построение и анализ». Вам нужны первые 20 страниц
На мой взгляд, лучше всего смотреть официальные доки NVDIA, особенно по оптимизации программ
график зависимости размера данных от времени перекачки приведен далее в статье
далее в статье есть только график зависимости времени перекачки от размера данных
можно получить latency от 350 микросекунд, а этого уже может хватить для некоторых low latency приложений.
на графике указаны миллисекунды. от 350 в какую сторону? можно получить и больше, и меньше. может не хватить?
за ссылки спасибо
далее в статье есть только график зависимости времени перекачки от размера данных
можно получить latency от 350 микросекунд, а этого уже может хватить для некоторых low latency приложений.
на графике указаны миллисекунды. от 350 в какую сторону? можно получить и больше, и меньше. может не хватить?
за ссылки спасибо
> график зависимости размера данных от времени перекачки приведен далее в статье
поправил, спасибо, привольно — «времени перекачки от размера данных»
> на графике указаны миллисекунды
да, 0.318 миллисекунд — 318 ~ 350 микросекунд
> от 350 в какую сторону
в большую, конкретно для Tesla k80
> может не хватить?
здесь именно смысл «хватить», у каждого свое представление о low latency, в моем представлении это 1-3 мс, поэтому я пишу «хватить»
поправил, спасибо, привольно — «времени перекачки от размера данных»
> на графике указаны миллисекунды
да, 0.318 миллисекунд — 318 ~ 350 микросекунд
> от 350 в какую сторону
в большую, конкретно для Tesla k80
> может не хватить?
здесь именно смысл «хватить», у каждого свое представление о low latency, в моем представлении это 1-3 мс, поэтому я пишу «хватить»
Код
#include <pthread.h>
#include <stdint.h>
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
#define MAIN_VOID int main(void)
#define MAIN_ARGS int main(const int argc, const char *const *const argv)
#define TIME_PAIR struct timespec ___t1, ___t2
#define TIME_GET_START clock_gettime(CLOCK_REALTIME, &___t1)
#define TIME_GET_STOP clock_gettime(CLOCK_REALTIME, &___t2)
#define TIME_DIFF_NS ((___t2.tv_nsec + ___t2.tv_sec * (int64_t)1e9) - \
(___t1.tv_nsec + ___t1.tv_sec * (int64_t)1e9))
#define TIME_DIFF_MS (TIME_DIFF_NS / (int64_t)1e6)
#define TIME_DIFF_MCS (TIME_DIFF_NS / (int64_t)1e3)
#define TIME_DIFF_EXEC(EXEC, DIFF_SUFFIX, DIFF_LVAL) \
TIME_GET_START; EXEC; TIME_GET_STOP; DIFF_LVAL = TIME_DIFF_##DIFF_SUFFIX
enum { N = 100800000, T = 4 };
#define SUM(func_name, TYPE) \
void* func_name##_T(void *_) { \
TYPE *p = *(TYPE **)_; TYPE r = 0; \
for (int i = 0; i < N / T; i++) r += p[i]; \
*(TYPE *)_ = r; \
return NULL; \
} \
_Bool func_name(TYPE *p, TYPE *R) { \
pthread_t th[T]; size_t r[T]; int t, i, L = N / T; _Bool e = 0; \
for (t = 0; t < T; t++) { \
r[t] = (size_t)(p + L * t); \
if (pthread_create(th + t, NULL, func_name##_T, r + t) != 0) { e = 1; break; } \
} \
for (i = 0; i < t; i++) if (pthread_join(th[i], NULL) != 0) e = 1; \
if (e) return e; *R = 0; \
for (i = 0; i < T; i++) *R += (TYPE)(r[i]); return 0; \
}
#define TRANSFORM(func_name, TYPE) \
void* func_name##_T(void *_) { \
TYPE *p = _; \
for (int i = 0; i < N / T; i++) p[i] = p[i] * p[i] + p[i] / 3; \
return NULL; \
} \
_Bool func_name(TYPE *p) { \
pthread_t th[T]; int t, i, L = N / T; _Bool e = 0; \
for (t = 0; t < T; t++) { \
if (pthread_create(th + t, NULL, func_name##_T, p + L * t) != 0) { e = 1; break; } \
} \
for (i = 0; i < t; i++) if (pthread_join(th[i], NULL) != 0) e = 1; \
return e; \
}
SUM(sum_d, double)
SUM(sum_l, int64_t)
SUM(sum_i, int32_t)
TRANSFORM(transform_d, double)
TRANSFORM(transform_l, int64_t)
TRANSFORM(transform_i, int32_t)
MAIN_VOID {
if (N % T) { printf("line 64\n"); return 1; } _Bool e;
double *d = malloc(N * 8), rd; if (d == NULL) { printf("line 66\n"); return 1; }
int64_t *l = (int64_t *)d, rl;
int32_t *i = (int32_t *)d, ri;
srand(time(NULL)); TIME_PAIR; size_t sd, td, sl, tl, si, ti;
for (int i = 0; i < N; i++) d[i] = rand();
TIME_DIFF_EXEC(e = sum_d(d, &rd), MS, sd); if (e) { printf("line 72\n"); return 1; }
printf("sum d = %30.1lf, %7zu ms\n", rd, sd);
for (int i = 0; i < N; i++) d[i] = rand();
TIME_DIFF_EXEC(e = transform_d(d), MS, td); if (e) { printf("line 75\n"); return 1; }
printf("d[rand] = %30.1lf, %7zu ms\n", d[rand() % N], td);
for (int i = 0; i < N; i++) l[i] = rand();
TIME_DIFF_EXEC(e = sum_l(l, &rl), MS, sl); if (e) { printf("line 79\n"); return 1; }
printf("sum l = %30ld, %7zu ms\n", rl, sl);
for (int i = 0; i < N; i++) l[i] = rand();
TIME_DIFF_EXEC(e = transform_l(l), MS, tl); if (e) { printf("line 82\n"); return 1; }
printf("l[rand] = %30ld, %7zu ms\n", l[rand() % N], tl);
for (int j = 0; j < N; j++) i[j] = rand();
TIME_DIFF_EXEC(e = sum_i(i, &ri), MS, si); if (e) { printf("line 86\n"); return 1; }
printf("sum i = %30d, %7zu ms\n", ri, si);
for (int j = 0; j < N; j++) i[j] = rand();
TIME_DIFF_EXEC(e = transform_i(i), MS, ti); if (e) { printf("line 89\n"); return 1; }
printf("i[rand] = %30d, %7zu ms\n", i[rand() % N], ti);
return 0;
}$ gcc -flto -O3 dram.c -lpthread --static && ./a.out
sum d = 19410551262083469312.0, 28 ms
d[rand] = 2111606310059096576.0, 51 ms
sum l = 108243668190261742, 19 ms
l[rand] = 4035494864057467728, 53 ms
sum i = -529253480, 9 ms
i[rand] = 841548210, 29 ms
$ cpuid | grep 'brand =' | uniq
brand = "AMD Ryzen 7 1700X Eight-Core Processor "
Fix, line 36:
Файл назван 'dram.c', потому что на моей машине всё упирается в 40ГБ/с пропускной способности памяти: наращивание числа птоков для 8-байтовых типов данных теряет смысл при 2-х тредах для 'transform_*' и при 4-х для 'sum_*'. На «железе» с числом каналов памяти большем, чем у 1700X производительность должна быть выше.
- for (i = 0; i < T; i++) *R += (TYPE)(r[i]); return 0; \
+ for (i = 0; i < T; i++) *R += *((TYPE *)(r + i)); return 0; \Файл назван 'dram.c', потому что на моей машине всё упирается в 40ГБ/с пропускной способности памяти: наращивание числа птоков для 8-байтовых типов данных теряет смысл при 2-х тредах для 'transform_*' и при 4-х для 'sum_*'. На «железе» с числом каналов памяти большем, чем у 1700X производительность должна быть выше.
В тестах для агрегации я использовал std::accumulate. Как оказалось, он примерно в четыре раза хуже обычного цикла, и результаты приведены для одного потока. К сожалению, если данных еще нет на карте, тогда оверхед на пересылку данных для 700 MB из вашего примера составит примерно 100 ms, а расчет займет около 6 ms, поэтому при текущей имплементации, для небольшого объема данных, агрегация не лучший пример для Tesla k80. Хотел попробовать запустить пример на Tesla v100, там пропускная способность и производительность выше, но, к сожаления пока не получилось поднять инстанс.
Многопоточная сортировка слиянием
msort.h:
m.c:
Big_O:
#ifndef ___MSORT_H
#define ___MSORT_H
#include <pthread.h>
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define MCMP(func_name) _Bool func_name(const void *a, const void *b)
typedef _Bool (* ___cmp_t) (const void *, const void *);
#define MSORT_DEC(func_name) \
void* func_name(void *Arr, size_t Arr_Len, void *Ext_Buff, ___cmp_t Is_Unordered);
#define MSORT_MT_DEC(func_name) \
void* func_name(size_t T, void *Arr, size_t Arr_Len, void *Ext_Buff);
#define ___I *x++ = *i++
#define ___J *x++ = *j++
#define MAIN_VOID int main(void)
#define MAIN_ARGS int main(const int argc, const char *const *const argv)
#define TIME_PAIR struct timespec ___t1, ___t2
#define TIME_GET_START clock_gettime(CLOCK_REALTIME, &___t1)
#define TIME_GET_STOP clock_gettime(CLOCK_REALTIME, &___t2)
#define TIME_DIFF_NS ((___t2.tv_nsec + ___t2.tv_sec * (int64_t)1e9) - \
(___t1.tv_nsec + ___t1.tv_sec * (int64_t)1e9))
#define TIME_DIFF_MS (TIME_DIFF_NS / (int64_t)1e6)
#define TIME_DIFF_MCS (TIME_DIFF_NS / (int64_t)1e3)
#define TIME_DIFF_EXEC(EXEC, DIFF_SUFFIX, DIFF_LVAL) \
TIME_GET_START; EXEC; TIME_GET_STOP; DIFF_LVAL = TIME_DIFF_##DIFF_SUFFIX
#define MSORT(func_name, TYPE) /* TYPE: size_t for pointers */ \
void* func_name(void *const A, const size_t L, void *const E, ___cmp_t cmp) { \
if (L < 2) return A; size_t z = 2, y = 1, l = L / 2, t = 0; \
TYPE tmp, *i = A, *j = i + 1, *I, *J, *a = A, *e = E, *x = a + L, *p; \
for (; l--; i += 2, j += 2) { if (cmp(i, j)) { tmp = *j; *j = *i; *i = tmp; } } goto t; \
y2: for (; l--; I += 4, J += 4, i += 2, j += 2) { \
if (cmp(i, j)) ___J; else ___I; \
if (cmp(i, j)) { ___J; if (j == J) { ___I; ___I; continue; } } \
else { ___I; if (i == I) { ___J; ___J; continue; } } \
if (cmp(i, j)) { ___J; ___I; } else { ___I; ___J; } } goto t; \
y4: for (; l--; I += 8, J += 8, i += 4, j += 4) { \
for (size_t k = 4; --k;) { if (cmp(i, j)) ___J; else ___I; } \
for (;;) { if (cmp(i, j)) { ___J; if (j == J) { for (; i < I;) ___I; break; } } \
else { ___I; if (i == I) { for (; j < J;) ___J; break; } } } } goto t; \
y_: for (; l--; I += z, J += z, i += y, j += y) { \
for (size_t a, b, k = y;;) { for (; --k;) { if (cmp(i, j)) ___J; else ___I; } \
a = I - i, b = J - j, k = a > b ? b : a; if (k < 4) break; } \
for (;;) { if (cmp(i, j)) { ___J; if (j == J) { for (; i < I;) ___I; break; } } \
else { ___I; if (i == I) { for (; j < J;) ___J; break; } } } } \
t: if (t == 0) { if (L % z == 0) goto n; else { \
if (z == 2) { i = (I = j = (J = a + L) - 1) - 2; x = e + (L - 3); t = 3; } \
else { i = (I = x) - z; x = (j = (J = a + L) - y) - z; t = z + y; } } } \
else { J = (j = p) + t; if (L % z < t) { t += y; } \
else { i = (I = x) - z; x = a + (i - e); t += z; } } p = x; \
for (size_t a, b, k = y;;) { for (; --k;) { if (cmp(i, j)) ___J; else ___I; } \
a = I - i, b = J - j, k = a > b ? b : a; if (k < 4) break; } \
for (;;) { if (cmp(i, j)) { ___J; if (j == J) { for (; i < I;) ___I; break; } } \
else { ___I; \
if (i == I) { if (x != j) { for (; j < J;) ___J; } else x = J; break; } } } \
n: if (L / z == 1) return (x == a + L) ? a : e; if (z > 2) a = e, e = (e == E) ? A : E; \
z = 2 * (y *= 2), l = L / z, J = (j = (I = (i = a) + y)) + y, x = e; if (L % z < t) l--; \
if (y > 4) goto y_; else if (y == 2) goto y2; else goto y4; }
typedef struct ___mttfd_t { void *A, *E, *V; size_t L, X; } ___mttfd_t;
#define MSORT_MT(before, func_name, TYPE, msort_func_name, cmp) /* TYPE: size_t for pointers */ \
static void* func_name##_T1(void *data) { ___mttfd_t *d = data; \
d->A = msort_func_name(d->A, d->L, d->E, cmp); return NULL; } \
static void* func_name##_T2(void *data) { ___mttfd_t *d = data; \
TYPE *i = d->A, *I = i + d->L, \
*j = (d->V == NULL) ? I : d->V, *J = j + (d->L + d->X), *x = d->E; \
for (size_t a, b, k = d->L;;) { for (; --k;) { if (cmp(i, j)) ___J; else ___I; } \
a = I - i, b = J - j, k = a > b ? b : a; if (k < 4) break; } \
for (;;) { if (cmp(i, j)) { ___J; if (j == J) { for (; i < I;) ___I; break; } } \
else { ___I; if (i == I) { if (x != j) { for (; j < J;) ___J; } break; } } } \
return NULL; } \
before void* func_name(size_t T, void *const A, const size_t L, void *const E) { \
if (T < 2 || T > 256 || (T & (T - 1))) return NULL; \
if (L < 4096) return msort_func_name(A, L, E, cmp); \
for (; T > 2; T /= 2) if (L / T > 2047) break; ___mttfd_t d[T]; _Bool R = 0; pthread_t th[T]; \
size_t t, P = T / 2, y = L / T, z = y * 2, X = L % T; TYPE *a = A, *e = E, *i = a, *j = e, *V; \
for (t = 0; t < T; t++) { \
d[t].A = i; i += y; d[t].E = j; j += y; d[t].L = (t < T - 1) ? y : y + X; \
if (pthread_create(th + t, NULL, func_name##_T1, d + t) != 0) { R = 1; T = t; break; } } \
for (t = 0; t < T; t++) if (pthread_join(th[t], NULL) != 0) R = 1; if (R) return NULL; \
if (d[0].A == d[0].E) { a = E, e = A; V = (d[T - 1].A != d[T - 1].E) ? d[T - 1].A : NULL; } \
else V = (d[T - 1].A == d[T - 1].E) ? d[T - 1].A : NULL; \
for(i = a, j = e, T /= 2; T; T /= 2, y *= 2, z *= 2, a = e, e = (e == E) ? A : E, i = a, j = e) { \
for (t = 0; t < T; t++) { \
d[t].A = i; i += z; d[t].E = j; j += z; d[t].L = y; d[t].X = (t < T - 1) ? 0 : X; \
d[t].V = (T == P && t == T - 1) ? V : NULL; \
if (pthread_create(th + t, NULL, func_name##_T2, d + t) != 0) { R = 1; T = t; break; } } \
for (t = 0; t < T; t++) if (pthread_join(th[t], NULL) != 0) R = 1; if (R) return NULL; } \
return a; }
#endif
m.c:
#include <stdio.h>
#include "msort.h"
#define N (size_t)1e8
#define TYPE int32_t
static inline MCMP(cmp) { return *(const TYPE *)a > *(const TYPE *)b; }
static inline MSORT(sort, TYPE)
MSORT_MT(static inline, sort_mt, TYPE, sort, cmp)
TYPE R[N], A[N], B[N], *v, *e; size_t ms, t = 2, T, i;
MAIN_ARGS {
if (argc != 2 || sscanf(argv[1], "%lu" , &T) == 0
|| T < 2 || T > 256 || (T & (T - 1))) goto ae;
srand(time(NULL)); for (; i < N; i++) R[i] = rand(); TIME_PAIR;
for (; t <= T; t *= 2) {
printf("%31ld threads:", t); memcpy(A, R, sizeof(TYPE) * N);
TIME_DIFF_EXEC(e = sort_mt(t, A, N, B), MS, ms); if (e == NULL) goto te;
for (v = e; v < e + (N - 1); v++) if (cmp(v, v + 1)) goto ve;
printf("%40ld\n", ms);
}
return 0;
ae: printf("Usage: './m <max_thread_count>', where\n"
" <max_thread_count> - power of 2 in inclusive range 2..256\n");
return 1;
te: printf(" ...THREAD_ERROR\n");
return 1;
ve: printf(" ...VERIFICATION_ERROR, #%ld\n", v - e);
return 1;
}
Big_O:
1e8 elem:
- MSORT: 27.00 N
- MSORT_MT:
- 2 threads: 14.00 N
- 4 threads: 7.75 N
- 8 threads: 4.75 N
- 16 threads: 3.30 N
- 32 threads: 2.60 N
- 64 threads: 2.30 N
- 128 threads: 2.15 N
- 256 threads: 2.05 N
def big_O log_N
log_N = Float log_N
for i in 1..8
return if i > log_N
x = (log_N - i) / 2 ** i
a = 1.0; i.times { x += a; a /= 2 }
puts "\t- %3d: %13.10f" % [2 ** i, x]
end
end
https://github.com/CppCon/CppCon2019/blob/master/Presentations/speed_is_found_in_the_minds_of_people/speed_is_found_in_the_minds_of_people__andrei_alexandrescu__cppcon_2019.pdf
http://www.win-vector.com/blog/2008/04/sorting-in-anger/
$ clang -flto -O3 m.c -o m -lpthread --static && ./m 256
2 threads: 3420
4 threads: 1991
8 threads: 1287
16 threads: 1298
32 threads: 1295
64 threads: 1298
128 threads: 1294
256 threads: 1293
$ cpuid | grep 'brand =' | uniq
brand = "AMD Ryzen 7 1700X Eight-Core Processor "
Сортировка для double на Tesla v100:
800 MB — 229.604 ms
4,5 GB — 1133.35 ms
github.com/tishden/gpu_benchmark/blob/master/cuda/benchmark_results_for_double_64_tesla_v100.txt
800 MB — 229.604 ms
4,5 GB — 1133.35 ms
github.com/tishden/gpu_benchmark/blob/master/cuda/benchmark_results_for_double_64_tesla_v100.txt
Денис, описание бенчмарка на гитхаб не соответствует действительности: вместо 'GPU vs CPU' должно быть 'Thrust vs STL'. На задаче сортировки это сравнение выглядит особенно «нелепо»: однопоточная «логарифмическая» сортировка сравнением, запущенная на 1-ом ядре с TDP 10Вт и ценой ~$100 против «линейной» поразрядной сортировки подсчётом, утилизирующей «видяху» с TDP 250Вт и ценой $5000.
В статье явно говорится, что для GPU используется Thrust и почему, про STL может быть и не явно, но подразумевается. Суть статьи — как быстро подступиться, т.е. без хардкорного С и CUDA девелопмента. По хорошему, тогда нужно на asm писать под конкретный процессор.
STL, т.к. многие им пользуются (хоть, он и не всегда эффективен) и не все готовы писать код, который приводите Вы. Для GPU я так же не утверждаю, что thrust самая быстрая библиотека.
>> На задаче сортировки это сравнение выглядит особенно «нелепо»
Вы не поняли, в чем суть этих графиков. Я не заявляю, что «GPU крут во всех задачах», я привожу конкретное latency для конкретного подхода. Один CPU поток, т.к. методом не сложных математических вычислений, можно прикинуть, какое latency будет, если алгоритм распарралелить. Для GPU — это примеры, от которых можно отталкиваться. Да, это сравнение «теплого» с «мягким», но вычисленный результат в итоге одинаковый и посчитано затраченное время, от которого можно отталкиваться.
>> утилизирующей «видяху» с TDP 250Вт и ценой $5000.
на консьюмерских картах можно что-то похожее получить, для проверки и написан бенчмарк. Мне самому было любопытно, что можно получить с топовой карты.
STL, т.к. многие им пользуются (хоть, он и не всегда эффективен) и не все готовы писать код, который приводите Вы. Для GPU я так же не утверждаю, что thrust самая быстрая библиотека.
>> На задаче сортировки это сравнение выглядит особенно «нелепо»
Вы не поняли, в чем суть этих графиков. Я не заявляю, что «GPU крут во всех задачах», я привожу конкретное latency для конкретного подхода. Один CPU поток, т.к. методом не сложных математических вычислений, можно прикинуть, какое latency будет, если алгоритм распарралелить. Для GPU — это примеры, от которых можно отталкиваться. Да, это сравнение «теплого» с «мягким», но вычисленный результат в итоге одинаковый и посчитано затраченное время, от которого можно отталкиваться.
>> утилизирующей «видяху» с TDP 250Вт и ценой $5000.
на консьюмерских картах можно что-то похожее получить, для проверки и написан бенчмарк. Мне самому было любопытно, что можно получить с топовой карты.
Флейм
Что касается NVIDIA, то я почти на 100% уверен, что Thrust «под капотом» написан на asm'е инженерами с Ph.D и 7-значной зарплатой: Huang'у нужны «красивые» цифры в бенчмарках, чтобы продавать.
По хорошему, тогда нужно на asm писать под конкретный процессор.Для RISC-V я бы может и заюзал «мнемоники машинного кода», писать на asm для современного AMD64-совместимого CPU, который по факту CISC-on-VLIW и работает по принципу «фиг пойми», мне неохота.
Что касается NVIDIA, то я почти на 100% уверен, что Thrust «под капотом» написан на asm'е инженерами с Ph.D и 7-значной зарплатой: Huang'у нужны «красивые» цифры в бенчмарках, чтобы продавать.
Один CPU поток, т.к. методом не сложных математических вычислений, можно прикинуть, какое latency будет, если алгоритм распарралелить.
Переиспользуемые потоки + массив volatile _Bool'ов для синхронизации = латенси в районе 100 наносекунд на подхват задания потоком. Каждый _Bool действует как переключатель с ровно двумя положениями: «0» — «child читает, main пишет», «1» — «main читает, child пишет». Когда поток, имеющий право на запись меняет значение «переключателя», то он одномоментно (и вполне атомарно) лишает себя права на запись и передаёт это право «напарнику».
Radix
rsort.h:
dram_again.c:
#ifndef ___RSORT_H
#define ___RSORT_H
#include <pthread.h>
#include <stdint.h>
#include <string.h>
typedef int8_t s7_t; typedef uint8_t u8_t;
typedef int16_t s15_t; typedef uint16_t u16_t;
typedef int32_t s31_t; typedef uint32_t u32_t;
typedef int64_t s63_t; typedef uint64_t u64_t;
#define pf printf
#define MALLOC(pointer, reg_size) if ((pointer = malloc(reg_size)) == NULL)
#define CALLOC(pointer, reg_size) if ((pointer = calloc(reg_size, 1)) == NULL)
#define for_in(stop) for (s63_t i = -1, _stop = stop; ++i < _stop;)
#define for_in_(iter_name, stop) for (s63_t iter_name = -1, _stop = stop; ++iter_name < _stop;)
#define for_inx(start, stop, increment) \
for (s63_t i = start, _stop = stop; i < _stop; i += increment)
#define for_inx_(iter_name, start, stop, increment) \
for (s63_t iter_name = start, _stop = stop; iter_name < _stop; iter_name += increment)
#define r_for_in(stop) for (s63_t i = stop; --i >= 0;)
#define r_for_in_(iter_name, stop) for (s63_t iter_name = stop; --iter_name >= 0;)
#define r_for_inx(start, stop, decrement) \
for (s63_t i = stop, _start = start; (i -= decrement) >= _start;)
#define r_for_inx_(iter_name, start, stop, decrement) \
for (s63_t iter_name = stop, _start = start; (iter_name -= decrement) >= _start;)
#define PTHC(id_ptr, thread_func, data_ptr) \
if (pthread_create(id_ptr, NULL, thread_func, data_ptr) != 0)
#define PTHJ(id) if (pthread_join(id, NULL) != 0)
#define RSORT(func_name) \
void func_name(const char *const Type, const char *const Ord, void *const A, const u64_t L, \
void *const E /* NULL if Type in ["s7_t", "u8_t"] */ ) { \
_Bool asc; if (!strcmp(Ord, "asc") || !strcmp(Ord, "<")) asc = 1; else \
if (!strcmp(Ord, "des") || !strcmp(Ord, ">")) asc = 0; else return; \
u64_t c[8][256] = {}, *m, r, o[8][256]; if (L < 2) return; \
s7_t *sb; u8_t *b, cx; s15_t *sw; u16_t *w, *we; \
s31_t *sd; u32_t *d, *de; s63_t *sq; u64_t *q, *qe; \
if (!strcmp(Type, "s7_t")) goto s1; if (!strcmp(Type, "u8_t")) goto u1; \
if (!strcmp(Type, "s15_t")) goto s2; if (!strcmp(Type, "u16_t")) goto u2; \
if (!strcmp(Type, "s31_t")) goto s4; if (!strcmp(Type, "u32_t")) goto u4; \
if (!strcmp(Type, "s63_t")) goto s8; if (!strcmp(Type, "u64_t")) goto u8; else return; \
s1: sb = A; m = c[0] + 128; for_in(L) m[sb[i]]++; \
if (asc) for_inx(-128, 128, 1) { for (; m[i]--;) *sb++ = i; } else \
r_for_inx(-128, 128, 1) { for (; m[i]--;) *sb++ = i; } return; \
u1: b = A; for_in(L) c[0][b[i]]++; \
if (asc) for_in(256) { for (; c[0][i]--;) *b++ = i; } else \
r_for_in(256) { for (; c[0][i]--;) *b++ = i; } return; \
s2: sw = A, w = A, we = E, cx = 3; \
for_in(L) { w[i] = sw[i] + 0x8000; for_in_(j, 2) c[j][((u8_t *)(w + i))[j]]++; } goto cx; \
c3: for_in(L) we[o[0][((u8_t *)(w + i))[0]]++] = w[i]; \
for_in(L) sw[o[1][((u8_t *)(we + i))[1]]++] = we[i] - 0x8000; return; \
u2: w = A, we = E; for_in(L) { for_in_(j, 2) c[j][((u8_t *)(w + i))[j]]++; } cx = 2; goto cx; \
c2: for_in(L) we[o[0][((u8_t *)(w + i))[0]]++] = w[i]; \
for_in(L) w[o[1][((u8_t *)(we + i))[1]]++] = we[i]; return; \
s4: sd = A, d = A, de = E, cx = 5; \
for_in(L) { d[i] = sd[i] + (1L << 31); for_in_(j, 4) c[j][((u8_t *)(d + i))[j]]++; } goto cx; \
c5: for_in_(j, 3) { for_in(L) de[o[j][((u8_t *)(d + i))[j]]++] = d[i]; \
de = d, d = (d == A) ? E : A; } \
for_in(L) sd[o[3][((u8_t *)(d + i))[3]]++] = d[i] - (1L << 31); return; \
u4: d = A, de = E; for_in(L) { for_in_(j, 4) c[j][((u8_t *)(d + i))[j]]++; } cx = 4; goto cx; \
c4: for_in_(j, 4) { for_in(L) de[o[j][((u8_t *)(d + i))[j]]++] = d[i]; \
de = d, d = (d == A) ? E : A; } return; \
s8: sq = A, q = A, qe = E; s63_t x63 = (1UL << 63) - 1; \
for_in(L) { q[i] = sq[i] < 0 ? (sq[i] + x63) + 1 : q[i] + (1UL << 63); \
for_in_(j, 8) c[j][((u8_t *)(q + i))[j]]++; } cx = 9; goto cx; \
c9: for_in_(j, 7) { for_in(L) qe[o[j][((u8_t *)(q + i))[j]]++] = q[i]; \
qe = q, q = (q == A) ? E : A; } \
for_in(L) sq[o[7][((u8_t *)(q + i))[7]]++] = \
q[i] < (1UL << 63) ? (((s63_t)(q[i])) - x63) - 1 \
: q[i] - (1UL << 63); return; \
u8: q = A, qe = E; for_in(L) { for_in_(j, 8) c[j][((u8_t *)(q + i))[j]]++; } cx = 8; goto cx; \
c8: for_in_(j, 8) { for_in(L) qe[o[j][((u8_t *)(q + i))[j]]++] = q[i]; \
qe = q, q = (q == A) ? E : A; } return; \
cx: for_in(cx & 14) { r = 0; if (asc) for_in_(j, 256) { o[i][j] = r; r += c[i][j]; } else \
r_for_in_(j, 256) { o[i][j] = r; r += c[i][j]; } } \
void *ca[] = { 0, 0, &&c2, &&c3, &&c4, &&c5, 0, 0, &&c8, &&c9 }; goto *ca[cx]; }
typedef struct ___rsmtd_t { u64_t *c, *o, L, cx; void *A, *E; } ___rsmtd_t;
#define RSORT_MT(before, func_name, rsort_func_name) \
static void* func_name##_T(void *data) { ___rsmtd_t *x = data; \
void *A = x->A, *E = x->E; u64_t cx = x->cx & 15, k = x->cx >> 16, c[256], \
o[256], *m, *n, L = x->L; _Bool s = (x->cx >> 8) & 1; \
if (s) memset(c, 0, 2048); else { memcpy(o, x->o, 2048); if (cx < 2) memcpy(c, x->c, 2048); } \
s7_t *sb; u8_t *b; s15_t *sw; u16_t *w, *we; const s63_t x63 = (1UL << 63) - 1; \
s31_t *sd; u32_t *d, *de; s63_t *sq; u64_t *q, *qe; \
void *sa[] = { &&u1, &&s1, &&u2, &&s2, &&u4, &&s4, 0, 0, &&u8, &&s8 }; \
void *ca[] = { &&c0, &&c1, &&c2, &&c3, &&c4, &&c5, 0, 0, &&c8, &&c9 }; goto aa; \
s1: sb = A, m = c + 128; for_in(L) m[sb[i]]++; goto r; c1: sb = A, n = o + 128, \
m = c + 128; for_inx(-128, 128, 1) { for (; m[i]--;) sb[n[i]++] = i; } goto r; \
u1: b = A; for_in(L) c[b[i]]++; goto r; \
c0: b = A; for_in(256) { for (; c[i]--;) b[o[i]++] = i; } goto r; \
s2: sw = A, w = A; \
for_in(L) { if (!k) w[i] = sw[i] + 0x8000; c[((u8_t *)(w + i))[k]]++; } goto r; \
c3: w = A; if (!k) { we = E; for_in(L) we[o[((u8_t *)(w + i))[0]]++] = w[i]; } \
else { sw = E; for_in(L) sw[o[((u8_t *)(w + i))[1]]++] = w[i] - 0x8000; } goto r; \
u2: w = A; for_in(L) c[((u8_t *)(w + i))[k]]++; goto r; \
c2: w = A, we = E; for_in(L) we[o[((u8_t *)(w + i))[k]]++] = w[i]; goto r; \
s4: sd = A, d = A; \
for_in(L) { if (!k) d[i] = sd[i] + (1L << 31); c[((u8_t *)(d + i))[k]]++; } goto r; \
c5: d = A; if (k < 3) { de = E; for_in(L) de[o[((u8_t *)(d + i))[k]]++] = d[i]; } \
else { sd = E; for_in(L) sd[o[((u8_t *)(d + i))[3]]++] = d[i] - (1L << 31); } goto r; \
u4: d = A; for_in(L) c[((u8_t *)(d + i))[k]]++; goto r; \
c4: d = A, de = E; for_in(L) de[o[((u8_t *)(d + i))[k]]++] = d[i]; goto r; \
s8: sq = A, q = A; \
for_in(L) { if (!k) q[i] = sq[i] < 0 ? (sq[i] + x63) + 1 : q[i] + (1UL << 63); \
c[((u8_t *)(q + i))[k]]++; } goto r; \
c9: q = A; if (k < 7) { qe = E; for_in(L) qe[o[((u8_t *)(q + i))[k]]++] = q[i]; } \
else { sq = E; for_in(L) sq[o[((u8_t *)(q + i))[7]]++] = \
q[i] < (1UL << 63) ? (((s63_t)(q[i])) - x63) - 1 : q[i] - (1UL << 63); } goto r; \
u8: q = A; for_in(L) c[((u8_t *)(q + i))[k]]++; goto r; \
c8: q = A, qe = E; for_in(L) qe[o[((u8_t *)(q + i))[k]]++] = q[i]; goto r; \
r: if (s) memcpy(x->c, c, 2048); return NULL; \
aa: if (s) goto *sa[cx]; else goto *ca[cx]; } before \
_Bool func_name(u64_t T, const char *const Type, const char *const Ord, void *const A, \
const u64_t L, void *const E /* NULL if Type in ["s7_t", "u8_t"] */ ) { \
if (L < (u64_t)2e5) { rsort_func_name(Type, Ord, A, L, E); return 0; } \
_Bool asc; if (!strcmp(Ord, "asc") || !strcmp(Ord, "<")) asc = 1; else \
if (!strcmp(Ord, "des") || !strcmp(Ord, ">")) asc = 0; else return 1; \
if (T < 2 || T > 256) return 1; for (; L / T < (u64_t)1e5; T--); ___rsmtd_t d[T]; \
u64_t (*c)[256], (*o)[256], r, v, z, cx, l = L / T; _Bool R = 0; pthread_t th[T]; \
if (!strcmp(Type, "s7_t")) cx = 1; else if (!strcmp(Type, "u8_t")) cx = 0; else \
if (!strcmp(Type, "s15_t")) cx = 3; else if (!strcmp(Type, "u16_t")) cx = 2; else \
if (!strcmp(Type, "s31_t")) cx = 5; else if (!strcmp(Type, "u32_t")) cx = 4; else \
if (!strcmp(Type, "s63_t")) cx = 9; else if (!strcmp(Type, "u64_t")) cx = 8; else return 1; \
CALLOC(c, 2048 * T * 2) return 1; o = c + T; \
void *a = A, *e = E; z = (cx & 14); z = z ? z : 1; \
for_in(T) { d[i].c = c[i]; d[i].o = o[i]; d[i].L = (i < T - 1) ? l : l + L % T; } \
for_in_(k, z) { \
for_in(T) { d[i].cx = (k << 16) + 256 + cx; d[i].A = a + i * l * z; \
PTHC(th + i, func_name##_T, d + i) { R = 1; T = i; break; } } \
for_in(T) PTHJ(th[i]) R = 1; if (R) goto r; \
r = 0; if (asc) for_in_(j, 256) { for_in_(t, T) { o[t][j] = r; r += c[t][j]; } } else \
r_for_in_(j, 256) { for_in_(t, T) { o[t][j] = r; r += c[t][j]; } } \
for_in(T) { d[i].cx = (k << 16) + cx; \
d[i].A = (z > 1) ? a + i * l * z : A; d[i].E = e; \
PTHC(th + i, func_name##_T, d + i) { R = 1; T = i; break; } } \
for_in(T) PTHJ(th[i]) R = 1; if (R) goto r; \
a = e, e = (e == E) ? A : E; } \
r: free(c); return R; }
#endif
dram_again.c:
#include <stdio.h>
#include "msort.h"
#include "rsort.h"
//static inline int dcmp(const void *a, const void *b) {
//return (*(const int32_t *)a > *(const int32_t *)b) -
//(*(const int32_t *)a < *(const int32_t *)b);
//}
//static inline int qcmp(const void *a, const void *b) {
//return (*(const int64_t *)a > *(const int64_t *)b) -
//(*(const int64_t *)a < *(const int64_t *)b);
//}
static inline RSORT(rsort)
RSORT_MT(static inline, rsort_mt, rsort)
#define N (u64_t)1e8
#define N31 16
#define N63 16
MAIN_VOID {
s63_t *R = malloc(N * 24), *A = R + N, *B = A + N, ms; _Bool e;
if (R == NULL) { pf("line 25\n"); return 1; } srand(time(NULL)); TIME_PAIR;
for_in(N) { R[i] = rand(); R[i] = -R[i] * R[i]; R[i] = -R[i] * R[i]; }
pf("int32_t:\n%15d thread ", 1); memcpy(A, R, N * 4);
TIME_DIFF_EXEC(rsort("s31_t", "<", A, N, B), MS, ms); pf("%13ld ms\n", ms);
// memcpy(B, R, N * 4); qsort(B, N, 4, dcmp); pf("%d\n", memcmp(A, B, N * 4));
pf("%15d threads ", N31); memcpy(A, R, N * 4);
TIME_DIFF_EXEC(e = rsort_mt(N31, "s31_t", "<", A, N, B), MS, ms);
if (e) { pf("line 35\n"); return 1; } pf("%13ld ms\n", ms);
// memcpy(B, R, N * 4); qsort(B, N, 4, dcmp); pf("%d\n", memcmp(A, B, N * 4));
pf("int64_t:\n%15d thread ", 1); memcpy(A, R, N * 8);
TIME_DIFF_EXEC(rsort("s63_t", "<", A, N, B), MS, ms); pf("%13ld ms\n", ms);
// memcpy(B, R, N * 8); qsort(B, N, 8, qcmp); pf("%d\n", memcmp(A, B, N * 8));
pf("%15d threads ", N63); memcpy(A, R, N * 8);
TIME_DIFF_EXEC(e = rsort_mt(N63, "s63_t", "<", A, N, B), MS, ms);
if (e) { pf("line 46\n"); return 1; } pf("%13ld ms\n", ms);
// memcpy(B, R, N * 8); qsort(B, N, 8, qcmp); pf("%d\n", memcmp(A, B, N * 8));
return 0;
}
$ clang -flto -O3 dram_again.c -lpthread --static && ./a.out
int32_t:
1 thread 727 ms
4 threads 481 ms
int64_t:
1 thread 2173 ms
4 threads 1830 ms
$ cpuid | grep 'brand =' | uniq
brand = "Intel(R) Core(TM) i3-8109U CPU @ 3.00GHz"
$ sudo dmidecode -t 17 | grep 'Size'
Size: 4096 MB
Size: No Module Installed
$ clang -flto -O3 dram_again.c -lpthread --static && ./a.out
int32_t:
1 thread 1680 ms
16 threads 275 ms
int64_t:
1 thread 3452 ms
16 threads 942 ms
$ cpuid | grep 'brand =' | uniq
brand = "AMD Ryzen 7 1700X Eight-Core Processor "
Тоже бенчили 2080ti vs t4/v100
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Вычисления на GPU – зачем, когда и как. Плюс немного тестов