 В библиотеке Intel Performance Primitives (IPP), начиная с версии 8.2, планомерно осуществляется переход от внутреннего распараллеливания функций к внешнему. Причины такого решения изложены в статье Функции IPP c поддержкой бордюров для обработки изображений в нескольких потоках.
В библиотеке Intel Performance Primitives (IPP), начиная с версии 8.2, планомерно осуществляется переход от внутреннего распараллеливания функций к внешнему. Причины такого решения изложены в статье Функции IPP c поддержкой бордюров для обработки изображений в нескольких потоках. В этом посте будут рассмотрены функции, реализующие фильтр с конечным откликом — FIR фильтр (Finite Impulse Response).
FIR фильтр
Фильтры являются одной из важнейших областей в цифровой обработке сигналов. И, конечно же, библиотека IPP имеет реализацию большинства классов этих фильтров, в том числе и FIR (finite impulse response) фильтра. Подробное описание FIR фильтров можно найти в многочисленной литературе или в википедии, но если кратко, в нескольких словах, то FIR фильтр просто умножает несколько предыдущих отсчетов и текущий отсчет входного дискретного сигнала на соответствующие им коэффициенты, складывает эти произведения и получает текущий отсчет выходного сигнала. Или чуть более формально: FIR фильтр осуществляет преобразование входного вектора X длиной N отсчетов в выходной вектор Y длиной тоже N отсчетов посредством умножения K отсчетов входного вектора на соответствующие им K коэффициентов H и последующим суммированием. Количество коэффициентов K называется порядком фильтра.

Рис. 1. FIR фильтр
Здесь:
tapsLen — это порядок фильтра,
numIters — это длина вектора.
Рисунок взят из документации на IPP библиотеку, поэтому используется принятая в IPP терминология.
Визуально можно представить FIR фильтр следующим образом.
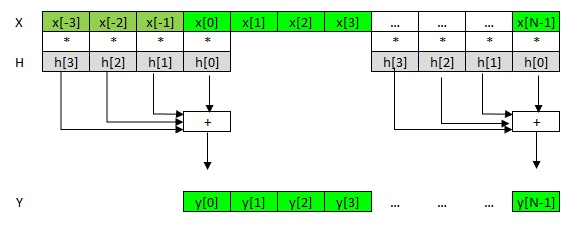
Рис. 2. FIR фильтр схематически
Как видим, здесь порядок фильтра K равен 4 и мы просто умножаем 4 коэффициента h фильтра на 4 отсчета вектора x, складываем и записываем сумму в один отсчет выходного вектора y. Отметим, что коэффициенты фильтра h[3],h[2],h[1],h[0] лежат в памяти в обратном порядке по отношению к x и y, в соответствии с общепринятой формулой на рис. 1
Линия задержки
Поскольку FIR фильтр это обычная свертка, то для получения выходного вектора длиной в N отсчетов, необходимо N+K-1 входных отсчетов, где K длина ядра. Первые K-1 отсчетов будем далее называть «линией задержки» (delay line). На рис. 2 они нумеруются x[-3], x[-2], x[-1]. Данные, подаваемые в функцию, могут быть довольно большого объема, вследствие чего быть разбитыми на отдельные последовательно обрабатываемые блоки. К примеру, если это аудио сигнал, то он может буферизоваться операционной системой, если это данные от внешнего устройства, то они могут приходить порциями по линии связи. А также данные могут обрабатываться через буфер и в самом приложении, поскольку заранее неизвестен объем возможных данных. В этом случае рабочий буфер выделяется некой фиксированной длины к примеру так, чтобы они укладывались в кэш некоторого уровня и тогда все данные проходят через этот буфер порциями. Во всех таких случаях линия задержки очень полезна. Она помогает очень просто «склеить» данные в один непрерывный поток таким образом, что не возникает краевого эффекта разбиения данных на блоки.
IPP API
Многолетний опыт использования библиотеки IPP выявил, что необходимо модифицировать API FIR фильтров так, чтобы удовлетворить следующим требованиям:
- была бы возможность обработки вектора последовательными блоками;
- отсутствовало бы скрытое выделение памяти;
- поддерживалась бы обработка вектора в разных потоках;
- был допустим in-place режим т.е входной вектор является одновременно и выходным.
Для того чтобы выполнить одновременно все эти требования, были введены понятия “входной” и “выходной” линий задержки, после чего API стал выглядеть следующим образом.
API FIR фильтров
// Name: ippsFIRSRGetSize, ippsFIRSRInit_32f, ippsFIRSRInit_64f
// ippsFIRSR_32f, ippsFIRSR_64f
// Purpose: Get sizes of the FIR spec structure and temporary buffer
// initialize FIR spec structure - set taps and delay line
// perform FIR filtering
// Parameters:
// pTaps - pointer to the filter coefficients
// tapsLen - number of coefficients
// tapsType - type of coefficients (ipp32f or ipp64f)
// pSpecSize - pointer to the size of FIR spec
// pBufSize - pointer to the size of temporal buffer
// algType - mask for the algorithm type definition (direct, fft, auto)
// pDlySrc - pointer to the input delay line values, can be NULL
// pDlyDst - pointer to the output delay line values, can be NULL
// pSpec - pointer to the constant internal structure
// pSrc - pointer to the source vector.
// pDst - pointer to the destination vector
// numIters - length of the destination vector
// pBuf - pointer to the work buffer
// Return:
// status - status value returned, its value are
// ippStsNullPtrErr - one of the specified pointer is NULL
// ippStsFIRLenErr - tapsLen <= 0
// ippStsContextMatchErr - wrong state identifier
// ippStsNoErr - OK
// ippStsSizeErr - numIters is not positive
// ippStsAlgTypeErr - unsupported algorithm type
// ippStsMismatch - not effective algorithm.
*/
IppStatus ippsFIRSRGetSize (int tapsLen, IppDataType tapsType , int* pSpecSize, int* pBufSize )
IppStatus ippsFIRSRInit_32f( const Ipp32f* pTaps, int tapsLen, IppAlgType algType, IppsFIRSpec_32f* pSpec )
IppStatus ippsFIRSR_32f (const Ipp32f* pSrc, Ipp32f* pDst, int numIters, IppsFIRSpec_32f* pSpec, const Ipp32f* pDlySrc, Ipp32f* pDlyDst, Ipp8u* pBuf)
Этот API следует стандартной схеме, применяемой в IPP. Вначале с помощью функции ippsFIRSRGetSize запрашивается размер памяти под контекст функции и рабочий буфер. Далее вызывается функция ippsFIRSRInit, в которую подаются коэффициенты фильтра. Эта функция инициализирует внутренние таблицы данных в структуре pSpec, ускоряющие работу процессирующей функции ippsFIRSR. Содержимое данной структуры не изменяется в процессе работы функции, что отражено в ее названии Spec, поэтому может быть использовано одновременно несколькими потоками, для более эффективного использования памяти. Параметр pBuf это рабочий и модицифируемый буфер функции, поэтому для каждого потока должен быть выделен свой рабочий буфер.
Суффикс SR означает single rate, и используется для единообразия c MR (multi rate) фильтрами, описание которых может являться целой отдельной статьей. Параметр numIters также позаимствован из MR фильтров и в нашем случае означает просто длину вектора.
На начало обрабатываемого блока x[0] указывает параметр pSrc.
Теперь рассмотрим какой смысл вкладывается в параметры pDlySrc и pDlyDst.
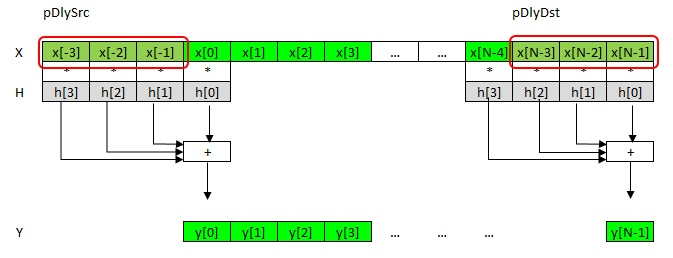
Рис. 3. «Входная» и «Выходная» линии задержки
Как уже упоминалось ранее, необходимость в x[-3], x[-2], x[-1] происходит из формулы свертки. Эти элементы называются «входной линией задержки» pDlySrc. А отсчеты x[N-3], x[N-2], x[N-1] это «хвост» обрабатываемого вектора, т.е. последние K-1 элементов. Они называются «выходной линией задержки» pDlyDst. Для следующего блока они соответственно будут являться входной линией и так далее.
Входная линия задержки pDlySrc может указывать на k-1 отсчетов левее x[0], на какой то другой буфер или равняться NULL. В случае NULL считается, что все элементы входной линии задержки равны 0. Это удобно для начального блока, когда еще нет поступивших данных.
По адресу pDlyDst осуществляется запись «хвоста» блока, т.е. k-1 последних отсчетов. Если значение равно NULL, то ничего не записывается.
Такой механизм из двух линий задержки позволяет распараллелить обработку вектора, даже в случае in-place режима, т.е. когда вектор перезаписывается. Для этого достаточно предварительно скопировать «хвосты» блоков в отдельные буферы и подать их в качестве входной линии в каждый поток. Пример кода использованого в статье приведен в конце единым листингом.
Пример использования Lowpass IPP FIR фильтра.
Рассмотрим, например, как использовать IPP FIR фильтр для того чтобы оставить лишь низкочастотную составляющюю сигнала.
Для генерации исходного нефильтрованного сигнала мы будем использовать специальную IPP функцию Jaehne, реализующую формулу
pDst[n] = magn * sin ((0.5πn2)/len), 0 ≤ n < len
Эта функция является рабочей лошадкой, на которой тестируются многие IPP функции. Сгенерированный сигнал будем записывать в простейший .csv файл и рисовать картинки в Excel. Выглядит исходный сигнал следующим образом.
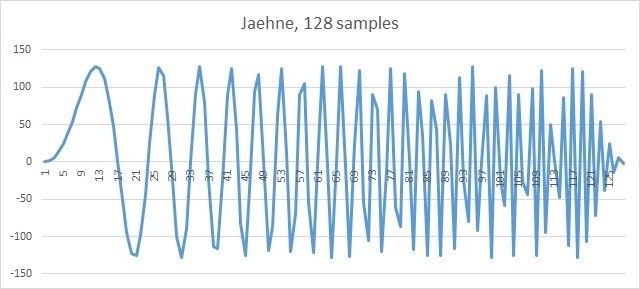
Рис. 4. 128 Отсчетов сигнала Jaehne
Рассмотрим к примеру фильтр порядка 31. Для генерации коэффициентов используется IPP функция ippsFIRGenLowpass_64f. Функция вычисляет коэффициенты только в double, поэтому они преобразуются в float. См. код функции firgenlowpass() в приложении. После вызова этой функции вычисляется размер буфера, инициализация и вызов основной функции ippsFIRSR, а также измеряется ее производительность.
После применения lowpass фильтра в сигнале осталась низкочастотная составляющая. Отметим, что фаза сдвинута, но это уже вытекает из свойства самих FIR фильтров и не относится к IPP библиотеке.
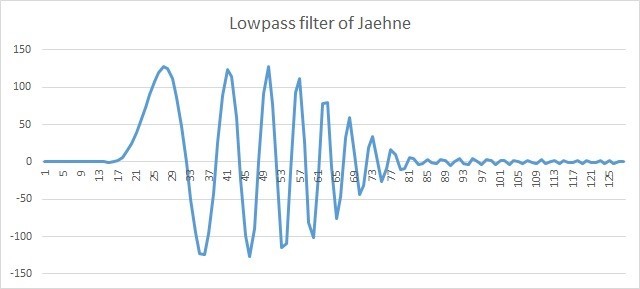
Рис. 5. 128 Отсчетов сигнала Jaehne после lowpass фильтра
На этих рисунках FIR фильтр обрабатывает 128 отсчетов, при этом 30 отсчетов входной линии задержки мы полагаем равными 0, указывая pDlySrc = NULL. Выходная линия нам также не нужна pDlyDst = NULL.
Производительность многопоточной версии
Библиотка IPP имеет в своем названии слово производительность (performance), которая и ставится во главу угла. Поэтому измеряем производительность ippFIRSR функции на процессоре с поддержкой AVX2. После чего реализуем следующий многопоточный код, использующий OpenMP померяем его и после сведем результаты измерений в один график.
API FIR фильтров разрабатывался таким образом чтобы разбиение вектора на несколько потоков было простым и логичным так, как это показано на рисунке:

Рис. 6. Разбиение исходного вектора между потоками
Подразумевается следующий способ разбиения вектора между потоками, см. функцию fir_omp.
Код fir_omp
void fir_omp(Ipp32f* src, Ipp32f* dst, int len, int order, IppsFIRSpec_32f* pSpec, Ipp32f* pDlySrc, Ipp32f* pDlyDst, Ipp8u* pBuffer)
{
int tlen, ttail;
tlen = len / NTHREADS;
ttail = len % NTHREADS;
#pragma omp parallel num_threads(NTHREADS)
{
int id = omp_get_thread_num();
Ipp32f* s = src + id*tlen;
Ipp32f* d = dst + id*tlen;
int len = tlen + ((id == NTHREADS-1) ? ttail : 0);
Ipp8u* b = pBuffer + id*bufSize;
if (id == 0)
ippsFIRSR_32f(s, d, len, pSpec, pDlySrc, NULL, b);
else if (id == NTHREADS - 1)
ippsFIRSR_32f(s, d, len, pSpec, s - (order - 1), pDlyDst, b);
else
ippsFIRSR_32f(s, d, len, pSpec, s - (order - 1), NULL, b);
}
}
Рассмотрим что делает этот код. Итак, к нам поступила очередная порция сигнала x[0],…,x[N-1], которую нужно обработать фильтром, а вместе с ней указатель на входную и выходную линии задержки или другими словами «хвост» предыдущей порции и буфер, куда следует поместить “хвост” текущей порции. Мы хотим ускорить процесс фильтрации и разбиваем обработку этой порции на T=NTHREADS блоков, соответствующее числу потоков. Для этого нам надо просто правильно указать входные и выходные линии, а также выделить свой рабочий буфер для каждого потока.
Для 0-ого потока входная линия задержки при вызове ippsFIRSR это тот самый «хвост» предыдущей порции, а для всех остальных в качестве входной линии подается указатель на блок смещенный на order-1 элементов. И только последний поток записывает «хвост» порции.
Приведенный подход подразумевает что результирующий вектор записывается по другому адресу чем исходный вектор, в случае же если данные будут перезаписаны, то линии задержки следует предварительно скопировать в отдельные буферы.
На графике показана производительность однопоточной и многопоточной версии для 4-х потоков фильтра 31 порядка на процессоре с поддержкой AVX2 инструкций Intel® Core(TM) i7-4770K 3.50Ghz. Для FIR фильтров используется единица измерения cpMAC, т.е. количество тактов на операцию Умножить+Сложить
cpMAC = (время выполнения функции) / (длина вектора * порядок фильтра)
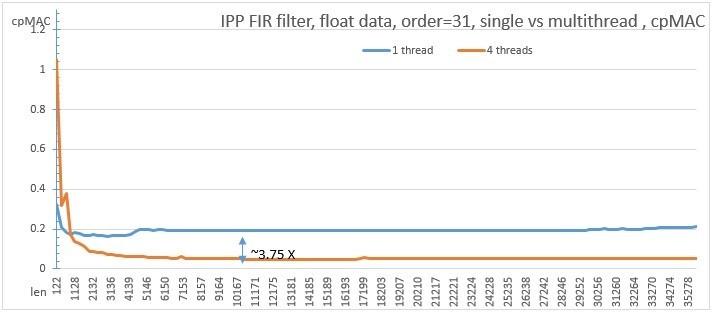
Рис. 7. Сравнение производительности однопоточной и многопоточной версий FIR фильтра
Видно, что функция очень хорошо масштабируется, и многопоточная версия работает приблизительно в 3.7 раз быстрее на достаточно длинных векторах, чем однопоточная, что очень хорошо соответствует 4 потокам. Критерий переключения между одно- и многопоточной версиями теперь, с новым API, можно подобрать экспериментально под конкретную машину, в отличие от предыдущего, где критерий был жестко зашит в код и функция параллелилась изнутри.
Сравнение direct и FFT реализаций
В цифровой обработке сигналов широко используется взаимное соответствие свертки и преобразования Фурье.
IPP FIR фильтры помимо прямой реализации имеют и реализацию через FFT, причем получаемые при этом cpMAC иногда превосходят теоретически возможную для данного cpu и прямого алгоритма, о чем иногда пишут пользователи на форумах, справедливо полагая, что вычисления идут через FFT.
Теперь для того, чтобы указать какой тип алгоритма использовать, следует использовать одно из значений параметра algType — ippAlgDirect ippAlgFFT, ippAlgAuto. Последний параметр означает, что функция выбирает алгоритм по фиксированному критерию для используемого cpu, а он не всегда может быть оптимальным.
Рассмотрим производительность на том же CPU фильтра разных порядков для длины вектора в 1024 и 128 отсчетов используя прямой алгоритм и FFT реализацию.
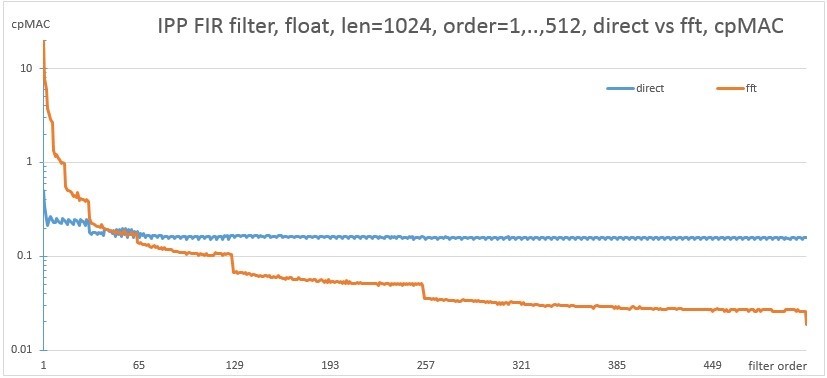
Рис. 8. Сравнение производительности direct и fft реализаций для длины в 1024 отсчета
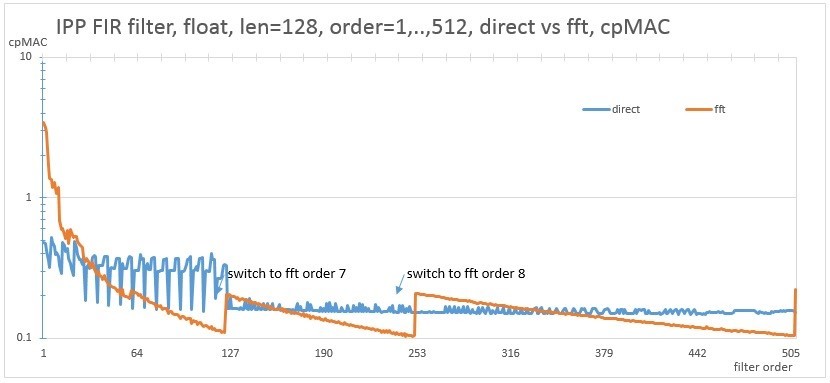
Рис. 9. Сравнение производительности direct и fft реализаций для длины в 128 отсчетов
Для FFT реализации характерны ступеньки. Это объясняется тем, что для фильтров нескольких близких порядков используется FFT одного порядка, а когда переходит переход на следующий порядок FFT, то производительность изменяется. Для достижения максимальной производительности следует использовать тот алгоритм, который лежит ниже на графике. Предлагаемый API позволяет реализовать пример, который будет запускать на измерение на конкретной машине обе версии алгоритма, и выбирать лучшую из них. Картинка буде выглядеть примерно следующим образом. На этой картинке нарисовано двумерное пространство размером 1024x1024, где по оси X порядок фильтра, а по оси Y длина вектора. Зеленый цвет означает что fft алгоритм работает быстрее прямой версии. Характерные прямые линии внизу рисунка соответствуют рис. 9, где fft вариант работает некоторое время медленнее, после перехода на следующий порядок.
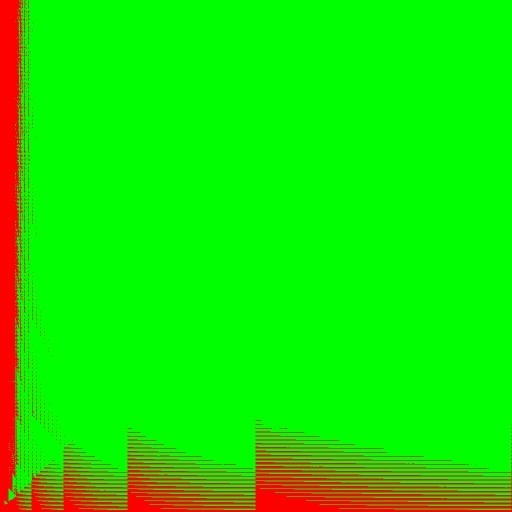
Рис. 10. Сравнение производительности direct и fft реализации IPP FIR float фильтра в пространстве filter order X vector length размерностью 1024 x 1024
Видно, что рисунок довольно сложный и его не так то просто интерполировать внутри IPP под произвольную платформу. К тому же, это рисунок может изменяться на конкретной машине. Помимо выбора между direct и fft кодом, можно добавить еще одну размерность в виде количества потоков и таким образом получится уже многослойная картинка. Предлагаемый API опять же позволяет позволяет выбрать оптимальный для данной платформы вариант и в этом случае.
Заключение
Введенный в IPP 9.0 API FIR фильтров позволяет использовать их в приложениях еще более эффективно, выбирая оптимальный вариант между прямым и fft алгоритмами, а также паралеллить каждый из выбранных вариантов. К тому же библиотека IPP абсолютно бесплатна и доступна для скачивания по этой ссылке Intel Performance Primitives (IPP).
Приложение. Пример кода, измеряющий производительность IPP FIR фильтра
Код примера
#include <stdio.h>
#include <math.h>
#include <omp.h>
#include "ippcore.h"
#include "ipps.h"
#include "bmp.h"
void save_csv(Ipp32f* pSrc, int len, char* fName)
{
FILE *fp;
int i;
if((fp=fopen(fName, "w"))==NULL) {
printf("Cannot open %s\n", fName);
return;
}
for (i = 0; i < len; i++){
fprintf(fp, "%.3f\n", pSrc[i]);
}
fclose(fp);
}
Ipp32f* pSrc;
Ipp32f* pDft;
Ipp32f* pDst;
Ipp32f* pTaps;
Ipp64f rFreq = 0.2;
int bufSize;
int NTHREADS = 1;
IppAlgType algType = ippAlgDirect;
void firgenlowpass(int order)
{
IppStatus status;
Ipp8u* pBuffer;
Ipp64f* pTaps_64f;
int size;
int i;
status = ippsFIRGenGetBufferSize(order, &size);
pBuffer = ippsMalloc_8u(size);
pTaps_64f = ippsMalloc_64f(order);
ippsFIRGenLowpass_64f(rFreq, pTaps_64f, order, ippWinBartlett, ippTrue, pBuffer);
for (i = 0; i < order;i++) {
pTaps[i] = pTaps_64f[i];
}
ippsFree(pTaps_64f);
}
void fir_omp(Ipp32f* src, Ipp32f* dst, int len, int order, IppsFIRSpec_32f* pSpec, Ipp32f* pDlySrc, Ipp32f* pDlyDst, Ipp8u* pBuffer)
{
int tlen, ttail;
tlen = len / NTHREADS;
ttail = len % NTHREADS;
#pragma omp parallel num_threads(NTHREADS)
{
int id = omp_get_thread_num();
Ipp32f* s = src + id*tlen;
Ipp32f* d = dst + id*tlen;
int len = tlen + ((id == NTHREADS-1) ? ttail : 0);
Ipp8u* b = pBuffer + id*bufSize;
if (id == 0)
ippsFIRSR_32f(s, d, len, pSpec, pDlySrc, NULL, b);
else if (id == NTHREADS - 1)
ippsFIRSR_32f(s, d, len, pSpec, s - (order - 1), pDlyDst, b);
else
ippsFIRSR_32f(s, d, len, pSpec, s - (order - 1), NULL, b);
}
}
void perf(int len, int order, float* cpMAC)
{
IppStatus status;
IppsFIRSpec_32f* pSpec;
Ipp8u* pBuffer;
int specSize;
Ipp32f* pDlySrc = NULL;/*initialize delay line with "0"*/
Ipp32f* pDlyDst = NULL;/*don't write output delay line*/
__int64 beg=0, end=0;
int i, loop = 10000;
/*allocate memory for input and output vectors*/
pSrc = ippsMalloc_32f(len);
pDst = ippsMalloc_32f(len);
pTaps = ippsMalloc_32f(order);
/*create special vector Jaehne*/
ippsVectorJaehne_32f(pSrc, len, 128);
/*get lowpass filter coeffs*/
firgenlowpass(order);
/*get necessary buffer sizes for pSpec and for pBuffer*/
status = ippsFIRSRGetSize(order, ipp32f, &specSize, &bufSize);
/*allocate memory for pSpec*/
pSpec = (IppsFIRSpec_32f*)ippsMalloc_8u(specSize);
/*for N threads bufSize should be multiplied by N*/
/*allocate bufSize*NTHREADS bytes*/
pBuffer = ippsMalloc_8u(bufSize*NTHREADS);
/*initalize pSpec*/
status = ippsFIRSRInit_32f(pTaps, order, algType, pSpec);
/*apply FIR filter*/
/*start measurement for sinle threaded*/
if (NTHREADS == 1){
ippsFIRSR_32f(pSrc, pDst, len, pSpec, pDlySrc, pDlyDst, pBuffer);
beg = __rdtsc();
for (int i = 0; i < loop; i++) {
ippsFIRSR_32f(pSrc, pDst, len, pSpec, pDlySrc, pDlyDst, pBuffer);
}
end = __rdtsc();
}
else {
fir_omp(pSrc, pDst, len, order, pSpec, pDlySrc, pDlyDst, pBuffer);
beg = __rdtsc();
for (int i = 0; i < loop; i++) {
fir_omp(pSrc, pDst, len, order, pSpec, pDlySrc, pDlyDst, pBuffer);
}
end = __rdtsc();
}
*cpMAC = ((double)(end - beg) / ((double)loop * (double)len * (double)order));
printf("%5d, %5d, %3.3f\n", len, order, *cpMAC);
ippsFree(pSrc);
ippsFree(pDst);
ippsFree(pTaps);
ippsFree(pSpec);
ippsFree(pBuffer);
}
int main()
{
int len = 32768;
int order;
float cpMAC;
NTHREADS = 1;
algType = ippAlgDirect;
//algType = ippAlgFFT;
len = 128;
printf("\nthreads: %d\n", NTHREADS);
printf("len, order, cpMAC\n\n");
for (order = 1; order <= 512; order++){
perf(len, order, &cpMAC);
}
return 0;
}
