В блоге онлайн-кинотеатра ivi накопилось достаточно статей про архитектуру рекомендательной системы Hydra. Однако рекомендации — это не только внешний API, но и алгоритмы, которые живут «под капотом» и реализуют достаточно сложную бизнес-логику.
В этой статье я расскажу о проблеме «холодного старта» контента. Если вам интересно узнать, как мы рекомендуем контент, который недавно добавился в каталог и не успел набрать фидбэк от пользователей — добро пожаловать под кат.

Статья будет содержать воспроизводимый пример кода на языке Python с использованием Keras.
Как работают рекомендации? Примерно следующим образом:

Мы используем для рекомендаций следующий пайплайн:
Все этапы пайплайна обучения модели холодного старта можно найти в этом репозитории github.com/ivi-ru/hydra
Фичи контента мы получаем с помощью библиотеки implicit следующим образом
Как рекомендовать контент, который вышел на сервисе совсем недавно? У такого контента будут отсутствовать просмотры (или просмотров будет очень мало) — это значит, что в выхлопе волшебной коробки машинного обучения не будет фичей по такому контенту и он не будет появляться в рекомендациях у пользователей. Фичи, которые мы получаем на основе взаимодействий пользователь-контент, кстати, называются коллаборативными.
Таким образом, мы приходим к проблеме холодного старта: как нам рекомендовать контент, по которому нет фидбэка от пользователей? Можно, к примеру, подмешивать новый контент в выдачу случайным образом и ждать, пока не наберутся «органические» просмотры.
Другой вариант — построить модель, которая умеет предсказывать фичи «холодного» контента.
Мы решили пойти по второму пути и вот куда пришли
Решить проблему холодного старта нам помогают контентные фичи, которые о новом контенте известны заранее, например
Редакторские тэги — это краткое описание контента в виде конечного (обычно несколько сотен) набора характеристик. Ниже приведён набор тэгов контента «Бобры-зомби»

В первом приближении мы решали задачу холодного старта следующим образом:

Данный метод как-то работал, но у него было два недостатка:
Мы поняли, что дальше так жить нельзя, и придумали более прозрачную и расширяемую модель.
Вместо того, чтобы вычислять ALS-фичи контента с помощью эвристик (вроде усреднения), мы можем натренировать нейросеть, которая будет предсказывать коллаборативные фичи контента — например, по редакторским тэгам. Похожая модель уже мелькала на Хабре вот тут, а до Яндекса о подобной модели рассказывал музыкальный сервис Spotify
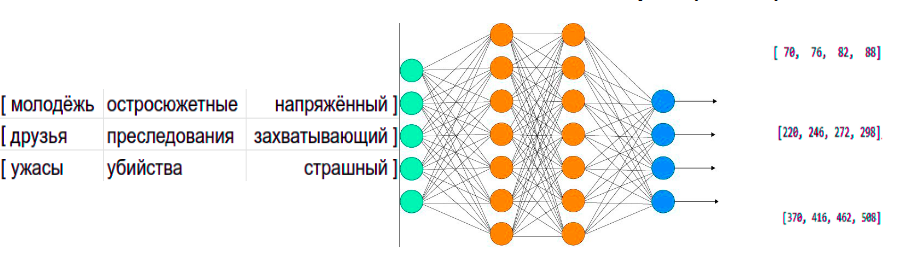
Код прототипа модели доступен в репозитории ivi, нейросеть для холодного старта выглядит следующим образом:
С какими сложностями столкнулись при реализации этого эксперимента?
В итоге мы запилили новый функционал чуть меньше, чему за пару спринтов, разработчик затратил около 100чч — а ведь это первый опыт использования нейросетей в продакшне на нашем проекте. Это время распределилось следующим образом:
Мы получили простор для дальнейших экспериментов — использование нейронных сетей позволяет обучаться не только на редакторских тэгах, но и на других фичах: картинках, сценариях, пользовательских комментариях, видеоряде и т.д.
В этой статье я расскажу о проблеме «холодного старта» контента. Если вам интересно узнать, как мы рекомендуем контент, который недавно добавился в каталог и не успел набрать фидбэк от пользователей — добро пожаловать под кат.

Статья будет содержать воспроизводимый пример кода на языке Python с использованием Keras.
Холодный старт контента: постановка проблемы
Как работают рекомендации? Примерно следующим образом:

Мы используем для рекомендаций следующий пайплайн:
- загружаем статистику просмотров контента в виде матрицы user-content
- применяем волшебную коробку машинного обучения
- на выходе из коробки у каждой единицы каталога появляются фичи
- фичи контента используем для рекомендаций
Все этапы пайплайна обучения модели холодного старта можно найти в этом репозитории github.com/ivi-ru/hydra
Фичи контента мы получаем с помощью библиотеки implicit следующим образом
train_model.py
import implicit
import numpy as np
from scipy.sparse import load_npz
# загружаем матриц user-item
user_item_views_coo = load_npz('/srv/data/user_item_interactions.npz')
als_params = { 'factors': 40, 'regularization': 0.1, 'num_threads': 3, 'iterations': 5}
print('Начинаем обучение ALS-модели')
als_model = implicit.als.AlternatingLeastSquares(**als_params)
als_model.fit(user_item_views_coo.T)
als_factors = als_model.item_factors
print('ALS-модель обучена, факторы контента ', als_factors.shape)
als_factors_filename = '/srv/data/fair_als_factors.npy'
np.save(als_factors_filename, als_factors,allow_pickle=True)
print('Сохранили факторы контента в', als_factors_filename)
Как рекомендовать контент, который вышел на сервисе совсем недавно? У такого контента будут отсутствовать просмотры (или просмотров будет очень мало) — это значит, что в выхлопе волшебной коробки машинного обучения не будет фичей по такому контенту и он не будет появляться в рекомендациях у пользователей. Фичи, которые мы получаем на основе взаимодействий пользователь-контент, кстати, называются коллаборативными.
Таким образом, мы приходим к проблеме холодного старта: как нам рекомендовать контент, по которому нет фидбэка от пользователей? Можно, к примеру, подмешивать новый контент в выдачу случайным образом и ждать, пока не наберутся «органические» просмотры.
Другой вариант — построить модель, которая умеет предсказывать фичи «холодного» контента.
Мы решили пойти по второму пути и вот куда пришли
Cold Start 1.0
Решить проблему холодного старта нам помогают контентные фичи, которые о новом контенте известны заранее, например
- персоны: режиссёр, сценарист, актёрский состав
- жанр контента: боевик, комедия и т.д.
- категория: художественный фильм, мультфильм, документалка
- редакторские тэги
Редакторские тэги — это краткое описание контента в виде конечного (обычно несколько сотен) набора характеристик. Ниже приведён набор тэгов контента «Бобры-зомби»

В первом приближении мы решали задачу холодного старта следующим образом:
- для каждого «холодного» контента натйти максимально похожий на него по тэгам
- взять коллаборативные фичи похожего контента
- коллаборативные фичи холодного контента — это среднее по фичам его «горячих» соседей
На python это выглядит как-то так
for row in new_items_neighbors:
neighbors_als_indices = row.neighbors_ids[:self.cold_start_neighbors_count]
neighbors_average_factors = item_factors[neighbors_als_indices].mean(axis=0)
# сохраняем результат усреднения в матрицу фичей ALS
item_factors[row.new_item_als_index] = neighbors_average_factors

Данный метод как-то работал, но у него было два недостатка:
- слабая расширяемость: тяжело добавить в модель, например, схожесть постеров
- никто не гарантирует похожесть ALS-фичей у схожего по тэгам контента, а без этого использование усреднения выглядит странно
Мы поняли, что дальше так жить нельзя, и придумали более прозрачную и расширяемую модель.
Рефакторинг модели холодного старта
Вместо того, чтобы вычислять ALS-фичи контента с помощью эвристик (вроде усреднения), мы можем натренировать нейросеть, которая будет предсказывать коллаборативные фичи контента — например, по редакторским тэгам. Похожая модель уже мелькала на Хабре вот тут, а до Яндекса о подобной модели рассказывал музыкальный сервис Spotify

Код прототипа модели доступен в репозитории ivi, нейросеть для холодного старта выглядит следующим образом:
cold_start_model.py
def _get_model(self, dims: List[int]) -> Sequential:
model = Sequential()
model.add(
Dense(
units=dims[1], activation='linear', input_dim=dims[0],
kernel_initializer=WeightInitializer.custom_normal,
bias_initializer='zeros'
)
)
model.compile(
loss=lambda y_true, y_pred: K.sum(K.square(y_pred - y_true), axis=-1),
optimizer=optimizers.Adam(lr=self.learning_rate, decay=self.decay)
)
return model
С какими сложностями столкнулись при реализации этого эксперимента?
- обучать сеть оказалось довольно тяжело: фичи закодированы one-hot, и сеть плохо обучается из-за большой размерности входного слоя. Пришлось проводить тщательный отбор фичей, в итоге используем только категории, жанры, а из редакторских тэгов выбираем самые «важные» с помощью tf-idf
- беда с установкой Keras с помощью менеджера пакетов pipenv: python окружение не собиралось, пришлось допиливать сторонний пакет maxvolpy, с которым не подружился Keras
Результаты эксперимента
В итоге мы запилили новый функционал чуть меньше, чему за пару спринтов, разработчик затратил около 100чч — а ведь это первый опыт использования нейросетей в продакшне на нашем проекте. Это время распределилось следующим образом:
- 60 чч на чтение статей и разработку прототипа
- 30 чч на интеграцию прототипа в кодовую базу проекта
- 10 чч на деплой новой модели — затащить Keras в python окружение оказалось не так просто из-за наших специфических зависимостей (вроде maxvolpy)
Мы получили простор для дальнейших экспериментов — использование нейронных сетей позволяет обучаться не только на редакторских тэгах, но и на других фичах: картинках, сценариях, пользовательских комментариях, видеоряде и т.д.
