Привет! Меня зовут Антон Поляков, и я разрабатываю аналитическое хранилище данных и ELT-процессы в ManyChat. В настоящий момент в мире больших данных существуют несколько основных игроков, на которых обращают внимание при выборе инструментария и подходов к работе аналитических систем. Сегодня я расскажу вам, как мы решили отклониться от скучных классических OLAP-решений в виде Vertica или Exasol и попробовать редкую, но очень привлекательную облачную DWaaS (Data Warehouse as a Service) Snowflake в качестве основы для нашего хранилища.
С самого начала перед нами встал вопрос о выборе инструментов для работы с БД и построении ELT-процессов. Мы не хотели использовать громоздкие и привычные всем готовые решения вроде Airflow или NiFi и пошли по пути тонкой кастомизации. Это был затяжной прыжок в неизвестность, который пока продолжается и вполне успешно.
Под катом я расскажу про архитектуру нашего аналитического хранилища и покажу, каким образом мы производим загрузку, обработку и трансформацию данных.
ManyChat — это платформа для общения компаний с клиентами через мессенджеры. Нашим продуктом пользуется более 1.8 млн бизнесов по всему миру, которые общаются c 1.5 млрд подписчиков.
Моя команда занимается разработкой хранилища и ELT-платформы для сбора и обработки всех доступных данных для последующей аналитики и принятия решений.
Большую часть данных мы получаем из собственного приложения: нажатия пользователями кнопок, попапов, события и изменения моделей бэкэнда (пользователя/подписчика/темплейтов/взаимодействия с нашим апи и десятки других). Также получаем информацию из логов и исторических данных из Postgres-баз.
Некоторые данные мы принимаем от внешних сервисов, взаимодействие с которыми происходит посредством вебхуков. Пока это Intercom и Wistia, но список постепенно пополняется.
Аналитики ManyChat для своей работы пользуются данными из слоя DDS (Data Distribution Storage / Service), где они хранятся в шестой нормальной форме (6 нф). По сути, аналитики хорошо осведомлены о структуре данных в Snowflake и сами выбирают способы объединения и обработки множеств с помощью SQL.
В своей ежедневной работе аналитики пишут запросы к десяткам таблиц разного размера, на обработку которых у СУБД уходит определенное время. За счет своей архитектуры Snowflake хорошо подходит для аналитики больших данных и работы со сложными SQL запросами. Приведу конкретные цифры:
В таблице ниже приведена производительность реальных запросов за последний месяц в зависимости от количества используемых в них объектов. Все эти запросы были выполнены на кластере размера S (запросы от ELT-процессов в данных расчетах не участвовали).
Все запросы
Запросы, выполняемые быстрее, чем за 1 секунду, вынесены в отдельную группу. Это позволяет разделить запросы, использующие SSD (локальный кэш и сохраненные данные), от тех, которым приходится основную часть данных читать с медленных HDD.
Запросы > 1 сек
Увеличение количества объектов в запросе усложняет его процессинг.
В этом примере анализ запросов производился с помощью поиска названий существующих таблиц в SQL-коде запросов аналитиков. Таким образом мы находим приблизительное количество использованных объектов.
При раскладке данных в хранилище мы используем классическую якорную модель (Anchor Model). Эта модель позволяет гибко реагировать на изменение уже хранимых или добавление новых данных. Также благодаря ей можно эффективнее сжимать данные и быстрее работать с ними.
Для примера, чтобы добавить новый атрибут к имеющейся сущности, достаточно создать еще одну таблицу и сообщить аналитикам о необходимости делать join'ы на нее.
Подробнее про Anchor Model, сущности, атрибуты и отношения вы можете почитать у Николая Голова aka @azazoth (здесь и здесь).

Размеры кластеров на примере цветных квадратов с текстом
СУБД выделяет расчетные мощности on-demand, как и во многих других продуктах AWS. Бюджет расходуется только если вы используете предоставленные для расчетов мощности — тарифицируется каждая секунда работы кластера. То есть, при отсутствии запросов, вы тратите деньги только на хранение данных.
Для простых запросов можно использовать самый дешёвый кластер (warehouse). Для ELT-процессов, в зависимости от объема обрабатываемых данных, поднимаем подходящий по размеру кластер: XS / S / M / L / XL / 2XL / 3XL / 4XL – прямо как размеры одежды. После загрузки и / или обработки выключаем его, дабы не тратить деньги. Время выключения кластера можно настраивать: от «тушим сразу, как закончили расчет запроса» до «никогда не выключать».

Выделяемое на каждый размер кластера железо и цена за секунду работы
Подробнее про кластеры Snowflake читайте тут. А так же в последней статье Николая Голова.
В настоящий момент ManyСhat использует 9 различных кластеров:
Объем наших данных в Snowflake составляет приблизительно 11 Тбайт. Объем данных без сжатия — около 55 Тбайт (фактор сжатия х5).
Все кластеры в системе работают изолированно. Архитектура решения Snowflake представляется тремя слоями:
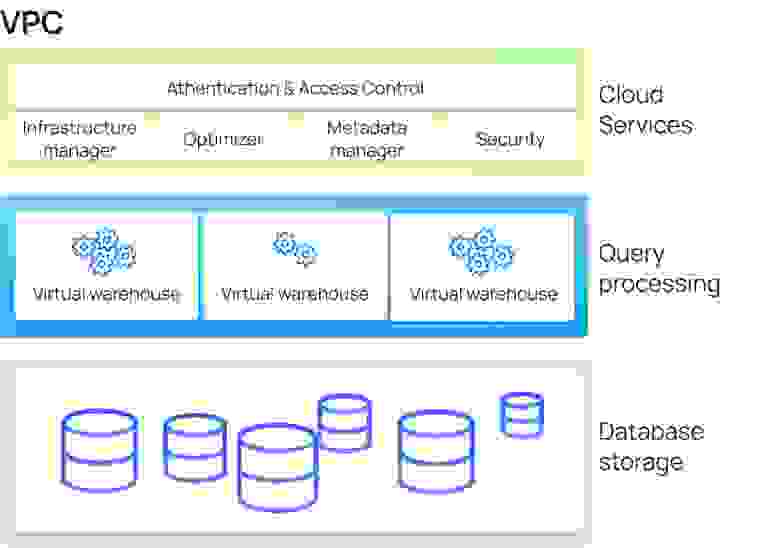
Иллюстрация архитектуры Snowflake
Snowflake работает с «горячими» и «холодными» данными. «Холодными» считаются данные, лежащие в S3 на обычных HDD (Remote Disk). При запросе они дольше считываются и загружаются в быстрые SSD отдельно для каждого кластера. Пока кластер работает, данные доступны на локальном SSD (Local Disk), что ускоряет запросы в несколько раз по сравнению с работой на «холодную».
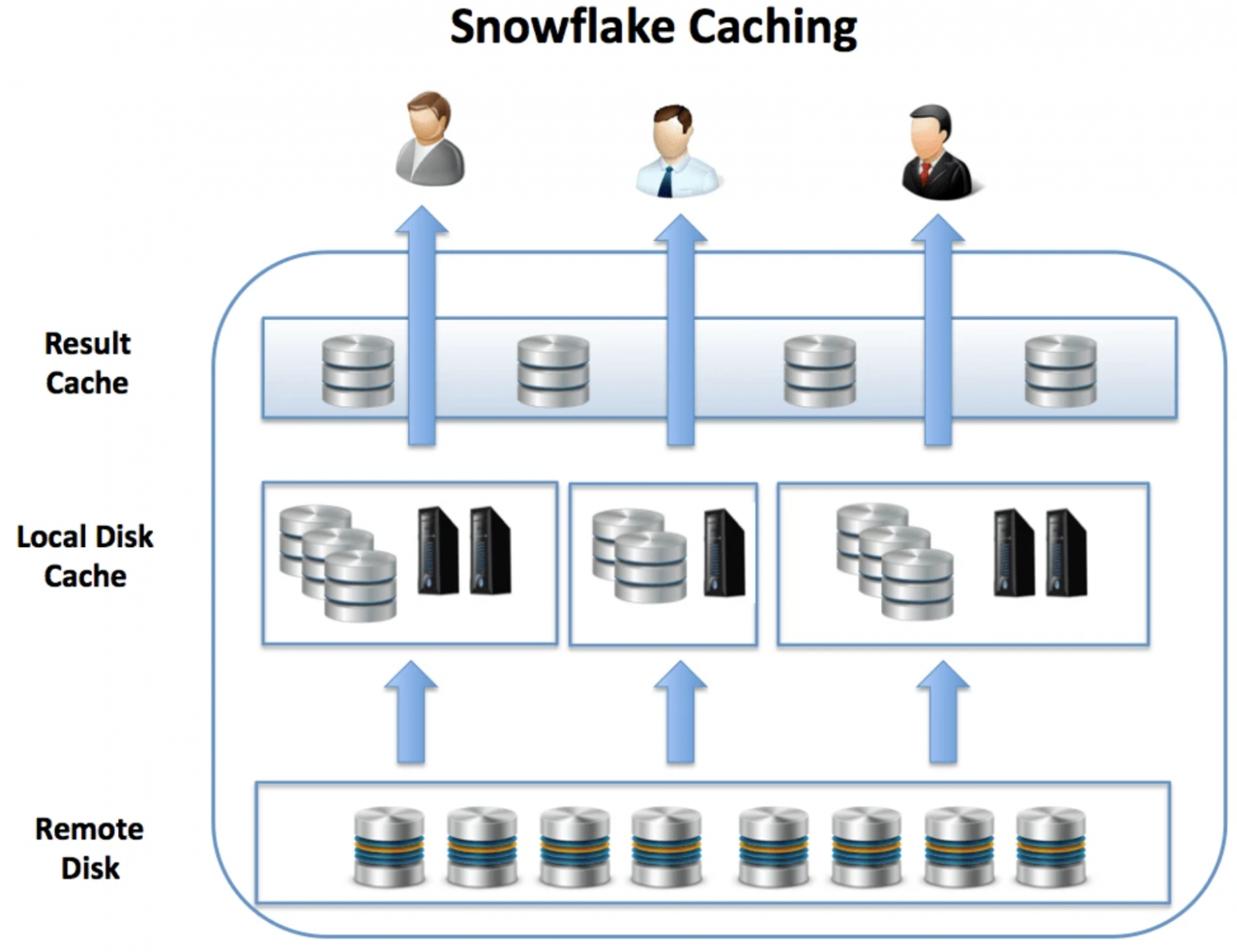
Помимо этого, существует общий для всех кластеров кэш результата запроса (Result Cache) за последние 24 часа. Если данные за это время не изменились, при повторном запуске одного и того же запроса на любом из кластеров они не будут считаны повторно. Подробнее можно почитать тут.
Одной из интересных фичей Snowflake является работа с динамическими микро-партициями. Обычно в базах данных используются статические, но в ряде случаев, например, при перекосе данных (data skew), данные между партициями распределяются неравномерно что усложняет / замедляет обработку запросов.
В Snowflake все таблицы хранятся в очень маленьких партициях, содержащих от 50 до 500 Мбайт данных без сжатия. СУБД хранит в метаданных информацию обо всех строках в каждой микро-партиции, включая:
Такой подход позволяет работать с невероятно большими таблицами, содержащими миллионы и сотни миллионов микро-партиций. Благодаря этому, запросы взаимодействуют только с теми данными, которые удовлетворяют условиям. Подробности и нюансы партиционирования данных в Snowflake можно изучить тут.
Потоки данных и слои их хранения и обработки в ManyChat выглядят примерно так:
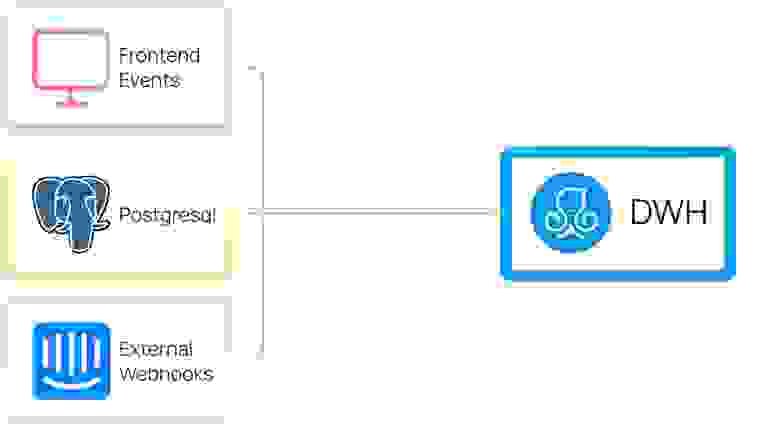
Данные поступают в DWH из нескольких источников:
Давайте рассмотрим, как устроена эта схема, на примере события из бэкенда:
Аббревиатуры слоёв SA* расшифровываются как Staging Area for (Archive/Loading/Extract)
Статистика по объектам в схемах
Используя 6 нф, DDS позволяет хранить достаточно большие объемы данных очень компактно. Все связи между сущностями осуществляются через целочисленные суррогатные ключи, которые отлично жмутся и очень быстро обрабатываются даже самым слабым XS-кластером.
SAA занимает более 80% объема хранилища из-за неструктурированных данных типа variant (сырой JSON). Раз в месяц SAA-слой скидывает данные в историческую схему.
В настоящий момент мы храним более 11 Тбайт данных в Snowflake с фактором сжатия х5, ежедневно получая сотни миллионов новых строк. Но это только начало пути, и мы планируем увеличивать количество источников, а значит и поступающих данных кратно год к году.
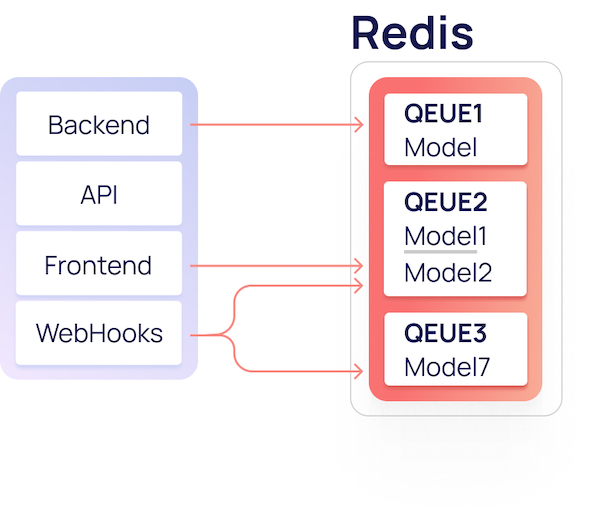
В ManyChat активно используется Redis, и наш проект не стал исключением: он является шиной для обмена данными. Для быстрого и безболезненного старта в качестве языка написания ELT-движка был выбран python, а для хранения логов и статистики — Postgres. Redis выступает в нашей архитектуре местом для временного хранения поступающей информации от всех источников. Данные в Redis хранятся в виде списка (List) JSON'ов.

Структура хранения данных в Redis
В каждом списке могут находится от 1 до N разнообразных моделей данных. Модели объединяются в списки методом дедукции. Например, все клики пользователей в независимости от источника кладутся в один список, но могут иметь разные модели данных (список полей).
Ключами для списков в Redis являются придуманные названия, которые описывают находящиеся в нем модели.
Пример некоторых названий списков и моделей в нем:
Весь ELT построен на python и использовании multiprocessing. Железо для всего ELT в ManyChat работает в AWS на m5.2xlarge инстансе:
Первым подходом к построению ELT-процесса для нас стала простая загрузка данных, выполняющаяся в несколько шагов в одном скрипте по cron'у.
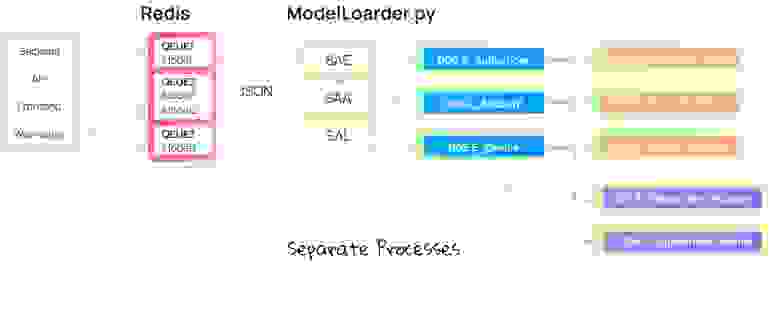
Каждая очередь в Redis вычитывается своим собственным лоадером, запускаемым по расписанию в cron.
Первым этапом на рисунке выше является загрузка данных из очереди Redis в JSON-файл командой

Лоадеры для загрузки данных. Названия лоадеров совпадают с названиями загружаемых очередей.
Псевдокод цикла считывания данных из Redis в JSON:
Вся последующая загрузка данных поделена на этапы:
Из плюсов такого подхода можно выделить:
Конечно, были и минусы:
Весь код наших интеграций был написан быстро и без оглядки на стандарты/практики. Мы запустили MVP, который показывал результат, но работать с ним не всегда было удобно. Именно поэтому мы решились на допиливание и переписывание нашего инструментария.
Главной задачей было, как и всегда, взять все самое лучшее из предыдущей реализации, сделать быстрее и надежнее и ничего не сломать по пути.
Мы произвели декомпозицию всего кода на несколько важных независимых частей.
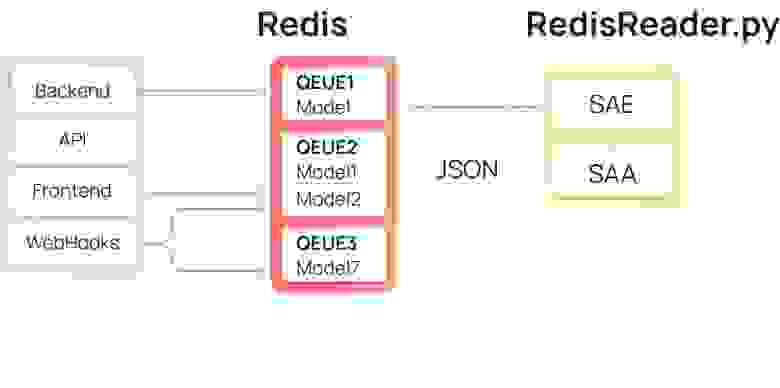
RedisReader — скрипт для непрерывного вычитывания шины Redis. Conf-файл для supervisord создан под каждую очередь и постоянно держит запущенным необходимый ридер.
Пример conf-файла для одной из очередей
Скрипт непрерывно мониторит определенную шину Redis, заданную через аргумент
Полученные данные сперва параллельно загружаются в таблицы
Все действия в RedisReader являются multiprocessing-safe и призваны сделать загрузку наиболее безопасной при одновременном использовании множества процессов для вычитки одной очереди Redis.
Устанавливая параметр
После внедрения RedisReader исчезла проблема с неконтролируемым расходованием памяти Redis. При появлении в очереди, данные практически моментально считываются и складываются в Snowflake-слое SAA по следующим колонкам:
SAA-слой является DataLake в нашей архитектуре. Дальнейшая загрузка данных из него в SAL сопровождается логированием, получением статистики по всем полям и созданием новой SAL-таблицы при необходимости.

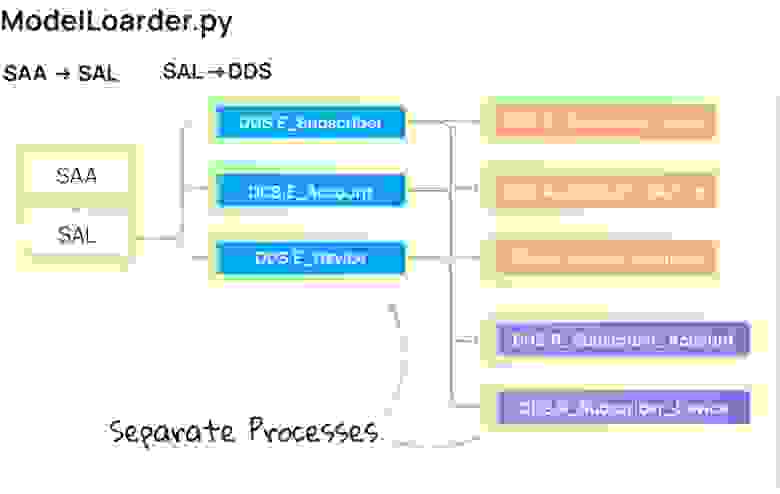
Сборка таблиц для слоя DDS происходит на основе данных из SAL-схемы. Она изменилась меньше всего с момента первой реализации. Мы добавили полезные фичи: выбор типа отслеживания изменений данных (Slowly Changing Dimension) в виде SCD1 / SCD0, а также более быстрые неблокирующие вставки в таблицы.
Данные в каждую таблицу в DDS-слое загружаются отдельным процессом. Это позволяет параллельно работать со множеством таблиц и не тратить время на последовательную обработку данных.
Загрузка в DDS разделена на 2 этапа:
Загрузка сущностей подразумевает загрузку только уникальных значений в таблицы типа
Метод загрузки принимает в качестве атрибутов название сущности, схему исходных данных, а также массив из названия колонки в SAL-таблице и самого названия исходной SAL-таблицы. Внутри происходит либо обычный
Поскольку сущности никак не связаны между собой, можно вполне законно загружать их параллельно друг другу, используя встроенный multiprocessing.
Загрузка отношений и атрибутов реализована похожим образом, единственное отличие – при вставке данных в DDS-схему происходит больше join'ов и проверок данных на актуальность.
Атрибуты:
Отношения:
Отношения и атрибуты не связаны между собой и зависят только от уже загруженных сущностей, поэтому мы без сомнений можем загружать их параллельно друг другу.
Лоадер каждый раз проверяет условия запуска. Если они заданы, и необработанных данных в SAA-слое накопилось больше чем
Сейчас метаданные по каждому лоадеру хранятся в Google Sheet, и у любого инженера есть возможность исправить значение и сгенерировать код лоадера путем простого запуска скрипта в консоли.
RedisReader в свою очередь работает независимо от всей остальной системы, ежесекундно опрашивая очереди в Redis. Загрузка данных SAA ⇒ SAL и далее в DDS тоже может работать абсолютно независимо, но запускается в одном скрипте.
Так мы смогли избавиться от прежних проблем:
Сейчас на постоянной основе мы загружаем данные из 26 очередей в Redis. Как только данные появляются в них, они сразу попадают в SAA-слой и ждут своей очереди на обработку и доведения до DDS. В среднем мы получаем 1400 событий в секунду в диапазоне от 100 до 5000 в зависимости от времени суток и сезонности.
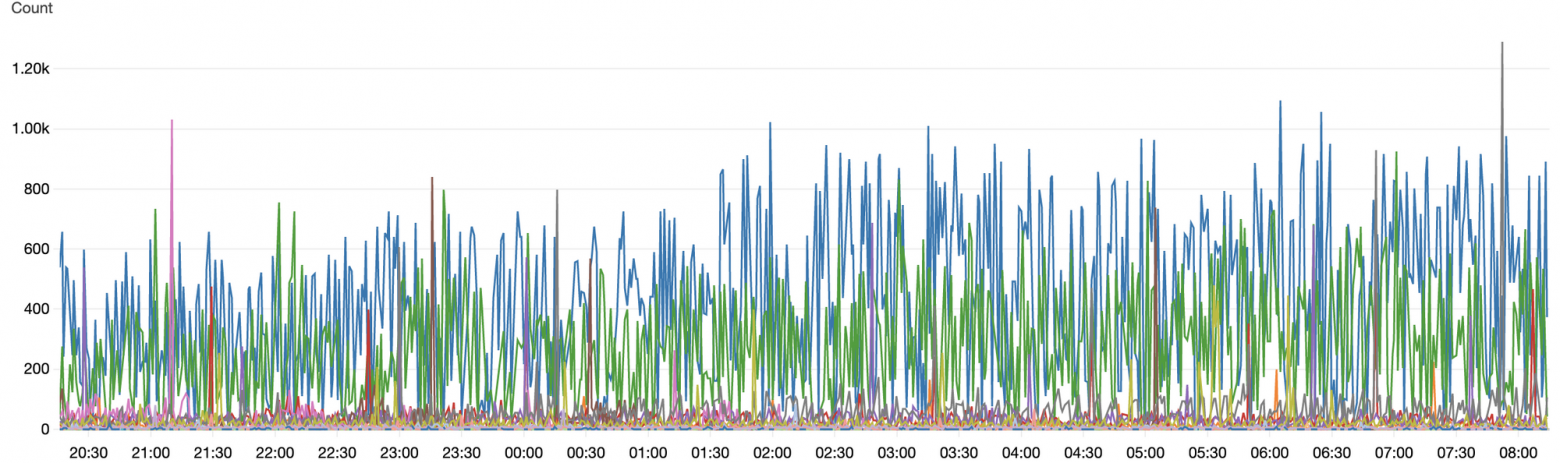
Количество полученных данных. Каждый цвет отвечает за отдельный поток данных.
Сейчас мы занимаемся тюнингом и поиском бутылочных горлышек при загрузке данных в Snowflake. Наш новый пайплайн позволил сократить количество ручной работы инженеров до минимума и наладить процессы разработки и взаимодействия со всей компанией.
При этом было реализовано множество сторонних процессов, например Data Quality, Data Governance и материализация представлений.
Фактически добавление нового лоадера теперь сводится к заполнению полей в Google Sheet и построению модели будущих таблиц в схеме DDS.
Про нюансы работы наших ELT-процессов или аспекты работы со Snowflake спрашивайте меня в комментариях – обязательно отвечу.
С самого начала перед нами встал вопрос о выборе инструментов для работы с БД и построении ELT-процессов. Мы не хотели использовать громоздкие и привычные всем готовые решения вроде Airflow или NiFi и пошли по пути тонкой кастомизации. Это был затяжной прыжок в неизвестность, который пока продолжается и вполне успешно.
Под катом я расскажу про архитектуру нашего аналитического хранилища и покажу, каким образом мы производим загрузку, обработку и трансформацию данных.
Описание данных ManyChat

ManyChat — это платформа для общения компаний с клиентами через мессенджеры. Нашим продуктом пользуется более 1.8 млн бизнесов по всему миру, которые общаются c 1.5 млрд подписчиков.
Моя команда занимается разработкой хранилища и ELT-платформы для сбора и обработки всех доступных данных для последующей аналитики и принятия решений.
Большую часть данных мы получаем из собственного приложения: нажатия пользователями кнопок, попапов, события и изменения моделей бэкэнда (пользователя/подписчика/темплейтов/взаимодействия с нашим апи и десятки других). Также получаем информацию из логов и исторических данных из Postgres-баз.
Некоторые данные мы принимаем от внешних сервисов, взаимодействие с которыми происходит посредством вебхуков. Пока это Intercom и Wistia, но список постепенно пополняется.
Данные для аналитиков
Аналитики ManyChat для своей работы пользуются данными из слоя DDS (Data Distribution Storage / Service), где они хранятся в шестой нормальной форме (6 нф). По сути, аналитики хорошо осведомлены о структуре данных в Snowflake и сами выбирают способы объединения и обработки множеств с помощью SQL.
В своей ежедневной работе аналитики пишут запросы к десяткам таблиц разного размера, на обработку которых у СУБД уходит определенное время. За счет своей архитектуры Snowflake хорошо подходит для аналитики больших данных и работы со сложными SQL запросами. Приведу конкретные цифры:
- Размер больших таблиц — от 6 до 21 миллиарда строк;
- Среднее количество просканированных в одном аналитическом запросе микро-партиций — 1052;
- Отношение количества запросов с использованием SSD к запросам без использования локального диска — 48/52.
В таблице ниже приведена производительность реальных запросов за последний месяц в зависимости от количества используемых в них объектов. Все эти запросы были выполнены на кластере размера S (запросы от ELT-процессов в данных расчетах не участвовали).
Все запросы
| Объектов в запросе | Количество запросов | AVG Время выполнения (сек) | MED Время выполнения (сек) |
|---|---|---|---|
| 1 — 3 | 15149 | 33 | 1.27 |
| 4 — 10 | 3123 | 48 | 8 |
| 11 + | 729 | 188 | 38 |
Запросы, выполняемые быстрее, чем за 1 секунду, вынесены в отдельную группу. Это позволяет разделить запросы, использующие SSD (локальный кэш и сохраненные данные), от тех, которым приходится основную часть данных читать с медленных HDD.
Запросы > 1 сек
| Объектов в запросе | Количество запросов | AVG Время выполнения (сек) | MED Время выполнения (сек) |
|---|---|---|---|
| 1 — 3 | 5747 | 71 | 9 |
| 4 — 10 | 2301 | 61 | 15 |
| 11 + | 659 | 201 | 52 |
Увеличение количества объектов в запросе усложняет его процессинг.
В этом примере анализ запросов производился с помощью поиска названий существующих таблиц в SQL-коде запросов аналитиков. Таким образом мы находим приблизительное количество использованных объектов.
Anchor Model
При раскладке данных в хранилище мы используем классическую якорную модель (Anchor Model). Эта модель позволяет гибко реагировать на изменение уже хранимых или добавление новых данных. Также благодаря ей можно эффективнее сжимать данные и быстрее работать с ними.
Для примера, чтобы добавить новый атрибут к имеющейся сущности, достаточно создать еще одну таблицу и сообщить аналитикам о необходимости делать join'ы на нее.
Подробнее про Anchor Model, сущности, атрибуты и отношения вы можете почитать у Николая Голова aka @azazoth (здесь и здесь).
Немного о Snowflake

Размеры кластеров на примере цветных квадратов с текстом
СУБД выделяет расчетные мощности on-demand, как и во многих других продуктах AWS. Бюджет расходуется только если вы используете предоставленные для расчетов мощности — тарифицируется каждая секунда работы кластера. То есть, при отсутствии запросов, вы тратите деньги только на хранение данных.
Для простых запросов можно использовать самый дешёвый кластер (warehouse). Для ELT-процессов, в зависимости от объема обрабатываемых данных, поднимаем подходящий по размеру кластер: XS / S / M / L / XL / 2XL / 3XL / 4XL – прямо как размеры одежды. После загрузки и / или обработки выключаем его, дабы не тратить деньги. Время выключения кластера можно настраивать: от «тушим сразу, как закончили расчет запроса» до «никогда не выключать».

Выделяемое на каждый размер кластера железо и цена за секунду работы
Подробнее про кластеры Snowflake читайте тут. А так же в последней статье Николая Голова.
В настоящий момент ManyСhat использует 9 различных кластеров:
- 2 X-Small – для ELT процессов с маленькими наборами данных до миллиарда записей.
- 4 Small – для запросов из Tableau и ELT процессов, требующих больших join'ов и тяжелых расчетов, например, заполнение строкового атрибута. Также этот кластер используется для работы аналитиков по умолчанию.
- 1 Medium – для материализации данных (View Materialization).
- 1 Large – для работы с данными больших объемов.
- 1 X-Large – для единоразовой загрузки / правки огромных исторических данных.
Объем наших данных в Snowflake составляет приблизительно 11 Тбайт. Объем данных без сжатия — около 55 Тбайт (фактор сжатия х5).
Особенности Snowflake
Архитектура
Все кластеры в системе работают изолированно. Архитектура решения Snowflake представляется тремя слоями:
- Слой хранилища данных
- Слой обработки запросов
- Сервисный слой аутентификации, метаданных и др.

Иллюстрация архитектуры Snowflake
Snowflake работает с «горячими» и «холодными» данными. «Холодными» считаются данные, лежащие в S3 на обычных HDD (Remote Disk). При запросе они дольше считываются и загружаются в быстрые SSD отдельно для каждого кластера. Пока кластер работает, данные доступны на локальном SSD (Local Disk), что ускоряет запросы в несколько раз по сравнению с работой на «холодную».

Помимо этого, существует общий для всех кластеров кэш результата запроса (Result Cache) за последние 24 часа. Если данные за это время не изменились, при повторном запуске одного и того же запроса на любом из кластеров они не будут считаны повторно. Подробнее можно почитать тут.
Микро-партиции
Одной из интересных фичей Snowflake является работа с динамическими микро-партициями. Обычно в базах данных используются статические, но в ряде случаев, например, при перекосе данных (data skew), данные между партициями распределяются неравномерно что усложняет / замедляет обработку запросов.
В Snowflake все таблицы хранятся в очень маленьких партициях, содержащих от 50 до 500 Мбайт данных без сжатия. СУБД хранит в метаданных информацию обо всех строках в каждой микро-партиции, включая:
- диапазон значений каждой колонки партиции;
- количество уникальных (distinct) значений;
- дополнительные параметры.
Такой подход позволяет работать с невероятно большими таблицами, содержащими миллионы и сотни миллионов микро-партиций. Благодаря этому, запросы взаимодействуют только с теми данными, которые удовлетворяют условиям. Подробности и нюансы партиционирования данных в Snowflake можно изучить тут.
ELT Pipelines
Потоки данных и слои их хранения и обработки в ManyChat выглядят примерно так:

Данные поступают в DWH из нескольких источников:
- PHP-бэкенд – события и изменения моделей данных;
- Внешние API – Intercom, Wistia, FaceBook и другие;
- ManyChat Frontend – события с фронтенда;
- WebHooks – сервисы, отдающие данные через вебхуки.
Давайте рассмотрим, как устроена эта схема, на примере события из бэкенда:
- PHP-бэкенд отправляет событие о создании нового аккаунта в ManyChat.
- Redis принимает данные и складывает в очередь.
- Отдельный python-процесс вычитывает эту очередь и сохраняет данные во временный JSON, загружая его в последующем в Snowflake.
- В Snowflake, с помощью python-ELT-процессов, мы прогоняем данные по всем необходимым слоям и, в итоге, раскладываем в Анкор-Модель.
- Аналитики используют DDS и SNP-слои с данными для сборки агрегированных витрин данных в слой DMA.
Аббревиатуры слоёв SA* расшифровываются как Staging Area for (Archive/Loading/Extract)
- SNP – слой для хранения агрегированных исторических данных из бэкэнд баз данных.
- SAE – слой для хранения сырых данных из Redis в виде одной колонки типа variant.
- SAA – слой для хранения обогащенных данных из Redis с добавлением служебных колонок с датами и id загрузки.
- SAL – более детальный слой данных с типизированными колонками. Таблицы в нем хранят только актуальные данные, при каждом запуске скрипта загрузки производится
truncate table. - DDS – 6 нф для хранения данных в виде «1 колонка SAL ⇒ 1 таблица DDS».
- DMA – аналитический слой, в котором хранятся вьюхи, материализации и исследования аналитиков на базе DDS.
Статистика по объектам в схемах
| Схема | Количество объектов | Количество представлений | AVG строк (млн) | AVG объём GB |
|---|---|---|---|---|
| SNP | 3337 | 2 | 2 | 0.2 |
| SAA | 52 | 2 | 590 | 60 |
| SAL | 124 | 121 | 25 | 2.2 |
| DDS | 954 | 6 | 164 | 2.5 |
| DMA | 57 | 290 | 746 | 15 |
Используя 6 нф, DDS позволяет хранить достаточно большие объемы данных очень компактно. Все связи между сущностями осуществляются через целочисленные суррогатные ключи, которые отлично жмутся и очень быстро обрабатываются даже самым слабым XS-кластером.
SAA занимает более 80% объема хранилища из-за неструктурированных данных типа variant (сырой JSON). Раз в месяц SAA-слой скидывает данные в историческую схему.
В настоящий момент мы храним более 11 Тбайт данных в Snowflake с фактором сжатия х5, ежедневно получая сотни миллионов новых строк. Но это только начало пути, и мы планируем увеличивать количество источников, а значит и поступающих данных кратно год к году.
Redis
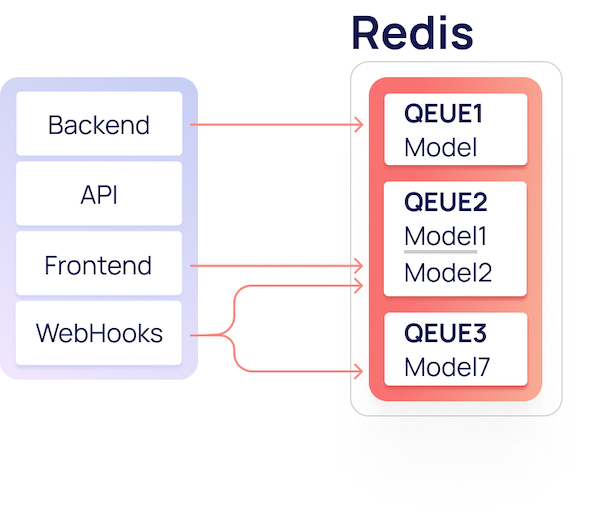
В ManyChat активно используется Redis, и наш проект не стал исключением: он является шиной для обмена данными. Для быстрого и безболезненного старта в качестве языка написания ELT-движка был выбран python, а для хранения логов и статистики — Postgres. Redis выступает в нашей архитектуре местом для временного хранения поступающей информации от всех источников. Данные в Redis хранятся в виде списка (List) JSON'ов.
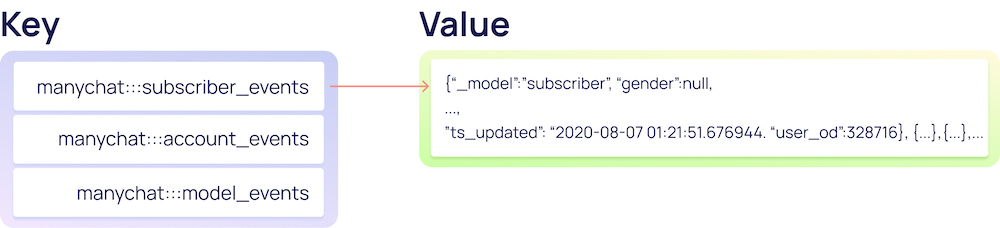
Структура хранения данных в Redis
В каждом списке могут находится от 1 до N разнообразных моделей данных. Модели объединяются в списки методом дедукции. Например, все клики пользователей в независимости от источника кладутся в один список, но могут иметь разные модели данных (список полей).
Ключами для списков в Redis являются придуманные названия, которые описывают находящиеся в нем модели.
Пример некоторых названий списков и моделей в нем:
- EmailEvent (события происходящие с почтой)
- email_package_reduce
- SubscriberEvent (при создании или изменении подписчика, он появляется в этой очереди)
- subscriber
- ModelEvent (модели данных из бэкэнда и их события)
- account_user
- pro_subscription
- wallet_top_up
- И еще 100500 разных моделей
- StaticDictionaries
- Статичные словари из бэкенда. Информация о добавлении или изменении элемента словаря.
Весь ELT построен на python и использовании multiprocessing. Железо для всего ELT в ManyChat работает в AWS на m5.2xlarge инстансе:
- 32 Гбайт RAM
- Xeon® Platinum 8175M CPU @ 2.50GHz
Первый подход
Первым подходом к построению ELT-процесса для нас стала простая загрузка данных, выполняющаяся в несколько шагов в одном скрипте по cron'у.
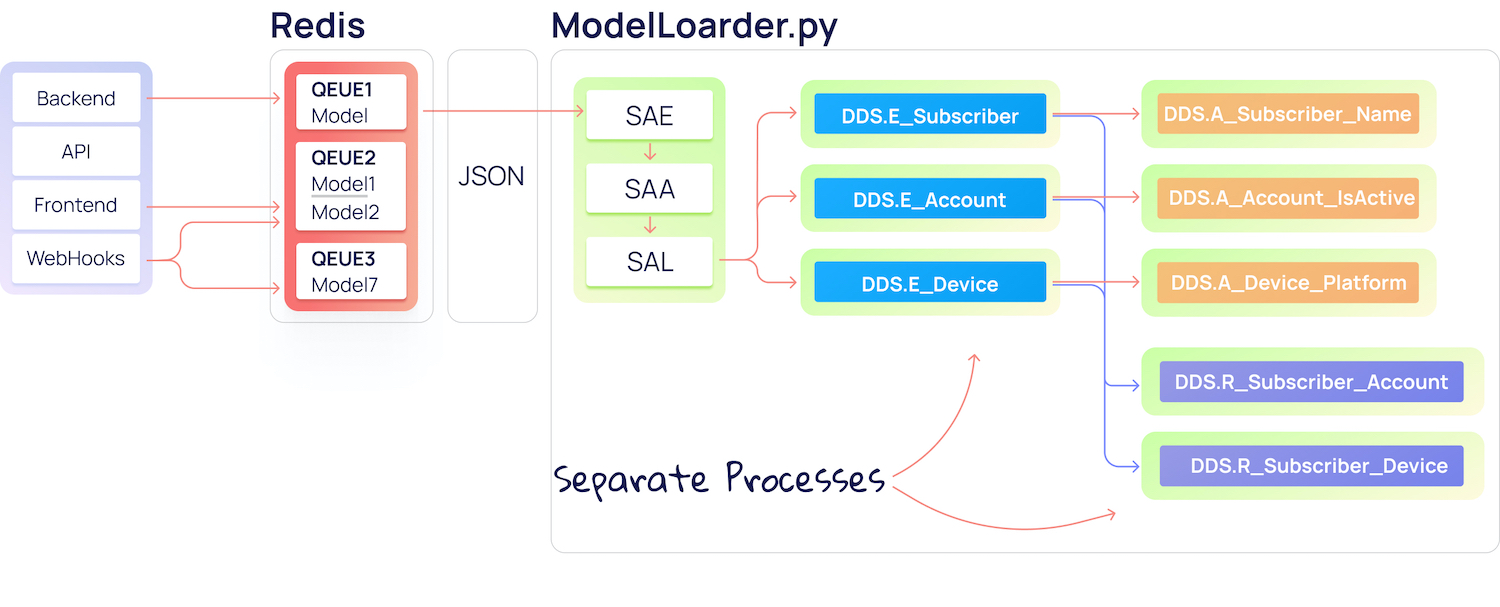
Каждая очередь в Redis вычитывается своим собственным лоадером, запускаемым по расписанию в cron.
Первым этапом на рисунке выше является загрузка данных из очереди Redis в JSON-файл командой
lpop(). Они вычитываются поэлементно из Redis, из каждой строки (словаря из JSON) снимается статистика по наполнению элементов словаря и затем записывается в Postgres. В этом же цикле данные записываются построчно в JSON-файл.
Лоадеры для загрузки данных. Названия лоадеров совпадают с названиями загружаемых очередей.
Псевдокод цикла считывания данных из Redis в JSON:
batch_size = 1000000 # Количество элементов для считывания из очереди Redis
with open(json_file) as f:
while batch_size > 0:
row = redis.lpop('Model')
save_statistics(row)
batch_size -= 1
f.write(row)
Вся последующая загрузка данных поделена на этапы:
- Загрузка из JSON в SAE-слой;
- Обогащение и загрузка из SAE в SAA;
- Загрузка из SAA в заранее созданную структурированную таблицу в SAL-схеме;
- Загрузка данных из SAL в DDS схему.
Из плюсов такого подхода можно выделить:
- Скорость адаптации. На внедрение нового сотрудника в пайплайн и процессы уходит 1 день.
- Скорость реализации. Python позволяет делать практически что угодно с очень низким порогом входа.
- Простота. При неисправности легко починить или запустить код руками.
- Стоимость. Вся инфраструктура создана на уже существующих мощностях, из нового – только Snowflake.
Конечно, были и минусы:
- Определенные сложности с масштабированием. Если лоадер был настроен на считывание 1кк записей из Redis раз в 10 минут, а в очередь прилетело, например, 5кк событий, они считывались 50 минут. Бывали случаи, когда очередь не пустела в течении суток.
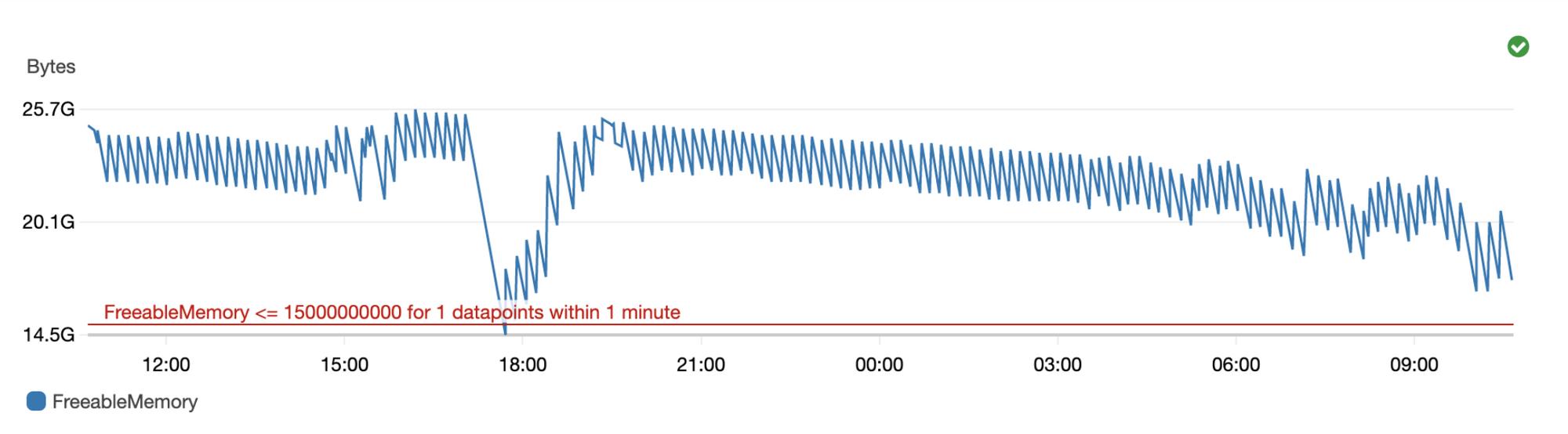
Такие ситуации происходили крайне редко. Зная среднюю нагрузку наших сервисов, мы заранее выставляли более высокое ограничение на объем вычитываемых событий. А в случае внезапных увеличений объемов данных, производили загрузку «руками» с использованием более быстрого кластера и увеличенного количества вычитываемых объектов. - При любом вынужденном простое, тесте ELT-процессов или исправлении ошибок, мы останавливали загрузку из одной или нескольких очередей. Redis начинал наполняться бесконтрольно, и у нас могло закончиться место (30 Гбайт), что приводило к потере новых данных.
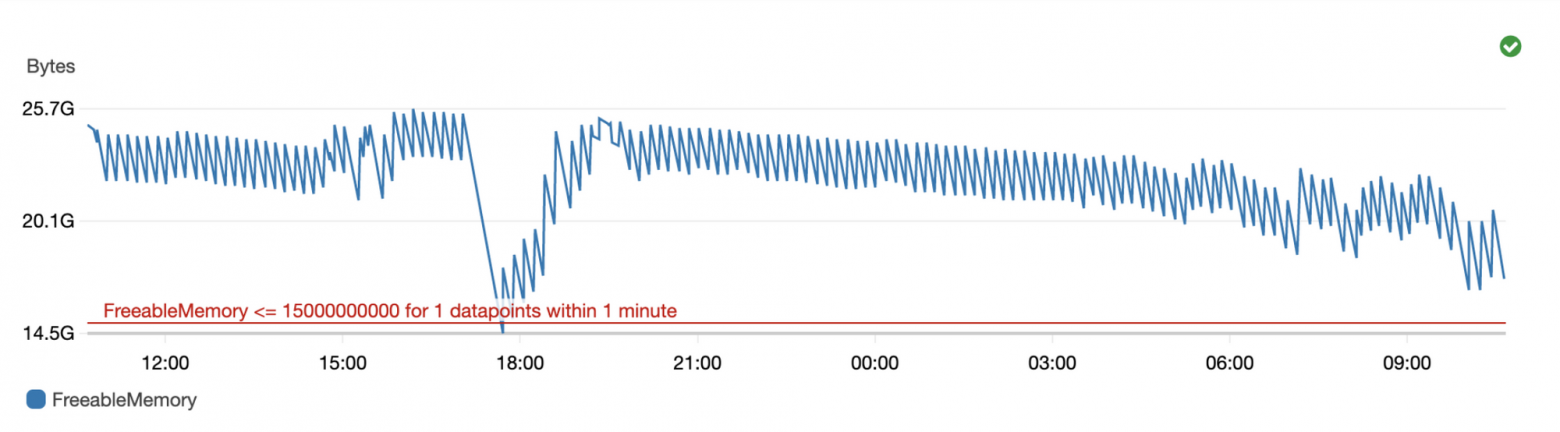
Остановка загрузки одной из очередей в Redis могла привести к расходованию всей памяти и невозможности принимать данные - Скрипт загрузки данных (Loader) содержал полный цикл от Redis до DDS, и в случае поломки его приходилось запускать заново. Если ошибка произошла где-то посередине, например, потерялся только что записанный JSON-файл, восстановить его было проблематично. Помочь могла только infra-команда и выгрузка исторических данных за определенные даты к нам в шину. В других случаях инженерам приходилось комментировать код и запускать определенную часть скрипта вручную, контролируя загрузку данных.
Второй подход
Весь код наших интеграций был написан быстро и без оглядки на стандарты/практики. Мы запустили MVP, который показывал результат, но работать с ним не всегда было удобно. Именно поэтому мы решились на допиливание и переписывание нашего инструментария.
Главной задачей было, как и всегда, взять все самое лучшее из предыдущей реализации, сделать быстрее и надежнее и ничего не сломать по пути.
Мы произвели декомпозицию всего кода на несколько важных независимых частей.
- Чтение данных из Redis. Загрузка данных из Redis должна быть максимально глупой: код выполняет только одну функцию, не затрагивая остальные компоненты системы.
- Трансформация данных внутри Snowflake. Подразумевает загрузку данных из слоя SAA в SAL со сбором статистики, ведением истории загрузок и информированием в Slack о появлении новых моделей и / или полей в моделях.
- Сборка DDS. Множество параллельно работающих процессов, загружающих данные.
Чтение данных из Redis
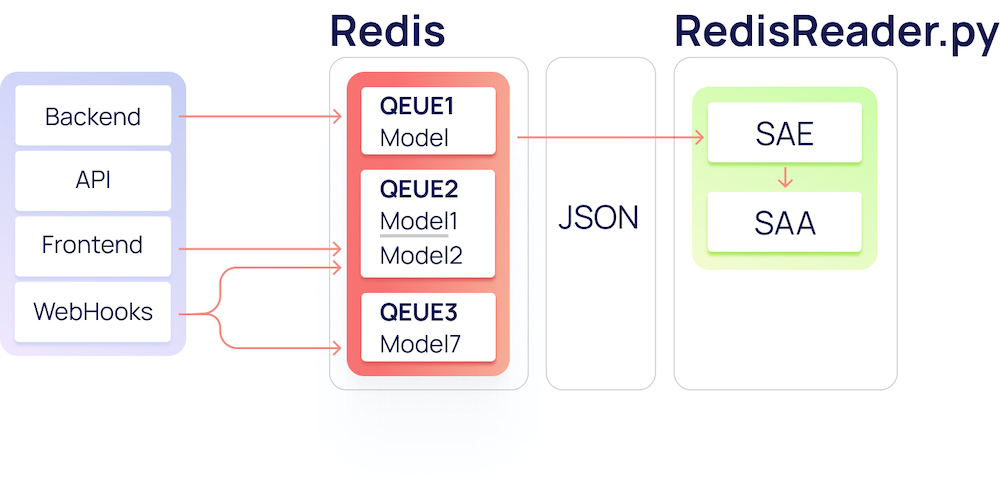
RedisReader — скрипт для непрерывного вычитывания шины Redis. Conf-файл для supervisord создан под каждую очередь и постоянно держит запущенным необходимый ридер.
Пример conf-файла для одной из очередей
email_event:[program:model_event_reader]
command=/usr/bin/env python3 $DIRECTORY/RedisReader.py --queue='manychat:::model_event' --chunk_size=500000
autostart=true
autorestart=true
stopsignal=TERM
stopwaitsecs=1800
process_name=%(program_name)s_%(process_num)d
numprocs=4
Скрипт непрерывно мониторит определенную шину Redis, заданную через аргумент
--queue на появление новых данных. Если данные в шине отсутствуют, он ждет RedisReader.IDLE_TIME секунд и повторно пробует прочитать данные. Если данные появились, скрипт считывает их через lpop() и складывает в файл вида /tmp/{queue_name}_pipe_{launch_id}_{chunk_launch_id}.json, где launch_id и chunk_launch_id – сгенерированные уникальные int'ы. Когда количество строк в файле достигает уровня --chunk_size или заданное время --chunk_timeout истекло, RedisReader завершает запись файла и начинает его загрузку в Snowflake. Полученные данные сперва параллельно загружаются в таблицы
SAE.{queue_name}_pipe_{launch_id}_{chunk_launch_id}, а затем в одном процессе вставляются простым insert'ом в таблицу SAA.{queue_name}_pipe не блокируя работу с уже существующими данными.Все действия в RedisReader являются multiprocessing-safe и призваны сделать загрузку наиболее безопасной при одновременном использовании множества процессов для вычитки одной очереди Redis.
Устанавливая параметр
numprocs, мы можем запускать столько RedisReader'ов, сколько требуется для своевременного вычитывания очереди.После внедрения RedisReader исчезла проблема с неконтролируемым расходованием памяти Redis. При появлении в очереди, данные практически моментально считываются и складываются в Snowflake-слое SAA по следующим колонкам:
- model – название загружаемой модели данных
- event_dt – дата заливки данных
- raw – сами данные в JSON формате (variant)
- launch_id – внутренний сгенерированный номер загрузки
Трансформация данных внутри Snowflake
SAA-слой является DataLake в нашей архитектуре. Дальнейшая загрузка данных из него в SAL сопровождается логированием, получением статистики по всем полям и созданием новой SAL-таблицы при необходимости.
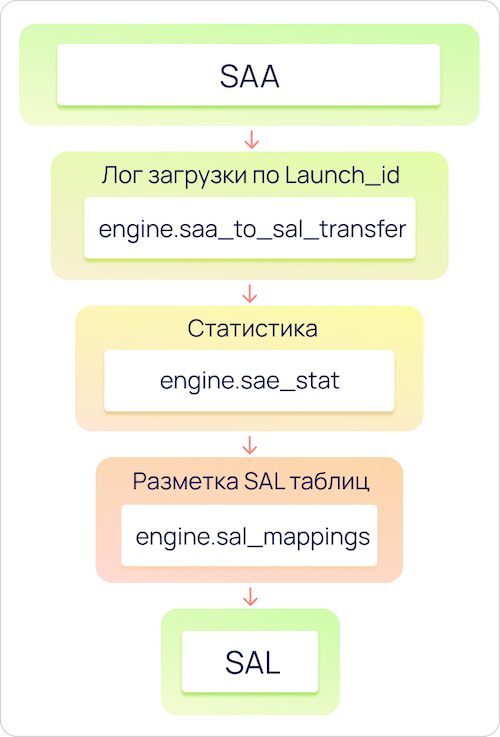
- На первом этапе необходимо получить список еще не обработанных
launch_id. Для этого была создана специальная таблицаengine.saa_to_sal_transfer, в которой хранится launch_id, статус его обработки is_done и прочая служебная информация. Задача скрипта – взять то количество необработанных строчек по каждой модели, которое указано в параметрах загрузчика либо немного меньше. - После этого по каждой модели собирается статистика. Мы храним данные о min / max значениях в колонке, типе данных, количестве ненулевых записей и множестве других вспомогательных характеристик. Сбор статистики является необязательным, для некоторых лоадеров, меняющихся крайне редко, сбор статистики отключен. При появлении новых полей (колонок) в статистике, инженеры увидят сообщение в Slack и приступят к созданию сущностей DDS для последующей загрузки.

Часть таблицы статистики - Далее происходит загрузка данных из слоя SAA в SAL. В SAL попадают только размеченные инженерами данные с описанием поля, правильным типом и названием, которые берутся из таблицы
engine.sal_mapping - Завершающий шаг трансформации – UPDATE в
engine.saa_to_sal_transferдля проставления статуса is_done, если загрузка в SAL прошла успешно.

Сборка DDS
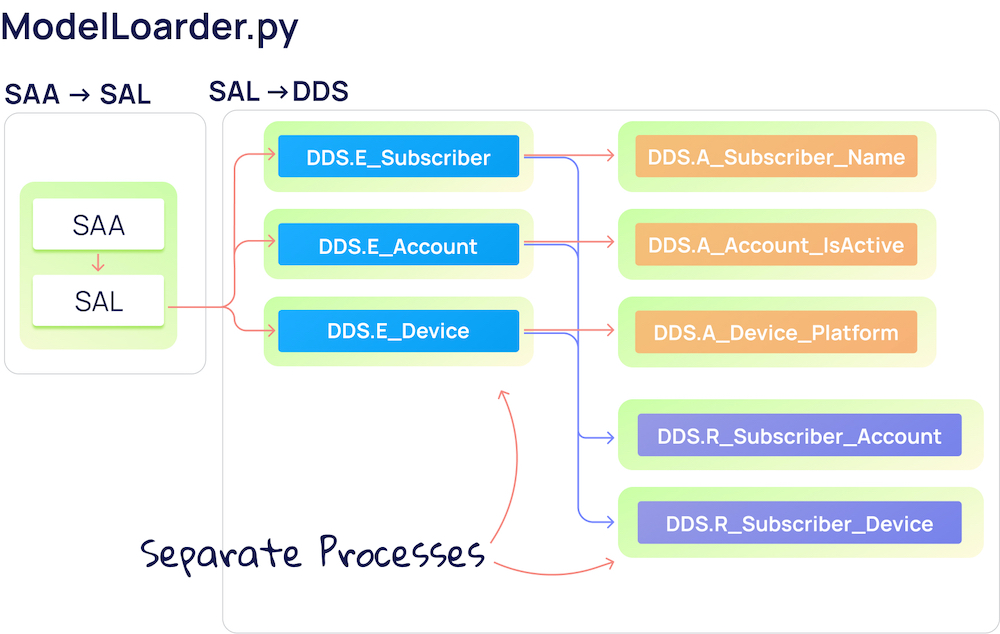
Сборка таблиц для слоя DDS происходит на основе данных из SAL-схемы. Она изменилась меньше всего с момента первой реализации. Мы добавили полезные фичи: выбор типа отслеживания изменений данных (Slowly Changing Dimension) в виде SCD1 / SCD0, а также более быстрые неблокирующие вставки в таблицы.
Данные в каждую таблицу в DDS-слое загружаются отдельным процессом. Это позволяет параллельно работать со множеством таблиц и не тратить время на последовательную обработку данных.
Загрузка в DDS разделена на 2 этапа:
- Сначала грузятся сущности для формирования суррогатного ключа;
- Затем загружаются атрибуты и отношения.
Загрузка сущностей
Загрузка сущностей подразумевает загрузку только уникальных значений в таблицы типа
DDS.E_{EntityName}, где EntityName – название загружаемой сущности.self.entity_loader(entity_name: str, source_schema: str, id_source_table_list: list),Метод загрузки принимает в качестве атрибутов название сущности, схему исходных данных, а также массив из названия колонки в SAL-таблице и самого названия исходной SAL-таблицы. Внутри происходит либо обычный
MERGE INTO, либо INSERT FIRST.Поскольку сущности никак не связаны между собой, можно вполне законно загружать их параллельно друг другу, используя встроенный multiprocessing.
Загрузка Отношений и Атрибутов
Загрузка отношений и атрибутов реализована похожим образом, единственное отличие – при вставке данных в DDS-схему происходит больше join'ов и проверок данных на актуальность.
Атрибуты:
self.attribute_loader(entity: str, attribute: str, source_table: str, id_column: str, value_column: str, historicity: str)Отношения:
self.relation_loader(left_entity: str, right_entity: str, source_table: str, left_id: str, right_id: str, historicity: str)Отношения и атрибуты не связаны между собой и зависят только от уже загруженных сущностей, поэтому мы без сомнений можем загружать их параллельно друг другу.
Псевдокод одного из лоадеров
from Loaders.SnowflakeLoaders import SnowflakeLoader
class ModelEventLoader(SnowflakeLoader):
DEFAULT_SOURCE_TABLE = 'saa.model_pipe'
DEFAULT_BATCH_STAT_SAMPLE_PERCENT = 50
DEFAULT_BATCH_SIZE = 1000000
DEFAULT_BUS_FULFILMENT_THRESHOLD = 100000
DEFAULT_HOURS_PASSED_THRESHOLD = 1.0
def sal_to_dds(self):
loaders = [
self.entity_loader('Account', 'sal', ['page_id', 'rb_model_event']),
self.entity_loader('Subscriber', 'sal', ['subscriber_id', 'rb_model_event']),
self.entity_loader('Device', 'sal', ['device_id', 'rb_model_event']),
]
self.run_loaders(loaders)
loaders = [
self.attribute_loader('Account', 'IsActive', 'sal.rb_model_event', 'page_id', 'is_active', historicity='scd1'),
self.attribute_loader('Subscriber', 'Name', 'sal.rb_model_event', 'subscriber_id', 'name', historicity='scd1'),
self.attribute_loader('Device', 'Platform', 'sal.rb_model_event', 'device_id', 'platform', historicity='scd0'),
self.relation_loader('Subscriber', 'Account', 'sal.rb_model_event', 'subscriber_id', 'account_id', historicity='scd1'),
self.relation_loader('Subscriber', 'Device', 'sal.rb_model_event', 'subscriber_id', 'device_id', historicity='scd0'),
]
self.run_loaders(loaders)
def run(self):
self.truncate_sal('rb_model_event')
self.saa_to_sal()
self.run_sal_to_dds()
if __name__ == '__main__':
ModelEventLoader().do_ELT()Лоадер каждый раз проверяет условия запуска. Если они заданы, и необработанных данных в SAA-слое накопилось больше чем
DEFAULT_BUS_FULFILMENT_THRESHOLD или после последнего запуска прошло больше чем DEFAULT_HOURS_PASSED_THRESHOLD часа, то будет взято не более DEFAULT_BATCH_SIZE строк из SAA-таблицы DEFAULT_SOURCE_TABLE, а также собрано статистики по DEFAULT_BATCH_STAT_SAMPLE_PERCENT процентам данных.Сейчас метаданные по каждому лоадеру хранятся в Google Sheet, и у любого инженера есть возможность исправить значение и сгенерировать код лоадера путем простого запуска скрипта в консоли.
RedisReader в свою очередь работает независимо от всей остальной системы, ежесекундно опрашивая очереди в Redis. Загрузка данных SAA ⇒ SAL и далее в DDS тоже может работать абсолютно независимо, но запускается в одном скрипте.
Так мы смогли избавиться от прежних проблем:
- Затирание JSON файла с данными.
- Переполнение памяти Redis при остановке лоадеров (теперь можно останавливать на сколько угодно, данные уже будут в Snowflake в SAA-слое).
- Ручное комментирование кода и запуск скриптов загрузки.
Сейчас на постоянной основе мы загружаем данные из 26 очередей в Redis. Как только данные появляются в них, они сразу попадают в SAA-слой и ждут своей очереди на обработку и доведения до DDS. В среднем мы получаем 1400 событий в секунду в диапазоне от 100 до 5000 в зависимости от времени суток и сезонности.
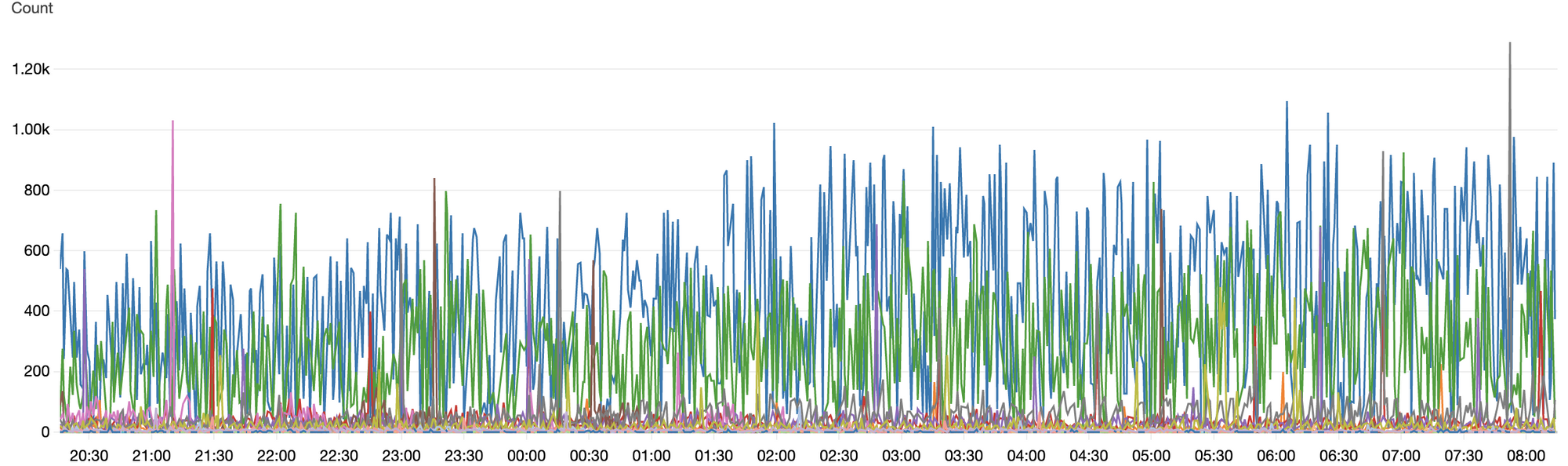
Количество полученных данных. Каждый цвет отвечает за отдельный поток данных.
Заключение
Сейчас мы занимаемся тюнингом и поиском бутылочных горлышек при загрузке данных в Snowflake. Наш новый пайплайн позволил сократить количество ручной работы инженеров до минимума и наладить процессы разработки и взаимодействия со всей компанией.
При этом было реализовано множество сторонних процессов, например Data Quality, Data Governance и материализация представлений.
Фактически добавление нового лоадера теперь сводится к заполнению полей в Google Sheet и построению модели будущих таблиц в схеме DDS.
Про нюансы работы наших ELT-процессов или аспекты работы со Snowflake спрашивайте меня в комментариях – обязательно отвечу.
