Привет! Меня зовут Роман Иваницкий, я работаю в команде автоматизации тестирования Одноклассников. OK — огромный сервис с более чем 70 миллионами пользователей. Если говорить про мобильные устройства, то большинство пользуется OK.RU на смартфонах под управлением Android. По этой причине мы очень серьёзно относимся к тестированию нашего Android-приложения. В этой статье я расскажу историю развития автоматизированного тестирования у нас в компании.
2012 год, «Одноклассники», компания переживает активный рост числа пользователей и увеличение количества пользовательских фич. Для того, чтобы удовлетворять задачам бизнеса, нужно было сокращать релизный цикл, но это было затруднено тем, что все функциональности тестировались вручную. Решение этой проблемы пришло само собой – нужна автотесты. Таким образом, в 2012 году в «Одноклассниках» появилась команда автоматизации тестирования, и первым шагом было – начать писать тесты.
Немного истории
Первые автотесты в Одноклассниках были написаны на Selenium, для их запуска подняли Jenkins, Selenium Grid с Selenium Hub и набором Selenium Node.
Быстрое решение, быстрый старт, быстрый профит – идеально.
Со временем количество тестов увеличивалось, а также появлялись вспомогательные сервисы – например, сервисы запусков, сервис отчетов, сервис тестовых данных. К концу 2014 года у нас была тысяча тестов, которые пробегали примерно за пятнадцать-двадцать минут. Это нас не устраивало, так как было понятно, что количество тестов будет расти, а вместе с этим будет увеличиваться и время, затрачиваемое на их прогон.
В то время инфраструктура автоматизированного тестирования выглядела так:
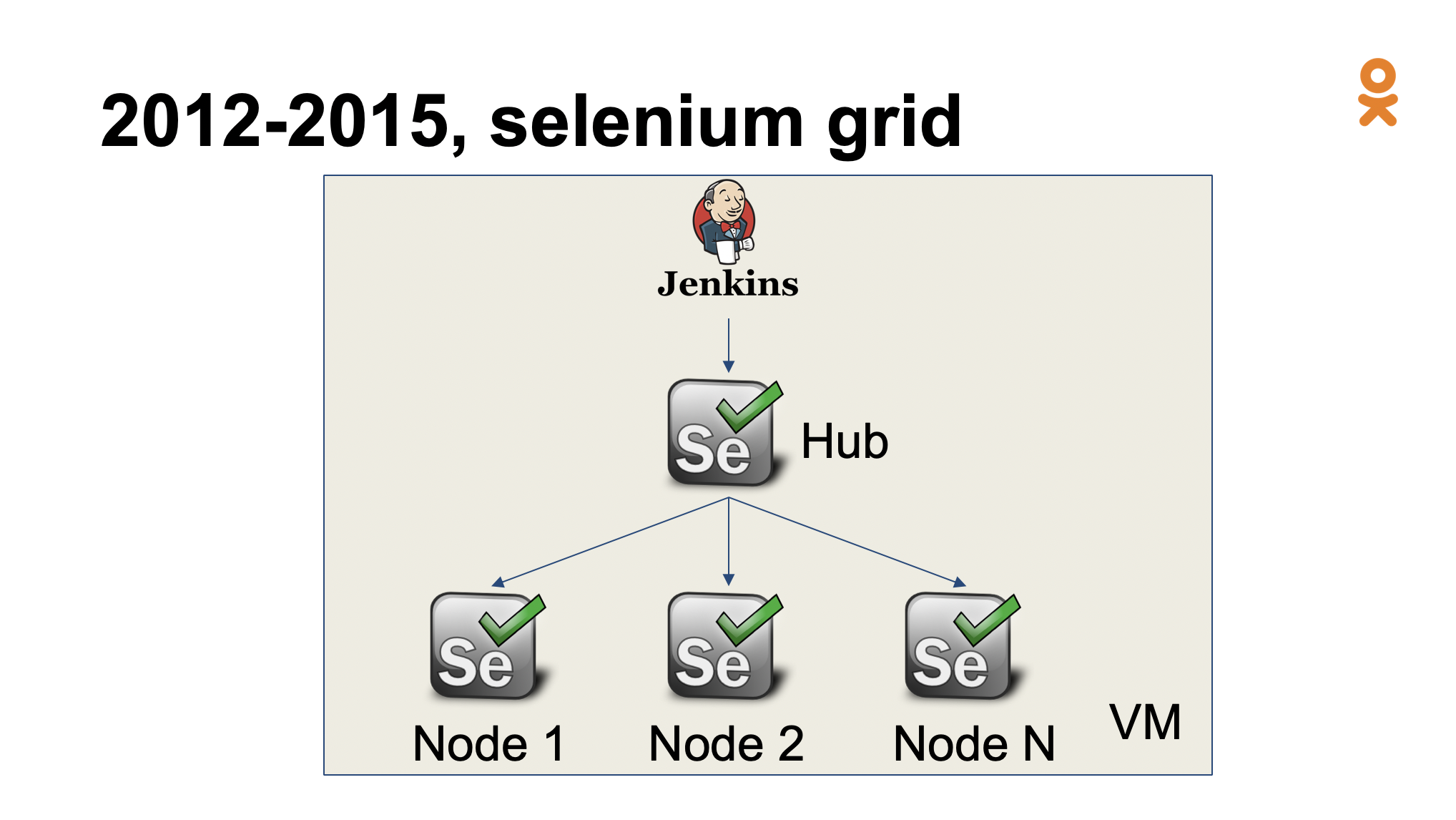
Однако, при количестве Selenium Node большем или равном 200, Hub не справлялся с нагрузкой. Сейчас эта проблема уже изучена, и именно поэтому появились такие инструменты как Zalenium или всеми любимый Selenoid. Но в 2014 не было какого-то стандартного решения, поэтому мы решили сделать свое.
Определили минимальные требования, которым должен отвечать сервис:
- Масштабируемость. Мы не хотим зависеть от ограничений Selenium Hub.
- Стабильность. В 2014 Selenium Hub не славился стабильной работой.
- Отказоустойчивость. Нам необходима возможность продолжать процесс тестирования в случае отказа дата-центра или любого из серверов.
Таким образом появилось наше решение для масштабирования Selenium Grid, состоящее из координатора и Node-менеджеров, внешне очень похожее на стандартный Selenium Grid, но со своими особенностями. Об этих особенностях дальше и пойдет речь.
Координатор

По сути, это брокер ресурсов (под ресурсами понимаются браузеры). Он имеет внешний API, через который тесты отправляют запросы на предоставление ресурсов. Эти запросы сохраняются в базу данных как задачи для запуска. Координатор знает всё о конфигурации нашего кластера – какие Node-менеджеры существуют, какие типы ресурсов эти Node-менеджеры могут предоставлять, общее количество ресурсов, сколько ресурсов сейчас задействовано задачами. При этом он осуществляет мониторинг ресурсов – активность, стабильность, и в случае чего уведомляет ответственных.
Особенностью координатора является то, что он объединяет все Node-менеджеры в так называемые фермы.
Вот так выглядит ферма. Больше половины ресурсов используется, и все ноды онлайн:
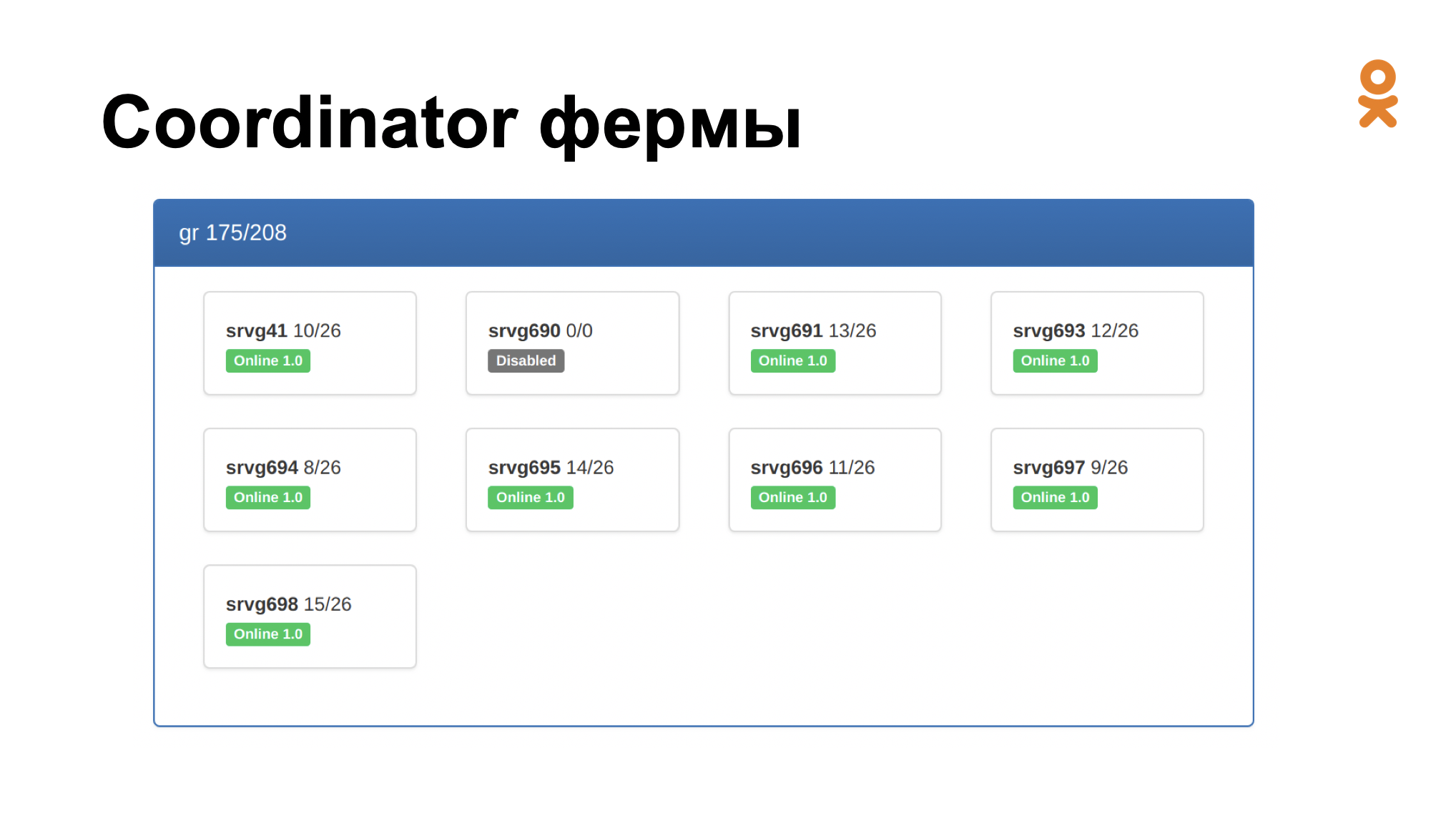
Также можно выводить ноды в офлайн или вводить их в ротацию на определенный процент, это требуется, если возникает необходимость снизить нагрузку на конкретную ноду.
Каждая ферма может быть объединена с другими в логическую единицу, которую мы называем сервисом. При этом одна ферма может быть включена в несколько разных сервисов. Во-первых, это даёт возможность установки ограничений и приоритизации ресурсов, используемых каждым конкретным сервисом. Во-вторых, это позволяет легко управлять конфигурацией – у нас есть возможность добавлять количество Node-менеджеров в сервисе на лету, или наоборот выводить их из фермы, чтобы иметь возможность взаимодействовать с этими Node-менеджерами, например, настраивать или обновлять и т.п.

API у координатора довольно простой: есть возможность запросить у сервиса текущее количество используемых ресурсов, получить его лимит и запустить или остановить какой-то ресурс.
Node-менеджер
Это сервис, который умеет делать хорошо две вещи – получать от координатора задачи и запускать по требованию некоторые ресурсы. По умолчанию он устроен так, что каждый запуск ресурса изолирован, то есть ни один из предыдущих запусков не может повлиять на запуск последующих тестов. В качестве ответа координатору используется связка хоста и набора поднятых портов. Например, хост, на котором запустился Selenium-сервер, и его порт.
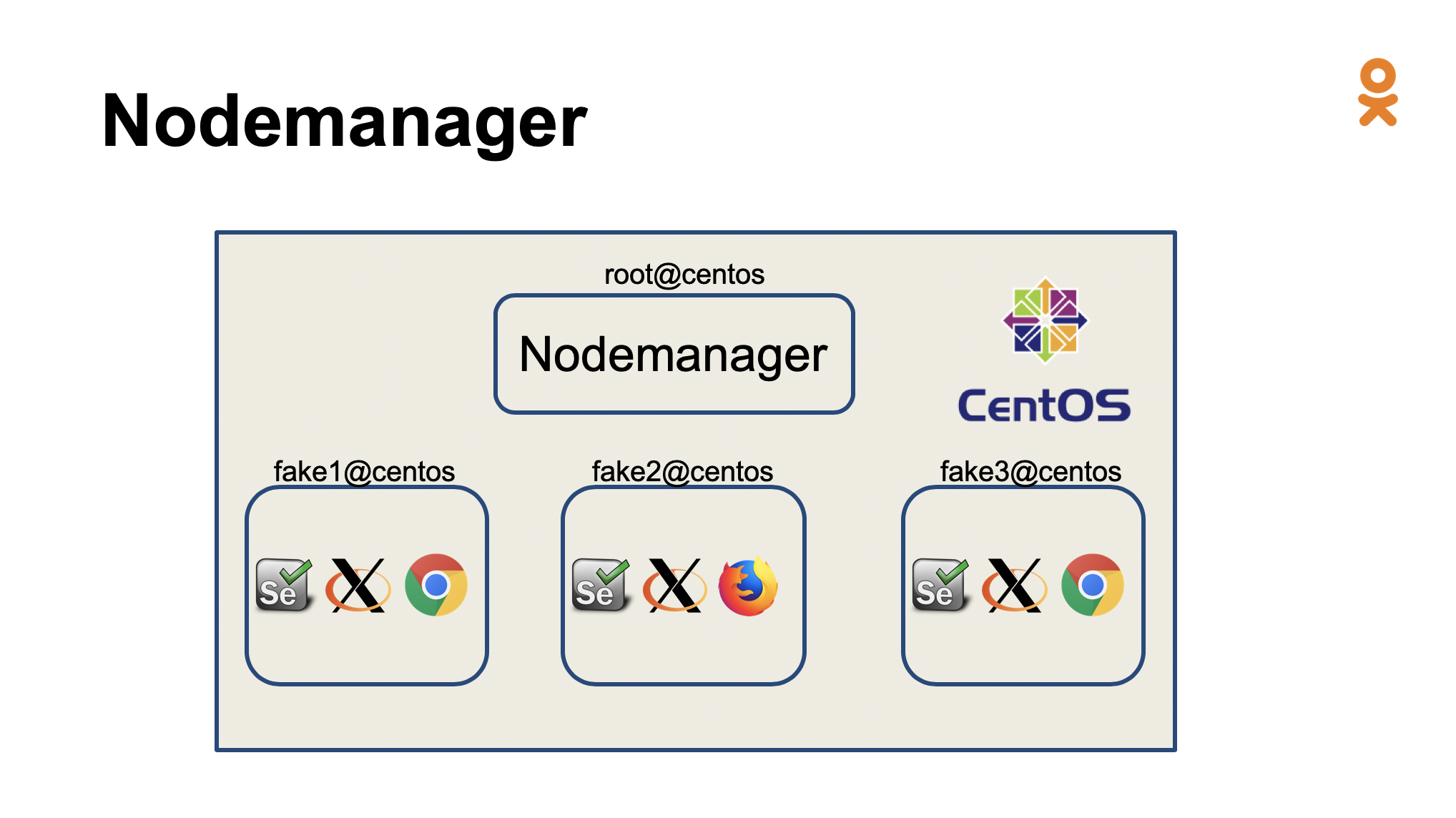
На хосте это выглядит так: запущен сервис Node-менеджер, и он управляет всем жизненным циклом ресурсов. Он поднимает браузеры, завершает их, смотрит за тем, чтобы их не забыли закрыть. Для гарантии изолированности друг от друга все это происходит от лица служебного пользователя.
Взаимодействие
Тест взаимодействует с описанной выше инфраструктурой следующим образом: он обращается к координатору с запросом на нужные ресурсы, координатор сохраняет эту задачу как требующую исполнения.
Node-менеджер, в свою очередь, обращается к координатору за задачами. Получив задачу, он осуществляет запуск ресурса. После этого он отправляет результат запуска в координатор, неудачные запуски тоже рапортуются в координатор. Тест получает результат запроса ресурса и в случае успеха начинает работать с ресурсом напрямую.

Плюсы такого подхода заключаются в снижении нагрузки на координатор с помощью получения возможности работы с ресурсом напрямую. Минусы — в необходимости реализации логики взаимодействия с координатором внутри тестовых фреймворков, но для нас это приемлемо.
На сегодняшний день мы можем запустить более 800 браузеров параллельно в трех дата-центрах. Для координатора это не предел.
Отказоустойчивость обеспечивается запуском нескольких заведенных за DNS-фейловер инстансов координатора в разных дата-центрах. Таким образом гарантируется доступ к рабочему инстансу в случае проблемы с дата-центром или сервером.
В итоге у нас получилось решение, которое отвечало всем поставленным изначально требованиям. Оно стабильно работает с 2015 года и доказало свою эффективность.
Android
Когда речь заходит о тестировании на Android, то обычно выделяют два основных подхода. Первый заключается в использовании WebDriver – так работают Selendroid и Appium. Второй – в работе с нативными инструментами, таким образом реализованы Robotium, UI Automator или Espresso.
Принципиальные сходства этих подходов заключаются в получении устройства и получении браузера.
Отличий же гораздо больше, основные из них это необходимость установки тестируемой APK, с помощью которой мы будем забирать артефакты в виде логов, скриншотов и т.п. а также, то что тестирование осуществляется на самом устройстве, а не на CI.
В 2015 году Одноклассники начали покрывать своё Android-приложение автотестами. Мы выделили одну Linux-машину, подключили по USB одно реальное устройство и начали писать тесты на Robotium. Это простое решение позволило быстро получить результаты.
Время шло, росло количество тестов и количество устройств. Для решения задач управления был создан Device Manager – обертка над adb (Android Debug Bridge) командами, которая позволяет http api интерфейс к их выполнению.
Так выглядел первый API для Device Manager – с его помощью можно было получить список устройств, установить/удалить APK, запустить тесты и получить результаты.

Однако, мы заметили, что результаты тестов деградируют при запуске, на ADB-сервере, к которому подключено больше одного устройства. Решение, которое помогло нам улучшить стабильность, было найдено в изолировании каждого ADB-сервера с помощью Docker.
Ферма готова – можно подключать телефоны.

Многим знакома такая картина. Я слышал о том, что если вы занимаетесь Android-фермами – вы как будто в аду каждый день.

Нам на помощь пришел Android-эмулятор. Его использование было обусловлено двумя факторами: во-первых, в то время он уже достиг необходимого уровня стабильности, а во-вторых, у нас не было каких-то фич, которые бы зависели от конкретно от железа в наших тестах. К тому же этот эмулятор хорошо проецировался на существующую на тот момент инфраструктуру. Следующим шагом надо было научить Node-менеджер запускать новые типы ресурсов.
Что требуется для запуска Android-эмулятора?
Во-первых, нужен Android SDK с набором утилит.
Затем необходимо создать AVD – Android Virtual Device – это то, как будет организован ваш Android-эмулятор – какая у него будет архитектура, сколько будет использоваться ядер, будут ли доступны Google-сервисы и т.п.

После этого, нужно выбрать имя созданного AVD, задать параметры, например, передать порт, на котором будет запущен ADB, и запустить.
Однако, в такой схеме существует особенность – система позволяет запустить только один инстанс-эмулятор на одном конкретном AVD.
Решение этой проблемы заключалось в создании базового AVD, который хранился в памяти, это давало возможность скопировать его куда-то ещё. Во время запуска Android-эмулятора базовый AVD копировался во временную директорию, замапленную в память, после этого происходил его запуск. Такая схема работала быстро, но была громоздкой. На сегодняшний день эта проблема решена опцией read only, которая позволяет запускать Android-эмуляторы в неограниченном количестве из одного AVD
Performance
По результатам работы с AVD мы выработали несколько внутренних рекомендаций:
- Обязательно используйте х86 архитектуру эмуляторов, иначе ARM будет медленным. Для этого вам понадобится dev/kvm на Linux и HAXM-драйвера на Mac и Windows
- GPU-эмуляция ускоряет работу. Можно использовать как софтовую реализацию, так и видеокарту хоста. Ходят слухи, что некоторые крупные компании используют мощные видеокарты не для того, чтобы майнить биткойны, а чтобы запускать Android-эмуляторы с тестами
- Используйте снепшоты. Загрузка из снепшота значительно ускоряет старт эмулятора
- Не забывайте о том, что по умолчанию эмулятор использует подключение только с localhost, поэтому необходимо прокинуть внешнее подключение на нужный порт
Что же касается Docker-образов для тестирования на Android, то хочется выделить Agoda и Selenoid, они используют возможности Android-эмуляторов по максимуму.
Разница между ними в том, что в Selenoid по умолчанию есть Appium, а в Agoda используется «чистый» эмулятор. К тому же, Selenoid обладает большей поддержкой сообщества.
В конце 2018 года был создан CloudNode-Manager, он обращается в координатор, получает задачи и запускается с помощью команд в облаке. Вместо железных машин этот сервис использует ресурсы one-cloud – собственного приватного облака Одноклассников.
Добиться масштабирования удалось научив DeviceManager работать с Координатором. Для этого пришлось изменить API Device manager добавив ему возможность запроса типа устройств (виртуальный/реальный).
Вот что получится, если вы попробуете запустить ADB Install на 250 эмуляторах с одной машины.
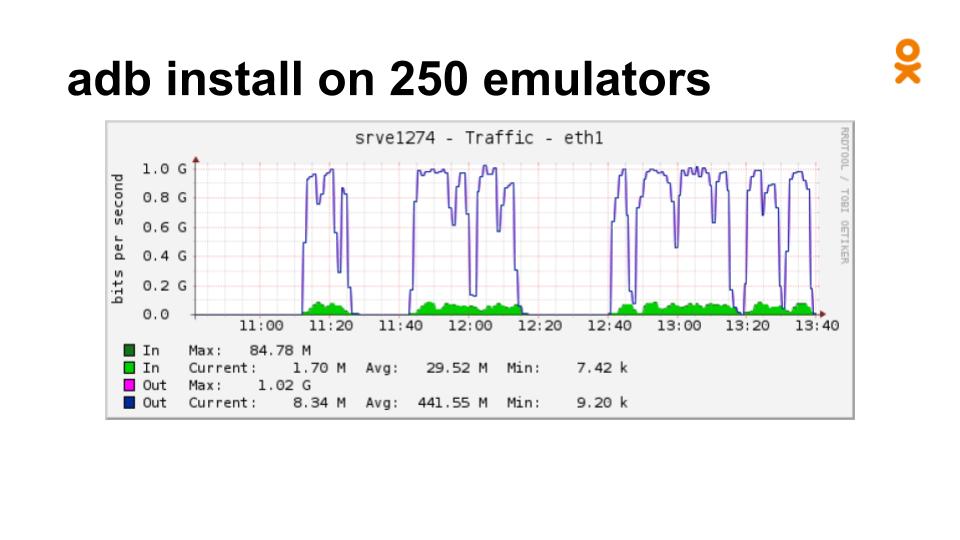
На это сразу среагировали дежурные и завели инцидент – машина загрузила гигабитный сетевой интерфейс исходящим трафиком. Эта сложность была решена увеличением пропускной способности на сервере. Не могу сказать, что эта проблема доставила нам много хлопот, но забывать о ней не стоит.
Казалось бы, успех – есть Devicemanager, координатор, масштабирование. Мы можем на всей ферме запускать тесты. В принципе, можем запускать их на каждый pull request, и разработчик будет быстро получать фидбэк.

Но не всё так радужно. Вы могли заметить, что пока ничего не было сказано о качестве тестов.
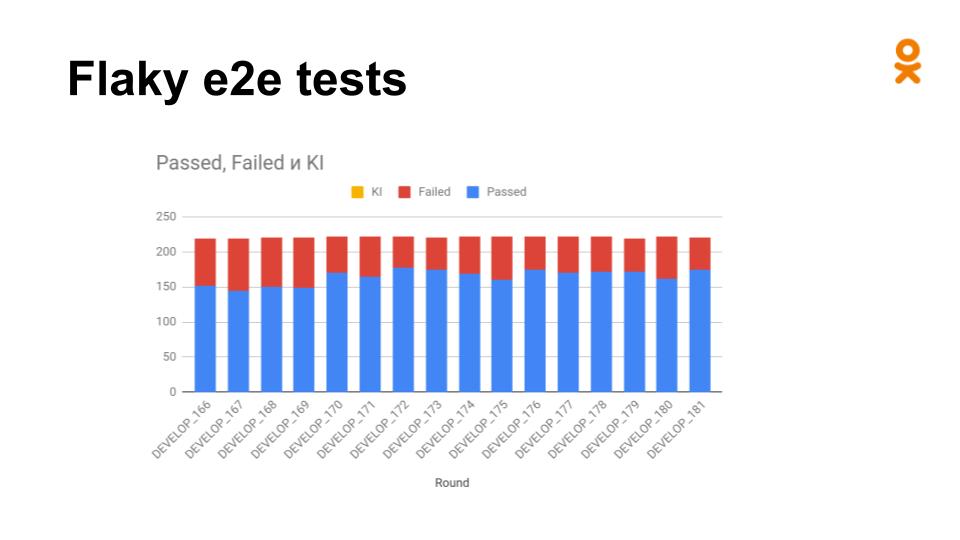
Вот так выглядели наши запуски. И самое интересное в том, что между запусками могли падать абсолютно разные тесты. Это были нестабильные падения. И ни я, ни разработчики, ни тестировщики не доверяли этим результатам.
Как мы справились с этой проблемой? Просто переписали всё с Robotium на Espresso, и стало хорошо… На самом деле, нет.
Для решения этой проблемы мы не только переписали всё на Espresso, но и начали использовать API для всевозможных действий таких как загрузка фотографий, создание постов, добавление в друзья и т.п., сделали быстрый логин, использовали диплинки, позволяющие переходить сразу на нужный экран, и, конечно, провели анализ всех тест-кейсов.
Теперь прогоны тестов выглядят вот так:

Можно заметить, что остались красные тесты, но важно помнить что это end-to-end тесты, которые бегают на продакшене. У нас есть ограничение количества тестов, которые могут падать в основной ветке приложения.
Теперь у нас есть стабильные тесты и масштабирование. Однако тестовая инфраструктура все ещё сильно связана с тестами. В то же время, по причине ожидания end-to-end тестов, занят CI, и другие сборки могут стоять в очереди, ожидая свободных агентов. Вдобавок нет чёткой схемы работы с параллельными запусками.
Причины, указанные выше, стали толчком для разработки QueueRunner – сервиса, который позволяет запускать тесты асинхронно, не блокируя CI. Для работы ему нужны тестовая и тестируемая APK, а также набор тестов. Получив необходимые данные, он сможет организовать запуски прогонов в очереди, выделив и освободив требуемые ресурсы. Результаты прогона QueueRunner загружает в Jira и Stash, а также отправляет по почте и в мессенджере.
QueueRunner имеет тестовый флоу – он следит за жизненным циклом теста. Дефолтный флоу, используемый у нас сейчас, состоит из пяти шагов:
- Получение устройства. На этом этапе Devicemanager запрашивает через координатор реальное или виртуальное устройство.
- Подготовка устройства. Она заключается в установке тестируемой и тестовой APK на эмулятор, очистке реальных устройств – бывают случаи, когда устройство завершило работу аварийно и мы не успели его очистить.
- Собственно, сам прогон теста и получение результатов
- Сбор артефактов
- Очистка устройства или остановка эмуляторов
В итоге пять простых шагов – это весь жизненный цикл теста в нашем сервисе.

Какие преимущества нам дал QueueRunner? Во-первых, он использует все возможные ресурсы по максимуму – его можно масштабировать на всю ферму и быстро получать результаты. Во-вторых, бонусом мы получили возможность управлять последовательностью выполнения тестов. Например, мы можем запустить самые долгие или самые проблемные тесты в начале и таким образом сократить время на ожидание их прогона.
Также QueueRunner позволяет делать «умные» ретраи. Все данные мы храним в базе, поэтому в любой момент можем посмотреть историю теста. Например, есть возможность посмотреть отношение успешных и неуспешных проходов теста и решить стоит ли, в принципе, перезапускать тест.
QueueRunner и Devicemanager дали нам возможность адаптироваться к количеству ресурсов. Теперь мы можем масштабироваться на всю ферму, благодаря использованию эмуляторов, то есть практически неограниченное количество виртуальных устройств дало нам возможность запускать намного больше тестов, но, если по какой-то причине ресурсы недоступны, то сервис дождется их возвращения и потери запусков не произойдет. Мы используем лишь доступные нам ресурсы, cоответственно, через какое-то время результаты всё равно будут получены и при этом CI не будет заблокирован. И самое главное – тестовая инфраструктура и тесты теперь разделены.
Теперь для того, чтобы запустить тесты на Android, нужно всего лишь передать нам тестовую APK и список тестов.
Мы прошли долгий путь от Selenium-фермы на виртуалках до запуска Android-тестов в облаке. Однако, этот путь еще не завершен.
Процесс разработки
Давайте посмотрим, как тестовая инфраструктура связана с процессом разработки и как её видят тестировщики и разработчики.
В нашей Android-команде используется стандартный GitFlow:

Для каждой фичи своя ветка. Основная разработка происходит в develop-ветке. Разработчик, решивший создать новую супер-фичу начинает её разработку в своей отдельной ветке, при этом параллельно в других ветках могут работать другие разработчики. Когда разработчик считает, что идеально красивый, лучший код в мире готов и его нужно побыстрее выкатить на пользователей, он делает pull request в develop, автоматически происходит сборка, запуск юнит-тестов и компонентных тестов. Одновременно собираются APK, отправляются на QueueRunner и запускаются end-to-end тесты. После этого результаты запуска тестов приходят разработчику.
Однако существует большая вероятность, что после создание фича-ветки в develop произошло много коммитов. Это значит, что develop может быть совершенно не тем, чем был раньше. Поэтому сначала происходит pre-merge – мы мерждим develop в текущий feature-branch, и именно на этом премердженном состоянии делаем сборку, unit-тесты, компонентные тесты, end-to-end, и уже на основе этих результатов делаем отчет. Таким образом мы понимаем насколько фича работоспособна в текущей версии develop и, если всё ОК, то она отправляется к пользователям.

Репортинг
Так выглядит репортинг в Stash:

Наш бот сначала пишет о том, что тесты запустились, а когда они проходят, он обновляет сообщение и дописывает, сколько прошло, сколько упало, сколько известных ошибок, и сколько было Flaky-тестов. То же самое он пишет в Jira, и добавляет ссылку на сравнение запусков.
Вот так выглядит сравнение двух запусков:

Здесь сравниваются текущий прогон в фича-ветке и последний прогон в девелопе. Тут содержится информация о количестве прогоняемых тестов, совпадающих проблемах, упавших тестах и нестабильных Flaky-тестах, которые были в одном состоянии, а перешли в другое.
Если у нас упал хотя бы один юнит-тест или больше какого-то порога end-to-end-тестов, то merge будет заблокирован.
Чтобы понять, стабильно ли падают тесты, мы сравниваем между собой хэши стектрейсов падений, перед этим они предварительно очищаются от цифр, остаются только номера строк. Если хэши совпадают, то это одно и то же падение, если они разные, то скорее всего и падения будут разные.
Итоги
В итоге мы реализовали стабильное, отказоустойчивое решение, которое хорошо масштабируется на нашу инфраструктуру. Затем получившаяся инфраструктура была адаптирована для Android-тестирования. В этом нам помогли Device manager, который помогает одновременно работать и с реальными устройствами, и с виртуальными, а также QueueRunner, который помог нам разделить инфраструктуру и тесты, и не блокировать CI на время прохождения тестов.
Так выглядело время прогона тестов в течении одной недели в 2016 году – от пятидесяти минут и дольше.
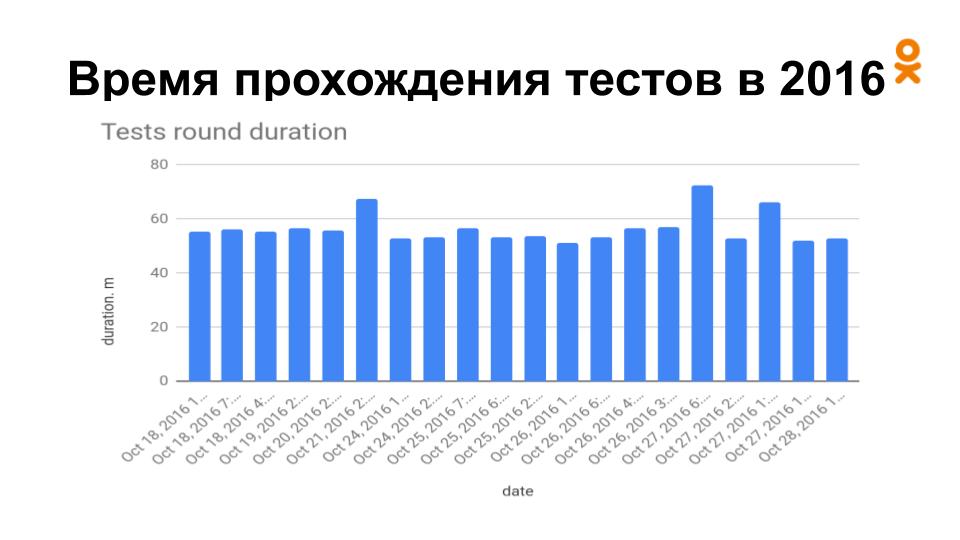
Вот так все выглядит сейчас:

Эта диаграмма показывает прогоны состоявшиеся в течении 2-х часов среднестатистического рабочего дня. Время прогонов сократилось до 15 минут максимум, количество прогонов заметно увеличилось.
