Привет, Хабр!
Делимся нашим исследованием вакансий и зарплат в сфере data science и data engineering. Спрос на специалистов растет, или рынок уже насытился, какие технологии теряют, а какие набирают популярность, размер зарплатных вилок и от чего они зависят?
Для анализа мы использовали вакансии, публикуемые в сообществе ODS. По правилам сообщества все вакансии должны иметь зарплатную вилку от и до и подробное описание вакансии - есть что анализировать. К статье прилагается репозиторий с ноутбуком и исходными данными.
Кол-во и динамика вакансий
В сообществе ODS вакансии публикуются в нескольких каналах в slack. Помимо самих вакансий там есть комментарии пользователей. Посмотрим на общую динамику по кол-ву сообщений в этих каналах.
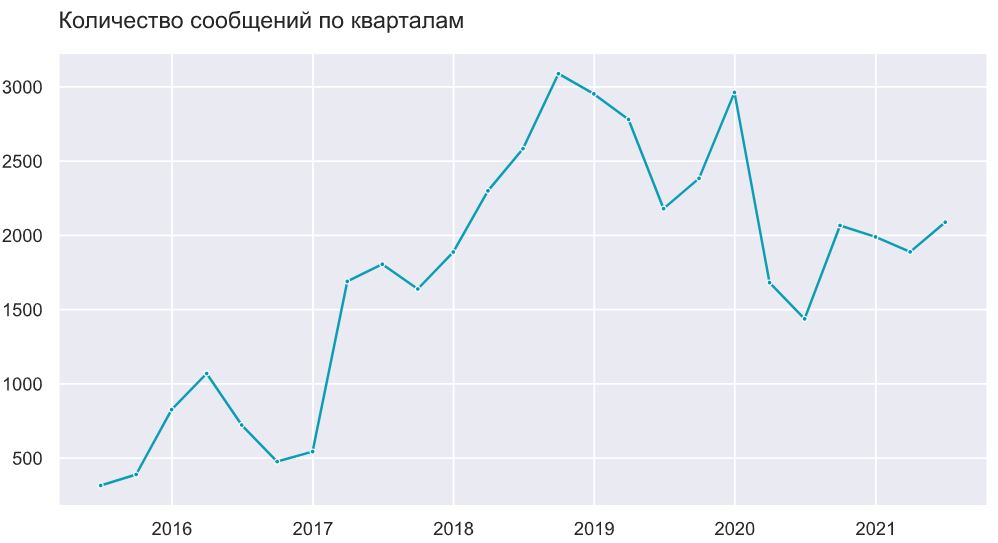
Общее кол-во сообщений достигло максимума в 3 квартале 2018 года. После этого активность снижалась - резкое падение кол-ва сообщений произошло в 2020 году.
Что это коронакризис или хайп по data science уже прошел?
Здесь мы смотрим на все сообщения: это и сами вакансии, и комментарии пользователей. Для дальнейшего анализа нам нужно отделить сообщения с вакансиями от комментариев, самый простой подход - это считать вакансией все сообщения, с которых начинается тред. Но до 2017 года тредов вообще не было, и все сообщения сыпались в общий канал. У части сообщений и сейчас нет треда, если никто не оставил комментарий. Плюс не все сообщения, с которых начался тред, являются вакансиями. Для дальнейшего анализа мы сделали простую модель, которая классифицирует сообщение в зависимости от используемых слов.
Вакансию характеризуют такие слова:
навыки: python, sql, data, английский
ссылки и email: http, https, mailto
слова связанные с вилкой зп: вилка, от, fork, 200, 50 и т.д.
приветствия - в комментариях люди редко здороваются
другие слова, характерные для вакансий: опыт, на, ищем, офис, Москва, требования
Для комментариев характерны более простые разговорные слова:
но, как, же, вот, просто, так, уже, есть, а также использование цитаты (тег gt)
Важность признаков в модели классификации сообщений

Теперь с помощью нашей модели можно выделить только вакансии и посмотреть на их динамику. Паника отменяется, товарищи, кол-во вакансий по прежнему растет!
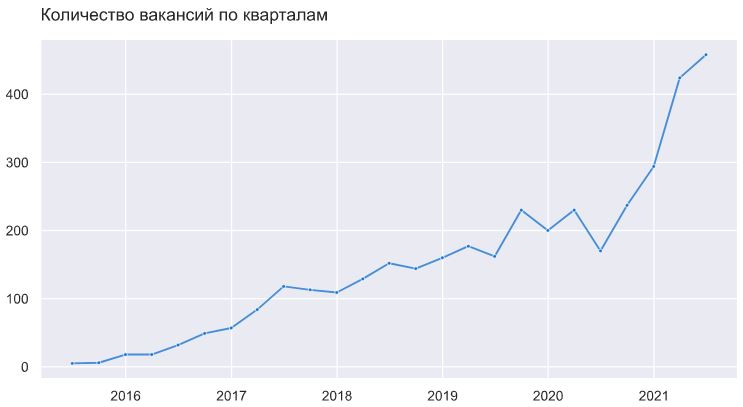
До второго квартала 2020 тренд был почти линейный, затем произошло небольшое падение и стагнация длиной в 2 квартала, но уже с 4 квартала 2020 года пошел заметный рост, который ускорился в 2021 году.
Динамика 2021 года вообще очень сильно выбивается из сложившегося тренда: прирост на 120% по кол-ву вакансий относительно 2020 года.

Скорее всего прирост кол-ва вакансий за весь год окажется меньше, но все равно это явная аномалия.
Специальности и грейды
Интересно посмотреть на динамику кол-ва вакансий по сегментам, для этого спарсим грейд и специализацию для каждой вакансии регулярками.

На рынке соотношение между этими специализациями может быть другим. Большая доля data scientist в нашем исследовании - это специфика чата ODS.
В 2021 году спрос на дата аналитиков вырос на 222%, на дата инженеров - на 127%, а вот на дата саентистов - только на 93%. Возможно, сейчас появилось понимание, что data science команда состоит из разных ролей, и набирать одних саентистов без инженеров и аналитиков не так эффективно.
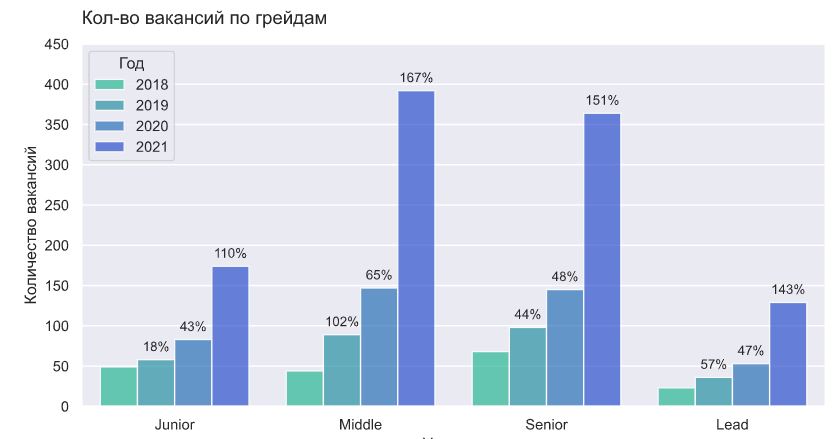
Больше всего вакансий и самый быстрый рост - по мидлам и синьорам/милордам. Джунов ищут чуть чаще, чем лидов, но спрос на лидов растет быстрее, возможно, это только специфика чата ODS, где чаще ищут специалистов с опытом.
Посмотрим еще на распределение грейдов для каждой специальности
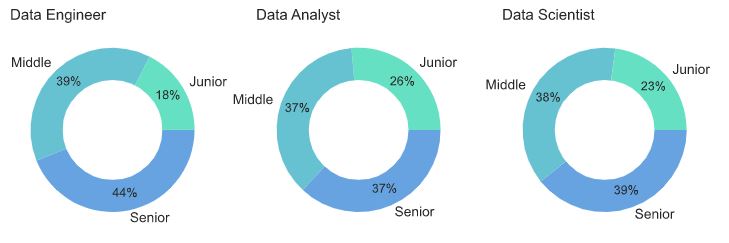
Спрос на джунов в дата инжиниринге ниже, чем в аналитике и data science. Если вы хотите стать дата инженером, то, возможно, стоит начать с аналитики или разработки и потом постепенно перекатываться.
Локации и удаленка
Дальше решили посмотреть на распределение вакансий по городам. При парсинге городов было несколько забавных ошибок, например, оказалось, что регулярка "казан" для Казани захватывает еще и слово "предсказание".
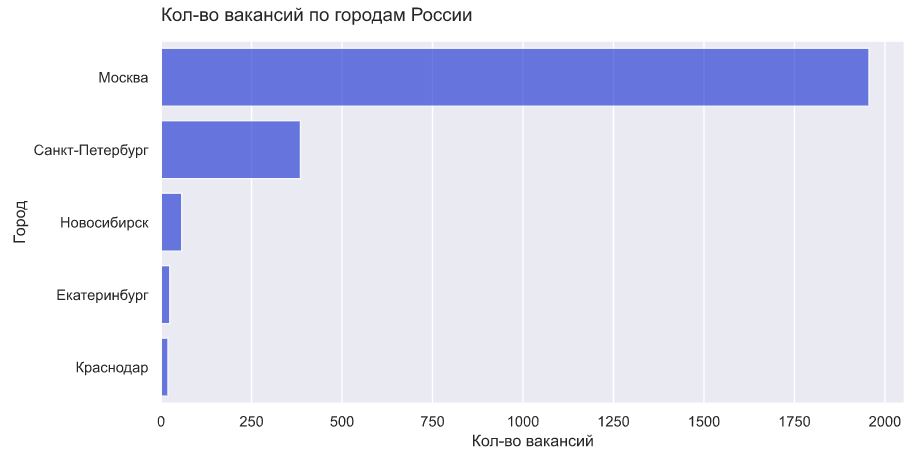
Дальше первой пятерки городов смотреть бессмысленно. Москва имеет подавляющее преимущество, Петербург отстает в 6 раз, Новосибирск - в 50. В регионах выбор мест для работы не такой большой, скорее всего и зарплата ниже, но у нас даже нет достаточного кол-ва данных, чтобы это проверить. Кажется, что в перспективе нет другого выбора, кроме переезда в Москву или Питер.
Но по ощущениям с 2020 года ситуация стала меняться: появилось очень много предложений с возможностью частичной или полной удаленки.
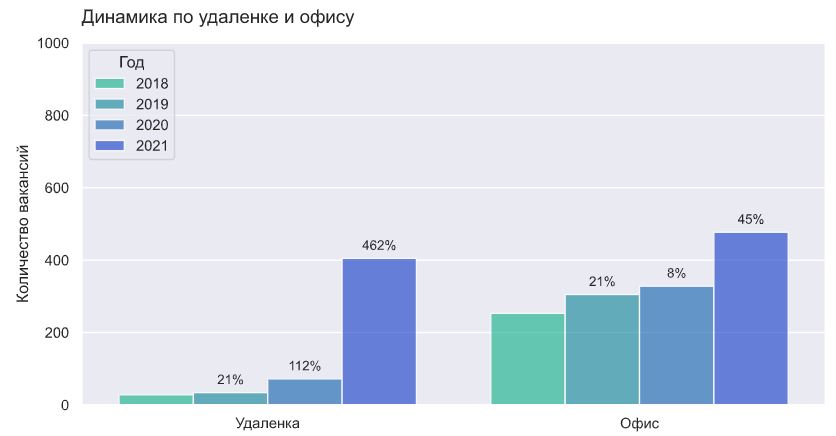
Кол-во вакансий с возможностью удаленки очень быстро растет и почти сравнялось с вакансиями в офисе. Для построения этого графика использовалась максимально простая регулярка, если есть слова "удаленка" или "remote", то относим к классу удаленка, иначе - офис. В удаленку могли попасть случаи, где написано "удаленки нет", так что цифры могут быть неточными, но тренд прослеживается.
Зарплаты в Data Science
Cбор и парсинг данных
По правилам сообщества ODS все вакансии должны публиковаться вместе с зарплатными вилками. И казалось бы их можно будет вытащить простой регуляркой, но есть несколько проблем. Зачастую зарплата указывается в тексте вакансии в неструктурированном виде, иногда в одной вакансии идет несколько позиций и несколько вилок. Также в вакансии могут быть указаны годовые бонусы или другие цифры, которые можно принять за зарплату.
Примеры указания зарплат в тексте вакансии




Для начала очистим текст вакансии от цифр, не относящихся к зарплате (ссылки, номера телефонов, интервалы времени, премии).
После этого сделаем 4 регулярки: для текста, который часто идет до и после зарплаты в вакансии, для самих цифр зарплаты и для текста, который встречается между нижней и верхней границей зарплатной вилки.
Cмотреть регулярки
start = r'(?:net|gross|гросс|нет|rub|$|€|£|eur|dol|mid|sen|jun|мидл|синь|джун|зп|з\\п|плат|компенсац|' + \
r'вилк|з/п|доход|fork|moneys|salary|moneyparrot|деньг|оклад|условия|ставка|_plug).{0,100}?\s*?'
end = r'[ \t]*?[^0123456789]{0,3}?(?:k |к |тыс\.|т\.р|net|gross|гросс|нет|rub|$|€|£|eur|dol|mid|' + \
r'sen|jun|мидл|синь|jun|р |джун)'
number = r'([123456789]\d{0,2}[,\'\. ]?\d0{2}|[123456789]\d{2}0{1,2}|[123456789]\d{1,2}|[123456789]\d{0,1}[\.,\']\d{1,3})'
middle = r'[ \t]*[^0123456789\.,\'%]{0,9}?(?:-|до|–|—|to|-)[ \t]*[^0123456789\.,\'%]{0,1}?'Для начала найдем полные вилки, состоящие из двух цифр и правильного шаблона между ними. После этого удалим их из текста, и дальше будем искать вилки, состоящие из одного числа, но имеющие "правильный" текст до и после самого числа. В итоге хотя бы одна корректная зарплата находится для 3108 (81%) вакансий из 3776.
Добавим признаки валюты и признак по налогообложению - net/gross.
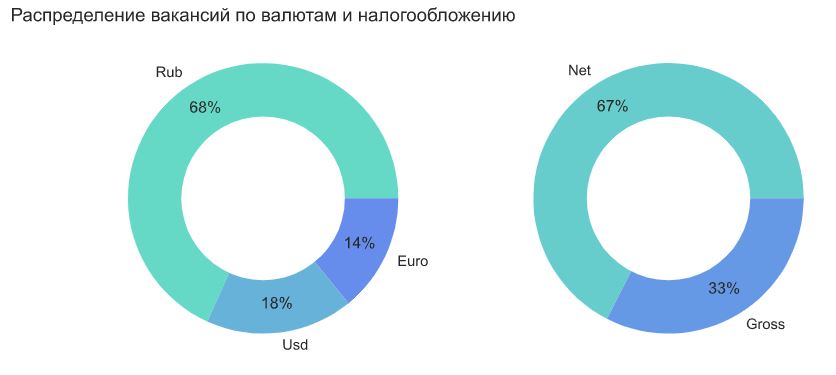
Вакансии в долларах и евро почти всегда указываются gross. Перевести их в net не так просто, нужно смотреть налогообложение во многих странах. Для простоты дальнейшего анализа оставим только вакансии в рублях и переведем их к формату net.
Анализ зарплат по грейдам и направлениям
Теперь мы почти готовы к ответу на главный вопрос: сколько зарабатывают в data science? Осталось только удалить явные выбросы, установим такие границы: для джунов 20 - 200, для мидлов 60 - 300, для синьоров и лидов от 100. Для вилок формата от X до Y добавим на график и X, и Y. Если взять просто среднее между нижней и верхней границей, то потеряется разброс.
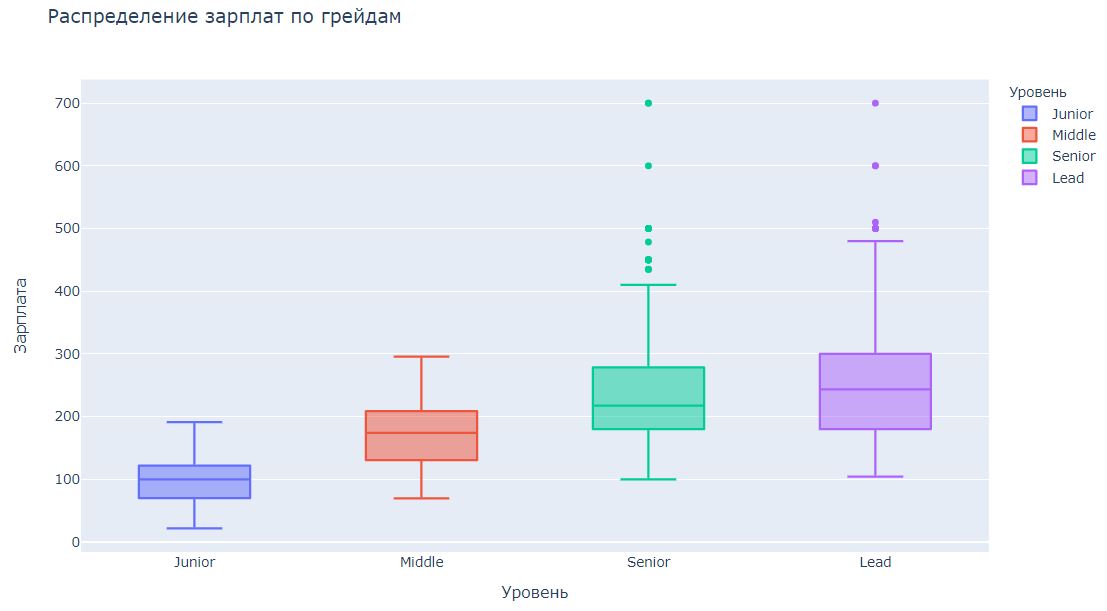
Совсем необязательно, что этот график показывает истинное состояние дел в индустрии. Всё-таки здесь предложения только из одного источника. На одной конференции автор рассказывал о том, что они стабильно нанимают людей на меньшие деньги на hh и не публикуют вакансии в ODS, чтобы не получить ушаты лапши. Вакансии на редких специалистов и руководящие должности часто публикуются в формате от X до бесконечности, поэтому верхняя граница тоже может быть смещена.
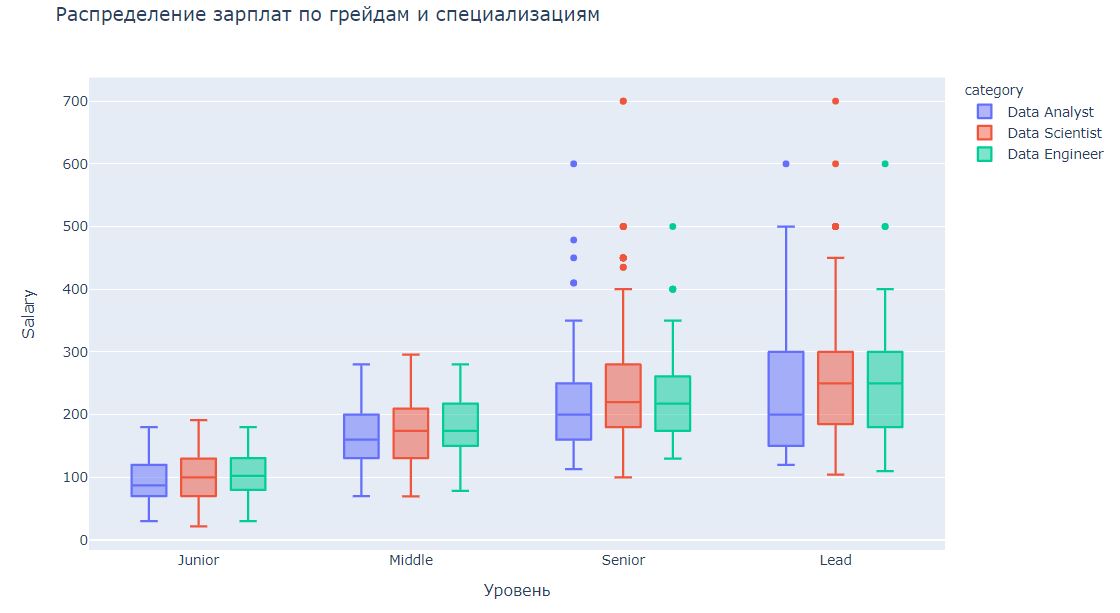
Data analyst зарабатывают немного меньше, чем саентисты и инженеры, но какой-то глобальной разницы нет, или ее сложно заметить на таком графике. Попробуем еще один подход: закодируем уровни и специальности как 0/1 и построим Ridge регрессию с целевой переменной "зарплата". Коэффициенты этой регрессии c определенной долей условности можно будет считать "доплатой" за фичу.
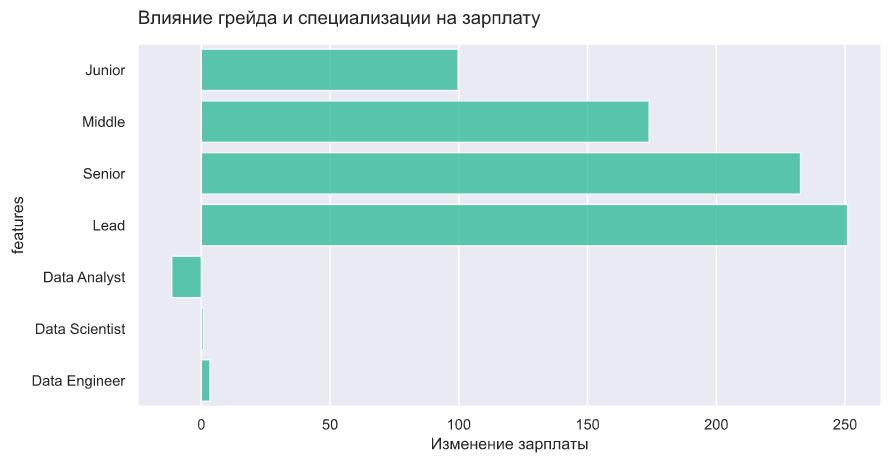
В целом, выводы подтверждаются, инженерам и саентистам платят немного больше, чем аналитикам, примерно на 11-14 тыс., а вот грейд влияет на вилку намного сильнее. Самый резкий скачок происходит при переходе от Джуна к Мидлу +74 тыс. (71%), далее - от мидла к синьору +58 тыс. (32%) и небольшой рост от синьора к лиду +17 тыс. (7%).
Динамика зарплат
Построим уже привычный график для изменения зарплат по годам, для сравнимости с 2021 годом будем использовать только данные за первые полугодия. В некоторые группы попадает мало данных, поэтому заменим среднее на устойчивую к выбросам медиану.
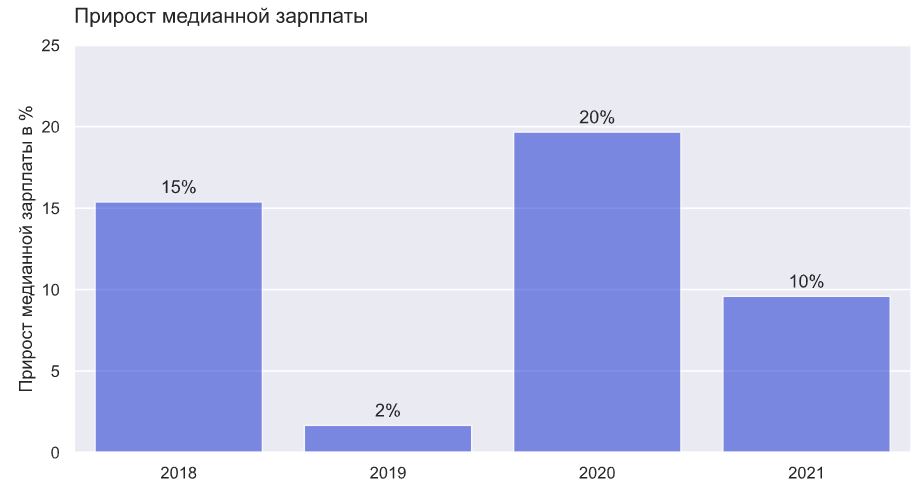
В среднем по рынку зарплата росла на 11% в год. При этом в 2019 году роста не было совсем, а вот в 2020 году наблюдался максимальный рост в 20%. Интересно, что в 2021 году зарплата увеличилась пока на 10%, при том что кол-во вакансий выросло на 120%, то есть зарплаты не поспевают за ростом спроса. Возможно, работодатели среагируют с некоторой задержкой, и мы увидим ускорение роста во втором полугодии 2021 года.
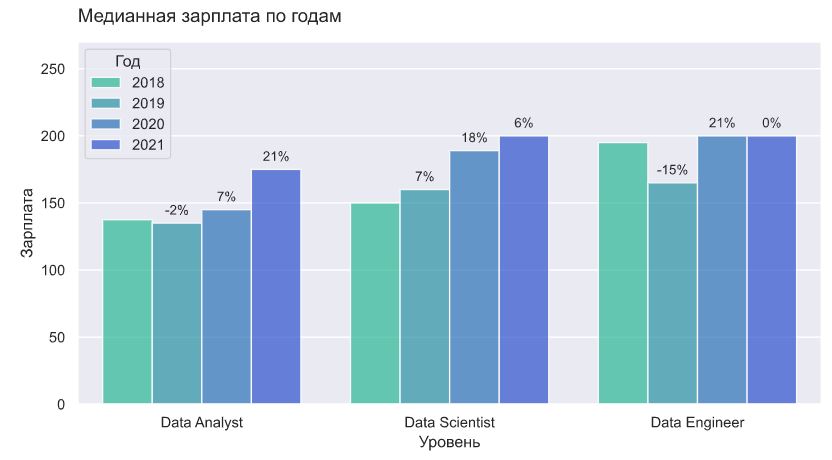
В разрезе специальностей и годов тоже есть интересные тенденции. Например, зарплата data engineer почти не изменилась за последние 3 года, но это может быть связано с использованием медианы и малым кол-вом наблюдений в этой группе или изменением соотношения по грейдам.
Data analyst, действительно, получали ощутимо меньше, чем саентисты и инженеры, но в 2021 году их зарплата выросла на 21%, и отставание сократилось. У data science стабильный рост зарплаты в cреднем на 11% в год.
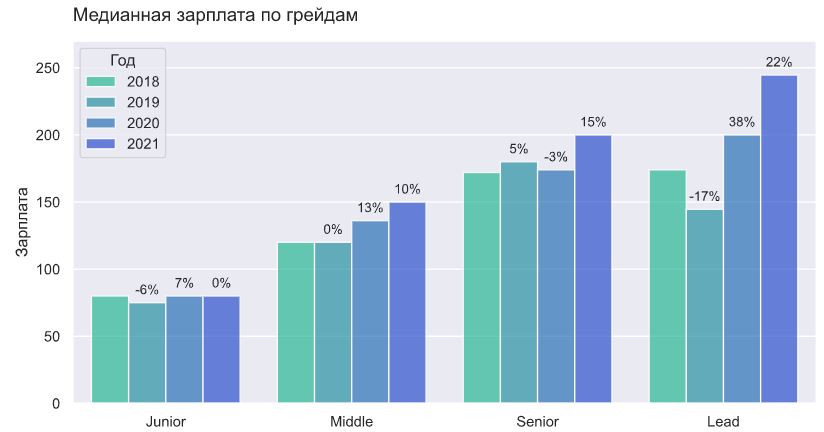
Вилка для джунов почти не изменилась за последние 3 года, по всем остальным уровням есть более-менее стабильный рост. Сильнее всего выросла зарплата специалистов уровня lead: +40% за 3 года.
Анализ навыков
Посмотрим, какие технологии чаще всего встречаются в вакансиях, и какие изменения по ним произошли за последнее время.
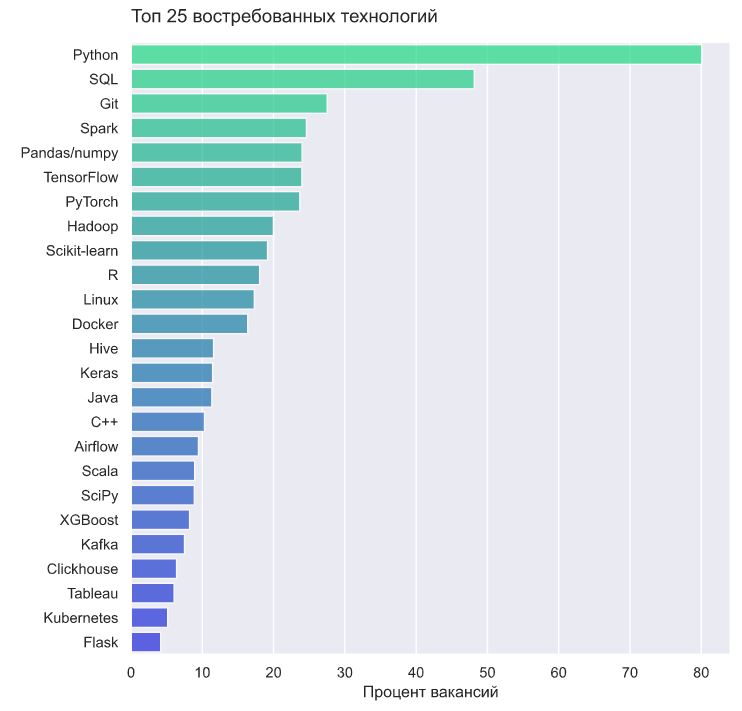
Самыми популярными являются базовые навыки: python, sql, git, после них идет big data, deep learning и классический machine learning. Далее - какие-то более узкоспециализированные инструменты, devops и разработка.
Можно закодировать наличие инструмента в вакансии как 0/1 и построить модель регрессии для определения "условной стоимости" владения.
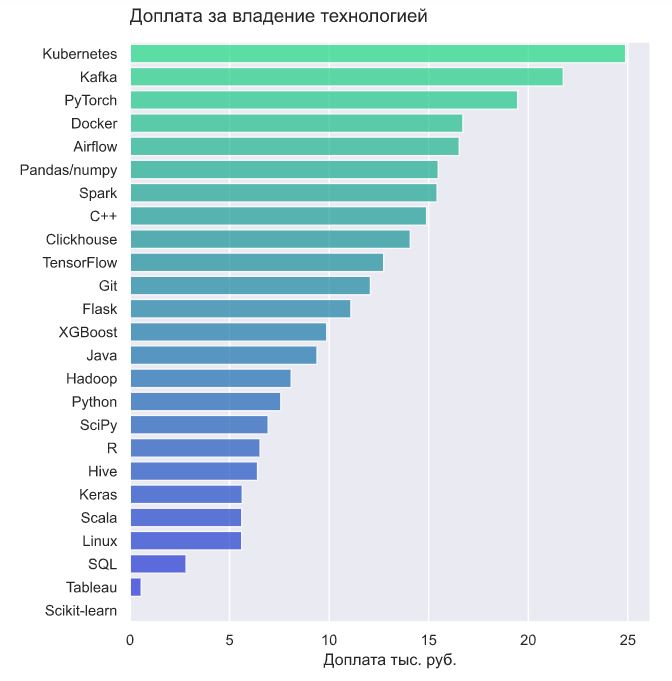
Самые высокооплачиваемые навыки связаны с devops, разработкой, дата инжинирингом и deep learning. Наименее ценные навыки - это sql, bi инструменты и sklearn.
Еще раз оговорюсь, что полученные цифры не нужно воспринимать слишком серьезно, это скорее шуточный эксперимент, который в лучшем случае покажет какие-то общие закономерности.
Попробуем понять, какие из популярных навыков в каждом направлении Data Science пересекаются между собой. Для этого возьмем по 13 наиболее востребованных технологий у каждой специальности и отобразим их на диаграмме Венна.
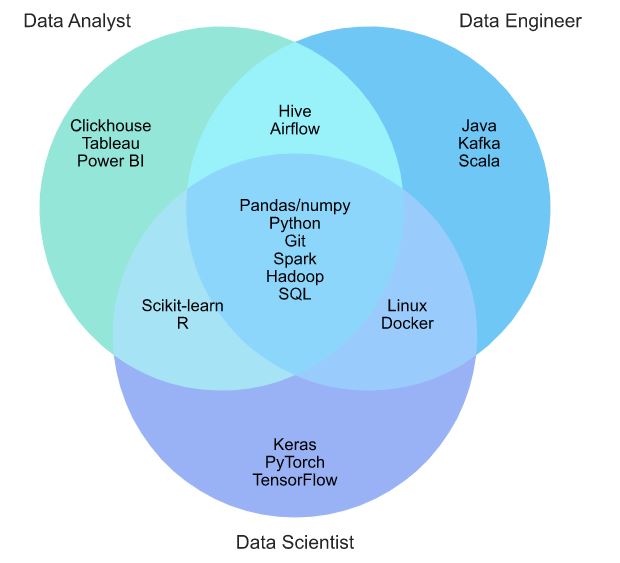
Изменение популярности технологий
Есть несколько популярных технологий, которые можно противопоставить друг другу. Самый простой пример - это R и Python для анализа данных и разработки моделей. Посмотрим, как менялась их популярность по доли упоминаний в вакансиях.
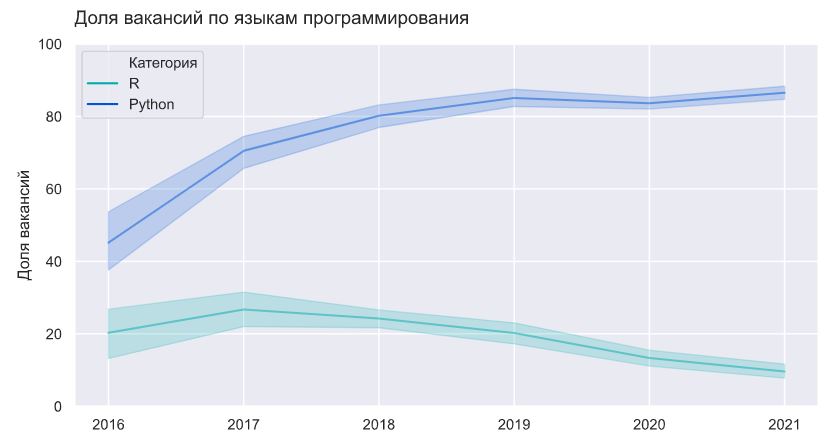
Популярность python растет, и сейчас он упоминается почти в 90% вакансий, то есть де факто владение python - необходимый минимум для любого специалиста в сфере data science. А вот R, наоборот, теряет позиции: на пике в 2017 году он упоминался в 28% вакансий, сейчас в 2021 году - только в 9%. Если вы только вкатываетесь в индустрию, изучать R или выбирать команду, в которой его используют, скорее всего не самое перспективное решение.
Построим теперь аналогичный график для трех основных deep learning фреймворков.
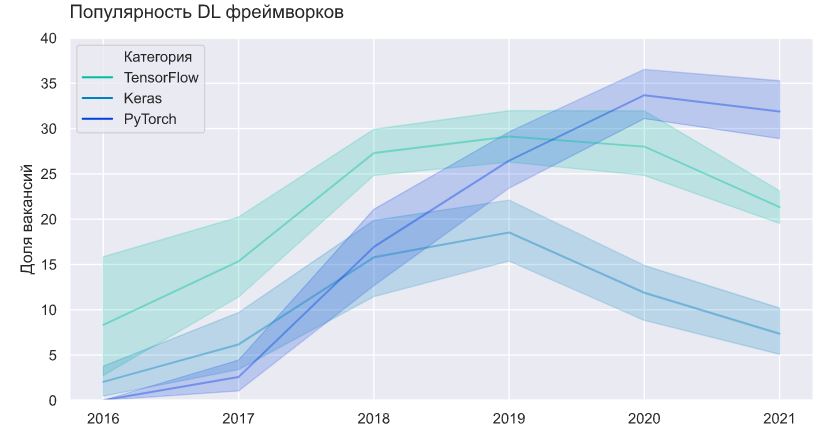
Популярность PyTorch стремительно растет. Он обогнал Keras в 2018 году и TensorFlow в 2020. В целом, знания deep learning становятся более востребованными: указаны в более 30% вакансий в 2021 году.
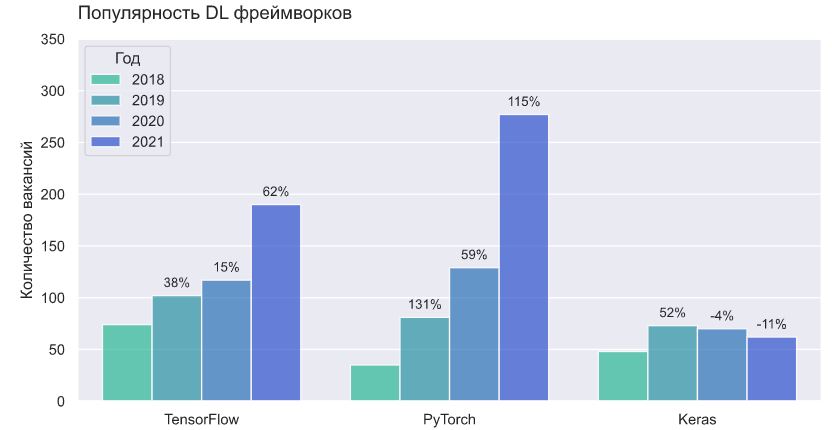
Keras снижается даже по абсолютному кол-ву вакансий, учитывая, что общий спрос растет. У TensorFlow в этом плане не все так плохо: кол-во вакансий растет, несмотря на то, что доля снижается. Если вы на находитесь в начале своего пути в DL, с карьерной точки зрения, лучше выбрать более востребованный инструмент.
Заключение
По ссылке находится репозиторий со всеми данными и кодом исследования. Можно попробовать поискать новые интересные инсайты в данных или уточнить какие-то выводы этой статьи. Надеюсь, что получилось интересно и познавательно, буду благодарен за обратную связь.
Хотел бы поблагодарить своих коллег Славу Ефимова и Андрея Глотова за помощь в работе над статьей.
Мой telegram: @borisov_egor
