

Максим Дунин (Nginx, Inc.)
Ведущий: Я представляю вашему вниманию следующего докладчика. Встречайте – Максим Дунин. И он расскажет о том, что же нового появилось в технологии под названием nginx.
Дисклеймер: речь пойдёт о нововведениях в 2016 году. Можно подумать, что это давно, но информация об изменениях в changelog от автора этих самых изменений полезна всегда!
Максим Дунин: Добрый день! Я Максим Дунин. Как вы, наверное, знаете, я разработчик nginx. Сегодня буду вам читать changelog вслух и с выражением. Для начала давайте определимся, с какого именно места мы будем читать changelog. Посмотрим на статистику.

Если верить W3Techs, нулевой версии nginx практически не осталось. Есть еще отдельные товарищи, которые держатся за Debian 6, но их мало, на них мы ориентироваться не будем. Если вы все еще используете нулевые версии nginx, вам стоит обновиться.
Первая версия – сейчас уже практически 97%. Я искренне считаю, что это хорошо, потому что когда 3 года назад я делал аналогичный доклад, все было очень печально, народ как-то очень усиленно сидел на старых версиях, мы предприняли массу усилий, чтобы как-то эту ситуацию изменить.
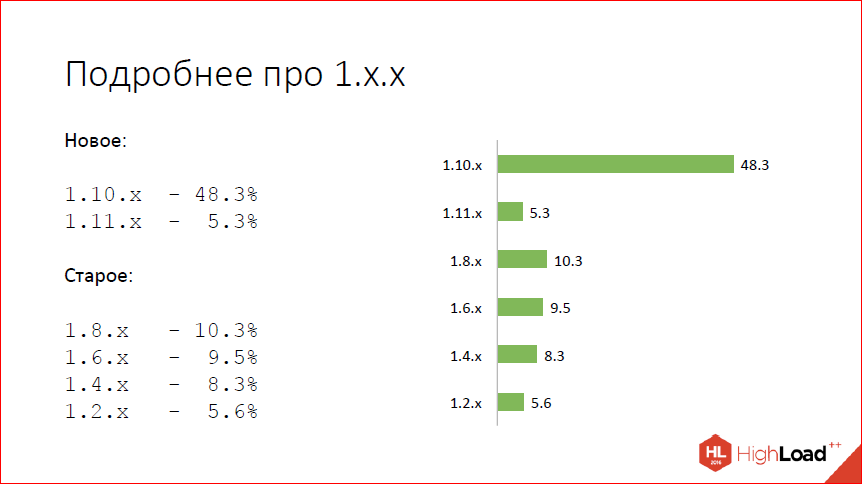
Смотрим подробнее на то, что происходит в первой версии. И видим, что фактически 50% пользователей уже на текущем стейбле 1.10, еще 5% достаточно смелые, чтобы использовать то, что мы используем и разрабатываем mainline 1.11. Остальные, так или иначе, выучили, что четные версии у нас стабильные, и как-то не спешат обновляться, наверное, просто потому что используют то, что предоставляют собственные дистрибутивы операционных систем и nginx не особо пользуются или не знают, чего нового появилось и зачем им нужно обновляться.
Сегодня я расскажу, зачем нужно обновляться, и что вы получили, если уже обновились до 1.10 или до 1.11.
Для начала – то, что появилось в ветке 1.9 и доступно в версии 1.10.

Мы научились, наконец-то, использовать порт клиента в различных местах, отошли от моделей, что IP’шников хватит всем, и, если вы много работаете с клиентами за NAT’ом (что сейчас, наверное, у всех), то Real_IP-модуль в том числе поддерживает порт, и можно вытаскивать его из proxy-протокола, можно передавать на бэкенд руками через X-Real-IP.

Следующий вопрос – идемпотентность. Кто знает, что такое идемпотентность? 3 человека в зале. Круто… Приблизительно это мне и говорил Игорь, когда я произносил слово «идемпотентность».

Идемпотентность – это такое свойство объекта или операции при повторе давать тот же самый результат. С точки зрения http, GET-запрос идемпотентен, потому что каждый раз вам возвращают один и тот же ресурс, если вы сделаете запрос не один раз, а два раза, то ничего не изменится. Если вы сознательно не пытались нарушить протокол http и не повесили на GET-запрос какую-нибудь операцию, как большинство счетчиков делают. Например, любая статистика у вас в результате не идемпотентна, потому что повторенный дважды GET-запрос засчитывает два хита. Но с точки зрения стандарта GET идемпотентен. Практически все методы http идемпотентны, кроме POST из основного стандарта и двух дополнительных методов LOCK И PATCH.
Почему это важно? Важно это потому что, когда nginx куда-то что-то проксирует, он имеет привычку запросы повторять. Для неидемпотентных запросов это может плохо кончиться, если ваше приложение ожидает полного соответствия стандарту. Вы можете от этого защититься, напрограммировав некую защиту для POST-запросов, чтобы детектировать дубли. Наверное, даже не можете, а должны защищаться, потому что, так или иначе, у вас, скорее всего, дубли из браузера будут прилетать. Но, поскольку мы стремимся быть стандартными, мы сделали так, что теперь nginx запросы неидемпотентные по умолчанию не повторяет и ведет себя так, как предполагает стандарт и т.к. некоторые люди программируют.
Если nignx начал уже отправлять запрос на бэкенд, случилась ошибка, повторно он этот запрос не отправляет для POST-запросов. GET-запросы замечательно отправляет, потому что имеет право. POST-запросы не отправляет. Если вам хочется вернуть прежнее поведение, это можно сделать легко с помощью конфигурации. Пишете: «proxy_next_upstream» и добавляете параметр «non_idempotent».

Следующий вопрос – запись в кэш. Мы в nginx записью особо долгие годы не занимались, потому что с записью все обычно просто. Вы сказали ОС: «Запиши мне в файлик данные», ОС сказала: «OK, я записала», а на самом деле сохранила в буфера и когда-то потом запишет.
Это не всегда так. Если у вас очень много записи, вы можете наступить на то, что буфера ОС закончились, и ваша запись заблокируется. Чтобы этого не происходило, теперь nginx умеет писать через thread’ы, если у вас очень много записи в кэш, вы можете с помощью директивы aio_write включить запись через thread’ы. Пока работает только через thread’ы. Вероятно, когда-нибудь в будущем сделаем и через posix aio.
Опять же, кэш теперь научился за собой следить и превентивно очищать зону разделяемой памяти от лишних записей, если у него памяти не хватает.

Теперь вы ошибок аллокации видеть не должны, если вдруг у вас зона маленькая, просто nginx будет хранить столько, сколько в зоне помещается. Он и раньше это пытался делать, но пытался он это делать по факту, т.е. когда он не мог аллоцировать очередную запись в разделяемой памяти, он говорил: «А давайте мы попробуем удалить самую старую запись», удалял ее и пытался аллоцировать снова. Обычно это получалось. Если у вас высокая нагрузка, много рабочих процессов, это могло не получиться просто потому, что какой-то другой рабочий процесс успевал освобожденную память занять. Плюс к тому, это требует некоторого времени, потому что предполагает удаление файла, соответственно, syscall, уход в диск. Не хочется этого делать в рамках обработки запроса, не хочется, чтобы пользователь ждал, теперь этим умеет заниматься cache manager.
Напрограммировали динамические модули, наконец-то.

Основные цели, которые мы ставили – это упростить сборку пакетов в первую очередь. потому что внешние зависимости у отдельных модулей сильно усложняют сборку и установку пакетов. Либо вы делаете некоего монстра, который зависит от всего в системе, либо вы не включаете какие-то модули, которые имеют плохие внешние зависимости, либо вы собираете много разных пакетов с такими модулями, с другими модулями. С точки зрения пакетирования, статическая сборка nginx – это боль.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Вторая цель, которая ставилась – это упростить отладку, потому что писать хорошие модули для nginx мало кто умеет и зачастую, когда к нам приходят с проблемами, проблема оказывается в сторонних модулях. Поэтому уже долгие годы первое, что мы просим, когда к нам приходят со словами: «А у меня nginx падает, все разваливается!», мы говорим: «Покажите нам “nginx –V”» и рекомендуем пересобраться без сторонних модулей и посмотреть, воспроизведется ли проблема. Скорее всего, она не воспроизведется.

Напрограммировали, теперь можно достаточно легко собрать динамический модуль. Для стандартных модулей это включается с помощью суффикса dynamic. Если вы собираете какой-то свой или сторонний модуль, вместо add-module вы используете add-dynamic-module. И потом в конфиге загружаете.

Переделать свой модуль, чтобы он умел загружаться динамически, достаточно тривиально. Мы предприняли массу усилий, чтобы максимально упростить это все для авторов модулей, и чтобы все это требовало минимальных переделок. Фактически вам нужно поменять config-файл, если он у вас в старом виде написан, чтобы использовался скрипт auto-модуля.
Если у вас сложный модуль, вам еще нужно проделать пару изменений во внутренней логике. Ничего сложного – вместо подсчета модулей с помощью собственного цикла нужно вызывать nginx-функцию, вместо глобальной переменной со списком модулей нужно использовать тот список, который теперь появился в цикле.
Конфиг переделывается как-то так.

Была прямая установка переменных со списками модулей, и стал вызов скрипта auto-модуля с поставленными параметрами для скрипта. Сам этот скрипт потом уже разберется – динамический ваш модуль собирают, статический собирают – и сделает все нужное.
Следующий вопрос – CPU affinity.

Nginx давно умеет CPU affinity, биндить рабочие процессы конкретным процессорам. Это конфигурилось как-то так. Т.е. бинарную маску задаете для каждого рабочего процесса, соответствующий рабочий процесс начинает работать на тех процессорах, которые ему разрешены. Это хорошо работало, когда были 2х-процессорные машины, 4х-процессорные машины. Сейчас, когда машины бывают 64х-процессорные, это уже немного неудобно конфигурить, потому что если вы хотите занять всю машину, у вас там 64 рабочих процесса по 64 бита в каждой маске, руками это уже писать невозможно. Я видел людей, которые пишут PERL-скрипты для того, чтобы делать это. Мы приняли их боль, сделали простую ручку auto, которая раскладывает рабочие процессы по процессорам один за одним. Если полной автоматики мало, можно указать маску, из которой nginx будет выбирать процессоры. Это позволяет ограничить эту раскладку каким-то сапсетом процессоров. Если в маске меньше бит, чем имеется рабочих процессов nginx, он просто пойдет по кругу.

Еще одна проблема, с которой периодически люди сталкиваются – это кэширование больших файлов. Совсем больших файлов, когда у вас 4 ГБ имидж или 40 ГБ имидж, или много-гигабайтное видео. Nginx, конечно, умеет такие файлы кэшировать, но делает это не очень эффективно, особенно, когда речь идет про range-запросы. Если вам присылают range-запрос на что-то из файлика 2 Гб, nginx пойдет скачивать файл целиком, чтобы положить его в кэш, положит его целиком в кэш и, когда до второго Гб докачает, начнет возвращать ответ клиенту. Latency для клиента получается совершенно запредельной. Как-то с этим хочется бороться, но опять же зачастую нужно только начало файла. Наоборот, если у вас какой-нибудь видеостриминг с длинным и скучным фильмом, большинство клиентов открывают, скачивают первые несколько Мб этого потока и после чего соединение закрывают. А вы пошли и скачали все несколько Гб, к себе в кэш положили и думаете, что они нужные.
Как с этим бороться? Одно из возможных решений которое предполагает, что у вас файлы на бэкенде не меняются – это качать по кускам и кэшировать тоже по кускам. У нас появился модуль slice, который умеет качать и кэшировать по кускам.

Он создает последовательно подзапросы на диапазоны заданного размера. И мы можем эти диапазоны, отдельные кусочки небольшого размера, закэшировать с помощью стандартного кэша. При отдаче клиенту эти кусочки склеиваются. Все работает и кэширует очень эффективно, но, опять же повторюсь, это все можно использовать только в неких специфических условиях, когда у вас файлы на бэкенде не меняются. Если у вас файлы меняются, то вполне возможна ситуация, когда клиенту отдалась половина файла, потом файл поменялся и что делать дальше? Второй половины у нас просто нет. Сейчас nginx пытается отслеживать подобные ситуации и закрывать соединения, ругаясь громко, но, вообще, если у вас такое, то этот модуль вам не нужен. Это стоит использовать, когда у вас просто статика на бэкенде, и вы ее пытаетесь раздавать и кэшировать.
Пока суд да дело, SPDY умер, вместо него появился HTTP/2. Отличия есть, но небольшие. С точки зрения общей логики идея все та же – мы в рамках одного соединения мультиплексируем много запросов, за счет этого пытаемся экономить на установлении соединений и экономить latency. Как-то это работает, что-то это дает. Не могу сказать, что это работает хорошо с той точки зрения, что очень много всяких нюансов в реализациях, протокол новый, много кто делает неправильно, в том числе сам google делает в chrome неправильно. Мы им периодически пишем тикеты про то, что они эту часть протокола обрабатывают не так, ту часть протокола обрабатывают не так, встраиваем в nginx workaround для всего этого. Как-то оно работает, я лично не большой фанат этого протокола, в основном, потому что протокол бинарный, и это боль с точки зрения отладки и разработки.
Теперь его мы тоже нормально умеем, даже убрали некоторые ограничения, которые были раньше в SPDY, с точки зрения реализации в nginx. Если хотите, можете пробовать пользоваться. Наверное, многие уже пробовали и пользовались. Тема популярная, говорят про него много.
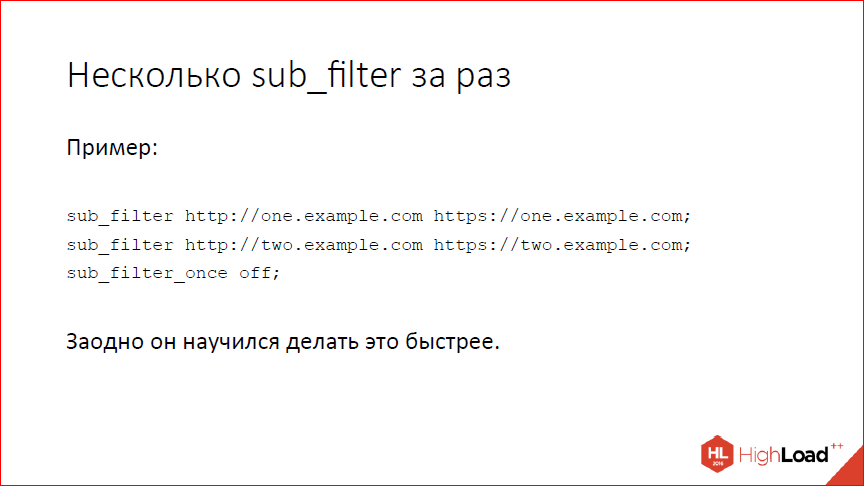
Научились несколько sub_filter’ов делать за раз, заодно sub_filter разогнали. Раньше не умели, это было плохо, а теперь умеем и это хорошо, с одной стороны. С другой стороны, если вы используете sub_filter, наверное, у вас опять же что-то не так в архитектуре. Для highload это плохое решение.
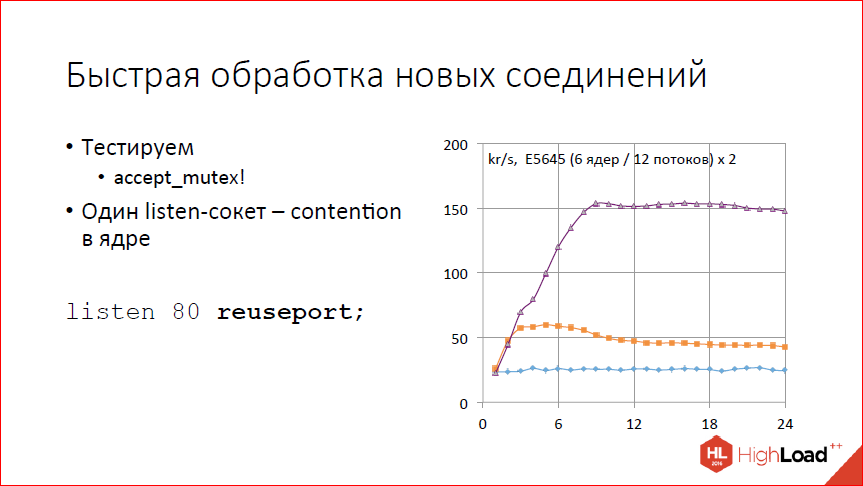
Разогнали слегка обработку новых соединений. Точнее говоря, сделали ручку, которая их позволяет обрабатывать быстрее. Смотрим на график. На графике тест количества обрабатываемых запросов в секунду в тысячах запросов от количества рабочих процессов. Видим, что совсем не скалируется. Почему так? Потому что у нас по умолчанию включен accept_mutex, и фактически у нас всегда работает один рабочий процесс. 25 тыс. соединений в секунду он как-то обрабатывает, а дальше не может, потому что все сериализованно.
Выключаем accept_mutex. Смотрим – где-то до 2-х рабочих процессов, может быть, до 3-х скалируется, 60 тыс. запросов в секунду выдает, дальше все становится только хуже с увеличением количества рабочих процессов. Почему так? Процессор у нас не кончился, но зато система начала лочиться на listen-сокете. У нас один listen-сокет, получаем contention просто на этом listen-сокете.
Как решать? Добавлять listen-сокетов. Простое решение. Можно добавить руками, разнести по IP-адресам, и все у вас будет хорошо. Если руками неудобно или невозможно, IP-адрес, например, один, теперь это можно сделать с помощью специальной ручки reuseport. Эта ручка позволяет nginx создавать для каждого рабочего процесса собственный listen-сокет, с помощью опции so_ reuseport.
Работает на Linux’е не очень хорошо, работает на DragonFly BSD хорошо, но, к сожалению, малопопулярная ОС. Если вы пытаетесь сделать это на Linux’е, стоит иметь в виду, что при изменении количества рабочих процессов у вас будут теряться соединения. Если вы уменьшили количество рабочих процессов, nginx один из listen-сокетов закроет. Если какие-то соединения в этом listen-сокете лежат, они закроются. Linux пока не умеет перераспределять эти соединения между другими сокетами.
С точки зрения производительности что получаем? Получаем вполне неплохое скалирование где-то до 8-ми рабочих процессов. Дальше опять полка. Почему полка? Потому что клиент на той же машине и ест вдвое больше, чем nginx. И когда у нас 8 процессоров заняты nginx, а остальные 16 заняты клиентом, больше машина не может – все, у нее процессор кончился. Если хочется больше, надо клиента на какие-нибудь другие машины выносить.

Еще одна большая вещь, которую добавили – это модуль Stream. Он позволяет балансировать произвольные соединения, не привязываясь к HTTP. В общем и целом, умеет почти то же, что и HTTP, но чуть попроще, чуть поменьше. Сейчас мы говорим про версии 1.9 и 1.10. Умеет балансировку произвольных соединений с теми же методами балансировки, что и у HTTP, Round-robin умеет, IP hash умеет. Умеет принимать SSL от клиентов, умеет устанавливать SSL к бэкендам. Умеет ограничивать количество соединений, умеет ограничивать скорость в этих соединениях, на бэкенд умеет через proxy-протокол отправлять адрес клиента. Даже умеет немного UDP, но так, чуть-чуть. Можно принять UDP-пакетик от клиента и отправить его на бэкенд, а потом обратно принять один или несколько пакетиков от бэкенда и отправить его обратно к клиенту. Если вам нужно, скажем, балансировать DNS, то, в принципе, можно сделать это с помощью модуля Stream. Если у вас что-то сложное на UDP, то, наверное, сейчас вам счастья не будет. Но зато произвольные TCP-соединения умеем в хвост и в гриву, как хотите.

И всякого разного по мелочи. Научили Resolver пользоваться не только UDP, но и TCP. Это позволяет работать нормально, если у вас больше 30 А-записей, и DNS-ответ не влезает в 512 байт UDP-пакета. Теперь Resolver может в этом случае увидеть, что там стоит битик truncate и пойти по TCP получить полный список. Если вы балансируете с использованием переменных имен и т.д. и используете Resolver, чтобы узнавать списки бэкендов, то вам это немного поможет. Блоки upstream теперь могут быть в разделяемой памяти. Это позволяет держать общий state между рабочими процессами. Т.о. если один рабочий процесс увидит, что ваш бэкенд умер, то все остальные об этом тоже узнают. Если у вас лист кон балансировка, и вы хотите минимизировать количество соединений к бэкендам, то, опять же, оно теперь не в рамках одного рабочего процесса работает и знает соединения только в конкретном рабочем процессе, но и знает все соединения по всему nginx.
Разделяемая память теперь работает на версиях Windows ASLR, т.е. Vista и новее. Если вы вдруг пытаетесь использовать nginx под Windows, вам это немного поможет. Но хочу заметить, что не надо использовать nginx под Windows в продакшне, пожалуйста. Это может быть очень больно. Он серьезно для этого никогда не точился.
SSLv3 мы по умолчанию выключили. Если очень надо можно включить, но, наверное, не надо.
Добавили переменную $upstream_connect_time, которая – сюрприз – показывает время, потраченное на установление соединения с бэкендом.
Умеем печатать полный конфиг по ключику «-T». Это, как показала практика нашего собственного support, очень важная и нужная фича, когда у вас траблшутинг, и вы пытаетесь разобраться, что у клиента не работает. Полный конфиг люди зачастую прислать просто не могут. Не понимают, где его брать. Мы этот процесс автоматизировали.
И научились выводить версию OpenSSL в выводе «-V». Причем, даже научились ее выводить не просто так, а смотреть, с какой версией OpenSSL nginx был собран и с какой будет сейчас работать. Если вдруг у вас nginx был собран с одной версией OpenSSL, а вы сейчас работаете с другой версией OpenSSL, он вам это покажет.
Собственно, более или менее все про ветку 1.9. Все это доступно в стабильной версии 1.10.2.

Что у нас появилось нового в 1.11. Это mainline-ветка, которую мы сейчас разрабатываем. Последняя версия 1.11.5. Что появилось?

В Stream появились переменные. Вообще, Stream усиленно развивается. Появились модули, которые умеют работать с переменными – map, geo, geoip, split_clients, real ip, access log, появилась возможность вернуть некий простой ответ из переменных или просто статическую строку return. Можно теперь делать всякие странные конструкции с помощью map’ов, limit_conn, чтобы применять ограничения избирательно. В общем, практически то же самое, что мы умеем делать в HTTP.
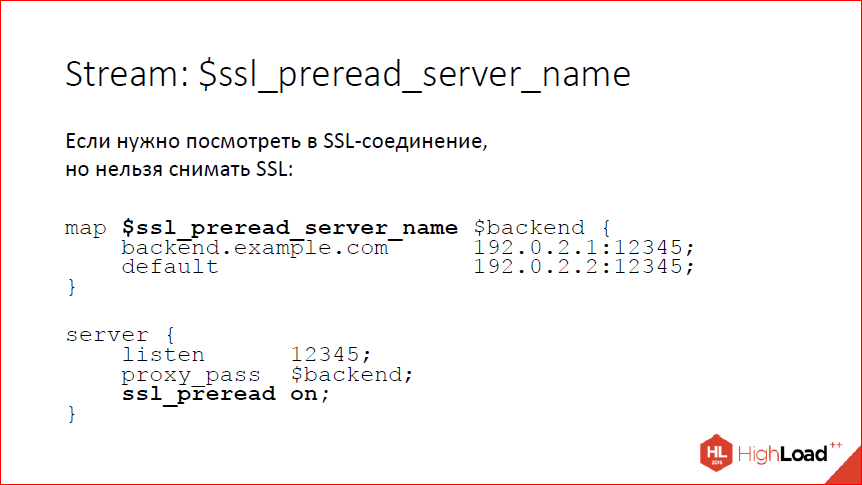
Опять же, в Stream мы научились заглядывать внутрь SSL-соединения, при этом, не снимая SSL. Зачем это может быть нужно? Вам может быть нужно посмотреть на server_name, который прислал клиент, и отправить клиента либо на один бэкенд, либо на другой бэкенд. Сейчас умеем вытаскивать из client_hello server_name. Есть для этого переменная, можно по этой переменной отбалансировать на один или другой бэкенд – на слайде пример, как это сделать. Это нужно включать явно, потому что по умолчанию мы, конечно, ничего не ждем. Если мы хотим дождаться client_hello, то включаем директиву ssl_preread, nginx дождется и, соответственно, будет переменная ssl_preread_server_name.
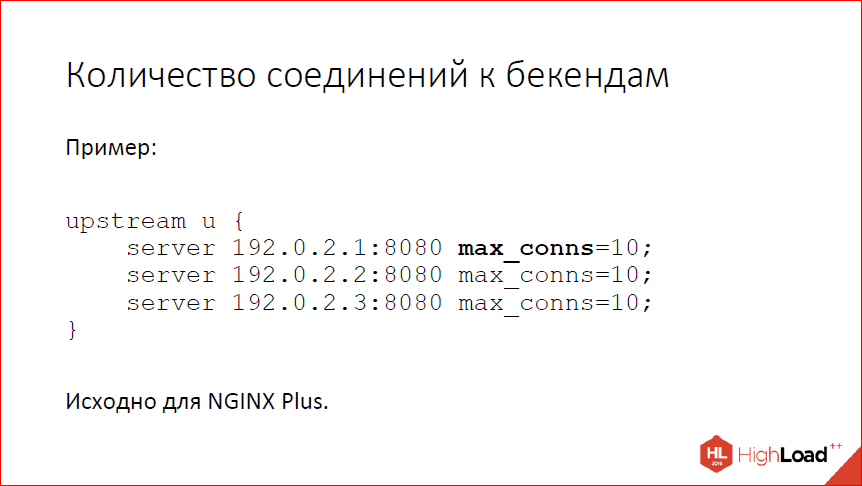
Научились ограничивать количество соединений с конкретными бэкендами, т.е. для каждого сервера вы теперь можете прописать max_conns, и nginx не будет открывать больше заданного числа соединений к данному бэкенду. Исходно это было сделано для NGINX Plus. Сейчас мы помержили open source просто для того, чтобы сделать людям приятно, с одной стороны, и таскать кастомного кода – с другой.

Научились работать в режиме transparent proxy. Обычно, если вам нужно передать адрес клиента на бэкенд, вы либо в HTTP используете заголовки с адресом клиента, либо, если речь идет про произвольные соединения, вначале соединения передаете заголовок proxy-протокола с адресом, портом. Это, к сожалению, не всегда возможно использовать, есть люди, у которых ничего из этого не работает. Есть люди, которые пытаются использовать nginx не со своими бэкендами, а просто внешний мир как-то проксировать.
Теперь можно в директиве proxy_bind сказать параметр «transparent», и она попытается сделать bind с нужной опцией для того адреса, который ей передали. Соответственно, если вы передадите туда remote_addr, т.е. адрес клиента, она сделает bind на адрес клиента. Соответственно, если вы построили сеть так, чтобы это все работало, то transparent proxy будет работать. Но для этого нужен root, для этого нужна специально построенная сеть. Вообще, если вы со своими бэкендами работаете, скорее всего вам лучше этого не пытаться делать. Может быть, это полезно со всяким legaсy-софтом, который обучить понимать X-Forwarded-For или X-Real-IP нереально.
Еще одна вещь, которой научились… Кто скажет, сколько соединений можно установить к одному бэкенду, если у нас есть один IP-адрес? Есть фронтенд с одним IP-адресом. Сколько соединений можно установить?

65 535 по количеству портов. Потому что destination-порт у нас один, а локальных портов, ну, максимум 65 535. Если у нас, соответственно, два бэкенда – 128 тысяч. Если у нас 10 бэкендов, то больше полумиллиона соединений можно установить, это не проблема.
А теперь пишем в конфиг «proxy_bind» и указываем IP-адрес. Наши полмиллиона портов при десяти бэкендах превращаются обратно в 65 тысяч. Почему так происходит? Происходит это потому что системный вызов bind делается до коннекта, то есть он не знает, куда именно мы будем коннектиться и он должен выбрать локальный порт. Поскольку куда именно мы будем коннектиться, он не знает, он должен выбрать локальный порт так, чтобы можно было потом законнектиться куда угодно, а всего локальных портов у нас 65 тыс. Соответственно, в 65 тысяч мы начинаем упираться, просто написав в конфиге «proxy_bind».
Как с этим бороться? Бороться с этим можно. На свежих версиях Linux есть специальная опция IP_BIND_ADDRESS_NO_PORT, которая говорит bind’у, что не надо ему выбирать локальный порт, мы его использовать не будем, клянемся, что не будем и, соответственно, операционная система не будет его выбирать, а сделает это как обычно в системном вызове connect, когда уже будет знать, куда именно мы хотим приконнектиться. Это опять возвращает нам наши многие тысячи соединений, даже если мы используем bind.

Следующий вопрос – accept mutex. Что, вообще, такое accept mutex? Это такая ручка для борьбы с проблемой thundering herd. Если у вас есть listen-сокет и много процессов, все процессы ждут событий на этом listen-сокете, т.е. ждут, пока придет клиент. Вот, клиент приходит, все процессы ждут, ядро все процессы разбудило. Клиент один, какой-то один процесс его забрал, а все остальные проснулись просто так, просто потратили процессор, погрели окружающий воздух, ничего полезного не сделали. Традиционный метод борьбы – это сказать только одному процессу, чтобы он слушал и ждал новых соединений, а все остальные пусть обрабатывают старые и о новых соединениях не беспокоятся.
Есть проблема с таким подходом. Ну, во-первых, у нас процессов не так много, чтобы это было как-то актуально, а, во-вторых, есть проблемы. Одну из проблем я показывал чуть раньше. Если мы забываем выключить accept mutex, то в наших тестах на количество соединений в секунду мы получаем полочку, которая никак не зависит от количества рабочих процессов, очень удивляемся. Ну, то есть, мы-то не удивляемся, потому что мы знаем, что это такое, а пользователи nginx зачастую удивляются, пишут нам письма с вопросами, иногда возмущенные, иногда публикуют бенчмарки про то, какой nginx плохой. Ну, в общем, нас это утомило – очень долго объяснять и бессмысленно, главное, потому что процессов так мало, вполне можно обойтись без всего этого.
Кроме того, accept mutex нельзя использовать на Windows, потому что на Windows у нас недопрограммирована нормальная работа с сокетами. Если вдруг вы запустили несколько рабочих процессов и включили accept mutex, то на Windows у вас все просто встанет колом. Точнее, сейчас не встанет, потому что accept mutex на Windows принудительно выключен и игнорируется. Даже если вы попытаетесь его включить, он все равно не включится.
При использовании listen reuseport accept mutex не нужен, потому что у каждого рабочего процесса свой listen-сокет. И, наконец, на свежих версиях Linux в ядре появился флаг EPOLLEXCLUSIVE, который позволяет сказать ядру, чтобы оно будило не все процессы, а только один. Это не для всех программ допустимо, потому что у вас может случиться какая-то другая активность, т.е. процесс разбудят, а он пойдет чем-то другим заниматься. В nginx это вполне работает. Так что мы accept mutex по умолчанию выключили, EPOLLEXCLUSIVE теперь поддерживаем.
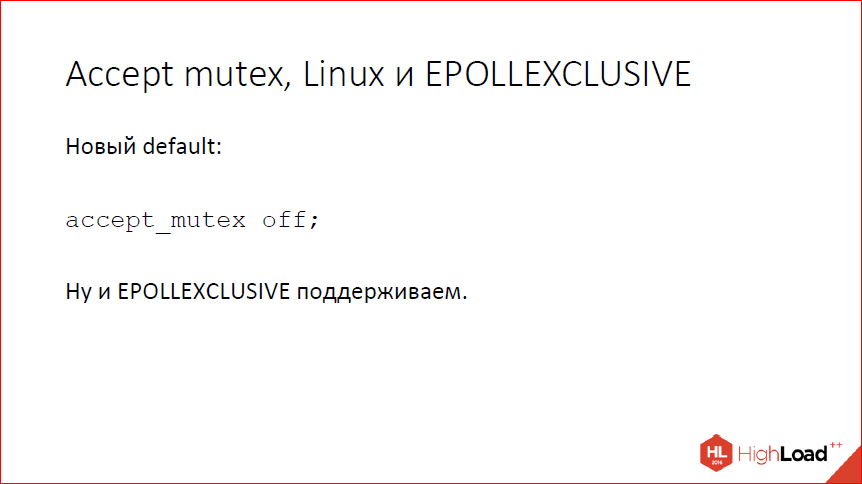
Так что если у вас совсем свежий Linux, вы ничего не потеряли, у вас сплошные плюсы, если у вас не Linux или что-то чуть более старое, то вы, в общем, тоже ничего не потеряли, у вас сплошные плюсы, потому что если вы будете запускать какие-нибудь бенчмарки, вы увидите реальное поведение системы, а не поведение accept mutex.
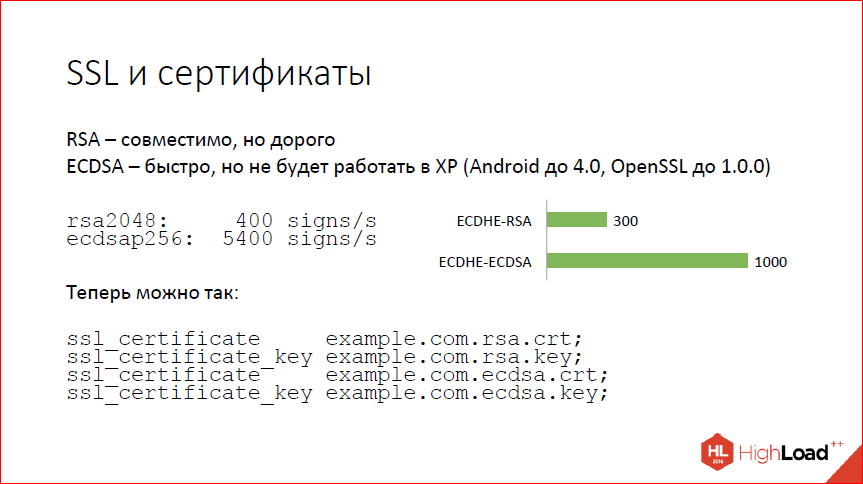
Следующий вопрос – SSL и сертификаты. SSL – это такая штука, где большая часть времени тратится на handshake. И handshake сводится к тому, чтобы проверить подлинность сертификата. Сертификаты бывают современные – RSA и ECDSA, т.е. на эллиптических кривых. RSA – это хорошо, но дорого, а эллиптические кривые – это быстро и, в общем, тоже хорошо, но не везде работает. В частности, не работает на Windows XP. Как показывают всякие сервисы статистики, Windows XP сейчас все еще от 5 до 10%. Так что, если переключитесь на ECDSA-сертификаты, вам будет несчастье, вы 5% клиентов потеряете. Наверное, если вы большая компания, вы себе не можете этого позволить.
Что делать? Вот циферки (на слайде). Запускаем по SSL speed, видим, что двухкилобитный RSA дает 400 подписей на ядре, мы можем сделать, а ECDSA – 5000 с лишним, и это не предел на самом деле. Это циферки от достаточно старой версии ОpenSSL. Конечно, когда вы поставите перед этим еще forward secrecy, все немножко ухудшится. На реальных handshake’ах с nginx циферки немного не такие впечатляющие, но все равно 300 handshake’ов в секунду в случае RSA, 1000 handshake’ов в секунду на ядре – в случае ECDSA. Рост в три раза.
То, что хочется получить, теперь мы умеем делать так. Вы можете сказать nginx’у: «Вот тебе два сертификата, работай с ними», и nginx их по мере необходимости будет предъявлять клиенту. Если клиент новый и умеет ECDSA, будет использоваться ECDSA, все будет быстро. Если клиент старый, то для него будем использовать RSA.
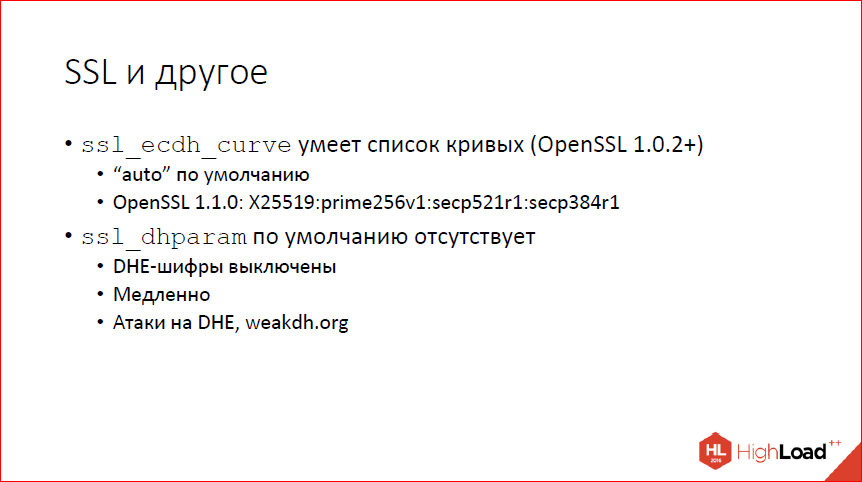
Кроме того, в SSL теперь можно задавать несколько кривых одновременно, если у вас достаточно свежая OpenSSL. По умолчанию, если раньше был prime256v1, теперь загадочное слово «auto». «Auto» зависит от того, какая именно версия OpenSSL у вас используется. В совсем свежем сначала будет кривая бернштейновская 25519, потом тот же самый prime256v1, который был раньше по умолчанию. Настоятельно рекомендую не трогать, просто имеет смысл знать, что такая ручка есть. Но трогать не надо.
dhparam – параметры для Диффи-Хеллмана обычного классического. По умолчанию мы теперь не предоставляем. Если раньше внутри nginx были защиты килобитные параметры, то теперь их нет, и по умолчанию у вас DHE-шифры, т.е. forward secrecy с использованием Диффи-Хеллмана выключены. Это на самом деле хорошо, потому что они медленные по сравнению с эллиптическими кривыми и есть все основания полагать, что существуют атаки даже на достаточно большую битность, потому что они поддаются предпросчету.

В динамических модулях существуют проблемы. В той реализации, которая в стабильной версии сейчас, проблема связана с тем, что структуры в nginx зависят от опции сборки. Nginx, если ему чего-то там не нужно, он это что-то из структуры убирает, позволяет сделать структуру поменьше, а nginx побыстрее. Это приводит к тому, что если вы собираете модуль, то собирать его нужно с теми же самыми опциями сборки, что и основной nginx, куда вы этот модуль собрались грузить.
В ситуации сборки пакетов это работает нормально. Когда вы собираете основной nginx и к нему множество пакетиков с разными модулями, вы можете контролировать опции сборки и собрать все одинаково. Это не всегда удобно, когда вы хотите свой модуль для каких-то произвольных пакетов подсобрать. Можно, но не всегда удобно. И, опять же, под каждую сборку nginx вам приходится делать свою сборку модуля. Теперь у нас есть специальная опция configure --with-compat, которая включает режим совместимости при динамической загрузке модулей, и все соответствующие поля, вне зависимости от опций сборки, в структурах nginx присутствуют. Соответственно, модули и nginx становятся бинарно совместимыми, даже если вы какие-то опции сборки поменяли, главное, чтобы среди опций был with-compat, тогда вы можете собрать свой модуль и загрузить в любой другой nginx, собранный тоже с опцией with-compat.
Кроме того, теперь можно так собирать модули и грузить их в наш коммерческий продукт NGINX Plus. Если раньше из-за той же самой проблемы собрать модули для NGINX Plus вы сами не могли, потому что там структуры другие внутри были, то теперь можете собрать сами свои модули и загрузить в наш коммерческий NGINX Plus.

И всякое разное по мелочи:
- EPOLLRDHUP на Linux. Теперь мы умеем на него полагаться, если видим, что ядро свежее, это экономит syscall’ы при детектировании, а не закрыл ли клиент соединение.
- HTTP/2 улучшаем, дополняем.
- Map научился работать с произвольными комбинациями переменных и строк.
- Для злопамятных людей появилась переменная $request_id, которая может использоваться для идентификации конкретного запроса.
Все это есть в 1.11.5. И разработка продолжается.

Свежий nignx можно скачать у нас на сайте. Если вы используете FreeBSD, можно поставить из портов, если вы используете Linux, то системные пакеты, скорее всего, у вас старые, хотя последнее время ситуация слегка улучшается. Мы предоставляем собственную сборку. Можно взять у нас на сайте. Для модулей, которые имеют внешние зависимости, у нас теперь отдельные пакеты с внешними зависимостями.
Спасибо за внимание!
Контакты
» mdounin@mdounin.ru
» Блог компании Nginx
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем HighLoad++.
Сейчас мы уже вовсю готовим конференцию 2017-года — самый большой HighLoad++
в истории. Если вам интересно и важна стоимость билетов — покупайте сейчас, пока цена ещё не высока!
