
Можно ли построить удобный для всех pipeline, приложив усилия один раз, а не 100? Об этом расскажет Виктория Вольферц. Она работает в БКС DevOps-инженером в управлении микросервисной архитектуры. БКС предоставляет брокерские и банковские услуги для клиентов. Их основные продукты — это мобильное приложение БКС Мир Инвестиций и веб-кабинет для клиентов.
Виктория поделится опытом своей компании, как им удалось решить проблему больших временных затрат на релиз-менеджмент и Time to Market с помощью подключения проектов к CI/CD. Она расскажет о том, как они автоматизировали процессы и закрыли слабые места.

CI/CD. Теория
CI/CD — это комплекс практик и инструментов, которые помогают автоматизировать сборку, тестирование и доставку новых версий разрабатываемого продукта конечным потребителям.
CI/CD состоит из двух практик:
CI – Continuous Integration (непрерывная интеграция), где происходит сборка и тестирование;
CD – Continuous Delivery/Deployment (непрерывная поставка или развёртывание).
Различие Delivery от Deployment в том, что при подходе Continuous Delivery придётся нажимать кнопку, чтобы задеплоить приложение на прод, а в Continuous Deployment это происходит автоматически.
На схеме представлен полный цикл CI/CD или как его ещё называют петля CI/CD:
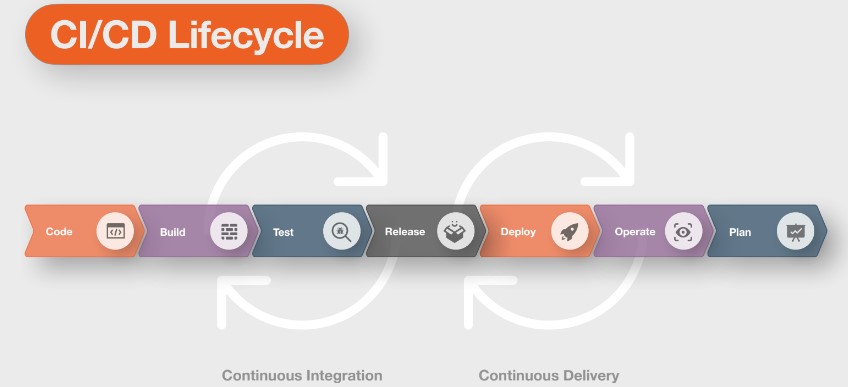
Он проходит в несколько этапов:
пишем код;
собираем;
тестируем;
получаем релиз кандидата;
деплоим на продакшен-сервера;
мониторим приложение;
планируем новые фичи или доработку функционала.
Как БКС жили до CI/CD

Был репозиторий проекта, в котором лежал только код микросервиса. В нём был файл gitlab-ci.yaml, индивидуальный для каждого проекта. После того как разработчик сливал свои изменения в feature branch, запускался небольшой pipeline. В нём было 5 job’s:
семантическое версионирование;
валидация коммита;
проверка кода;
сборка;
отправка артефактов в gitlab registry.
Чтобы обновить микросервис на продакшене, разработчик создавал merge request, в отдельном репозитории, где хранятся только helm charts всех проектов, с указанием новой версии приложения, которую он хочет доставить на прод. Далее, разработчик создавал задачу на DevOps’ов или писал в чат, что хочет задеплоить новую версию. DevOps-инженер проверял merge request, мёржил, и потом шёл руками обновлять сервис.
На всё это уходило от 20 до 180 минут. Потому что бывают пожары на продакшене, неполадки с инфраструктурой и прочим. Не всегда DevOps’ы могли в моменте обновить продакшен. Time to Market процесса был слишком высокий. Требовалось очень много ручных действий DevOps’ов. Поэтому решили разобрать процессы, автоматизировать и оптимизировать их.
Выявили ряд минусов.
Поддержка и дебаг gitlab-ci.yaml в каждом репозитории. Когда в БКС за 2 года стало 157 репозиториев, было невероятно сложно вручную настраивать каждый.
Отдельный общий репозиторий с helm charts, как результат — единый релиз. К примеру, есть 4 merge request с 4-мя разными сервисами. MR смёрджили, пошли обновлять, 3 из 4 поднялись успешно, один закрашился и не поднимается. Сразу делали helm rollback, откатывали релиз на предыдущий. Соответственно, вместе с тем, который не запустился, откатывались и те 3, которые успешно обновились — что не очень хорошо.
Требовалось много ресурсов команды DevOps на релиз-менеджмент и на настройку и поддержание репозиториев в актуальном состоянии, и как результат — неэффективный Time to Market.
Тогда в БКС собрали воедино все эти проблемы и придумали пути их решения.
Избавились от поддержки gitlab-ci.yaml файла в каждом репозитории. Некоторые разработчики любят добавить что-то от себя в gitlab-ci.yaml файл: прописать прокси или указать какие-то новые зависимости. И когда у них падает pipeline, они пишут DevOps’ам. В итоге каждый раз нужно было смотреть, что могли сломать в CI. На это уходило невероятное количество времени. Решили проблему так: удалили все gitlab-ci.yaml файлы со всех репозиториев сервисов и сделали в отдельном репозитории (с доступом только для devops) только два — один для Java, второй для .Net.
Автоматизировали настройки репозиториев. Подключили job, который автоматически проставлял нужные нам настройки в каждом репозитории.
Избавились от единого релиза для всех сервисов: 1 микросервис — это 1 релиз. Перенесли helm charts из общего репозитория в репозитории, где лежит кодовая база сервиса.
Убрали себя из цепочки обновления, доверив это тестировщикам команд. Потому что они — это последняя инстанция, которая может сказать, что код проверен, работает и можно обновляться.
Быстро подключили проект к CI/CD.
Pipeline в БКС стал состоять из 7 stages:

Автоматизация настройки и различных проверок. Это задача Repo Settings, чтобы настраивать дефолтные ветки, правила для merge request и прочее.
Сборка и проверка кода.
Публикация image и helm charts. Закрыли минус общего репозитория, перенесли helm charts в репозиторий с кодовой базой. Также их версионировали и сложили в Artifactory.
Релиз кандидата. Создание Gitlab Release (только для ветки master)
Деплой на тестовое окружение.
Деплой на продакшен.
Некий пост-продакшен для работы с уже запущенным подом в Kubernetes.
После этого время полного прохождения pipeline снизилось до 10 минут, максимум до 25 в зависимости от загруженности GitLab-раннеров. Сократилось и время Time to Market.
Как подключали проект к CI/CD
Зашли в настройки CI/CD в репозитории, указали путь до gitlab-ci.yaml файла:

Файл gitlab-ci.yaml лежит в отдельном репозитории и доступен только для DevOps-инженеров. Разработчик не может добавить туда новые строчки кода.
Прежде чем перейти к подробному описанию каждой job на каждом stage, поговорим об одной переменной, которую команда БКС внедрила в процесс CI/CD. Это переменная $TEAM, она указывает к какой команде принадлежит проект. БКС её придумали и используют почти во всех jobs, которые запускаются в pipeline.

Как зародилась идея?
Раньше был чат, куда приходили алерты по всем сервисам от мониторинга Grafana. В БКС решили добавить в этот чат всех разработчиков команд, чтобы они тоже были в курсе, что происходит с их сервисами. Но разработчики не хотели видеть алерты по сервисам чужих команд , потому что им это не нужно. Они желают видеть только свои сервисы, чтобы не упустить что-то важное. Поэтому приняли решение добавить переменную $TEAM, название команды, внесли ее в variables каждого репозитория (Settings - CI/CD - Variables). И в deployment начали ссылаться на данную переменную в лейблах.
Благодаря этому получили некий якорь. Кто работал с Grafana, знает, что невозможно написать выражение, не имея какого-то якоря, который вытащит сервисы, разрабатываемые конкретной командой, приходится хардкодить руками. Чтобы этого не делать в БКС просто имеют лейбл в deployment.
Stage 1. Continuous Integration
Приступим к разбору заданий, которые запускаются в рамках CI.
Job 1. Repo Settings
Цель — автоматизировать все настройки репозитория, которые раньше делали вручную и исключить ошибки при его создании.
Действия:
Проверка наличия и корректности переменной $TEAM.
Создание dev branch.
Настройка правил для Merge requests.

Автоматизация запускается сразу после создания репозитория. Единственное, что в БКС делают руками — это сами вносят переменную $TEAM в проект. Поскольку никто, кроме человека, не знает, какая команда разрабатывает тот или иной сервис.
Далее проверяют, что 100% внесена переменная $TEAM, поскольку она используется во многих заданиях. Создают default-ветку (dev) и настраивают правила для merge requests. Обязательно должен быть успешно выполнен pipeline и закрыты все discussions.
Job 2. Badges
Цель — быстро понять к какой команде принадлежит проект и отобразить статус последнего запущенного pipeline на default-ветке.
Действия:
Создание badges с названием команды ($TEAM).
Добавление badges из Sonarqube через API.

Badges - информативные плашки в проектах, в которые можно вывести любую нужную информацию. Первый badges, который создали в БКС — это badges TEAM, чтобы просто заходить в проект и сразу видеть, к какой команде он принадлежит. Тем самым избавили аналитиков от рутинной работы ведения списка ответственных команд в Confluence. Теперь из variables проекта тянется переменная TEAM, создаётся кастомный badges с помощью утилиты Anybadge. Этот проект есть на GitHub.
Также в БКС тянут уже готовые badges с SonarQube, которые показывают статус последнего пройденного pipeline на default-ветке проекта. Теперь главная страница выглядит информативно.
Job 3. Sentry
Цель — узнавать о проблемах раньше, чем клиент напишет в поддержку, находить источник ошибки и причину, связывать релиз микросервиса с ошибками.
Действия:
Создание команды ($TEAM) и проекта.
Настройка интеграции для отправки алертов в Rocket Chat.
Запись переменной SENTRY_DSN в проект.
Sentry — это суперкрутая программа для агрегации exceptions, для работы с ошибками. Здесь можно по stack trace определить, какая строчка кода могла создать проблему в сервисе. В Sentry есть абсолютно всё. Виктория считает, что это серебряная пуля в мониторинге микросервисов и не только. Её используют как веб-разработчики, так и DevOps.

БКС создают команду в Sentry, к ней привязывают проект, чтобы слать алерты только по сервисам, которые разрабатывает та или иная команда. Далее настраивают webhook, в случае БКС это webhook для Rocket Chat (корпоративного мессенджера) и записывают переменную SENTRY_DSN в проект. Это ссылка, по которой микросервис понимает, куда ему нужно отправлять алерты.
Job 4. Must Have Check
Цель — проверять то, что важно.
Действия:
Запуск простой проверки, написанной на bash, проверка наличия файлов/строк.
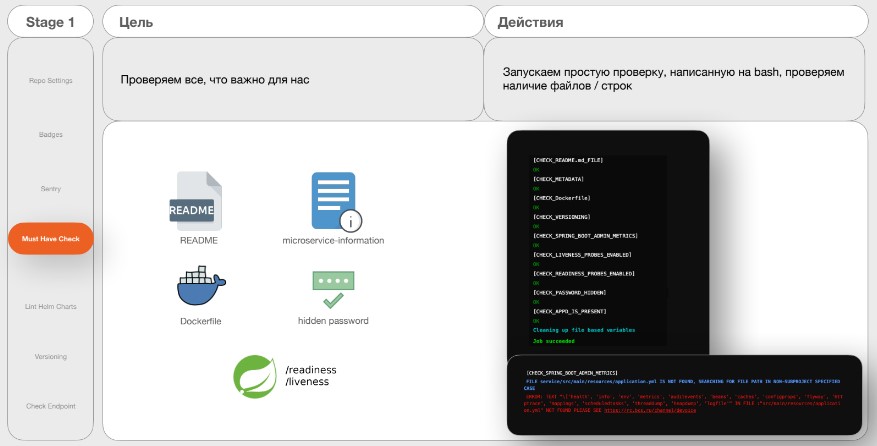
К примеру, проверка описания проекта, Docker-файл. Всё, что похоже на пароли, должно быть замаскировано, либо лежать в секретах в Vault, то есть не должно быть никаких открытых паролей. Также подключение проб готовности пода: /readiness, /liveness; скриншоты успешного или неуспешного прохождения. В случае неуспешного прохождения выходит ошибка с информацией чего не хватает и где посмотреть. В данном случае это канал DevOps, где написана вся важная информация.
Job 5. Lint Helm Charts
Цель — проверить, что helm charts написаны верно, нет ошибок рендера.
Действия:
Использовать helm template, helm lint.
Проверить для всех окружений.
Запустить при любом изменении в директории helm/.

Нужно проверить, что все переменные, объявленные в сущностях в папке template, 100% есть в values-файлах. Для этого все values-файлы для тестового окружения, pre-prod и продакшена прогоняют через helm template и получают готовые helm charts для трёх окружений. Проходят по ним Helm Lint — всё, проверили!
Это задание запускают не просто так, а только при изменении директории helm.
Job 6. Versioning
Цель — рассчитать версию кода микросервиса и связать её с определённой версией сборки helm charts.
Действия:
Семантическое версионирование.
Добавление ревизии — версии сборки helm charts.

В БКС есть шаблон написания коммита, который соблюдают разработчики:
LK-***[TYPE]: description commit
Здесь:
*** — номер задачи в Jira;
TYPE — масштаб изменений.
Масштаб изменений может быть разным. Ранее уже было внедрено семантическое версионирование на основе трёх обязательных номерных версий: MAJOR — новый сервис; FEATURE — крупный блок нового функционала; MINOR — небольшие изменения. Также добавили коммит BYPASS. Он используется для всех коммитов на фиче ветки, кроме первого, то есть он не влияет на расчёт версии.
После перехода на CI/CD, была добавлена ревизия. Это число, которое идёт через дефис после основной версии. То есть версия сборки helm charts. Всё это также версионируется, привязывается к определённой версии сервиса. Предыдущие нигде не хранятся.
Версионирование работает так: каждый раз, когда запускается эта задача, счётчик равен 0000. В БКС в хронологическом порядке берут все commit message, высчитывают, какая должна быть версия кода и charts. В результате получаются две переменные:
APP VERSION 1.3.12, которая включает в себя только версию кодовой базы;
CHART VERSION 1.3.12-22 — кодовая база плюс версия сборки helm charts.
То есть привязывают рабочую версию приложения к charts. На выходе получается 100% рабочая сборка.
Job 7. Check Endpoint
Цель — не сломать продакшен.
Действия:
Отрисовать с помощью helm template готовый Ingress-манифест в текущем проекте.
Получить через API-kubernetes все пути, которые есть на проде по всем сервисам.
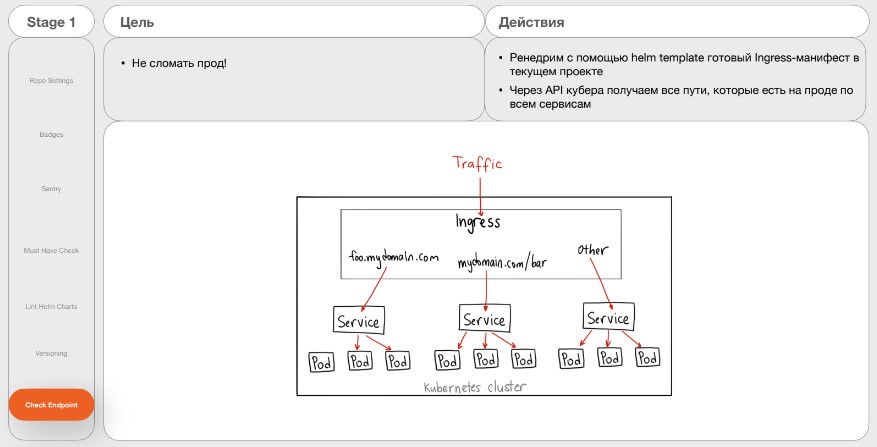
Есть трафик от клиентов и Ingress-контроллер, который маршрутизирует трафик по сервисам в Kubernetes. Поскольку микросервисов в БКС очень много, невозможно вести страничку в Confluence, где будут указаны все endpoints. Чтобы аналитики или разработчики, когда придумывают, по какому endpoint будет доступен сервис на проде, заходили и смотрели, что сейчас такого же нет.
В БКС написали эту задачу сами на Python. Они рендерят с помощью Helm Template готовый Ingress-манифест. Через API Kubernetes дёргают все endpoints, которые сейчас существуют на проде по всем namespaces. Сравнивают в текущем сервисе, какие придуманы новые, и всё, что есть. Если находятся совпадения, то пишут ошибку в job, что endpoint такой же, как в этом сервисе. Дальнейшие задания не запускаются, пока не будет исправлено.
Stage 2. Сборка и проверка кода
Job 1. Build
Цель — получить артефакт сборки кода.
Действия:
Использовать подход Docker in Docker.
Компилировать код проекта — результат .jar-файл.
Выполнить unit-тесты.
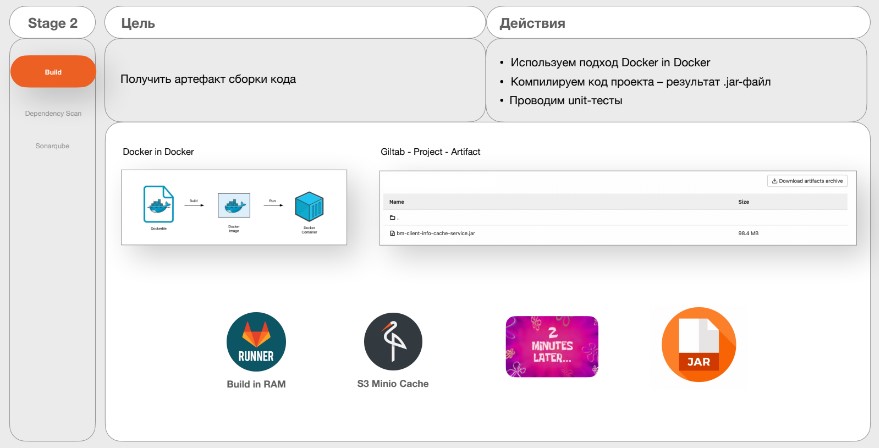
Здесь используют подход Docker in Docker, компилируют код, проводят unit-тесты и складывают в GitLab Registry. Совсем недавно БКС добавили надстройку на GitLab-раннерах, чтобы сборка осуществлялась в оперативной памяти, так как они не используют хранилища. Добавили ещё S3 Minio Cache. Буквально через 2-3 минуты получился собранный и проверенный артефакт.
Job 2. Dependency-scan and SonarQube
Цель — проанализировать качество кода микросервиса и проверить зависимые библиотеки на известные уязвимости на основе данных из NVD.
Действия:
Автоматически создать проект с настройками Quality Gate и Quality profile при первом запуске SonarQube.
По результатам Dependency Scan сгенерировать отчёт и отправить в SonarQube.

SonarQube сам проверяет код, Dependency Scan проверяет все подключённые библиотеки в микросервисе на известные уязвимости на основе БД уязвимостей NVD. Если какая-то уязвимость находится в рамках Dependency Scan, он складывает это всё в SonarQube. Далее генерирует этот артефакт в формате JSON и также через API посылает его в SonarQube.
На картинке указана уязвимость из интернета — Log4j, которую в БКС исправили:

Stage 3. Публикация
Job 1. Publish Helm Charts
Цель — упаковать helm charts и отправить в Artifactory.
Действия:
helm package —app-version=1.3.12—version=1.3.12-22;
отправить в Artifactory.
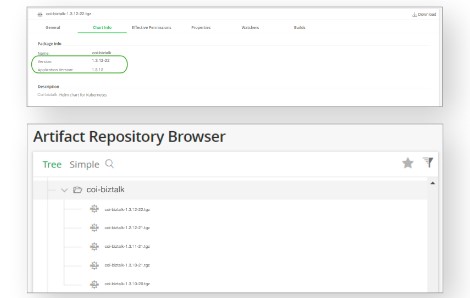
В БКС используют утилиту Helm Package, указывают APP version — версию кодовой базы и ревизию charts (версия сборки helm charts).
Job 2. Publish Image
Цель — собрать готовый docker-образ микросервиса.
Действия:
Вычислить тип коммита — собрать образы.
Отправить в Gitlab Registry.
Здесь собирают Docker-образы и складывают их в GitLab Registry по стандартной практике.
Stage 4. Релиз
Цель — связать релиз (версию микросервиса) с задачей в Jira, для отслеживания истории изменений.
Действия:
Использовать Gitlab Release API.
Создать релиз, включающий в себя: исходный код репозитория; ссылку на задачу, в рамках которой были внесены изменения в код и собрана новая версия; ссылку на созданный tag.

На данном этапе БКС создают единую страничку в GitLab, где будет вся информация по релизу, кодовая база, ссылки.
Благодаря тому, что есть единое описание коммитов, которое выглядит как: LK-***[TYPE]: description commit, можно сделать ссылку на задачу в Jira. В релизе есть исходный код, ссылка на задачу, по которой были внесены изменения. На неё можно кликнуть, попасть в Jira, посмотреть, какие изменения были, что за задача, кто заказчик и прочее. Также посмотреть все изменения в коде и все коммиты. На этом стадия Continuous Integration завершена.
Stage 5. Continuous Delivery
На этом этапе происходит деплой на тестовое окружение.
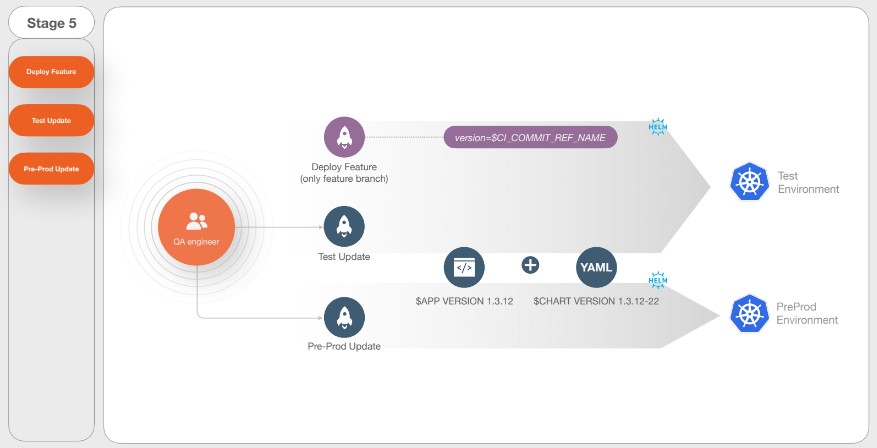
В БКС права есть только у тестировщиков. Но разработчики, хотят выкатывать прямо с фичи-ветки, задеплоить и проверить, как работает их код. Поэтому в БКС сделали кнопочку Deploy Feature. Она доступна только для разработчиков. Здесь не присваивается никакой номер версии, используют как версию имя фичи ветки.
Для деплоя на тест, есть Test Update и Pre-Prod Update. Здесь уже деплоится непосредственно версия, которая собралась и рассчиталась в рамках ранее пройденных job.
Stage 6. Production

Есть кнопка Prod Update, доступная только для тестировщиков. Также, в БКС есть основной и резервный namespace. Для чего? Некоторые сервисы должны смотреть, например, на два разных сервера для торгов, поэтому их задублировали в двух разных окружениях. Получается, нужно обновлять одновременно основной продакшн namespace и резервный.
Если этот сервис задублирован на втором окружении, когда нажимают на кнопку Prod Update, в БКС проверяют, что на основном окружении все поды успешно поднялись. Они ждут какое-то время, и только потом запускают обновление на резервном окружении.
Чтобы понять, что сервис задублирован, в БКС добавили в variables проекта переменную, которую чекают в начале задания. Если она есть, то понятно, что сервис задублирован.
Следующая job — это Prod Rollback. В рамках неё откатывают релиз на предыдущий. Эта кнопка тоже доступна только для тестировщиков в случае неуспешного выката.
Последняя кнопка Prod Remove — это полное удаление релиза. Она нужна в pipeline, потому что бывает такое, что микросервис просто устарел. Эта функциональность не нужна и этот процесс не развивают. Чтобы не идти в консоль и не делать ничего руками, было решено тоже это автоматизировать. Кнопка доступна только для DevOps-инженеров.
Stage 7. Post production
Цель — получить Thread/Heap dump с запущенного пода Java-микросервиса для дебага утечки памяти.
Действия:
запустить pipeline на любой ветке (var $POD);
кинуть оповещение команде в чат.
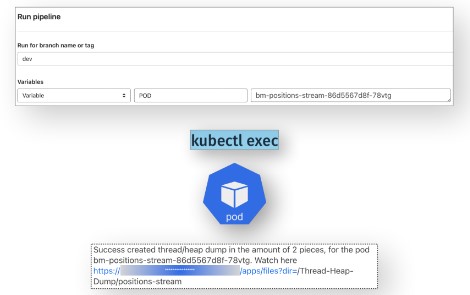
Эта кнопка в БКС появилась после того как, разработчики начали приходить с просьбой снять Thread или Heap dump с Java-машины, с уже запущенного пода на проде. Например, к ним приходили алерты, что память сервиса ушла в потолок или был низкий RPS. Возникла потребность это дебажить, смотреть распределение потоков. На всё могло уйти от 5 до 15 минут, в dump уже могло не оказаться нужной информации. Требовалось ускорение процесса. Поэтому решили его автоматизировать.
Эта задача запускается на любой ветке проекта. Разработчик сам может запустить pipeline с указанием переменной пода, с которой он хочет снять dump. Далее запускается команда удалённого управления. В рамках прохождения job снимается dump, складывается в хранилище и направляется алерт в чат команды, в котором указана информация: какие dump сняты; их количество; с какого пода. Также в алерте есть кликабельная ссылка, по которой можно пройти и скачать dump. На это уходит буквально 1-2 минуты.
Итог
Для уменьшения времени на релиз-менеджмент и сокращения Time to Market команда БКС сделала следующее:
Автоматизировали всё, что можно, кроме добавления переменной в самом начале.
Закрыли слабые места — такие, как единый релиз и пересечение путей API gateway на проде.
Написали два универсальных gitalb-ci.yaml файла для разных языков.
В итоге довольны все — DevOps-инженеры, разработчики, клиенты, бизнес. Хочется сделать вывод, что автоматизация является одним из ключевых принципов DevOps. Всё, что не автоматизировано, приходится каждый раз делать руками.
Как говорил Авраам Линкольн:
«Дайте мне шесть часов, чтобы срубить дерево, и я потрачу первые четыре на заточку топора»

