
Привет! Меня зовут Олег Мифле. Одной из команд, где удалось поработать за 7 лет с PHP, стала Customer Support. Мы автоматизировали анализ тысяч задач в день и оператору больше не нужно думать и включать голову для того, чтобы понять, какая задача прямо сейчас важна. О том, как работает приоритизация и что такое дерево игры, расскажу в статье.
На старте погружу в предметную область. Она непростая, но постараюсь быстро. Эта статья по моему докладу с PHP Russia 2022. Вот запись.
О внутренней кухне Customer Support Service
CSS — это критически важная часть операционки. В тикетную систему попадают обращения пользователей (учеников школы) и обращения преподавателей. Это могут быть как технические вопросы, так и просто боль или пожелания.
Не только операторы технической поддержки работают с системой, но и операторы продаж, операторы, которые звонят и «будят» давно не занимавшихся студентов и так далее. Если бы тикетная система вышла из строя, то встала бы вся операционка.
CSS — это уже около 8 миллионов закрытых задач. 5000 операторов, примерно 100 задач в день на каждого и 350 000 задач в месяц (около 5 минут на задачу). Если попробовать свести расчеты, то они не сойдутся, потому что нагрузка не линейная: какие-то операторы закрывают больше 100 задач, а какие-то не закрывают ни одной, потому что им нужно глубже погрузиться в кейс.
Жизнь до собственного продукта
Сначала был «зоопарк». Мы использовали Google-таблицы и облачные сервисы Usedesk и Omnidesk.
Главные проблемы того времени:
Долгий и дорогой онбординг новых операторов — попробуй разобраться в множестве платформ.
Все задачи ставились вручную — тимлиды операторов ходили по выгрузкам, собирали и расставляли задачи. Это неудобно и повышало риск ошибки.
Отсутствовала гибкой системы приоритетов. В лучшем случае, это было «first in, first out». В худшем — оператор сам выбирал, какую задачу ему решать. История ненадежная и порождала фроды.
Сложно строить прозрачную аналитику. Или хотя бы какую-то аналитику, потому что далеко не каждый сервис предоставляет доступ к своим данным по публичным путям. Или дают, но в обрезанном виде.
Сложно разделять доступ. Каждый оператор тикетной системы мог видеть любую задачу, в том числе ту, над которой уже кто-то работает.
Лимит по производительности — облачные решения в основном рассчитаны на какие-то средние компании. Когда мы залезли со своими мощностями, все начало дико тормозить.
И это не все. Когда приходишь к разработчику облачной системы и говоришь: «Нужны такие-то фичи, мы хотим приоритизировать», то будь добр, подожди полгода.
Нам это не понравилось и мы решили попробовать сделать свой инструмент. Посчитали, прикинули, собрали MVP, запустили первые группы и процесс пошел. Начали запускать еще и еще.
В итоге, получилось вот что:
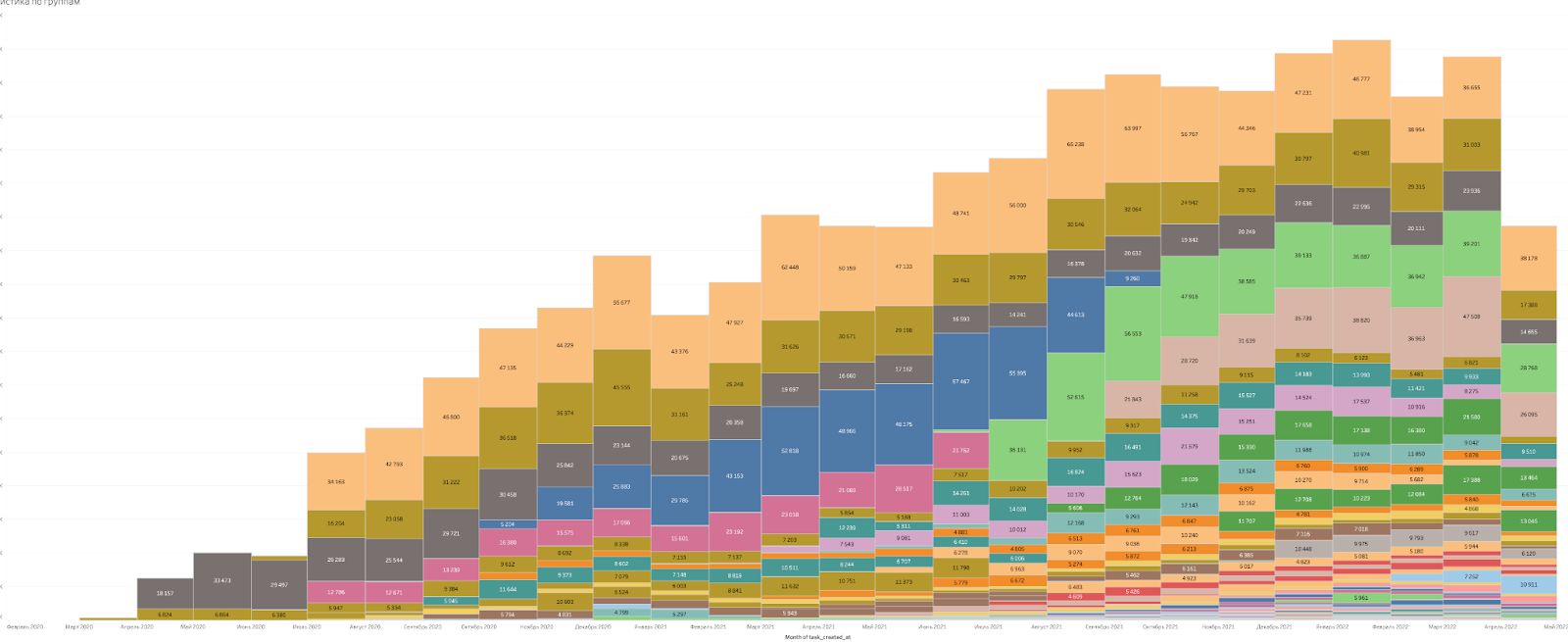
Каждый кубик — это группа операторов и количество задач, которое они решают в месяц: от пары сотен до нескольких сотен тысяч.
Разбираемся с понятиями
Оператор — слово всем знакомое. Он обрабатывает задачу и взаимодействует с нашей системой.
Группа операторов — это объединение людей по скоупу задач. Например, операторы поддержки, продажники, операторы, которые поддерживают преподавателей, и так далее.
Шаблон задачи — паттерны поведения задачи, по которым мы запускаем бизнес-процесс.
Сама задача, она же тикет, вокруг чего наша система построена.
Задача включает в себя время на обработку, за которое оператор должен взять задачу и закрыть ее. Общее время на выполнения задачи (учитываем время в бэклоге) — наш коммит перед пользователем, что за это время мы дадим ему ответ.
Далее, конфигурационные опции. С их помощью можно поменять поведение конкретной задачи. Мы можем собирать интерфейсы как из кубиков благодаря этим опциям, можем менять поведение при обработке задачи.
Резолюции — это причины, по которым задача может быть завершена. Метки — с помощью них размечаем нашу задачу понятным образам, чтобы потом анализировать, что происходило и как мы ее разбирали.
Если представить верхнеуровнево, то вот у нас есть входящие потоки: звонки, почта, триггеры, результаты, задачи. Под блоком API скрыт не только Rest, но и разные асинхронные способы взаимодействия. Далее мы пытаемся определить тип задачи и группу, которая будет эту задачу обрабатывать. И уже потом приоритезируем задачу, кладем ее в бэклог, где она дожидается своего часа.

О приоритизации детальнее
Наш сервис прошел много стадий по изменению приоритизации. Сначала это был простой запрос в базу данных: достаем с сортировкой по типу, по дате создания первую попавшуюся задачу.
Вы можете справедливо спросить, чем же это лучше облачных сервисов, где был first in, first out? Как минимум тем, что есть возможность контролировать то, какая задача попадет оператору, грубо говоря, на стол. Мы можем менять этот процесс и управлять им.
Такой запрос пожил у нас какое-то время, но потом оказалось, что мы упираемся в коллизии. Операторы брали задачи друг друга или могли взять задачу по пользователю, по которому уже идет работа. А двойное касание часто вызывает негатив у клиента.
Окей. Отфильтровываем лишние задачи по типу (считаем одни приоритетными больше, другие приоритетными меньше) и продолжаем жить дальше. Но с ростом системы увеличивается и количество типов задач и получается, что менее важные никак с ID не сопоставляются — фильтровать уже не получится.
Что делаем дальше? Мы разбиваем задачи по важности, составляем карту весов, обычный массив, и добавляем новую колонку «вес» в таблицу с задачами. Сортируем по уже рассчитанному заранее весу.
Допустим, нам попадает задача «проблема с подключением». Дальше магия, мы обогащаем задачу данными, находим группу и все, что я рассказал до этого, доходит до расчета приоритетов.
Пусть вес задачи по умолчанию, например, 10. Мы возвращаемся к вопросу о причине открытия: новая ли это задача или задача уже была обработана и требуются какие-то действия дополнительно, перезвонить или допустим задача пришла из другого отдела и так далее. Это все тоже влияет на приоритет.
В целом, формула будет примерно такая: Тип задачи плюс вес резолюции.
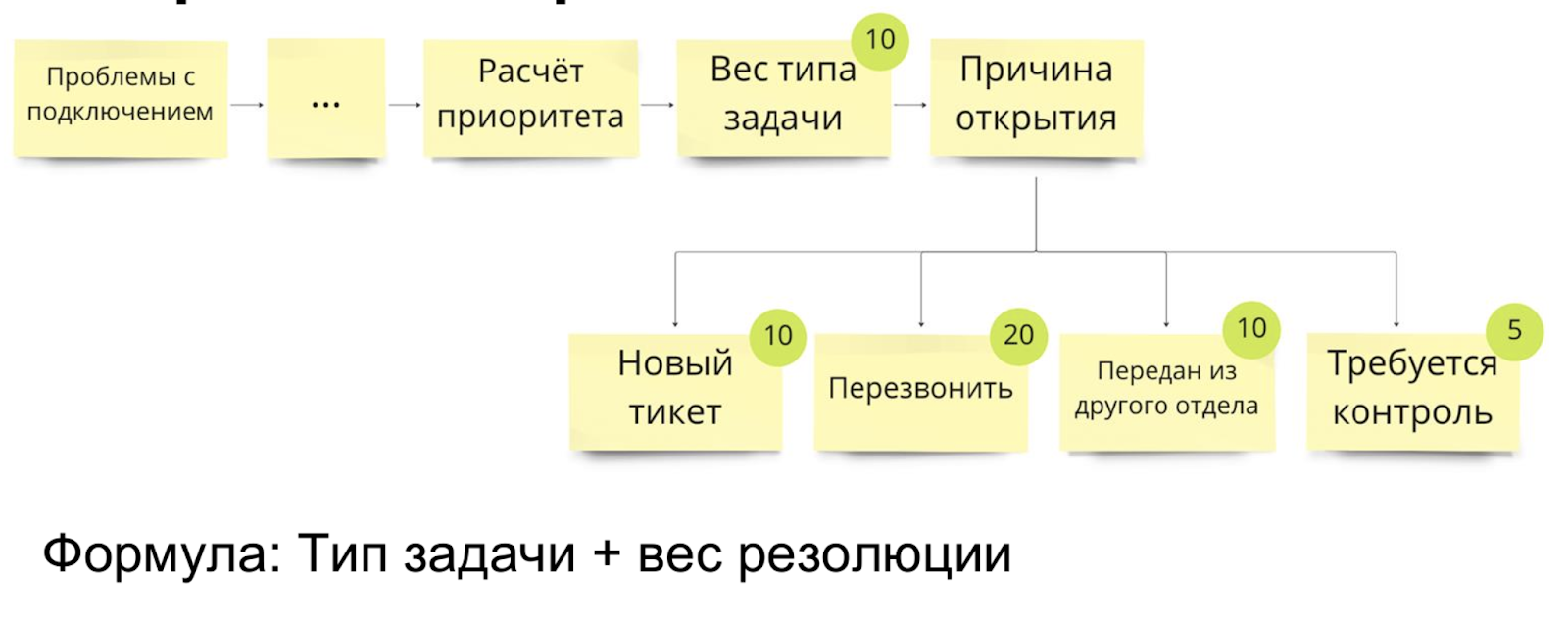
В таком воплощении можно жить долго, но оказалось, что для разных групп операторов критичность выражается по-разному.
Просто так «в лоб» взять и посчитать одинаково технические проблемы не получится, потому что надо понимать контекст. А контекст может быть разным. Например, идет урок и критически важно пойти и починить проблему. А если в процессе вводный урок, то его нужно спасать еще быстрее, потому что это продажа продукта. Кто бы хотел заниматься в системе, у которой на самом старте начались проблемы и к вам никто не пришел и не помог?
Таким образом, даже тип задач может иметь разный приоритет в зависимости от контекста.
Теория игр
Да, можно пойти в машинное обучение, но это дольше и дороже. Поэтому обратились к «дереву игры» — разновидности теории игр. У нас есть листья и ребра. Мы взвешиваем листья и тем самым пытаемся найти максимально выгодный для нас ход решения.
Из вариантов:
Игры с полной информацией, где в любой момент времени нам известно, что было. Мы можем рассчитать, что будет дальше и какие ходы можно предпринять. Классический пример игры с полной информацией — «крестики-нолики», «шашки», «шахматы».
Игры с неполной информацией — те игры, где в какой-то момент времени может иметь место случай. Это практически любая карточная игра или же игра в кубики.
Основные понятия у дерева игры — это правила игры, по которым мы будем играть, и сами игроки.
Начальная позиция — из нее мы начинаем ветвление графа.
Позиция игры, то есть то, что получилось в конкретный момент времени.
Партия — это один тур игры двух игроков. Ход игры изменяет позицию.
Заключительная позиция, когда продолжение невозможно, когда кто-то либо проиграл, либо выиграл, либо же ничья.
Возьмем крестики-нолики, когда мы играем за игрока MAX, а наш соперник играет за игрока MIN.

Нужно найти лист с наиболее выгодным для нас весом и с наименее выгодным для соперника. Можно представить, что в случае победы мы назначаем листу 5, в случае поражения — -5, в случае ничьей — 2, а когда ничего не понятно — 0.
Посчитав, где для нас будет наиболее выгодный результат, можно понять, куда двигаться для победы.
Это походит на то, что нам нужно. Но вот момент — у нас нет игроков. Нет стороны, которая явно победила или проиграла от того, что мы обработаем не ту задачу. Зато есть задачи, которые конкурируют между собой. И нужно найти ту единственную, которая прямо сейчас принесет максимальный профит школе и ученикам.
Итак, вернемся к реальной жизни.
Есть такое понятие как стратегия. У каждой группы свои критерии важности. Мы выделяем их и объединяем в стратегию для расчета приоритета задачи каждой группы.
Эта схема нам уже знакома:
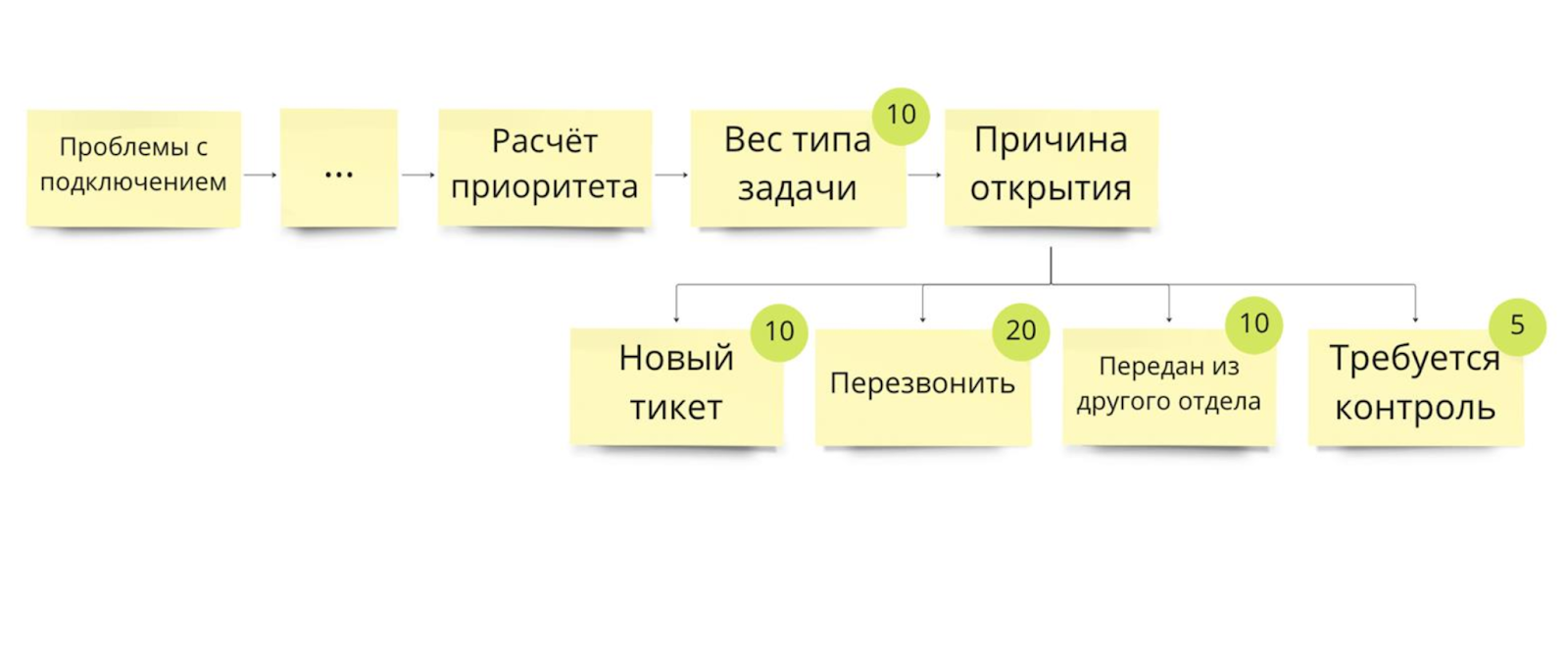
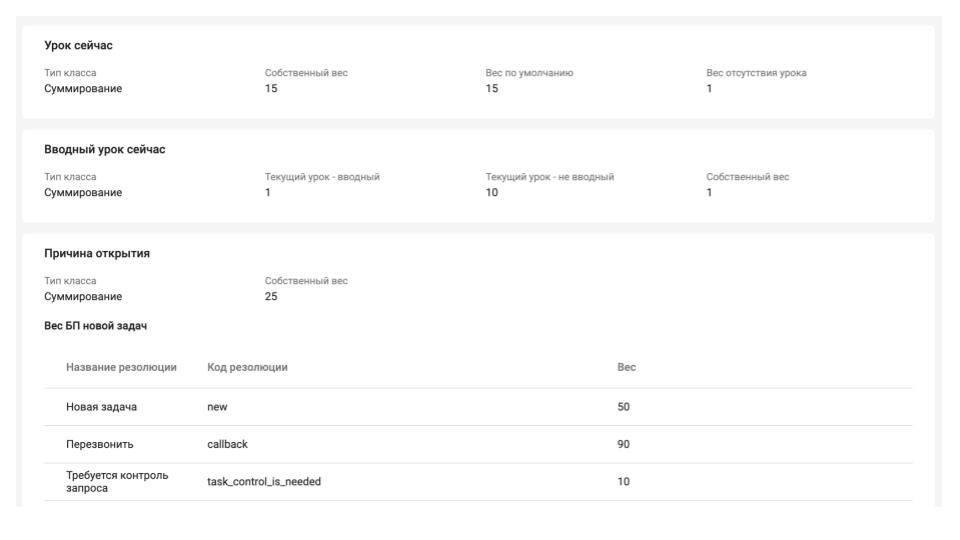
Допустим, есть вес задачи и причина открытия. Представим, что у нас новая задача. Мы добавляем новый коэффициент, новую причину, по которой нужно эту задачу чуть больше поднять в бэклоге.
Рассмотрим на примере тикета «Проблема с подключением».
Допустим, сбой случился во время урока. Это проблема, которую нужно быстро эскалировать до оператора. Сразу же проверяем, какой урок идёт: регулярный или вводный. Это разные процессы, управляют ими разные сервисы и отделы школы. Вводный урок приоритетнее для спасения, так как это новая продажа.
Расчёт приоритета такой задачи для вводного урока можно представить следующим образом:
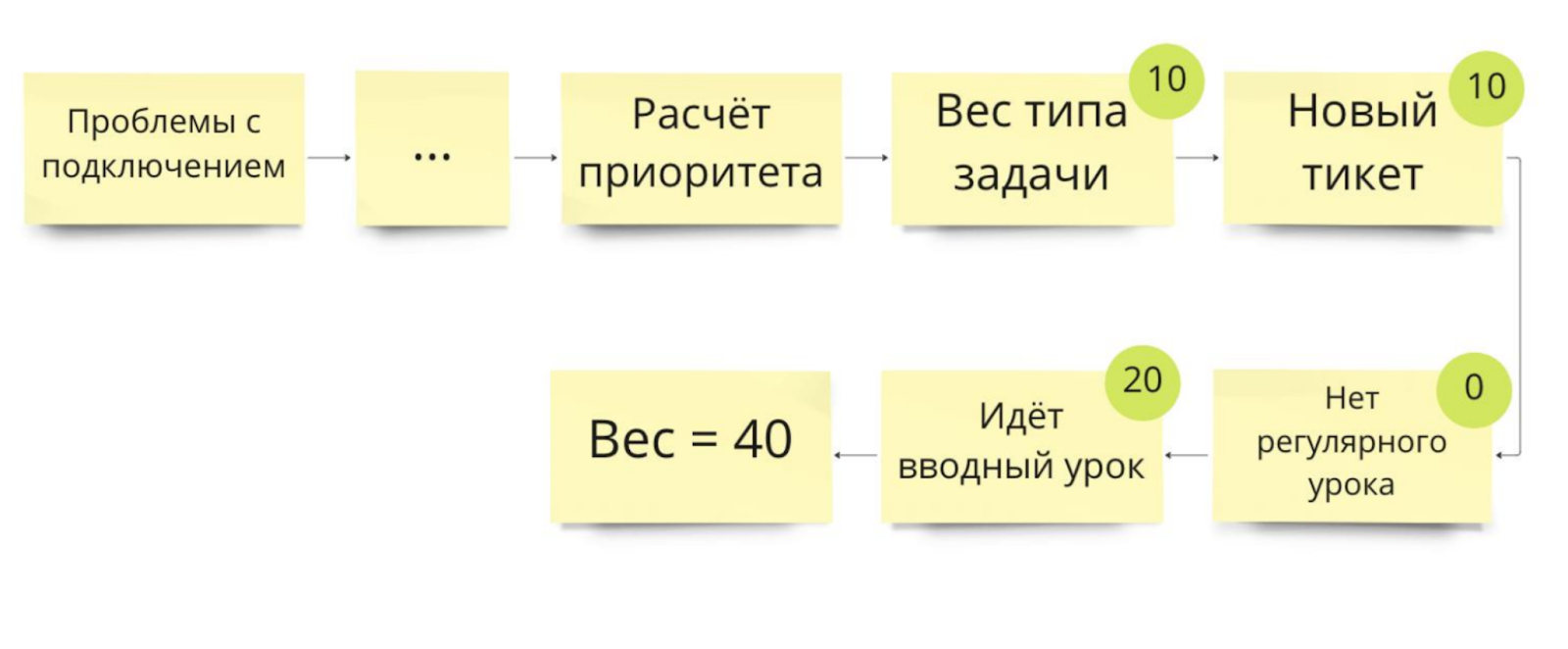
Давайте попробуем все это дело закодить.
Как процесс может выглядеть на PHP
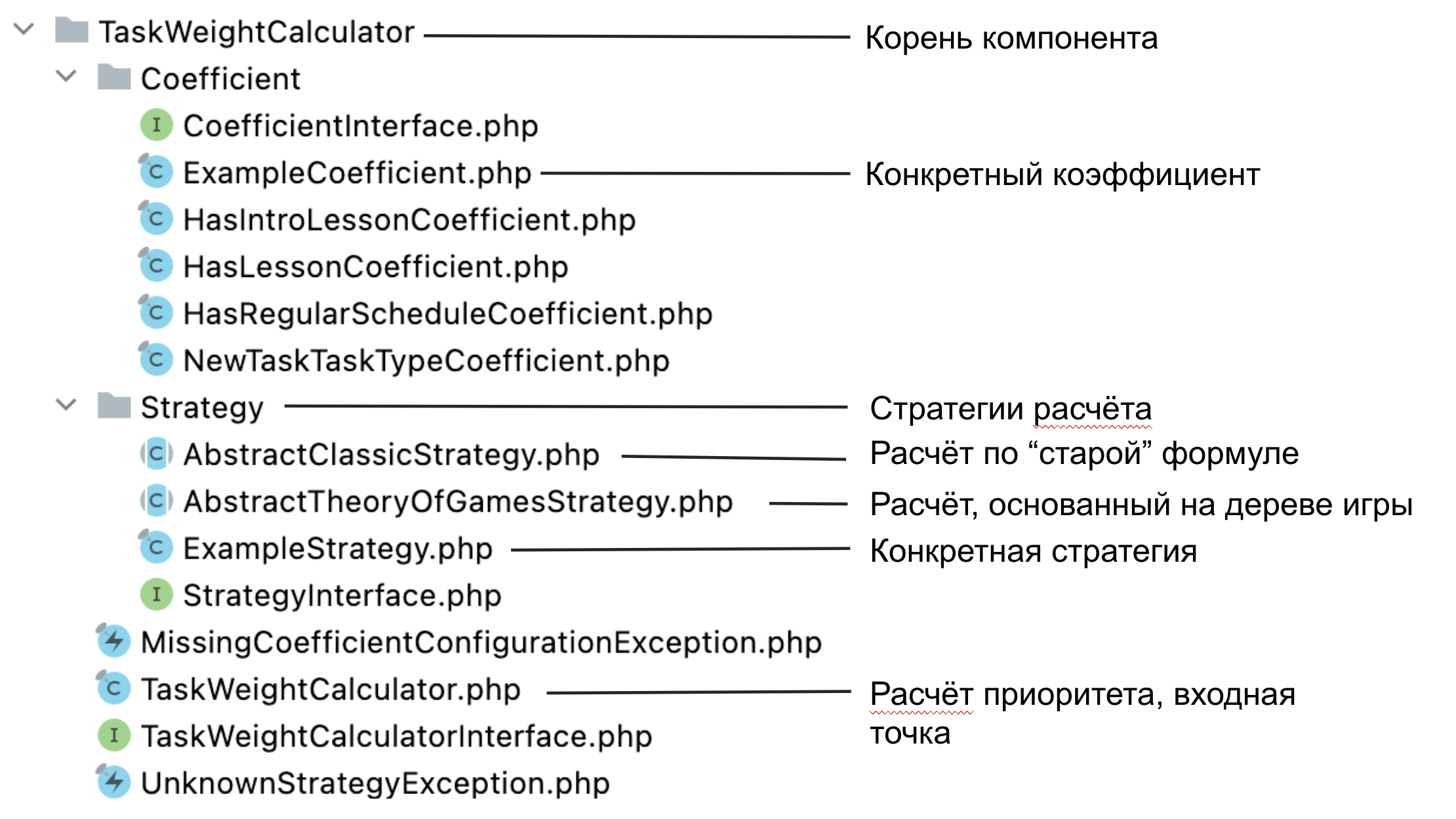
Допустим, есть компонент TaskWeightCalculator. У него единая точка входа — класс TaskWeightCalculator и один публичный метод calculate. У нас есть стратегии. Старая, где мы просто суммировали тип задачи и причину открытия. И новая, а-ля теории игр, где у нас есть стратегии и интерфейс разных коэффициентов, которые реализуют все по правилам бизнеса.
Выглядит вот так:

Стратегии как конструкторы собираются из коэффициентов. Коэффициенты не зависят друг от друга и могут быть переиспользованы в любом количестве стратегий. Мы можем назначить им любой вес и собрать стратегию, которая нужна конкретно этой группе.
Коэффициент — это маленький класс, который можно конфигурировать и который будет рассчитывать, основываясь на бизнес правилах.
Если спуститься на уровень кода, у нас есть TaskWeightCalculator. Набрав в себя все имеющиеся стратегии, у него один публичный метод — calculate. Клиентскому коду больше ничего не нужно знать, а только рассчитать приоритет по своей задаче. Остальным займется компонент.
Компонент опрашивает стратегии: подходит ли она для расчета приоритета для конкретной группы. Если такая стратегия находится, окей, едем дальше, пытаемся все рассчитать.
Метод calculate делегирует свою работу в стратегию. У нас есть какая-то абстрактная стратегия теории игр, которая будет собирать коэффициенты уже у конкретной стратегии, суммировать их и отдавать результат. Конкретная стратегия ничего экстраординарного не содержит. Это метод, который говорит: готова ли стратегия обслужить эту группу и отдать свои коэффициенты.

Через конструктор конфигурируем стратегию, накидываем ей коэффициентов, которые нужны конкретной группе операторов, добавляем им вес и приоритет. Приоритеты могут быть как повышающими, так и понижающими.

На примере, у нас есть коэффициент, который сходит в CRM и запросит услуги. Если услуги нашлись — отдаем один вес, если не нашлись — отдаем другой вес. Это может быть важно, например, для групп продажников, которые будут взаимодействовать более активно с теми пользователями, у которых услуг нет.

Но если необходимо кратно увеличить вес задачи так, чтобы она ярко выделялась в бэклоге (например, при наступлении дедлайна), то добавляем умножающие коэффициенты.

У нас есть уже рассчитанный вес. Далее наступает дедлайн и мы увеличиваем еще на какой-то коэффициент.

На слайде выше не кратное увеличение, но главный принцип работы понятен.
Как меняются при этом все эти стратегии и конфигурация? Не сильно. У нас просто разделяются на два массива. Отдельно суммирующие, отдельно умножающие.

Сам калькулятор сначала суммирует, а потом доумножает результат на те коэффициенты, которые должны быть умножающими.

В регистрации дедлайна у нас тоже ничего сверхъественного. Ходит CRON, опрашивает задачу, достает какую-то команду, регистрируем дедлайн, диспатчим события в системе и после этого перерасчитываем вес и все. Получается гибкая система, которая умеет как собирать по кубикам приоритеты, так и кратно увеличивать их вес.
Выглядит неплохо, работает, но есть еще одна проблема — изменения стратегии происходят через разработку. Если группе нужно срочно поменять веса, добавить или убрать приоритет, то что происходит? Мы говорим, приходите, ставьте задачу, мы запланируем. Это не очень здорово. Клиенты ждут, студенты вовремя не могут получить ответ на свой вопрос. Польза доставляется долго.
Админка — ответ на любой вопрос. Отдаем ее аналитику, он там сам ковыряется, меняет приоритеты, убирает или добавляет классы. Все начинает работать здесь и сейчас.
Про итоги
Получается анализ задач по параметрам. Мы можем анализировать гибко экосистему школы и легко понимать, что произошло и происходит с задачей, а так же, как это развивать.
Стратегии собираются по кирпичикам для каждой группы операторов. Мы можем тонко подстраивать их под нужды без каких-то проблем, дополнительных релизных циклов и прочего: берем, собираем, получаем пользу.
Такая система приоритетов справедлива не только для тикетной системы, которую делали мы. В любой системе вы можете внедрять такую технологию и приоритизировать, допустим, выдачу, и находить наиболее весомые и ключевые сущности для своей системы.

