
На связи команда по разработке риск-моделей для крупного корпоративного, а также малого и среднего бизнеса банка «Открытие» Андрей Бояренков и Кирилл Козлитин. Сегодня мы хотим поделиться с вами процессом разработки модели выявления связанных компаний на основании транзакционных данных. Пришли к нам заказчики и говорят: «Хотим по имеющимся транзакциям наших клиентов определять, кто из контрагентов является с ними связанным».
Небольшое отступление. Может возникнуть резонный вопрос: "А для чего, собственно, определять эту связанность?". Для ответа на данный вопрос отправимся на небольшую экскурсию за кулисы банковских бизнес-процессов.
Когда в банк от юридического лица поступает заявка на кредит, один из параметров, который оценивается – группа связанных с ЮЛ компаний. То есть банку важно знать: "А как идут дела у круга лиц, который как-либо связан с потенциальным заемщиком?"
Да, здесь важно сказать, что связи бывают разные. Как минимум их можно разделить на два вида: экономические и юридические. Юридические связи имеют, например, головная компания и ее "дочка". Такие связи сложно скрыть, они на бумаге. А вот с экономическими сложнее. К экономически связанным можно отнести такие компании, которые дают друг другу займы, между компаниями идет существенный товарно-денежный оборот, либо компании поручаются друг за друга при получении кредитов. Раскрывает такие связи далеко не каждый заемщик.
Банку очень важно знать, кто придет на помощь к потенциальному заемщику, если дела его будут плохи, или к кому на помощь побежит он. Поэтому чем точнее нам удастся определить круг таких лиц, тем лучше мы нивелируем связанные с заемщиком риски. Получать по нажатию кнопки список компаний, которые с высокой вероятностью являются связанными, было бы очень удобно. Для этого и нужна модель.
В процессе работы мы столкнулись с разными проблемами. Забегая вперед, скажем, что модель нам построить удалось. Но об этом позже. А пока – начнем с анализа данных.
1. Подготовка данных
Прежде чем начать строить модель, мы задались вопросом: "Какие данные из всего пула транзакций могут нам помочь?", или иначе: "Как нам преобразовать данные транзакций так, чтобы вытащить максимум информации?". Вообще у нас есть готовый стандартный лонг-лист факторов, построенных на транзакционных данных. Перечень ранее разрабатывался под задачу прогнозирования дефолта по заемщику. Но очевидно, что факторы, влияющие на дефолт по заемщику (такие как стабильность и динамика поступлений, наличие штрафов, пеней и т.п.), должны отличаться от факторов, выявляющих наличие связей между юридическими лицами. Поэтому мы решили сформировать под данную задачу новый лонг-лист факторов, который взяли бы для дальнейшего анализа на предмет статистической значимости.
ИНН клиента (отправителя транзакции) | ИНН корреспондента (получателя транзакции) | Месяц, за который агрегировались транзакции | Тип транзакции | Объем транзакций между Клиентом и Контрагентом | Количество транзакций между Клиентом и Контрагентом |
xxxxxxxxxx14 | xxxxxxxxxx09 | 01.11.2022 | CR_Interest | 239 520 | 45 |
xxxxxxxxxx39 | xxxxxxxxxx11 | 01.11.2022 | CR_Loan | 35 000 000 | 6 |
xxxxxxxxxx71 | xxxxxxxxxx23 | 01.11.2022 | CR_Sales | 61 087 372 | 285 |
xxxxxxxxxx16 | xxxxxxxxxx22 | 01.11.2022 | CR_Rent | 2 633 | 3 |
xxxxxxxxxx16 | xxxxxxxxxx01 | 01.12.2022 | DB_Avans | 11 860 | 19 |
xxxxxxxxxx50 | xxxxxxxxxx08 | 01.12.2022 | DB_Loan | 35 000 000 | 11 |
xxxxxxxxxx48 | xxxxxxxxxx93 | 01.12.2022 | DB_Expenses | 294 540 | 5 |
xxxxxxxxxx05 | xxxxxxxxxx12 | 01.12.2022 | CR_Deposit | 10 896 | 1 |
Перед нами пример исходных данных по задаче. Это не чистая витрина с транзакциями клиентов, а ее помесячный агрегат по сумме транзакций и количеству проводок в разрезе различных типов транзакций.
Как видим, сырые данные, на первый взгляд, не очень информативны.
Ранее в одной из статей мы описывали, что в целом для работы с транзакциями нами были сформированы отдельные правила раскраски транзакций заемщика по типам с использованием парсинга текста проводок. Например, возможно выделение таких типов, как получение/погашение кредитов, оплата налогов, выдача из кассы, аренда, инкассация, платежи от покупателей и т.д. Возможно выделение большого количества таких типов (у нас их более 40), в том числе с использованием подходов ML. То есть по сути каждый денежный перевод имеет свой тип, который содержит в себе информацию о цели транзакции и ее направлении (кто получатель). Например, код CR_Rent означает перечисление денег в направлении от контрагента к нашему клиенту (кодировка CR, т.е. «Credit») за аренду (кодировка Rent).
В основе всей этой работы лежит гипотеза: «Характер транзакций связанных лиц отличается от характера транзакций несвязанных». Как нам это проверить? Имея на руках базу данных транзакций, мы предположили, что, возможно, связанные лица транзачат друг с другом по какому-то определенному типу чаще, чем по остальным. Например: Иван может получать средства для своего бизнеса от компании брата Алексея посредством транзакции типа CR_Loan. Т.е. Алексей выдает займы Ивану.
Это мы и хотим проверить. Для этого мы провели разведочный анализ (EDA) с целью выяснить, какие типы проводок встречаются у клиента чаще при работе со связанными лицами, чем при работе с несвязанными. Т.е. разбив выборку на связанных и несвязанных и проагрегировав данные по типам транзакций, мы уже сможем вытащить информацию о различии выборок.
Для этого наш перечень транзакций разделили на две выборки: транзакции между связанными лицами и транзакции между несвязанными лицами. Для разметки является ли контрагент связанным собирали статистику из наших внутрибанковских систем (юридические и экономические связи, по кому была такая информация). И далее проанализировали каждый тип проводок отдельно.
Еще небольшой нюанс: статистики оценивались в рамках каждой "пары клиент – контрагент" отдельно и затем усреднялись. Это позволяет нивелировать большой вклад в итоговые метрики "крупных клиентов". Каждая пара имеет одинаковый вес. Визуализация подхода на схеме ниже:
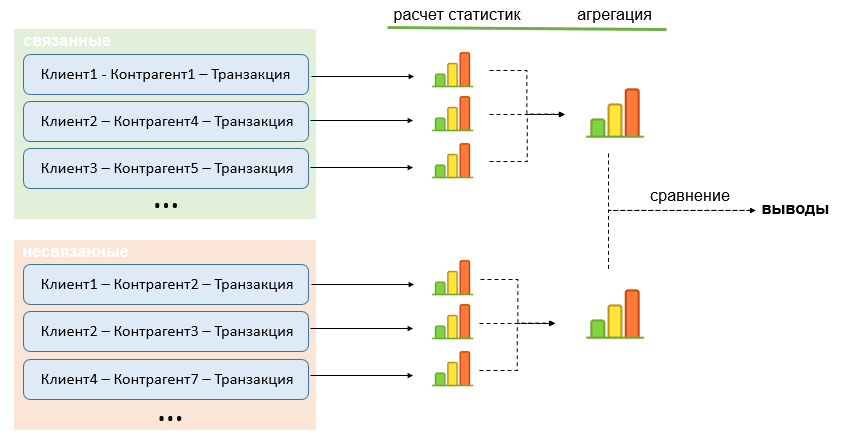
2. Первичная предобработка данных
Прежде чем приступить к анализу, почистим выборку. В текущем виде она может содержать в себе некорректные значения, аномалии, нерелевантные для анализа значения. Поэтому сначала произведем очистку:
Убираем ошибки, некорректные значения первоначальных данных (например, ИНН, состоящие из одних нулей, пропуски и т.п.);
Отбрасываем операции с физлицами, которые не являются индивидуальными предпринимателями;
Отбрасываем операции с банками (выдачи/погашения банковских кредитов, операции с депозитами);
Отбрасываем операции по неклиентским типам проводок (это могут быть налоги, штрафы и прочие операции с государственными органами). Они неинтересны для данного анализа.
3. Анализ данных
Средняя доля объема каждого типа транзакций в общем объеме транзакций:

На графике видно, что доли некоторых типов транзакций при работе со связанными лицами различаются от аналогичных при работе с несвязанными лицами. Поэтому дальнейшую генерацию фичей для лонг-листа модели будем делать уже на ограниченном, отобранном по итогам аналитики наборе типов транзакций.
4. Отбор проводок и фильтрация
Самыми информативными для нашей задачи оказались проводки на оплату товаров и услуг, на выдачу и погашение займов, арендные платежи.
Все необходимое для формирования перечня факторов мы сделали. Кроме одного. Обратим внимание на применимость модели. Очевидно, что, если между клиентом и контрагентом было всего несколько проводок, определить вероятность их связи вряд ли получится корректно. Очевидно, что такие наблюдения не подойдут для обучения модели и будут вносить дополнительный шум.
Поэтому необходимо ввести условия применимости модели. По итогам анализа данных определили, что будем работать только с наблюдениями (клиент – контрагент), которые совершили транзакций не менее чем на 1 млн руб. в год при не менее 12 транзакциях за данный период.
В результате всех манипуляций наша выборка сократилась примерно в 30 раз. С 90+ млн изначальных строк (транзакций) до чуть более 3 млн.
5. Расчет факторов
Мы уже открыли для себя, что доля определенных типов проводок может быть хорошим признаком связанности. Соответственно, это отлично подойдет в качестве фактора для тестирования статистической значимости. Но попытаемся для получения более качественного результата расширить пространство признаков. Для этого рассчитаем дополнительные факторы, которые могут нести в себе полезную информацию:
Найдем долю объема/количества каждого типа проводок в общем объеме/количестве проводок связки клиента с его контрагентом. Отдельно по кредитовым и отдельно по дебетовым проводкам;
Найдем долю объема/количества некоторых типов проводок в общем объеме/количестве проводок связки клиента с его контрагентом без разбивки на дебетовые/кредитовые проводки (например, проводки с кодировкой Avans есть как среди дебетовых, так и среди кредитовых, поэтому итоговый фактор будет иметь в виду долю сумму такого типа проводок во всех оборотах компании независимо от того поступления это или расходные операции);
Более сложные факторы. Включают в себя суммирование типов проводок, чья сумма по объему или количеству несет определенный бизнес-смысл. И вычисление доли такого совместного объема в общем объеме/количестве проводок связки клиента с его контрагентом.
Таким несложным образом мы нагенерили лонг-лист из 107 факторов, на которых в итоге и строилась модель.
Дальнейший процесс построения модели ничем принципиально не отличается от построения любой другой модели согласно нашему стандартному внутрибанковскому пайплайну. Кратко пробежимся по нему, не углубляясь в тонкости, и перейдем к результатам. Детальнее про него можно прочитать в статье наших коллег.
6. Разбиение выборки на тренировочную и тестовую
Нашим внутрибанковским стандартом принято бить выборки стратифицированно. Так, чтобы Target Rate двух выборок был максимально одинаковым. Это помогает нам бороться с дисбалансом классов и делает обучение более стабильным.
7. Однофакторный анализ
Процесс оценки факторов строится на процедуре биннинга с помощью библиотеки optbinning и последующем WOE-преобразовании. Сама модель строится на WOE-преобразованных факторах (что тоже уже является некоторым стандартом отрасли). В качестве метрики дивергенции выбрана "Information Value".
Результаты биннинга каждого фактора сводятся в единую таблицу, где факторы подвергаются дополнительному отбору. Критерии прохождения однофакторного анализа:
Gini фактора >= 5%;
Нижний доверительный интервал Gini фактора >= 0%;
Отклонение Gini на тестовой выборке от выборки трейн <= 15% в относительном выражении, и <= 10% в абсолютном;
Наличие не менее 2 бакетов;
Количество пропущенных значений < 50%.
В нашей задаче из 107 факторов из лонг-листа проверку на однофакторном анализе прошли только 31.
8. Многофакторный анализ
На полученном перечне статистически значимых факторов и строилась модель. Модель строилась по подходу StepWise методом логистической регрессии. То есть сначала отбиралась самая эффективная трехфакторная комбинация, которая прошла все стандартные проверки, такие как: мультиколлинеарность, тест Колмогорова-Смирнова и др.
Далее на каждом шаге добавлялся один фактор из оставшегося перечня и уже новая комбинация прогонялась по тому же перечню проверок.
Детали итоговой модели раскрыть не можем в силу коммерческой тайны. Однако результатами ранжирующей способности поделиться можем: Джини 72,4% на тестовой выборке.
* * *
Предложив ряд факторов, исходя из проведенной аналитики, мы получили достаточно неплохие результаты. Помимо этого производили эксперименты с бустинговыми моделями, которые показали еще больший прирост. Значимо улучшить модель, предположительно, можно, добавив ей информации. В этом также могут помочь графовая аналитика и фичи, полученные с ее помощью. Но об этом мы напишем в следующих статьях – уже совсем скоро.
