
Плагин Structure для Jira очень полезен в ежедневной работе с задачами и их анализом. Он выводит на новый уровень визуализацию и структуризацию Jira-тикетов. И все это доступно сразу «из коробки».
Не все знают, но в Structure есть формулы, которые своей функциональностью просто взрывают мозг. С помощью формул можно создавать крайне полезные таблицы, которые могут сильно упростить работу с задачами, а главное, очень полезны в более глубоком анализе релизов, эпиков и проектов.

В этой статье мы разберемся, как создавать свои формулы, начиная от самых простых примеров и заканчивая довольно сложными, но полезными кейсами.
Для кого этот текст
Казалось бы, есть официальная документация на сайте ALM Works — бери да читай. Зачем писать отдельно статью?
С одной стороны, это верно. Однако, я из тех людей, кто даже не подозревал, что в Structure спрятана такая широкая функциональность, вызывающая только одну реакцию — «а что, так можно было?!».
Подумал, вдруг найдутся еще люди, которые тоже не знают, какие штуки можно вытворять, благодаря формулам в Structure.
Ну и конечно, статья будет полезна тем, кто уже знаком с формулами. Вы сможете посмотреть на интересные варианты применения кастомных полей из реальной практики нашей студии и, возможно, взять к себе на проект какие-то из них.
Кстати, если у вас уже есть интересные примеры, буду рад, если поделитесь ими в комментариях.
Чего ожидать от статьи
Статья похожа на инструкцию-обзор возможностей Structure с ее формулами. Каждый пример разобран подробно — от описания решаемой проблемы до объяснения кода — так, чтобы не оставалось вопросов, для чего это нужно. И конечно же, каждый пример сопровожден кодом, который можно попробовать самостоятельно, не вникая в разбор.
Если не хочется читать, но про формулы интересно, то есть вебинары ALM Works. Там сжато, но в них за 40 минут объясняют базу.
Для понимания примеров вам не требуется каких-то дополнительных знаний, поэтому любой, кто работает с Jira и Structure, смогут без проблем повторить примеры у себя в таблицах.
Причем разработчики в своем языке Expr предусмотрели достаточно гибкий синтаксис. У ребят, можно сказать, получилось реализовать формулы по принципу — «пиши как хочешь, все равно будет работать».
Итак, давайте начнем.
О формулах
Зачем нужны формулы
Бывает, что нам не хватает стандартных Jira-полей, таких как «Assignee», «Story Points» и прочих. Иногда нам нужно посчитать какую-то сумму по определенным полям, вывести остаток капасити по версии, узнать, сколько раз задача меняла статус. Может быть, мы вовсе хотим объединить несколько полей в одно, чтобы проще читать нашу Structure.
Для решения этих проблем нам понадобятся формулы, с помощью которых мы будем создавать кастомные поля.
Первое, что нужно понять — как работает формула. По сути, она позволяет нам применить какую-то операцию к строке. В силу того, что мы выгружаем в структуру много задач, формула применяется для каждой строки всей таблицы. Обычно все ее операции направлены на работу с задачами в этих строках.
Получается, если мы попросим формулу вывести какое-то Jira-поле, например, «Assignee», то формула сработает для каждой задачи, и у нас будет еще одна колонка с «Assignee».
Что есть в формулах
Сами формулы состоят из нескольких основных сущностей:
переменные — для обращения к Jira-полям и для сохранения промежуточного результата;
встроенные функции — совершают заранее определенную операцию, например, считают количество часов между датами или фильтруют данные в массиве;
кастомные (свои) функции — если нам потребуются уникальные вычисления;
разные формы отображения результата — например, «Date/Time», «Duration», «Number» или «Wiki Markup» для своего варианта.
Знакомство с формулами
Знакомиться с формулами и синтаксисом будем на примерах. Нас будут ждать шесть кейсов из реальной практики. Все кастомные поля мы с коллегами используем в своих таблицах.
В начале каждого примера будет указано, какие особенности Structure мы используем, а новые фишки, которые еще не разобрали, будут выделены жирным. Все примеры идут по нарастающей сложности и подобраны таким образом, чтобы постепенно познакомить вас с важными особенностями формул.
Структура примеров:
проблема;
идея решения;
задействованные особенности Structure;
пример кода;
разбор решения.
Эти примеры касаются разных тем — от маппинга переменных до сложных массивов:
два примера отображения дат начала и конца работы над задачей (варианты с разным отображением);
родительская задача — отображение типа и названия родительской задачи;
сумма Story Points подзадач и «статус» этих оценок;
индикация недавних изменений статуса задачи;
расчет рабочего времени, исключая выходные и лишние статусы.
Как создавать формулы
Для начала нужно разобраться, как создавать кастомные поля с формулами. В правой верхней части Structure, в конце всех колонок, есть иконка «+» — нажимаем на нее. В появившемся поле пишем «Formula…» и выбираем соответствующий пункт.
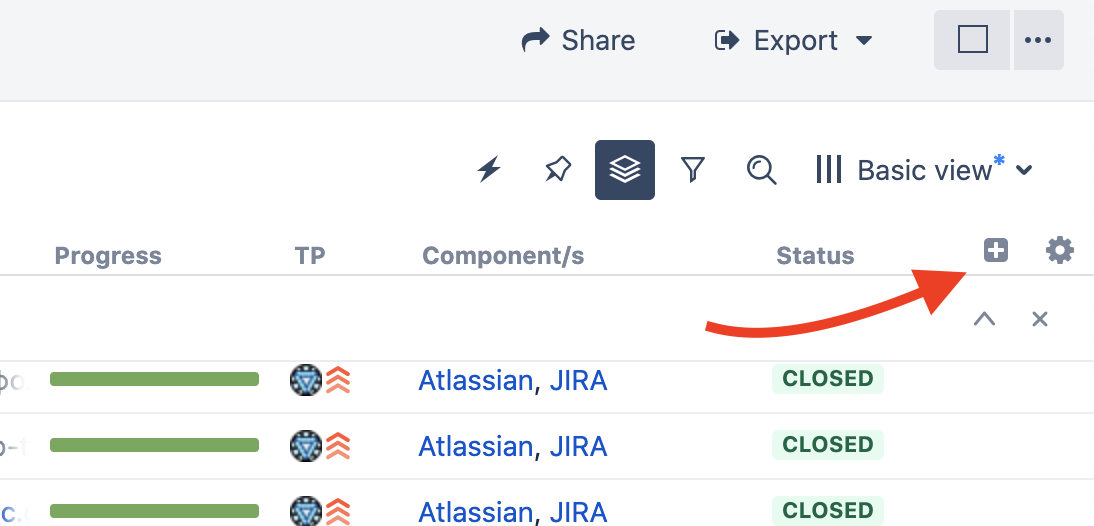
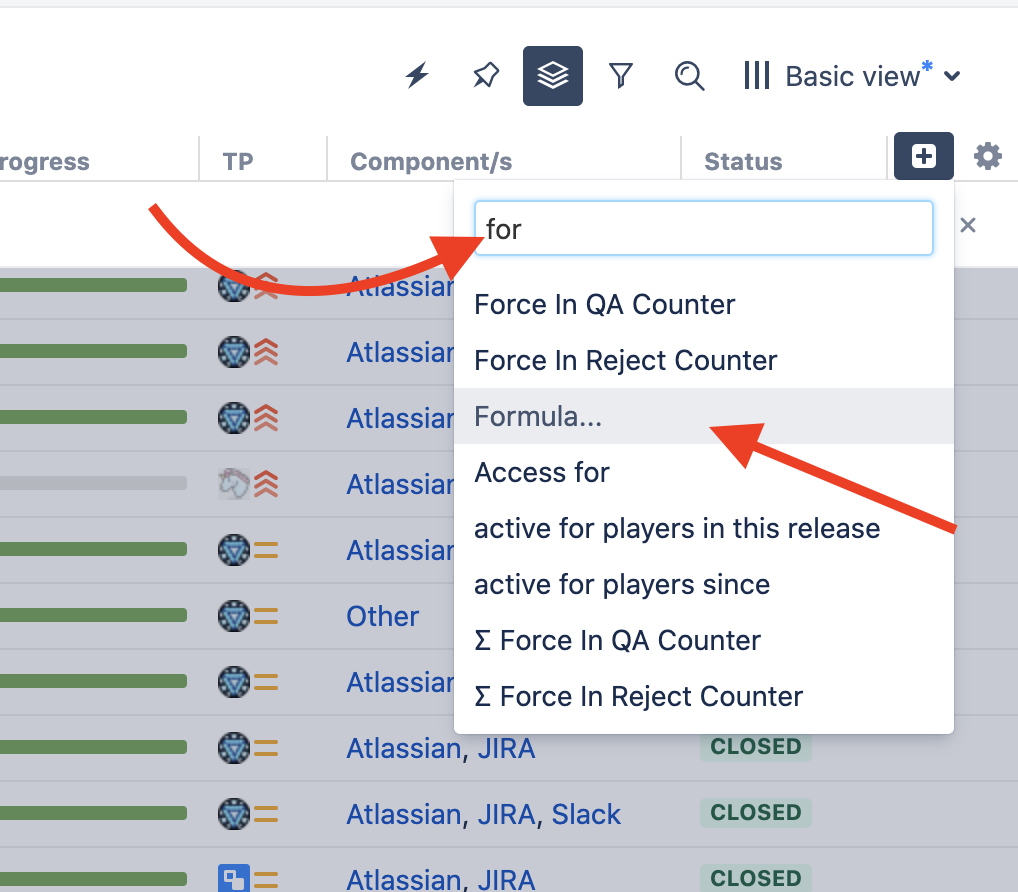
Как сохранять формулы
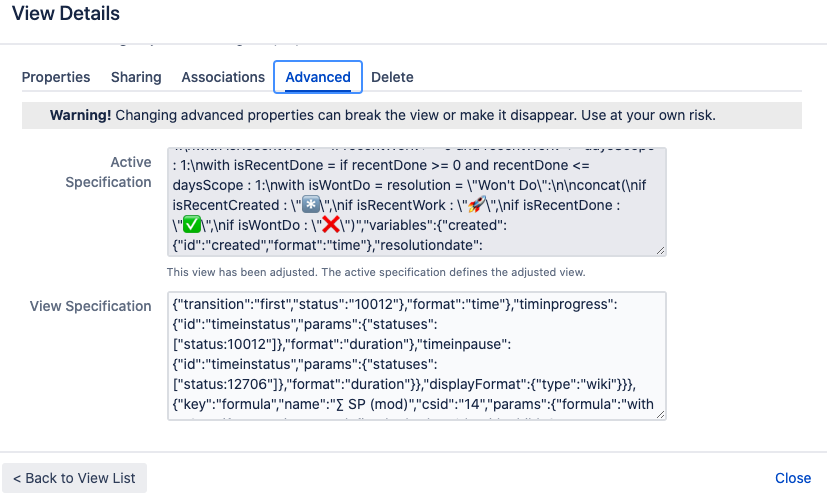
Сразу обращу внимание на то, как сохранить свою формулу. К сожаление, куда-то отдельно сохранить конкретную формулу пока нельзя (только если себе в блокнот, как это делаю я). На вебинаре ALM Works говорили, что работают над банком формул, но сейчас единственный способ сохранить их — сохранить весь view вместе с формулой.
Когда мы закончили работать над формулой, нам нужно кликнуть на view нашей структуры (он, скорее всего, будет отмечен синей звездочкой) и нажать «Save», чтобы перезаписать текущий view. Или можно нажать на «Save As…», чтобы создать новый view. Не забудьте сделать его доступным для остальных пользователей Jira, так как по умолчанию новые view приватные.

Формула сохранится к остальным полям в конкретном view — это можно увидеть во вкладке «Advanced» в меню «View Details».
Переходим к нашим примерам.
Отображение дат начала и конца работы над задачей

Проблема
Нужна табличка со списком задач, а также датами начала и конца работы над ними. Сама табличка нужна, чтобы экспортировать ее в отдельный excel-gantt (про нее есть отдельная статья). К сожалению, «из коробки» Jira и Structure такие даты отдавать не умеют.
Идея для решения
Даты начала и конца работы — это даты перехода в конкретные статусы, в нашем случае это: «In Progress» и «Closed». Поэтому нам нужно вытащить эти даты, и каждую из них показать в отдельном поле (это нужно для дальнейшего экспорта в гант). Следовательно, у нас будут два поля (две формулы).
Что используем:
маппинг переменных;
настройку формата отображения.
Пример кода
Поле даты начала работы:
firstTransitionToStartПоле даты конца работы:
latestTransitionToDoneРазбор решения
В данном случае весь код является одной переменной — firstTransitionToStart для поля определения даты начала работы, а также latestTransitionToDone для второго поля. Сосредоточимся пока на поле даты начала работы.
Наша цель получить дату перехода задачи в статус «In Progress» (соответствующий логическому старту задачи), поэтому и переменная названа достаточно явно — «первый переход в старт», чтобы потом не вспоминать, за что она отвечает.
Чтобы записать дату в переменную, мы обратимся к маппингу переменных. Для этого сохраним нашу формулу, нажав на кнопку «Save».
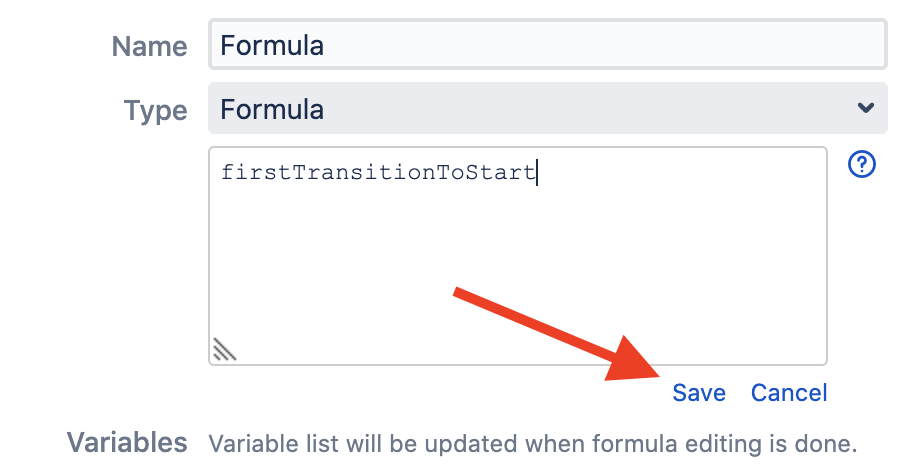
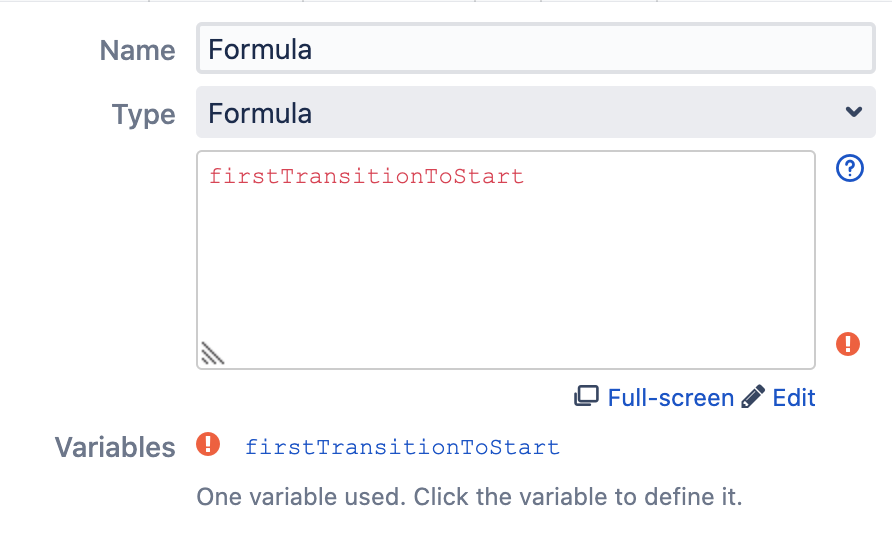
В секции «Variables» появилась наша переменная, а рядом с ней восклицательный знак. Structure сообщает, что не может самостоятельно связать переменную с полем в Jira, и нам придется сделать это самим (то есть маппить ее).
Нажимаем на переменную и проваливаемся в интерфейс маппинга. Там выбираем нужное нам поле или операцию — сейчас мы ищем операцию «Transition Date…». Пишем «transition» в поле выбора. Нам предлагают сразу несколько вариантов: один из них, в принципе, нам подходит — это «First Transition to In Progress». Но в качестве демонстрации работы маппинга выберем вариант «Transition Date…».
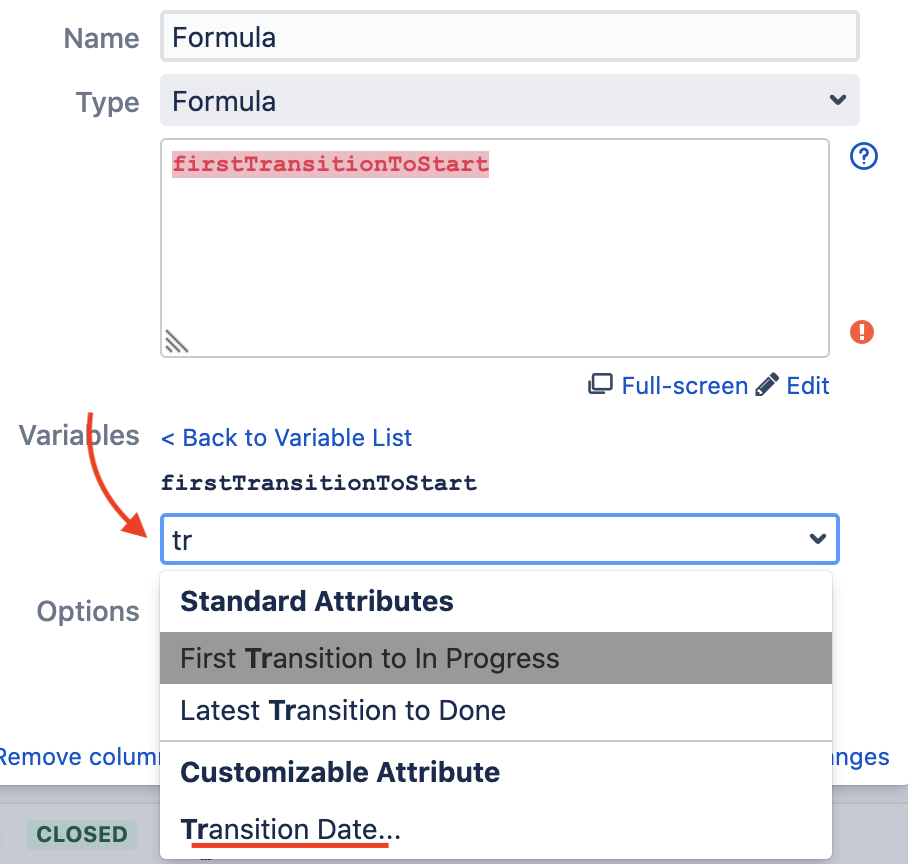
После этого нам предлагают выбрать статус, в который произошел транзишен, и очередность этого перехода — первый или последний.
Выбираем или вписываем в «Status» — «Status: In Progress» (или соответствующий статус в вашем Workflow), а в «Transition» — «First transition to status», так как начало работы над задачей — это самый первый переход в соответствующий статус.
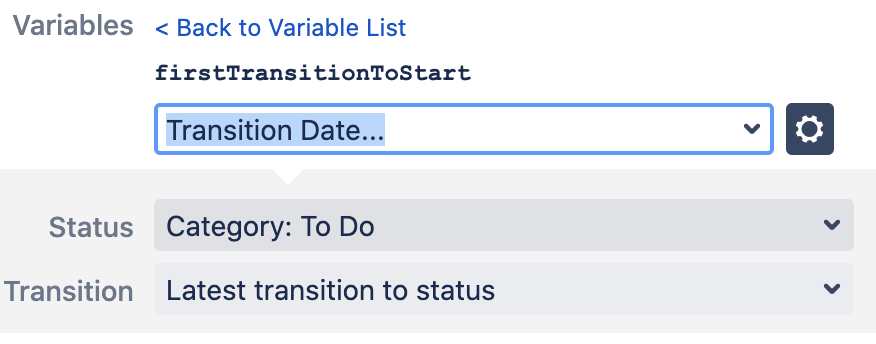

Если бы вместо «Transition Date…» мы выбрали предложенный изначально вариант «First Transition to In Progress», то результат был бы почти таким же — Structure сама выбрала бы нужные параметры за нас. Единственное, вместо «Status: In Progress» у нас был бы вариант «Category: In Progress».
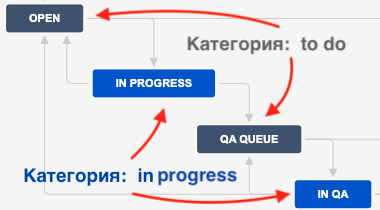
Отмечу важную особенность — есть статус, а есть категория. Статус — это конкретный статус, он однозначен, а вот категория может включать в себя несколько статусов. Категорий всего три: «To Do», «In Progress» и «Done». Обычно в Jira они обозначены серым, синим и зеленым цветами соответственно. Статус обязательно принадлежит какой-то из категорий.
Рекомендую в таких кейсах указывать конкретный статус, чтобы избежать путаницы со статусами одной категории. Например, у нас на проекте есть два статуса категории «To Do» — «Open» и «QA Queue».
Вернемся к нашему примеру.
После того, как мы выбрали нужные опции, можем нажать на «< Back to Variables List», чтобы завершить настройку параметров маппинга переменной firstTransitionToStart. Если мы сделали все правильно, то увидим зеленую галочку.

При этом в нашем кастомном поле мы видим какие-то странные цифры, которые совсем не похожи на дату. В нашем случае результатом формулы будет значение переменной firstTransitionToStart, а ее значение — это просто миллисекунды с января 1970 года. Чтобы получить корректную дату, нам нужно выбрать определенный формат отображения формулы.
Выбор формата расположен в самом низу окна редактирования. Сейчас там выбран «General». Нам нужен «Date/Time» — с ним дата будет отображаться корректно.
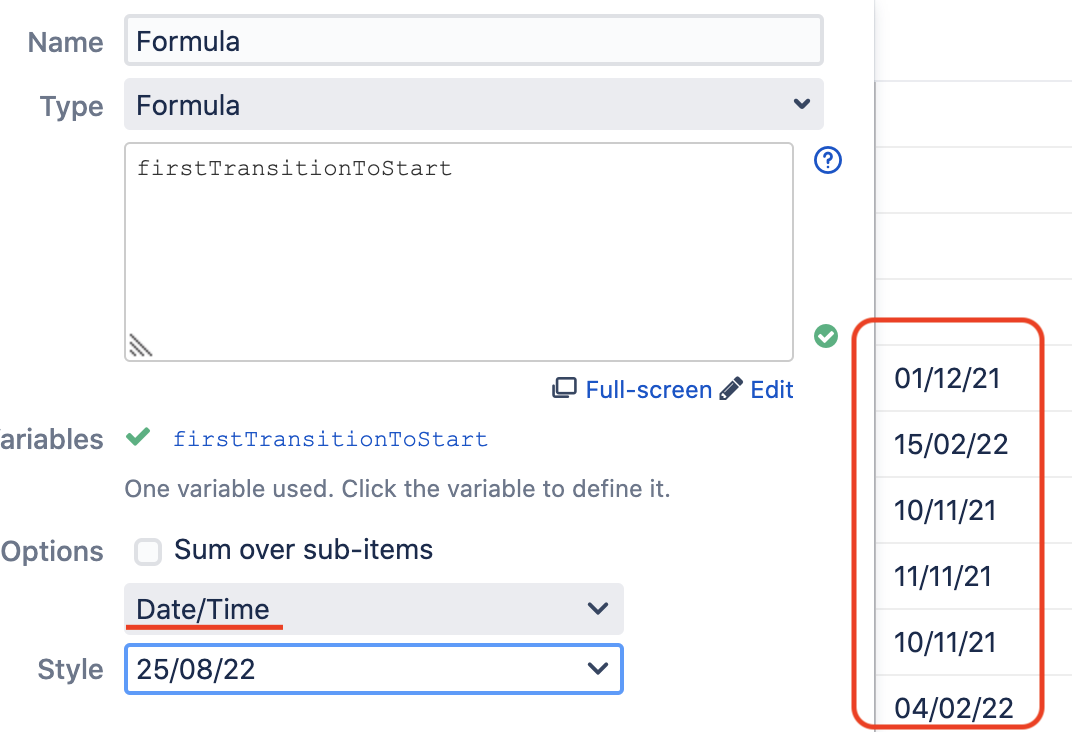
Для второго поля latestTransitionToDone делаем все то же самое. Только при маппинге уже можем выбирать категорию «Done», а не статус (так как обычно есть только один однозначный статус завершения задачи). В качестве параметра транзишена выбираем «Latest Transition», так как нас интересует самый последний переход в категорию «Done».
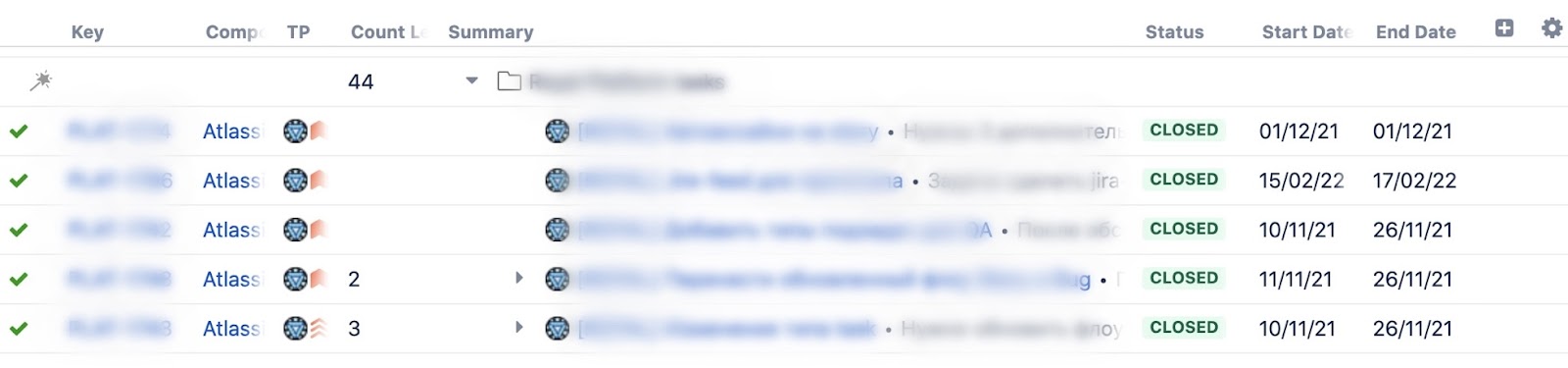
Финальный результат для двух полей будет выглядеть как на иллюстрации.
Теперь давайте посмотрим, как добиться такого же результата, но со своим форматом отображения.
Отображение дат — свой формат

Проблема
Нас не устраивает формат отображения дат из прошлого примера, так как для гант-таблицы нам нужен особенный — «01.01.2022».
Идея для решения
Выведем даты с помощью встроенных в Structure функций, указав подходящий нам формат.
Что используем:
маппинг переменных
функции языка Expr
Пример кода
FORMAT_DATETIME(firstTransitionToStart;"dd.MM.yyyy")Разбор решения
Разработчики предусмотрели много разных функций, в том числе отдельную для вывода даты в своем формате — FORMAT_DATETIME. Ее мы и применим. Функция принимает в себя два аргумента — дату и строку желаемого формата.
Переменную firstTransitionToStart (первый аргумент) мы настраиваем, использую те же правила маппинга, что и в прошлом примере. Второй аргумент — строка с указанием формата. Определяем ее так — "dd.MM.yyyy". Это соответствует желаемой нам форме — «01.01.2022».
Таким образом, наша формула сразу будет возвращать строку в нужном виде. Поэтому можно оставить опцию «General» в настройках поля.
Второе поле с датой конца работы делаем аналогичным образом. В итоге должна получиться структура как на рисунке ниже.
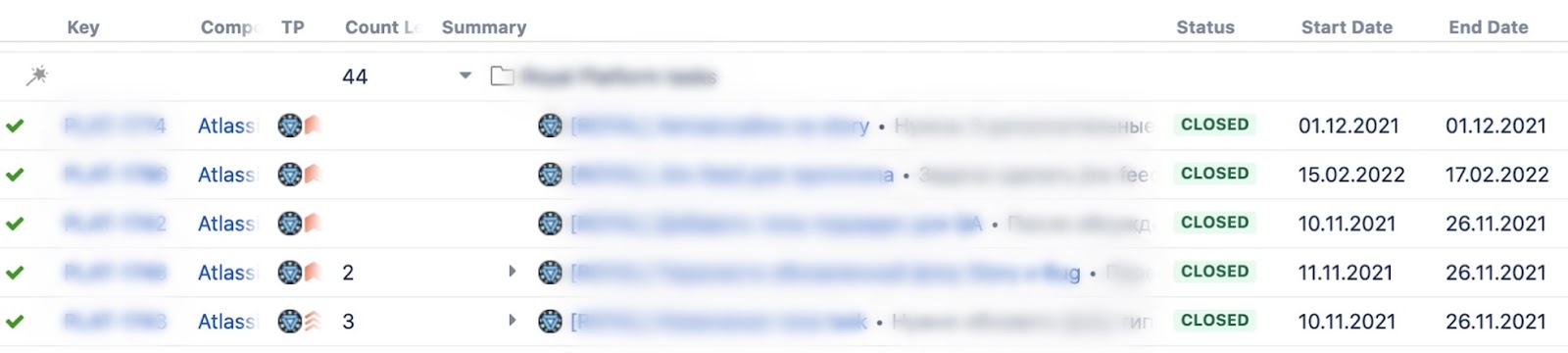
В принципе, каких-то особых сложностей в синтаксие формул нет. Нужна переменная — пишем ее название; нужна функция — тоже просто пишем ее название и передаем аргументы (если они требуются).
Когда Structure сталкивается с неизвестным именем, она предполагает, что это переменная, и пытается ее маппить сама, либо просит нас помочь.
Кстати, важное замечание — для Structure не важен регистр, поэтому и firstTransitionToStart, и firsttransitiontostart, и firSttrAnsItiontOStarT — это одна и та же переменная. Аналогичное правило работает и для функций. Чтобы добиться однозначности в стиле кода, в примерах мы будем стараться придерживаться правил Capitalization Conventions от MSDN.
Теперь углубимся в синтаксис и посмотрим на особый формат отображения результата.
Отображение названия родительской задачи

Проблема
Мы работаем и с обычными задачами (Task, Bug и прочими), и с задачами типа Story (стори), у которых есть подзадачи (Sub-task). В какой-то момент приходит потребность узнать, над какими задачами и саб-тасками работал сотрудник за определенный период.
Проблема в том, что многие саб-таски не дают информацию о самой стори, так как названы «работа над стори», «настройка» или, например, «подключение эффекта». И если запросить список задач за какой-то период, мы получим десяток задач с названием «работа над стори» без полезной для нас информации.
Хотелось бы иметь view со списком из двух колонок — задача и родительская задача, чтобы в дальнейшем можно было сгруппировать такой список по сотрудникам.
Идея для решения
У нас на проекте есть два варианта, когда у задачи может быть родитель:
либо задача — это подзадача (Sub-task) и ее родитель — это только Story;
либо задача — это обычная задача (Task, Bug и прочее) и у нее может быть Epic, а может и не быть, и тогда задача вовсе без родителя.
Поэтому нам нужно:
узнать, есть ли у задачи родитель;
узнать тип этого родителя;
вывести тип и название этой задачи по следующей схеме: «[Parent-type] Parent-name».
Чтобы упростить восприятие информации, мы будем окрашивать текст типа задачи: то есть либо «[Story]», либо «[Epic]».
Что используем:
маппинг переменных
условие
обращение к полям задачи
формат отображения — wiki markup
Пример кода
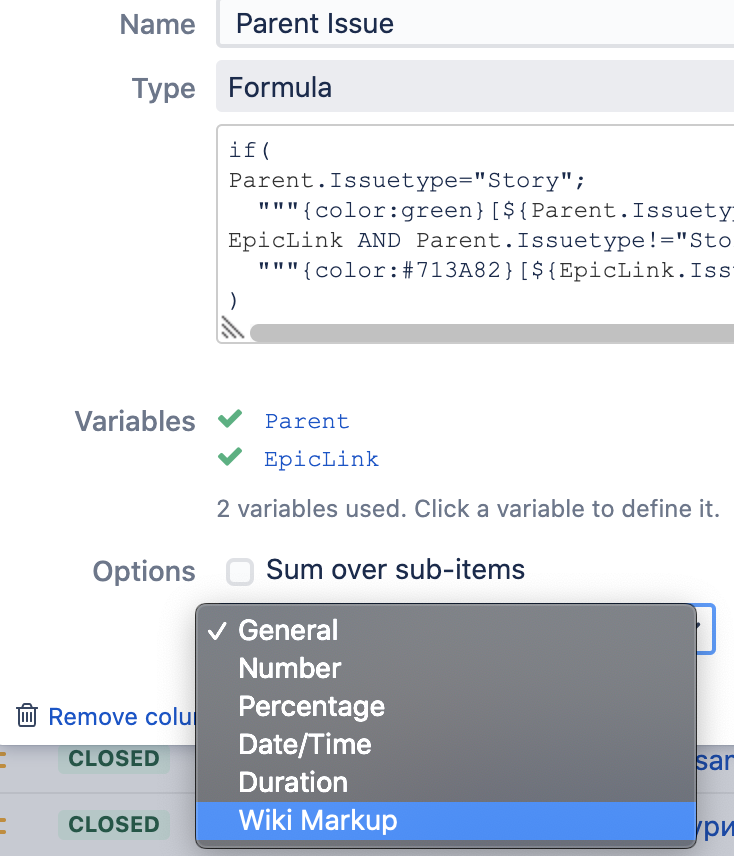
if(
Parent.Issuetype = "Story";
"""{color:green}[${Parent.Issuetype}]{color} ${Parent.Summary}""";
EpicLink;
"""{color:#713A82}[${EpicLink.Issuetype}]{color} ${EpicLink.EpicName}"""
)Разбор решения
Казалось бы, почему формула сразу начинается с условия if, если нам просто нужно вывести строку и вставить туда тип задачи и название? Разве нет какого-то универсального способа обратиться к полям задачи? Есть, но для задач и эпиков эти поля названы по-разному и обращаться к ним тоже нужно по-разному — это особенность Jira.
Различия начинаются уже на уровне поиска родителя. Для подзадачи (Sub-task) родитель живет в Jira-поле «Parent Issue», а для обычной задачи родителем будет являться эпик — он находится в поле «Epic Link». Поэтому нам придется написать два разных варианта обращения к этим полям.
И вот тут нам потребуется условие if. В языке Expr есть разные способы работы с условиями. Выбор между ними — это дело вкуса.
Есть «excel-like» метод: if (условие1; результат1; условие2; результат2 … )
Или более «кодерский» метод:
if условие1 : результат1
else if условие2 : результат2
else результат3В примере я использовал первый вариант. Теперь давайте посмотрим на наш код в упрощенном виде:
if(
Parent.Issuetype = "Story";
Какой-то там результат 1;
EpicLink;
Какой-то там результат 2
)Перед нами явно выделяются два условия:
Parent.Issuetype = "Story"EpicLink
Разберемся, что они делают, и начнем с первого — Parent.Issuetype="Story".
В данном случае Parent — это переменная, которая автоматически маппится на поле «Parent Issue». В нем, как мы обсуждали выше, должен жить родитель для подзадачи. Через точку (.) мы обращаемся к свойству этого родителя, а именно к свойству Issuetype, которое соответствует Jira-полю «Issue Type», то есть типу задачи. Получается, вся строка Parent.Issuetype возвращает нам тип родительской задачи, если такая задача существует.
Дополнительно нам не пришлось ничего определять или маппить, так как разработчики постарались за нас. Вот, например, ссылка на все свойства (в том числе и Jira-поля), которые заранее определены в языке, а вот тут можно посмотреть список всех стандартных переменных, к которым тоже можно смело обращаться без дополнительных настроек.
Таким образом, первое условие — проверка на то, действительно ли тип родительской задачи — это Story. Если первое условие не выполняется, то тип родительской задачи — не Story, либо его вообще не существует. И это переносит нас ко второму условию — EpicLink.
По сути это просто проверка на заполненность jira-поля «Epic Link» (то есть его существование). Переменная EpicLink тоже является стандартной и маппить ее не нужно. Получается, наше условие выполняется, если у задачи есть Epic Link.
И третий вариант — если ни одно из условий не выполнено, то есть у задачи нет ни родителя, ни Epic Link. В таком случае мы ничего не выводим и оставляем поле пустым. Это происходит автоматически, так как мы не попадем ни в один из результатов.
С условиями разобрались, теперь перейдем к результатам. В обоих случаях — это строка с текстом и особым форматированием.
Результат 1 — если родитель Story:
"""{color:green}[${Parent.Issuetype}]{color} ${Parent.Summary}"""Результат 2 — есть Epic Link:
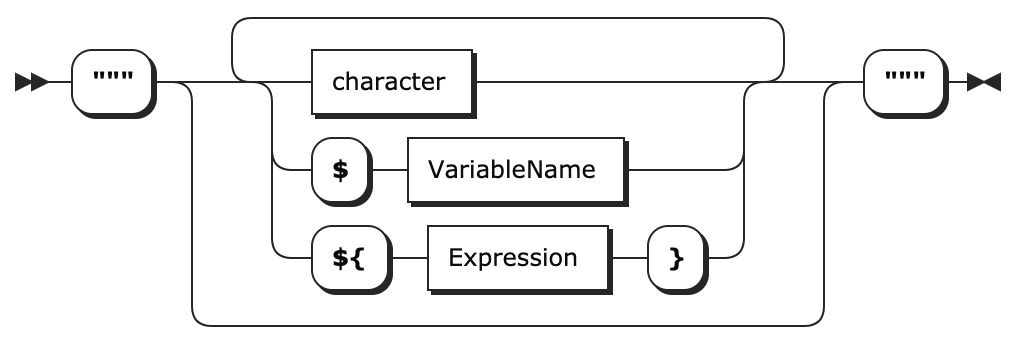
"""{color:#713A82}[${EpicLink.Issuetype}]{color} ${EpicLink.EpicName}"""Оба результата похожи по структуре. По факту они состоят из тройных кавычек """ в начале и в конце выводимой строки, указания цвета с открывающим {color: ЦВЕТ} и закрывающим {color} блоками, а также операций, переданных через символ $. Тройные кавычки говорят структуре, что внутри строки будут передаваться переменные, совершаться операции или использоваться блоки форматирования (например, цвета).
Для результата первого условия мы:
передаем тип родительской задачи
${Parent.Issuetype};заключаем его в квадратные скобки «[…]»;
подкрашиваем все это зеленым цветом — оборачивая выражение [
${Parent.Issuetype}]в блок выбора цвета{color:green}…{color}, куда вписали цвет «green»;и последнее — через пробел добавляем название задачи-родителя
${Parent.Summary}.
Таким образом, у нас получится строка «[Story] Какое-то название задачи». Как вы могли догадаться, Summary — это тоже стандартная переменная.
Чтобы схема конструирования подобных строк была понятнее, прикреплю картинку из официальной документации.
Аналогичным способом собираем строку для второго результата, но цвет задаем уже через hex-код. Мне показалось, что цвет эпика — это «#713A82» (в комментариях, кстати, можете предложить более точный цвет для эпика). Не забываем и про поля (свойства), которые меняются для эпика. Вместо «Summary» — «EpicName», вместо «Parent» — «EpicLink».
В итоге схему нашей формулы можно представить в виде таблицы условий.
Условие | Результат |
Задача-родитель существует, а ее тип — Story | Строка с зеленым типом задачи-родителя и ее названием |
Поле Epic Link заполнено | Строка с эпик-цветом типа и его названием |
По умолчанию в поле выбрана опция отображения «General», и если ее не менять, то результат будет выглядеть как обычный текст — без изменения цвета и распознавания блоков. Если изменить формат отображения на «Wiki Markup», то текст преобразится.
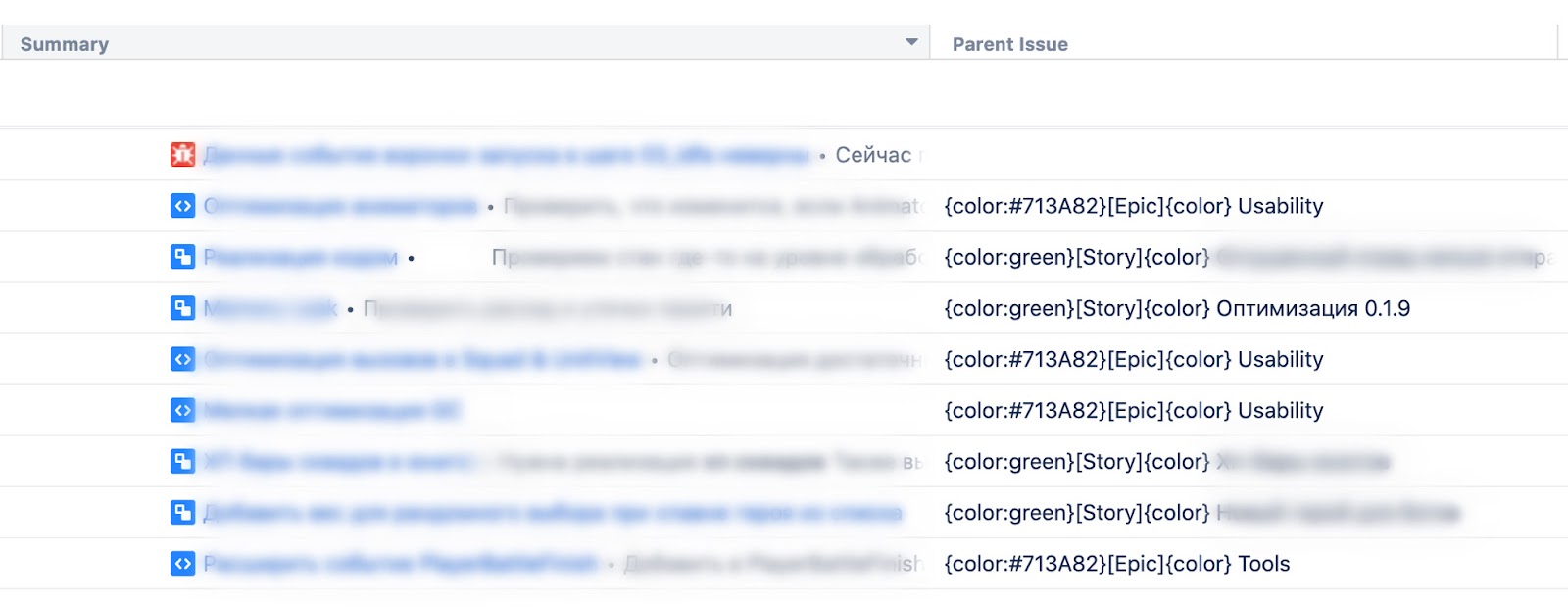
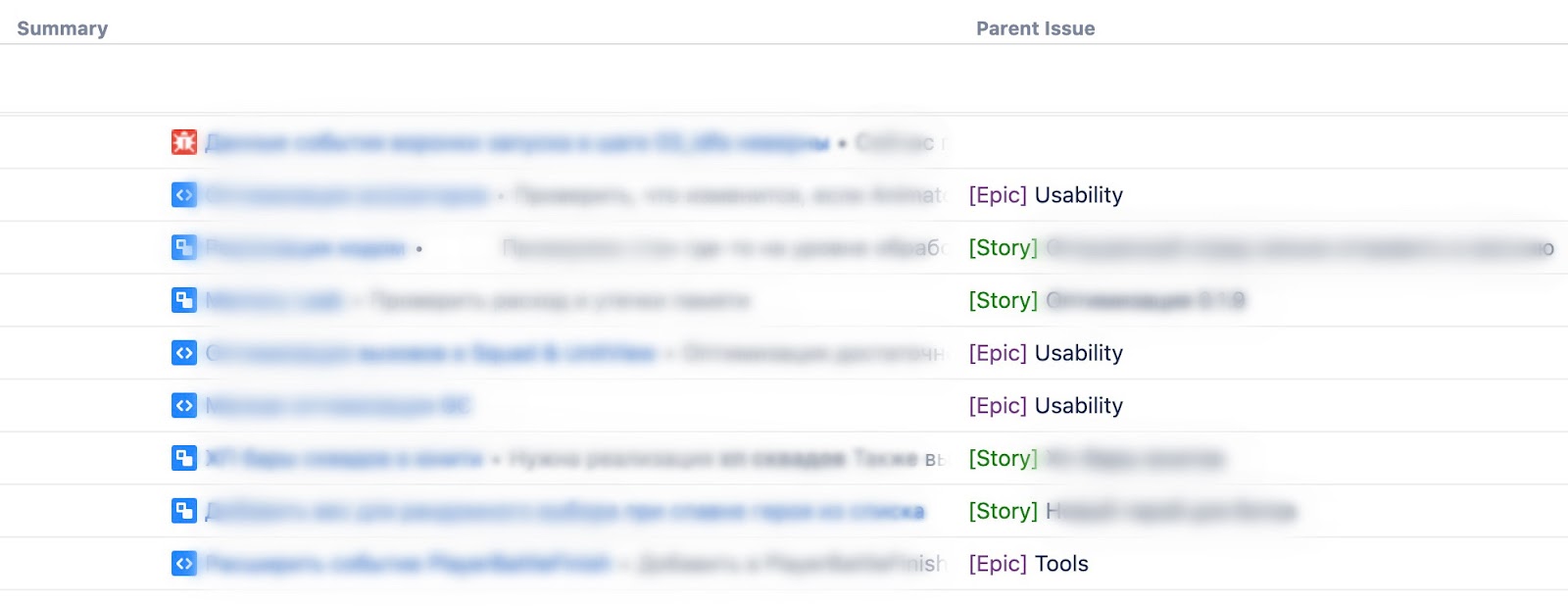
Теперь давайте познакомимся с переменными, которые не относятся к Jira-полям — с локальными переменными.
Расчет суммы Story points с цветовой индикацией

Проблема
Из прошлого примера вы узнали, что мы работает с задачами типа Story, у которых есть подзадачи (Sub-task). Отсюда возникает особый кейс с оценками.
Чтобы получить оценку стори, мы суммируем оценки ее подзадач, которые оцениваются в абстрактных story points. Подход необычный, но для нас работает.
Таким образом, когда у стори нет оценки, а у подзадач есть — проблема отсутствует, но когда оценка есть и у стори, и у подзадач, то стандартная опция от Structure — «Σ Story Points» работает некорректно. В ней к сумме подзадач прибавляется оценка самой стори.
В итоге в стори отображается неверная сумма. Хочется от этого избавиться и добавить индикацию несоответствия установленной оценке в стори и суммы по подзадачам.
Идея решения
Нам сразу потребуется несколько условий, так как все зависит от того, установлена ли оценка в стори.
Итак, условия:
Когда оценки у стори нет — оранжевым цветом выводим сумму оценок по саб-таскам, чтобы обозначить, что это значение еще не установлено в стори.
Если у стори оценка есть, то проверяем, соответствует ли она сумме оценок подзадач:
если не соответствует, то окрашиваем оценку красным, а рядом в скобках пишем верную сумму;
если оценка и сумма сходятся — просто пишем оценку зеленым цветом.
В тексте этих условий можно запутаться, поэтому упростим их до схемы.
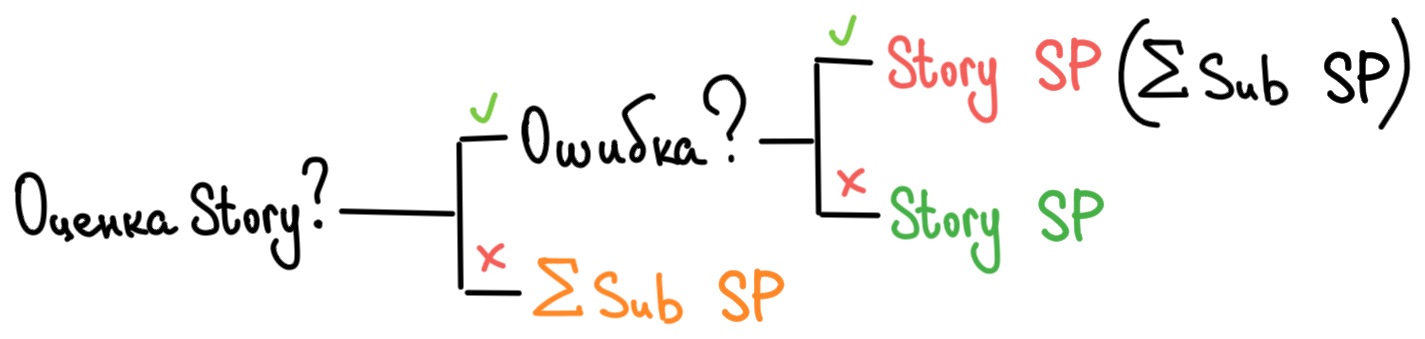
Что используем:
маппинг переменных;
локальные переменные;
методы агрегации;
условия;
текст с форматированием.
Пример кода
with isEstimated = storypoints != undefined:
with childrenSum = sum#children{storypoints}:
with isStory = issueType = "Story":
with isErr = isStory AND childrenSum != storypoints:
with color = if isStory :
if isEstimated :
if isErr : "red"
else "green"
else "orange":
if isEstimated : """{color:$color}$storypoints{color}
${if isErr :""" ($childrenSum)"""}"""
else """{color:$color}$childrenSum{color}"""Разбор решения
Прежде, чем нырять с головой в код, давайте преобразуем нашу схему в более «кодерский» вид, чтобы понять, какие переменные нам потребуются.

Из схемы видим, что нам потребуются:
переменные условия:
isEstimated (наличие оценки);
isError (соответствие оценки стори и суммы).
одна переменная цвета текста — color;
и еще две переменных оценок:
sum (сумма оценок подзадач);
и sp (оценка стори).
Более того, переменная color тоже зависит от ряда условий, например, от наличия оценки и от типа задачи в строке (см. схему ниже).
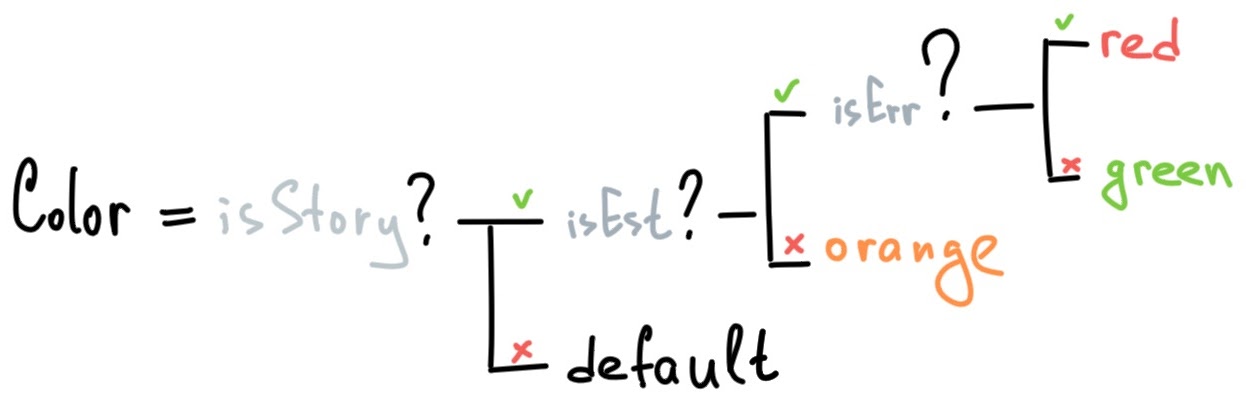
Поэтому для определения цвета нам понадобится еще одна переменная условия isStory, которая указывает, является ли тип задачи Story.
Переменная sp (storypoints) будет стандартной, то есть она автоматически маппится на соответствующее Jira-поле. Остальные переменные нам следует определить самим и они будут у нас локальными.
Теперь попробуем реализовать схемы кодом. Для начала определим все переменные.
with isEstimated = storypoints != undefined:
with childrenSum = sum#children{storypoints}:
with isStory = issueType = "Story":
with isErr = isStory AND childrenSum != storypoints:Строки объединяет одна и та же схема синтаксиса — ключевое слово with, имя переменной и в конце строки символ двоеточия «:».
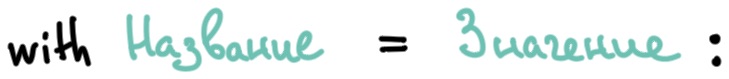
Ключевое слово with используется для обозначение локальных переменных (и кастомных функций, но об этом в отдельном примере). Оно сообщает формуле, что сейчас будет обозначена переменная, которую не нужно маппить. Символ двоеточия «:» сигнализирует о завершении определения переменной.
Таким образом, создаем переменную isEstimated (напомню, что регистр не важен). В ней будем хранить либо 1, либо 0 в зависимости от того, заполнено ли поле story points. Переменная storypoints маппится автоматически, так как до этого мы не создавали локальную переменную с таким же именем (например, так with storypoints = … :).
Значение undefined — обозначает несуществование чего-либо (как в других языках null, NaN и тому подобных). Поэтому выражение storypoints != undefined можно читать как вопрос: «Заполнено ли поле story points?».
Дальше нам следует определить сумму сторипоинтов всех дочерних задач. Для этого создаем локальную переменную childrenSum.
with childrenSum = sum#children{storypoints}:Сумма подсчитывается через функцию агрегации. Про такие функции можно почитать в официальной документации. Если описать «в двух словах», то Structure может совершать различные операции с задачами, учитывая иерархию текущего view.
Мы пользуемся функцией суммы — sum и в дополнение к ней через символ «#» передаем уточнение children, которое ограничивает подсчет суммы только дочерними задачами у текущей строки. В фигурных скобках указываем, какое поле хотим суммировать — нам нужна оценка в сторипоинтах (storypoints).
Следующая локальная переменная isStory хранит в себе условие — является ли тип задачи в текущей строке Story.
with isStory = issueType = "Story":Для этого мы обращаемся к знакомой по прошлому примеру переменной issueType, то есть типу задачи, которая сама маппится на нужное поле. Мы делаем это, так как это стандартная переменная, и мы не определяли ее ранее через with.
Теперь определим переменную isErr — она служит сигналом несоответствия суммы саб-тасок и оценки стори.
with isErr = isStory AND childrenSum != storypoints: Здесь мы уже используем созданные ранее локальные переменные isStory и childrenSum. Чтобы сигнализировать об ошибке, нам нужно одновременное выполнение двух условий — тип задачи является Story (isStory) и (AND) сумма дочерних оценок (childrenSum) не равна (!=) установленной оценке в задаче (storypoints). Да, как и в JQL, мы можем пользоваться связующими словами при создании условий, например, AND или OR.
Обращаю внимание, что для каждой из локальных переменных в конце строки стоит символ «:». Напомню, что он должен стоять только в конце, после всех операций, определяющих переменную. Например, если нам нужно разбить определение переменной на несколько строк, то двоеточие «:» ставится только после последней операции. Как в примере с переменной color — цветом текста.
with color = if isStory :
if isEstimated :
if isErr : "red"
else "green"
else "orange":Тут мы видим много «:», но они выполняют разную роль. Двоеточие после if isStory — это обозначение результата условия isStory. Вспомним конструкцию: if условие : результат. Представим эту конструкцию в более сложной форме, которая определяет переменную.
with переменная =
(if условие : (if условие2 : результат2 else результат3) ):Получается, что if условие2 : результат2 else результат3 — это как бы результат первого условия, а в самом конце стоит двоеточие «:», завершающее определение переменной.
На первый взгляд, определение color может показаться сложным, хотя по факту тут расписана, схема определения цвета, нарисованная в начале примера. Просто в качестве результата первого условия начинается еще одно условие — вложенное условие, а в нем еще одно.
А вот финальный результат чуть-чуть отличается от нарисованной схемы.
if isEstimated : """{color:$color}$storypoints{color}
${if isErr :""" ($childrenSum)"""}"""
else """{color:$color}$childrenSum{color}"""Нам не обязательно два раза писать в коде строку «{color}$sp», как было в схеме. Мы поступим хитрее. В ветке, если у задачи есть оценка, мы всегда будем выводить строку {color: $color}$storypoints{color} (то есть просто оценку в сторипоинтах нужным цветом), а если есть ошибка, то через пробел дополним строку суммой оценок саб-тасок — ($childrenSum).
Если ошибки нет, она добавляться не будет. Также обращаю внимание, что символа «:» нет, так как мы не определяем переменную, а выводим финальный результат через условие.
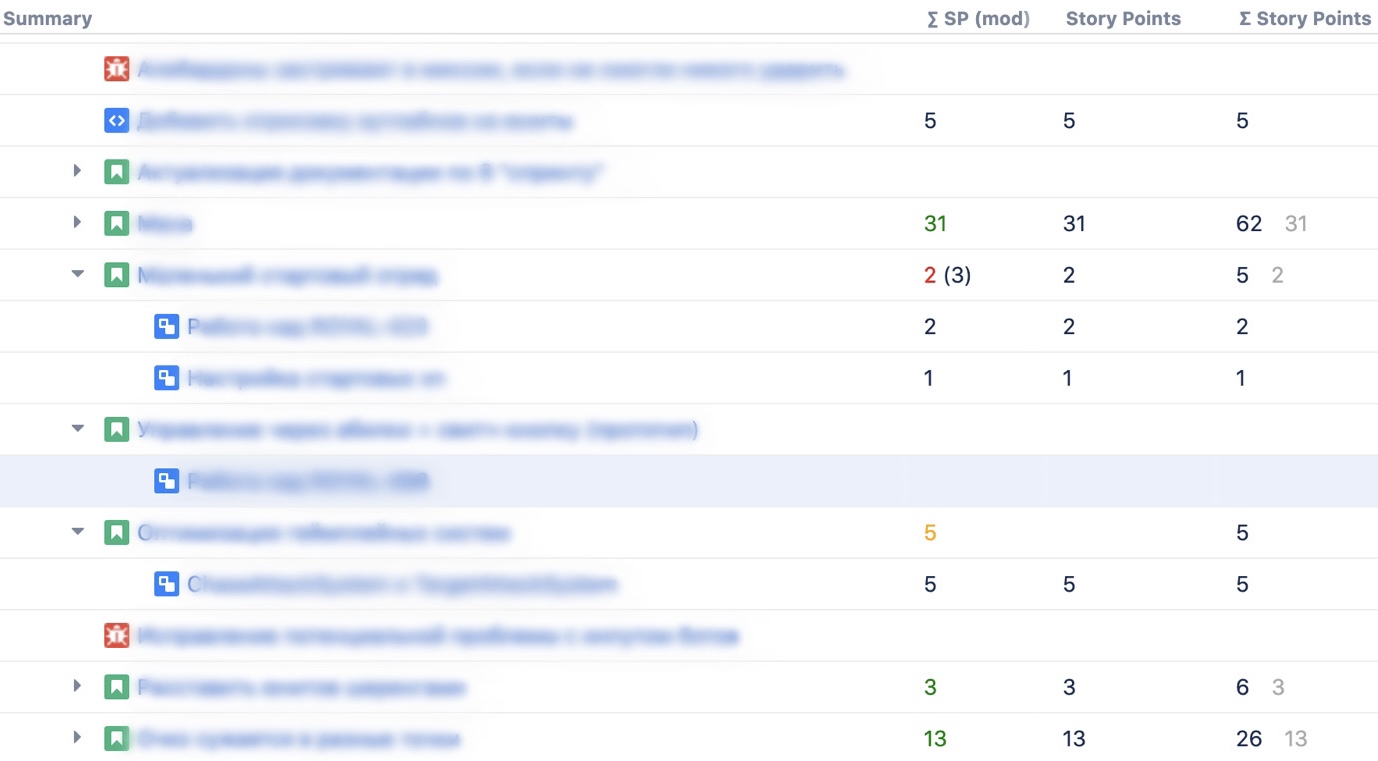
Наш труд мы можем оценить на рисунке ниже в поле «∑ SP (mod)». На скриншоте специально приведены два дополнительных поля:
«Story Points» — это оценка в story points (стандартное Jira-поле).
«∑ Story Points» — стандартное кастомное поле от Structure, которое некорректно считает сумму.
На этих примерах мы с вами разобрали основные фишки языка структуры, которые помогут вам решить большинство возникающих проблем. Нам осталось посмотреть на еще две полезные фишки — свои функции и массивы. Пойдем по порядку и посмотрим, как сделать свою, кастомную функцию.
Последние изменения

Проблема
Иногда задач в спринте много и есть вероятность пропустить небольшие изменения в них. Например, упустить, что появилась новая подзадача или одна из стори пошла в работу. Было бы неплохо иметь инструмент, помогающий отмечать последние важные изменения в задачах.
Идея решения
Нас интересует три типа изменения статуса задач, произошедших со вчера: задача пошла в работу, появилась новая задача, задача закрыта. Дополнительно будет полезно отмечать, что задача закрыта с резолюшеном «Won’t Do».
Для этого мы создадим поле со строкой из эмодзи, отвечающих за последние изменения. Например, если вчера была создана задача и она же пошла в работу, то около нее будет отмечено сразу два эмодзи — «В работе» и «Новая задача».
Может появиться вопрос — зачем нам такое кастомное поле, если можно вывести несколько дополнительных полей, например, дату перехода в статус «In Progress» или отдельное поле «Resolution». Ответ прост — иконки воспринимаются проще и быстрее, чем текст, который еще нужно проанализировать и собрать взглядом из разных полей. Формула все соберет в одном месте и проанализирует за нас, что сэкономит нам энергию и время на более полезные дела.
Давайте сразу определим, за что будут отвечать разные эмодзи:
создание новой задачи привычнее всего отметить звездочкой *️⃣;
завершенную задачу имеет смысл обозначить галочкой — ✅;
задачу, которую решили отменить («Won’t Do») — красным крестиком ❌;
а вот задача, которую взяли в работу, отметим ракетой 🚀 (так привычнее именно для нашей команды. У вас, возможно, по-другому).
Что используем:
маппинг переменных;
методы языка Expr;
локальные переменные;
условия;
свою функцию.
Пример кода
if defined(issueType):
with now = now():
with daysScope = 1.3:
with workDaysBetween(today, from)=
(
with weekends = (Weeknum(today) - Weeknum(from)) * 2:
HOURS_BETWEEN(from;today)/24 - weekends
):
with daysAfterCreated = workDaysBetween(now,created):
with daysAfterStart = workDaysBetween(now,latestTransitionToProgress):
with daysAfterDone = workDaysBetween(now, resolutionDate):
with isWontDo = resolution = "Won't Do":
with isRecentCreated = daysAfterCreated >= 0
and daysAfterCreated <= daysScope
and not(resolution):
with isRecentWork = daysAfterStart >= 0 and daysAfterStart <= daysScope :
with isRecentDone = daysAfterDone >= 0 and daysAfterDone <= daysScope :
concat(
if isRecentCreated : "*️⃣",
if isRecentWork : "🚀",
if isRecentDone : "✅",
if isWontDo : "❌")Разбор решения
Для начала подумаем, какие глобальные переменные нам понадобятся, чтобы определить интересующие нас события. Нам важно знать, произошло ли со вчерашнего дня:
создание задачи;
перемещение в статус «In Progress»;
присвоение резолюшена (и какое именно).
Проверить все эти условия нам помогут уже известные и новые переменные маппинга:
created— дата создания задачи;latestTransitionToProgress— дата последнего перехода в статус «In Progress» (маппим как в первом примере);resolutionDate— дата завершения задачи;resolution— текст резолюшена.
Теперь перейдем к коду.
Первая строчка нас встречает условием, которое проверяет, существует ли тип задачи.
if defined(issueType):Это делается через встроенную функцию defined, которая проверяет существование указанного поля. Проверка сделана для оптимизации расчетов формулы.
Мы не будем нагружать бесполезными расчетами Structure, если строка не является задачей. Получается, весь код после этого if — это результат, то есть вторая часть конструкции if (условие : результат). И если условие не выполняется, то и код тоже не будет выполнен.
Следующая строка with now = now(): тоже нужна для оптимизации расчетов. Дальше в коде нам придется несколько раз сравнивать разные даты с текущей датой. Чтобы не делать один и тот же расчет несколько раз, мы посчитаем эту дату один раз и запишем ее в локальную переменную now.
Еще было бы неплохо отдельно хранить наше «вчера». Удобное «вчера» эмпирическим методом превратилось в 1,3 дня. Запишем это в переменную — with daysScope = 1.3:.
Теперь нам потребуется несколько раз рассчитывать количество дней между двумя датами. Например, между текущей датой и датой начала работы. Конечно, есть встроенная функция DAYS_BETWEEN, которая, вроде бы, должна нам подойти. Но, если задачу, например, создали в пятницу, то в понедельник мы не увидим отметку о новой задаче, так как по факту прошло больше, чем 1,3 дня. К тому же функция DAYS_BETWEEN считает только полное количество дней (то есть 0,5 дня превратится в 0 дней), что нам тоже не подходит.
Таким образом, сформировалось требование — нужно посчитать точное количество рабочих дней между датами. И в этом нам поможет кастомная функция.

Синтаксис ее определения очень похож на синтаксис определения локальной переменной. Единственное отличие и дополнение — это опциональное перечисление аргументов в первых скобках. Во вторых скобках находятся операции, которые будут выполняться при вызове нашей функции. Способ определения функции не единственный, но использовать будем именно этот (другие можно посмотреть в официальной документации).
with workDaysBetween(today, from)=
(
with weekends = (Weeknum(today) - Weeknum(from)) * 2:
HOURS_BETWEEN(from;today)/24 - weekends
):Наша кастомная функция workDaysBetween будет рассчитывать рабочие дни между датами today и from, которые передаются через аргументы. Логика функции очень проста — считаем количество выходных и вычитаем их из общего количество дней между датами.
Чтобы посчитать количество выходных, узнаем сколько прошло недель между today и from. Для этого считаем разницу между номерами каждой из недель. Этот номер получим из функции Weeknum, которая возвращает номер недели с начала года. Умножив эту разницу на два, мы получим количество прошедших выходных.
Дальше функция HOURS_BETWEEN считает количество часов между нашими датами. Полученный результат делим на 24, чтобы получить количество дней. А из них вычитаем выходные — таким образом получим рабочие дни между датами.
Пользуясь нашей новой функцией, определим пачку вспомогательных переменных. Обратите внимание, что некоторые даты в определениях — это глобальные переменные, о которых мы говорили в начале примера.
with daysAfterCreated = workDaysBetween(now,created):
with daysAfterStart = workDaysBetween(now,latestTransitionToProgress):
with daysAfterDone = workDaysBetween(now, resolutionDate):Для читаемости кода определим переменные, хранящие в себе результаты условий.
with isWontDo = resolution = "Won't Do":
with isRecentCreated = daysAfterCreated >= 0
and daysAfterCreated <= daysScope
and not(resolution):
with isRecentWork = daysAfterStart >= 0 and daysAfterStart <= daysScope :
with isRecentDone = daysAfterDone >= 0 and daysAfterDone <= daysScope :Замечу, что для переменной isRecentCreated я добавил необязательное условие and not(resolution) — оно помогаем мне упростить будущую строку, так как если задача уже закрыта, то мне неинтересна информация о ее недавнем создании.
Финальный результат конструируется через функцию concat, соединяющую строки.
concat(
if isRecentCreated : "*️⃣",
if isRecentWork : "🚀",
if isRecentDone : "✅",
if isWontDo : "❌")Получается, эмодзи будет в строке только в тех случаях, когда переменная в условии равна 1. Таким образом, наша строка может одновременно отображать независимые изменения задачи.
Мы затронули тему учета рабочих дней без выходных. С ней связана еще одна проблема, которую мы разберем в нашем последнем примере и заодно познакомимся с массивами.
Расчет времени работы, исключая выходные

Проблема
Бывает полезно знать, сколько времени задача была в работе, исключая выходные дни. Это нужно, например, для анализа выпущенной версии. Чтобы понять, чем мешают выходные, представьте, что есть две задачи и обе находятся в работе четыре дня. Только одна в работе с понедельника по четверг, а другая — с пятницы по понедельник. В такой ситуации мы не можем утверждать, что задачи равносильны, хотя разница календарных дней нам говорит обратное.
К сожалению, Structure «из коробки» не умеет игнорировать выходные дни, и поле с опцией «Time in status…» выдает результат независимо от настроек Jira — даже если суббота и воскресенье указаны как выходные.
В итоге наша цель — подсчитать точное количество рабочих дней, игнорируя выходные, и правильно учесть влияние на это время переходов по статусам.
Причем тут статусы? Отвечаю. Предположим, мы насчитали, что между 10 и 20 марта задача была в работе три дня. Только вот из них она сутки была на паузе и еще полтора дня в ревью. Получается, непосредственно в работе задача была только полдня.
Именно из-за проблемы перехода по статусам нам не подойдет решение из прошлого примера — потому что кастомная функция workDaysBetween учитывает только время между двумя выбранными датами.
Идея решения
Эту задачу можно решить разными способами. Метод в примере самый дорогой в плане производительности, но самый точный в плане учета выходных дней и статусов. Обращаю внимание, что его реализация работает только в Structure-версии старше 7.4 (декабрь 2021).
Итак, идея формулы в следующем:
узнаем, сколько дней прошло со старта до завершения задачи;
делаем из этого массив — то есть список дней между началом и концом работы;
оставляем в списке только выходные;
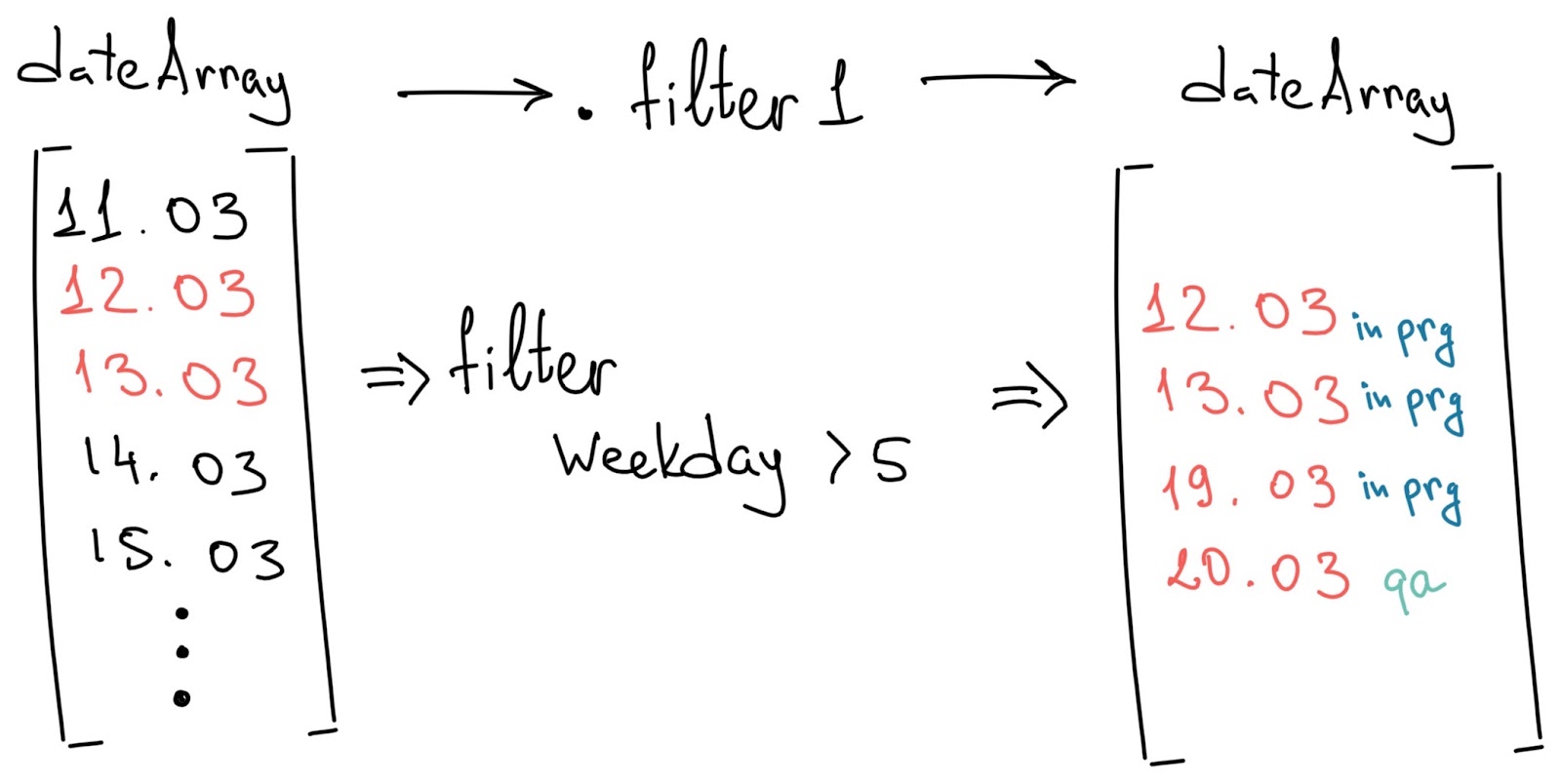
из этих выходных оставляем только те, в которых задача была в статусе «In Progress» (тут нам поможет фишка из версии 7.4 — «Historical Value»);
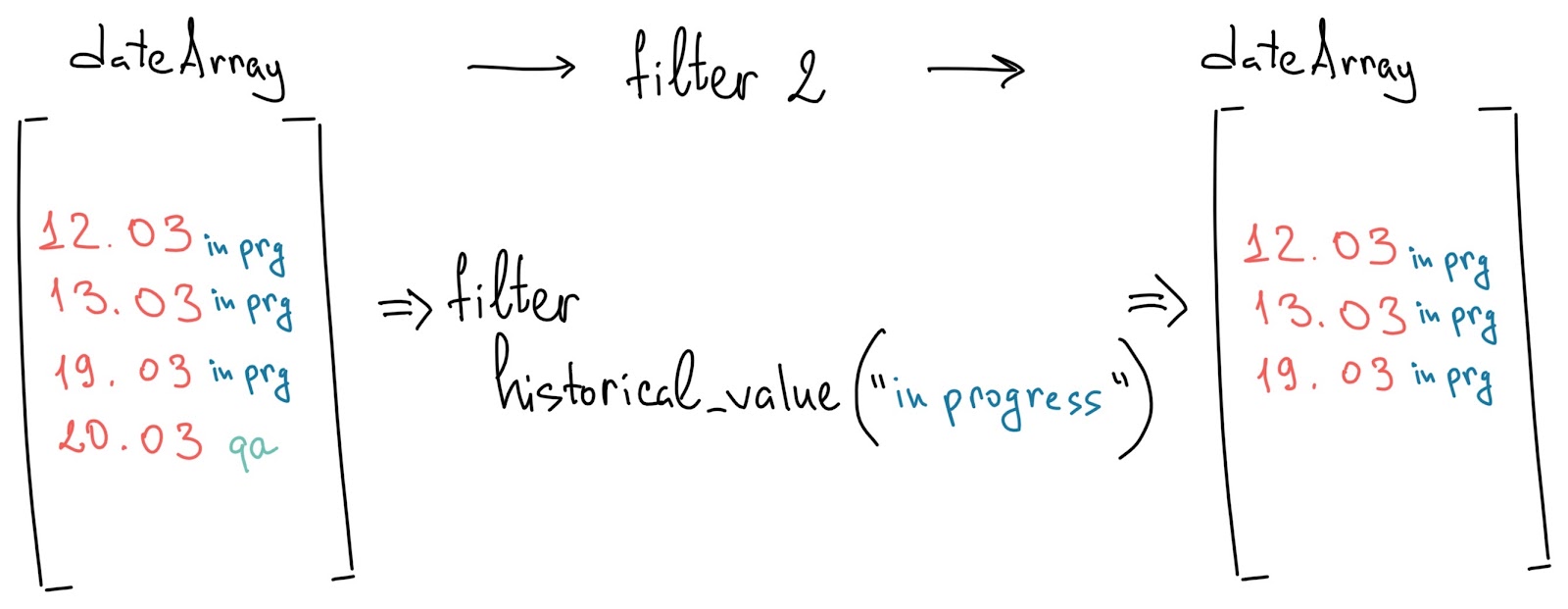
теперь в списке остались только те выходные, которые попали на период «In Progress»;
отдельно узнаем общее время, проведенное в статусе «In Progress» (через встроенную в Structure опцию «Time in status…»);
и вычитаем из этого времени количество ранее полученных выходных.
Таким образом, мы получим точное время работы над задачей, игнорируя выходные дни и переходы по лишним статусам.
Что используем:
маппинг переменных;
методы языка Expr;
локальные переменные;
условия;
внутренний метод (своя функция);
массивы;
обращение к истории задачи;
текст с форматированием.
Пример кода
if defined(issueType) :
if status != "Open" :
with finishDate =
if toQA != Undefined : toQA
else if toDone != Undefined : toDone
else now():
with startDate = DEFAULT(toProgress, toDone):
with statusWeekendsCount(dates, status) =
(
dates.filter(x -> weekday(x) > 5 and historical_value(this,"status",x)=status).size()
):
with overallDays = round(hours_between(startDate,finishDate)/24):
with sequenceArray = SEQUENCE(0,overallDays):
with datesArray = sequenceArray.map(DATE_ADD(startDate,$,"day")):
with progressWeekends = statusWeekendsCount(datesArray, "in Progress"):
with progressDays = (timeInProgress/86400000 - progressWeekends).round(1):
with color = if(
progressDays = 0 ; "gray"
; progressDays > 0 and progressDays <= 2.5; "green"
; progressDays > 2.5 and progressDays <= 4; "orange"
; progressDays > 4; "red"
):
"""{color:$color}$progressDays d{color}"""Разбор решения
Прежде, чем переносить наш алгоритм в код, облегчаем расчеты для Structure.
if defined(issueType) :
if status != "Open" :Если строка не является задачей или ее статус «Open», то такие строки будем пропускать. Нас интересуют только задачи, которые были запущены в работу.
Чтобы посчитать количество дней между датами, нужно сначала определить эти даты — finishDate и startDate.
with finishDate =
if toQA != Undefined : toQA
else if toDone != Undefined : toDone
else now():
with startDate = DEFAULT(toProgress, toDone):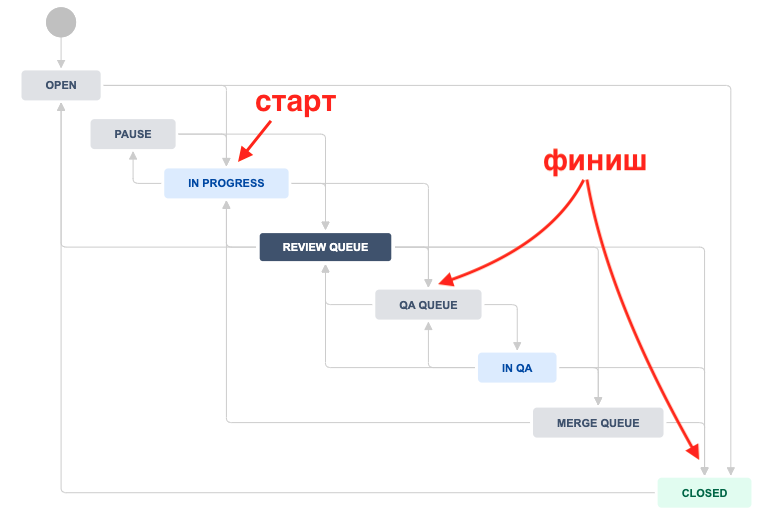
Будем считать, что дата завершения задачи (finishDate) — это:
либо дата перехода задачи в статус «QA»;
либо дата перехода в «Closed»;
либо если задача все еще в «In Progress», то сегодняшнее число (чтобы понять, сколько уже прошло времени).
Дата начала работы — startDate, определяется по дате перехода в статус «In Progress». Бывают случаи, когда задача сразу закрывается без перехода в работу. В таком кейсе считаем дату закрытия датой начала работы, чтобы результат был 0 дней.
Как вы могли догадаться, toQA, toDone и toProgress — это переменные, которые нужно маппить на соответствующие статусы как в первом и прошлом примерах.
Также видим новую функцию DEFAULT(toProgress, toDone). Она проверяет, есть ли какое-то значение у toProgress, и если нет, то использует значение переменной toDone.
Дальше идет определение кастомной функции statusWeekendsCount, но к ней мы вернемся позже, так как она плотно связана со списками дат. Лучше сразу перейдем к определению этого списка, чтобы потом понять, как применить к нему нашу функцию.
Мы хотим получить список из дат вида: [startDate (допустим 11.03), 12.03, 13.03, 14.03 … finishDate]. Простой функции, которая сделала бы за нас всю работу в Structure, не существует. Поэтому воспользуемся хитростью.
Создадим простой список из последовательности цифр от 0 до количества дней в работе, то есть [0, 1, 2, 3 … n дней в работе].
К каждой цифре (то есть дню) прибавим дату старта задачи. В результате получим список (массив) нужного вида: [начало + 0 дней, начало + 1 день, начало + 2 дня … начало + n дней работы].
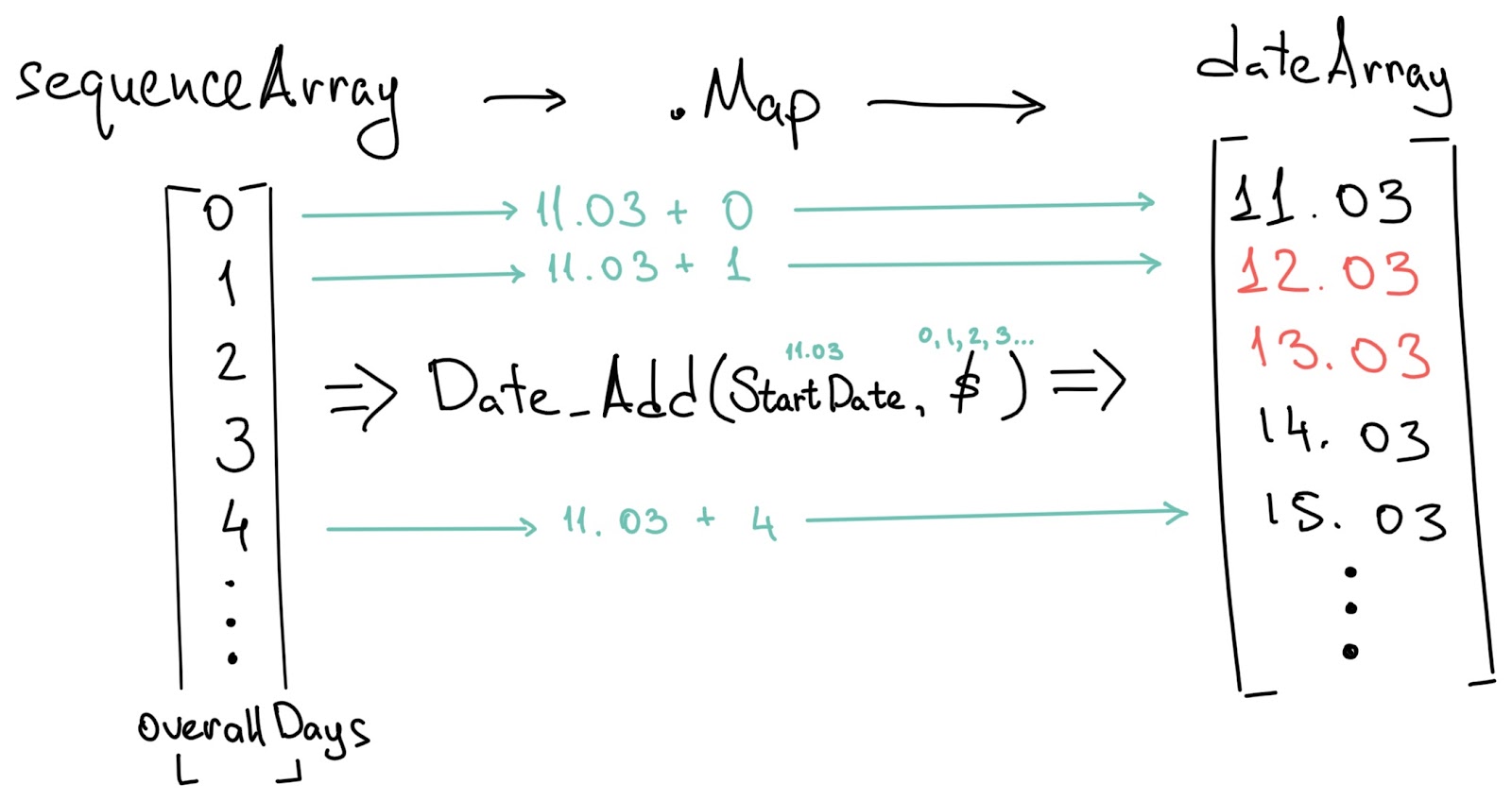
Теперь посмотрим, как такое реализовать кодом. Здесь мы будем работать с массивами.
with overallDays = round(hours_between(startDate,finishDate)/24):
with sequenceArray = SEQUENCE(0,overallDays):
with datesArray = sequenceArray.map(DATE_ADD(startDate,$,"day")):Считаем, сколько всего дней занимает работа над задачей. Как и в прошлом примере — через деление на 24 и функцию hours_between(startDate,finishDate). Результат записываем в переменную overallDays.
Массив последовательности цифр создаем в виде переменной sequenceArray. Этот массив конструируется через функцию SEQUENCE(0,overallDays), которая просто делает массив нужного размера с последовательностью от 0 до overallDays.
Дальше происходит магия. Одна из функций работы с массивами — это map. Она применяет указанную операцию на каждый элемент массива.
Наша задача — к каждой цифре (то есть номеру дня) прибавить дату старта. Такое умеет делать функция DATE_ADD, которая добавляет к указанной дате определенное количество дней, месяцев или лет.
Зная это, расшифруем строку:
with datesArray = sequenceArray.map(DATE_ADD(startDate, $,"day"))К каждому элементу в массиве sequenceArray функция .map() применяет DATE_ADD(startDate, $, "day").
Посмотрим, что передается в аргументах для DATE_ADD. Первое — это startDate — дата, к которой будет прибавляться нужное число. Это число указывается вторым аргументом, но мы видим $.
Символ $ обозначает элемент массива. Структура понимает, что функция DATE_ADD применяется к массиву, и поэтому вместо $ будет стоять нужный элемент массива (то есть 0, 1, 2 …).
Последний аргумент "day" — это указание того, что мы прибавляем именно день, так как функция может прибавлять и день, и месяц, и год в зависимости от того, что мы укажем.
Таким образом, в переменной datesArray будет хранится массив из дат от начала работы до ее завершения.
Вернемся к кастомной функции, которую мы пропустили. Она будет выполнять отсеивание лишних дней и подсчитывать остаток. Этот алгоритм мы описали в самом начале примера, до разбора кода, а именно в пунктах 3 и 4 про отсеивание выходных и статусов.
with statusWeekendsCount(dates, status) =
(
dates.filter(x -> weekday(x) > 5 and historical_value(this,"status",x)=status).size()
):В кастомную функцию будет передается два аргумента — массив из дат, назовем его dates, и искомый статус — status. К переданному массиву dates применяем функцию .filter(), оставляющую в массиве только те записи, которые прошли через условие фильтра. В нашем случае их два, и они объединены через and. После фильтра видим .size() — он возвращает размер массива после всех операций над ним.
Если упростить выражение, то получится что-то вроде — массив.фильтр(условие1 и условие2).размер(). Таким образом, в результате мы получили количество подходящих для нас выходных дней, то есть тех выходных, которые прошли условия.
Посмотрим внимательно на оба условия.
x -> weekday(x) > 5 and historical_value(this,"status",x)=statusВыражение x -> — просто часть синтаксиса фильтра, говорящая о том, что элемент массива мы будем называть x. Поэтому в каждом условии фигурирует x (подобно тому, как было с $). Получается, что x — это каждая дата из переданного массива dates.
Первое условие — weekday(x) > 5 требует, чтобы день недели даты x (то есть каждого элемента) был больше 5 — это либо суббота (6), либо воскресенье (7).
Второе условие использует historical_value
historical_value(this,"status",x) = statusЭто фишка структуры версии 7.4.
Функция обращается к истории задачи и смотрит указанное поле за определенную дату. В данном кейсе мы смотрим поле "status" на момент даты x. Переменная this — это просто часть синтаксиса функции, она маппится автоматически и обозначает текущую задачу в строке.
Таким образом, в условии мы сравниваем переданный аргумент status и поле "status", которое возвращает функция historical_value для каждой даты x в массиве. Если они совпадают, то запись остается в списке.
Последний штрих — это применение нашей функции для подсчета количества дней в нужном статусе.
with progressWeekends = statusWeekendsCount(datesArray, "in Progress"):
with progressDays = (timeInProgress/86400000 - progressWeekends).round(1):Сначала узнаем, сколько выходных со статусом "in Progress" попало в наш массив дат datesArray. То есть в кастомную функцию statusWeekendsCount передаем наш список дат и искомый статус. Функция убирает оттуда все будние дни и все выходные, в которых статус задачи отличался от "in Progress" и возвращает количество оставшихся в списке дней.
Затем вычитаем это количество из переменной timeInProgress, которую маппим через опцию «Time in status…».
Число 86400000 — это делитель, который превратит миллисекунды в дни. Функция .round(1) нужна, чтобы округлить результат до десятых, например до «4.1», иначе можно получить запись вида «4.0999999…».
Для индикации затянутости задачи введем переменную цвета — color. Будем ее менять в зависимости от количества затраченных дней.
серый — 0 дней.
зеленый — больше 0, но менее 2,5 дней;
рыжий — от 2,5 до 4 дней;
красный — более 4 дней.
with color = if(
progressDays = 0 ; "gray"
; progressDays > 0 and progressDays <= 2.5; "green"
; progressDays > 2.5 and progressDays <= 4; "orange"
; progressDays > 4; "red"
):И финальная строка с выводом рассчитанных дней:
"""{color:$color}$progressDays d{color}"""Наш результат будет выглядеть как на рисунке ниже.

Кстати, в этой же формуле можно выводить время любых статусов. Если, например, в нашу кастомную функцию передать статус «Pause», а переменную timeInProgress маппить через «Time in … — Pause», то мы посчитаем точное время в паузе.
По аналогии с этой формулой можно объединить статусы и сделать запись типа «wip: 3.2d | rev: 12d», то есть рассчитать время в работе и время в ревью. Вы ограничены лишь фантазией и вашим workflow.
Заключение
Мы с вами посмотрели на исчерпывающее количество фишек языка формул, которые помогут вам сделать что-то аналогичное у себя или написать что-то совсем новое и интересное для анализа Jira-задач.
Надеюсь, статья помогла вам разобраться с формулами или хотя бы заинтересовала вас этой темой. Не претендую на «самый лучший код и алгоритм», так что если у вас есть идеи, как улучшить примеры — буду рад, если поделитесь.
Конечно, нужно понимать, что лучше, чем разработчики из ALM Works, про формулы не расскажет никто. Поэтому прикрепляю ссылки на их документацию и вебинары. И если вы начнете работать с кастомным полями, то вы будете туда очень часто заглядывать, чтобы посмотреть, какие еще функции есть.
Ссылки и документация
Самую активную и «живую» помощь вы всегда можете найти в Telegram-канале «Structure Community». Там очень приятные люди, которые готовы в любой момент подсказать решение и помочь с проблемой.
Примеры от ALM Works
Примеры формул — тут еще больше примеров применения формул. От самых простых до очень хитрых отображений, например, Burndown chart-ов.
Красивое форматирование — еще несколько примеров.
Документация
Список функций с массивами (SUM, MAX и прочее)
