
Привет, Хабр! Меня зовут Дмитрий Раевский, я Data Scientist в Райффайзенбанке, занимаюсь цифровизацией кредитов и кредитного контроля. Сегодня я хочу рассказать про оценку коммерческой недвижимости — объектов, которые используются для извлечения прибыли. Поскольку мы на Хабре, то разговор пойдет не об оценке в вакууме, а о привлечении технологий для решения этой задачи.
Мой рассказ я решил разделить на два смысловых раздела. В первом немного расскажу об оценке коммерческой недвижимости как задаче — что это, для чего нужно, как выполняется, какие есть сложности и т.п. Во втором — покажу, как эту задачу можно решить при помощи технологий. И бонусом — анонсирую большой хакатон по оценке коммерческой недвижимости от Райффайзенбанка.
Зачем банку оценивать недвижимость?
Практически в любом банке выдают кредиты под залог, поэтому объектов такого типа может быть очень много. Для банка недвижимость — дополнительная страховка в случае непредвиденных ситуаций , а для клиента — возможность получить крупную сумму кредита, иногда даже под меньшие проценты. Для правильного расчета размера кредита и других его показателей каждый объект залога проходит процедуру оценки — определение рыночной стоимости объекта. В нашем случае рассматриваться будет коммерческая недвижимость.
Оценка коммерческой недвижимости обычно проводится одним из двух методов (или их комбинацией):
1. Сравнительный подход — при таком подходе рыночная стоимость объекта определяется с помощью сравнения текущих предложений на рынке. Так, на сайте с предложениями о продаже коммерческой недвижимости (например, «Циан» или Avito) оценщик подбирает наиболее похожие объекты недвижимости — обычно от 3 до 6 аналогов, и сравнивает их.
2. Доходный подход — при таком подходе рыночная стоимость определяется как потенциальный доход от эксплуатации данного объекта. Здесь анализируется привлекательность местоположения объекта, цена за аренду похожих объектов на рынке и другие характеристики, влияющие на доходность коммерческой недвижимости. На основе анализа выводится рыночная стоимость объекта.

При оценке коммерческой недвижимости важную роль играет продолжительность этого процесса — чем медленнее оценщик выполняет свою задачу, тем дольше задерживается решение о выдаче кредита. Это, в свою очередь, повышает вероятность того, что клиент уйдет к конкуренту. Скорость оценки в этой сфере имеет огромное значение — чем быстрее банк работает с объектами, тем больше он их оценит. Соответственно, тем больше он выдаст кредитов — влияние на бизнес здесь самое прямое.
ИТ-решения для автоматической оценки
В разных странах рынок недвижимости развит неравномерно, поэтому все решения по автоматической оценке напрямую зависят от того, в рамках какого рынка велась разработка. Поэтому мы рассмотрим только инструменты по анализу и автоматической оценке недвижимости, которые на данный момент есть в России.
Вот какие основные факторы мы выявили для внедрения моделей по оценке недвижимости:
объем доступных данных;
историчность доступных данных;
качество данных;
инфраструктура;
На российском рынке есть немало компаний, качество оценки которых находится на высоком уровне (например, SRG или «Мобильный оценщик»), а сервисы поиска недвижимости, такие как «Циан», продолжают активно развивать это направление. Кроме того, собственные разработки есть даже в некоторых банках. Все эти решения разработаны на базе большого объема исторических данных по продаже объектов недвижимости.
Как выглядит интерфейс сервисов для оценки жилой недвижимости на примере мобильного оценщика:
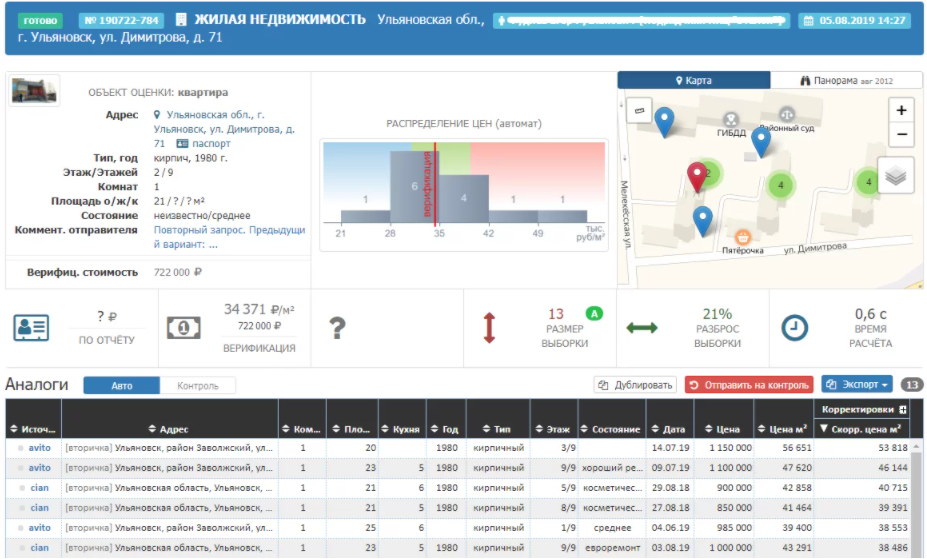
Технологии и автоматизация оценки недвижимости
С точки зрения Machine Learning (ML), задачу прогнозирования стоимости коммерческой недвижимости можно рассматривать с нескольких точек зрения:
Как предсказание стоимости — задача регрессии. Берем доступные данные о продаже объектов коммерческой недвижимости, делаем time series валидацию, проверяем итоговые метрики (например, mean absolute percentage error (MAPE), root mean squared error). После этого — анализируем качество модели.
Как задачу классификации. Если рассматривать сравнительный подход, то у нас уже есть исторические ручные оценки — то есть подобранные аналоги к каждому объекту оценки. На основе этих данных мы можем обучить классификатор, который сможет для каждого объекта оценки говорить, подходит он, — или нет. Если данных очень много, то вначале можно сделать предварительный отбор аналогов (например, по местоположению), и уже после этого натравить классификатор сверху.
Вместо задачи классификации можно решать эту задачу и как задачу ранжирования — все аналоги ранжируются от самого приоритетного, после этого выбирается топ n кандидатов.
Если первый пункт про предсказание стоимости решать традиционными state-of-the-art алгоритмами машинного обучения для табличных задач регрессии (например, градиентным бустингом), то теряется интерпретируемость алгоритма, которая иногда может быть важна. Во 2 и 3 случаях интерпретировать результаты алгоритма можно путем интерпретации подобранных аналогов для оценки.
Сейчас существует два основных источников данных для оценки и валидации в зависимости от доступности:
Предложения на рынке о продаже недвижимости. Они необходимы, чтобы можно было как минимум «скопировать» действия оценщика при сравнительном подходе.
Результаты ручных оценок реальных объектов недвижимости.
Если датасет по предложениям на рынке можно собрать и самостоятельно, то объем результатов ручных оценок на 1-2 порядка меньше, чем количество предложений на рынке недвижимости. К примеру, в банк ежедневно может поступать около 100 заявок на оценку недвижимости (ипотека или кредит). В то же время на любом сайте недвижимости можно найти сотни тысяч актуальных предложений о покупке недвижимости. Опытный специалист сразу увидит сложность в том, что мы обучаем модель на одном датасете, а делаем предсказания — на другом.
Как минимум для себя следует ответить на некоторые вопросы:
Какие фичи вообще доступны и в первом и втором датасете?
Отличаются ли распределения по фичам?
Есть ли сезонность и коррелируют ли они друг с другом?
Как грамотно построить валидацию алгоритма?
Если во втором датасете очень мало данных, как грамотно проверить, что алгоритм работает правильно?
Один из трюков, который поможет разобраться в этих вопросах, и уже хорошо зарекомендовавший себя при решении различных конкурсов машинного обучения, называется adversarial validation — мы позволим классификатору учиться отделять предложения на рынке от результатов ручных оценок.
С помощью этого подхода мы можем посмотреть, какие фичи у нас наиболее отличаются в выборках. Также он позволяет построить грамотную валидацию, выбирая из обучающей выборки только подходящие объекты. При таком подходе можно построить грамотную валидацию, по крайней мере, в наших разработках это играло важную роль — и дальше обучить модель, которая будет неплохо обобщаться и на валидационные данные.
Небольшой, но показательный пример
Допустим, вы грамотно построили валидацию, и метрики от ваших гипотез стабильно растут. Теперь следует показать бизнесу, что ваша модель работает хорошо, и что она готова к проду. Как бы хорошо ни была обучена модель, все равно появятся некоторое количество сильных выбросов (например, по MAPE), которые могут многое испортить.
Пример: если среднее значение MAPE=8%, но каждый 10-й объект имеет MAPE=80%, то есть большая вероятность, что каждый 10 клиент будет уходить из-за того, что модель сильно занизила/завысила стоимость его объекта. Понятно, что вряд ли банк сможет согласиться с таким риском. Поэтому с бизнесовой точки зрения отдельно нужно рассматривать несколько кейсов:
Количество кейсов на валидации, когда модель «несильно» отклоняется от ручной оценки (обычно этот порог +/-15% по отклонению);
Количество кейсов, когда модель «сильно» переоценила объект — переоценка ведет к увеличению возможных потерь в случае дефолта клиента;
Количество кейсов, когда модель «сильно» недооценила объект — недооценка ведет к уменьшению величины кредита, что может сказаться на решении клиента уйти в другой банк.
Можно долго и упорно улучшать качество своей модели, но выбросы вряд ли уйдут полностью. Поэтому очень остро стоит вопрос в аналитике «проблемных» объектов модели — например, аналитика, которая показывает, чем эти объекты отличаются от других. Сюда можно включить большой разброс цен по похожим аналогам в этой локации по сравнению с другими объектами. Тут же можно задействовать другие алгоритмы интерпретации результатов модели — например, SHAP. Главная задача — уметь отделить такие объекты от остальных, перестраховаться и отправить их на ручную оценку.
Итогом всех страданий станет рабочая модель, предсказывающая стоимость недвижимости, в результатах которой вы уверены, а также отделение «плохих» объектов от «хороших» для снижения риска для всего бизнеса.
Пример работы такой системы: один клиент хочет отдать в залог коммерческое помещение street-retail, находящееся на первом этаже многоэтажного жилого дома. Модель дает свою оценку, после чего с помощью второго алгоритма мы проверяем, что при обучении модели было достаточно похожих объектов в пределах одного километра. Тогда оценка первой модели принимается, и залоговый менеджер видит, что стоимость этого объекта рассчитана автоматически.
Другой пример — клиент хочет сдать в залог офисное встроенное помещение в элитном бизнес-центре в центре Москвы. Модель дает свою оценку, но по статистике мы видим, что в этом бизнес-центре очень большой разброс по ценам и мало объектов. Оценка модели не принимается, и залоговому менеджеру приходит уведомление, что лучше этот объект оценить руками.
Хотите решить эту задачу?
Мы планируем провести хакатон по оценке коммерческой недвижимости в сентябре 2021 года. Специально для этого мы подготовили датасеты и постановку задачи таким образом, чтобы она была максимально приближена к продакшену.

Почему хакатон может быть интересен DS-специалистам?
Актуальная задача и реальные данные, собранные за год.
Задача регрессии на табличках. Всем, кто соскучился по такой классике, будет очень интересно. Нестандартная метрика, приближенная к потребностям бизнеса.
Можно отточить свои навыки в плане построения правильного алгоритма валидации, на 100% приближенного к продовой реальности.
Интерпретация результатов модели (interpretable ml, causal inference) — самые лучшие подходы будут непременно оценены.
Регистрируйтесь!
