
In this article we present the ruDALL-E XL model, an open-source text-to-image transformer with 1.3 billion parameters as well as ruDALL-E XXL model, an text-to-image transformer with 12.0 billion parameters which is available in DataHub SberCloud, and several other satellite models.
Free demo available: https://rudalle.ru/en/
Free Telegram bot
Better and faster generation is available with the Salute App: https://sberdevices.ru/app/
Instagram with examples of the best generations
GitHub with ruDALL-E XL
Our demo now works with automatic translation from 107 languages:

Motivation
Multimodality has led the pack in machine learning in 2021. Neural networks are wolfing down images, text, speech and music all at the same time. OpenAI is, as usual, top dog, but as if in defiance of their name, they are in no hurry to share their models openly. At the beginning of the year, the company presented the DALL-E neural network, which generates 256x256 pixel images in answer to a written request. Descriptions of it can be found as articles on arXiv and examples on their blog.
As soon as DALL-E flushed out of the bushes, Chinese researchers got on its tail. Their open-source CogView neural network does the same trick of generating images from text. But what about here in Russia? One might say that “investigate, master, and train” is our engineering motto. Well, we caught the scent, and today we can say that we created from scratch a complete pipeline for generating images from descriptive textual input written in Russian.
Teams at Sber AI, SberDevices, Samara University, AIRI and SberCloud all actively contributed. We trained two versions of the model, each a different size:
ruDALL-E XXL, with 12.0 billion parameters
ruDALL-E XL, having 1.3 billion parameters
Some of our models are already freely available:
ruDALL-E XL [GitHub, HuggingFace, Kaggle]
Sber VQ-GAN [GitHub, HuggingFace]
ruCLIP Small [GitHub, HuggingFace]
Super Resolution (Real ESRGAN) [GitHub, HuggingFace]
The latter two models are included in the pipeline for generating images from text (as you’ll see later on).
The models ruDALL-E XL, ruDALL-E XXL, and ruCLIP Small are now available on DataHub. The models ruCLIP Large and Super Resolution (Real ESRGAN) will also be available soon there.
Training the ruDALL-E neural networks on the Christofari cluster has become the largest calculation task in Russia:
ruDALL-E XXL was trained for 37 days on the 512 GPU TESLA V100, and then also for 11 more days on the 128 GPU TESLA V100, for a total of 20,352 GPU-days;
ruDALL-E XL was trained for 8 days on the 128 GPU TESLA V100, and then also for 15 more days on the 192 GPU TESLA V100, for a total of 3,904 GPU-days.
Accordingly, training for both models totaled 24,256 GPU-days.
Now let’s explore what our generative models are capable of.
")
Why is Big Tech doing image generation?
The long term goal of this research is the creation of multimodal neural networks. They will be able to pull on concepts from a variety of mediums (from text and visuals at first) in order to better understand the world as a whole.
Image generation might seem like the wrong rabbit hole in our century of big data and search engines. But it actually addresses two important requirements that search is currently unable to cope with:
Being able to describe in writing exactly what you’re looking for and getting a completely new image created personally for you.
Being able to create at any time as many licence-free illustrations as you could possibly want
The most obvious uses for image generation are:
Illustrative photos for journalists, copywriters and advertisers. You can create imagery for articles automatically (meaning also more cheaply and quickly), and generate concept-boards for ads simply from a written description. Some examples:
")
")
")
An artwork, completely license-free, can also be created ad infinitum:
")
"Векторная иллюстрация с розовыми цветами" (“Vector artwork with pink flowers”) Interior design mock-ups. You can do a quick visual check of your ideas for a remodel, and play with colors, form, and light:
")
")
")
Visual art. A source of visual concepts combining various attributes with abstraction:
")
"Темная энергия" (“Dark energy”)
")
")
")
")
")
")
")
Model Architecture
The architectural foundation of DALL-E, the so-called transformer, is an encoder-decoder model. It works in two steps. First, the encoder needs to calculate an embedding from the input. Then the decoder deciphers the resulting vector in view of a known target so that the output matches expectations.


The self-attention is the most important component of the transformer. It helps the model determine which parts of the input are important and how important each part is to other parts of the input. Conceptually, the self-attention allows the model to refine the input series via insights generated from global information about all the elements in the series. Similar to LSTM models, this makes the transformer naturally good with long series data. However, in contrast with LSTM models, transformers are also good at parallelization, and, by turn, its effective inference.
The transformer also creates a dictionary. Each element in the dictionary is a token. The size of the dictionary depends on the model. Thus, input first is converted into a series of tokens that then is converted into an embedding with the help of the encoder. For the text, its own tokenizer is used (in our case YTTM tokenizer); for the image, low-level tokens are first calculated, and then visual tokens are calculated in a sliding window. Using a self-attention allows the model to extract context from input token series during learning. It’s worth noting that training the model requires a large volume of (ideally “clean”) data, which we’ll discuss presently.
How ruDALL-E is constructed
ruDALL-E architecture is designed so that the transformer will autoregressively learn to model textual and visual tokens as a unified flow. However, directly using pixels as a representation of the image requires extraordinary amounts of memory. To avoid training only short term dependencies between pixels and text (meaning to attain a higher level of execution overall) the model should undergo training in two steps:
Images having undergone compression to a resolution of 256x256 enter the autoencoder (we used our own SBER VQ-GAN, having earlier improved the metrics for generation on some domains, which we described here, and even shared our code), which learns to compress them into a 32x32 matrix of tokens, totalling 1024. The 8 times compression factor ensures the image can be reconstructed without much loss of quality, as can be seen in the cat picture below.
The transformer learns to combine the 1024 image tokens with the textual tokens. We had meanwhile used the YTTM tokenizer to prepare 128 tokens from the text input. The image and the textual tokens come into contact one after the next in series.

Important aspects of training
At the current time, OpenAI’s code for DALL-E is not publicly available. Their publication describes the model in general terms, but it does attend to a few important subtleties in implementation. We started with our own code for training ruGPT models and, after studying the documentation, other attempts from open-sourcers, and Chinese efforts, we coded our own DALL-E model. It includes features like positional coding of image blocks, convolutional and coordinated masked attention layers, a general representation of text and image embeddings, weighted losses in the text and image sections, and a dropout-tokenizer.
Because of the enormous calculation requirements to effectively train a model, one must use the fp16 precision mode. It’s 5-7 times faster than in the classic fp32, and it takes up less space. But barriers to precise numerical representations created a mass of difficulties for such a deep architecture:
a) Sometimes really large values found in the network can cause a Nan loss and halt learning;
b) When the learning rate is set at low values in order to avoid problem a), the network stops improving and falls apart because of a large number of zeros appearing in gradients.
To address this issue, we implemented some ideas from the CogView project at China’s Tsinghua University. We also carried out our own research into stability, which gave us a number of architectural insights that then helped us stabilize learning. Since we found ourselves training the model and researching it simultaneously, the road to success turned out to be long and bumpy. For distributed learning across a couple DGX, we used DeepSpeed, just as we did for ruGPT-3.
Collecting and filtering data. As everybody knows, a lot of data is needed to train a transformer, and it should be “clean.” We defined “clean” as having two properties. First and foremost, the data must contain good verbal descriptions (which we then translated into Russian). And secondly, images must have an aspect ratio no worse than 1:2 or 2:1, so that cropping doesn’t exclude the main content of the image.
Our first move was to snare the data that OpenAI proffered in their publication (over 250 million pairs) along with the data used by Cogview (30 million pairs). Together this included: Conceptual Captions, YFCC100m, Wikipedia data, and ImageNet. Then we added the OpenImages, LAION-400m, WIT, Web2M and HowTo datasets as sources of data about human activities. We also included other datasets that covered domains of interest to us. Key domains were people, animals, famous figures, interiors, landmarks and landscapes, various types of technology, human activities, and emotions.
After collecting the data, filtering out overly short descriptions, overly small pictures, pictures with unexaptable aspect ratios, and pictures poorly matching their description (we used the English CLIP model for this), after translation of all English captions into Russian, we were able to create a broad learning dataset of over 120 million pairs image—text caption.
Below is the sloping learning trajectory of ruDALL-E XXL. As you can see, learning needed to be restarted a few times after mistakes and getting off track as a result of Nan.
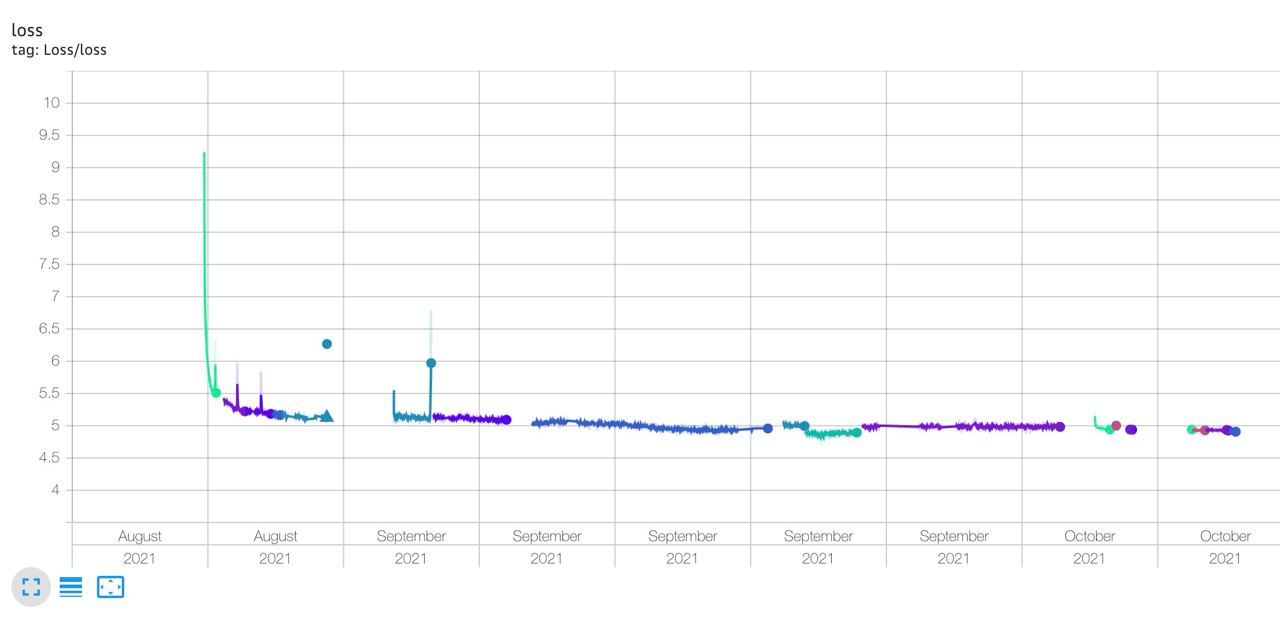
The ruDALL-E XXL model was trained in 2 phases: 37 days on 512 TESLA V100 GPUs, and then another 11 days on 128 TESLA V100 GPUs.
Details of training ruDALL-E XL:

Loss dynamics on a train sample 
Loss dynamics on a valid sample 
Learning rate dynamics The ruDALL-E XL model was trained in 3 phases: 8 days on 128 TESLA V100 GPUs, and then another 6.5 and 8.5 days on 192 TESLA V100 GPUs, but with slightly different training samples.
Choosing optimal generation parameters for different objects and domains is not easy. When it came time to use the model generatively, we began with Nucleus Sample and Top-K sampling. These have already proven their usefulness on NLP tasks and limit the token space accessible for generation. Although this topic is well researched for textual creation, the standard setup turned out not to work well for images. A series of experiments helped us determine appropriate parameter ranges, but also indicated to us that for different types of outputs, the ranges might be drastically different. A mistake might cause significant degradation of quality in the resulting images. Whether parameter ranges can be determined automatically for generation is a topic for future investigations.




Here are some not-so-great examples of output generated in response to the request, «котик с красной лентой» (“cat with a red ribbon”):

And here are some results for the request, "Автомобиль на дороге среди красивых гор" (“A car on a road surrounded by beautiful mountains”). In the one on the left, the car encountered some sort of pole, and on the right, it is misshapen.
")
Pipeline for image generation
Image generation today involves using a pipeline consisting of three parts: 1) generation using ruDALL-E, 2) ranking the results with ruCLIP, and 3) improving the quality and resolution of the images using SuperResolution.
During generation and ranking, it’s possible to play with the parameters that affect the quantity of examples generated, their selection, and their level of abstraction.
Pipeline for generating images from text:

In Colab one can run the inference model ruDALL-E XL using the whole pipeline (image generation, automatic ranking, and enlargement). Let’s review it via the example with the deer from earlier.
Step 1. Set up and import libraries
git clone https://github.com/sberbank-ai/ru-dalle
pip install -r ru-dalle/requirements.txt > /dev/null
from rudalle import get_rudalle_model, get_tokenizer, get_vae,
get_realesrgan, get_ruclip
from rudalle.pipelines import generate_images, show, super_resolution,
cherry_pick_by_clip
device = 'cuda' Step 2. Generate images based on the textual input.
text = 'озеро в горах, а рядом красивый олень пьет воду'
tokenizer = get_tokenizer()
dalle = get_rudalle_model('Malevich', pretrained=True, fp16=True, device=device)
vae = get_vae().to(device)
pil_images, _ = generate_images(text, tokenizer, dalle, vae, top_k=1024, top_p=0.99, images_num=24)
show(pil_images, 24)The result looks like this:

Step 3. Automatic ranking of images and selection of the best
ruclip, ruclip_processor = get_ruclip('ruclip-vit-base-patch32-v5')
ruclip = ruclip.to(device)
top_images, _ = cherry_pick_by_clip(pil_images, text, ruclip,
ruclip_processor, device=device, count=24)
show(top_images, 6)")
It’s worth noticing that one deer looks fairly slug-like. During generation, one can tweak hyperparameters that control how well the output matches your domain. After experimenting a bit, we learned that the parameters top_p and top_k control the level of abstraction in the image. We generally recommend assigning their values this way:
top_k=2048, top_p=0.995
top_k=1536, top_p=0.99
top_k=1024, top_p=0.99
Step 4. Apply Super Resolution
realesrgan = get_realesrgan('x4', device=device)
sr_images = super_resolution(top_images, realesrgan)
show(sr_images, 6)
The model catalog DataHub (ML Space Christofari) can also be used to initialize the pipeline for ruDALL-E XXL or XL.
The future for multimodal models
Multimodal research is becoming more and more popular for the wide variety of tasks. Taking center stage are CV + NLP (the first such model for Russian, called ruCLIP, we presented here). Just behind them are NLP + programming code. And then there are models being trained on many source media simultaneously, for example, AudioCLIP. Of particular interest is the Foundation Model, which was recently announced by researchers at Stanford University.
Along this line, the AI Journey conference was holding the Fusion Brain Challenge competition as we speak. In it a unified model has to solve the following four tasks:
С2С — translation from Java to Python;
HTR — recognition of handwriting found in photographs;
Zero-shot Object Detection — detection of objects described in natural language in images;
VQA — answers to questions about images.
According to the competition’s rules, the neural network should dedicate at least 25% of its parameters to general weights! Weights shared among tasks makes models more economical compared to their monomodal analogs. The organizers also provided a baseline solution, which can be found officially on GitHub, and the teams provided very good concepts of the Fusion Brain. Despite the fact that the competition has been completed, the organizers promise to develop this idea and launch a new competition for a longer period.
While specialists are pumping their skills, and while companies will cultivate their calculating prowess for training private models, we remain dedicated to open source and the community at large. We’d be happy to see your prototypes, unexpected finds, tests, and suggestions for model improvement!
The most important links:
Free demo available: https://rudalle.ru/en/
Free Telegram bot
Better and faster generation is available with the Salute App: https://sberdevices.ru/app/
Instagram with examples of the best generations
GitHub with ruDALL-E XL
Team of authors: @rybolos, @shonenkov, @ollmer, @kuznetsoff87, @alexander-shustanov, @oulenspeigel, @mboyarkin, @achertok, @da0c, @boomb0om
