Комментарии 22
Итак у вас 13 признаков. Разница в показателях между успехом и неуспехом у вас около 10%.
Чтоб получить значение по каждому признаку хотя бы в пределах 1%, вам надо сколько записей проанализировать? миллион? миллиард? там же N^M при M признаках, нет?
Имхо вы слишком много параметров в модель внесли. Какая достоверность модели? Доверительные интервалы?
Чтоб получить значение по каждому признаку хотя бы в пределах 1%, вам надо сколько записей проанализировать? миллион? миллиард? там же N^M при M признаках, нет?
Имхо вы слишком много параметров в модель внесли. Какая достоверность модели? Доверительные интервалы?
Вроде немного разбираюсь в ML, но суть вопроса от меня ускользает. Речь идет о «curse of dimensionality»? Собственно, автор пишет, что изначально признаков было около 100, но в результате осталось 13, то есть это уже результат некого отбора. И признаки с точки зрения здравого смысла выглядят достаточно релевантными.
И зачем «получать значение каждого признака в пределах 1%»? Конечно же в тренировочных данных будут «пустоты» с отсутствующими диапазонами значений признаков, но это не мешает построить модель, которая стабильно дает прогноз лучше, чем простое подбрасывание монеты. Скорее всего на ограниченном отрезке времени такие же «пустоты» будут и в данных, которые используются для прогноза, ну и никто не мешает снова обучить модель на новых данных.
И зачем «получать значение каждого признака в пределах 1%»? Конечно же в тренировочных данных будут «пустоты» с отсутствующими диапазонами значений признаков, но это не мешает построить модель, которая стабильно дает прогноз лучше, чем простое подбрасывание монеты. Скорее всего на ограниченном отрезке времени такие же «пустоты» будут и в данных, которые используются для прогноза, ну и никто не мешает снова обучить модель на новых данных.
Возможно, я не до конца поняла ваш вопрос, но постараюсь всё же ответить)
Если вас интересует соотношение объема выборки и количества признаков, то могу вам ответить, что для обучения модели у нас была выборка размерностью около 50К — по всем эмпирическим rules of thumb данное соотношение вполне подходит для того, чтобы строить даже достаточно сложные модели.
Кроме того — признаки, которые остались в модели, были отобраны из большего множества как значимые (в основном на основании применения различных статистических критериев средних).
Иными словами, если какой-то признак был слабо представлен в одном из классов или не давал статистического различия между классами, то, скорее всего, он не прошел этап отбора признаков.
По поводу достоверности модели могу сказать, что все метрики, которые приведены в статье — получены по тестовой подвыборке и, кроме того, различие в метриках между обучающей и тестовой выборками было незначительное, а значит можно говорить об устойчивости прогноза.
Если вас интересует соотношение объема выборки и количества признаков, то могу вам ответить, что для обучения модели у нас была выборка размерностью около 50К — по всем эмпирическим rules of thumb данное соотношение вполне подходит для того, чтобы строить даже достаточно сложные модели.
Кроме того — признаки, которые остались в модели, были отобраны из большего множества как значимые (в основном на основании применения различных статистических критериев средних).
Иными словами, если какой-то признак был слабо представлен в одном из классов или не давал статистического различия между классами, то, скорее всего, он не прошел этап отбора признаков.
По поводу достоверности модели могу сказать, что все метрики, которые приведены в статье — получены по тестовой подвыборке и, кроме того, различие в метриках между обучающей и тестовой выборками было незначительное, а значит можно говорить об устойчивости прогноза.
НЛО прилетело и опубликовало эту надпись здесь
Мы ждали этот вопрос) Тот, который не про КДПВ.
Конечно, время задуматься про модель определения оптимального канала коммуникации с человеком: время мы уже знаем, а всем, действительно, не угодишь, — кто-то любит голосом общаться, кто-то текстом.
Но бывают случаи, когда иначе сложно. Вы откажете оператору. Ок. А кто-то с ним поговорит: и обратная связь поможет развивать продукт. Здесь не всегда подойдет опросник с 10 пунктами или онлайн-анкета: банально, но, когда человек пишет, он больше задумывается над формой или банально отвлекается, из-за этого иногда теряется важный смысл и нюансы. Оператор же, по сути, собирает эти нюансы. Она, причины поступков — и то, как человек их для себя формулирует — могут быть очень индивидуальны.
Видите, здесь речь идет не об одностороннем случае коммуникации вида «привет, хочу рассказать тебе, что...», а о случае «привет, а расскажи, пожалуйста....» — т.е. это диалог.
p.s. К сожалению, в жизни бывают и более грустные неожиданные звонки, если понимаете, о чем я. А звонки колл-центра всегда можно пережить)
Конечно, время задуматься про модель определения оптимального канала коммуникации с человеком: время мы уже знаем, а всем, действительно, не угодишь, — кто-то любит голосом общаться, кто-то текстом.
Но бывают случаи, когда иначе сложно. Вы откажете оператору. Ок. А кто-то с ним поговорит: и обратная связь поможет развивать продукт. Здесь не всегда подойдет опросник с 10 пунктами или онлайн-анкета: банально, но, когда человек пишет, он больше задумывается над формой или банально отвлекается, из-за этого иногда теряется важный смысл и нюансы. Оператор же, по сути, собирает эти нюансы. Она, причины поступков — и то, как человек их для себя формулирует — могут быть очень индивидуальны.
Видите, здесь речь идет не об одностороннем случае коммуникации вида «привет, хочу рассказать тебе, что...», а о случае «привет, а расскажи, пожалуйста....» — т.е. это диалог.
p.s. К сожалению, в жизни бывают и более грустные неожиданные звонки, если понимаете, о чем я. А звонки колл-центра всегда можно пережить)
А звонки колл-центра всегда можно пережить)
Многое можно пережить, но это не значит что это надо переживать. И по этому месту в вашем тексте лично я вижу понимание того, что ваше поведение на самом то деле не совсем социально.
И получается что когда речь идёт о вашей прибыли, то на человека на другом конце провода вам в общем-то наплевать.
Или я что-то неправильно понимаю?
Субъективное мнение: компания, которая пишет так
А звонки колл-центра всегда можно пережить)не может говорить о лояльности и о том, что она старается не бесить пользователей. Она может врать об этом с самого первого предложения статьи. Инженеры дожили до того, что врут подобно менеджерам в своих статьях о том, зачем и что они делают. И это уже ужасно, даже если не рассматривать методы и качество этого исследования, либо качество его описания.
пережить и внести очередной номер в черный список
На графиках с конверсиями хорошо бы еще доверительные интервалы сделать, чтобы было понятно, что это не просто случайно так вышло, а и правда есть закономерность.
В механизм последующего выбора времени дозвона хорошо бы еще встроить немного рандома, чтобы не переобучаться потом на себя.
В механизм последующего выбора времени дозвона хорошо бы еще встроить немного рандома, чтобы не переобучаться потом на себя.
По поводу доверительных интервалов — согласна, с ними было бы намного нагляднее. Для примера я построила доверительные интервалы для одного из первых графиков, где представлена конверсия по дням недели общая и в разрезах Москва/Санкт-Петербург и регионы — получилось следующее:
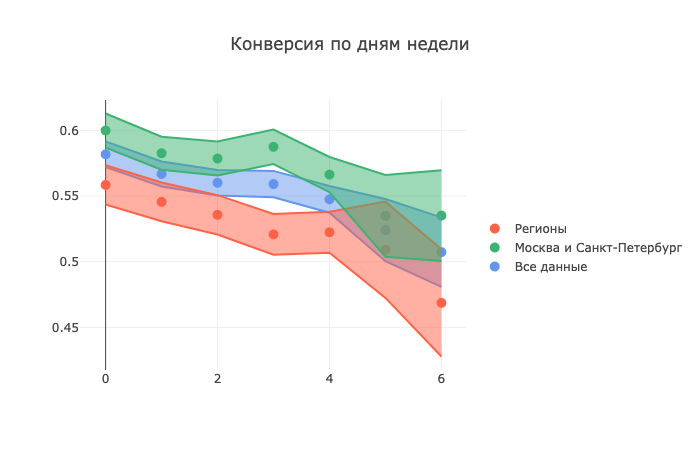
Здесь хорошо видно, что в выходные доверительный интервал шире, так как там намного меньше изначальное количество совершенных звонков, но в целом доверительные интервалы получились не слишком широкими и видно, что общая зависимость по дням недели в них укладывается.
По поводу второго вопроса с рандомизацией результатов прогноза — на самом деле она уже в некотором виде есть. Модель на выходе для каждого пользователя рассчитывает слоты по часам и дням недели с вероятностями дозвона, однако, операторы не всегда выбирают наилучший слот:

Здесь хорошо видно, что в выходные доверительный интервал шире, так как там намного меньше изначальное количество совершенных звонков, но в целом доверительные интервалы получились не слишком широкими и видно, что общая зависимость по дням недели в них укладывается.
По поводу второго вопроса с рандомизацией результатов прогноза — на самом деле она уже в некотором виде есть. Модель на выходе для каждого пользователя рассчитывает слоты по часам и дням недели с вероятностями дозвона, однако, операторы не всегда выбирают наилучший слот:
Если звонок не срочный, то оператор может подобрать наиболее оптимальный слот на неделе, а в крайнем случае — если звонок откладывать уже нельзя — самый удачный момент текущего рабочего дня.
Наталья, интересный опыт и рассуждения, похвально, что стараетесь быть удобными… но почему-то очень много предположений «скорее всего», «наверное» и нигде не рассматривается вариант напрямую спросить человека об удобном для него времени: безальтернативно принято суждение, что с 10-18 отправная точка, но ведь это рабочее время, клиенту может быть как раз неудобно отвечать в это время… А на практике странность еще и в том, что даже на прямую просьбу не звонить с 10 до 18 ваш колл-центр настойчиво продолжает это делать… не слишком ли вы загоняете его в рамки?
Спасибо за статью, она довольно интересная.
Как вы считаете, можно ли ваши результаты распространить на другие компании? Я правильно понимаю, что люди не знают, что им звонит именно skyeng? И получается, что любая компания с колцентром может воспользоваться вашими результатами, чтобы улучшить вероятность дозвона?
Как вы считаете, можно ли ваши результаты распространить на другие компании? Я правильно понимаю, что люди не знают, что им звонит именно skyeng? И получается, что любая компания с колцентром может воспользоваться вашими результатами, чтобы улучшить вероятность дозвона?
Скорее всего в воскресенье утром учатся дети. Им такой график удобнее, точнее мамам: пока мама занимается домашними делами, чадо под присмотром занимается полезным. А вечером у школьников уже свои дела, друзья и улица.
А если у пользователей будет стоять запрет на все незнакомые номера то как? Если вам это действительно важно, а не просто для галочки, то не лучше ли сначала послать смс, где вы представившись с названием вашей компании и номера телефона, можете предложить время когда вы сможете позвонить. И человек заинтересованный в вас забьет ваш номер, который будет определяемым и тогда сможет поговорить. Я понимаю это долго и не удобно, но почти всегда наверняка. Это если вам это действительно нужно.
Я вас точно не услышу, у меня запрет
Запрет на все входящие может сильно аукнуться: что, если кому-то из семьи стало плохо, или украли телефон, а у Вас — запрет?
Лучше использовать какой-нибудь анти-спам, типа Kaspersky WhoCalls. Раза три-четыре на дню звонят шаромыжники, и он сам их отсекает. Чем больше пользователей пожалуются ему на номер, тем быстрее номер начнёт отсекаться у всех пользователей. Очень рекомендую.
Лучше использовать какой-нибудь анти-спам, типа Kaspersky WhoCalls. Раза три-четыре на дню звонят шаромыжники, и он сам их отсекает. Чем больше пользователей пожалуются ему на номер, тем быстрее номер начнёт отсекаться у всех пользователей. Очень рекомендую.
стараюсь сократить подобные «разговоры» до трех секунд, понять, что это не важный звонок и сказать громко и ясно: нет, спасибо, до свидания.
Анти-спам из яндекс телефона неплохо отрабатывает, некоторые звонки просто не берется трубка, добавляется в бан по повторной попытке.
Анти-спам из яндекс телефона неплохо отрабатывает, некоторые звонки просто не берется трубка, добавляется в бан по повторной попытке.
У нас самые конверсионные дни — вторник, среда. Во вторник обычно больше конверсий, но бывает и среда обгоняет. Но редко. В понедельник конверсия ближе к концу дня разгоняется, в пятницу активность утром, а к вечеру — падает. И так уже полтора года. Я удивляюсь, какие люди все-таки предсказуемые существа.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Как я построила прогнозную модель call-центра, чтобы их звонки не бесили пользователей