
Название ENTRYPOINT всегда меня смущало. Это название подразумевает, что каждый контейнер должен иметь определенную инструкцию ENTRYPOINT. Но после прочтения официальной документации я понял, что это не соответствует действительности.
Название ENTRYPOINT всегда меня смущало. Это название подразумевает, что каждый контейнер должен иметь определенную инструкцию ENTRYPOINT. Но после прочтения официальной документации я понял, что это не соответствует действительности.

Компания GitLab уже несколько раз привлекала наше внимание: мы писали об инциденте с базой данных, решении перейти на собственное железо и о том, как пользователи убедили GitLab не уходить из облака. Все эти истории объединяет небывалая открытость, которую проявила компания при ликвидации последствий аварий и принятии жизненно важных решений. Мы решили узнать причины такой публичности и нашли замечательный документ, в котором описаны ценности GitLab.
Помимо открытости в нем оказалось много вещей, с которыми, как нам кажется, будет интересно познакомиться и читателям Хабра. Многие из нас работают в похожих условиях: из дома, общаясь удаленно, иногда годами не видя своих коллег. У такого типа работы есть не только преимущества, но и недостатки, а компания GitLab накопила немалый опыт, который может оказаться полезен нам всем. Перевод ценностей GitLab вы можете найти под катом.

Я стал техническим руководителем около двух лет назад. За это время одной из самых сложных задач оказалось нахождение баланса между обязанностями руководителя и желанием программировать.
Похоже, я не единственный, кто столкнулся с такого рода трудностями, поэтому думаю, что стоит добавить в обсуждение этого вопроса и мои пять копеек.

В первой части статьи «Ускоряем восстановление бэкапов в Postgres» я рассказал о предпринятых шагах по уменьшению времени восстановления в локальном окружении. Мы начали с простого: pg_dump-пили (а есть ли такое слово?), паковали gzip-ом, распаковывали и направляли вывод в psql < file.sql. На восстановление уходило около 30 минут. В итоге мы остановились на настраиваемом (custom) формате Postgres и применили аргумент -j, добившись уменьшения времени до 16 минут.
В этой статье я описал, как нам удалось уменьшить размер файла резервной копии, что дополнительно ускорило процедуру восстановления.

Мои ощущения от процесса работы
Недавно я решил заняться ускорением восстановления нашей базы данных в dev-окружении. Как и во многих других проектах, база вначале была небольшой, но со временем значительно выросла. Когда мы начинали, ее размер было всего несколько мегабайт. Теперь упакованная база занимает почти 2 ГБ (несжатая — 30 ГБ ). Мы восстанавливаем dev-окружение в среднем раз в неделю. Старый способ проведения операции перестал нас устраивать, а вовремя подвернувшаяся в Slack-канале картинка “DB restore foos?” побудила меня к действию.
Ниже описано, как я ускорял операцию восстановления базы данных.

Чтобы отслеживать состояние работающих приложений, необходимо проводить их постоянный мониторинг. А если приложения выполняются в таком хорошо масштабируемом окружении, как Docker Swarm, то потребуется также и хорошо масштабируемый инструмент мониторинга. В этой статье говорится о настройке именно такого инструмента.
В процессе работы мы установим агенты cAdvisor на каждой ноде для сбора метрик хоста и контейнеров. Метрики будут сохраняться в InfluxDB. Для построения графиков на основе этих метрик воспользуемся Grafana. Эти инструменты распространяются с открытым исходным кодом и могут быть развернуты в виде контейнеров.
Для построения кластера мы будем использовать Docker Swarm Mode и развернем необходимые сервисы в виде стека. Это позволит организовать динамическую систему мониторинга, которая способна автоматически начинать мониторинг новых нод по мере их добавления в рой (swarm). Файлы проекта можно найти здесь.

Кадр из фильма «Матрица: Революция»
В этой статье мы подробно рассмотрим детали одной интересной находки: два часто используемых системных вызова (gettimeofday, clock_gettime) в AWS EC2 выполняются очень медленно.
В Linux реализован механизм по ускорению этих двух часто используемых системных вызовов, благодаря которому их код выполняется в пространстве пользователя, что позволяет избежать переключениям в контекст ядра. Это сделано с помощью предоставляемой ядром виртуальной общей библиотеки (virtual shared library), которая отображается в адресное пространство всех запущенных программ.
Два вышеназванных системных вызова не могут использовать vDSO (virtual Dynamic Shared Object) в AWS EC2, поскольку виртуализированный источник временных меток (virtualized clock source) в xen (и некоторых конфигурациях kvm) не поддерживает получение информации о времени через vDSO.
Обойти эту проблему не получится. Можно поменять источник информации о времени на tsc, но это небезопасно. Далее мы рассмотрим вопрос более подробно и проведем сравнительное тестирование с помощью microbenchmark.
 Согласно данным, которые представил на Dockercon 2016 CEO компании Docker Бен Го́луб (Ben Golub), количество работающих в контейнерах Docker приложений за последние два года выросло на 3100%. Docker обеспечивает функционирование 460 тысяч приложений по всему миру. Это невероятно!
Согласно данным, которые представил на Dockercon 2016 CEO компании Docker Бен Го́луб (Ben Golub), количество работающих в контейнерах Docker приложений за последние два года выросло на 3100%. Docker обеспечивает функционирование 460 тысяч приложений по всему миру. Это невероятно!
Если вы еще не начали использовать Docker, прочтите этот впечатляющий документ о его внедрении. Docker изменил подход к созданию приложений и стал крайне важным инструментом для разработчиков и DevOps-специалистов. Эта статья рассчитана на тех, кто уже использует Docker, и призвана открыть еще одну причину, по которой стоит продолжать это делать.
Мы бы хотели поделиться своим опытом использования docker-compose в больших проектах. Применив этот инструмент для автоматизации задач, связанных с разработкой, тестированием и конфигурированием, мы за несколько простых шагов смогли сделать нашу команду более эффективной и сфокусироваться непосредственно на разработке продукта.

В конце 2016 компания Gitlab сообщила, что собирается уходить из облака (мы делали перевод этой статьи на Medium). Также был представлен весьма подробный план по покупке аппаратного обеспечения. Пользователи с интересом следили за развитием событий, активно комментировали опубликованные статьи и в итоге убедили GitLab отказаться от этой идеи.
У этой истории есть дополнительная интрига. Компания GitLab, которая сама по сути является поставщиком облачных услуг (правда, предоставляя пользователям приложение, а не вычислительные ресурсы), вдруг решила, что ей как потребителю подобная схема работы больше не подходит, но все же в итоге передумала.

Возможно ли с помощью Python обработать миллион запросов в секунду? До недавнего времени это было немыслимо.
Многие компании мигрируют с Python на другие языки программирования для повышения производительности и, соответственно, экономии на стоимости вычислительных ресурсов. На самом деле в этом нет необходимости. Поставленных целей можно добиться и с помощью Python.
Python-сообщество в последнее время уделяет много внимания производительности. С помощью CPython 3.6 за счет новой реализации словарей удалось повысить скорость работы интерпретатора. А благодаря новому соглашению о вызове (calling convention) и словарному кэшу CPython 3.7 должен стать еще быстрее.
Для определенного класса задач хорошо подходит PyPy с его JIT-компиляцией. Также можно использовать NumPy, в котором улучшена поддержка расширений на Си. Ожидается, что в этом году PyPy достигнет совместимости с Python 3.5.
Эти замечательные решения вдохновили меня на создание нового в той области, где Python используется очень активно: в разработке веб- и микросервисов.

В этой статье говорится о том, как настроить обратный прокси-сервер NGINX или NGINX Plus в качестве балансировщика нагрузки для хранилища объектов (object storage) на базе Minio.

Источник: 'Nova typis transacta navigatio' (Linz: s.n., 1621), p.12 (British Library, G.7237).
Часто во время разговоров о Docker я слышу мнения, с которыми не совсем согласен.
«Docker по своей сути предназначен для крупных компаний»
«под OSx у него экспериментальная поддержка, под Windows работает еле-еле»
«Я не уверен, что смогу быстро развернуть его локально»
… и еще много всякого.
В этих утверждениях есть доля истины (см. ниже мифы 3 и 5), но она мала, и по большей части реальная картина получается искаженной.
А есть еще и наполненные жаргоном статьи о том, как при использовании немалого количества фреймворков обрабатывать 10к миллионов запросов в секунду. И это с помощью всего лишь 30к контейнеров при автоматизации 5к микросервисов, размещенных на шести сотнях облачных виртуальных машин…
Что ж, нетрудно догадаться, почему Docker окружен таким количеством мифов.
К сожалению, эти мифы очень живучи. И главное их достижение заключается в том, что они пугают разработчиков и не дают им решиться на использование Docker.
Давайте поговорим о самых распространенных мифах – тех, с которыми я сталкивался и в которые верил, – и попробуем найти в них истину, а также решения, если таковые имеются.
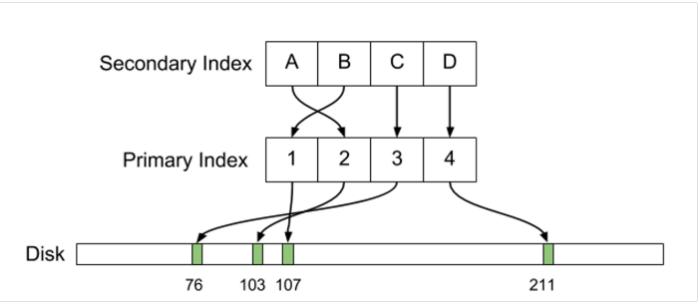
В конце июля 2016 года в корпоративном блоге Uber появилась поистине историческая статья о причинах перехода компании с PostgreSQL на MySQL. С тех пор в жарких обсуждениях этого материала было сломано немало копий, аргументы Uber были тщательно препарированы, компанию обвинили в предвзятости, технической неграмотности, неспособности эффективно взаимодействовать с сообществом и других смертных грехах, при этом по горячим следам в Postgres было внесено несколько изменений, призванных решить некоторые из описанных проблем. Список последствий на этом не заканчивается, и его можно продолжать еще очень долго.
Наверное, не будет преувеличением сказать, что за последние несколько лет это стало одним из самых громких и резонансных событий, связанных с СУБД PostgreSQL, которую мы, к слову сказать, очень любим и широко используем. Эта ситуация наверняка пошла на пользу не только упомянутым системам, но и движению Free and Open Source в целом. При этом, к сожалению, русского перевода статьи так и не появилось. Ввиду значимости события, а также подробного и интересного с технической точки зрения изложения материала, в котором в стиле «Postgres vs MySQL» идет сравнение физической структуры данных на диске, организации первичных и вторичных индексов, репликации, MVCC, обновлений и поддержки большого количества соединений, мы решили восполнить этот пробел и сделать перевод оригинальной статьи. Результат вы можете найти под катом.

Разработанная инженерами Uber система хранения данных Schemaless используется в нескольких самых важных и крупных сервисах нашей компании (например, Mezzanine). Schemaless — это масштабируемое и отказоустойчивое хранилище данных, работающее поверх кластеров MySQL¹. Когда этих кластеров было 16, управление ими было несложным делом. Но в настоящий момент у нас их более 1 000, и в них развернуто не менее 4 000 серверов баз данных. Управление такой системой требует инструментов совсем другого класса.
Из множества компонентов, входящих в Schemadock, сравнительно небольшой, но очень важной частью является Docker. Переход на более масштабируемое решение стал для нас знаковым событием, и в данной статье мы рассказали о том, как Docker помог нам этого добиться.


В этой статье я описал создание в AWS состоящего из трех нод кластера Docker Swarm и подключение к нему общего для всех нод реплицируемого тома GlusterFS.

Он пьянел медленно, но все-таки опьянел, как-то сразу, скачком; и когда в минуту просветления увидел перед собой разрубленный дубовый стол в совершенно незнакомой комнате, обнаженный меч в своей руке и рукоплещущих безденежных донов вокруг, то подумал было, что пора идти домой. Но было поздно.
Аркадий и Борис Стругацкие
31 января 2017 года произошло важное для мира OpenSource событие: один из админов GitLab.com, пытаясь починить репликацию, перепутал консоли и удалил основную базу PostgreSQL, в результате чего было потеряно большое количество пользовательских данных и сам сервис ушел в офлайн. При этом все 5 различных способов бэкапа/репликации оказались нерабочими. Восстановились же с LVM-снимка, случайно сделанного за 6 часов до удаления базы. It, как говорится, happens. Но надо отдать должное команде проекта: они нашли в себе силы отнестись ко всему с юмором, не потеряли голову и проявили удивительную открытость, написав обо всем в твиттере и выложив в общий доступ, по сути, внутренний документ, в котором команда в реальном времени вела описание разворачивающихся событий.
Во время его чтения буквально ощущаешь себя на месте бедного YP, который в 11 часов вечера после тяжелого трудового дня и безрезультатной борьбы с Постгресом, устало щурясь, вбивает в консоль боевого сервера роковое sudo rm -rf и жмет Enter. Через секунду он понимает, что натворил, отменяет удаление, но уже поздно — базы больше нет...
По причине важности и во многих смыслах поучительности этого случая мы решили целиком перевести на русский язык его журнал-отчет, сделанный сотрудниками GitLab.com в процессе работы над инцидентом. Результат вы можете найти под катом.

— Сударь, каким образом вас взломали?
— Не образом, а контейнером.
Старинный анекдот
Все лишние компоненты компьютерной системы могут оказаться источником совершенно необязательных уязвимостей. Поэтому образы контейнеров должны по возможности содержать только то, что нужно приложению. И их размер имеет значение не только с точки зрения удобства дистрибуции, но также стоимости владения и безопасности. В этой статье мы поговорим о методах минимизации размера и поверхности атаки образов Docker, а также об инструментах их сканирования на предмет наличия уязвимостей.

В 2016 году у меня было очень много задач, связанных с реагированием на инциденты информационной безопасности. Я потратил на них в общей сложности около 300 часов, самостоятельно выполняя необходимые действия либо консультируя специалистов пострадавшей стороны. Материалом для данной статьи послужили мои записи, сделанные в процессе этой работы.
